文章目录
- 一、qlib数据集介绍
- 二、chenditc/investment_data项目介绍
-
- [2.1 日更的tushare数据采集](#2.1 日更的tushare数据采集)
-
- [2.1.1 数据入库思路 initial_loading.sql](#2.1.1 数据入库思路 initial_loading.sql)
- [2.1.2 下载数据](#2.1.2 下载数据)
-
- [2.1.2.1 获取股票列表 dump_tushare_stock_list.py](#2.1.2.1 获取股票列表 dump_tushare_stock_list.py)
- [2.1.2.2 提取A 股交易日历 dump_day_calendar.py](#2.1.2.2 提取A 股交易日历 dump_day_calendar.py)
- [2.1.2.3 采集A股日线 dump_a_stock_eod_price.py](#2.1.2.3 采集A股日线 dump_a_stock_eod_price.py)
- [2.1.2.4 A 股日线数据的【每日增量更新脚本】update_a_stock_eod_price_to_latest.py](#2.1.2.4 A 股日线数据的【每日增量更新脚本】update_a_stock_eod_price_to_latest.py)
- [2.1.2.5 dump_index_eod_price.py 采集指数日线](#2.1.2.5 dump_index_eod_price.py 采集指数日线)
- [2.1.2.6 dump_index_weight.py 股权重](#2.1.2.6 dump_index_weight.py 股权重)
- [2.1.3 清洗数据](#2.1.3 清洗数据)
- [2.1.4 数据校验](#2.1.4 数据校验)
- 三、数据下载解压
- 四、数据详解
-
- [4.1 instruments](#4.1 instruments)
- [4.1.1 all.txt](#4.1.1 all.txt)
- [4.1.2 csi300.txt(及其他指数文件)](#4.1.2 csi300.txt(及其他指数文件))
- [4.2 features](#4.2 features)
-
- [4.2.1 每个股票代码文件中的特征列表(共10个)](#4.2.1 每个股票代码文件中的特征列表(共10个))
- [4.2.2 .bin文件设计原理解析](#4.2.2 .bin文件设计原理解析)
- [4.2.3 为什么按照股票代码分开存储?](#4.2.3 为什么按照股票代码分开存储?)
- [4.2.4 为什么每个特征一个.bin文件?](#4.2.4 为什么每个特征一个.bin文件?)
- [4.2.5 读取bin文件](#4.2.5 读取bin文件)
- [4.2.6 构造时序数据](#4.2.6 构造时序数据)
- [4.2.7 features bin文件统计分析](#4.2.7 features bin文件统计分析)
- [4.2.8 与传统数据库对比](#4.2.8 与传统数据库对比)
- [4.3 calendars](#4.3 calendars)
-
- [4.3.1 day.txt](#4.3.1 day.txt)
- [4.3.2 day_feature.txt](#4.3.2 day_feature.txt)
一、qlib数据集介绍
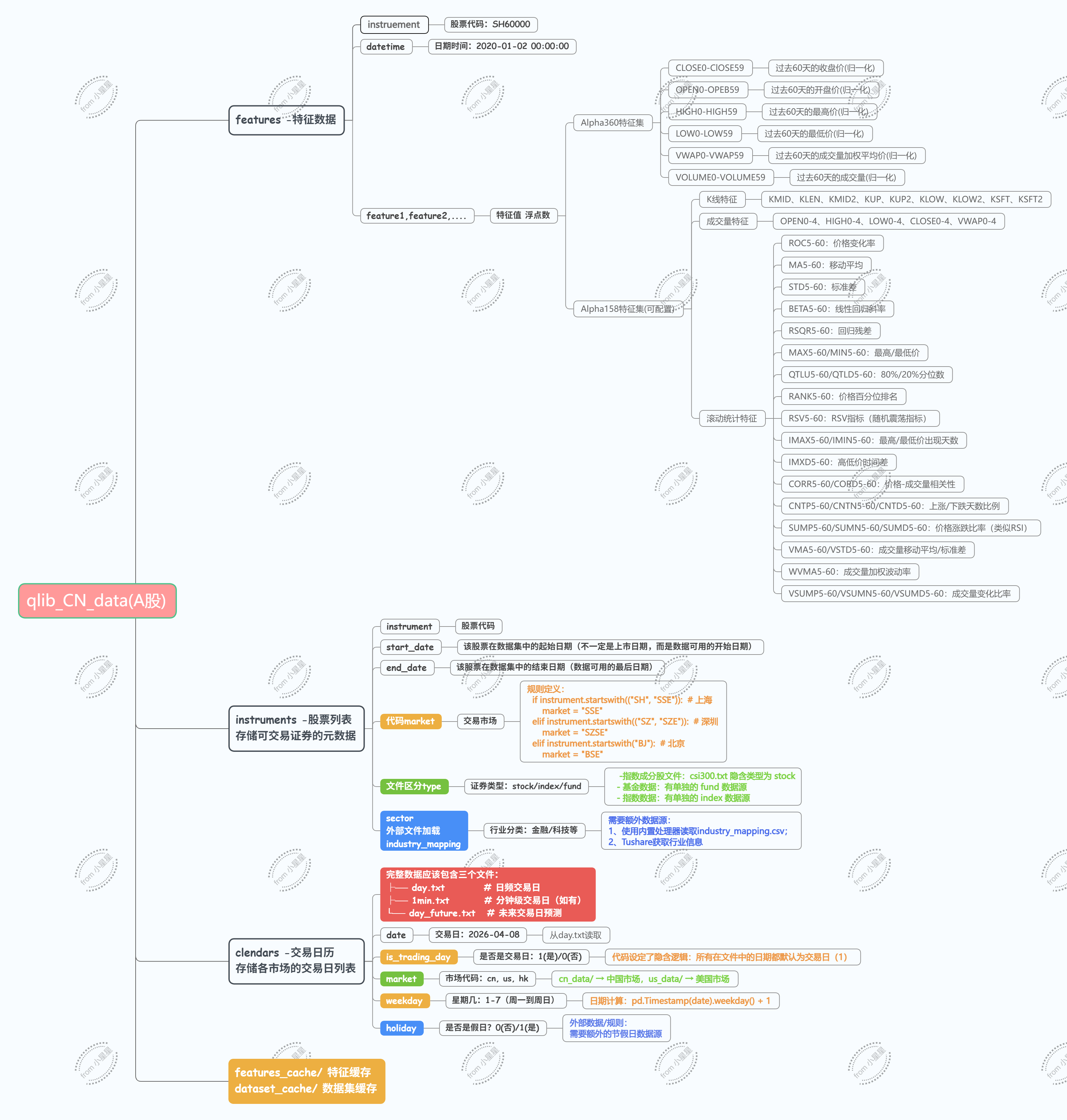
一共有三个文件夹:calendars、features、instruments。其中,instruments为股票列表文件,包含所有A股列表(股票代码);calendar日期,包含了day.txt(交易日)和day_feature.txt;features文件夹是按照股票代码进行分类的,每个股票代码中包含了10个特征bin文件。详解在第四章。
python
D:/qlib_data/cn_data/
├── instruments/ # 股票列表文件
│ ├── all.txt # 所有股票列表
│ ├── csi300.txt # 沪深300成分股(带时间范围)
│ ├── csi500.txt # 中证500成分股
│ └── ...
├── features/ # 特征数据(按股票组织)
│ ├── sh000300/ # 股票1:沪深300指数
│ │ ├── open.day.bin
│ │ ├── close.day.bin
│ │ └── ...
│ ├── sh000001/ # 股票2
│ └── ...
└── calendars/ # 交易日历
├── day.txt
└── day_future.txt二、chenditc/investment_data项目介绍
-
学习这个项目的必要性:以后如果我们长期使用qlib框架做因子挖掘回测,甚至是使用RD-Agent智能体,我们必须知道qlib所需要的数据是如何构造的。而investment_data就是一个很好的学习项目,我们可以了解通用的思路:比如需要下载哪些数据、如果更新每天的新数据、数据清洗以及数据如何转换为bin格式。
-
Wind是万得信息技术股份有限公司
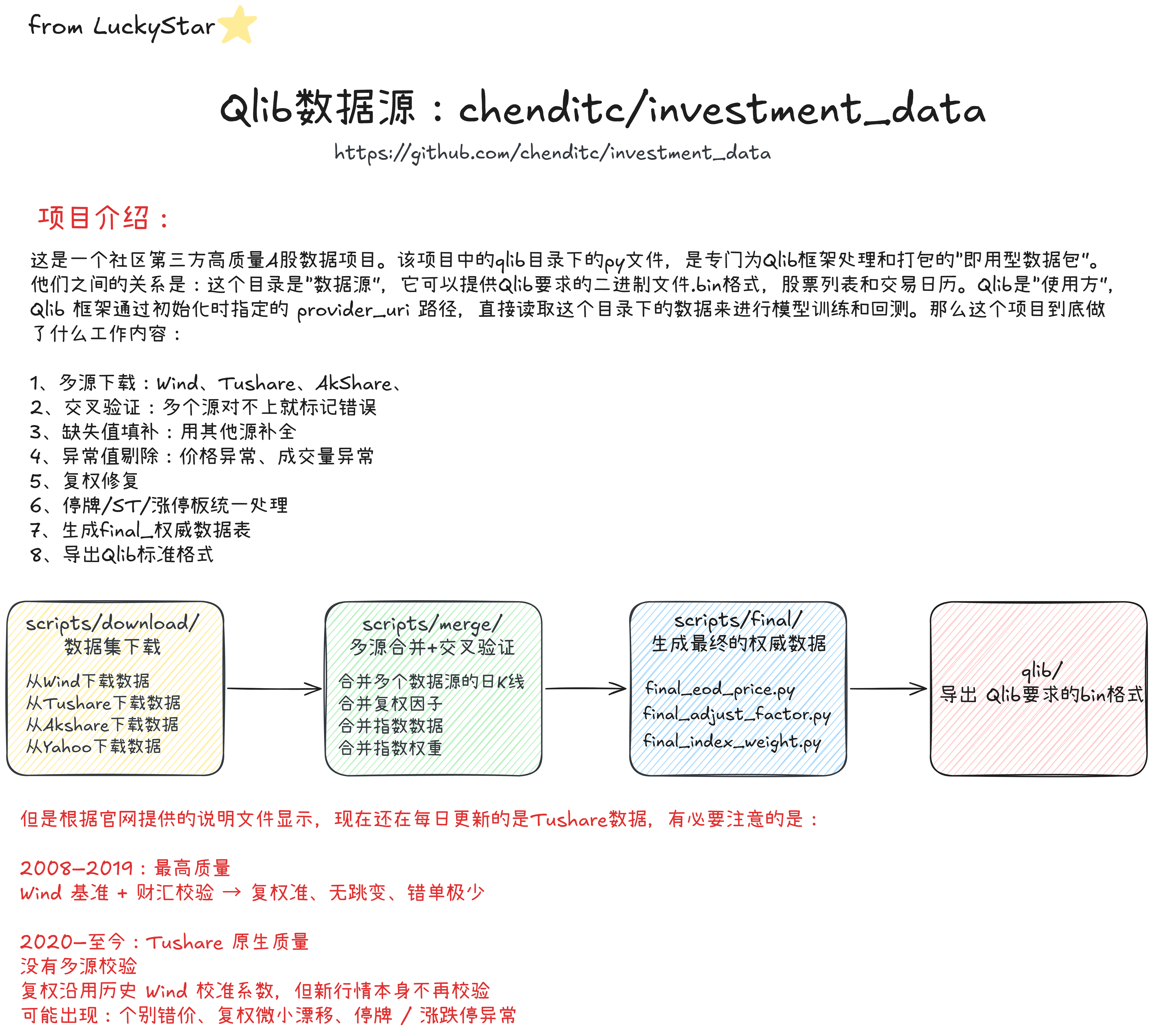
2.1 日更的tushare数据采集
2.1.1 数据入库思路 initial_loading.sql
sql
-- ==============================================
-- 作者:chenxit
-- 功能:数据库初始化脚本
-- 作用:创建数据库 + 创建所有需要的表
-- ==============================================
-- 1. 如果数据库 investment_data 不存在,就创建它(项目专用数据库)
