
一、背景与问题
在做Python网络请求开发时,常见的HTTP客户端库有:
- requests:最经典的同步库
- aiohttp:异步IO专用库
- httpx.Client:httpx的同步客户端
- httpx.AsyncClient:httpx的异步客户端
好久没有用异步http请求, 最近在做项目时候经常用到这几个库,所以特意总结一下。
它们之间有什么区别?什么时候用同步,什么时候用异步?异步真的比同步快吗?
本文通过实际代码实验,带你深入理解这四种客户端的本质区别。
二、核心概念对比
2.1 四种客户端的本质区别
| 库 | 类型 | 是否阻塞 | 适用场景 |
|---|---|---|---|
| requests | 同步 | 阻塞整个线程 | 单次请求、简单脚本 |
| aiohttp | 异步 | 非阻塞,事件循环 | 高并发、大量IO操作 |
| httpx.Client | 同步 | 阻塞整个线程 | 单次请求、兼容旧代码 |
| httpx.AsyncClient | 异步 | 非阻塞,事件循环 | 高并发、现代项目 |
核心区别:同步库在执行请求时,整个程序会"停下来等待";异步库在等待响应时,会切换去执行其他任务。
2.2 同步 vs 异步原理图解
同步执行(串行):
请求1 → 等待 → 响应1 → 请求2 → 等待 → 响应2 → 请求3 → 等待 → 响应3
总耗时 = 单次耗时 × 请求数量
异步执行(并发):
请求1 → 等待1 ──────────────────→ 响应1
请求2 → 等待2 ──────────→ 响应2
请求3 → 等待3 → 响应3
总耗时 ≈ 单次耗时(并发时)2.3 同步阻塞 vs 异步非阻塞的本质
这是理解同步和异步最关键的一点:
| 特性 | 同步库 | 异步库 |
|---|---|---|
| 执行方式 | 阻塞线程/事件循环 | 非阻塞,立即返回 |
| 等待时做什么 | 线程停下来等待 | 切换去执行其他任务 |
| CPU利用率 | 等待时CPU空闲 | 等待时CPU可执行其他代码 |
什么是阻塞?
python
# 同步库(requests)执行流程
def fetch():
response = requests.get(url) # ← 程序在这里停下来,什么都不做
# 线程被"卡住",等待网络响应
# 这段时间CPU空转,无法执行其他代码
return response.json()调用 requests.get() 时,整个线程被阻塞,程序"卡"在那里等待网络响应。等待期间,线程无法做任何其他事情。
什么是非阻塞?
python
# 异步库执行流程
async def fetch():
response = await session.get(url) # ← 发起请求后立即返回控制权
# 等待期间,事件循环切换去执行其他协程
# CPU继续工作,不会空转
return await response.json()调用异步方法时,立即返回一个协程对象,控制权交还给事件循环。等待期间,事件循环可以去执行其他协程,CPU不会空闲。
事件循环的核心机制
事件循环工作流程:
┌─────────────────────────────────────────┐
│ 协程A发起请求 → 挂起,等待IO │
│ ↓ 控制权返回事件循环 │
│ 事件循环切换到协程B → 执行B的代码 │
│ ↓ 协程B也发起请求 → 挂起 │
│ 事件循环切换到协程C → ... │
│ ↓ 某个协程IO完成 → 恢复执行 │
└─────────────────────────────────────────┘关键陷阱:在async函数里用同步库
python
# ❌ 错误示范
async def fetch_data():
response = requests.get(url) # 同步库!
return response.json()
# 看起来是async函数,但requests.get()会阻塞整个事件循环
# 事件循环被卡住,所有其他协程都无法执行!
# 这比纯同步代码更糟糕,因为伪装成了异步这是新手最容易犯的错误:async函数里用同步库,会阻塞整个事件循环,导致所有协程都无法并发执行。
三、实战对比实验
3.1 测试环境
创建app_server.py先搭建一个模拟fastapi服务,每个请求固定延迟0.5秒:
python
# app_server.py
import time
import uvicorn
import asyncio
from fastapi import FastAPI, Query
from pydantic import BaseModel
app = FastAPI(title="测试接口", version="1.0")
# ------------------------------
# 统一响应模型(所有接口返回格式一致)
# ------------------------------
class BaseResponse(BaseModel):
code: int = 0
msg: str = "success"
time: str = "0.5s delay"
# ------------------------------
# GET 无参接口
# ------------------------------
@app.get("/api/get_sync", summary="测试GET接口(无参)", )
def test_api():
time.sleep(0.5)
return {
**BaseResponse().model_dump(),
"params": False,
}
# ------------------------------
# GET 无参接口
# ------------------------------
@app.get("/api/get_test", summary="测试GET接口(无参)", )
async def test_api():
await asyncio.sleep(0.5)
return {
**BaseResponse().model_dump(),
"params": False,
}
# ------------------------------
# GET 带参数接口(强校验)
# ------------------------------
@app.get("/api/get_user", summary="获取用户ID", )
async def test_user_id(
user_id: str = Query(..., min_length=1, description="用户ID不能为空")
):
await asyncio.sleep(0.5)
return {
**BaseResponse().model_dump(),
"params": True,
"userId": user_id
}
# ------------------------------
# POST 无参接口
# ------------------------------
@app.post("/api/test_post", summary="测试POST接口(无参)")
async def test_user_info():
await asyncio.sleep(0.5)
return {
**BaseResponse().model_dump(),
"params": False,
}
# ------------------------------
# POST 接收JSON参数(标准用法)
# ------------------------------
class UserInfoRequest(BaseModel):
name: str
age: str
@app.post("/api/user_info", summary="提交用户信息")
async def get_user_info(req: UserInfoRequest):
await asyncio.sleep(0.5)
return {
**BaseResponse().model_dump(),
"params": True,
"data": req.model_dump()
}
# 为测试启动的http服务
if __name__ == "__main__":
uvicorn.run(app, host="127.0.0.1", port=8000)3.2 requests vs aiohttp 单个和批量请求对比
前提在开启fastapi服务之后创建test_aiohttp_request_batch.py 文件并执行该文件
python
# test_aiohttp_request_batch.py
import time
import os
import requests
import aiohttp
import asyncio
from tqdm.asyncio import tqdm_asyncio # 👈 异步专用进度条
# 1. 看似异步,里面其实是同步请求
async def test_faker_async_requests(url, headers, params):
"""虚假的异步 - async函数里用同步requests,会阻塞事件循环,不支持真正的并发"""
response = requests.post(url, headers=headers, json=params)
return response.json()
# 2. 同步方法
def test_sync_requests(url, headers, params):
"""同步请求函数 - 需要配合线程池才能实现并发"""
response = requests.post(url, headers=headers, json=params)
return response.json()
# 用 asyncio.to_thread 包装同步函数实现并发(下策,能用异步优先用异步)
async def test_to_thread_requests(url, headers, params):
"""通过线程池执行同步请求,实现真正的并发"""
res = await asyncio.to_thread(test_sync_requests, url, headers, params) # 多线程,调用同步函数
return res
# 3. 真正的异步
async def test_aiohttp(url, headers, params):
"""真正的异步请求,对异步并发友好。注意:每次调用都新建session(仅用于演示)"""
async with aiohttp.ClientSession() as session:
async with session.post(url, headers=headers, json=params) as response:
return await response.json()
# 单个请求任务
async def fetch_one(semaphore, fetch_func, base_url: str, headers: dict, params: dict, request_id: int):
# 信号量加锁,控制并发
async with semaphore:
request_start_time = time.time()
try:
result = await fetch_func(base_url, headers, params)
request_cost_time = time.time() - request_start_time
return {
"request_id": request_id,
"status": "success",
"result": result,
"cost_time": request_cost_time
}
except Exception as e:
request_cost_time = time.time() - request_start_time
return {
"request_id": request_id,
"status": "error",
"result": str(e),
"cost_time": request_cost_time
}
async def test_concurrent(
fetch_func, # 测试的异步方法名称
total_requests: int = 100, # 总请求次数
max_concurrent: int = 10 # 最大并发数(信号量控制)
):
"""
高并发请求函数
- 带信号量控制并发
- 自动连接池
- 异常捕获
- 批量请求
"""
# 基础配置
base_url = "http://127.0.0.1:8000/api/user_info"
headers = {
"User-Agent": f"PythonClient/2.0 (PID:{os.getpid()})",
"Accept": "application/json",
}
params = {
"name": "jordan",
"age": "50",
}
# 信号量:限制最大协程并发数(核心)
semaphore = asyncio.Semaphore(max_concurrent)
method_start_time = time.time()
# 创建所有任务
tasks = [fetch_one(semaphore, fetch_func, base_url, headers, params, i) for i in range(total_requests)]
# 利用单线程多协程并发执行
results = await tqdm_asyncio.gather(*tasks)
method_cost_time = time.time() - method_start_time
# 统计结果
success_results = [r for r in results if r["status"] == "success"]
error_results = [r for r in results if r["status"] == "error"]
print("\n" + "=" * 50)
print(f"测试结果统计 并发数: {max_concurrent}")
print("=" * 50)
print(f"执行方法: {fetch_func.__name__}")
print(f"总请求数: {total_requests}")
print(f"成功数: {len(success_results)}")
print(f"失败数: {len(error_results)}")
print(f"总耗时: {method_cost_time:.2f}s")
if success_results:
elapsed_times = [r["cost_time"] for r in success_results]
print(f"各请求耗时: {[round(t, 2) for t in elapsed_times]}s")
print(f"平均响应时间: {sum(elapsed_times)/len(elapsed_times):.2f}s")
print(f"最快响应时间: {min(elapsed_times):.2f}s")
print(f"最慢响应时间: {max(elapsed_times):.2f}s")
if error_results:
print("\n失败详情:")
for r in error_results:
print(f" 请求 #{r['request_id']}: {r['result']}")
print("\n成功响应示例:")
for r in success_results[:2]:
print(f" 请求 #{r['request_id']} ({r['cost_time']:.2f}s): {r['result']}")
return results
# ==================
# 运行
# ==================
async def test_main():
# COUNT = 10
target_url = "http://127.0.0.1:8000/api/user_info"
params = {
"name": "jordan",
"age": "50",
}
# 单次请求测试 -------------------------------------------------------------------------------------------
print("===== 虚假异步 requests(会阻塞事件循环) =====")
requests_response = await test_faker_async_requests(target_url, {}, params)
print(f"requests_response: {requests_response}")
print("===== 线程池包装 requests =====")
thread_response = await test_to_thread_requests(target_url, {}, params)
print(f"thread_response: {thread_response}")
print("===== 真正异步 aiohttp =====")
aiohttp_response = await test_aiohttp(target_url, {}, params)
print(f"aiohttp_response: {aiohttp_response}")
# 协程异步并发调用请求测试 -------------------------------------------------------------------------------------------
print("\n===== 虚假异步并发测试(实际串行,阻塞事件循环) =====")
faker_batch_res = await test_concurrent(test_faker_async_requests, total_requests=5, max_concurrent=5) # 耗时 2.5秒左右
print("\n===== 线程池包装并发测试(真正并发) =====")
thread_batch_res = await test_concurrent(test_to_thread_requests, total_requests=5, max_concurrent=5) # 耗时 0.5秒左右
print("\n===== 真正异步并发测试 =====")
aiohttp_batch_res = await test_concurrent(test_aiohttp, total_requests=5, max_concurrent=5) # 耗时 0.5秒左右
# 针对post请求, 针对同步请求request, 和异步请求aiohttp的测试
if __name__ == "__main__":
asyncio.run(test_main())运行结果: 这里我只贴出并发的关键结果,单次调用的结果基本上是没有区别的
===== 同步 requests =====
requests 总耗时:5.12s # 串行执行,10 × 0.5秒
===== 异步 aiohttp =====
aiohttp 总耗时:0.56s # 并发执行,约0.5秒
==================================================
测试结果统计 并发数: 5
==================================================
执行方法: test_requests
总请求数: 5
成功数: 5
失败数: 0
总耗时: 2.53s
各请求耗时: [0.5, 0.5, 0.5, 0.5, 0.5]s
平均响应时间: 0.50s
最快响应时间: 0.50s
最慢响应时间: 0.50s
==================================================
测试结果统计 并发数: 5
==================================================
执行方法: test_to_thread_requests
总请求数: 5
成功数: 5
失败数: 0
总耗时: 0.51s
各请求耗时: [0.51, 0.51, 0.51, 0.51, 0.51]s
平均响应时间: 0.51s
最快响应时间: 0.51s
最慢响应时间: 0.51s
==================================================
测试结果统计 并发数: 5
==================================================
执行方法: test_aiohttp
总请求数: 5
成功数: 5
失败数: 0
总耗时: 0.51s
各请求耗时: [0.5, 0.51, 0.5, 0.5, 0.51]s
平均响应时间: 0.50s
最快响应时间: 0.50s
最慢响应时间: 0.51s▎ 到这里有人可能会问,为什么同步方法中 各请求耗时: [0.5, 0.5, 0.5, 0.5, 0.5]s 这个同步并发调用的每个请求结果都是 0.5s 左右呢?
▎ 这是因为 cost_time 只记录了该请求本身的执行耗时,从请求发起到响应返回的时间。由于request
是同步阻塞调用,会阻塞整个事件循环,实际上请求是串行执行的:请求1完成后请求2才开始,请求2完成后请求3才开始...
▎ 所以虽然每个请求的 cost_time 都是 0.5s,但总耗时 = 10 × 0.5s = 5s,这才是串行执行的真实体现。Semaphore 在这里只是控制协程进入的数量,但由于同步调用阻塞了事件循环,无法实现真正的并发。 于是就有了这个结果,这里主要看总耗时就可以明白了。
总结:虽然用了 Semaphore,但同步调用会阻塞事件循环【线程】,请求还是一个接一个执行的。
3.2.1 补充:asyncio.to_thread 的原理
上面的代码展示了三种并发请求方式,其中 test_to_thread_requests 使用了 asyncio.to_thread 包装同步函数,实现了真正的并发。那么 asyncio.to_thread 是什么?
什么是 asyncio.to_thread?
asyncio.to_thread 是 Python 3.9+ 提供的函数,它将同步函数放到独立线程中执行,让事件循环可以继续处理其他协程。
python
# asyncio.to_thread 的工作原理
async def test_to_thread_requests(url, headers, params):
# 将同步函数 test_sync_requests 放到线程池执行
# 事件循环不会被阻塞,可以继续执行其他协程
res = await asyncio.to_thread(test_sync_requests, url, headers, params)
return res执行流程对比:
虚假异步(test_faker_async_requests):
┌─────────────────────────────────────────┐
│ 协程1调用requests → 阻塞事件循环 │
│ ↓ 所有协程都在等,无法并发 │
│ 协程2等待... 协程3等待... │
│ 串行执行,总耗时 = N × 单次耗时 │
└─────────────────────────────────────────┘
asyncio.to_thread(test_to_thread_requests):
┌─────────────────────────────────────────┐
│ 协程1 → to_thread → 线程1执行requests │
│ ↓ 事件循环继续,不被阻塞 │
│ 协程2 → to_thread → 线程2执行requests │
│ ↓ 多个线程并行执行 │
│ 真正并发,总耗时 ≈ 单次耗时 │
└─────────────────────────────────────────┘
真正异步(test_aiohttp):
┌─────────────────────────────────────────┐
│ 协程1 → aiohttp发起请求 → 挂起等待IO │
│ ↓ 事件循环切换执行其他协程 │
│ 协程2 → aiohttp发起请求 → 挂起等待IO │
│ ↓ 单线程内多协程并发,无需额外线程 │
│ 真正并发,总耗时 ≈ 单次耗时 │
└─────────────────────────────────────────┘三种方式的本质区别:
| 方式 | 执行位置 | 是否阻塞事件循环 | 是否并发 |
|---|---|---|---|
| 虚假异步(async函数里直接调用同步库) | 主线程 | 阻塞 | ❌ 串行 |
| asyncio.to_thread | 独立线程 | 不阻塞 | ✓ 并发 |
| 真正异步(aiohttp) | 主线程(协程挂起) | 不阻塞 | ✓ 并发 |
为什么 asyncio.to_thread 不阻塞主线程?
这是理解 asyncio.to_thread 的关键点:
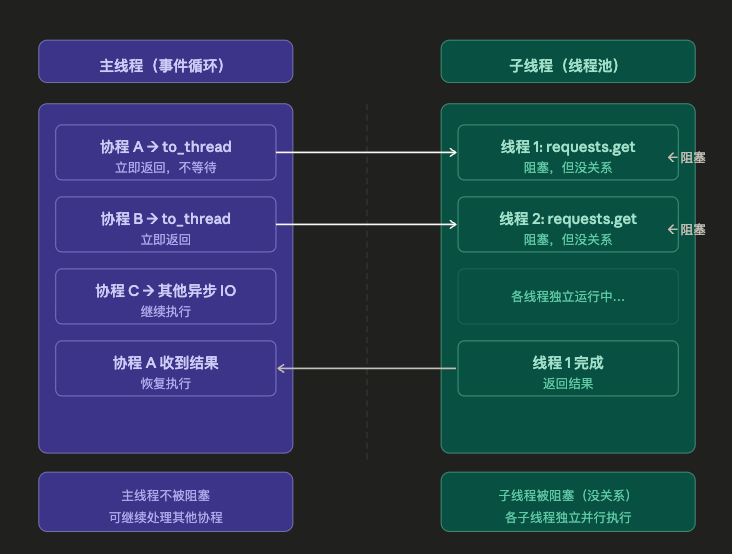
核心原理:
| 线程 | 阻塞情况 | 影响 |
|---|---|---|
| 主线程(事件循环) | 不阻塞 | 可以继续调度其他协程 |
| 子线程(线程池) | 阻塞 | 但不影响主线程,子线程之间并行 |
所以:
requests.get()依然是阻塞调用- 但它阻塞的是子线程,不是主线程
- 主线程的事件循环继续运转,可以调度其他协程
- 多个子线程可以并行执行,实现真正的并发
一句话总结 :asyncio.to_thread 把阻塞甩给子线程,主线程保持自由。
为什么 asyncio.to_thread 是"下策"?
python
# 下策:用线程池包装同步函数
async def fetch():
res = await asyncio.to_thread(requests.get, url) # 需要额外线程
return res.json()
# 上策:直接用异步库
async def fetch():
async with aiohttp.ClientSession() as session:
async with session.get(url) as response:
return await response.json() # 无需额外线程,更高效| 对比项 | asyncio.to_thread | 真正异步(aiohttp) |
|---|---|---|
| 线程开销 | 需要创建线程 | 不需要,协程足够轻量 |
| 内存占用 | 每个线程~8MB | 每个协程~几KB |
| 最大并发数 | 受线程数限制(通常几十到几百) | 几千甚至上万 |
| 适用场景 | 无法修改的同步代码、遗留代码 | 新项目、高并发场景 |
什么时候用 asyncio.to_thread?
