当你让机器人从厨房台面上拿一杯水递给客人时,期待的是它能避开杂乱的餐具、准确握住杯子、平稳走到你面前------而不是杯子歪了、水洒了,或者中途"迷路"。"听懂并准确做对"的朴素需求,正是真实场景对具身智能的核心考验。在过去很长一段时间里,具身智能始终在接近这个目标,却始终隔着一层难以逾越的壁垒。

机器人能听懂"把杯子拿过来",也能精准识别杯子的位置,在理想化的仿真环境中,它的路径规划几乎不会出错,可一旦走进真实的物理空间,各种意外便接踵而至:反光的厨房台面会让它的末端出现明显偏差,杂乱的物品摆放常导致它抓握空落;若是遇到"热牛奶+递杯子"这类多步骤长任务,细微的误差会不断累积,最终让整个任务功亏一篑。规划越是完美,执行越是容易脱节;任务越长,稳定性越难保障,这就是具身智能在真实场景中面临的尴尬现状。
这并不是个例,而是整个行业共同面对的现实困境。机器人的高层语义推理不断变强,底层控制算法持续优化,但二者之间始终存在一条看不见的鸿沟:理解足够聪明,执行却不够扎实;规划足够合理,落地却不够稳定。
核心困境:语义与运动之间的无形鸿沟
传统VLA模型把感知、推理、动作挤压在同一套表征体系里,模型既要理解场景语义,又要输出毫米级别的动作指令,最终顾此失彼。要知道,语义是离散、符号化的,而动作是连续、低维、高精度的,用同一套表征强行兼顾,正是问题的根源。更关键的是,执行模块为了响应实时性,往往绕过高层规划,直接依赖瞬时观测生成控制量,长时域任务的一致性几乎无法保证。

这就是"Semantic-Actuation Gap"------机器人脑子里能"理解任务"(比如知道要拿哪个杯子),但手上的动作却"做不到位"(比如抓不准、走不稳),就像人想写工整字却手抖一样,这也是具身智能走向真实世界必须跨过的核心门槛。
GO-2的破局之道:重构"思考-执行-进化"逻辑
在这样的背景下,智元新一代具身基座模型 Genie Operator-2(GO-2)正式亮相。它不是一次简单的模型迭代,不是在原有架构上增大数据、加深网络,而是从推理空间、执行架构、落地闭环三个根源层面,重构了机器人"思考---执行---进化"的完整逻辑。

GO-2的突破在于三个核心创新,精准破解行业痛点:①动作空间推理:提前模拟多种执行路径(比如绕开障碍物的3种方式),避免临时决策失误,从源头减少执行偏差;②异步粗精执行:先规划"大致路线"(粗执行),再通过实时传感器反馈微调细节(精执行),彻底解决轨迹漂移、姿态晃动的问题;③全生命周期智能体闭环:每次执行后自动记录误差(如抓握力度不足、位置偏差),下次执行时直接优化调整,让机器人在反复实践中持续提升稳定性。

