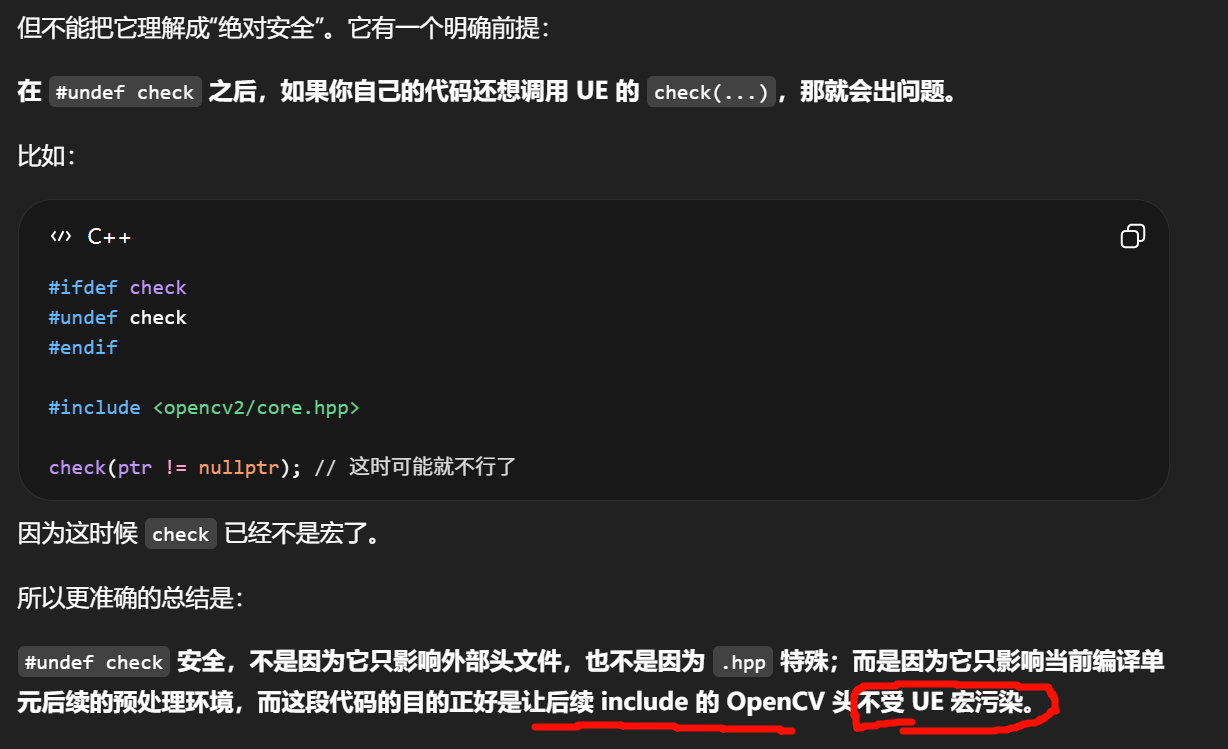
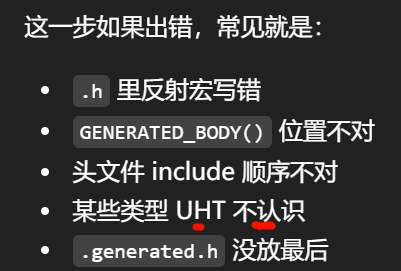
image placeimage placeimage placeimage placeimage placeimage placexxx(xxxxx) 这种形式通常就是 函数式宏 ,也叫 带参数宏。
对象式宏:#define true false
函数式宏:看括号
C++
#define MAX(a, b) ((a) > (b) ? (a) : (b))
Rider / Visual Studio / clangd 往往会在悬停时告诉你它是 macro。
Type Deduction (类型推导)
MyStruct* pMS = malloc(sizeof(MyStruct));这里用 malloc 申请了一块原始内存,大小够放一个 MyStruct。
注意这里是 C 风格分配,应该配套 free,而不是 delete。
关键点有两个:
-
你确实每次都新追加了
image place- 代码里
appendAnchorParagraph()每次都会body.appendChild(paragraph)。 - 所以截图里后面多个
image place说明"追加文本"这一步是成功的。
- 代码里
-
但图片 paste 时,CSDN 并没有按"你刚选中的最新那一段"来替换
- 你现在只是用原生
Range+Selection去选中文本,然后直接对body.dispatchEvent(pasteEvent)派发 paste。 - CSDN 这个编辑器本质上是 CKEditor,它内部通常维护一套自己的 selection/bookmark/focus 状态,不一定完全跟随你手工塞进去的浏览器原生选区。
- 所以会出现这种现象:页面上看起来新文本加到了后面,但编辑器内部真正"认定的插入点"还停留在第一次成功 paste 的那个位置,于是后续图片仍然插到第一次的区域。
- 你现在只是用原生
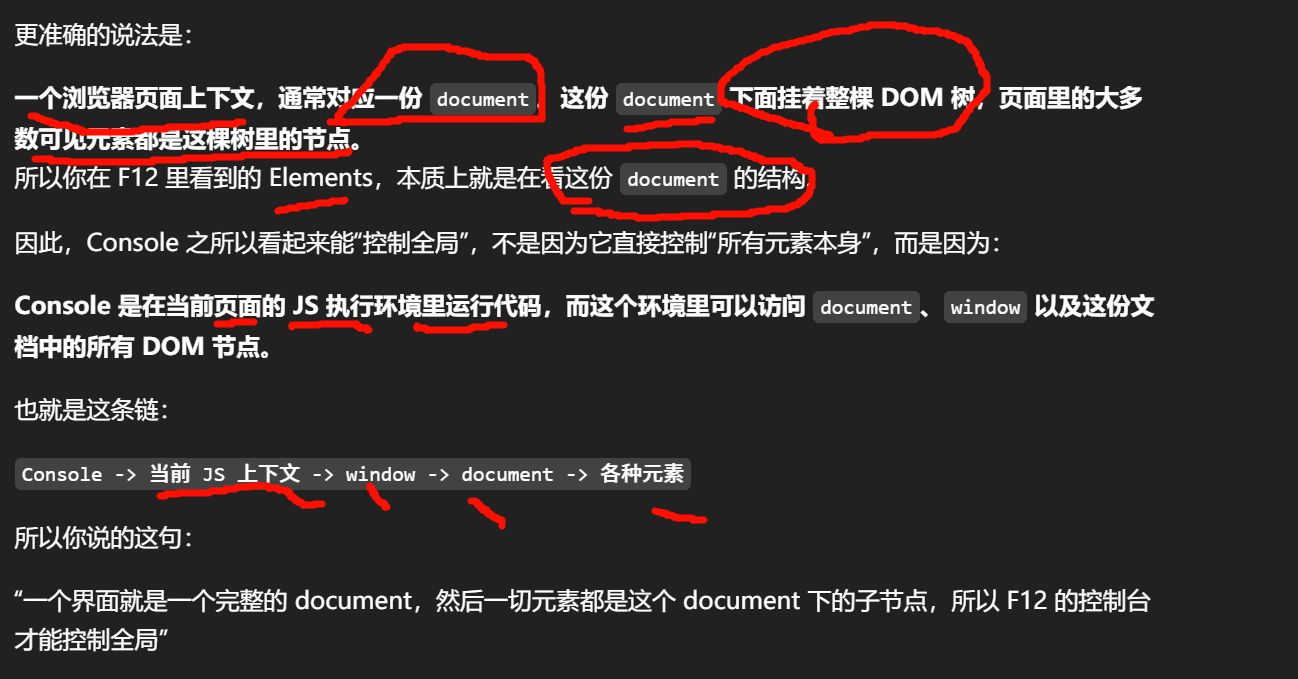
F12 控制台默认控制的是当前页面的运行环境;单独元素只是这个环境里的一个对象,不是一个独立控制台。
CKEDITOR exists: true:说明全局 CKEDITOR 存在
instances: ['editor']:说明当前至少有一个实例,名字是 editor
has focus: function:可以用 editor.focus()
has getSelection: function:可以用 CKEditor 自己的选区 API,而不必依赖原生 document.getSelection()
has createRange: function:可以用 CKEditor 自己的 range,而不必依赖原生 document.createRange()
has editable: function:可以拿到编辑器真正的可编辑区域
has insertHtml: function:可以用编辑器原生方式插入 image place当前这段:
- 追加文本:
appendAnchorParagraph() - 选中文本:
selectAnchorParagraphText() - 派发粘贴:
body.dispatchEvent(pasteEvent)
这套流程只改了浏览器 DOM 和原生选区,但没有确保 CKEditor 内部选区同步切到最新的 image place。
现在的逻辑是直接拿"刚 append 出来的那个段落节点引用"继续往下用,不是从 body 顶部往下扫,也不是从底部往上扫。
"粘贴完图片后,默认选中图片"的逻辑,不是你这段扩展代码直接规定的 ,而主要是 CSDN 编辑器 / CKEditor 的图片 widget 机制 在起作用。
Console 是在当前页面的 JS 执行环境里运行代码,而这个环境里可以访问 document、window 以及这份文档中的所有 DOM 节点。
div 是 HTML 里的一个非常通用的元素,全称通常理解为 division,就是"分区、区块"。
range.setStart(textNode, 0)
range.setEnd(textNode, textNode.textContent?.length || 0)
不 collapse:是"选中一段"
前者是在创建一个有长度的选区 ,后者是在创建一个没有长度、只有一个插入点的光标位置。
