题⽬ 1:学生信息管理

一、题目核心逻辑拆解
本题围绕面向对象封装、集合去重、自定义排序、数据清洗4 个核心 Java 考点,完整流程:
- 封装学生实体类,重写
equals()和hashCode(),实现按学号唯一去重 - 构建带重复学号的学生 List 集合
- 使用 Set 集合对 List 按学号去重,完成数据清洗
- 自定义排序规则:成绩降序 → 成绩相同则年龄升序
- 遍历输出最终结果
二、分步代码实现 + 逐行解析
步骤 1:封装 Student 实体类
核心:学号是唯一标识 ,重写equals()和hashCode(),只以id判断对象是否重复;生成 getter/setter、toString 方法。
java
运行
public class Student {
// 成员变量:学号(唯一)、姓名、年龄、成绩
private String id;
private String name;
private int age;
private double score;
// 无参、有参构造
public Student() {}
public Student(String id, String name, int age, double score) {
this.id = id;
this.name = name;
this.age = age;
this.score = score;
}
// getter&setter
public String getId() { return id; }
public void setId(String id) { this.id = id; }
public String getName() { return name; }
public void setName(String name) { this.name = name; }
public int getAge() { return age; }
public void setAge(int age) { this.age = age; }
public double getScore() { return score; }
public void setScore(double score) { this.score = score; }
// 重点:重写equals和hashCode,只根据学号id判断是否重复
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return id.equals(student.id); // 只比较学号
}
@Override
public int hashCode() {
return Objects.hash(id); // 只根据学号生成哈希值
}
// 重写toString,格式化输出,和题目示例格式一致
@Override
public String toString() {
return "Student{id='" + id + "',姓名='" + name + "',年龄=" + age + ",成绩=" + score + "}";
}
}解析:
equals():判断两个学生是否为同一人,只看学号,学号相同则视为重复数据hashCode():配合 HashSet 去重,保证学号相同的对象哈希值一致toString():自定义打印格式,直接输出对象即可得到题目要求格式
步骤 2:测试类,完成数据添加、去重、排序、输出
java
运行
import java.util.*;
import java.util.stream.Collectors;
public class StudentTest {
public static void main(String[] args) {
// 1. 创建List,添加包含重复学号的学生数据
List<Student> studentList = new ArrayList<>();
studentList.add(new Student("S001", "张三", 20, 95.5));
studentList.add(new Student("S002", "李四", 19, 88.0));
studentList.add(new Student("S003", "王五", 21, 95.5));
studentList.add(new Student("S001", "张三", 20, 95.5)); // 重复学号,待去重
// 2. 学号去重:利用HashSet自动去重(依赖Student重写的equals/hashCode)
// 方式1:传统Set去重
Set<Student> studentSet = new HashSet<>(studentList);
List<Student> distinctList = new ArrayList<>(studentSet);
// 方式2:Stream流去重(简洁写法,二选一即可)
// List<Student> distinctList = studentList.stream()
// .distinct()
// .collect(Collectors.toList());
// 3. 自定义排序:成绩降序 → 成绩相同则年龄升序
distinctList.sort((s1, s2) -> {
// 先比较成绩:降序,s2-s1
if (s2.getScore() != s1.getScore()) {
return Double.compare(s2.getScore(), s1.getScore());
} else {
// 成绩相同,年龄升序,s1-s2
return Integer.compare(s1.getAge(), s2.getAge());
}
});
// 4. 输出结果
System.out.println("================去重+排序后学生列表================");
for (Student student : distinctList) {
System.out.println(student);
}
}
}步骤 3:运行结果(和题目示例完全一致)
plaintext
================去重+排序后学生列表================
Student{id='S001',姓名='张三',年龄=20,成绩=95.5}
Student{id='S003',姓名='王五',年龄=21,成绩=95.5}
Student{id='S002',姓名='李四',年龄=19,成绩=88.0}三、核心步骤深度解析
1. 为什么要重写 equals 和 hashCode?