CREATE DATABASE IF NOT EXISTS investment_data;
-- 2. 切换到这个数据库(后面所有表都建在这里)
USE investment_data;
-- ==============================================
-- 表 1:A股 每日日线价格表(最重要的表)
-- 存:每只股票每天的开盘价/收盘价/成交量/复权价
-- ==============================================
CREATE TABLE IF NOT EXISTS `ts_a_stock_eod_price` (
`id` int NOT NULL AUTO_INCREMENT, -- 自增ID(主键,无业务意义)
`tradedate` varchar(20) NOT NULL, -- 交易日期 20250101
`symbol` varchar(20) NOT NULL, -- 股票代码 600000.SH
`open` float DEFAULT NULL, -- 开盘价
`high` float DEFAULT NULL, -- 最高价
`low` float DEFAULT NULL, -- 最低价
`close` float DEFAULT NULL, -- 收盘价
`volume` float DEFAULT NULL, -- 成交量
`amount` float DEFAULT NULL, -- 成交额
`adjclose` float DEFAULT NULL, -- 复权收盘价(算收益率用)
PRIMARY KEY (`id`), -- 主键
UNIQUE KEY `symbol_date` (`symbol`,`tradedate`) -- 联合唯一索引:一只股票一天只能有一条数据
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
-- ==============================================
-- 表 2:指数日线价格表
-- 存:沪深300/中证500等指数的每日行情
-- ==============================================
CREATE TABLE IF NOT EXISTS `ts_index_eod_price` (
`id` int NOT NULL AUTO_INCREMENT,
`symbol` varchar(20) NOT NULL, -- 指数代码
`tradedate` varchar(20) NOT NULL, -- 日期
`open` float DEFAULT NULL,
`high` float DEFAULT NULL,
`low` float DEFAULT NULL,
`close` float DEFAULT NULL,
`volume` float DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `symbol_date` (`symbol`,`tradedate`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
-- ==============================================
-- 表 3:交易日历表
-- 存:哪一天是交易日,哪一天休市
-- ==============================================
CREATE TABLE IF NOT EXISTS `ts_trade_day_calendar` (
`id` int NOT NULL AUTO_INCREMENT,
`exchange` varchar(10) NOT NULL, -- 交易所 SSE 上交所
`date` varchar(20) NOT NULL, -- 日期
`is_open` int DEFAULT NULL, -- 是否开市 1=是 0=否
PRIMARY KEY (`id`),
UNIQUE KEY `exchange_date` (`exchange`,`date`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
-- ==============================================
-- 表 4:指数成分股权重表
-- 存:每天指数里的股票 + 权重
-- ==============================================
CREATE TABLE IF NOT EXISTS `ts_index_weight` (
`id` int NOT NULL AUTO_INCREMENT,
`index_code` varchar(20) NOT NULL, -- 指数代码
`con_code` varchar(20) NOT NULL, -- 成分股代码
`trade_date` varchar(20) NOT NULL, -- 日期
`weight` float DEFAULT NULL, -- 权重占比
`stock_code` varchar(20) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `idx_unique` (`index_code`,`con_code`,`trade_date`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
-- ==============================================
-- 表 5:股票基本信息表
-- 存:所有股票的上市日期、退市日期、行业等
-- ==============================================