range.setStart(textNode, 0)
range.setEnd(textNode, 11)
这表示从 0 到 11 的内容都被选中了。
如果这段文本是 "image place",那就等于整段被高亮选中。
这时后续 paste / insert 行为通常会被浏览器或编辑器理解成:
- 用新内容替换这段选中的文本
- 或在这段选区上执行某种插入逻辑
所以它不是"光标停在后面",而是"这一段内容正处于被选中状态"。
collapse() 的作用就是:
把原本有起点和终点的 range,收缩成同一个位置。
所以 collapse 后,这个 range 不再表示"一段被选中的文本",而表示:
一个插入点 / 光标位置
这就是你图里说的"光标闪在 place 后面"的那个意思。
粘贴图片之后,原 range 基本应该视为"失效"或"语义变了" ,然后你要基于插入后的实际 DOM / 编辑器选区重新定位。
for (const auto &x : data) {
model.update(x);
}
它的一个直接好处就是:
你不需要自己写这种东西:
for (size_t i = 0; i < data.size(); ++i) {
model.update(datai);
}
确实少了一类和"索引"有关的错误,例如:
-
i < data.size()写成i <= data.size() -
i、j混用 -
data[i]写成data[k] -
下标偏移写错,比如
i + 1
因为 append text 这套逻辑根本不是"在当前光标位置插入",而是直接操作 DOM,把节点 append 到编辑区容器末尾 ,所以它天然稳定落在尾部。
在英语语境中, Sun 更多指那个巨大的发热天体;而 Sunshine 象征着"快乐、希望、温暖",形容人时听起来更亲切、更自然。
TUniquePtr 是虚幻引擎(Unreal Engine, UE)中的一个核心概念 。它是 UE 自行实现的智能指针库的一部分,专门用于独占式管理 非 UObject 对象的生命周期。
自动释放 :当 TUniquePtr 超出作用域或被重新赋值时,它所包含的对象会被自动删除并释放内存。
为什么 UE 不直接用 std::unique_ptr ?
虽然 C++ 标准库中有 std::unique_ptr ,但 UE 开发了自己的版本,原因主要包括:
- 跨平台兼容性:确保在所有目标平台(PC, 控制台, 移动端)上表现一致。
- 深度集成 :更好地适配 UE 的内存分配器和容器库(如
TArray,TMap)。
TUniquePtr 与 UObject 的关系
这是最容易混淆的一点:
- 非 UObject 专用 :
TUniquePtr主要用于管理原生 C++ 对象 (不带UCLASS宏的类)。 - 不能管理 UObject :
UObject受到 UE 自身的垃圾回收(GC)机制 管理。如果你尝试用TUniquePtr包装一个UObject,会导致引擎崩溃或引用计数的逻辑冲突。
除了 TUniquePtr ,UE 的 智能指针系统 还包括:
TSharedPtr:共享指针,允许多个指针指向同一对象(带引用计数)。TSharedRef:共享引用,类似于TSharedPtr但不能为空,安全性更高。TWeakPtr:弱指针,不增加引用计数,用于解决循环引用问题。
UE 官方强烈建议"尽可能优先使用 TSharedRef" ,但这主要是为了提升代码安全性
TSharedRef 永远不能为空 :它在初始化时必须绑定一个有效对象,且没有 IsValid() 方法。如果你尝试给它传空值,程序会直接崩溃(断言失败)。
TSharedPtr 可以为空 :它支持 nullptr ,你可以用它来表示"可能有、也可能没有"的对象。
TWeakObjectPtr :如果你想引用一个 UObject 但不想影响它的回收时机,就必须用 TWeakObjectPtr 。它常用于观察关卡中的 Actor 状态。
It's a "Smart" Observer (Safety)
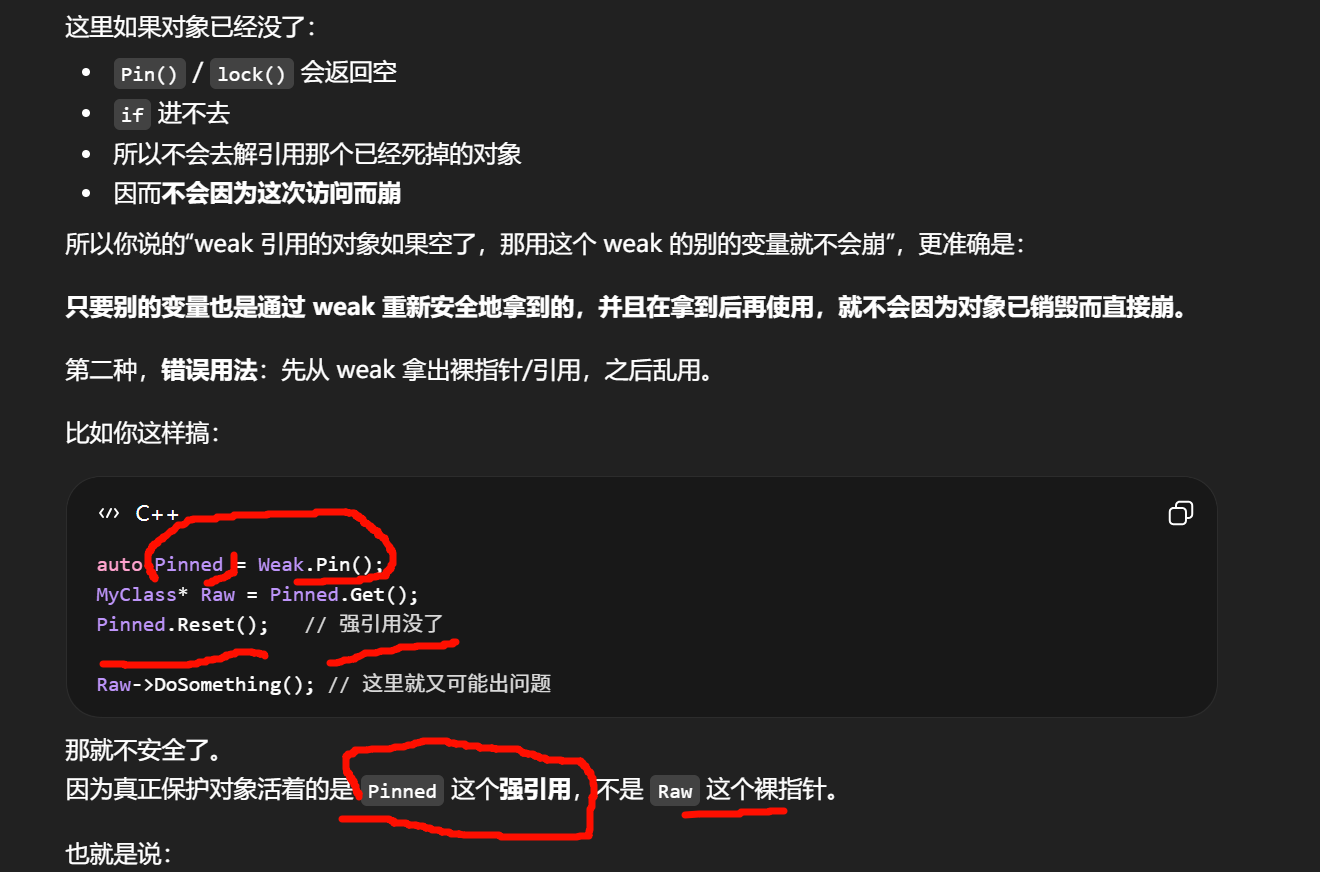
If you use a Raw Pointer (MyClass* ) to avoid a leak:
If B tries to use that pointer, the game crashes (Use-after-free).
