中文分词 - 正向最大匹配
1.收集一个词表
2.对于一个待分词的字符串,从前向后寻找最长的,在此表中出现的词,在词边界做切分
3.从切分处重复步骤2,直到字符串末尾
正向最大匹配实现方式一:
找出词表中的最大词长度
从字符串开头开始选取最大词长度的窗口,检查窗口内词是否在词表中
如果在词表中,在词边界处进行切分,之后移动到词边界处,重复步骤2
如果不在词表中,窗口右边界回退一个字符,之后检查窗口词是否在词表中
实现方式二:
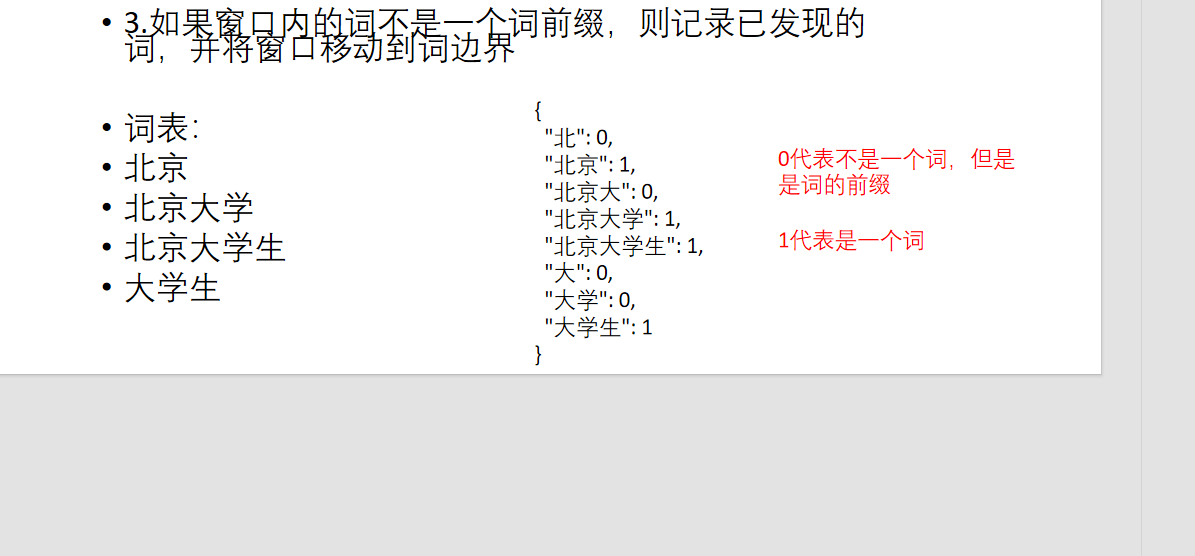
从前向后进行查找
如果窗口内的词是一个词前缀则继续扩大窗口
如果窗口内的词不是一个词的前缀,则记录已发现的词,并将窗口移动到词边界
中文分词-jieba分词
比如北京大学生前来报到
把所有的情况切分出来
那么哪种切分最好 ,根据切分方式总词频最高
它会自己算出来词频,然后找到总词频更高的值
怎么实现的?