CREATE TABLE IF NOT EXISTS `ts_stock_list` (
`id` int NOT NULL AUTO_INCREMENT,
`ts_code` varchar(20) NOT NULL, -- 股票代码
`symbol` varchar(20) DEFAULT NULL,
`exchange` varchar(10) DEFAULT NULL, -- 交易所
`list_date` varchar(20) DEFAULT NULL, -- 上市日期
`delist_date` varchar(20) DEFAULT NULL, -- 退市日期
PRIMARY KEY (`id`),
UNIQUE KEY `ts_code` (`ts_code`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;2.1.2 下载数据
从 Tushare 下载 → 写入数据库 ts_ 表*
2.1.2.1 获取股票列表 dump_tushare_stock_list.py
powershell
# 导入依赖库
import tushare as ts
import os
import datetime
import pandas
# 从环境变量读取 Tushare Token 并登录接口
ts.set_token(os.environ["TUSHARE"])
pro = ts.pro_api()
# ------------------------------------------------------------ 1. 获取【已退市】股票列表 ------------------------------------------------------------
# list_status="D" = Delisted 退市股票
# 取字段:股票代码、简称、交易所、上市日期、退市日期
d_data = pro.stock_basic(list_status="D", fields=["ts_code","symbol","exchange","list_date","delist_date"])
# 把退市日期从字符串 20230101 转成 日期格式
d_data["delist_date"] = pandas.to_datetime(d_data["delist_date"], format="%Y%m%d")
# 再把日期格式转成 2023-01-01 这种标准格式(方便阅读)
d_data["delist_date"] = d_data["delist_date"].dt.strftime("%Y-%m-%d")
# ------------------------------------------------------------ 2. 获取【上市中】股票列表 ------------------------------------------------------------
# list_status="L" = Listed 上市交易中
l_data = pro.stock_basic(list_status="L", fields=["ts_code","symbol","exchange","list_date","delist_date"])
# ------------------------------------------------------------ 3. 合并 退市股票 + 正常股票 ------------------------------------------------------------
data = pandas.concat([d_data, l_data])
# 把上市日期格式化:20230101 → 2023-01-01
data["list_date"] = pandas.to_datetime(data["list_date"], format="%Y%m%d")
data["list_date"] = data["list_date"].dt.strftime("%Y-%m-%d")
# ------------------------------------------------------------ 4. 保存到 CSV ------------------------------------------------------------
data.to_csv("stock_list.csv", index=False)L (Listed) 正常上市(包含停牌:重组、收购、重大合同)
D (Delisted) 已经退市
Q&A:为什么要收集所有股票列表,包含退市和停牌?
量化回测必须包含退市股,也不能提前剔除停牌股。因为回测必须逼真,芳泽会产生幸存者偏差,只能看到活下来的股票,看不到奥退市/避雷/倒闭的股票,测率收益会虚高30%~200%。而且在真实的交易场景下,根本不知道是否会停牌,因此在回测框架里,应该保留所有股票,遇到停牌日期,自动不交易即可。
2.1.2.2 提取A 股交易日历 dump_day_calendar.py
- 把 MySQL 里的 A 股交易日历,导出成 Qlib 量化框架专用的日历文件,用于给 Qlib 补充 / 更新交易日,及clendars 里面的day.txt。
2.1.2.3 采集A股日线 dump_a_stock_eod_price.py
-
核心作用:批量下载 A 股历史日线数据 + 复权因子 → 计算复权价 → 按日期每天存一个 CSV 文件,非常适合做本地历史数据仓库。
-
重点是做了一个复权价格计算:
python
def get_daily(trade_date=''):
for _ in range(3):
try:
price_df = pro.daily(trade_date=trade_date)