TWeakPtrfix: It knows when the object is gone. You callPin(), it returnsnullptr, and your game keeps running.
"加一个空判断"并不能从根上拦住 use-after-free。
裸指针世界里,运行时根本不知道它是不是还合法。

Parsing headers for ZMDRenderEditor
对 ZMDRenderEditor 这个 target 的头文件做解析。
UnrealBuildTool、UnrealHeaderTool 这些工具本身是基于 .NET 跑的。
为了避免你电脑本地 .NET 版本不一致导致问题,UE 往往会直接带一套它自己认可的版本。
.NET Framework :这是 .NET 的早期版本,主要且仅能运行在 Windows 系统上。
.NET Core:这是为了实现跨平台而重新设计的开源版本,是现代 .NET 的前身。
.NET (5及以后版本):微软从 2020 年起删除了 "Core" 后缀,将两者合并,现在的 ".NET" 特指这个最新的跨平台通用平台。
C# 依赖 .NET 提供的 CLR(公共语言运行时)和类库来工作。
C# 编写代码,这些代码必须编译成中间语言 (IL)。程序在运行时,由 .NET 的 CLR 进行即时编译 (JIT) 转换成机器码并执行。
以前的 .NET Framework,还是现在的 .NET 5/6/7+,都包含垃圾回收、内存管理和异常处理等功能,C# 代码的这些运行管理全部依赖 CLR。
.NET 平台不只服务于 C#,它也支持 VB.NET、F# 等其他编程语言,但 C# 是其中最主流、最原生的一种。

裸指针本身只是一个地址值。
编译器只需要知道"这是个指向 FOpenCVState 的指针",不需要知道 FOpenCVState 里面到底有多少成员、占多少字节。
TUniquePtr<FOpenCVState>
隐含了所有权和析构责任。TUniquePtr<FOpenCVState> 自己析构时,delete Ptr;不是模板参数一出现就必须知道完整 layout,
而是 TUniquePtr<T> 的析构逻辑在这个点上要对 T 做 delete,于是要求 T 是完整类型。
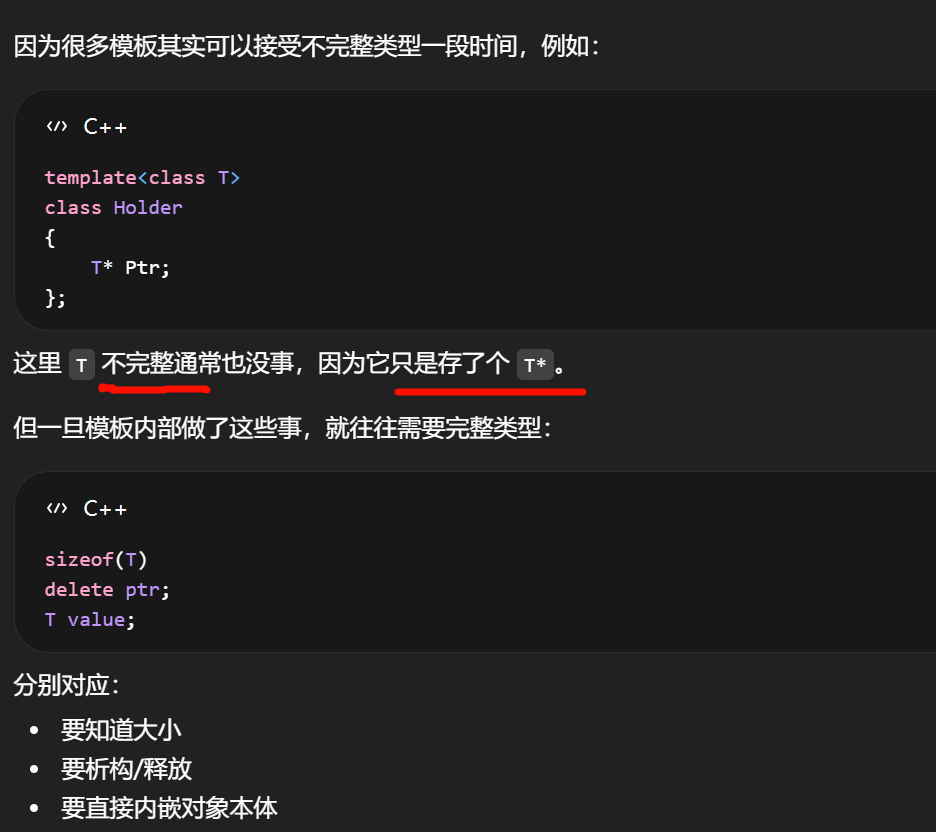
裸指针只需要知道"指向谁";
智能指针在析构点还需要知道"怎么把它正确销毁"。
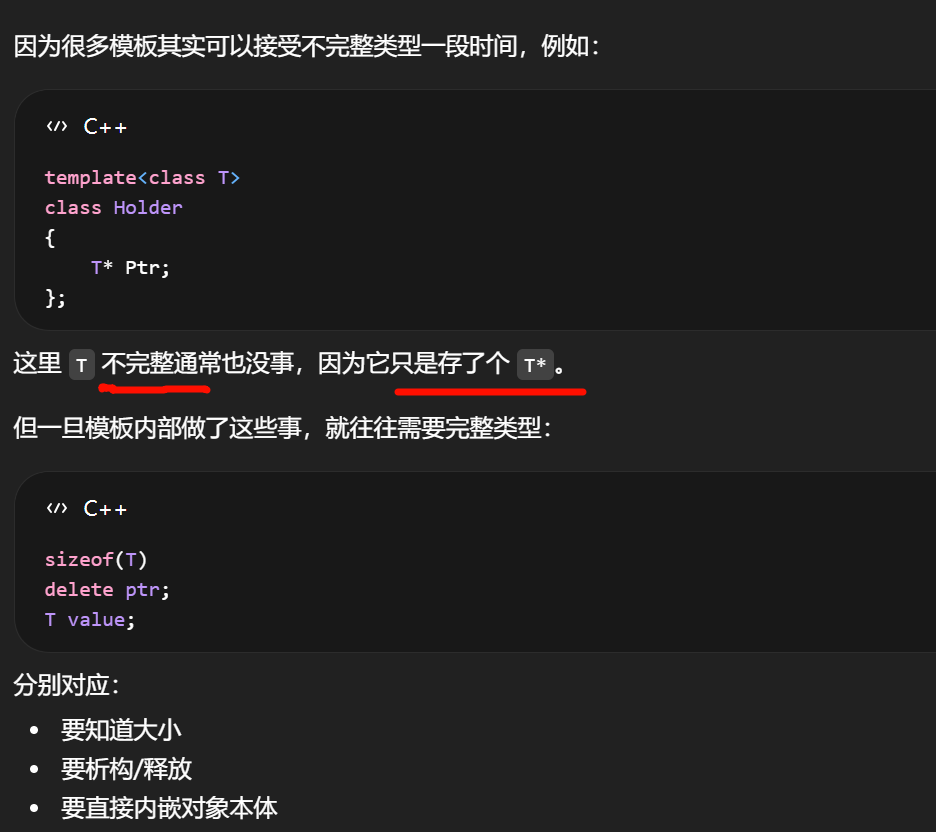

能声明在头文件里,但常常要求析构函数写到 cpp 里"。
Python 自带的 list 不是为数值计算设计的。
比如你有一百万个点坐标、像素值、矩阵元素,list 当然也能装,但它的问题是:
-
每个元素本质上是一个 Python 对象,开销大
-
循环计算通常靠 Python 解释器一项一项跑,慢
-
不天然适合线代、图像、张量这类"规则数组"
而 NumPy 的 ndarray 是"连续、同类型、面向数值"的内存块,更接近 C 数组。
所以它在做大规模数值运算时,速度和内存效率通常都比 list 好很多。
ONNX Runtime (ORT) is a high-performance, cross-platform engine for accelerating machine learning model inference and training .
