通过 SDD (Spec-Driven Development 规范驱动开发)来规范 AI 编程,让 AI 更可控,已经变得可行。
今天详细介绍的,是由 GitHub 亲自开发的 spec-kit。
GitHub 亲自下场开发工具的情况确实相当少见。使用下来,整体感觉非常良好,无论是设计理念还是实际体验,都体现了 GitHub 对开发者需求的深刻理解。目前也获得了社区 62.3K 的收藏数,在之前介绍的三个开源工具中,是最多的。
安装
开源源码地址:github.com/github/spec...
收藏 Star 数:62.3K
安装命令,在已安装 Python 及 uv 工具的机器下执行:
bash
uv tool install specify-cli --from git+https://github.com/github/spec-kit.git初始化
安装之后,使用命令行,进行初始化:
bash
specify init --here
执行完成后,会在 .specify 下生成记忆、脚本、 模板三个文件夹。相比之前介绍的 openSpec 多了不少内容。而由于它部分功能是通过脚本实现的,一定程度上减少了 AI 自由发挥,产出更稳定。
有部分工具需要重启,才能调用命令。
使用
开发流程一共有 8 步,其中 3 个步骤可选

对应的命令如下:
- /speckit.constitution 确立项目原则
- /speckit.specify 制定基准规范
- /speckit.clarify 可选步骤,需求澄清,在规划前通过结构化提问消除模糊领域的风险;
- /speckit.plan 创建实施计划
- /speckit.checklist 可选步骤,文档校验,制定质量检查清单,以验证需求的完整性、清晰度和一致性;
- /speckit.tasks 生成可执行任务
- /speckit.analyze 可选步骤,生成对齐报告,跨交付件一致性与校准报告;
- /speckit.implement 落实实施方案
Constitution 确立项目原则
如果没有特殊要求,使用官方的内容即可,但是要注意转换成中文。如果复制官方的对话,会导致后续步骤都是英文回答,文档也是英文的。
在对话框输入如下内容:
bash
/speckit.constitution 制定以代码质量、测试标准、用户体验一致性和性能要求为核心的原则完成之后,会更新 .specify/memory 文件夹里的 constitution.md 文档。
一般不需要更改,除非你想放松一些上线条件,比如单元测试覆盖率不需要 100%;或者你想拿 spec-kit 来写文章等的非编程工作。
Specify 制定基准规范
后续就可以开始执行了需求开发了。在对话框输入:
bash
/speckit.specify 做一个xx网站/app,实现xxx功能。请使用中文回答。同上,spec-kit 对中文支持一般,有概率使用英文回答,还是要加一下"请使用中文回答"。