这套创新设计,让GO-2首次在统一架构内,实现了动作空间推理、异步粗精执行、全生命周期智能体闭环的深度融合,真正实现从"理解任务"到"稳定完成任务"的跨越,让具身智能的核心目标------"知行合一"不再是口号。
从GO-1到GO-2:从"能做"到"稳定做"的跨越
回望智元在具身智能领域的技术路径,从 GO-1 到 GO-2 的演进,清晰而坚定。GO-1 凭借 ViLLA 架构首次实现视觉-语言-动作的统一表征建模,把机器人从专用策略带入通用基座模型时代。它让机器人具备了跨场景感知、泛化指令理解、基础动作执行的能力,在真实环境中完成了规模化落地验证,实现了"能做"的突破------比如单次拿杯子成功率可达70%。
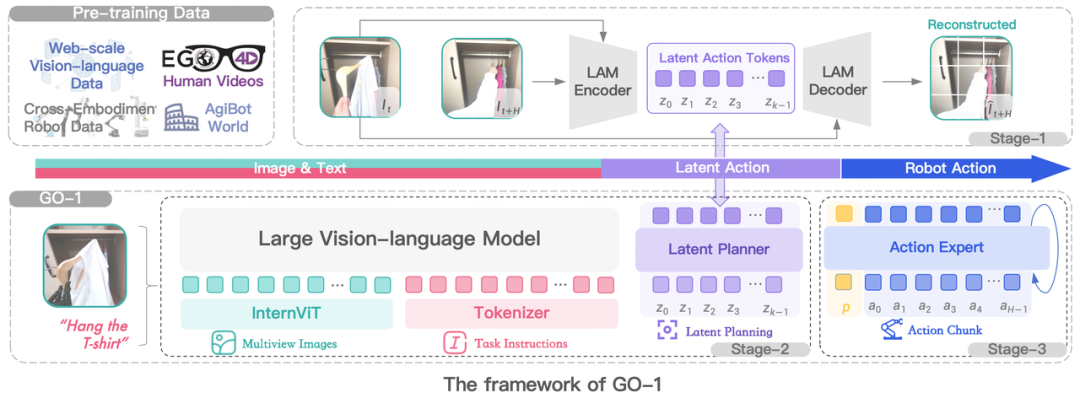
但当任务进入长时域、多扰动、多物体交互的场景时,GO-1规划与执行断裂的问题被无限放大:像"取快递+拆包装+放桌上"这样的长任务,其成功率仅45%,一旦遇到有人碰了桌子、物品位置轻微移动等扰动,就很容易任务失败。而GO-2的诞生,正是为了补上这最后一块短板,它将长任务成功率提升至82%,且在多扰动场景下,机器人的恢复能力提升3倍,真正实现了从"能做"到"稳定做"的跨越。
一、回归动作本质:把推理空间从语言与视觉,拉回到动作本身
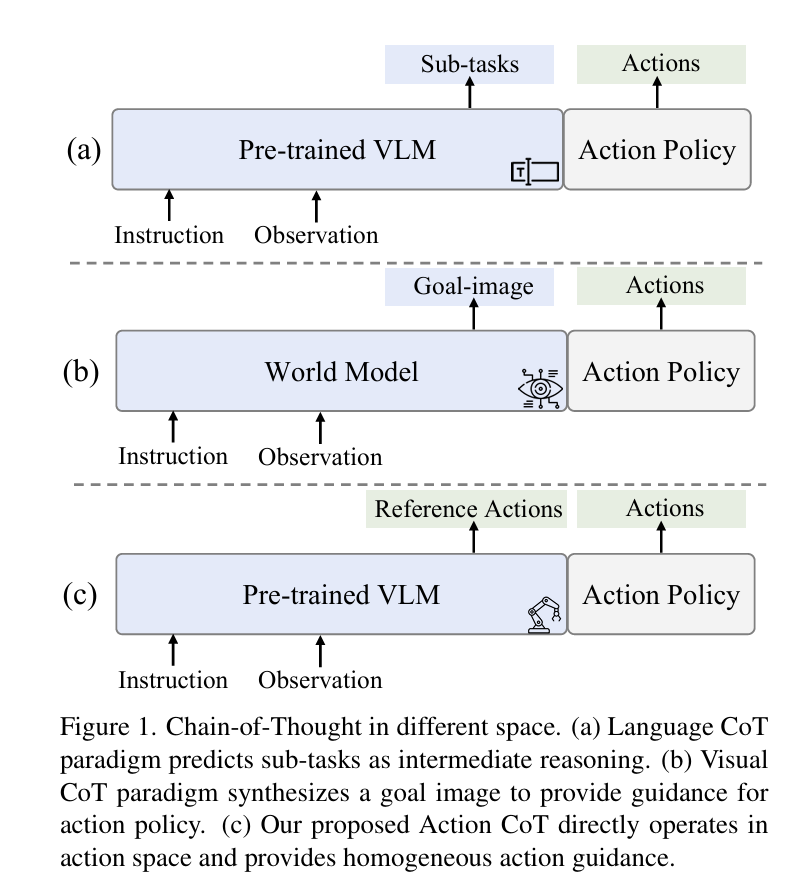
传统VLA模型的推理过程,始终局限在感知空间而非动作执行空间。一类方法在语言空间拆分子任务,将复杂行为转化为文本化步骤;另一类在视觉空间预测目标图像或未来状态,用视觉表征间接引导动作生成。两种路径都无法回避一道核心障碍 ------语义 - 运动学鸿沟:必须把抽象的语义或视觉表示,强行映射为连续、精准、时序一致的物理动作。
这套间接推理模式在实验室可控环境中尚能取得不错效果,但一旦进入光照变化、相机位移、物体布局扰动、纹理改变的真实场景,信息损耗、分布偏移与执行偏差几乎不可避免,机器人行为会变得脆弱、敏感、难以稳定复现。大量实验反复验证:中间推理表示越抽象,向动作空间传递的细粒度信息越弱;推理与实际执行的距离越远,长时域任务越容易累积误差而崩溃。 由此引发出新的思考判断:机器人最可靠的推理,不应发生在语言或视觉空间,而应直接发生在动作空间。