ONNX 是一种模型交换格式,不是某个单独"推理库"。全称是 Open Neural Network Exchange。你可以把它理解成"神经网络的通用文件格式 / 中间表示",目的是把模型从 PyTorch、TensorFlow 等训练框架导出后,交给别的运行时去做推理
训练框架训练模型 → 导出成 .onnx → 用某个 runtime 跑推理。
真正执行推理的,常见是 ONNX Runtime,而不是 ONNX 本身。
Epic 的 NNE(Neural Network Engine)官方文档明确写了,UNNEModelData 在 cook 模型时就会处理诸如 .onnx 这样的文件格式;另外官方插件 NNERuntimeORT 也明确是一个基于 ONNX Runtime 的 runtime。也就是说,Unreal 不是把 ONNX 当野路子兼容,而是有官方插件和官方框架在接它。
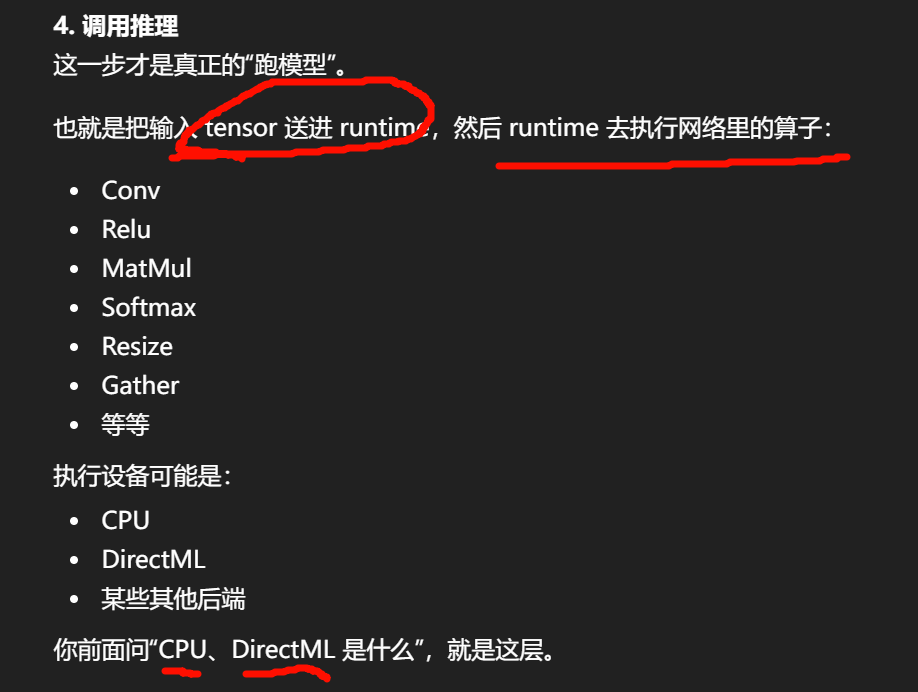
在 Unreal 进程里,把一个训练好的神经网络当成一个可调用的计算模块来执行。
UE 不只是画画面、跑逻辑、播动画,
它还把一份模型文件喂给某个推理后端,然后每帧或按需输入数据,拿回结果,再把结果用于游戏逻辑或画面表现。
UE 自己不是"直接理解所有模型数学细节"的那个东西,真正执行时通常要靠一个 runtime / backend。
具体执行可能走某个 runtime
加载后,UE 会得到一个"可执行模型实例"。
模型一般不能直接吃 UE 原始数据,要先整理成模型要求的 tensor。
例如:
-
把摄像头帧缩放到
224x224 -
BGR 转 RGB
-
uint8转float -
做归一化
-
按
[N, C, H, W]或[N, H, W, C]排列
这一步很关键。很多"模型跑不通"其实不是模型坏了,而是:
-
输入 shape 不对
-
通道顺序不对
-
数据类型不对
-
归一化不对

第一类,是"把 MetaHuman 角色放进工程"本身占的空间。
这个会占一些,而且往往不算特别小,因为 MetaHuman 不是一个简单模型,它通常带着:
材质与贴图
面部骨骼/控制相关资源
身体、头发、服装等资源
LOD、动画蓝图、控制 Rig 或相关依赖
实时流,不是 iPhone 那类偏离线深度捕获再后处理流程。实时链路更像是在传实时数据,重点是网络连通和 UE 端绑定,不是本地堆积大量录制文件。
手机上先把面部数据录下来,尤其是深度数据,
然后再把这份录制数据拿去驱动 MetaHuman / 做解算,
这叫 offline workflow。Epic 的文档里明确写的是:iOS 版 Live Link Face 支持"实时"或"基于深度数据的离线"工作流;而 Android 版页面写的是用于"实时生成动画",没有写 iOS 那种离线深度捕获能力。
而不是
先在手机里做一段高质量面捕录制,再把那段"深度面捕数据"拿回来后处理。
MetaHuman 在编辑器里跑起来,对显存、CPU、实时预览压力,通常比"磁盘再多占一点"更容易先成为问题。
MetaHuman Capture Source 官方 API 描述就是:它代表一个物理设备或档案,用来把素材导入编辑器,并在 MetaHuman Performance 里生成动画序列;这明显是偏 采集数据资产化/离线处理 的对象,不是你现在最短路径里必须先建的第一步。
这里不是 Content Browser 右键加资产,而是去 Live Link 面板 里加 source。Live Link 本身就是 UE 的实时流数据系统,Live Link Face Source 文档也明确说明它用于配置 source 和 subject 来做 realtime animation。
"电脑摄像头不一定更好",很多时候反而更差 。大量笔记本 webcam 的典型问题是:
分辨率低、动态范围差、弱光噪点重、镜头太广或太软、固定在屏幕上导致拍摄角度偏高,而且用户离镜头太远。面捕最怕的就是这些,因为嘴角、眼睑、法令纹附近的细节会直接影响解算质量。Epic 在 MetaHuman Video Source 的文档里甚至专门提到 webcam 可能会掉帧,需要看 Live Link subject properties 里的 dropping 指标。