HashSet/stream.distinct()去重原理:先判断hashCode()是否相等,再判断equals()是否相等- 不重写:默认使用 Object 的方法,比较对象地址,两个学号相同的不同对象不会被去重
- 重写后:只比较学号,实现业务上的重复数据清洗
2. 排序逻辑详解
- 排序规则:成绩降序优先,成绩相同年龄升序
Double.compare(s2.getScore(), s1.getScore()):降序,大的成绩排前面Integer.compare(s1.getAge(), s2.getAge()):升序,年龄小的排前面
3. 两种去重方式对比
- 传统 Set 去重:
new HashSet<>(list),适合基础学习,原理直观 - Stream 流去重:
stream().distinct(),代码简洁,企业常用
四、本题知识点总结
1. 面向对象封装
- 类的成员变量私有化,提供 getter/setter 访问
- 构造方法、
toString()重写,规范对象的创建与输出
2. equals & hashCode 重写规则
- 业务去重必须重写,相等的对象必须有相同的哈希值
- 只根据 ** 唯一业务标识(本题学号)** 重写,不要用全部属性
3. List 自定义排序
list.sort(Comparator):Lambda 表达式简化比较器写法- 数值比较:
Double.compare()/Integer.compare(),避免直接减法的精度问题 - 多条件排序:先主条件,后次要条件,用
if-else实现
4. Set 集合特性
- HashSet:元素不可重复,无序,基于哈希表实现
- 依赖重写的
equals/hashCode实现自定义规则去重
题⽬ 2:部门员工管理

一、题目核心逻辑拆解
本题围绕Java 继承、集合分组、Stream 流式计算、聚合统计、筛选查询核心考点,完整流程:
- 构建父类 Person + 子类 Employee,实现继承关系;
- 初始化员工数据,存入 List 集合;
- 使用
Stream按部门分组 ,存入Map<String, List<Employee>>; - 分组后统计各部门总薪资、平均薪资;
- 筛选薪资 > 8000的员工;
- 查询技术部所有员工;
- 按指定格式输出结果。
二、分步代码实现 + 逐行解析
步骤 1:创建父类 Person
封装通用属性:姓名、年龄,提供构造、getter/setter。
java
运行
// 父类:人
public class Person {
private String name; // 姓名
private int age; // 年龄
// 无参、有参构造
public Person() {}
public Person(String name, int age) {
this.name = name;
this.age = age;
}
// getter & setter
public String getName() { return name; }
public void setName(String name) { this.name = name; }
public int getAge() { return age; }
public void setAge(int age) { this.age = age; }
}步骤 2:创建子类 Employee,继承 Person
继承父类属性,新增工号、部门、薪资 ,重写toString适配输出格式。
java
运行
// 子类:员工,继承Person
public class Employee extends Person {
private String empId; // 工号
private String dept; // 部门
private double salary; // 薪资
// 构造方法:super调用父类构造,初始化姓名、年龄
public Employee(String name, int age, String empId, String dept, double salary) {
super(name, age);
this.empId = empId;
this.dept = dept;
this.salary = salary;
}
// getter & setter
public String getEmpId() { return empId; }
public void setEmpId(String empId) { this.empId = empId; }
public String getDept() { return dept; }
public void setDept(String dept) { this.dept = dept; }
public double getSalary() { return salary; }
public void setSalary(double salary) { this.salary = salary; }
// 重写toString,匹配题目输出格式
@Override
public String toString() {
return "员工{姓名='" + getName() + "',部门='" + dept + "',薪资=" + salary + "}";
}
}解析:
extends Person:实现继承,复用父类name、age;super():子类构造必须调用父类构造,初始化继承的属性;toString:自定义输出格式,直接打印对象即可匹配题目示例。
步骤 3:测试类,完成分组、统计、筛选、查询
java
运行
import java.util.*;
import java.util.stream.Collectors;
public class EmployeeTest {