这正是 ACoT-VLA 的底层创新逻辑。模型不再先生成文本或图像类中间量,而是直接输出结构化、运动学合理、可直接指导执行的粗粒度动作意图序列,即动作思维链(Action Chain-of-Thought)。这条思维链并非对任务的自然语言描述,而是机器人内部的运动预演,是执行层可直接理解的意图轨迹。它从根源上消除了感知到动作的跨空间异构映射偏差,让规划输出本身就具备物理落地性。
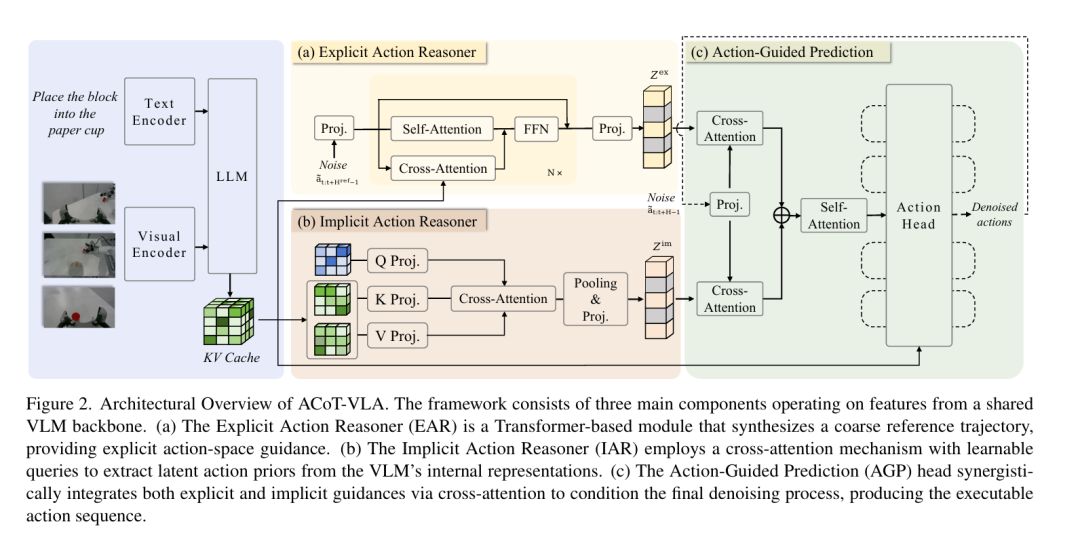
为让动作空间推理具备强鲁棒性与泛化性,ACoT-VLA 构建了显式 + 隐式双路径互补推理机制:
-
显式动作推理器(EAR):生成粗粒度参考动作轨迹,为机器人提供清晰的运动骨架,明确运动路径、姿态变化与时序结构;
-
隐式动作推理器(IAR):从VLM的内部表征中提取潜在线索,捕捉场景可供性、接触意图、空间约束、运动趋势等难以用显式轨迹完整描述的先验信息。
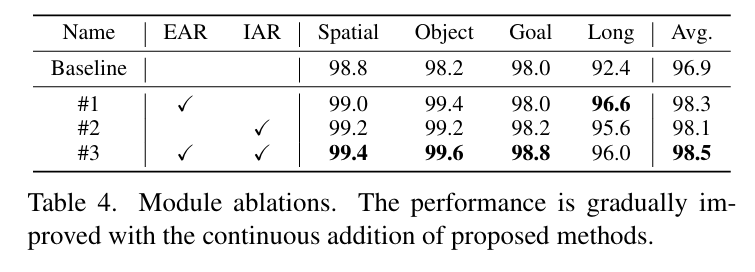
双路径融合后,机器人从 "边感知边反应" 的被动策略,升级为先形成可执行运动方案、再精准落地动作的主动具身智能体。
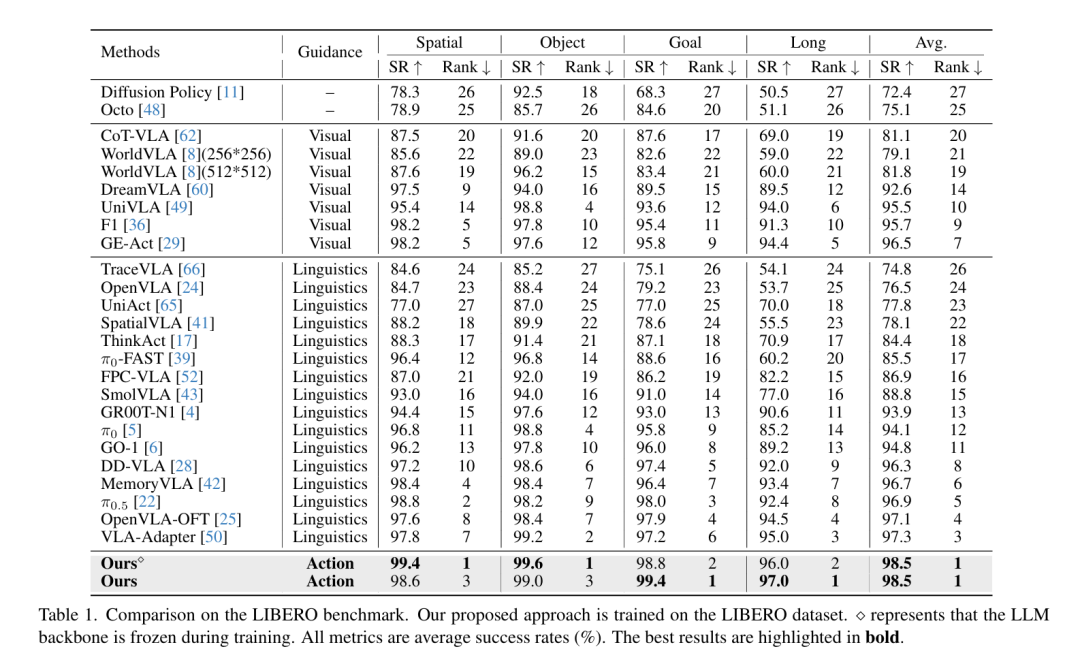
在真实桌面操作任务中,这一范式革新带来直观的体验提升:抓取不再空夹、移动不再飘移、放置不再偏移。在 LIBERO 仿真基准上,动作原生推理带来稳定且显著的性能提升,平均成功率达到 98.5%,尤其在需要严格误差控制的长时域操作任务上,提升幅度远优于传统语言 / 视觉思维链方法。核心原因在于:动作思维链天然为长序列动作提供结构化约束,让误差不再无限制扩散。
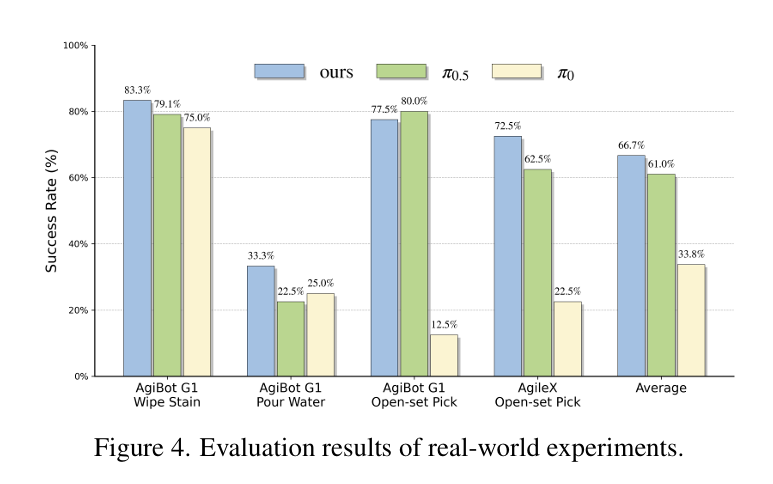
对真实机器人部署而言,这一突破的价值远不止指标提升。它让机器人首次具备接近人类的决策模式:先在运动层面形成完整意图,再分步稳健执行,而非依赖瞬时视觉刺激做被动反应。

这种动作中心化的推理模式,使机器人在复杂场景、强干扰场景、长序列任务中保持高度行为一致性,实现了传统 VLA 模型难以达到的部署稳定性与泛化能力,是通用机器人从 "感知理解" 走向 "物理落地" 的关键一步。
二、解开执行矛盾:用异步分层双系统,让规划稳定落地