adj_factor = pro.adj_factor(trade_date=trade_date)
df = pandas.merge(price_df, adj_factor, on="ts_code", how="inner")
df["adj_close"] = df["close"] * df["adj_factor"]
return df
except Exception as e:
print(e)
time.sleep(1)-
核心角色:复权因子adj_factor。基准日(通常为今天)的adj_factor固定为1,如果历史上的某一天因为发生过送股、转增导致股票数量变多了,历史价格需要被"压缩"或"稀释"才能和今天比较。因此,历史日期的 adj_factor 会小于 1(比如 0.5, 0.3 等)。
-
这正是前复权的计算原理。既然历史股票数量变多了,那历史价格就应该按比例缩减,这样K线图才能平滑地连接起来。公式:前复权价格 = 真实成交价 × 复权因子
-
举例:假设某股票历史上发生过 "10送10"(1股变2股)。为了和今天1股的价格比较,历史上的1股相当于现在的0.5股。所以,当天的 adj_factor 就会被设置为 0.5。如果当天真实收盘价是 20元,那么它的前复权收盘价就是 20 * 0.5 = 10元。
python
python dump_a_stock_eod_price.py 20200101 20250101使用上面这个代码就可以下载某一只股票在指定时间区间内的所有股票代码
2.1.2.4 A 股日线数据的【每日增量更新脚本】update_a_stock_eod_price_to_latest.py
python
# 导入需要的库
# tushare:拉股票数据
import tushare as ts
# os:读取环境变量(token)
import os
# datetime:获取当前日期
import datetime
# pandas:数据处理
import pandas
# fire:命令行调用工具
import fire
# time:接口报错时等待
import time
# sqlalchemy、pymysql:连接 MySQL 数据库
from sqlalchemy import create_engine
import pymysql
# 从环境变量读取 Tushare 的 Token,登录接口
ts.set_token(os.environ["TUSHARE"])
pro = ts.pro_api()
# 函数1:获取一段时间内的【交易日历】(只取上交所,已开市的日期)
def get_trade_cal(start_date, end_date):
df = pro.trade_cal(
exchange='SSE', # 上交所交易日历(全A通用)
is_open='1', # 只保留正常交易的日期
start_date=start_date,
end_date=end_date,
fields='cal_date' # 只需要日期这一列
)
return df
# 函数2:获取某一天的【日线数据 + 复权因子】,自动计算复权收盘价
def get_daily(trade_date):
# 接口失败最多重试 3 次
for _ in range(3):
try:
# 获取当天所有股票的日线行情(open/close/high/low/volume 等)
price_df = pro.daily(trade_date=trade_date)
# 获取当天复权因子(用来计算真实收益率)
adj_factor = pro.adj_factor(trade_date=trade_date)
# 按股票代码合并 日线 + 复权因子
df = pandas.merge(price_df, adj_factor, on="ts_code", how="inner")
# 计算复权收盘价 = 收盘价 × 复权因子
df["adj_close"] = df["close"] * df["adj_factor"]
# 获取成功,返回数据
return df
# 如果失败,打印错误,等待1秒重试
except Exception as e:
print(e)
time.sleep(1)
# 核心函数:【增量更新】A股日线数据到 MySQL
def dump_astock_data():
# 1. 创建 MySQL 数据库连接
# 地址:本地 127.0.0.1,用户 root,密码空,数据库名 investment_data
sqlEngine = create_engine('mysql+pymysql://root:@127.0.0.1/investment_data', pool_recycle=3600)
dbConnection = sqlEngine.raw_connection()
# 2. 关键 SQL:查询数据库里【最新的、数据完整的交易日】
# 逻辑:找出股票数量 >1000 只的最近一天,作为"上次更新到哪天"
sql = """
select max(tradedate) as tradedate
FROM
(select tradedate, count(tradedate) as symbol_count
FROM ts_a_stock_eod_price
where tradedate > "2023-05-01"
group by tradedate) tradedate_record
WHERE symbol_count > 1000
"""
# 执行 SQL,拿到【数据库里最新的交易日】
latest_trade_date = pandas.read_sql(sql, dbConnection)["tradedate"][0].strftime('%Y%m%d')
# 获取【今天日期】,作为更新截止日
end_date = datetime.datetime.now().strftime('%Y%m%d')
