目录
[一、 传统时序数据库选型的局限与痛点](#一、 传统时序数据库选型的局限与痛点)
[二、 下一代 TSDB 选型新范式:库内分析与原生 AI](#二、 下一代 TSDB 选型新范式:库内分析与原生 AI)
[三、 破局者:Apache IoTDB 的 AINode 原生智能架构](#三、 破局者:Apache IoTDB 的 AINode 原生智能架构)
[四、 核心 AI 功能解析:不仅能存,更能"算"](#四、 核心 AI 功能解析:不仅能存,更能“算”)
[五、 模型全生命周期管理:将 MLOps 融入 DBA 日常](#五、 模型全生命周期管理:将 MLOps 融入 DBA 日常)
[六、 结语与资源获取](#六、 结语与资源获取)

🎬 攻城狮7号 :个人主页
🔥 个人专栏 :《AI前沿技术要闻》
⛺️ 君子慎独!
🌈 大家好,欢迎来访我的博客!
⛳️ 此篇文章主要介绍 面向未来的时序数据库选型指南
📚 本期文章收录在《AI前沿技术要闻》,大家有兴趣可以自行查看!
⛺️ 欢迎各位 ✔️ 点赞 👍 收藏 ⭐留言 📝!
前言
面对每天动辄TB甚至PB级增长的机器传感器数据、业务监控指标以及智能网联汽车轨迹,如何挑选一款合适的时序数据库,一直是技术架构师们绕不开的挑战。过去,我们拿着"写入吞吐量"、"数据压缩比"、"查询延迟"这三把板斧去衡量各个产品。 然而,当业务部门的需求从"看看昨天发生了什么"升级为"预测明天会发生什么"时,传统架构的疲态便显露无疑。时代变了,选型标准也必须与时俱进。
一、 传统时序数据库选型的局限与痛点
如果你现在去网上去搜"时序数据库怎么选",大部分技术文章依然在强调以下几个维度:
**(1)高并发写入能力:**物联网设备的数据产生是连续且密集的,能否抗住每秒百万级乃至千万级的数据点写入,是系统的及格线。
**(2)极致的数据压缩比:**时序数据往往带有极强的时间局部性和冗余性,优秀的压缩算法不仅能省下巨额的存储硬件成本,还能大幅降低磁盘 I/O。
**(3)多维查询与聚合性能:**降采样查询、时间窗口聚合计算是否足够快,直接决定了上层监控看板的刷新速度。
不可否认,这些基础指标依然非常重要,它们决定了系统能不能"站得稳"。但是,如果仅仅停留在这个层面,你会面临一个非常尴尬的工程困境:数据存进去了,然后呢?
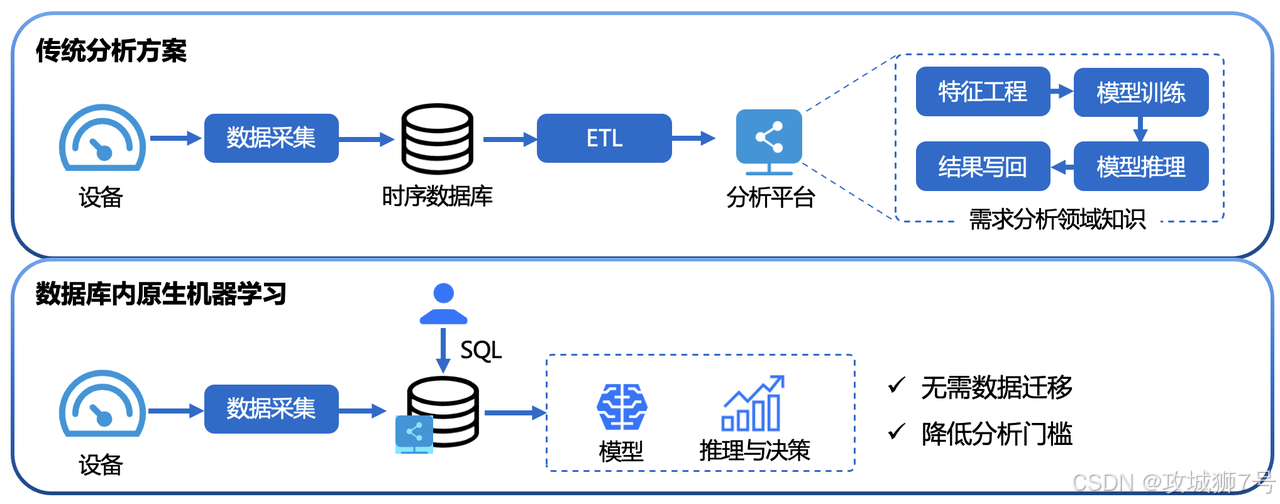
在真实的企业数据工作流中,一旦我们要对这些海量时序数据进行稍微高级一点的分析------比如用机器学习算法预测未来的电力负荷、检测产线设备的异常震动,整个架构就会变得异常臃肿。
传统的做法是"数据搬家":数据工程师需要编写复杂的 ETL 脚本,将数据从时序数据库导出;接着通过消息队列或者批量文件传输,把数据喂给外部的机器学习平台;算法工程师再使用 Python 跑模型;最后把推理出来的结果导回业务系统。
这条漫长的数据管道带来了三个致命问题:
**其一,极高的延迟。**从数据产生到模型推理出结果,中间经历了漫长的网络传输和磁盘落地,对于要求毫秒级响应的工业实时控制来说,这种延迟根本无法接受。
**其二,高昂的运维成本。**你需要同时维护数据库集群、数据同步管道以及独立的机器学习集群,排查任何一个链路节点的问题都让人头疼。
**其三,安全性风险。**数据在多个平台间流转,极大地增加了敏感数据泄露或丢失的风险。
这就引出了下一代时序数据库选型的一个核心拷问:数据库能否不只是一个冷冰冰的"仓库",而是成为一个自带"炼丹炉"的智能引擎?