动作推理的问题解决后,下一个工程瓶颈自然浮现:即使推理完全正确,机器人依然难以做到高频、精准、低延迟的稳定执行。
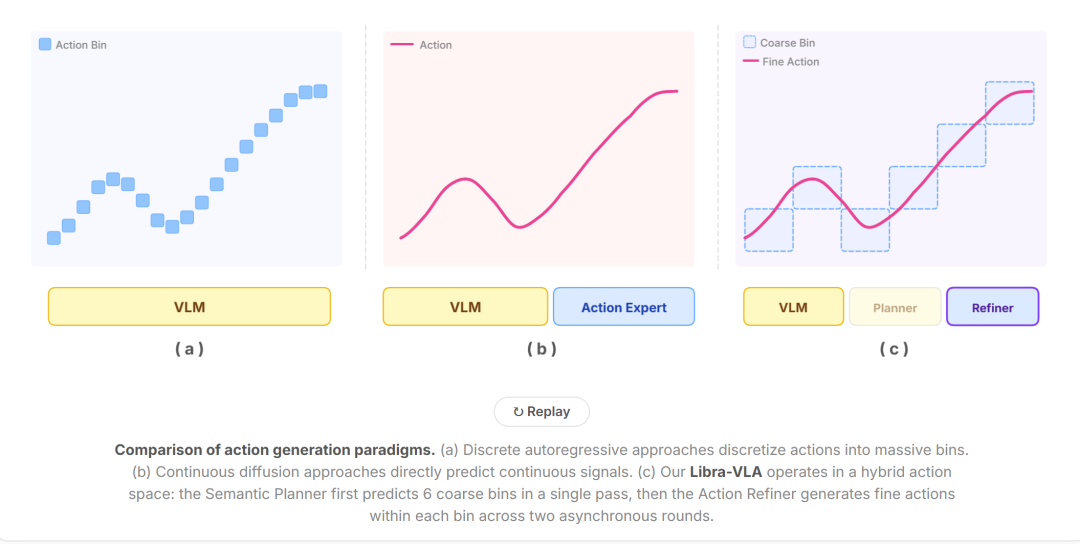
只要深入机器人的行为结构就会发现,复杂操作天然具备两层逻辑:宏观上,机器人需要知道"往哪里去、整体结构是什么、长时域目标是什么",这部分是低频、离散、全局的;微观上,机器人需要处理"毫米级对位、接触调整、姿态修正、力度控制",这部分是高频、连续、局部的。传统架构把两层目标压在同一个网络、同一个频率中学习,结果必然是顾此失彼。宏观规划被细节噪声带偏,精细控制被全局意图扰动,最终表现为动作响应性不足,稍微遇到扰动就失控。
GO-2 采用了一套彻底解耦却又高度协同的异步双系统架构,把规划与执行分到两套节奏、两套目标、两套模块中运行。低频慢系统(语义规划器)专注于宏观意图,基于预训练VLM主干,通过并行解码输出离散的粗粒度动作token,以交叉熵损失训练,以更低的频率更新,输出稳定、长时域、结构化的动作约束,形成持续引导执行的意图流,填充先进先出(FIFO)意图缓冲区;高频快系统(动作细化器)专注于实时观测与局部修正,采用DiT搭配独立视觉编码器,以MSE损失训练,以高频率响应环境变化,在慢系统给出的约束内完成精准对位、姿态调整、误差修正,逐段消费缓冲区中的意图并进行精修。
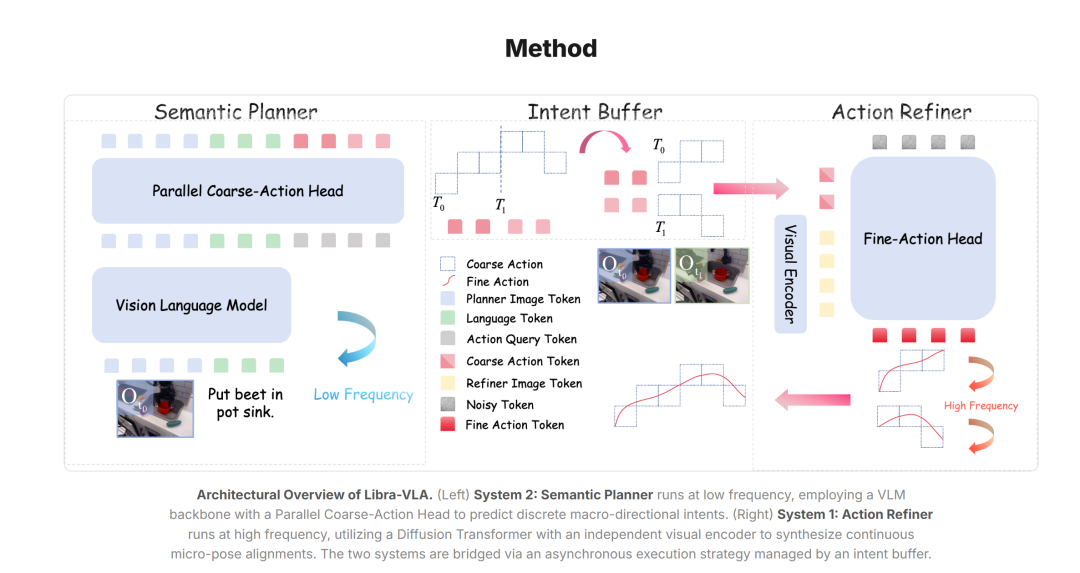
两套系统之间通过意图缓存实现异步流转。慢系统一次性输出一段未来的动作意图(时域扩展因子M决定输出长度),快系统逐段消费、逐段精修。这种结构带来两个关键收益:一是延迟显著降低,在RTX 4090平台上,相较于基准架构可实现44.5%以上的延迟降低,机器人的响应更流畅、更灵敏;二是鲁棒性大幅提升,在一定范围的观测噪声、物体位置偏移下,快系统可将动作拉回正确轨道,这得益于粗粒度动作约束的空间容错性。
更重要的是,这套架构遵循学习均衡的规律。我们在大量消融实验中观察到清晰的规律:动作分解的粒度(分箱数量N)与性能呈现倒U型关系。太粗(N≤2),精度不足,系统退化为纯扩散模型;太细(N≥50),规划复杂度爆炸,系统退化为自回归模型。只有在宏观与微观的学习难度达到均衡点(实验验证最优分箱数量N=10)时,成功率、泛化性、延迟同时达到最优。GO-2 正是在这个均衡点上工作,这也是它在零样本泛化、分布偏移、仿真到真实迁移中保持稳定的核心原因------粗粒度规划提供充足的宏观引导,细粒度精修保证精准执行,两者学习难度均衡,避免单一系统负担过重。
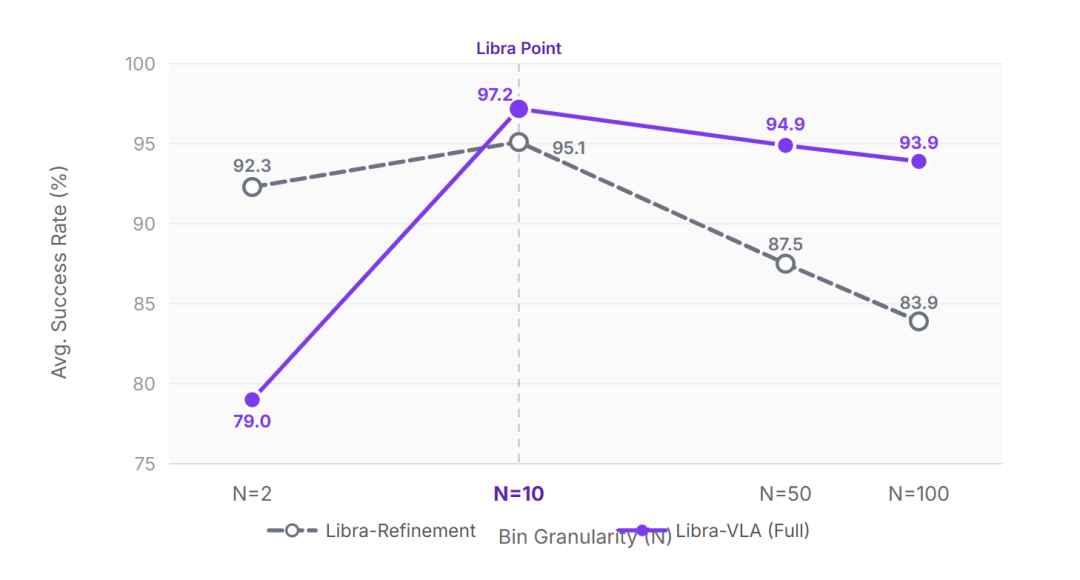
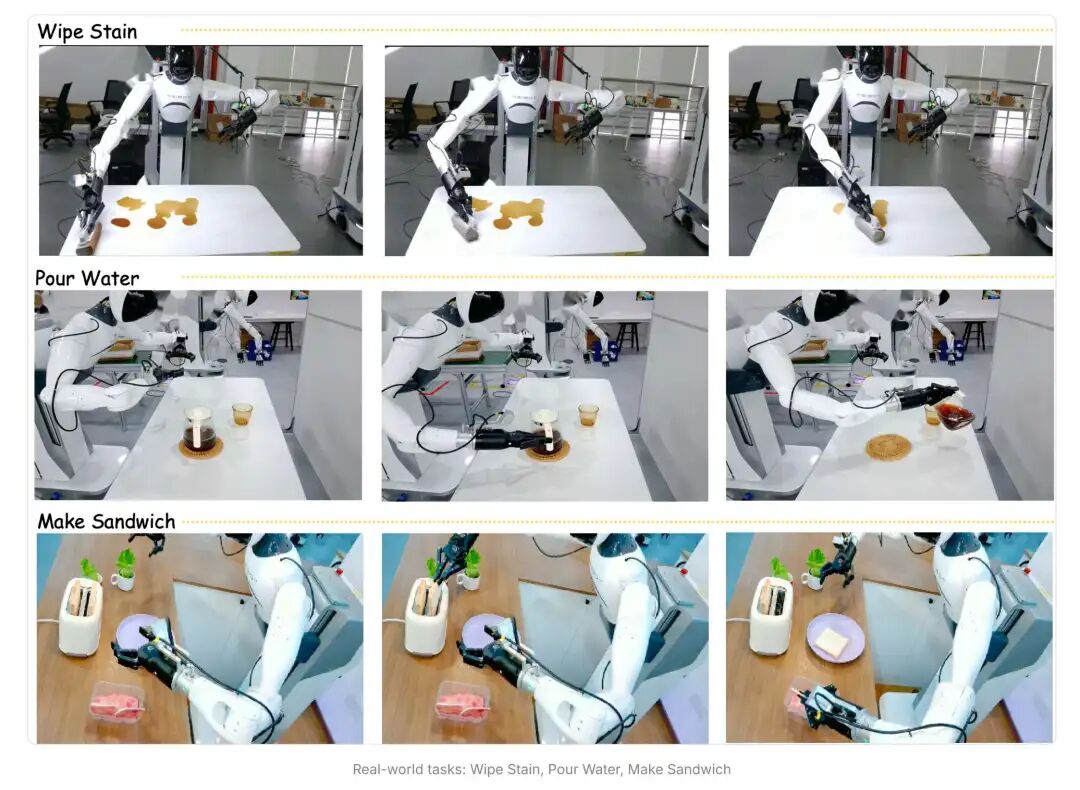
在真实场景测试中,异步双系统的价值尤为明显:桌面高度不一致、物体轻微滑动、光照突然变化等场景下,机器人可在线调整动作,减少误差累积,但仍存在一定局限性------当分箱粒度偏离均衡点、时域扩展因子M过大(M≥5)时,成功率会出现轻微下降(平均成功率从97.2%降至95.3%)。长时域任务中,误差得到有效控制,机器人可稳定完成多步骤、多阶段的复杂操作。对于需要连续接触、精细调整、姿态保持的任务,比如擦拭、倒水、插入、装配,这种结构带来的稳定性提升尤为关键,在AgiBot G1机器人平台的真实测试中,GO-2完成此类任务的平均成功率达到69.4%,显著优于同类模型。
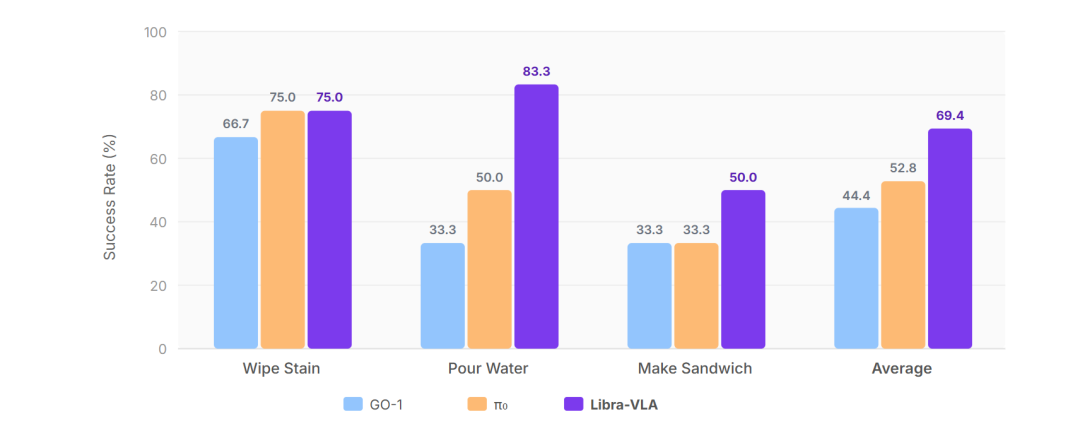
这也让 GO-2 在真实硬件上的表现显著区别于前代模型。机器人的运动更加平滑、姿态更加可控、末端更加稳定,在低成本执行器、视觉噪声较大的平台上,仍能保持较高的任务成功率。这让具身智能模型进一步具备了跨硬件、跨场景、跨扰动的可靠性,为工业级落地奠定了基础,但目前尚未完全实现成熟的工业级应用,仍需在极端场景适配、多硬件兼容等方面进一步优化。
三、打通落地闭环:让机器人脱离人工看护,实现自主进化
动作精准、执行稳定,仅是机器人技术的基础能力,距离真实世界规模化部署仍存在核心瓶颈:机器人必须具备自主闭环数据采集、自主执行长时序任务、自主故障恢复、自主策略迭代的全链路能力,才能脱离人工依赖。
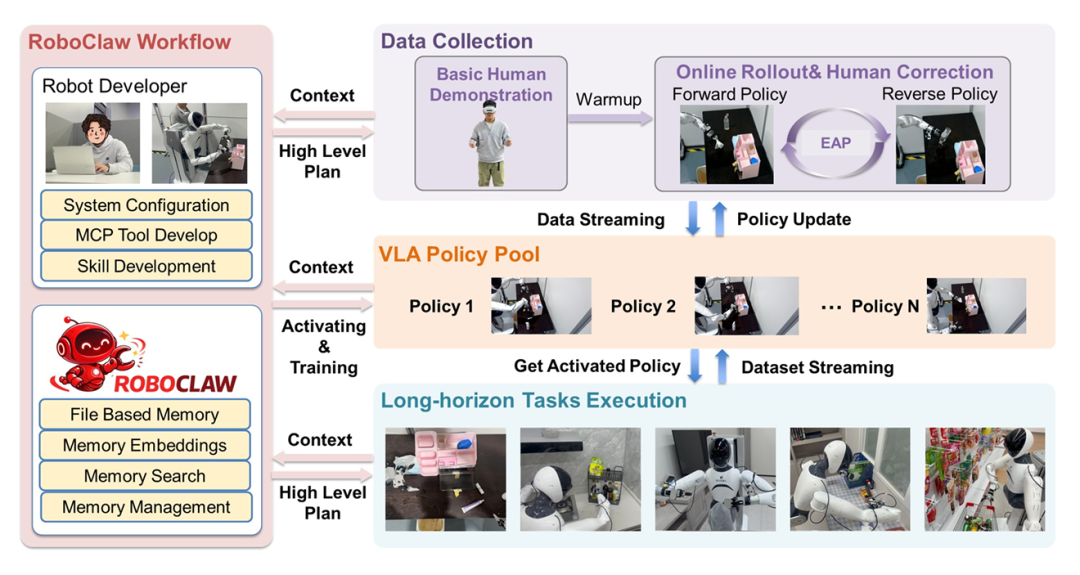
传统机器人系统的最大落地障碍,源于全流程高度人工介入 与架构割裂。数据采集依赖人工示教、环境重置依赖人工操作、任务执行依赖人工监控、故障处理依赖人工干预,任务复杂度越高,人力成本呈指数级上升,规模化部署完全无法实现。仅优化单步操作策略,无法解决长时序任务误差级联、训练与部署语义/分布不匹配、系统扩展性差的根因问题。
GO-2将系统架构提升至全生命周期智能体闭环 层级,以统一VLM元控制器、全生命周期一致上下文语义、同一套决策逻辑,深度融合数据采集、策略学习、任务执行、故障恢复与持续进化。