你以前看到的那套 Live Link Face ,确实主要是手机导向,尤其 iPhone。
但现在如果你用的是 MetaHuman 相关工作流,UE 5.6/5.7 已经存在 webcam 实时面捕路径,不再是"只能手机"。
**Live Link 面板里看到你的 Android 设备 / subject。**subject 绑定到 MetaHuman。Live Link 面板在跳,但 MetaHuman 不动。
Live Link Face Source
是"实时流入口"。把手机表情数据送进 UE。官方文档专门就是拿它做实时动画的。
Capture Source(离线)
是"采集数据来源资产"。更接近 Capture Manager / Animator 工作流里的输入源描述。
-
PyTorch 常见
.pt、.pth -
TensorFlow 常见 SavedModel、
.pb -
Keras 常见
.h5 -
scikit-learn、XGBoost 也有各自序列化方式
-
还有很多厂商/推理引擎自己的专用格式
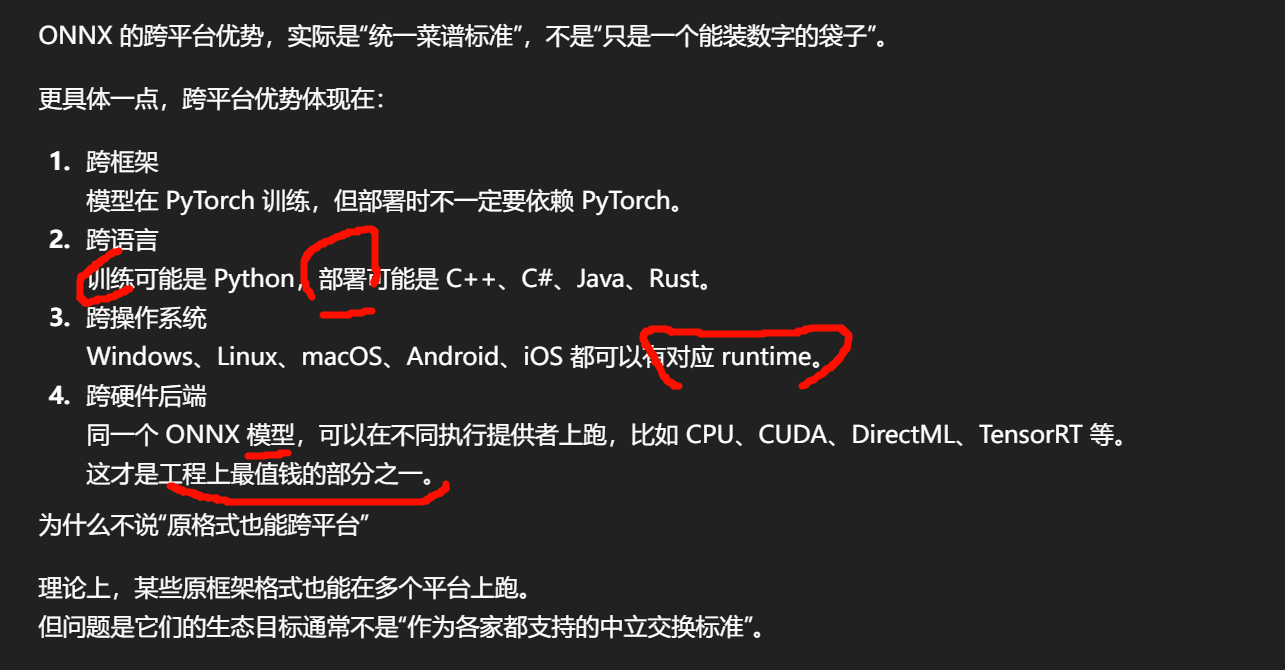
训练结果可以有很多种格式,ONNX 只是其中一种,而且是偏"通用交换格式"的一种。
原框架格式通常和原框架绑定得很深。
比如你在 PyTorch 里训练出一个模型,最自然的做法就是继续用 PyTorch 去推理。
但如果你的部署目标是:
-
Windows 桌面程序
-
Android/iOS
-
UE/Unity 插件
-
C++ 服务端
-
GPU/NPU/加速卡
-
浏览器 / WebAssembly
-
边缘设备
这时问题就来了:目标环境未必适合把整套训练框架搬过去。
-
体积大
-
依赖复杂
-
启动慢
-
对目标平台支持不一致
-
对某些硬件优化不够
-
C++/游戏引擎里集成麻烦
所以很多时候,训练框架负责"产出模型",部署/runtime 负责"高效执行模型"。
ONNX 本质上是一个中间标准。
意思是:
"我不管你最早在 PyTorch、TensorFlow 还是别的框架里训练,我先把模型导出成一个统一规范,然后交给支持 ONNX 的推理引擎去跑。"
训练框架 → 导出成 ONNX → 用 ONNX Runtime / TensorRT / OpenVINO / 其他后端部署
所以 ONNX 的定位不是"最适合训练",而是"适合交换、部署、推理"。
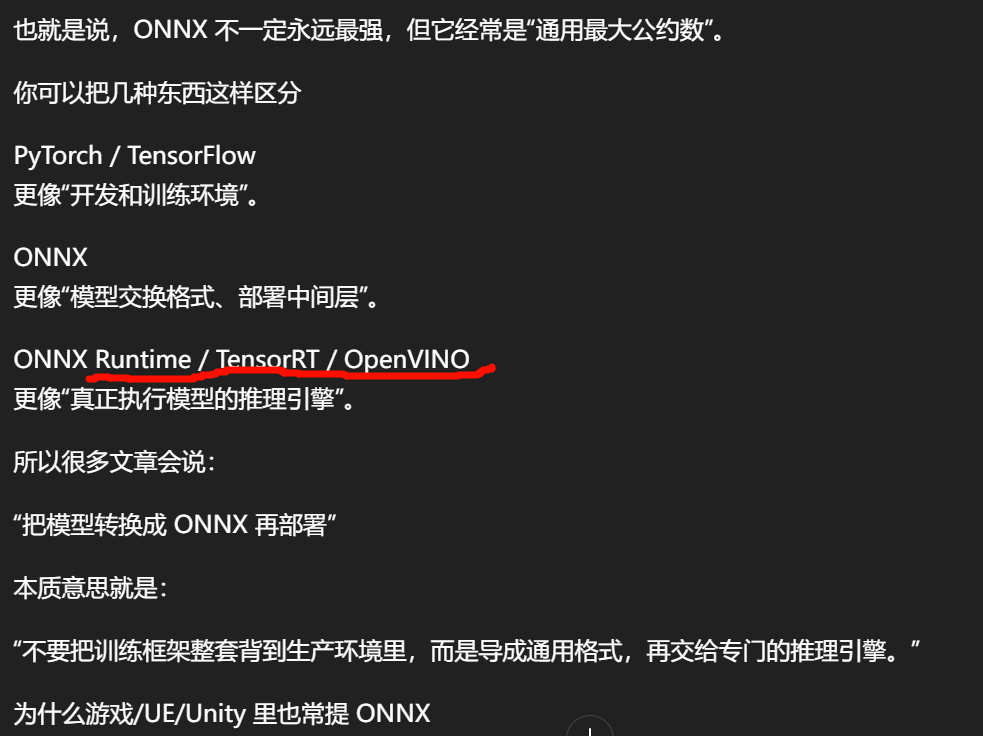
游戏/UE/Unity 里也常提 ONNX
轻量集成
C++ 接口
容易接入 GPU/NPU 加速
UE 里做人脸、姿态、分类、分割、语音之类功能,很多时候并不想把 Python + PyTorch 整套塞进项目里。
这时 ONNX + ONNX Runtime 就很自然。
MetaHuman Performance
是"把采集到的 footage / capture data 解算成动画序列"的资产,不是实时预览的第一步。官方 API 描述里就写了,它是从 Capture Source 的视频素材追踪出动画序列。
MetaHuman Identity
是"表演者数字身份/拟合身份"的资产,主要用于 Animator 的解算链路,不是你现在只想让手机实时驱动 MetaHuman 时必须先做的第一步。MetaHuman Performance 的官方描述里也明确提到它依赖 Identity。
;Fab 上也有越来越多的 MetaHuman collections。
UE 5.6 起最新版 MetaHuman Creator 直接在 Unreal Engine 内使用,不再以"新用户走旧网页应用"为主。
https://dev.epicgames.com/documentation/metahuman/metahumans-on-fab?
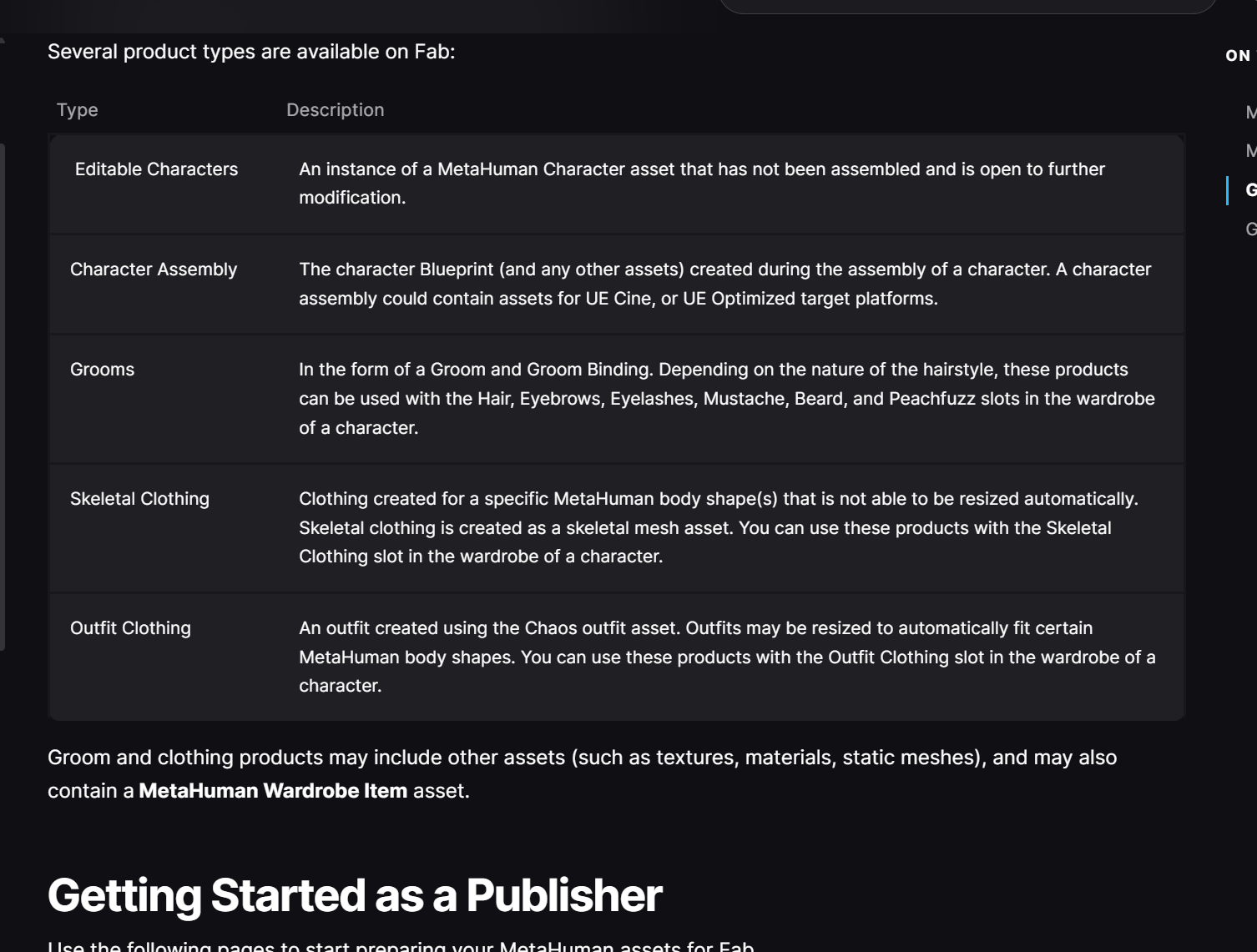
MetaHuman format (.mhpkg).
