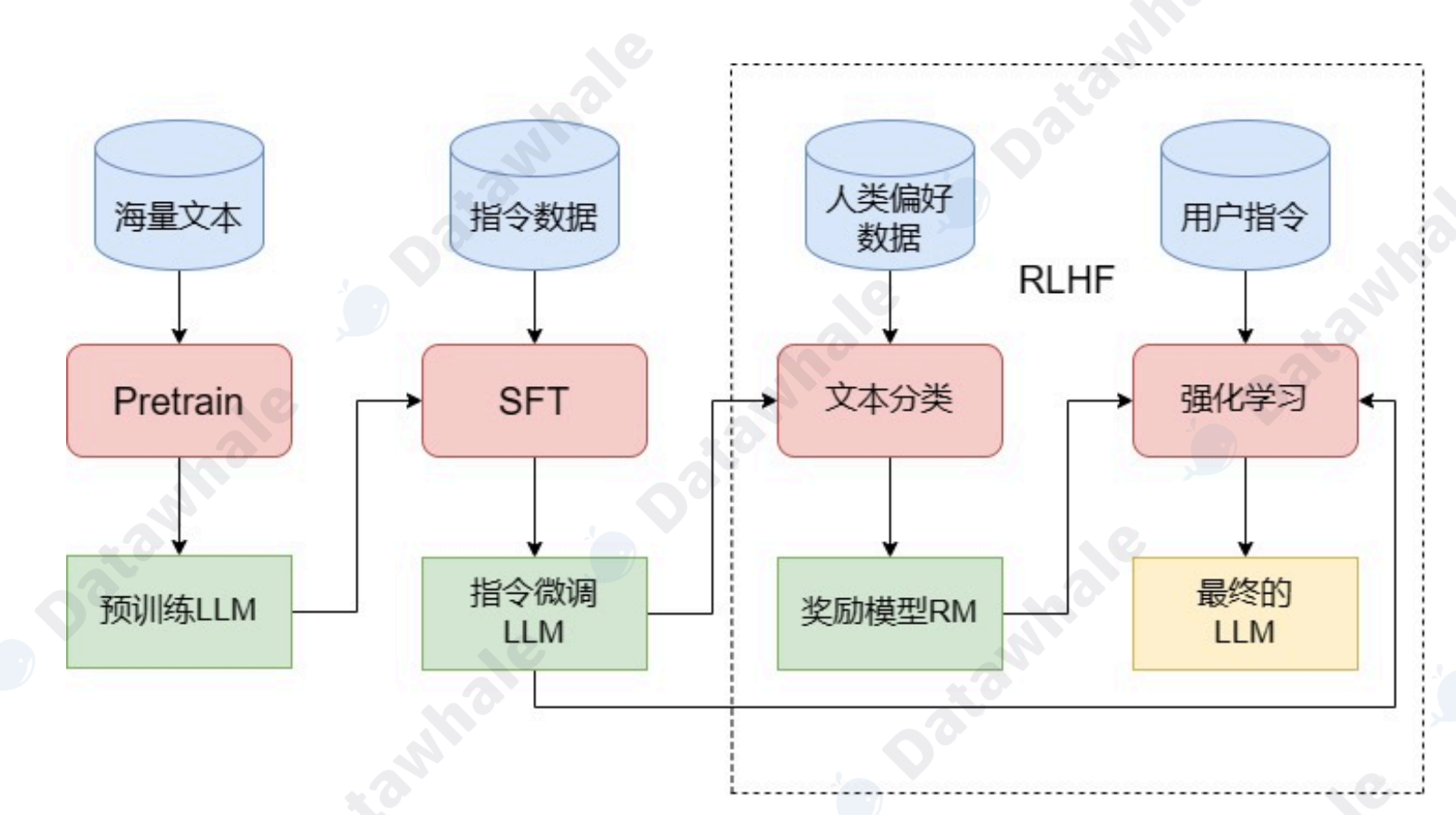
如何训练一个LLM
数据准备
高质量数据是训练LLM的基础。
Pretrain阶段需要海量文本数据,通常来自公开数据集如Common Crawl、Wikipedia、BooksCorpus等。数据需经过清洗、去重、过滤有害内容等预处理步骤。
SFT阶段需要人工标注的高质量对话或指令数据。数据规模较小但质量要求极高,通常由专业人员编写或筛选。
RLHF阶段需要人类反馈数据,包括排序或评分形式的偏好标注。
Pretrain训练
Pretrain采用自监督学习,通过预测下一个词的任务训练模型。使用Transformer架构,在分布式计算集群上运行。关键参数包括batch size、learning rate、dropout等,需根据硬件条件调整。
训练目标是最小化交叉熵损失函数:
其中表示第i个词,
表示前文。
SFT微调
SFT阶段使用监督学习微调Pretrain模型。输入是指令或问题,输出是期望的回答。训练数据形式为对,x是输入文本,y是目标输出。
损失函数与Pretrain类似,但只计算y部分的损失: M是y的长度。
RLHF优化
RLHF分为奖励模型训练和策略优化两步。奖励模型训练使用人类偏好数据,学习一个映射的函数,r表示回答质量。
策略优化通过PPO算法微调SFT模型,最大化奖励同时限制与SFT模型的KL散度: 其中
是归一化后的奖励,
是调节系数。
评估与迭代
每个阶段都需要严格评估。Pretrain评估困惑度(perplexity),SFT评估任务完成率,RLHF评估人类偏好得分。根据评估结果调整数据、模型架构或训练策略,形成迭代优化闭环。
训练过程需大量计算资源,建议使用分布式训练框架如Megatron-LM或DeepSpeed。注意监控训练动态,防止过拟合或退化。