如何计算神经网络的参数
在上一篇文章中,我们了解到神经网络本质上是一个由大量参数(权重 w和偏置 b)构成的复杂非线性函数。那么,这些参数究竟是如何确定下来的呢?
始终记住,我们的目标是找到一组参数,使得网络的预测结果尽可能接近真实数据。如下图所示,显然左边的拟合效果更好。
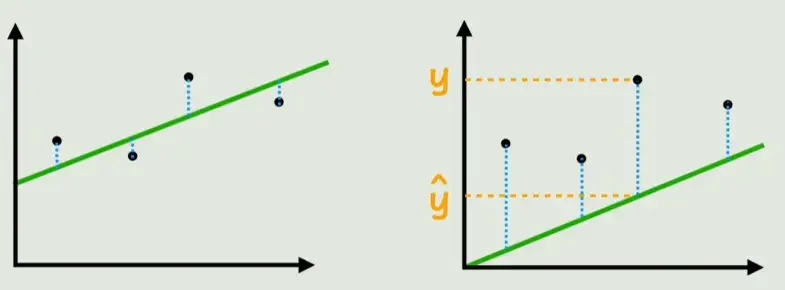
为了量化"拟合得好不好",我们需要一个衡量标准。对于单个样本,可以用预测值与真实值之差的绝对值来表示误差。将所有样本的误差累加起来,就得到了整体误差的度量。这个函数就叫做损失函数 ------用于表示预测数据与真实数据误差的函数。为了避免绝对值带来的不可导问题,通常采用平方来代替绝对值,然后对所有样本取平均,这样就得到了均方误差 ------一种常用的损失函数。
我们将损失函数记为 L。从参数的角度看,L 是关于所有 w 和 b 的函数:

损失函数表示的是预测值与真实值的误差,其值越小,说明模型的预测越准确。因此,我们的任务转化为:找到使损失函数 L 最小的那一组 w和 b。
如果参数很少,理论上可以通过令偏导数为零直接求解。例如,在线性回归中,我们正是用这种方法求解析解的。然而,神经网络的损失函数通常极其复杂,涉及成千上万个参数和非线性激活函数,根本无法直接求解。这时,我们需要一种更通用的方法------梯度下降。
梯度下降
梯度下降的核心思想很简单:既然无法一步到位,那就一步步朝误差减小的方向调整参数。
假设我们只关注某一个参数 w,当前取值下损失函数值为 L。如果我们让 w 增大一点点,发现 L 也随之增大,那就说明应该反过来减小 w;反之,如果增大 w 使 L 减小,那我们就继续朝这个方向调整。而损失函数L随着参数w变化而变化的程度,其实就是损失函数对w的偏导数。而我们要做的,就是让w和b不断地向偏导数地反方向去变化。具体变化的快慢,我们再增加一个系数(学习率 )来控制。这些偏导数所构成的向量就叫做梯度 。不断变化w和b使得损失函数不断减小,进而求出最后的w和b,这个过程就叫做梯度下降。这个过程用数学语言描述,就是利用损失函数对 w 的偏导数(即梯度)来指导参数的更新方向------朝着梯度的反方向移动。
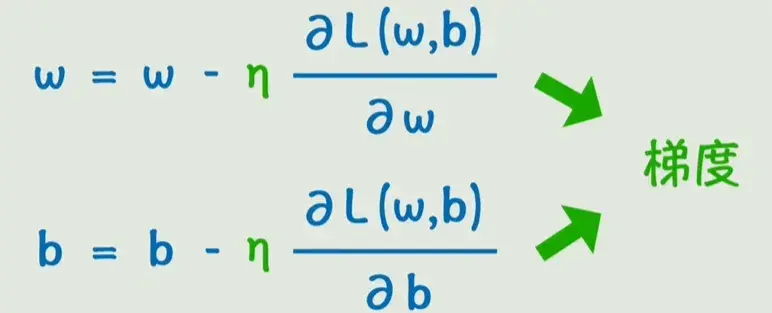
其中 η 是学习率 ,控制每一步调整的步长。将所有参数的偏导数组合成一个向量,就是梯度。沿着梯度的反方向更新所有参数,就能使损失函数逐渐下降。这个过程反复进行,直到损失函数收敛到足够小,我们就得到了训练好的模型。
反向传播
现在问题变成了如何求偏导数。梯度下降的关键在于计算每个参数的偏导数。在深度神经网络中,参数数量巨大,直接逐个计算几乎不可能。幸运的是,借助链式法则 ,我们可以高效地求出所有梯度,这就是反向传播算法。
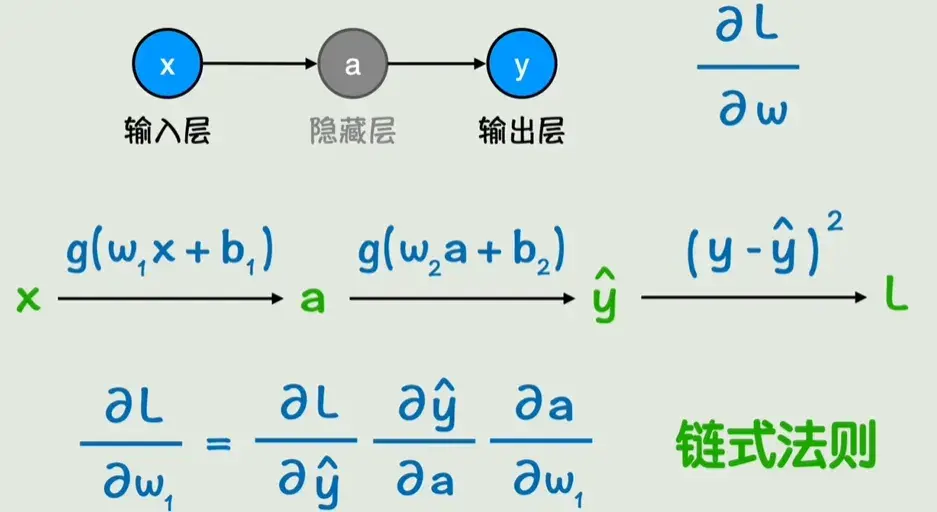
如图,要求L对w1的偏导,只需要用链式法则分别求图中的三个偏导,再相乘就好了。从输出层开始,我们可以由右向左逐层计算这些偏导数。有趣的是,计算前一层的梯度时,会用到后一层的某些中间结果,这些结果可以"反向传播"给前层复用,所以可以让这些值从右向左传播,这个过程就叫做反向传播。
总结
综上所述,神经网络的训练包含两个核心阶段:
- 前向传播:通过前向传播根据输入x计算输出y。
- 反向传播:根据预测值与真实值的误差(损失函数),利用链式法则计算每个参数的梯度,然后按照梯度下降法更新所有参数。
每一轮这样的操作称为一次训练迭代。经过足够多轮的迭代,损失函数不断下降,最终,经过多轮训练使得损失函数足够小,就得到了我们想要的函数。