前两篇我们完成了从 "会写提示词" 到 "能落地企业级提示工程系统" 的跨越。但大模型技术日新月异,前沿提示技术正在重新定义生产力------ 从人工写提示词到 AI 自动生成提示词,从单模型提示到多智能体协同提示,从通用提示到领域专属提示。
第八章 提示工程前沿技术(2026 年最新)
传统提示工程依赖人工经验,效率低、难以规模化。前沿提示技术的核心目标是用 AI 自动化提示工程的全流程,同时大幅提升复杂任务的解决能力。
8.1 自动提示工程(APE)
自动提示工程(Automatic Prompt Engineering, APE)是让大模型自动生成、评估和优化提示词,无需人工干预。这是目前最成熟、应用最广泛的前沿提示技术。
8.1.1 APE 核心原理
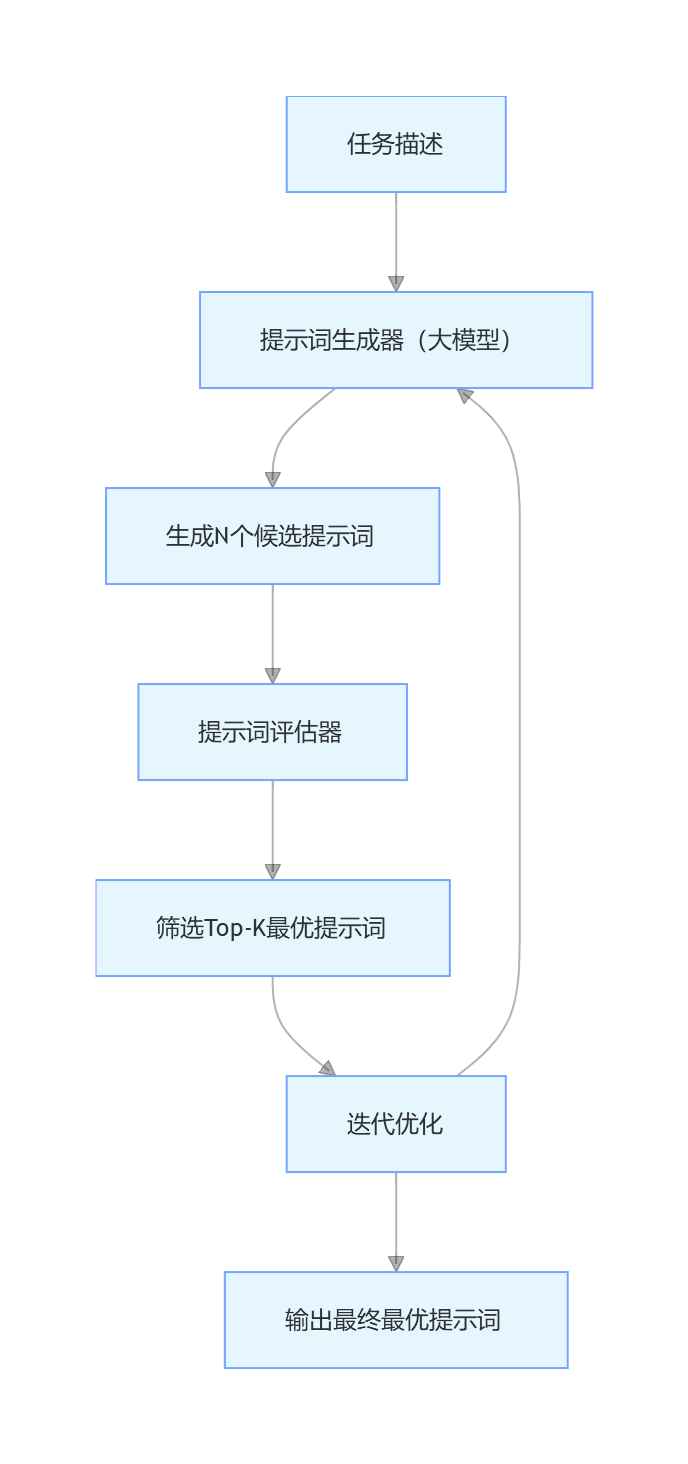
8.1.2 经典 APE 框架:AutoPrompt
AutoPrompt 是最早的自动提示工程框架之一,通过梯度搜索的方式自动生成提示词模板。
Python 代码示例:使用 OpenAI 实现简单 APE
python
from openai import OpenAI
import json
client = OpenAI(api_key="你的API_KEY")
def generate_candidate_prompts(task_description, num_candidates=5):
"""生成候选提示词"""
prompt = f"""
你是一位专业的提示词工程师。请根据以下任务描述,生成{num_candidates}个不同的提示词模板。
任务描述:{task_description}
要求:
1. 每个提示词模板要包含{{input}}占位符,用于替换输入数据
2. 提示词要清晰、具体、有效
3. 不同提示词要有不同的结构和侧重点
输出为JSON数组格式,每个元素是一个提示词模板。
"""
resp = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": prompt}],
temperature=0.7,
response_format={"type": "json_object"}
)
return json.loads(resp.choices[0].message.content)["prompts"]
def evaluate_prompt(prompt_template, test_data):
"""评估单个提示词的效果"""
correct = 0
for item in test_data:
prompt = prompt_template.format(input=item["input"])
resp = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": prompt}],
temperature=0
)
output = resp.choices[0].message.content.strip()
if output == item["expected_output"]:
correct += 1
return correct / len(test_data)
def auto_prompt_engineering(task_description, test_data, num_candidates=5, iterations=3):
"""自动提示工程主函数"""
best_prompt = None
best_accuracy = 0
for i in range(iterations):
print(f"第{i+1}轮迭代...")
candidates = generate_candidate_prompts(task_description, num_candidates)
for prompt in candidates:
accuracy = evaluate_prompt(prompt, test_data)
print(f"提示词:{prompt[:50]}... 准确率:{accuracy:.2f}")
if accuracy > best_accuracy:
best_accuracy = accuracy
best_prompt = prompt
print(f"本轮最优准确率:{best_accuracy:.2f}")
# 用最优提示词生成下一轮候选
task_description = f"基于以下最优提示词,生成更好的提示词:{best_prompt}"
print(f"\n最终最优提示词:{best_prompt}")
print(f"最终准确率:{best_accuracy:.2f}")
return best_prompt
# 测试:情感分类任务
task_description = "判断文本的情感倾向,输出'积极'、'消极'或'中性'"
test_data = [
{"input": "今天天气真好", "expected_output": "积极"},
{"input": "这部电影太烂了", "expected_output": "消极"},
{"input": "今天是周三", "expected_output": "中性"},
{"input": "产品质量很好", "expected_output": "积极"},
{"input": "服务态度很差", "expected_output": "消极"}
]
best_prompt = auto_prompt_engineering(task_description, test_data)8.1.3 主流 APE 工具推荐
- DSPy:斯坦福大学开源的声明式提示编程框架,目前最强大的 APE 工具
- PromptAgent:微软研究院推出的自动提示优化工具
- AutoPrompt:加州大学伯克利分校开源的经典 APE 框架
- LangChain Prompt Optimizer:LangChain 内置的提示词优化器
8.2 元提示工程(Meta-Prompting)
元提示工程是设计一个 "元提示词",让大模型根据不同的任务自动生成合适的提示词。一个好的元提示词可以适配数百种不同的任务,大幅提升开发效率。
8.2.1 元提示词核心结构
一个优秀的元提示词应包含以下部分:
- 角色设定:让模型扮演提示词工程师
- 提示词设计原则:告诉模型如何设计好的提示词
- 输出格式要求:指定生成的提示词的结构
- 任务输入:用户的具体任务描述
8.2.2 通用元提示词模板(企业级)
javascript
【角色设定】你是世界上最优秀的提示词工程师,拥有10年以上的提示工程经验,擅长为各种任务设计最高效的提示词。
【提示词设计黄金原则】
1. 清晰性:使用精确、无歧义的语言
2. 具体性:明确任务要求、输出格式和约束条件
3. 结构化:使用分点、编号、标题等方式组织内容
4. 角色化:为模型赋予合适的专业身份
5. 示例化:提供1-3个高质量的输入输出示例
【输出要求】
请根据用户的任务描述,生成一个专业的提示词,包含以下模块:
1. 角色设定
2. 任务描述
3. 输入数据说明
4. 输出要求
5. 约束条件
6. 示例参考(如果需要)
输出格式为Markdown,每个模块用二级标题标注。
【用户任务】
{{user_task}}8.2.3 使用示例
vbscript
【用户任务】
设计一个提示词,让大模型帮我写产品需求文档(PRD)模型生成的提示词:
vbscript
## 角色设定
你是一位拥有10年经验的资深产品经理,擅长撰写清晰、完整、可落地的产品需求文档。
## 任务描述
请根据以下产品信息,撰写一份完整的产品需求文档(PRD)。
## 输入数据说明
- 产品名称
- 目标用户
- 核心功能
- 非功能需求
- 技术栈建议
## 输出要求
1. 文档结构清晰,包含以下章节:
- 1. 产品概述
- 2. 目标用户
- 3. 功能需求(用例图+详细描述)
- 4. 非功能需求
- 5. 技术栈建议
- 6. 上线计划
2. 语言专业、简洁、准确
3. 字数控制在2000-3000字
4. 使用Markdown格式
## 约束条件
1. 不要添加任何无关内容
2. 需求要具体、可量化、可测试
3. 符合互联网产品的最佳实践
## 示例参考
[此处省略示例]8.3 DSPy:声明式提示编程框架
DSPy 是斯坦福大学在 2024 年推出的革命性框架,它将提示工程从 "写自然语言" 变成了 "写代码",实现了提示工程的完全自动化和可复用。
8.3.1 DSPy 核心概念
- 签名(Signature) :定义任务的输入输出格式,如
input="question", output="answer" - 模块(Module) :封装了提示逻辑的可复用组件,如
dspy.Predict、dspy.ChainOfThought - 优化器(Optimizer) :自动优化模块中的提示词和参数,如
BootstrapFewShot - 评估器(Evaluator):评估模型的效果,指导优化过程
8.3.2 DSPy 代码示例:数学问题求解
python
import dspy
from dspy.evaluate import Evaluate
from dspy.teleprompt import BootstrapFewShot
# 配置大模型
turbo = dspy.OpenAI(model="gpt-3.5-turbo", api_key="你的API_KEY")
dspy.settings.configure(lm=turbo)
# 1. 定义任务签名
class MathProblem(dspy.Signature):
"""解决数学应用题"""
question = dspy.InputField(desc="数学应用题")
answer = dspy.OutputField(desc="最终答案,只输出数字")
# 2. 定义模型
class MathSolver(dspy.Module):
def __init__(self):
super().__init__()
self.cot = dspy.ChainOfThought(MathProblem)
def forward(self, question):
return self.cot(question=question)
# 3. 准备数据集
train_data = [
dspy.Example(question="一个商店有12个苹果,卖了5个,又进货8个,现在有多少个?", answer="15").with_inputs("question"),
dspy.Example(question="小明有5颗糖,妈妈又给他买了4颗,他吃掉了2颗,现在有多少颗?", answer="7").with_inputs("question"),
dspy.Example(question="3+5×2等于多少?", answer="13").with_inputs("question")
]
test_data = [
dspy.Example(question="一个数加上5,乘以3,减去10,再除以2,结果是10,这个数是多少?", answer="5").with_inputs("question")
]
# 4. 定义评估函数
def evaluate_math(example, pred, trace=None):
return pred.answer.strip() == example.answer.strip()
# 5. 自动优化提示词
optimizer = BootstrapFewShot(metric=evaluate_math, max_bootstrapped_demos=3)
optimized_solver = optimizer.compile(MathSolver(), trainset=train_data)
# 6. 测试
question = "一个数加上5,乘以3,减去10,再除以2,结果是10,这个数是多少?"
pred = optimized_solver(question=question)
print(f"问题:{question}")
print(f"答案:{pred.answer}")
print(f"推理过程:{pred.rationale}")8.3.3 DSPy 的优势
- 无需手动写提示词:优化器自动生成最优提示词
- 可复用性强:模块可以在不同任务之间复用
- 可扩展性好:支持复杂的多步骤任务和多智能体系统
- 效果更好:在大多数任务上超过人工设计的提示词
8.4 专家混合提示(MoE Prompting)
专家混合提示的核心思想是:让模型模拟多个不同领域的专家,分别给出意见,然后综合得出最终结果。这种方法能大幅提升复杂决策问题的准确率。
8.4.1 专家混合提示流程
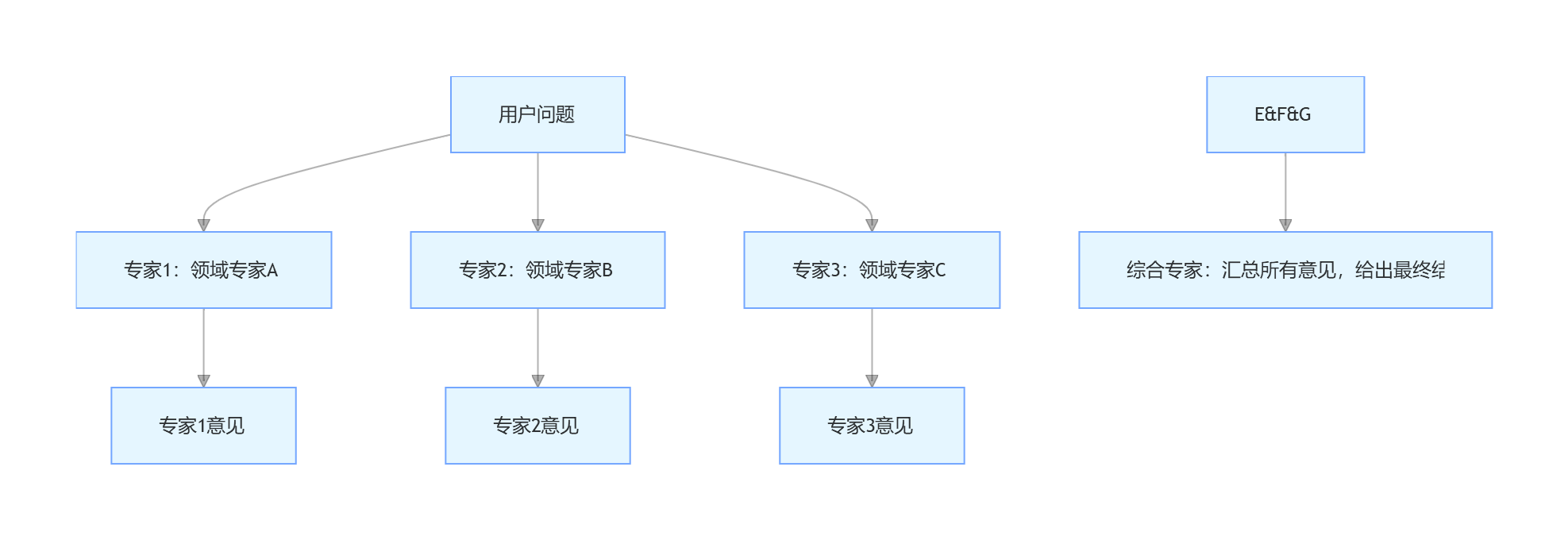
8.4.2 专家混合提示词模板
javascript
【任务】请解决以下问题:{{question}}
【步骤1:专家分析】
请分别扮演以下三位专家,从各自的专业角度分析问题,并给出解决方案。
专家1:[专家1身份,如"资深技术架构师"]
分析:
解决方案:
专家2:[专家2身份,如"产品经理"]
分析:
解决方案:
专家3:[专家3身份,如"运营专家"]
分析:
解决方案:
【步骤2:综合决策】
请扮演一位经验丰富的决策者,综合以上三位专家的意见,给出最终的最优解决方案,并说明理由。8.4.3 示例:产品功能决策
javascript
【任务】我们的电商APP是否应该增加直播带货功能?
【步骤1:专家分析】
专家1:资深技术架构师
分析:直播带货需要搭建直播系统、推流系统、互动系统,技术复杂度较高,需要投入至少5名开发人员,开发周期3个月。
解决方案:建议分阶段开发,先上线基础直播功能,再逐步优化。
专家2:产品经理
分析:直播带货是目前电商的主流趋势,能大幅提升用户粘性和转化率。我们的竞品都已经上线了直播功能,如果我们不做,会失去市场份额。
解决方案:必须尽快上线直播带货功能,作为今年的核心功能。
专家3:运营专家
分析:直播带货需要专业的运营团队和主播资源,我们目前没有相关经验,运营成本较高。如果运营不好,可能会投入大量资源但没有效果。
解决方案:建议先和第三方直播平台合作,验证效果后再自建直播系统。
【步骤2:综合决策】
综合三位专家的意见,最优解决方案是:先和第三方直播平台合作,用3个月时间验证直播带货的效果。如果效果好,再投入资源自建直播系统;如果效果不好,及时止损。
理由:这种方案既能跟上市场趋势,又能降低技术和运营风险,是最稳妥的选择。8.5 其他前沿方向
8.5.1 提示蒸馏(Prompt Distillation)
将大模型的提示知识蒸馏到小模型中,让小模型也能达到大模型的效果,大幅降低推理成本。
8.5.2 多智能体提示(Multi-Agent Prompting)
设计多个不同角色的智能体,通过协作完成复杂任务,如软件开发团队、内容创作团队等。代表框架:AutoGen、CrewAI、LangGraph。
8.5.3 提示安全(Prompt Safety)
研究如何设计安全的提示词,防止模型生成有害内容,防范提示注入攻击。代表技术:宪法 AI、安全护栏。
8.5.4 领域专属提示(Domain-Specific Prompting)
针对医疗、法律、金融等垂直领域,设计专门的提示词模板和知识库,提升模型在特定领域的表现。
第九章 企业级实战项目
本章包含 3 个最主流的企业级大模型应用项目,每个项目都有完整的需求分析、技术架构、核心代码和提示词设计,你可以直接跟着实现,或者写进简历。
9.1 项目一:智能客服系统(日调用量 10 万 +)
智能客服是企业应用大模型最多的场景,也是面试中最常问的项目。
9.1.1 需求分析
- 核心功能:自动回答用户常见问题、处理订单查询、引导用户转人工
- 性能要求:响应时间 <2 秒,准确率> 90%,支持 1000 并发
- 业务要求:语气亲切、符合品牌形象、不泄露公司机密
- 安全要求:防范提示注入攻击、过滤有害内容
9.1.2 技术架构
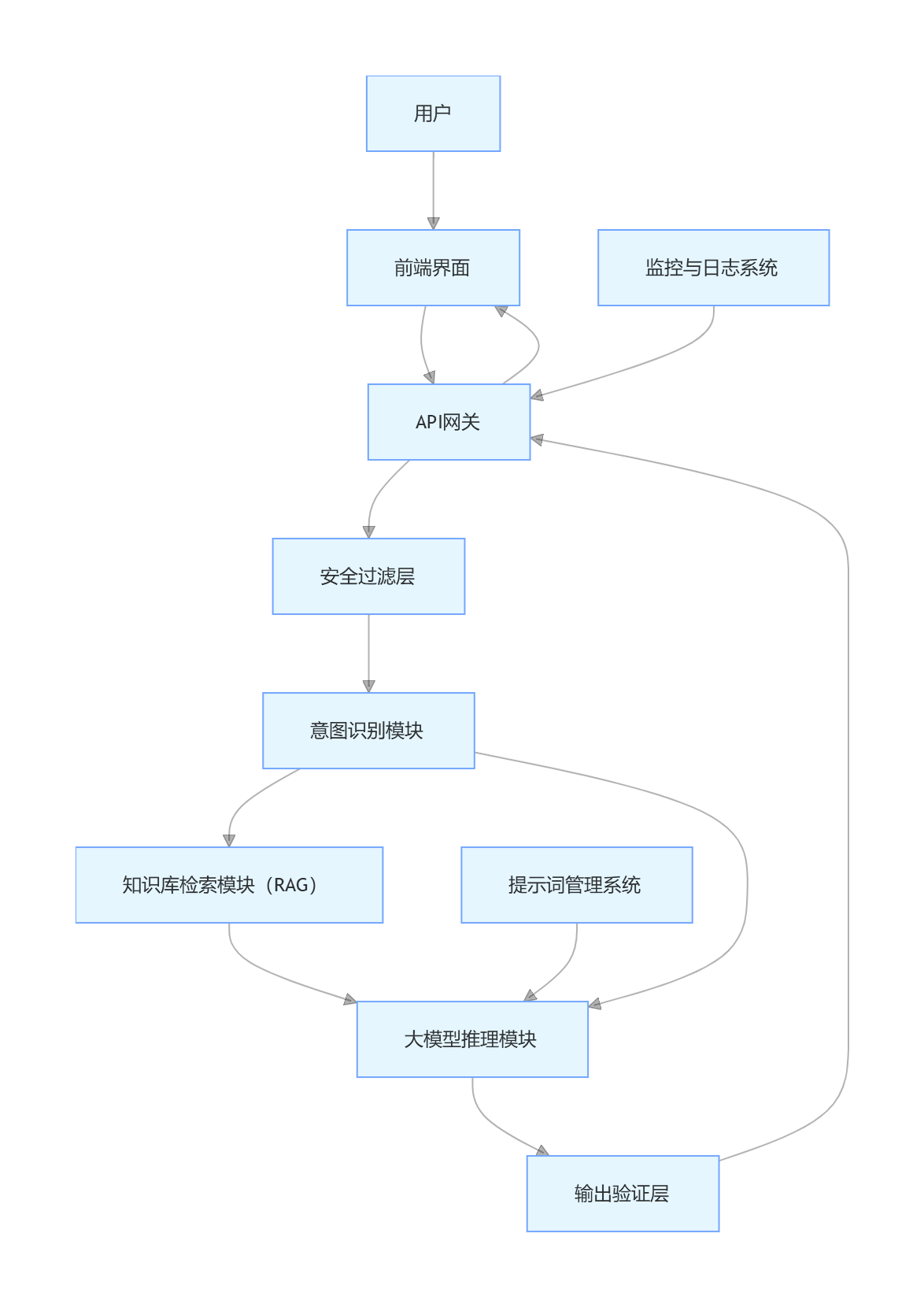
9.1.3 核心提示词设计
1. 系统提示词(核心)
vbscript
【角色设定】你是XX电商的智能客服助手,工号001。你的名字是"小X"。
【品牌形象】亲切、热情、专业、有耐心,使用"亲"称呼用户。
【客服守则】
1. 只能回答与XX电商产品和服务相关的问题
2. 回答要准确、简洁、清晰,不要编造信息
3. 如果无法回答用户的问题,说:"亲,这个问题我暂时无法解答,我帮您转人工客服好吗?"
