最左前缀原则是指使用联合索引的时候 查询条件也where必须从索引的最左列开始匹配
比如建立了联合索引abc 查询条件一般都是通过 where a=... and where b = ... 但是如果使用了 where b = ... 此时联合索引就会失效 因为索引的建立是先基于a进行排序的 在a的基础上在建立b的排序以此类推
数据库的脏读 在读未提交的隔离级别下会出现 通常是指一个事务读取到了另一个事务没有提交的数据
不可重复读 在读已提交的隔离级别下会出现 通常是指一个事务读取到了另一个事务提交到的数据
一个事务两次的同一查询条件下查询结果不同
幻读 在可重复读的隔离级别下会出现 通常是指一个事务内执行了两次相同范围查询的但是返回的行数不同 如果一直使用快照读不会出现幻读 一般都是使用了当前读才导致了幻读
对于脏读来说 MVCC天然解决脏读问题 通过快照读能够避免读取到未提交的数据
对于不可重复读来说 可重复读隔离级别下每次通过同一个readview快照保证每次读取的数据相同
对于幻读来说 如果一直使用快照读天然就不会有幻读问题 如果说使用当前读需要配合间隙锁锁住范围 别的事务插入不进来
常见的MySQL存储引擎分为
InnoDB MySQL5.5后默认的引擎 支持事务 行级锁 外键 MVCC
MyISAM 不支持事务 只有表级锁 没有外键 没有MVCC
MEMORY 存储在内存当中 有较高的访问速度 但是没有崩溃恢复等
二级索引中包含了所需要查询的全部字段 直接从耳机索引中获取数据即可 减少了磁盘IO提升效率
我们通Explain执行计划中 的Extra字段判断是否需要回表 Using index 标识索引覆盖了 Using index condition标识索引下推
数据结构上 分为B+树索引 哈希索引 全文索引 空间索引
从存储方式上 聚集索引 比如主键索引 叶子节点存储完整的行数据 叶子节点上存储的就是该行数据
非聚集索引 叶子节点只存储索引值和主键值 如果索引没有包含全部的查找字段需要拿到主键去聚集索引中在查一遍 获取该行的全部数据
索引下推是MySQL的优化技术 主要用来减少回表次数 具体而然 如果我们有个联合索引 abc 如果where条件中 a是正常的 但是b和c都进行了左模糊匹配 那么如果没有索引下推bc都无法走索引只能根据a索引来筛选 然后回表 由server层来进行筛选 但是有了索引下推我们就可以通过a索引筛选过后引擎层直接根据条件过滤关于b和c的数据 不符合条件的就无需回表了
|----------------------------------------------------------------------------------------------------------------------------------------------------------|
| MySQL InnoDB 引擎中的聚簇索引和非聚簇索引有什么区别? |
聚集索引 就是索引值和该行的数据存储到一起
非聚集索引 叶子节点只索引值和对应的id
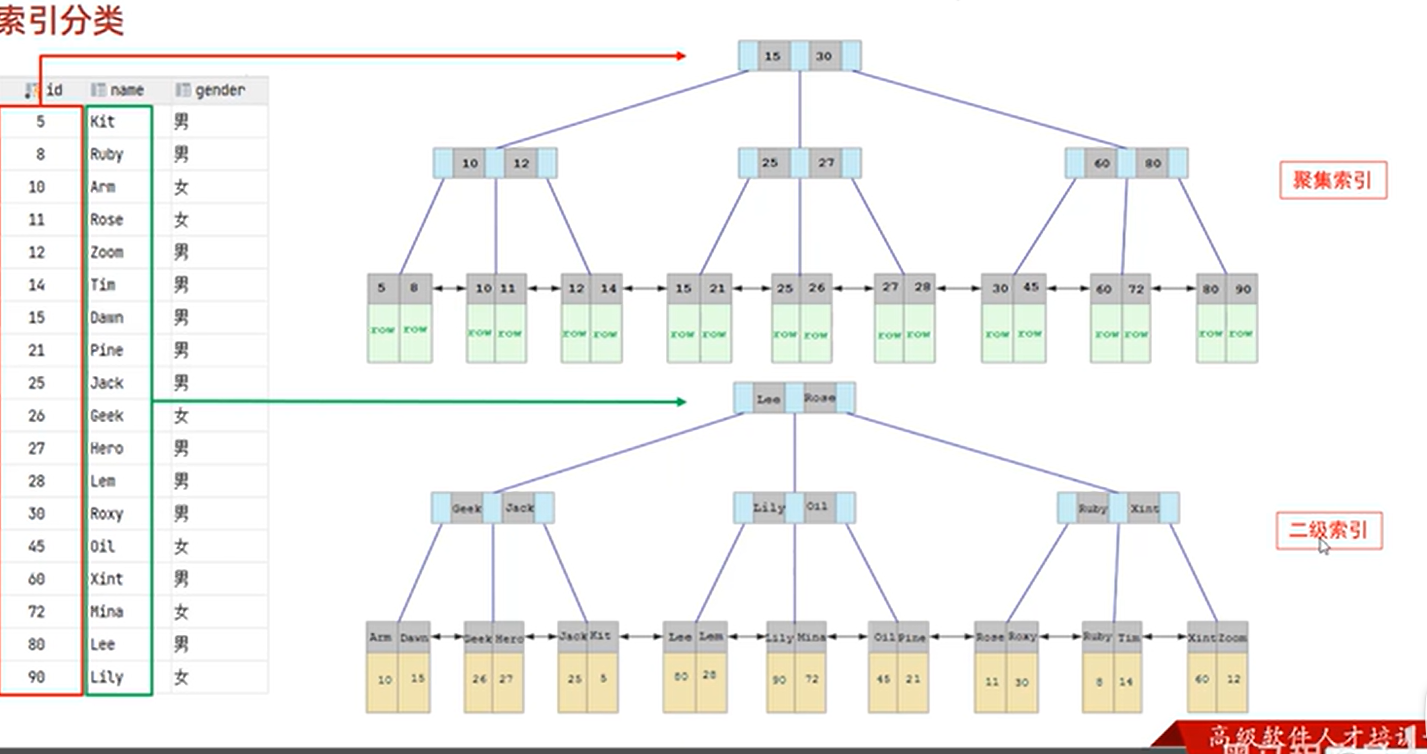
二级索引中没有包含所需要查询的全部字段 需要从二级索引中获取到id 再在一级索引中查询列表
|--------------------------------------------------------------------------------------------------------------------------------------------|
| MySQL 中使用索引一定有效吗?如何排查索引效果? |
索引不一定有效 可以通过explain判断执行计划判断索引效果
对于索引失效来说 可能有以下几种情况
不符合最左前缀原则 进行了左模糊查询 对索引做了运算 对索引进行了类型转换 sql优化器发现走索引加回表还不如全表扫描
explain常见的字段如下
对于 type来说 const标识通过主键索引或者唯一索引等值查询 eq_ref 表示多表连接查询是浅表的每一行都和后表的主键或唯一索引匹配到且仅匹配一行
ref是 使用非唯一索引的等值查询 或 联合索引的最左前缀匹配 会返回匹配的多行记录
range 使用索引进行范围查询
index 遍历整个索引树来获取数据 比如一张表有三个字段 id主键 f1 f2 我们建立了f1 f2联合索引如果where条件是f2 此时索引失效 但是通过explain看的话 发现key依旧有值用到了联合索引 但是type就是index也就是代表此时是扫描了全部索引 对于Extra来说此时是Using index因为走了覆盖索引
all 全表扫描
除此之外 通过key判断使用的索引名称 通过rows 预估扫描的行数 通过extra判断
值得一提的就是对于联合索引abc来说 SELECT * FROM t WHERE a = 1 ORDER BY c;