- 无法修改的遗留同步代码
- 第三方库只有同步接口,没有异步版本
- 快速验证并发效果,后续再迁移到异步库
总结 :能用异步库就优先用异步库,asyncio.to_thread 是不得已的下策。
3.3 httpx同步 vs 异步对比 单个和批量请求对比
前提在开启fastapi服务之后创建test_http_client_batch.py 文件并执行该文件
python
# 04_test_http_client_batch.py
import os
import time
import httpx
import asyncio
from loguru import logger
from typing import Dict
from tqdm.asyncio import tqdm_asyncio # 👈 异步专用进度条
async def test_sync_httpx(base_url, headers, params):
"""测试同步请求方法, 阻塞线程"""
with httpx.Client(base_url=base_url, headers=headers, timeout=5) as sync_client:
params_response = sync_client.request(
"post",
f"/api/user_info",
json=params,
)
return params_response.json()
async def test_async_httpx(base_url, headers, params):
"""异步调用, 非阻塞线程正确的异步调用方法"""
# 异步调用的客户短
async with httpx.AsyncClient(base_url=base_url, headers=headers, timeout=5) as async_client:
params_response = await async_client.request(
"post",
f"/api/user_info",
json=params,
)
return params_response.json()
# 单个请求任务
async def fetch_one(semaphore, fetch_func, base_url: str, headers: dict, params: dict, request_id: int):
# 信号量加锁,控制并发
async with semaphore:
request_start_time = time.time()
try:
result = await fetch_func(base_url, headers, params)
request_cost_time = time.time() - request_start_time
return {
"request_id": request_id,
"status": "success",
"result": result,
"cost_time": request_cost_time
}
except Exception as e:
request_cost_time = time.time() - request_start_time
return {
"request_id": request_id,
"status": "error",
"result": str(e),
"cost_time": request_cost_time
}
async def test_concurrent(
fetch_func, # 测试的异步方法名称
total_requests: int = 100, # 总请求次数
max_concurrent: int = 10 # 最大并发数(信号量控制)
):
"""
高并发请求函数
- 带信号量控制并发
- 自动连接池
- 异常捕获
- 批量请求
"""
# 基础配置
base_url = "http://127.0.0.1:8000"
headers = {
"User-Agent": f"PythonClient/2.0 (PID:{os.getpid()})",
"Accept": "application/json",
}
params = {
"name": "jordan",
"age": "50",
}
# 信号量:限制最大协程并发数(核心)
semaphore = asyncio.Semaphore(max_concurrent)
method_start_time = time.time()
# 创建所有任务
tasks = [fetch_one(semaphore, fetch_func, base_url, headers, params, i) for i in range(total_requests)]
# 利用单线程,多协程并发执行
results = await tqdm_asyncio.gather(*tasks)
method_cost_time = time.time() - method_start_time
# 统计结果
success_results = [r for r in results if r["status"] == "success"]
error_results = [r for r in results if r["status"] == "error"]
print("\n" + "=" * 50)
print(f"测试结果统计 并发数: {max_concurrent}")
print("=" * 50)
print(f"执行方法: {fetch_func.__name__}")
print(f"总请求数: {total_requests}")
print(f"成功数: {len(success_results)}")
print(f"失败数: {len(error_results)}")
print(f"总耗时: {method_cost_time:.2f}s")
if success_results:
elapsed_times = [r["cost_time"] for r in success_results]
print(f"各请求耗时: {[round(t, 2) for t in elapsed_times]}s")
print(f"平均响应时间: {sum(elapsed_times)/len(elapsed_times):.2f}s")