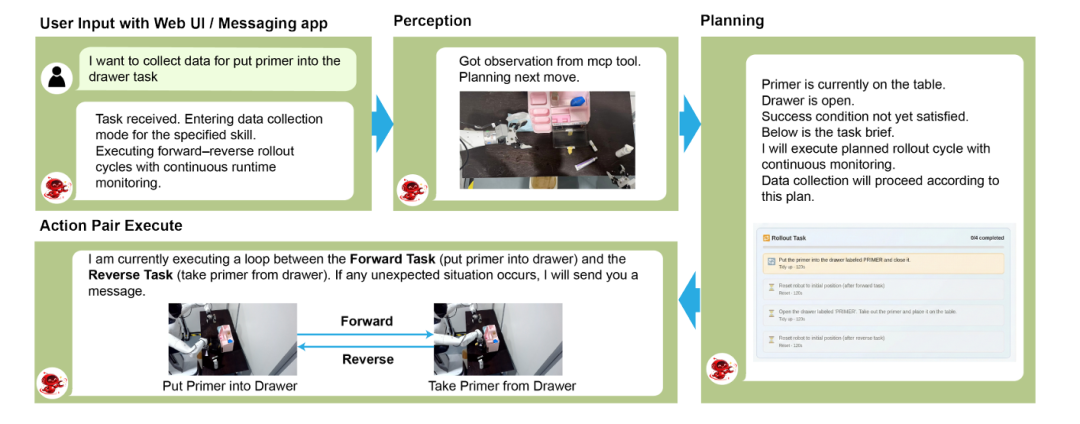
在数据采集阶段,机器人基于纠缠动作对(EAP) 机制,将前向操作策略与逆向恢复策略深度耦合,构建自重置循环。完成单次操作后,机器人可自主将环境恢复至可复用的初始状态,无需人工介入即可实现连续在线rollout与策略迭代。真实场景实验数据验证,该模式可降低53.7%的人工时间投入,人工干预频率降低8.04倍,让低成本、规模化数据采集成为现实。
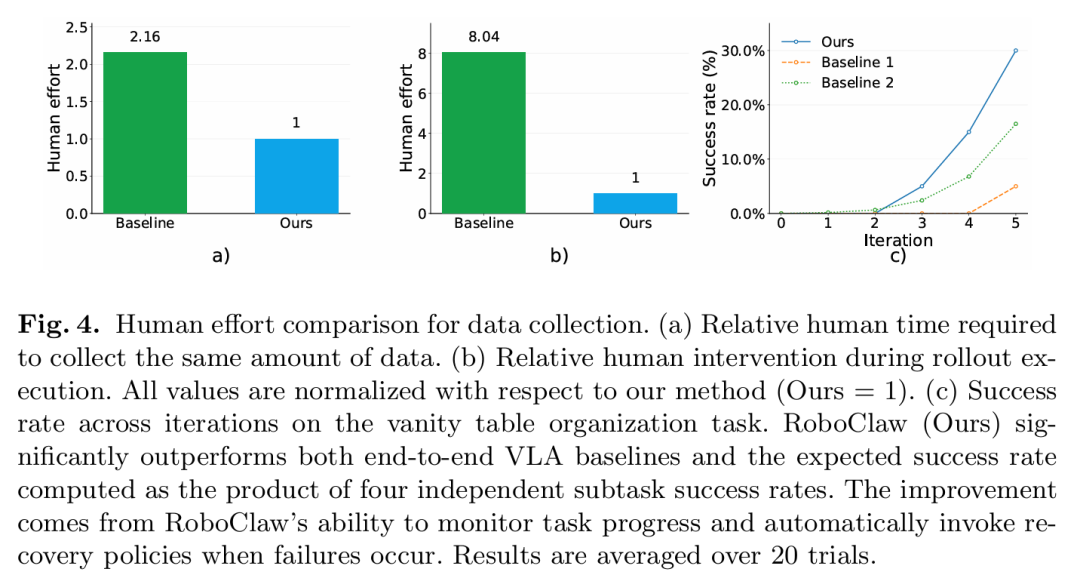
在部署阶段,机器人摒弃静态技能序列与固定脚本执行模式,依托结构化记忆与上下文推理,自主完成任务拆解、技能动态调度与子任务执行状态实时校验。针对抓取空抓、位姿偏移、物体倾倒等异常,机器人可自主区分非退化故障与退化故障,完成重试、环境恢复、重规划等操作,实现无人工持续看守的稳定运行。

更核心的是,真实执行轨迹可直接回流至训练pipeline,让策略在真实环境扰动、真实故障场景中持续迭代优化,真正实现每一次执行都是一次学习,每一次迭代都提升鲁棒性与泛化能力,长时序任务成功率相较基线方法**提升25%**。
这并非传统意义上的单步动作策略,而是一套具备自主感知、自主推理、自主执行、自主修复、自主迭代能力的具身智能体。它不再局限于解决单一动作精度问题,而是打通机器人从实验室走向产业现场的全链路,攻克长时序任务执行脆弱、人工依赖过重、无法规模化扩展的行业难题。
对于企业级部署与规模化落地而言,这套全生命周期闭环的价值具备决定性意义。机器人无需大量现场工程师持续调试、维护与干预,可实现长时间、少人看护条件下的稳定运行;数据不再依赖高成本人工采集,可在部署过程中自主生成、自主迭代;模型不再是交付后固定不变的软件包,而是能够持续进化、持续适配场景、持续提升性能的智能系统。
这让GO-2从单一高性能操作模型,真正升级为可规模化落地、自主闭环进化的产业级生产力系统。
四、三位一体的统一架构:GO-2 真正的范式价值
把三层技术逻辑放在一起,一条完整、自洽、层层递进的技术路线彻底清晰: 第一层,把推理放回动作空间,从根源消除语义-运动鸿沟; 第二层,用异步分层双系统,让宏观意图与微观控制各司其职,达到学习与执行的均衡; 第三层,用全生命周期智能体闭环,让机器人脱离人工看护,实现自主数据、自主执行、自主进化。