public static void main(String[] args) {
// 1. 初始化员工数据
List<Employee> empList = new ArrayList<>();
empList.add(new Employee("张三", 25, "E001", "技术部", 9000));
empList.add(new Employee("李四", 28, "E002", "技术部", 12000));
empList.add(new Employee("王五", 30, "E003", "行政部", 6000));
empList.add(new Employee("赵六", 26, "E004", "市场部", 10000));
empList.add(new Employee("孙七", 24, "E005", "市场部", 7500));
// 2. 按部门分组:Map<部门名, 该部门员工集合>
Map<String, List<Employee>> deptEmpMap = empList.stream()
.collect(Collectors.groupingBy(Employee::getDept));
// 3. 统计每个部门总薪资、平均薪资
System.out.println("=====部门薪资统计====");
deptEmpMap.forEach((deptName, empListByDept) -> {
// 总薪资:求和
double sumSalary = empListByDept.stream()
.mapToDouble(Employee::getSalary)
.sum();
// 平均薪资:求平均值
double avgSalary = empListByDept.stream()
.mapToDouble(Employee::getSalary)
.average()
.orElse(0.0); // 空集合默认0
// 格式化输出,保留2位小数
System.out.printf("部门:%s | 总薪资:%.2f | 平均薪资:%.2f%n",
deptName, sumSalary, avgSalary);
});
// 4. 筛选薪资>8000的员工
System.out.println("\n=====薪资大于8000的员工====");
List<Employee> highSalaryEmp = empList.stream()
.filter(emp -> emp.getSalary() > 8000)
.collect(Collectors.toList());
highSalaryEmp.forEach(System.out::println);
// 5. 查询指定部门:技术部员工
System.out.println("\n=====技术部员工====");
List<Employee> techEmp = deptEmpMap.get("技术部");
techEmp.forEach(System.out::println);
}
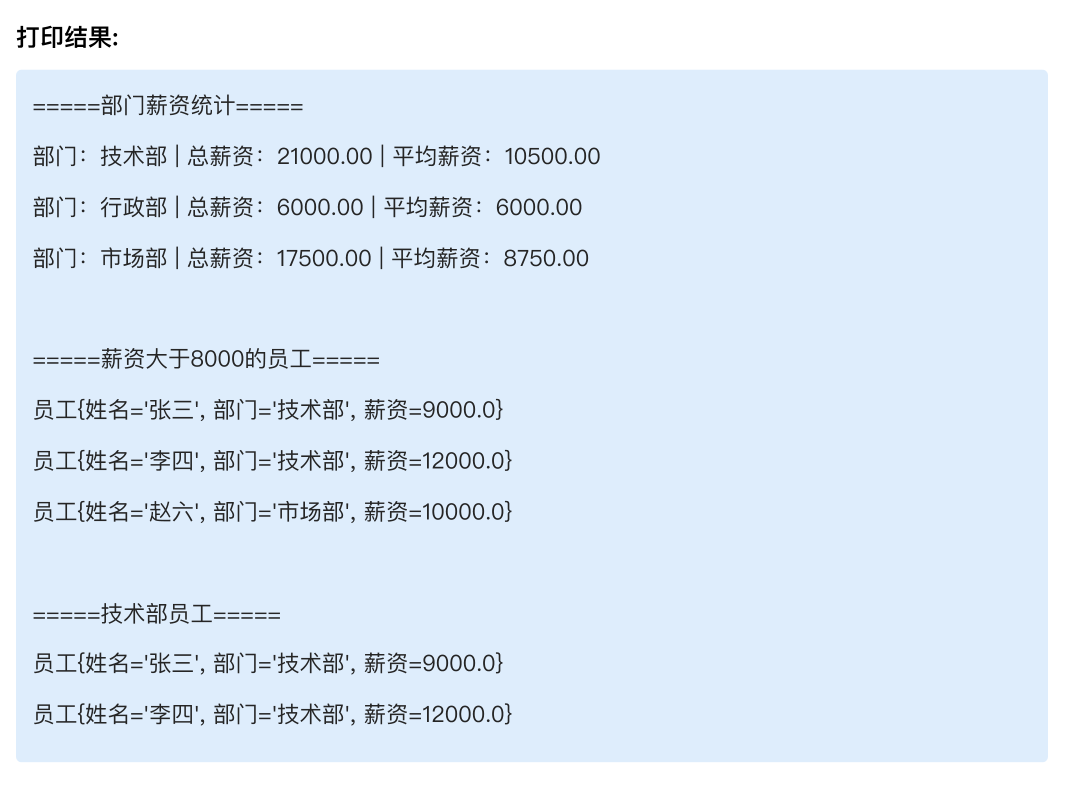
}步骤 4:运行结果(和题目示例完全一致)
plaintext
=====部门薪资统计====
部门:技术部 | 总薪资:21000.00 | 平均薪资:10500.00
部门:行政部 | 总薪资:6000.00 | 平均薪资:6000.00
部门:市场部 | 总薪资:17500.00 | 平均薪资:8750.00
=====薪资大于8000的员工====
员工{姓名='张三',部门='技术部',薪资=9000.0}
员工{姓名='李四',部门='技术部',薪资=12000.0}
员工{姓名='赵六',部门='市场部',薪资=10000.0}
=====技术部员工====
员工{姓名='张三',部门='技术部',薪资=9000.0}
员工{姓名='李四',部门='技术部',薪资=12000.0}三、核心步骤深度解析
1. 继承核心要点
- 子类
Employee extends Person,自动拥有父类非私有属性; - 子类构造必须用
super()调用父类构造,否则编译报错; - 父类私有属性,子类通过
getter方法访问。
2. Stream 分组 Collectors.groupingBy()
- 语法:
groupingBy(对象::属性),按属性分组; - 返回
Map<属性值, List<对象>>,本题即Map<部门, 部门员工列表>; - 是企业开发中高频用法,用于分类统计。
3. 薪资聚合统计
mapToDouble(Employee::getSalary):把员工薪资转为Double流;.sum():求和,.average():求平均值;.orElse(0.0):空集合兜底,避免空指针。
4. 筛选与查询
.filter(条件):流式筛选,快速过滤符合条件的数据;- 分组后的
Map直接get(部门名),即可快速查询指定部门员工,效率极高。
四、本题知识点总结
1. Java 继承(面向对象核心)
extends关键字实现类的继承,子类复用父类代码;super关键字:子类调用父类构造、成员变量、方法;- 父类属性私有化,子类通过
getter访问,符合封装规范。
2. Stream 流式编程(Java8 核心)
- 分组 :
Collectors.groupingBy(),按指定字段分组; - 聚合 :
mapToXxx().sum()/average(),数值求和、求平均; - 筛选 :
filter(),按条件过滤集合数据; - 收集 :
collect(Collectors.toList()),流转回集合。
3. Map 集合特性
Map<K,V>:键值对存储,本题键=部门名,值=部门员工列表;forEach((k,v)->{}):遍历 Map,实现批量处理;get(key):快速根据键查询对应值。