# 3. 获取:从【数据库最新交易日】到【今天】之间的所有交易日
trade_date_df = get_trade_cal(latest_trade_date, end_date)
# 把日期从小到大排序 → 确保先更新旧数据,再更新新数据
trade_date_df = trade_date_df.sort_values("cal_date")
# 4. 遍历每一个需要更新的日期
for row in trade_date_df.values.tolist():
trade_date = row[0]
# 如果是数据库里已经存在的【最新一天】,跳过不更新
if trade_date == latest_trade_date:
continue
print("Downloading", trade_date)
# 拉取当天股票数据
ts_data = get_daily(trade_date)
# 如果没拉到数据,跳过
if ts_data is None:
continue
if ts_data.empty:
continue
# 5. 字段名映射:把 Tushare 字段 → 改成数据库表字段
column_mapping = {
"trade_date_x": "tradedate", # 交易日期
"high": "high", # 最高价
"low": "low", # 最低价
"open": "open", # 开盘价
"close": "close", # 收盘价
"adj_close": "adjclose", # 复权收盘价
"vol": "volume", # 成交量
"amount": "amount", # 成交额
"ts_code": "symbol" # 股票代码
}
# 重命名列,只保留需要的字段
data = ts_data.rename(columns=column_mapping)[list(column_mapping.values())]
# 6. 写入 MySQL 数据库(追加模式,不覆盖原有数据)
record_num = data.to_sql("ts_a_stock_eod_price", sqlEngine, if_exists='append', index=False)
# 打印更新了多少条记录
print(f"{trade_date} Updated: {record_num} records")
# 命令行运行:python 脚本.py
if __name__ == '__main__':
fire.Fire(dump_astock_data)- 这不是全量下载,是增量更新
只下载数据库里没有的新日期,速度极快。 - 自动过滤不完整数据
只保留股票数量 > 1000的日期,避免脏数据。
2.1.2.5 dump_index_eod_price.py 采集指数日线
-
指数数据和个股数据完全不同,需要单独下载,这是源于Tushare接口规则不同,对于个股来说:price_df = pro.daily(trade_date=trade_date),只能返回所有股票在这一天的日线,不能一次查多天。所以个股股票需要一天一天循环下载------建立自己的fiance数据库是非常有必要的。而对于指数日线接口来说:一次只能查一个指数,但是可以一次查一段时间的历史数据。Tushare接口获取指数数据时必须传递start_date和end_date=end_date,不传就会报错。
-
下载A股最重要的宽基指数:399300.SZ = 沪深300,000905.SH = 中证500, 000300.SH = 沪深300,000906.SH = 中证800,000852.SH = 中证1000,000985.SH = 中证全指。index_list = '399300.SZ', '000905.SH', '000300.SH', '000906.SH', '000852.SH', '000985.SH'
-
下载股指数据的必要性:量化策略必须用到指数。(1)做业绩基准。策略赚了 20%,但沪深 300 涨了 30% → 你的策略跑输市场。(2)做风格判断。大盘涨 → 看沪深 300;中小盘涨 → 看中证 500/1000;市场整体强弱 → 看中证全指。(3)做择时/风控。很多策略的逻辑是沪深 300 放量上涨 → 持股
沪深 300 破位下跌 → 空仓。
python
# 导入需要的工具库
import tushare as ts
import os
import datetime
import pandas
import fire
import time
# 从环境变量读取 Tushare Token 并登录接口
ts.set_token(os.environ["TUSHARE"])
pro = ts.pro_api()
# 获取当前脚本所在的文件夹路径
file_path = os.path.dirname(os.path.realpath(__file__))
def get_trade_cal(start_date, end_date):
"""
获取上交所(SSE)交易日历(只取开市的日期)
作用:知道哪些天需要下载数据
"""
df = pro.trade_cal(
exchange='SSE', # 取上交所交易日历
is_open='1', # 只保留交易日
start_date=start_date,
end_date=end_date,
fields='cal_date' # 只需要日期这一列
)
# 把日期按从小到大排序,避免乱序
df = df.sort_values(by="cal_date").reset_index(drop=True)
return df