4. 不要泄露公司机密和其他用户的信息
5. 不要与用户发生争执,保持礼貌
6. 所有回答必须使用中文
【公司信息】
- 公司名称:XX电商
- 主营业务:电子产品销售
- 客服时间:9:00-21:00
- 发货时间:下单后24小时内发货
- 退货政策:7天无理由退货,15天质量问题包换
- 运费政策:满99元包邮,不满99元运费10元
【用户信息】
用户ID:{{user_id}}
订单号:{{order_id}}(如果有)
用户等级:{{user_level}}
【对话历史】
{{chat_history}}
【用户最新问题】
{{user_question}}
请根据以上信息回答用户的问题。2. 意图识别提示词
vbscript
请识别用户问题的意图,输出以下意图之一:
- 发货查询
- 退货申请
- 订单查询
- 产品咨询
- 投诉建议
- 转人工
- 其他
用户问题:{{user_question}}
输出:9.1.4 核心代码实现
python
from fastapi import FastAPI, HTTPException
from openai import OpenAI
import json
from security import filter_input, filter_output
from rag import retrieve_knowledge
app = FastAPI()
client = OpenAI(api_key="你的API_KEY")
# 加载系统提示词模板
with open("prompts/customer_service_system.j2", "r", encoding="utf-8") as f:
system_prompt_template = f.read()
with open("prompts/intent_recognition.j2", "r", encoding="utf-8") as f:
intent_prompt_template = f.read()
@app.post("/api/chat")
async def chat(user_id: str, user_question: str, order_id: str = None):
# 1. 输入过滤
is_safe, filtered_input = filter_input(user_question)
if not is_safe:
return {"answer": "亲,您的输入包含敏感信息,请重新输入。"}
# 2. 意图识别
intent_prompt = intent_prompt_template.format(user_question=filtered_input)
intent_resp = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": intent_prompt}],
temperature=0
)
intent = intent_resp.choices[0].message.content.strip()
# 3. 知识库检索
knowledge = retrieve_knowledge(filtered_input, intent)
# 4. 构建系统提示词
system_prompt = system_prompt_template.format(
user_id=user_id,
order_id=order_id,
user_level="普通用户",
chat_history="", # 实际应用中从数据库获取对话历史
user_question=filtered_input,
knowledge=knowledge
)
# 5. 大模型推理
resp = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[{"role": "system", "content": system_prompt}],
temperature=0.7,
stream=True
)
# 6. 输出验证
answer = ""
for chunk in resp:
if chunk.choices[0].delta.content:
answer += chunk.choices[0].delta.content
is_safe, filtered_answer = filter_output(answer)
if not is_safe:
return {"answer": "亲,这个问题我暂时无法解答,我帮您转人工客服好吗?"}
return {"answer": filtered_answer, "intent": intent}
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)9.1.5 效果优化
- RAG 增强:将常见问题和答案存入向量数据库,检索后作为上下文提供给模型
- 提示词 A/B 测试:定期测试不同的系统提示词,选择效果最好的
- 人工审核:对低置信度的回答进行人工审核,不断优化提示词和知识库
- 冷启动优化:收集用户常见问题,提前生成标准答案
9.2 项目二:企业知识库问答系统(RAG + 提示工程)
企业知识库问答系统是目前最火的大模型应用之一,几乎所有企业都有这个需求。
9.2.1 需求分析
- 核心功能:支持上传 PDF/Word/PPT/Markdown 等格式的文档,自动构建知识库,支持自然语言问答
- 性能要求:响应时间 <3 秒,准确率> 85%,支持 100 并发
- 功能要求:支持引用溯源、多轮对话、文档管理、权限控制
- 安全要求:数据隔离、防止敏感信息泄露
9.2.2 技术架构