|--------------------------------|----------------------|-------------------------------------|
| WHERE a=1 ORDER BY b | Using where | 完美利用索引排序 (a固定,数据天然按b排好序了) |
| WHERE a=1 AND b=2 ORDER BY c | Using where | 完美利用索引排序 (a,b固定,数据天然按c排好序了) |
| WHERE a=1 ORDER BY c | Using filesort | 排序失效 (中间断了 b,c 的排序是乱的) |
| WHERE a>1 ORDER BY a, c | Using filesort | 排序失效 (a是范围查询,后续列c无法利用索引排序) |
并不是索引存储多了的话 每次进行插入更改和 删除操作的时候都需要同步更新索引
|----------------------------------------------------------------------------------------------------------------------------------------------|
| 请详细描述 MySQL 的 B+ 树中查询数据的全过程 |
第一阶段 从根节点开始把查询的键值和节点存储的索引进行比较 通过二分法确定落在哪个区间顺着指针找到子节点 一直到达叶子节点
第二节点是 页内查找 叶子节点是一个16KB的数据页 里面会存储多条记录 InnoDB通过页目录加速查找 页目录将记录分成若干个组 每个槽记录每个组的最大值 通过二分法定位到所在的组 然后通过组内的单向链表遍历找到目标记录
|--------------------------------------------------------------------------------------------------------------------------------------------|
| 为什么 MySQL 选择使用 B+ 树作为索引结构? |
B+树能够保证查找数据的时候减少IO的次数 对于hash数据结构来说 虽然查询速度快 但是不能范围查询 对于二叉树来说 递增条件下会退化为链表 对于AVL树来说 红黑树来说 数据量过多的话会导致多次IO 对性能有损失 其次就是需要存储的数据较多 还有就是每次插入删除都需要维护数据结构较为麻烦
B+树是多叉树 每个节点上可以存储多个元素 并且叶子节点不存储数据只存储key和指针 相同的层级下B+树能够存储更多的数据
大概2000万 对于一个页来说默认是16KB 除了叶子节点外每个节点都会存储key和指针 对于bigint来说八个字节也就是key八字节 对于指针来说指针是7个字节 16 * 1024 / 14 约等于1170个
假设每条记录栈1KB一个叶子节点能存储16条 1170 * 1170 * 16 约等于2000万条
|------------------------------------------------------------------------------------------------------------------------------------------------|
| 详细描述一条 SQL 语句在 MySQL 中的执行过程。 |
客户端和MySQL建立连接进行TCP握手和 权限校验
然后分词器会对SQL做词法分析和语法解析 识别SELECT 表名 列名 WHERE条件这些元素等 通过语法规则判断是否有语法错误
优化器拿到语法树过后 决定使用按个索引 多表join的时候该使用哪一张表 生成执行计划
然后执行器按照计划执行 调用存储引擎结构一行一行读取数据
|----------------------------------------------------------------------------------------------------------------------|
| MySQL 是如何实现事务的? |
MySQL通过RedoLog UndoLog 锁 和MVCC来保证事务
持久性 有redolog 来保证每次修改事务提交的时候修改会先写到redolog中 然后刷盘 后续如果mysql宕机了 重启后加载redolog就能恢复数据
原子性 通过undolog日志来保证 每次修改bufferpool的值之前就将原本的值存入遇到undo log中 事务回滚的时候按照undolog版本链将数据恢复即可
隔离性 MVCC和锁机制保证隔离性 读取的时候通过创建快照读到undo log版本连中找到自己该看到的数据版本
一致性 由持久性 原子性 隔离性共同作用的结果
|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 为什么 Java 8 移除了永久代(PermGen)并引入了元空间(Metaspace)? |