如果项目关联了 Github,还会自动生成并切换到新分支。
命令执行后,会生成 checklist 和 spec 文档。
- checklist 文档,初步的校验清单,后续如果不使用 /speckit.checklist 可以忽略。
- spec 文档,最重要的文档,大概分成以下的内容:
- 用户场景与测试:用户故事与测试验收场景。
- 需求清单:功能需求与关键信息
- 成功标准:验收标准
做过敏捷开发的同学,对 spec 文档的内容,应该不陌生。
如果没做过敏捷开发,也不用担心,理解用户场景与测试中的用户故事其实并不复杂:它们本质上都是站在用户视角,把流程从头到尾执行一遍。比如,对于一个"用户登录"场景,你需要模拟真实用户打开应用、输入账号密码、点击登录按钮,并验证是否成功进入主页。
通过视角转换,你可以更有效地检查流程中是否有逻辑漏洞、界面误导或功能遗漏。
如果你担心自己有些地方没考虑到,或者没有明确的需求,都可以可以让 AI 帮你。在对话框输入:
bash
/speckit.clarifyAI 再帮你把把脉,这是它会提出一些关键问题,让你选择。

Plan 创建实施计划
确认需求规范文档之后,就可以执行详细设计和列开发计划了。在对话框中输入:
bash
/speckit.plan验证需求文档之后,开始生成下列文档:
- plan 文档:项目架构,关键技术选项
- research 文档,技术选型的原因、决策过程
- data-model 文档: 字段名、索引已经定义好。还有一些关系图、状态机的内容
- openapi.YAML,接口定义。
这期间会调用搜索工具,获取最新的技术信息,并调研最佳实践,以保证更符合当下的技术要求。所以整体项目的质量也比单纯用 IDE/CLI 工具简单的 plan 模式产出的要佳。
同时也考虑了数据模型,后端数据库、前端状态管理都有详细设计。而接口定义也从之前的 md 文档改成了 yaml 文档。这些都保证了开发的项目能切切实实跑起来。
如果想 AI 后续帮你检查,可以再在对话框中输入:
bash
/speckit.checklist此时会询问你想做那些检验:

完成后,会在 checklist 文件夹生成一些检查清单。后续执行任务时,会进行校验。
Tasks 生成可执行任务
在对话框中输入:
bash
/speckit.tasks生成可执行的任务文档 task.md。
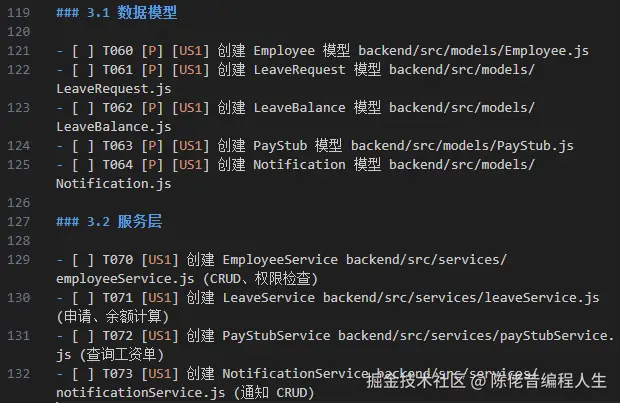
文档中,会关联上具体的用户故事,如 [US1] 是第一个用户故事关联的内容。另外,[P] 是可并行的任务。如果工具可以并行执行,如 Claude Code,速度会大大加快。
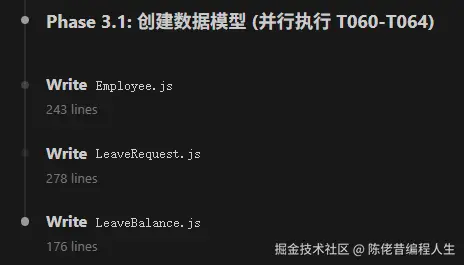
对比其他工具只是粗略的描述,speckit 还精确到要修改的具体的文件。最后的任务,也会有明确的测试任务。
这些都是其划分任务时的强大之处,一定程度上也是后期质量的保证。