二、 下一代 TSDB 选型新范式:库内分析与原生 AI
在关系型数据库和数仓领域,"计算下推"(将计算过程推送到靠近数据存储的地方执行)早已成为共识。而在时序数据领域,这种理念正在进化为更高级的形态:将 AI 模型与推理能力直接嵌入到数据库引擎中。
在进行时序数据库选型时,架构师应当把目光投向"库内智能分析"能力。一款优秀的前沿 TSDB,应当能够打破 DBA 与算法工程师之间的壁垒,让数据在不离开数据库的前提下,直接转化为业务决策。
以 Apache IoTDB 为例,它在近年来开创性地引入了原生 AI 架构,彻底颠覆了传统的时序数据分析工作流。它没有选择通过外挂第三方插件的方式来妥协,而是从底层架构上原生支持了 AI 能力。这种设计理念,正是我们在评估现代时序数据库时应当重点考察的方向。
三、 破局者:Apache IoTDB 的 AINode 原生智能架构
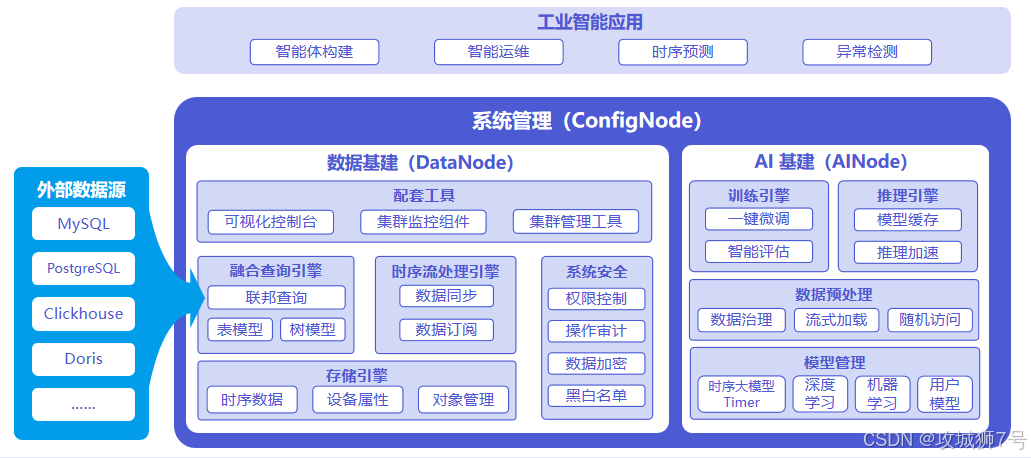
在评估 Apache IoTDB 的智能化特性时,最令人瞩目的莫过于其独创的 AINode(AI 节点)架构。这并非是一个简单的语法糖,而是一个真正将机器学习能力融入分布式数据库的系统级创新。
在一个典型的 Apache IoTDB 集群中,不同节点各司其职又紧密协作:
**(1)ConfigNode(配置节点):**它是整个集群的"大脑",负责管理分布式节点、处理系统负载均衡,同时存储和管理 AI 模型的元数据信息。
**(2)DataNode(数据节点):**它是数据的"躯干",负责接收用户的 SQL 请求,安全地将时序数据落盘,并执行底层的预处理和基础计算。
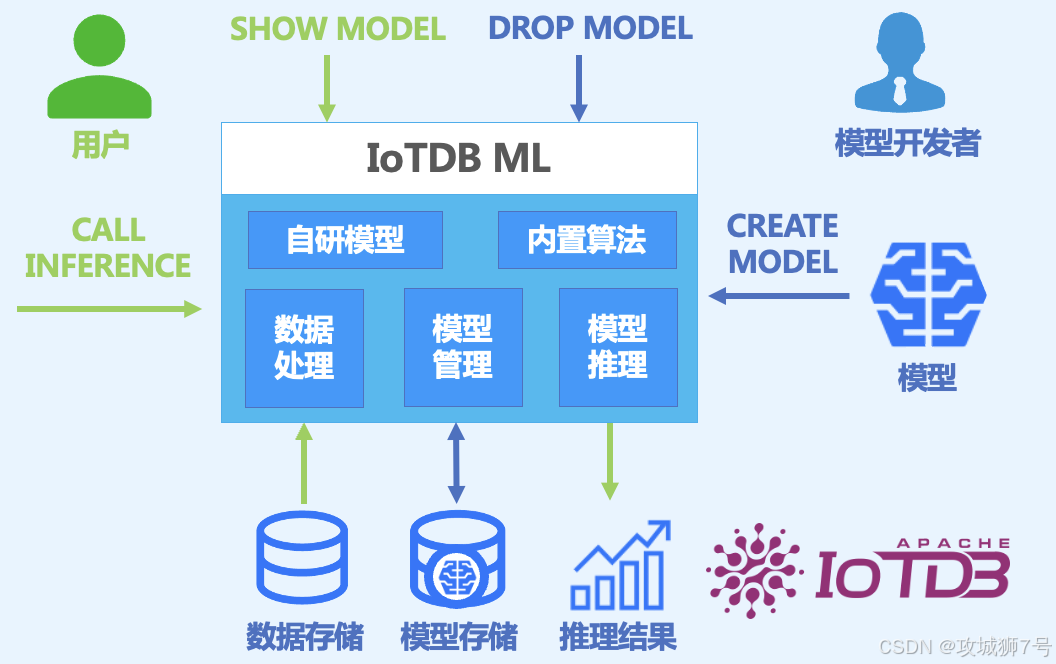
**(3)AINode(智能节点):**这是整个集群的"超级外脑",专门负责时间序列模型文件的导入、生命周期管理以及核心的模型推理与训练任务。
这种架构设计带来了一个极其优雅的用户体验:零数据迁移,零 Python 代码代码编写。
过去,算法工程师为了跑通一个模型,需要搭建复杂的 Python 数据处理栈。而在 IoTDB 的架构下,一切都被抽象为了标准的 SQL 语句。你可以直接使用 `CREATE MODEL` 语句注册一个外部训练好的模型,或者直接调用内置大模型;当需要预测未来趋势时,只需要一条 `CALL INFERENCE(...)` 语句。
这意味着时序数据刚刚写入磁盘,就可以立刻参与模型的实时推理。这种"近数据计算"的模式,彻底省去了网络 I/O 开销,实现了毫秒级的实时推理响应,同时大幅降低了整体架构的软硬件成本。