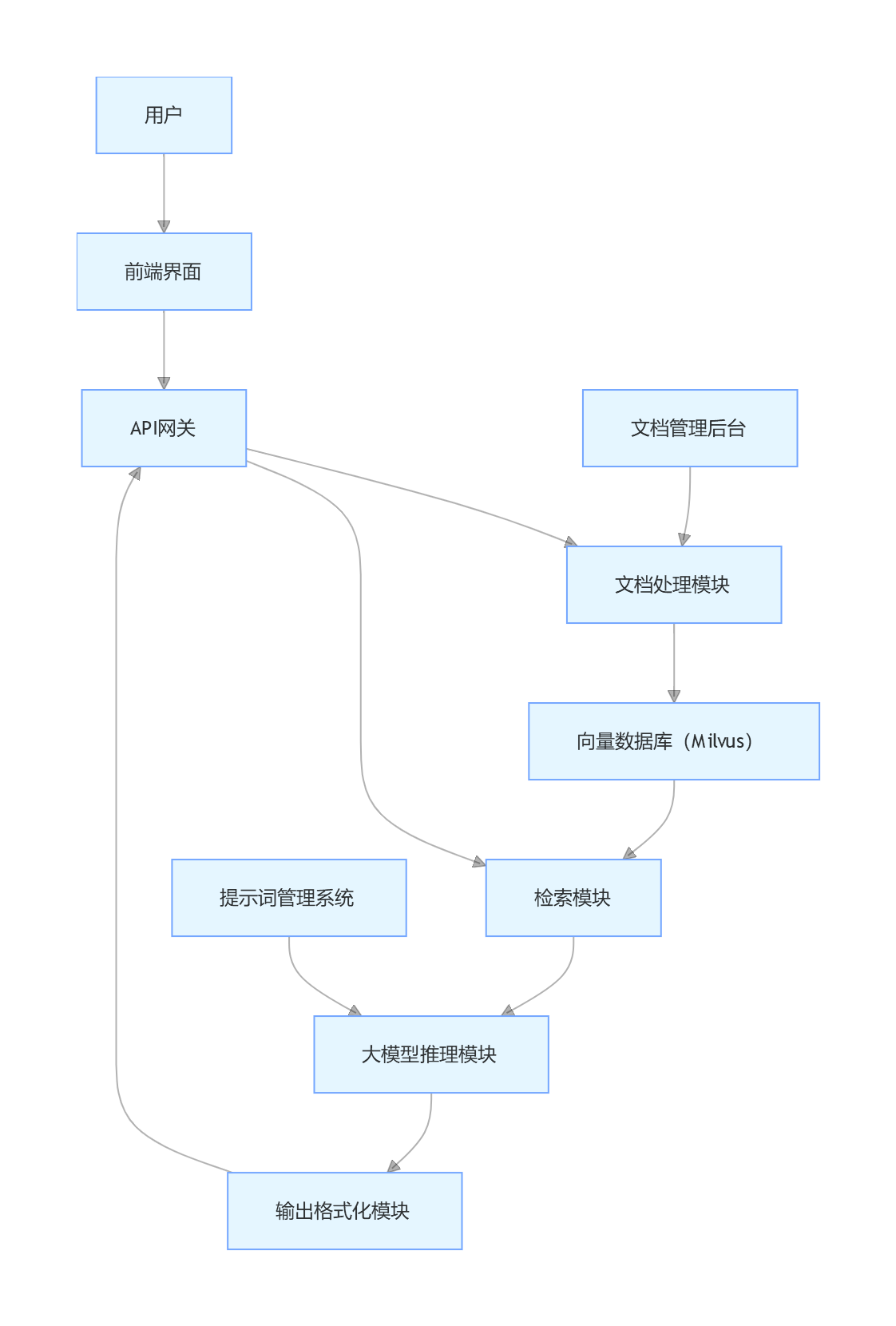
9.2.3 核心提示词设计
1. 问答提示词(核心)
vbscript
【角色设定】你是一位专业的知识库助手,擅长根据提供的文档内容回答用户的问题。
【任务描述】请根据以下参考文档,回答用户的问题。
【参考文档】
{{documents}}
【用户问题】
{{question}}
【输出要求】
1. 只能使用参考文档中的信息回答问题
2. 如果参考文档中没有相关信息,说:"抱歉,知识库中没有找到相关信息。"
3. 回答要准确、简洁、清晰
4. 重要信息用加粗标注
5. 在回答的末尾添加引用来源,格式为:[来源:文档名称-页码]
【约束条件】
1. 不要编造任何没有依据的信息
2. 不要回答与参考文档无关的问题
3. 所有回答必须使用中文2. 问题重写提示词
TypeScript
请根据对话历史,将用户的最新问题重写为一个完整、清晰的独立问题。
对话历史:
{{chat_history}}
用户最新问题:{{latest_question}}
重写后的问题:9.2.4 核心代码实现
python
from fastapi import FastAPI, UploadFile, File
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import PyPDFLoader, Docx2txtLoader
from langchain_community.embeddings import HuggingFaceBgeEmbeddings
from langchain_community.vectorstores import Milvus
from openai import OpenAI
import os
import uuid
app = FastAPI()
client = OpenAI(api_key="你的API_KEY")
# 初始化嵌入模型和向量数据库
embeddings = HuggingFaceBgeEmbeddings(model_name="BAAI/bge-large-zh-v1.5")
vector_store = Milvus(
embedding_function=embeddings,
connection_args={"host": "localhost", "port": "19530"},
collection_name="enterprise_kb"
)
# 加载提示词模板
with open("prompts/rag_qa.j2", "r", encoding="utf-8") as f:
qa_prompt_template = f.read()
@app.post("/api/upload")
async def upload_document(file: UploadFile = File(...)):
"""上传文档并构建知识库"""
file_id = str(uuid.uuid4())
file_path = f"temp/{file_id}_{file.filename}"
os.makedirs("temp", exist_ok=True)
# 保存文件
with open(file_path, "wb") as f:
f.write(await file.read())
# 加载文档
if file.filename.endswith(".pdf"):
loader = PyPDFLoader(file_path)
elif file.filename.endswith(".docx"):
loader = Docx2txtLoader(file_path)
else:
raise HTTPException(status_code=400, detail="不支持的文件格式")
documents = loader.load()
# 文档分块
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=50,
separators=["\n\n", "\n", "。", " ", ""]
)
chunks = text_splitter.split_documents(documents)
# 添加元数据
for chunk in chunks:
chunk.metadata["file_name"] = file.filename
chunk.metadata["file_id"] = file_id
# 存入向量数据库
vector_store.add_documents(chunks)
# 删除临时文件
os.remove(file_path)
return {"file_id": file_id, "file_name": file.filename, "chunks_count": len(chunks)}
@app.post("/api/qa")
async def qa(question: str, file_id: str = None):
"""知识库问答"""
# 检索相关文档
search_kwargs = {"k": 5}
if file_id:
search_kwargs["filter"] = {"file_id": file_id}
docs = vector_store.similarity_search(question, **search_kwargs)
# 构建参考文档
documents_str = ""
for i, doc in enumerate(docs):
documents_str += f"文档{i+1}:\n{doc.page_content}\n来源:{doc.metadata['file_name']}-第{doc.metadata.get('page', 1)}页\n\n"