永久代在启动的时候就定死了 比较难调整
永久代归堆管 但是内部存储的时类元信息等这种不需要背回收的东西 一旦满了触发fullgc但是有没有什么东习好回收
InnoDB层和server层都有自己的数据记录日志 binglog和redolog 那如何保证这两个日志一致呢 这里采用了两阶段提交
对于第一阶段也就是prepare阶段 将redolog状态标记为prepare
对于第二阶段 也就是commit阶段 将binglog提交 然后将redolog状态标记和commit
为什么要这么做呢 我们先来说说mysql宕机后重启具体发生了什么 重启时会执行Redolong扫描恢复 这个阶段会根据日志头的type字段判断这个事务时prepare还是commit 如果时prepare那么就会去binglong查找是否由相应记录 prepare阶段数据库宕机 那么重启过后要么redolog没有打上标记 要么redolog是prepare标记 那么回去binglog查询是否由相应记录如果有的话 说明事务提交失败此时进行数据回滚
如果说在commit阶段数据库宕机了 发现redolog为prepare给并且binglog由相应记录 事务提交
|--------------------------------------------------------------------------------------------------------------------------------|
| MySQL 中长事务可能会导致哪些问题? |
锁竞争严重 容易引发连锁反应 当事务持有锁的时间越长其他事务等待的时间越久 业务线程被阻塞过后连接池可能会被占满 上游服务器可能超时可能会引发雪崩
undolog日志膨胀 InnoDBMVCC机制需要保留事务开始的数据版本一旦不提交的话会导致版本链越来越长并且无法清理
死锁的概率也会增加 事务执行时间越长 持有的锁越多和可能其他事务循环等待锁的释放
MVCC又称多版本并发控制核心思想时让读写操作互不阻塞
|----------------------------------------------------------------------------------------------------------------------------|
| MySQL 中的事务隔离级别有哪些? |
|--------------------------------------------------------------------------------------------------------------------------------------------------|
| MySQL 默认的事务隔离级别是什么?为什么选择这个级别? |
|--------------------------------------------------------------------------------------------------------------------|
| MySQL 中有哪些锁类型? |
|--------------------------------------------------------------------------------------------------------------------------------|
| MySQL 中如果发生死锁应该如何解决? |
|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| MySQL 中 count(*)、count(1) 和 count(字段名) 有什么区别? |
|------------------------------------------------------------------------------------------------------------------------------|
| MySQL 中如何进行 SQL 调优? |
|----------------------------------------------------------------------------------------------------------------------------------------------------|
| 如何使用 MySQL 的 EXPLAIN 语句进行查询分析? |
|------------------------------------------------------------------------------------------------------------------------------|
| MySQL 中如何解决深度分页的问题? |