四、 核心 AI 功能解析:不仅能存,更能"算"
在考察时序数据库的 AI 特性时,我们需要深入了解它到底能解决哪些实际的业务问题。IoTDB 的 AINode 内置了众多业界领先的时序分析算法(包括清华大学自研的 Timer 系列时序大模型),覆盖了绝大多数典型的工业与商业分析场景。
(1)时序预测(Time Series Forecasting)
无论是电网的电力负荷预测,还是新能源电池的寿命衰减评估,都需要依赖历史规律来推演未来。
IoTDB 内置了诸如 Arima、HoltWinters 等经典统计算法,并前瞻性地引入了基于深度学习的 DLinear 以及 Timer 大模型。在电网预测场景下,系统可以通过分析过去一段时间内多个变压器的载荷、油温等高频数据,瞬间推理出未来数十个小时的变化曲线。以往需要跨越多个系统才能生成的预测报表,现在一条带有 `window=head(...)` 的 SQL 语句就能直接返回给监控大屏。
(2)时序异常检测(Anomaly Detection)
工业现场的传感器数据往往掺杂着大量噪声,设备故障前也会产生突发的异常波动。及时捕获这些异常,是保障生产安全的关键。
IoTDB 提供的异常检测能力(如 Stray 模型),能够让数据库在接收数据的同时自动"审视"数据。比如在交通客流量监测中,系统能学习历史序列的变化模式,一旦最新数据偏离了模型预测的置信区间,数据库便能输出异常标记。对于风控预警、设备预测性维护(PdM)来说,这无疑是极具杀伤力的特性。
(3)缺失值填补与时序标注
在现实的物联网环境中,网络抖动或传感器故障会导致时序数据出现大量空洞,带着这些缺失值去计算会导致分析结果失真。通过原生 AI 能力,IoTDB 可以在查询阶段智能地对缺失值进行推断补全。同时,系统还支持利用高斯隐马尔可夫模型(GaussianHMM)自动为特定序列添加状态突变标签,极大地减轻了数据清洗阶段的人工干预成本。
(4)灵活的窗口函数与连续推理
处理时序模型时,数据通常需要按照特定的滑动窗口进行切割。IoTDB 在 SQL 语法中原生支持了辅助模型推理的窗口函数,比如提取头尾数据的 `head(window_size)` 和 `tail(window_size)`,以及支持按步长滑动的 `count(window_size, sliding_step)`。这让类似"每收集满24行数据就进行一次异常判定"的流式连续推理任务,在数据库层面变得如同执行聚合查询一样简单直观。
五、 模型全生命周期管理:将 MLOps 融入 DBA 日常