print(f"最快响应时间: {min(elapsed_times):.2f}s")
print(f"最慢响应时间: {max(elapsed_times):.2f}s")
if error_results:
print("\n失败详情:")
for r in error_results:
print(f" 请求 #{r['request_id']}: {r['result']}")
print("\n成功响应示例:")
for r in success_results[:2]:
print(f" 请求 #{r['request_id']} ({r['cost_time']:.2f}s): {r['result']}")
return results
async def main():
base_url = "http://127.0.0.1:8000"
headers={
"User-Agent": f"PythonClient/2.0 (PID:{os.getpid()})",
"Accept": "application/json",
# "Authorization": "Bearer " + cls._secret, # 如果要进行token验证
}
# 同步调用的客户端
params = {
"name": "jordan",
"age": "50",
}
# 单次请求测试 -------------------------------------------------------------------------------------------
print("===== 同步 requests =====")
requests_response = await test_sync_httpx(base_url, headers, params) #
print(f"requests_response: {requests_response}")
print("===== 异步 aiohttp =====")
aiohttp_response = await test_async_httpx(base_url, headers, params)
print(f"aiohttp_response: {aiohttp_response}")
sync_httpx_res = await test_concurrent(test_sync_httpx, total_requests=10, max_concurrent=5) # 耗时 5秒左右
# print(f"sync_httpx_res: {sync_httpx_res}")
async_httpx_res = await test_concurrent(test_async_httpx, total_requests=10, max_concurrent=5) # 耗时 1秒左右
# print(f"async_httpx_res: {async_httpx_res}")
# 运行方式
# 测试Semaphore针对http.client,http.AsyncClient针对异步的并发支持 效果
if __name__ == "__main__":
# 发 50 个请求,最大同时并发 10
asyncio.run(main())运行结果: 这里我只贴出并发的关键结果,单次调用的结果基本上是没有区别的
==================================================
测试结果统计 并发数: 5
==================================================
执行方法: test_sync_httpx
总请求数: 10
成功数: 10
失败数: 0
总耗时: 5.57s
各请求耗时: [0.55, 0.56, 0.54, 0.56, 0.56, 0.56, 0.56, 0.56, 0.55, 0.56]s
平均响应时间: 0.56s
最快响应时间: 0.54s
最慢响应时间: 0.56s
==================================================
测试结果统计 并发数: 5
==================================================
执行方法: test_async_httpx
总请求数: 10
成功数: 10
失败数: 0
总耗时: 1.32s
各请求耗时: [0.64, 0.66, 0.66, 0.62, 0.59, 0.57, 0.69, 0.67, 0.54, 0.58]s
平均响应时间: 0.62s
最快响应时间: 0.54s
最慢响应时间: 0.69s关键点:
httpx.Client= 同步,阻塞线程,和requests类似httpx.AsyncClient= 异步,非阻塞,和aiohttp类似
▎ 到这里有人可能会问,为什么 各请求耗时: [0.55, 0.56, 0.54, 0.56, 0.56, 0.56, 0.56, 0.56, 0.55, 0.56]s 这个同步并发调用的每个请求结果都是 0.5s 左右呢?
▎ 这是因为 cost_time 只记录了该请求本身的执行耗时,从请求发起到响应返回的时间。由于 httpx.Client
是同步阻塞调用,会阻塞整个事件循环,实际上请求是串行执行的:请求1完成后请求2才开始,请求2完成后请求3才开始...
▎ 所以虽然每个请求的 cost_time 都是 0.5s,但总耗时 = 10 × 0.5s = 5s,这才是串行执行的真实体现。Semaphore 在这里只是控制协程进入的数量,但由于同步调用阻塞了事件循环,无法实现真正的并发。 于是就有了这个结果,这里主要看总耗时就可以明白了。
总结:虽然用了 Semaphore,但同步调用会阻塞事件循环【线程】,请求还是一个接一个执行的。
四、资源管理最佳实践
4.1 错误写法(资源泄漏)
python
# ❌ 错误:每次请求创建session但不关闭
async def test_aiohttp(url, headers, params):
session = aiohttp.ClientSession() # 没关闭!
response = await session.post(url, json=params)
return await response.json() # 如果这里异常,session永远不关闭
# ❌ 错误:httpx client 不关闭
async_client = httpx.AsyncClient(...)