GO-2 不是三个独立模块的拼接,而是把三者熔铸成一个端到端、同语义、同闭环的统一基座模型。它的内部数据流简洁而强大:多模态输入进入模型后,先在动作空间完成推理,形成结构化意图;意图进入异步双系统,完成低频规划与高频精修;动作输出由智能体闭环调度、监控、校验、自愈;执行轨迹回流训练,持续优化整个系统。
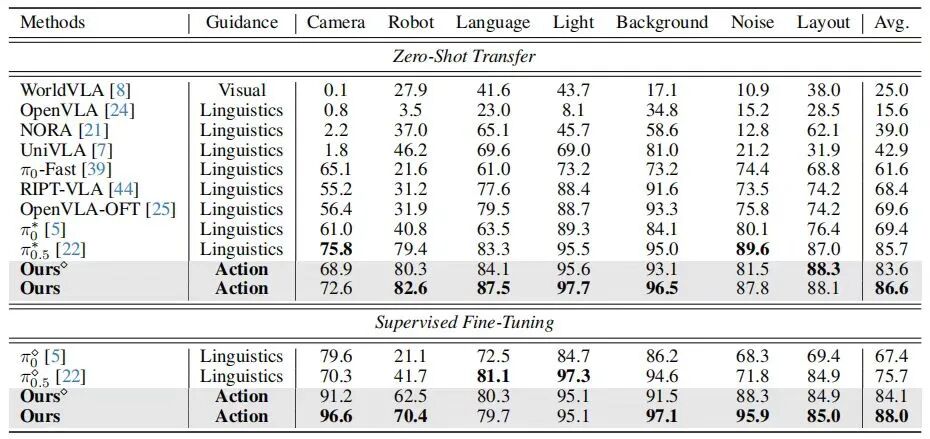
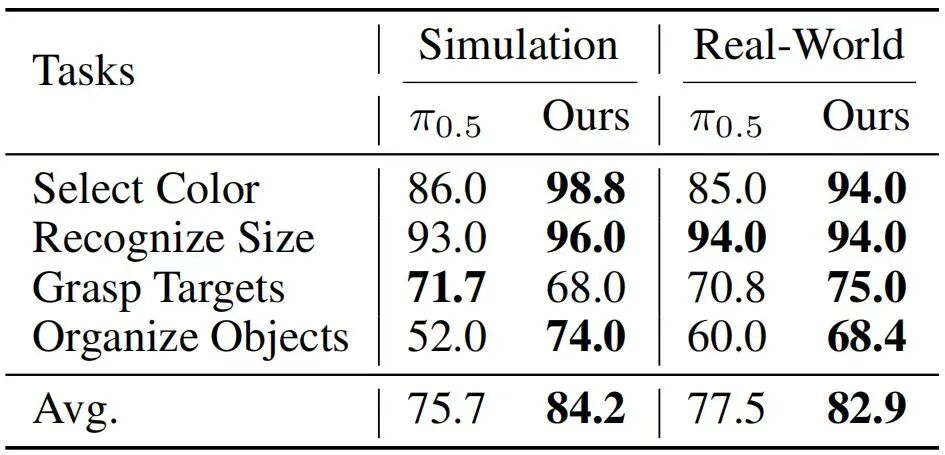
这种融合带来的不是简单的指标提升,而是机器人行为范式的改变。在 LIBERO 基准上,98.5% 的平均成功率,代表机器人在严格控制的长时域操作中达到了前所未有的稳定;在 LIBERO-Plus 零样本迁移中,86.6% 的成功率,体现出对相机、光照、背景、布局等分布偏移的强鲁棒性;在 VLABench 纹理泛化任务中,大幅领先的成绩来自动作空间特征的域不变性;在 Genie Sim 3.0 仿真到真实迁移中,82.9% 的成功率,证明动作约束在跨域时保持高度一致。

这些成绩不是靠更大的模型、更多的数据堆出来的,而是靠更贴近物理世界的架构设计带来的。
对于行业而言,GO-2 的出现标志着一个重要转向:具身智能正式从"追求理解能力"进入"追求执行可靠性"的新阶段。过去几年,行业的重心放在如何让机器人听懂、看懂、理解任务;从 GO-2 开始,行业的重心将转向如何让机器人稳定做到、可靠完成、长期运行。这是具身智能从实验室走向现实世界的关键一步。
五、从模型到生产力:GO-2 的产业级闭环体系
GO-2 的价值不止于技术创新,更在于它构建了一套可工业化、可规模化、可持续进化的产业体系。依托 Genie Studio 一站式具身开发平台,GO-2 形成了从预训练、在线后训练、多机协同数据采集到持续迭代的完整链路。它不再是一个静态模型文件,而是一套可以在真实世界中持续学习、持续变强的生产力系统。
云端与多机器人协同采集真实交互数据,在线后训练持续优化策略,每一次部署、每一次执行、每一次恢复,都在为模型提供新的经验。机器人不再是交付后就停止进化的设备,而是可以伴随场景持续成长的智能体。对于家庭、商用、工业等各类真实场景而言,这意味着更低的部署成本、更高的稳定性、更强的场景适应能力。