for DCC 的,本质上不是"现成可直接放进 UE 里玩的角色资产",而是给 外部数字内容制作软件 用的配套工具。DCC 就是 Digital Content Creation ,典型就是 Maya、Houdini、Blender 这类建模/绑定/毛发/动画软件。
一组 Maya 工具,用来编辑 MetaHuman 的某些部分,比如面部、身体次级形变、以及相关数据处理,不是一个"直接下载完整角色就能免 rig 使用"的角色包。通常它依赖从 UE 里的 MetaHuman 角色通过 DCC Export 导出的数据来继续编辑。
for Maya = 你已经有 MetaHuman 了,现在要进 Maya 做深加工 。常见用途是:
改表情/脸部数据、做身体的二级变形、调整某些绑定相关内容。官方也单独提供了 Maya 的 Pose Editor 这类工具来做身体次级变形。
for Houdini 更偏程序化流程、毛发流程、组装流程。如果你是想做发型、胡子、复杂 groom,Houdini 这条线更相关。官方还有专门的 Groom Starter Kit / Advanced Kit / Exporter 文档。
Assembly 在官方定义里就是"把你的角色构建成可在项目里使用的资产"的过程;而 UE 5.7 的 Blueprint API 里甚至直接有 Build MetaHuman 这样的装配入口,目标就是 MetaHuman Character Editor,这说明 assembly 现在本身就是 UE 内的一段资产构建流程,而不是单纯云端网页操作。
能不能把它当资源迁移到别的项目?
原则上可以 ,但要用 UE 的 Migrate ,不要只靠资源管理器手拷一个 .uasset。官方对 Migrate 的定义很明确:它会复制所选资产,连同它的 references 和 dependencies 一起复制 到另一个项目;Sources Panel 里对 Migrate 的说明也是"复制该资源及其依赖到另一个项目的 Content 文件夹"。这意味着,MetaHuman Character 作为一个 uasset 可以参与项目间迁移,但前提是把依赖一起带走。
按目前官方文档看,不会被 uasset 取代,因为两者用途不同 。.uasset 是 UE 项目里的原生资产形态;.mhpkg 是 MetaHuman Manager 用来验证并打包、上传到 Fab 的分发格式 。Epic 明确写了:MetaHuman Manager 会生成 .mhpkg;而在新的 MetaHuman 格式下,Fab 只接受来自 MetaHuman Manager 的 .mhpkg 文件来上架。
项目内编辑/迁移:看 uasset
对外发布/上架 Fab:看 .mhpkg
官方流程里,webcam 方法也属于 Live Link 体系 ,但不是传统意义上"手机 Live Link Face 那一条老路"的唯一入口了。MetaHuman 的实时驱动文档明确写了:实时动画可以来自 mono camera(包括 webcam) 、支持的移动设备,或者音频源;并且这些 MetaHuman Live Link sources 可以在 Unreal 的 Live Link 面板里创建,也可以在 Live Link Hub 里创建。
Live Link 里生成 Source 和 Subject。你要理解成:
-
Source = 数据从哪里来(webcam / 手机 / 音频)
-
Subject = Unreal 里可被角色消费的那路动画数据
官方文档就是按 "create source and subject" 这个模型来描述 MetaHuman 实时驱动的。
不要把"webcam 面捕"简单理解成"电脑版 Live Link Face app"。更准确地说,它仍然是 Live Link 管线,但源类型不是同一个东西。