在选型时,除了考察推理功能,还要评估模型的工程化落地能力。Apache IoTDB 将 MLOps(机器学习运维)的核心理念巧妙地融入了数据库的系统管理中。
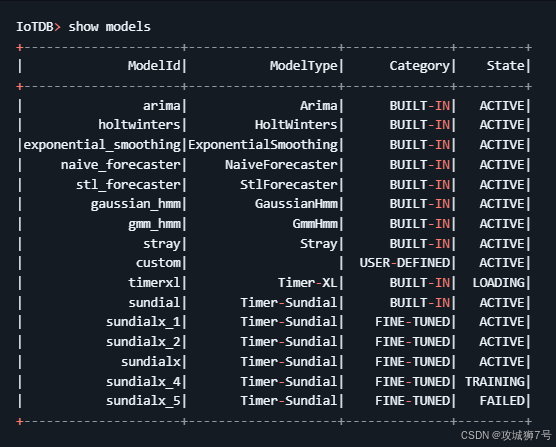
它不仅允许直接调用预置模型,还支持用户通过 URI 将外部训练好的 PyTorch 模型(`.pt` 权重文件及 `config.yaml` 配置文件)一键注册到数据库。系统会自动校验模型的输入输出维度与数据类型,确保运行时环境的安全隔离。
从模型的创建注册、查看状态流转(显示 LOADING、TRAINING、ACTIVE、DROPPING 等完整状态)、到基于特定数据集路径执行模型微调(Fine-tuning),再到最终的下线删除,整个生命周期都可以在安全可控的 SQL 权限体系(如 `USE_MODEL` 权限管控)内运行。
这种设计使得数据科学家可以心无旁骛地专注于算法本身的迭代,而运维人员和业务开发人员只需要通过统一的 SQL 接口调用最新的模型,极大提升了跨团队的协作效率。
六、 结语与资源获取
回顾时序数据库的发展,我们正处在一次从"单纯的读写性能比拼"向"深度数据智能挖掘"跨越的关键节点。在未来的系统架构设计中,是否具备计算逻辑下推的能力、是否内嵌原生 AI 推理引擎、是否能以极简的 SQL 语言抹平数据工程与数据科学的鸿沟,必将成为企业核心数据库选型的关键维度。
Apache IoTDB 以其开创性的 AINode 架构交出了一份令人惊艳的答卷。它不仅凭借扎实的分布式存储底座扛住了工业级海量数据的冲击,更用极具前瞻性的 AI 融合设计,彻底重塑了时序数据的业务价值链。对于正在寻找下一代时序数据库解决方案的企业而言,它提供了一条极其清晰且极具竞争力的技术演进路径。
如果您正在规划企业的时序数据架构,或者希望亲自体验无需搬运数据即可实现的一键式 SQL AI 建模与毫秒级推理能力,建议您深入了解 Apache IoTDB:
**- 开源版下载链接:**您可以访问 Apache 基金会官方地址获取最新版本及部署文档:
https://iotdb.apache.org/zh/Download/
**- 企业版官网链接:**如果您需要适用于大型复杂生产环境的企业级专业支持与进阶增强特性,欢迎访问天谋科技(Timecho)官网了解更多详情:
https://timecho.com
在这个数据觉醒的时代,选对具有远见的底层数据库,就是为企业的智能化未来打下最坚实的地基。
看到这里了还不给博主点一个:
⛳️ 点赞☀️收藏 ⭐️ 关注!
💛 💙 💜 ❤️ 💚💓 💗 💕 💞 💘 💖
再次感谢大家的支持!
你们的点赞就是博主更新最大的动力!