他会先选文本,然后根据切分做出词典,统计词频,就是在跟我们做任务之前,他已经准备好了,词典
.正向最大切分,负向最大切分,双向最大切分共同的缺点:
对词表及其依赖,如果没有词表,则无法进行;如果词表中缺少需要的词,结果也不会正确
切分过程中不会关注整个句子表达的意思,只会将句子看成一个个片段
如果文本中出现一定的错别字,会造成一连串影响
对于人名等的无法枚举实体词无法有效处理
中英混杂也是个问题
中文分词 - 基于机器学习
分词的本质需要我们知道
假如
我们的本质是对每个词进行二分类
# 统计tf和idf的值 def build_tf_idf_dict(corpus): tf_dict = defaultdict(dict) # key:文档号,value:dict,文档中每个词出现的概率 idf_dict = defaultdict(set) # key: 词 value: set,文档序号,最终用于计算每个词在多少篇文档中出现过 for text_index,text_words in enumerate(corpus): for word in text_words: if word not in tf_dict[text_index]: tf_dict[text_index][word] = 0 tf_dict[text_index][word] += 1 idf_dict[word].add(text_index) idf_dict = dict([(key,len(value)) for key,value in idf_dict.items()]) return tf_dict,idf_dict # 根据tf值和idf值计算tfidf def calculate_tf_idf(tf_dict,idf_dict): tf_idf_dict = defaultdict(dict) for text_index,word_tf_count_dict in tf_dict.items(): for word,tf_count in word_tf_count_dict.items(): tf = tf_count/sum(word_tf_count_dict.values()) # tf-idf = tf * log(D/(idf + 1)) tf_idf_dict[text_index][word] = tf * math.log(len(tf_dict) / (idf_dict[word] + 1)) return tf_idf_dict # 输入语料 list of string #["******","*******","********"] def calculate_tfidf(corpus): # 先进性分词 corpus = [jieba.lcut(text) for text in corpus] tf_dict,idf_dict = build_tf_idf_dict(corpus) tf_idf_dict = calculate_tf_idf(tf_dict,idf_dict) return tf_idf_dict #根据tfidf字典,显示每个领域topK的关键词 def tf_idf_topk(tfidf_dict, paths=[], top=10, print_word=True): topk_dict = {} for text_index, text_tfidf_dict in tfidf_dict.items(): word_list = sorted(text_tfidf_dict.items(), key=lambda x:x[1], reverse=True) topk_dict[text_index] = word_list[:top] if print_word: print(text_index, paths[text_index]) for i in range(top): print(word_list[i]) print("----------") return topk_dict


但是传统分法都很依赖词表,但是多数情况下没有词表,如果不依赖词表怎么做
新词发现
随着时间的推移,新词会不断出现,固有词表会过时
补充词表有利于下游任务
什么是词:
词相当于一种固定搭配
那怎么定义一种固定搭配:
词的内部应该是稳固的 内部凝固度
c1,cn 代表其中字,p(c1)字的频率连乘起来,p(w)词频
词的外部应该是多变的 左右熵
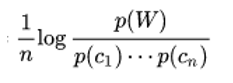
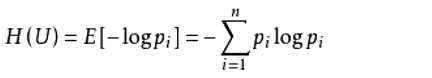
从词到理解
有了分词能力后,需要利用词来完成对文本的理解
首先可以想到的,就是从文章挑选重要的词
何为重要词:
如何用数学角度刻画
一种nlp的经典统计值: TF*IDF
TF: 词频
某个词在某类别中出现的次数/该类别词总数
IDF: 逆文档频率
N代表文本书总数
dfi 代表包含qi的文本中的总数
逆文档频率高->该词很少出现在其他文档
TF-IDF高->该词对于该领域重要程度高


TFIDF应用-搜索引擎
对于已有所有网页(文本),计算每个网页中,词的TFIDF值
对于一个输入query进行分词
对于文档D,计算query中的词在文档D中的TFIDF值总和,作为query和文档的相关性得分
TFIDF应用-文本摘要
1.通过计算TFIDF值得到每个文本的关键词
2.将包含关键词多的句子,认为是关键句
3.挑选若干关键句,作为文本的摘要
TFIDF应用-文本相似度计算
1.对所有文本计算tfidf后,从每个文本选取tfidf较高的前n个词,得到一个词的集合S
对于每篇文本D,计算S中的每个词的词频,将其作为文本的向量。
通过计算向量夹角余弦值,得到向量相似度,作为文本的相似度
向量夹角余弦值计算:
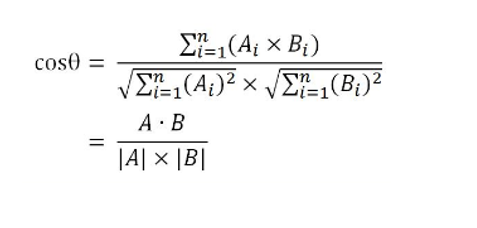
TFIDF劣势
1.受分词影响大
词与词之间没有语义相似度
没有语序信息
能力范围有限,无法完成复杂任务,如机器翻译和实体挖掘
样本不均衡会对结果有很大影响
类内样本分布不被考虑