response = await async_client.get(url) # 不关闭会泄漏连接4.2 正确写法对比
方式一:上下文管理器(推荐)
python
# aiohttp 正确写法
async with aiohttp.ClientSession() as session:
async with session.post(url, json=params) as response:
return await response.json()
# httpx.AsyncClient 正确写法
async with httpx.AsyncClient(base_url=url, timeout=5) as client:
async with client.post("/api/user_info", json=params) as response:
return await response.json()方式二:try-finally手动关闭
python
# aiohttp 手动关闭
session = aiohttp.ClientSession()
try:
response = await session.post(url, json=params)
return await response.json()
finally:
await session.close()
# httpx.AsyncClient 手动关闭
async_client = httpx.AsyncClient(base_url=url, timeout=5)
try:
response = await async_client.post("/api/user_info", json=params)
return await response.json()
finally:
await async_client.aclose() # 注意是aclose,不是close4.3 关闭方法对照表
| 库 | 同步关闭 | 异步关闭 |
|---|---|---|
| aiohttp.ClientSession | - | await session.close() |
| httpx.Client | client.close() |
- |
| httpx.AsyncClient | - | await client.aclose() |
注意 :AsyncClient的异步关闭方法是 aclose(),不是 close()!
五、使用场景总结
5.1 什么时候用同步?
- 单次请求:简单脚本、配置文件读取
- 非IO密集:计算密集型任务
- 兼容旧代码:迁移成本考虑
- 调试阶段:同步代码更容易调试
python
# 简单脚本用 requests 最方便
import requests
response = requests.get("https://api.example.com/data")
print(response.json())5.2 什么时候用异步?
- 高并发请求:批量API调用、爬虫
- IO密集型:大量网络/文件IO等待
- 实时应用:WebSocket、长连接
- 微服务架构:多个下游服务调用
python
# 高并发场景用异步
async def batch_request(urls):
async with aiohttp.ClientSession() as session:
tasks = [session.get(url) for url in urls]
responses = await asyncio.gather(*tasks)
return [await r.json() for r in responses]5.3 httpx vs requests vs aiohttp 选择
| 场景 | 推荐库 | 原因 |
|---|---|---|
| 快速原型开发 | requests | API简单,文档丰富 |
| 高并发爬虫 | aiohttp | 异步性能最优 |
| 现代项目(同步+异步都支持) | httpx | 一套API两种模式,迁移方便 |
| FastAPI/现代异步框架 | httpx.AsyncClient | 和框架风格统一 |
六、常见错误与注意事项
6.1 async函数中使用同步库
python
# ❌ 错误:async函数里用同步库
async def fetch_data():
response = requests.get(url) # 阻塞整个事件循环!
return response.json()
# ✓ 正确:用对应的异步库
async def fetch_data():
async with aiohttp.ClientSession() as session:
async with session.get(url) as response:
return await response.json()6.2 忘记await
python
# ❌ 错误:忘记await
async def fetch():
async with aiohttp.ClientSession() as session:
response = session.get(url) # 没await,得到的是coroutine对象
return response.json() # 报错!
# ✓ 正确
async def fetch():
async with aiohttp.ClientSession() as session:
async with session.get(url) as response: # 加await/async with
return await response.json()6.3 高并发时每个请求创建新session
python
# ❌ 效率低:每次请求新建session
async def fetch_one(url):
async with aiohttp.ClientSession() as session: # 每次新建
async with session.get(url) as response:
return await response.json()
# ✓ 推荐:复用session
async def batch_fetch(urls):
async with aiohttp.ClientSession() as session: # 只创建一次
tasks = [session.get(url) for url in urls]
responses = await asyncio.gather(*tasks)
return responses七、性能对比总结
| 场景 | 同步耗时 | 异步耗时 | 提升 |
|---|---|---|---|
| 10个请求(串行) | ~5秒 | ~0.5秒 | 10倍 |
| 100个请求(并发10) | ~50秒 | ~5秒 | 10倍 |
| 单次请求 | ~0.5秒 | ~0.5秒 | 无差异 |
结论:
- 单次请求:同步和异步性能相同
- 批量请求:异步性能提升N倍(N为并发数)
- 异步的优势在于等待IO时可以做其他事,不是单次请求更快
参考资料
博客为个人学习笔记,如有错误,请指正修改。