填手机 IP + Port,然后点 Connect,这一步叫"连接 Source(源)"。
把数据源接进 Live Link Client 。Live Link 官方定义里,Source 是数据来源/连接本身 ,Subject 是这个 Source 提供出来的一条具体数据流。
Source 连上后,Live Link 才会出现对应 Subject。
然后你在角色蓝图或动画蓝图里选这个 Subject,
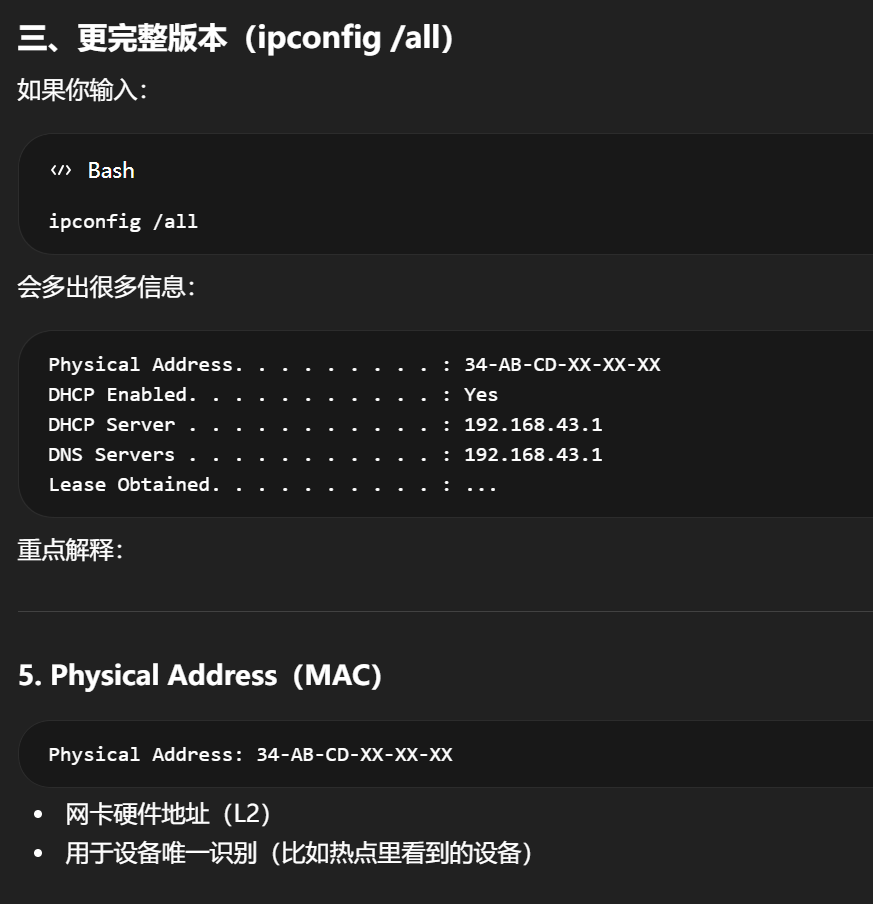
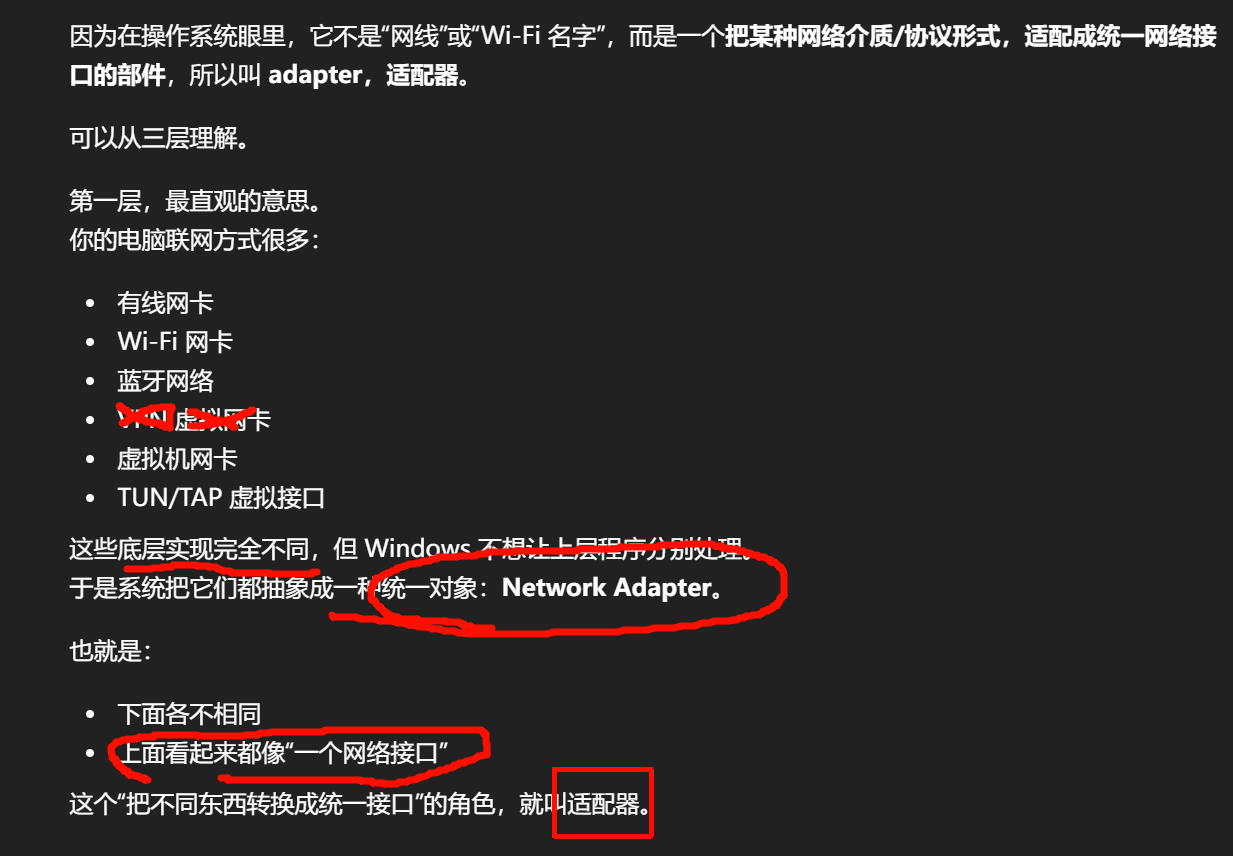
ipconfig 里会看到:
-
Ethernet adapter -
Wireless LAN adapter Wi-Fi
很多根本不是实体硬件卡,而是:
-
驱动创建的虚拟接口
-
软件层模拟出来的网络出口
-
协议封装器
这时候叫"网卡"就不准确了。
叫"适配器"更合理,因为它强调的是:
它向系统提供了一个可用的网络接入接口,不管背后是硬件还是真虚拟。

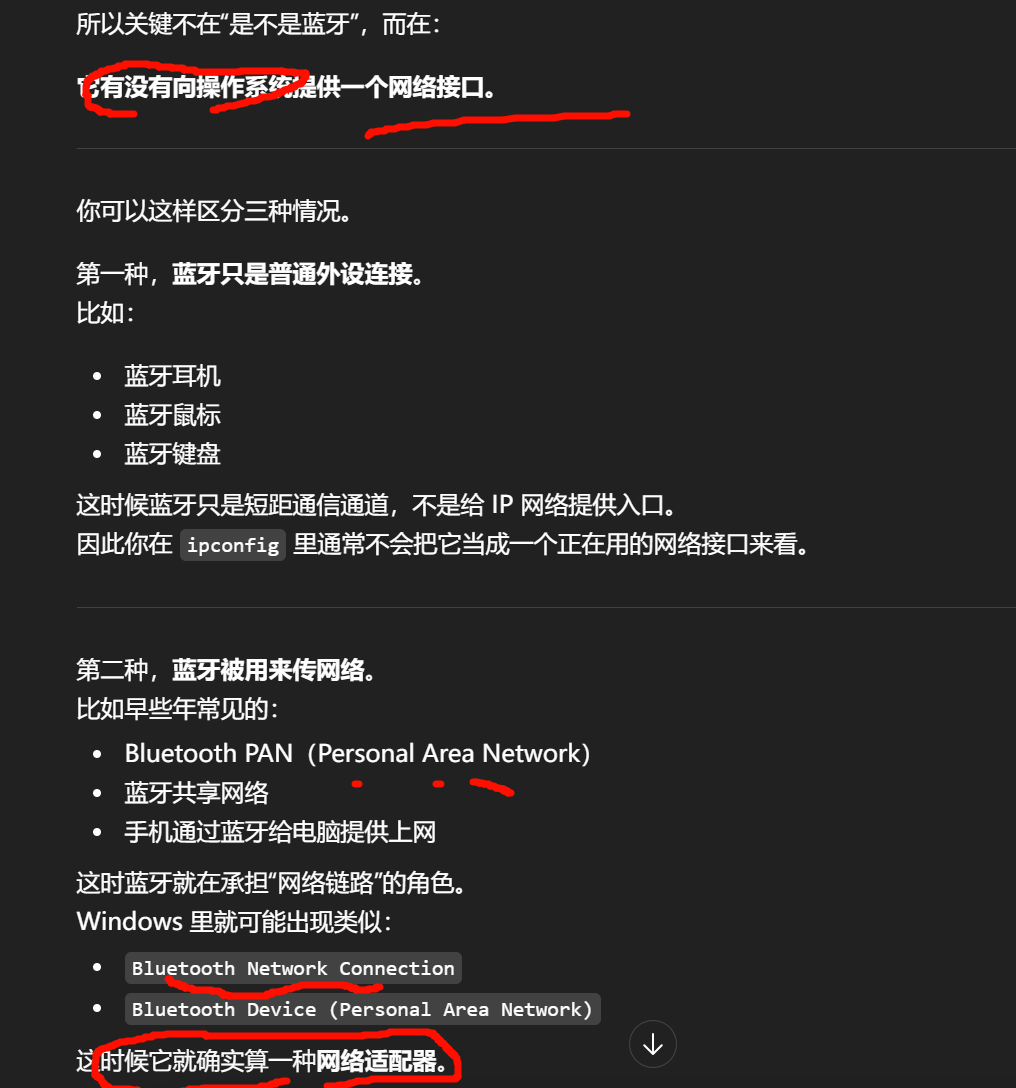
"无线局域网 adapter"不等于"热点"。
无线局域网适配器(Wireless LAN adapter) 是你电脑或手机里的 Wi-Fi 网络接口。
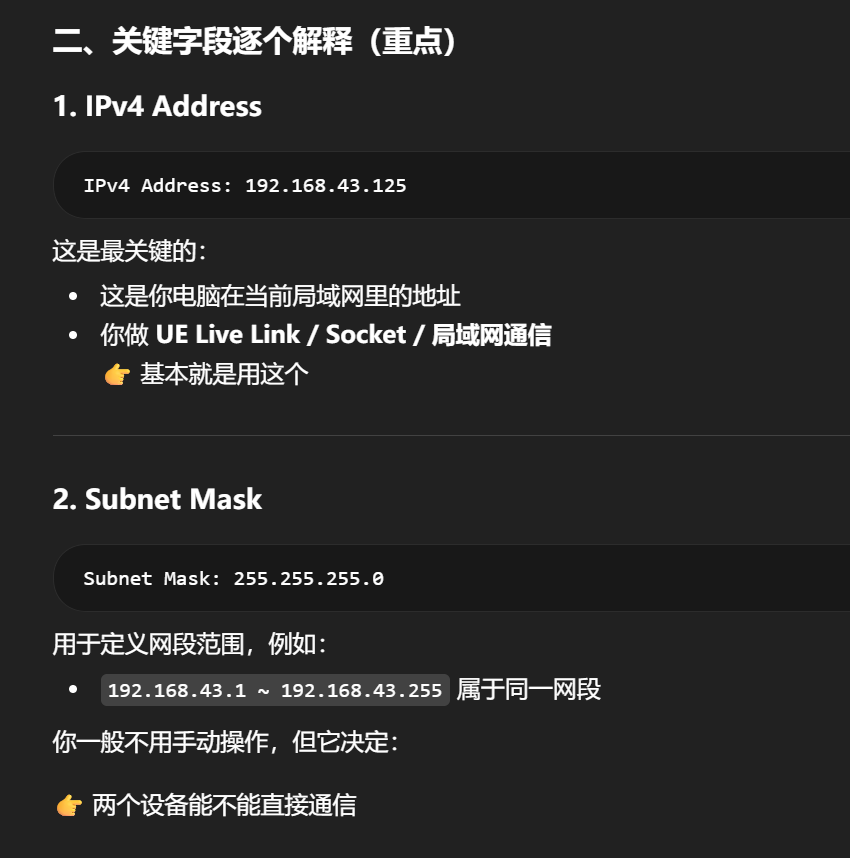
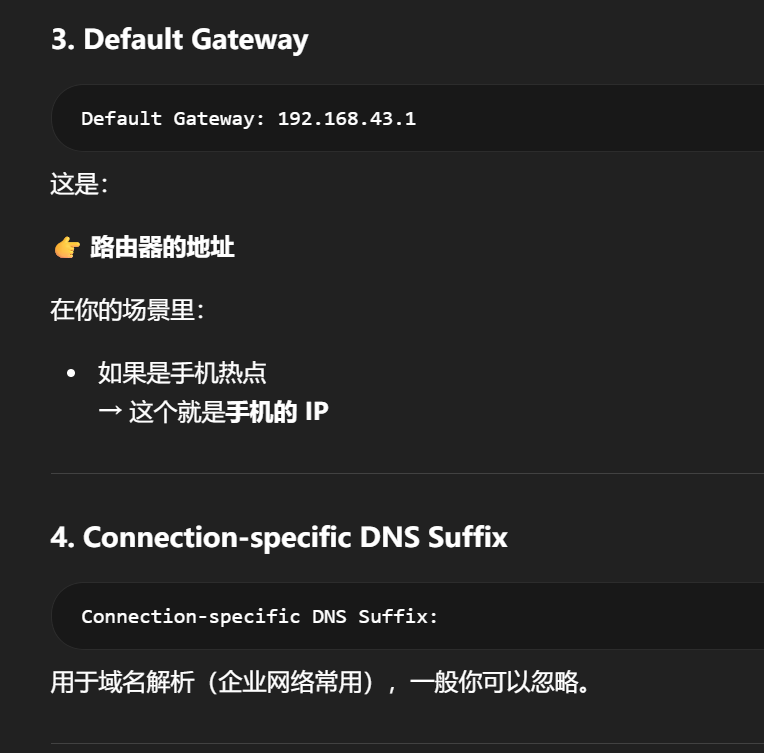
Default Gateway 的含义是:这张接口把"去别的网段/外网的流量"交给谁。
它描述的是路由出口,不是单独用来标记"发出端/接收端"。
-
有 Default Gateway:通常说明这张网卡正在把某个设备当作上游路由器
-
没有 Default Gateway:通常说明这张网卡不是当前默认出网口,或者它所在网络根本不需要再往上交
"电脑连接手机热点"这个场景里:
-
默认网关 往往就是 手机在这个热点局域网里的地址
-
也就是手机作为这个小局域网的"路由器"
所以你会常看到这种结构:
手机热点: 192.168.82.11
电脑: 192.168.82.49
默认网关: 192.168.82.11
这里:
-
电脑自己的局域网地址:
192.168.82.49 -
手机给自己的热点接口分配的地址:
192.168.82.11 -
电脑看到的默认网关:也是
192.168.82.11
手机既是热点提供者,也是这个局域网里的网关。
为什么会这样?
因为默认网关本来就是"本机要出这个局域网时,先把包交给谁"。
而在手机热点场景里,电脑要出网只能先交给手机,所以手机自然就是网关。
app 里的连接/目标地址设置页,把 电脑当前所在局域网 IP 填进去。
当电脑连接手机热点时:
-
手机会充当路由器 / 网关
-
手机自己有一个热点局域网地址
-
电脑会被手机分配另一个局域网 IPv4 地址
所以通常是:
-
手机 IP :例如
192.168.43.1 -
电脑 IP :例如
192.168.43.72
它们在同一个网段 ,但不是同一个地址。
电脑上看 ipconfig 时,常见对应关系是:
-
IPv4 地址 = 电脑自己的地址
-
默认网关 = 手机热点的地址
手机一边用蜂窝数据上网
一边自己开一个 Wi-Fi 热点给电脑接入
这两个不是一回事。
所以即使手机没有连任何外部 Wi-Fi,只用 SIM 卡流量,它仍然会给热点分配一个本地网段,比如:
192.168.82.11
或
192.168.43.1
这就是你要找的那个"手机 IP"。
你说的是"像镜子一样的屏幕里向右",这本质是监看需求。
如果你去反 Yaw 数据,那么:
你录到的角色动作也会真的变成反向,
不是"显示像镜子",而是"动画本身被改了"。