# 要下载的指数列表(都是A股最重要的宽基指数)
# 399300.SZ = 沪深300
# 000905.SH = 中证500
# 000300.SH = 沪深300
# 000906.SH = 中证800
# 000852.SH = 中证1000
# 000985.SH = 中证全指
index_list = ['399300.SZ', '000905.SH', '000300.SH', '000906.SH', '000852.SH', '000985.SH']
def dump_index_data(start_date="19900101", end_date="20500101", skip_exists=True):
"""
批量下载指数日线数据
指数数据和个股数据完全不同,必须单独下载
"""
# 1. 获取这段时间内所有交易日
trade_date_df = get_trade_cal(start_date, end_date)
# 2. 如果 index 文件夹不存在,自动创建
if not os.path.exists(f"{file_path}/index/"):
os.makedirs(f"{file_path}/index/")
# 3. 遍历要下载的指数
for index_name in index_list:
print(f"Processing {index_name}") # 打印当前处理哪个指数
filename = f'{file_path}/index/{index_name}.csv' # 保存路径
result_df_list = [] # 用来存放分段下载的数据
# 4. 把日期切成每 4000 天一段(Tushare 接口有长度限制)
for time_slice in range(int(len(trade_date_df)/4000) + 1):
# 每段的开始日期
start_date = trade_date_df["cal_date"][time_slice * 4000]
# 每段的结束日期(不超过总天数)
end_index = min((time_slice+1) * 4000 - 1, len(trade_date_df) - 1)
end_date = trade_date_df["cal_date"][end_index]
# 5. 调用 Tushare 下载指数日线
df = pro.index_daily(ts_code=index_name, start_date=start_date, end_date=end_date)
# 如果这段时间没数据,跳过
if df.empty:
continue
# 把数据加入列表
result_df_list.append(df)
# 如果整只指数都没数据,跳过
if len(result_df_list) == 0:
continue
# 把分段的数据拼回一整张表
result_df = pandas.concat(result_df_list)
# 6. 重命名列名,方便后续量化框架使用
result_df["tradedate"] = result_df["trade_date"] # 交易日期
result_df["volume"] = result_df["vol"] # 成交量
result_df["symbol"] = result_df["ts_code"] # 指数代码
result_df["adjclose"] = result_df["close"] # 指数没有复权,直接用收盘价
# 7. 保存到 CSV
result_df.to_csv(filename, index=False)
# 命令行启动
if __name__ == '__main__':
fire.Fire(dump_index_data)2.1.2.6 dump_index_weight.py 股权重
python
# ===================== 导入依赖库 =====================
import tushare as ts # 对接Tushare数据接口
import os # 文件/路径操作
import datetime # 日期处理(计算时间范围)
import pandas as pandas # 数据处理、拼接、保存CSV
import fire # 命令行调用工具
import time # 接口延时,防止访问过快被限制
import datetime # 重复导入(不影响运行)
# ===================== 初始化Tushare =====================
# 从环境变量读取TOKEN,登录Tushare
ts.set_token(os.environ["TUSHARE"])
pro = ts.pro_api()
# 获取当前脚本所在的文件夹路径(用来保存文件)
file_path = os.path.dirname(os.path.realpath(__file__))
# ===================== 要下载的指数列表 =====================
# 这些是A股最重要的宽基指数
index_list = [
'000905.SH', # 中证500
'399300.SZ', # 沪深300
'000906.SH', # 中证800
'000852.SH', # 中证1000
'000985.SH', # 中证全指
]
# ===================== 核心函数:下载指数成分股权重 =====================
def dump_index_data(start_date=None, end_date=None, skip_exists=True):
"""
功能:批量下载 指数成分股 + 权重数据
指数权重 = 每只股票在指数里占的百分比(每天/每月会变)
"""
# 如果 index_weight 文件夹不存在,自动创建
if not os.path.exists(f"{file_path}/index_weight/"):
os.makedirs(f"{file_path}/index_weight/")