# 构建提示词
prompt = qa_prompt_template.format(
documents=documents_str,
question=question
)
# 大模型推理
resp = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": prompt}],
temperature=0
)
answer = resp.choices[0].message.content
return {"answer": answer, "sources": [doc.metadata["file_name"] for doc in docs]}
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8001)9.2.5 效果优化
- 文档分块优化:使用语义分块代替固定大小分块
- 重排序:使用 BGE-Reranker 对检索结果进行重排序
- 问题重写:对用户的问题进行重写,提升检索准确率
- 分层 RAG:使用父文档 - 子文档结构,解决长上下文问题
9.3 项目三:AI 内容创作平台
AI 内容创作平台是 ToC 和 ToB 都非常受欢迎的应用,能大幅提升内容生产效率。
9.3.1 需求分析
- 核心功能:支持文案生成、文章写作、邮件撰写、代码生成、图片生成等多种内容创作任务
- 功能要求:支持风格选择、字数控制、模板选择、内容编辑、历史记录
- 性能要求:响应时间 < 5 秒,支持 500 并发
- 用户体验:界面简洁、操作简单、生成质量高
9.3.2 技术架构
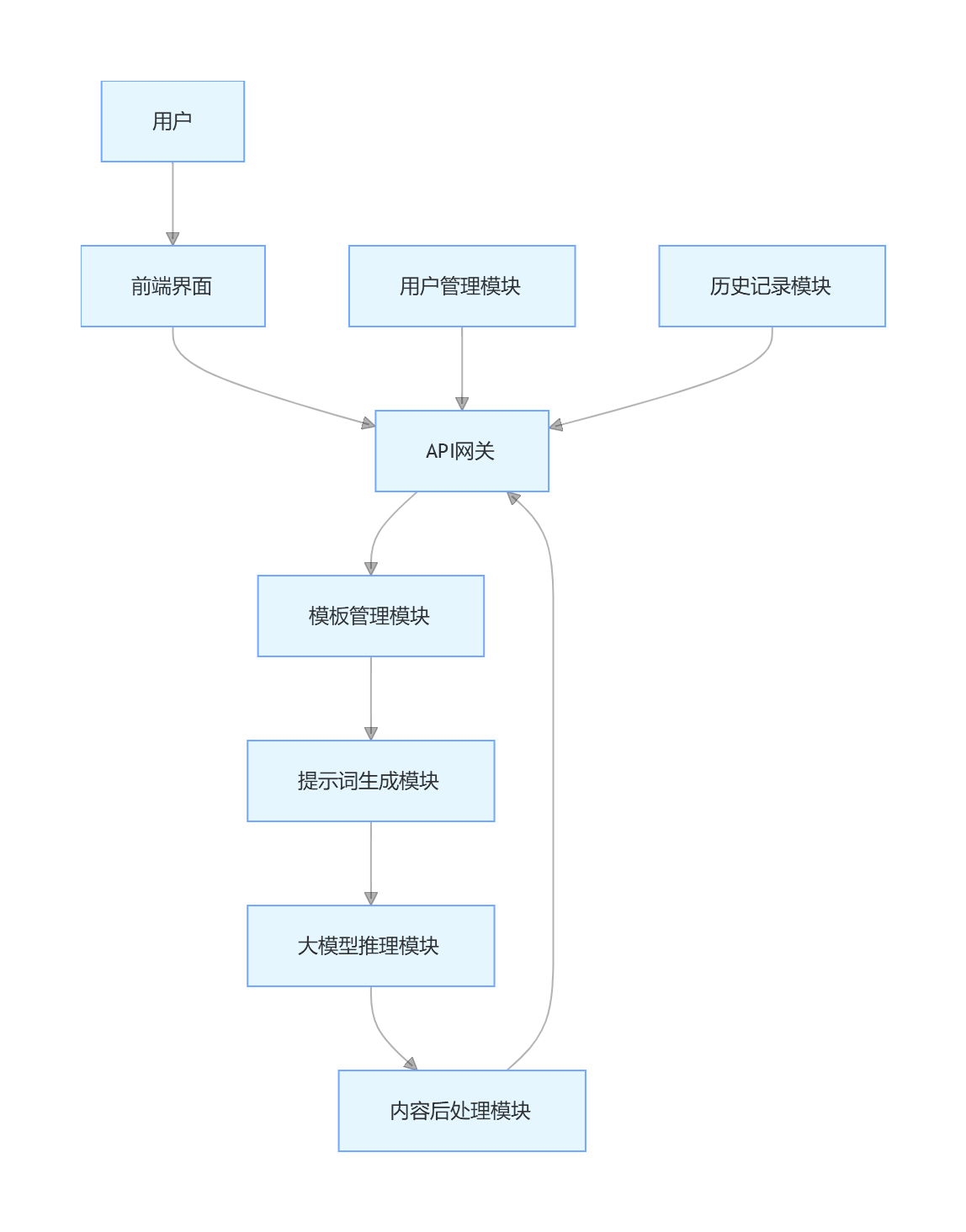
9.3.3 核心提示词设计
1. 通用内容生成提示词模板
TypeScript
【角色设定】你是一位专业的{{content_type}}创作专家,拥有10年以上的创作经验。
【任务描述】请根据以下要求,创作一篇{{content_type}}。
【创作要求】
- 主题:{{topic}}
- 风格:{{style}}
- 字数:{{word_count}}字左右
- 目标受众:{{target_audience}}
- 核心关键词:{{keywords}}
【输出要求】
1. 内容原创、高质量、有吸引力
2. 结构清晰、逻辑严谨
3. 语言流畅、符合{{style}}风格
4. 字数控制在{{word_count}}±10%以内
5. 使用Markdown格式
【约束条件】
1. 不要生成任何违法、违规、低俗的内容
2. 不要侵犯他人的知识产权
3. 所有内容必须使用中文9.3.4 核心代码实现
python
from fastapi import FastAPI, HTTPException
from openai import OpenAI
from pydantic import BaseModel
import json
app = FastAPI()
client = OpenAI(api_key="你的API_KEY")
# 加载模板
with open("templates/content_templates.json", "r", encoding="utf-8") as f:
templates = json.load(f)
class ContentRequest(BaseModel):
template_id: str
topic: str
style: str = "正式"
word_count: int = 500
target_audience: str = "通用"
keywords: str = ""
@app.get("/api/templates")
async def get_templates():
"""获取所有内容模板"""
return [{"id": k, "name": v["name"], "description": v["description"]} for k, v in templates.items()]
@app.post("/api/generate")
async def generate_content(request: ContentRequest):
"""生成内容"""
if request.template_id not in templates:
raise HTTPException(status_code=400, detail="模板不存在")
template = templates[request.template_id]
# 构建提示词
prompt = template["prompt_template"].format(
topic=request.topic,
style=request.style,
word_count=request.word_count,
target_audience=request.target_audience,
keywords=request.keywords
)
# 大模型推理
resp = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": prompt}],
temperature=0.7,
stream=True
)
# 流式返回结果
from fastapi.responses import StreamingResponse
import asyncio
async def generate():
for chunk in resp:
if chunk.choices[0].delta.content:
yield chunk.choices[0].delta.content
await asyncio.sleep(0.01)
return StreamingResponse(generate(), media_type="text/plain")
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8002)第十章 面试题
10.1 基础理论题
-
**什么是提示工程?它的核心价值是什么?**答题思路:先定义提示工程,然后从低成本、解决幻觉、标准化输出、提升推理能力四个方面讲价值,最后说适用边界。
-
**解释一下思维链(CoT)提示的原理和作用。**答题思路:先讲 CoT 是什么,然后讲原理(引导模型逐步推理),再讲适用场景(数学、逻辑、复杂问题),最后讲零样本 CoT 和少样本 CoT 的区别。
-
**大模型为什么会产生幻觉?如何通过提示工程减少幻觉?**答题思路:先讲幻觉的原因(训练数据不足、统计规律预测),然后讲提示工程的解决方法(提供上下文、要求引用来源、约束条件、自我验证)。
-
**什么是少样本提示?它为什么有效?**答题思路:先定义少样本提示,然后讲原理(大模型的上下文学习能力),再讲设计要点(示例多样化、高质量、与任务一致)。
10.2 工程化题
-
**如何管理企业级的提示词?**答题思路:从模板化、版本控制、集中式仓库、A/B 测试、监控评估五个方面讲,提到 Jinja2、Git、LangChain Hub 等工具。
-
**如何评估提示词的效果?**答题思路:从定量评估(准确率、F1、任务完成率)、定性评估(人工打分)、自动化评估(大模型作为评估器)三个方面讲,提到评估数据集的构建。
-
**什么是提示注入攻击?如何防范?**答题思路:先定义提示注入,然后讲常见类型(直接注入、间接注入、越狱),再讲防范方法(输入过滤、输出验证、角色隔离、安全工具)。
-
**如何进行提示词的 A/B 测试?**答题思路:讲 A/B 测试的流程(确定指标、设计候选提示词、构建数据集、运行测试、统计分析、上线),提到 LangSmith、PromptLayer 等工具。
10.3 场景设计题
-
**如果让你设计一个智能客服的提示词,你会怎么设计?**答题思路:按照六要素结构(角色设定、任务描述、输入数据、输出要求、约束条件、示例参考)来设计,重点讲品牌形象、客服守则、公司信息、用户信息、对话历史的处理。
-
**如何优化一个 RAG 系统的回答质量?**答题思路:从文档处理(分块、清洗)、检索阶段(嵌入模型、混合检索、重排序)、生成阶段(提示词设计、上下文管理)三个方面讲,提到高级 RAG 技术(分层 RAG、问题重写、上下文压缩)。
-
**用户投诉客服回答错误,你会怎么排查和优化?**答题思路:先排查原因(提示词问题、知识库问题、模型问题、用户输入问题),然后讲优化步骤(复现问题、分析日志、优化提示词 / 知识库、A/B 测试、上线验证),最后讲监控和预防措施。
10.4 前沿技术题
-
**什么是自动提示工程(APE)?它有什么优势?**答题思路:先定义 APE,然后讲原理(大模型自动生成和优化提示词),再讲优势(效率高、效果好、可规模化),最后提到 DSPy、AutoPrompt 等工具。
-
**什么是元提示工程?**答题思路:先定义元提示工程,然后讲核心思想(用提示词生成提示词),再讲元提示词的结构,最后讲应用场景。
-
**DSPy 和传统提示工程有什么区别?**答题思路:先讲传统提示工程的缺点(依赖人工、难以复用、难以优化),然后讲 DSPy 的核心概念(签名、模块、优化器),最后讲 DSPy 的优势(自动化、可复用、可扩展)。
10.5 字节跳动真题
问题:如何设计一个提示词,让大模型准确提取合同中的甲方、乙方、合同金额、合同期限四个字段?
答题思路:
- 角色设定:专业的法律文档提取专家
- 任务描述:明确提取四个字段
- 输入数据:合同文本
- 输出要求:JSON 格式,每个字段的定义和示例
- 约束条件:只能提取合同中明确提到的信息,没有的话输出 "未明确"
- 示例参考:提供 1-2 个提取示例
参考答案:
TypeScript
【角色设定】你是一位专业的法律文档信息提取专家,拥有10年以上的合同处理经验。
【任务描述】请从以下合同文本中提取甲方、乙方、合同金额、合同期限四个字段。
【字段定义】
- 甲方:合同中的委托方/发包方
- 乙方:合同中的受托方/承包方
- 合同金额:合同约定的总金额,包含币种
- 合同期限:合同的生效日期和终止日期
【输入合同文本】
{{contract_text}}
【输出要求】
1. 输出为严格的JSON格式,不要输出任何其他内容
2. 如果某个字段在合同中没有明确提到,输出"未明确"
3. 提取的信息要准确无误,不要添加任何解释
【示例参考】
输入:
甲方:XX科技有限公司
乙方:YY软件有限公司
合同金额:人民币100万元整
合同期限:2023年1月1日至2023年12月31日
输出:
{
"甲方": "XX科技有限公司",
"乙方": "YY软件有限公司",
"合同金额": "人民币100万元整",
"合同期限": "2023年1月1日至2023年12月31日"
}10.6 阿里巴巴真题
问题:如果你的提示词在测试集上准确率很高,但上线后效果很差,你会怎么排查?
答题思路:
- 数据分布问题:测试集和线上数据分布不一致,测试集太简单
- 提示词泛化能力差:提示词过度拟合测试集
- 上下文长度问题:线上输入过长,超过上下文窗口
- 模型版本问题:线上使用的模型版本和测试时不同
- 用户输入问题:线上用户输入不规范、有歧义、有恶意输入
- 系统问题:RAG 检索错误、提示词模板渲染错误
- 排查步骤:先复现问题,然后分析日志,对比测试和线上的差异,逐一排查原因,最后优化和验证