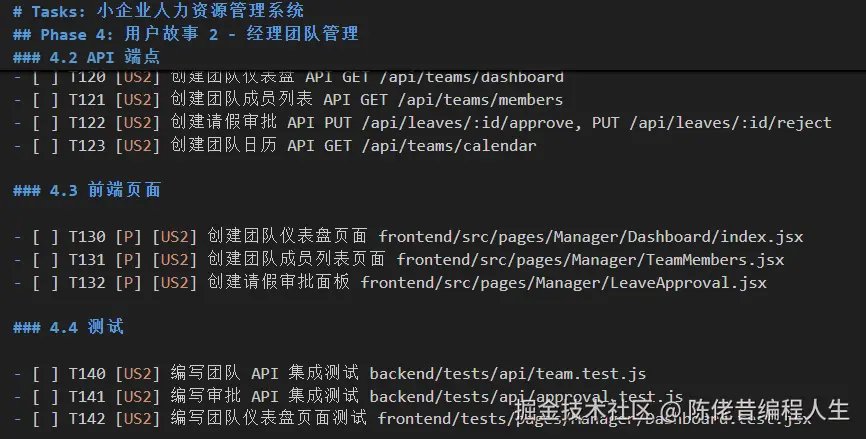
对所有的任务,还有依赖图:

如果执行后面的任务依赖前面的,他会强制执行前面的任务。如上面的 Phase 3 任务,依赖于 Phase 1 和 Phase 2 的任务,执行时,会检查是否前面已完成,未完成则跳回 Phase 1 和 Phase 2 :
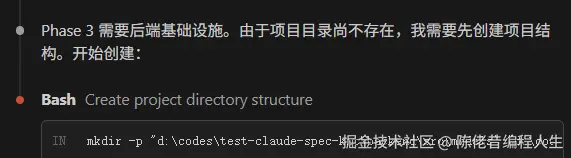
当然,还是推荐按依赖关系顺序执行。如果使用 Claude Code,可以尝试将无依赖的任务用多个窗口执行,也能加快进度。如上面的 Phase 3 和 Phase 4。
在此阶段完成后,再回去改需求、技术细节,虽然也能自动更新到task中。不过,还是推荐在上一步就完成所有的技术细节确认。
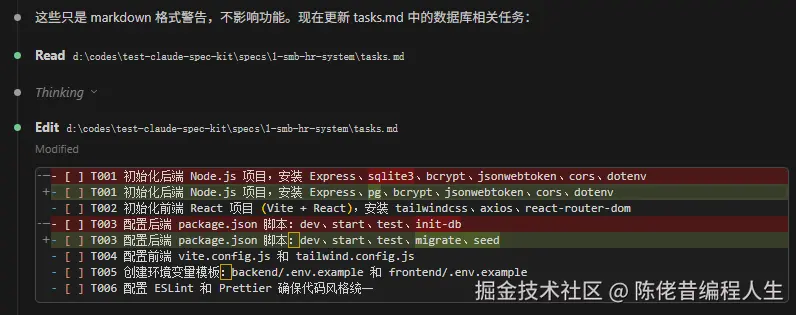
Implement 落实实施方案
确认任务列表之后,开始实施任务执行,在对话框输入:
bash
# 全部任务
/specify.implement
# 或者具体的任务
/specify.implement 开始实施 Phase 1
# 或者具体的多个任务
/specify.implement 开始实施 T001-T005可以选择性执行其中一个或多个或全部任务。
目前由于各种原因,还无法全自动执行。时不时需要开发者看一看有什么状况。或者命令需要授权,或者 memory 使用超过 100%,或者任务被中断了,都需要手动确认或输入继续。
如果不是 Claude、Gemini、OpenAI 官方的模型,还是建议每次执行完一个场景 Phase,都在开发环境中验证一下,再执行下一步,能减少后续调试的麻烦。
另外,测试任务比较消耗时间和 Token,建议把测试任务单独执行。
有可能会有泄露的任务,最后可以检查一下。
成果与体验
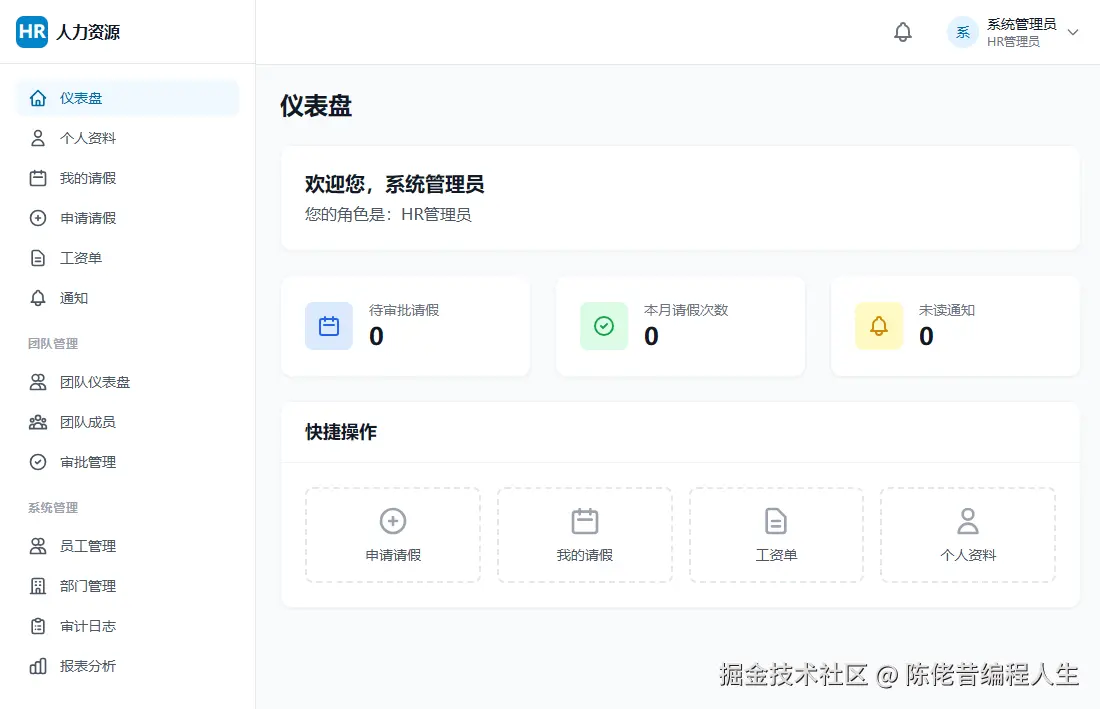
这是我用 3 个迭代做出来的 HR 管理系统。
目前发布在 Github 上,需要源码的可以去看看:
给团队打个广告,有需要开发中小企业系统的,可以联系我
由于精细到页面级,出错的概率并不高,或者都是一些比较简单的错误。这次遇到的是路径问题,轻松修复了。
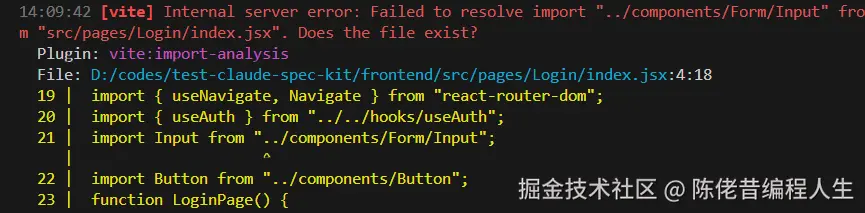
最后成品的页面:
整体体验下来,speckit 的开发流程更完善,能完成复杂项目的可能性更高,完成度也很优秀。AI 输出代码的质量更加可控。
虽然没有完全做到自动化,但是需要开发查看、修改代码的机会并不多。执行任务时,离开电脑 3-5分钟也完全没问题。
由于文档更完善,在完全交给AI开发后,信心更足了,没有了 Trae / Claude Code Yolo 模式等待时候的担心。
当然,需要前期文档工作消耗的时间也要多一些,复杂任务大概是 30 分钟左右。
总的来说,如果你想通过确认文档来规范并完成开发,使用 speckit 完完全全没有问题。
五星满分推荐!
相关文章: