Python中的并发编程-1
现如今,我们使用的计算机早已是多CPU或多核架构,而主流操作系统基本都支持"多任务"------这让我们可以同时运行多个程序,也能将一个程序拆解为若干相对独立的子任务,让多个子任务"并行"或"并发"执行,从而缩短程序总执行时间,同时提升用户体验。因此,无论使用何种编程语言开发,实现"并行"或"并发"编程,已成为程序员的必备技能。要讲解如何在Python程序中实现"并行"或"并发",我们首先需要明确两个核心概念:进程和线程。
线程和进程
通过操作系统运行一个程序,会创建一个或多个进程。进程是具有一定独立功能的程序,在某个数据集合上的一次运行活动。简单来说,进程是操作系统分配存储空间的基本单位,每个进程都拥有自己的地址空间、数据栈,以及其他用于跟踪进程执行状态的辅助数据;操作系统负责管理所有进程的执行,为它们合理分配系统资源。一个进程可以通过fork或spawn的方式创建新进程来执行其他任务,但新进程会拥有独立的内存空间,因此两个进程若要共享数据,必须通过进程间通信机制实现,常见方式包括管道、信号、套接字等。
一个进程还可以拥有多个执行线索------即多个可获得CPU调度的执行单元,这就是线程。由于线程隶属于同一个进程,它们可以共享进程的上下文环境,因此相较于进程,线程间的信息共享和通信更加便捷。当然,在单核CPU系统中,多个线程无法真正同时执行:某个时刻只有一个线程能获得CPU资源,多个线程通过快速轮换占用CPU执行时间的方式,实现并发效果。
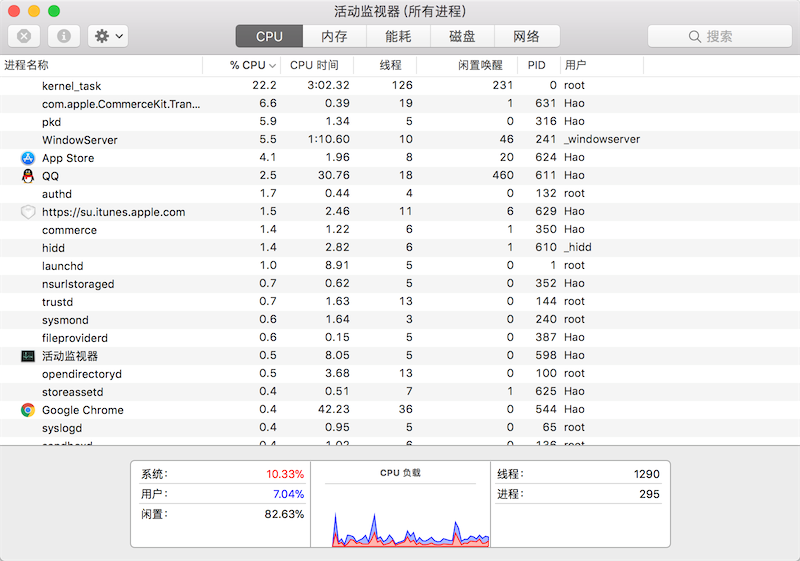
在程序中使用多线程技术,带来的好处不言而喻,最核心的就是提升程序性能、改善用户体验。如今我们使用的绝大多数软件,都用到了多线程技术,这一点可以通过系统自带的进程监控工具验证(如macOS中的"活动监视器"、Windows中的"任务管理器"),如下图所示。
这里,我们需要再次强调两个易混淆的概念:并发 (concurrency)和并行(parallel)。
并发:同一时刻只能有一条指令执行,但多个线程对应的指令会被快速轮换执行。例如,一个处理器先执行线程A的指令一段时间,再切换到线程B执行一段时间,随后再切回线程A。由于处理器执行和切换指令的速度极快,宏观上看起来多个线程在同时运行,但微观上同一时刻只有一个线程在执行。
并行:同一时刻,有多条指令在多个处理器上同时执行。并行必须依赖多处理器,无论从宏观还是微观角度,多个线程都能在同一时刻共同执行。
很多时候,我们无需严格区分"并发"和"并行",因此常将Python中的多线程、多进程及异步I/O,均视为实现并发编程的手段。但实际上,多线程和多进程也能实现并行编程,这就涉及到全局解释器锁(GIL)的问题,我们后续再详细讨论。
多线程编程
Python标准库中threading模块的Thread类,能帮助我们轻松实现多线程编程。下面我们通过一个"联网下载文件"的示例,对比使用多线程与不使用多线程的差异,代码如下。
不使用多线程的下载
import randomimport timedefdownload(*, filename): start = time.time() print(f'开始下载 {filename}.') time.sleep(random.randint(3, 6)) print(f'{filename} 下载完成.') end = time.time() print(f'下载耗时: {end - start:.3f}秒.')defmain(): start = time.time() download(filename='Python从入门到住院.pdf') download(filename='MySQL从删库到跑路.avi') download(filename='Linux从精通到放弃.mp4') end = time.time() print(f'总耗时: {end - start:.3f}秒.')if __name__ == '__main__': main()说明 :上述代码并未真正实现联网下载功能,而是通过
time.sleep()模拟下载所需的时间开销,与实际下载场景的耗时特征一致。
运行上述代码,得到的结果如下。可以看出,单线程程序中,每个下载任务必须等待上一个任务执行完毕才能启动,因此程序总耗时等于三个下载任务各自耗时的总和。
开始下载Python从入门到住院.pdf.Python从入门到住院.pdf下载完成.下载耗时: 3.005秒.开始下载MySQL从删库到跑路.avi.MySQL从删库到跑路.avi下载完成.下载耗时: 5.006秒.开始下载Linux从精通到放弃.mp4.Linux从精通到放弃.mp3下载完成.下载耗时: 6.007秒.总耗时: 14.018秒.事实上,这三个下载任务之间没有逻辑因果关系,完全可以"并发"执行------下一个任务无需等待上一个任务结束。为此,我们可以用多线程编程改写代码,如下所示。
import randomimport timefrom threading import Threaddefdownload(*, filename): start = time.time() print(f'开始下载 {filename}.') time.sleep(random.randint(3, 6)) print(f'{filename} 下载完成.') end = time.time() print(f'下载耗时: {end - start:.3f}秒.')defmain(): threads = [ Thread(target=download, kwargs={'filename': 'Python从入门到住院.pdf'}), Thread(target=download, kwargs={'filename': 'MySQL从删库到跑路.avi'}), Thread(target=download, kwargs={'filename': 'Linux从精通到放弃.mp4'}) ] start = time.time() # 启动三个线程 for thread in threads: thread.start() # 等待所有线程执行结束 for thread in threads: thread.join() end = time.time() print(f'总耗时: {end - start:.3f}秒.')if __name__ == '__main__': main()某次运行结果如下:
开始下载 Python从入门到住院.pdf.开始下载 MySQL从删库到跑路.avi.开始下载 Linux从精通到放弃.mp4.MySQL从删库到跑路.avi 下载完成.下载耗时: 3.005秒.Python从入门到住院.pdf 下载完成.下载耗时: 5.006秒.Linux从精通到放弃.mp4 下载完成.下载耗时: 6.003秒.总耗时: 6.004秒.从结果可以看出,程序总耗时几乎等于耗时最长的单个下载任务的时间,这说明三个任务是并发执行的,不存在相互等待的情况,程序执行效率显著提升。简单来说,若程序中有多个耗时执行单元,且它们之间无逻辑依赖(即B单元的执行不依赖A单元的结果),则可将这些单元放到不同线程中并发执行。这样做不仅能减少程序等待时间,还能避免因单个单元阻塞导致的程序"假死",提升用户体验。
使用 Thread 类创建线程对象
从上述代码可以看出,直接使用Thread类的构造器即可创建线程对象,线程对象的start()方法用于启动线程。线程启动后,会执行target参数指定的函数(前提是获得CPU调度);若target指定的目标函数需要参数,可通过args参数传入位置参数,通过kwargs参数传入关键字参数。Thread类的构造器还有其他参数,后续遇到时再详细讲解,目前需重点掌握target、args和kwargs三个参数。
继承 Thread 类自定义线程
除了上述方式,还可通过继承Thread类、重写run()方法的方式自定义线程,具体代码如下:
import randomimport timefrom threading import ThreadclassDownloadThread(Thread): def__init__(self, filename): self.filename = filename super().__init__() defrun(self): start = time.time() print(f'开始下载 {self.filename}.') time.sleep(random.randint(3, 6)) print(f'{self.filename} 下载完成.') end = time.time() print(f'下载耗时: {end - start:.3f}秒.')defmain(): threads = [ DownloadThread('Python从入门到住院.pdf'), DownloadThread('MySQL从删库到跑路.avi'), DownloadThread('Linux从精通到放弃.mp4') ] start = time.time() # 启动三个线程 for thread in threads: thread.start() # 等待所有线程执行结束 for thread in threads: thread.join() end = time.time() print(f'总耗时: {end - start:.3f}秒.')if __name__ == '__main__': main()使用线程池
通过线程池管理线程,是多线程编程的最优选择之一。事实上,线程的创建和释放会产生较大的系统开销,频繁创建和释放线程通常不是理想方案。利用线程池,可提前初始化若干个线程,使用时直接复用线程池中的线程,无需手动创建和释放,大幅降低系统开销。Python内置的concurrent.futures模块,提供了对线程池的原生支持,代码如下:
import randomimport timefrom concurrent.futures import ThreadPoolExecutorfrom threading import Threaddefdownload(*, filename): start = time.time() print(f'开始下载 {filename}.') time.sleep(random.randint(3, 6)) print(f'{filename} 下载完成.') end = time.time() print(f'下载耗时: {end - start:.3f}秒.')defmain(): with ThreadPoolExecutor(max_workers=4) as pool: filenames = ['Python从入门到住院.pdf', 'MySQL从删库到跑路.avi', 'Linux从精通到放弃.mp4'] start = time.time() for filename in filenames: pool.submit(download, filename=filename) end = time.time() print(f'总耗时: {end - start:.3f}秒.')if __name__ == '__main__': main()守护线程
所谓"守护线程",是指在主线程结束时,不值得保留的执行线程。其核心特征是:守护线程会在所有非守护线程全部执行完毕后被销毁,它"守护"的是当前进程内所有非守护线程。简单来说,守护线程会跟随主线程一起终止,而主线程的生命周期,就是整个进程的生命周期。若仍不理解,可参考以下示例代码。
import timefrom threading import Threaddefdisplay(content): whileTrue: print(content, end='', flush=True) time.sleep(0.1)defmain(): Thread(target=display, args=('Ping', )).start() Thread(target=display, args=('Pong', )).start()if __name__ == '__main__': main()说明 :上述代码中,我们将
flush参数设为True。这是因为,若flush=False且
上述代码运行后会持续执行、无法自动停止------因为两个子线程中都包含死循环,除非手动中断程序。但如果在创建线程对象时,将daemon参数设为True,这两个线程就会成为守护线程:当其他非守护线程(此处为主线程)结束时,即便存在死循环,守护线程也会被销毁,不再继续执行。修改后的代码如下:
import timefrom threading import Threaddefdisplay(content): whileTrue: print(content, end='', flush=True) time.sleep(0.1)defmain(): Thread(target=display, args=('Ping', ), daemon=True).start() Thread(target=display, args=('Pong', ), daemon=True).start() time.sleep(5)if __name__ == '__main__': main()上述代码中,我们在主线程中添加了time.sleep(5),让主线程休眠5秒。在这5秒内,输出"Ping"和"Pong"的守护线程会持续运行;当主线程5秒后结束时,两个守护线程也会被销毁,程序随之终止。
思考 :如果删除上述代码第12行的
daemon=True,代码会如何执行?有兴趣的读者可自行尝试,对比实际结果与预期是否一致。
资源竞争
编写多线程代码时,不可避免会遇到多个线程竞争同一个资源(如对象、数据)的情况。若没有合理的保护机制,就可能出现数据不一致等非预期问题。下面的代码创建了100个线程,向同一个初始余额为0元的银行账户转账,每个线程转账1元。正常情况下,账户最终余额应为100元,但运行代码后,我们无法得到这个预期结果。
import timefrom concurrent.futures import ThreadPoolExecutorclassAccount(object): """银行账户""" def__init__(self): self.balance = 0.0 defdeposit(self, money): """存钱""" new_balance = self.balance + money time.sleep(0.01) self.balance = new_balancedefmain(): """主函数""" account = Account() with ThreadPoolExecutor(max_workers=16) as pool: for _ inrange(100): pool.submit(account.deposit, 1) print(account.balance)if __name__ == '__main__': main()上述代码中,Account类代表银行账户,deposit方法实现存款功能,money参数为存入金额,time.sleep用于模拟存款业务的处理耗时。我们通过线程池启动100个线程转账,但无法得到100元的预期结果------这就是多线程竞争资源时常见的数据不一致问题。
关键问题出在第14行:当多个线程同时执行到这行代码时,它们会基于同一个账户余额(如0元)执行"加钱"操作,随后的time.sleep(0.01)会让线程进入休眠,此时其他线程会继续执行相同操作,最终导致"丢失更新"------前一个线程的修改结果被后一个线程覆盖,因此无法得到正确余额。
要解决这个问题,可使用锁机制,对操作数据的关键代码进行保护。Python标准库threading模块提供了Lock和RLock类支持锁机制,此处不深究二者区别,建议直接使用RLock(可重入锁)。下面我们为银行账户添加锁对象,解决存款时的"丢失更新"问题,代码如下:
import timefrom concurrent.futures import ThreadPoolExecutorfrom threading import RLockclassAccount(object): """银行账户""" def__init__(self): self.balance = 0.0 self.lock = RLock() defdeposit(self, money): # 获得锁 self.lock.acquire() try: new_balance = self.balance + money time.sleep(0.01) self.balance = new_balance finally: # 释放锁,确保无论是否出错,锁都会被释放 self.lock.release()defmain(): """主函数""" account = Account() with ThreadPoolExecutor(max_workers=16) as pool: for _ inrange(100): pool.submit(account.deposit, 1) print(account.balance)if __name__ == '__main__': main()上述代码中,获得锁和释放锁的操作,也可通过上下文语法(with语句)实现,代码会更加简洁优雅,这也是我们推荐的方式:
import timefrom concurrent.futures import ThreadPoolExecutorfrom threading import RLockclassAccount(object): """银行账户""" def__init__(self): self.balance = 0.0 self.lock = RLock() defdeposit(self, money): # 通过上下文语法自动获得锁、释放锁 withself.lock: new_balance = self.balance + money time.sleep(0.01) self.balance = new_balancedefmain(): """主函数""" account = Account() with ThreadPoolExecutor(max_workers=16) as pool: for _ inrange(100): pool.submit(account.deposit, 1) print(account.balance)if __name__ == '__main__': main()思考 :将上述代码修改为"5个线程存钱、5个线程取钱",取钱线程在账户余额不足时,需暂停等待存钱线程存入资金后再尝试取钱。这需要用到线程调度相关知识,大家可自行研究
threading模块的Condition类,尝试完成这个任务。
GIL问题
若使用官方Python解释器(通常称为CPython)运行Python程序,我们无法通过多线程将CPU利用率提升至逼近400%(4核CPU)或800%(8核CPU)------这是因为CPython执行代码时,会受到GIL(全局解释器锁)的限制。
具体来说,CPython执行任何代码时,对应的线程必须先获得GIL;每执行100条字节码指令,CPython会让当前持有GIL的线程主动释放GIL,让其他线程有机会获得CPU执行权。由于GIL的存在,无论CPU有多少个核心,Python代码都无法真正并行执行。
GIL是CPython设计上的历史遗留问题,要彻底解决这个问题、让多线程发挥CPU多核优势,需要重新实现一个不带GIL的Python解释器。根据官方说法,这个问题将在Python 4.0版本中得到解决,让我们拭目以待。
当下,对于CPython而言,若希望充分发挥CPU多核优势,可考虑使用多进程------每个进程对应一个独立的Python解释器,因此每个进程都有自己的GIL,从而突破GIL的限制。在下一章节中,我们将介绍多进程的相关知识,并对比多线程与多进程的代码及执行效果。
AI工具
新用户🉑体验3天,体验最新最强GPT 5.4 Thinking,关注并私信,备注ai体验