在实际落地案例中,这套体系已经展现出清晰的价值。在桌面整理、仓储分拣、商用服务、家庭辅助等场景中,GO-2 能够在较少人工干预的条件下快速适配新场景、新物体、新任务。模型不需要从零开始训练,只需要少量真实交互数据,就能快速迭代、快速收敛、快速落地。这大大降低了具身智能的使用门槛,让VLA基座模型真正走进产业现实。
从技术研发到产业落地,GO-2 搭建了一座完整的桥梁。它不再是实验室里只能演示的模型,而是能够在真实环境中创造价值、提升效率、降低成本的生产力工具。这也是智元在具身智能领域一贯坚持的方向:让技术真正落地,让机器人真正可用。
六、迈向具身智能的下一个时代:记忆、行动与闭环智能
在 GO-2 稳定动作能力的基础上,智元正在推进更完整的具身智能架构。当机器人可以稳定可靠地执行动作后,下一个核心能力自然浮现:记忆与经验复用。OpenClaw 记忆系统让机器人可以记录历史交互、积累操作技能、复用已有知识,在新任务中快速迁移、快速适应。
当动作空间推理、异步分层执行、长期记忆、智能体闭环结合在一起,机器人就进入了真正的具身智能体时代:感知、推理、行动、记忆、自愈、进化,形成完整闭环。这也是 GO-2 为行业打开的新方向:具身智能不再是感知与动作的简单拼接,而是推理、执行、记忆、进化的统一体系。
未来的具身智能,将不再只是执行指令的机器,而是能够理解任务、自主规划、稳定执行、记住经验、持续进化的真正智能体。它能够在复杂环境中长期运行、自主维护、自主优化、自主成长。它能够从每一次任务、每一次交互、每一次恢复中学习,变得越来越可靠、越来越聪明、越来越贴合人类需求。
这正是 GO-2 所开启的未来。
结语
从 GO-1 到 GO-2,是具身智能从"理解世界"到"稳定作用于世界"的范式跃迁。 GO-2 没有停留在增强感知、扩大模型、增加数据的传统路径,而是回到机器人最本质的需求:如何稳定地在物理世界中完成任务。它以动作空间推理重构机器人的思考方式,以异步分层双系统保证执行的稳定与流畅,以全生命周期智能体闭环打通真实落地的最后一公里。
它回答了具身智能长期以来的三个核心问题: 机器人该在哪里思考?------在动作空间。 机器人该如何稳定执行?------异步分层,学习均衡。 机器人如何走向真实世界?------自主闭环,持续进化。
GO-2 不仅是一个新一代具身基座模型,更是具身智能走向"知行合一"的里程碑。它让机器人不再只是能理解、能规划、能演示的实验室系统,而是能稳定、可靠、自主地在真实世界中完成任务的生产力智能体。这,正是具身智能走向现实的真正方向。