现在的热点分享无需同时打开WLAN,主要是因为手机硬件(芯片)能力提升,实现了双频Wi-Fi技术(Wi-Fi Bridge) ,热点创建与接入不再冲突。此外,蓝牙、蜂窝数据网络等多种连接方式的成熟,使得热点分享不再单一依赖WLAN芯片,提高了分享效率和便捷性。
早期的手机Wi-Fi芯片功能单一,只能"连接"或"发出"信号,因此开热点需先关闭Wi-Fi(即WLAN)。现代芯片支持同时进行无线信号的接收和发送,即把手机当作一个路由器使用,实现Wi-Fi信号桥接
蜂窝数据直接热点 :开启热点主要目的是分享蜂窝数据(4G/5G),而不是WiFi网络,现代系统已优化vivo官网 和HONOR 所示的移动网络共享流程,
Android的话连Wi-Fi的同时是开热点的情况下热点的网络流量会走热点机连上的Wi-Fi。类似于路由器无线中继的效果(多一层NAT转换)
虽然实时编译很强大,但它主要适用于修改 .cpp 文件中的函数体 。以下情况通常无法通过实时编译生效,建议关闭编辑器重新编译:
- 修改头文件 :例如在
UCLASS中新增UPROPERTY或UFUNCTION。 - 更改构造函数:修改构造函数中的初始化逻辑。
Live Coding :使用 Live++ 技术,通过打补丁的方式更新二进制文件,通常比旧版的热重载更稳定,不会产生 REHOTRELOADED 类名污染的问题。
UE 的构建工具 UnrealBuildTool 检测到你的项目是一个 Git 仓库,于是它去调用系统里的 git status,判断哪些文件改过,用来辅助 adaptive non-unity build 的工作集分析。也就是根据改动文件,决定更合理的编译范围。
-
A Source/ZMDRender/SimpleRotatingCube.cpp说明这个文件已经
git add了 -
AM Source/ZMDRender/ZMDRender.Build.cs说明你 add 之后又继续改了
-
?? Source/ZMDRender/MirrorCaptureDisplayActor.cpp说明这个文件还没被 Git 跟踪
它当时不是在严格读取这个类的真实接口,而是在拿 UE 里"常见 UMG / UserWidget 使用习惯"去套。
SetZOrderInViewport 不是所有 widget 类都能这么直接用
你的这个类里,实际 ZOrder 可能是通过 AddToViewport 传入,或者在你自定义逻辑里由 UUserWidget 外层控制
也就是说,它把"常见模式"误当成"当前类一定支持的模式"
写了 WidgetClassToUse 的 fallback,但用的是接近普通 C++ 的写法,而 Unreal 这里实际是 TSubclassOf<UUserWidget>,不是裸 UClass*。
很多 AI 写 UE 代码时,表面上像 C++,但它脑子里其实还是"泛 C++ + 一点 UE 词汇",没有真正进入 Unreal 的类型规则。
draft 是从 Unreal UI patterns 的概念层写出来的,但没有针对你项目中的具体类型做严格验证。
TSubclassOf、TObjectPtr、TWeakObjectPtr 这些 UE 包装类型
UMG / Slate / Widget API,因为版本和类层级差异大
Actor / Component / Widget 的生命周期函数调用点
任何"看起来像 UE 里应该有"的函数名,比如 SetXXXInViewport、RefreshBrush、UpdateLayout 这种最容易被它脑补
viewport
指的是这个 Widget 怎么被放到屏幕显示层里,以及放进去之后的显示布局控制。通常包括:
-
什么时候
AddToViewport() -
什么时候移除
-
显示在屏幕哪个位置
-
尺寸多大
-
对齐方式是什么
-
是否全屏、是否铺满、是否跟随某个规则更新