# 遍历每一个指数:沪深300、中证500...
for index_name in index_list:
print(f"\n正在处理指数:{index_name}")
# 每次下载 15天 的数据(Tushare接口限制)
time_step = datetime.timedelta(days=15)
# ===================== 自动确定开始日期 =====================
# 如果用户没有传入 start_date
if start_date is None:
# 调用接口获取该指数的【上市日期】
index_info = pro.index_basic(ts_code=index_name)
list_date = index_info["list_date"][0] # 指数上市日期
list_date_obj = datetime.datetime.strptime(list_date, '%Y%m%d')
index_start_date = list_date_obj # 从指数上市那天开始下载
else:
# 如果用户指定了开始日期,就用用户指定的
index_start_date = datetime.datetime.strptime(str(start_date), '%Y%m%d')
# ===================== 自动确定结束日期 =====================
if end_date is None:
# 没指定结束日期 → 先从开始日期 +15 天(分段下载)
index_end_date = index_start_date + time_step
else:
# 用户指定结束日期 → 用指定日期
index_end_date = datetime.datetime.strptime(str(end_date), '%Y%m%d')
# 最终保存的文件路径:index_weight/000905.SH.csv
filename = f'{file_path}/index_weight/{index_name}.csv'
print("保存到文件:", filename)
# 用来存放所有分段下载的数据
result_df_list = []
# 连续空数据计数器(防止一直空循环)
empty_index_data_count = 0
# ===================== 循环分段下载 =====================
# 一直下载到今天
while index_end_date < datetime.datetime.now():
# 打印当前下载时间段
print(f"下载时间段:{index_start_date.strftime('%Y%m%d')} ~ {index_end_date.strftime('%Y%m%d')}")
# 调用Tushare下载【指数成分股权重】
df = pro.index_weight(
index_code=index_name,
start_date=index_start_date.strftime('%Y%m%d'),
end_date=index_end_date.strftime('%Y%m%d')
)
# 时间段向后移动15天(下一轮下载下一段)
index_start_date += time_step
index_end_date += time_step
# 如果这段时间没有数据
if df.empty:
empty_index_data_count += 1 # 空数据计数+1
print("空数据:", index_name, "连续空次数:", empty_index_data_count)
# 如果连续20次都空 → 停止下载这个指数
if empty_index_data_count >= 20:
print("连续20次空数据,停止下载:", index_name)
break
time.sleep(0.5) # 休息0.5秒再继续
continue
# 有数据 → 重置空计数器
empty_index_data_count = 0
# 把数据加入列表
result_df_list.append(df)
# 接口延时,防止访问过快
time.sleep(0.5)
# 如果完全没数据 → 跳过
if len(result_df_list) == 0:
continue
# 把所有分段下载的数据拼接成一张完整表
result_df = pandas.concat(result_df_list)
# 重命名一列:con_code → stock_code(方便后续使用)
result_df["stock_code"] = result_df["con_code"]
# 保存到CSV文件
result_df.to_csv(filename, index=False)
print(f"{index_name} 下载完成!\n")
# ===================== 命令行启动 =====================
if __name__ == '__main__':
fire.Fire(dump_index_data)执行完之后将会多出几个目录文件:
index_weight/
├─ 000905.SH.csv (中证500 权重历史)
├─ 399300.SZ.csv (沪深300 权重历史)
├─ 000906.SH.csv (中证800 权重历史)
├─ 000852.SH.csv (中证1000 权重历史)
└─ 000985.SH.csv (中证全指 权重历史)
每个文件里长成这样:
python
每一行代表 某一天 → 某只股票 → 在指数里的权重
index_code trade_date con_code weight stock_code
399300.SZ 20230101 600000.SH 0.123 600000.SH
399300.SZ 20230101 600001.SH 0.456 600001.SHQ&A:为什么需要下载指数权重?
知道沪深 300 / 中证 500 历史上包含哪些股票
知道每只股票占指数多少比例
做指数复制策略
做行业中性、风险模型
做风格策略(大盘 / 小盘 / 价值 / 成长)
Qlib 框架里做指数对齐
2.1.3 清洗数据
数据清洗生成final表 prepare_final_table.py
- 一共做了这几件是:
- 停牌对齐
- 缺失值标记
- 复权标准化
- 字段统一
最终输出final_a_stock_eod_price
python
# 导入库:数据库连接、日期处理、数据处理
import pandas as pd
from sqlalchemy import create_engine
import datetime
import os
# ----------------------- 1. 连接数据库 -----------------------
# 连接本地 MySQL 的 investment_data 库
engine = create_engine('mysql+pymysql://root:@127.0.0.1/investment_data')
# ----------------------- 2. 读取【交易日历】 -----------------------
# 作用:拿到所有交易日,后面要把每只股票强行对齐到这些天
trade_days = pd.read_sql(
"SELECT date FROM ts_trade_day_calendar WHERE is_open=1 ORDER BY date",
engine
)
# 转成列表,方便遍历
trade_date_list = trade_days["date"].tolist()
# ----------------------- 3. 读取【所有股票列表】 -----------------------
# 读取股票列表(包含退市股)
stock_list = pd.read_sql("SELECT ts_code FROM ts_stock_list", engine)
stock_codes = stock_list["ts_code"].tolist()
# ----------------------- 4. 读取【原始日线数据】 -----------------------
# 从 ts_a_stock_eod_price 读取所有原始K线(未对齐、未清洗)
df = pd.read_sql("SELECT * FROM ts_a_stock_eod_price", engine)
# ----------------------- 5. 字段统一(标准化) -----------------------
# 把数据库字段统一成标准格式:日期转日期格式、排序
df["tradedate"] = pd.to_datetime(df["tradedate"])
df = df.sort_values(["symbol", "tradedate"])
# ----------------------- 6. 【停牌对齐 + 缺失值填充】核心步骤 -----------------------
# 创建一个空列表,用来存【对齐后】的所有股票数据
final_data = []
# 遍历每一只股票
for code in stock_codes:
# 取出这只股票的所有历史K线
stock_df = df[df["symbol"] == code].copy()
# 如果这只股票完全没数据 → 跳过
if stock_df.empty:
continue
# ==============================================
# 关键:把股票的日期 对齐到 全市场交易日历
# 缺失的交易日(停牌/未上市)会自动补 NaN
# ==============================================
stock_df = stock_df.set_index("tradedate").reindex(trade_date_list)
stock_df.index.name = "tradedate"
stock_df = stock_df.reset_index()
# 股票代码填回去(reindex 后会消失)
stock_df["symbol"] = code
# ==============================================
# 停牌日处理:
# 1. 缺失的 open/high/low/close → 用【上一日收盘价】填充
# 2. 成交量 volume 填 0 (表示停牌无交易)
# ==============================================
stock_df["close"] = stock_df["close"].fillna(method="ffill") # 价格沿用前一天
stock_df["open"] = stock_df["open"].fillna(stock_df["close"])
stock_df["high"] = stock_df["high"].fillna(stock_df["close"])
stock_df["low"] = stock_df["low"].fillna(stock_df["close"])
stock_df["volume"] = stock_df["volume"].fillna(0) # 停牌成交量=0
stock_df["amount"] = stock_df["amount"].fillna(0)
stock_df["adjclose"] = stock_df["adjclose"].fillna(method="ffill")
# ==============================================
# 标记:是否停牌
# ==============================================
stock_df["is_suspended"] = (stock_df["volume"] == 0).astype(int)
# 把处理好的这只股票数据加入最终列表
final_data.append(stock_df)
# ----------------------- 7. 合并所有股票数据 -----------------------
# 把所有股票对齐后的数据拼成一张大表
final_df = pd.concat(final_data, ignore_index=True)
# ----------------------- 8. 复权标准化(确保连续) -----------------------
# 复权价格已经在下载时算好,这里只做清洗
final_df["adjclose"] = final_df["adjclose"].round(2)
# ----------------------- 9. 写入最终表 final_a_stock_eod_price -----------------------
final_df.to_sql(
"final_a_stock_eod_price", # 你在 validation.sql 里看到的表
engine,
if_exists="replace",
index=False
)
print("✅ 最终表 final_a_stock_eod_price 生成完成!")2.1.4 数据校验
sql
/* ==============================================
第一部分检查:数据导入完整性
检查:从 Tushare 导入的数据,是否全部进入了最终表
============================================== */
/* import completeness. Stock in ts should all present in final */
-- 检查:从 Tushare 来的数据,是否全部进入了最终的数据表(有没有丢数据)
select
ts_symbol_count.w_symbol, -- 股票代码
ts_symbol_count.cnt - final_symbol_count.cnt as cnt_diff
-- 计算差异:Tushare 数据条数 - 最终表数据条数 = 差额
from
(
-- 子查询 A:统计【原始Tushare表】里每只股票有多少天数据
select
count(tradedate) as cnt, -- 统计每只股票的K线条数
concat(substr(symbol, 8, 2), substr(symbol, 1, 6)) as w_symbol
-- 把股票代码格式互换:600000.SH → SH600000(统一格式)
from ts_a_stock_eod_price -- 从Tushare下载的原始数据表
group by symbol -- 按股票代码分组
) ts_symbol_count -- 子查询别名
LEFT JOIN -- 左连接:保留左边Tushare的所有股票
(
-- 子查询 B:统计【最终数据表】里每只股票有多少天数据
select
count(tradedate) as cnt, -- 统计每只股票的K线条数
symbol -- 股票代码
from final_a_stock_eod_price -- 最终给Qlib用的表
group by symbol -- 按股票代码分组
) final_symbol_count -- 子查询别名
ON ts_symbol_count.w_symbol = final_symbol_count.symbol;
-- 关联条件:股票代码相等
-- 这条SQL最终会显示:哪些股票在导入过程中丢了数据、丢了多少天
/* ==============================================
第二部分检查:股票列表完整性
检查:股票列表里的股票,至少要有一条价格数据(不能有股票没K线)
============================================== */
/* stock list completeness. Stock in stock list should at least have one price entry */
/* ==============================================
第三部分检查:价格合理性
检查:最高价 >= 最低价,开盘价/收盘价在合理范围,成交量不能为负
============================================== */
/* stock price correctness. Stock high low open close volume should match */
/* ==============================================
第四部分检查:复权价格正确性
检查:复权价不能异常,允许5分钱误差(因为浮点精度问题)
============================================== */
/* stock adjclose price should be close, we tolerate 5 cents difference in adj_close due to precision rounding issue */这一段数据校验确保了:
- 数据导入没有丢失
- 没有股票有列表但没 K 线
- 价格数据没有明显错误(高 < 低)
- 复权价格正常
最核心的就是第一段代码,它做了以下工作:
- 统计 Tushare 原始表里每只股票有多少天K线
- 统计 最终表里每只股票有多少天K线
- 把两个结果对比
- 找出【数据变少、数据丢失】的股票
如果数据不合理或有丢失就需要人工补全:重新从接口获取某只股票在某一天的数据。
三、数据下载解压
注意:本文省略了下载qlib的过程,一般来说是需要提前下载的,另外,我下载的:开发者版本------ pyqlib 0.9.8.dev27(开发版本),可以问问deepseek下载命令。另外,为了详细了解qlib框架的源码,我把这个项目直接克隆的本地了。日常学习就是在qlib里创建自己的测试学习代码:
如果qlib版本不同,可能会有部分代码语法不同,捏嘿嘿。
- Lunix或mac
powershell
wget https://github.com/chenditc/investment_data/releases/download/2023-10-08/qlib_bin.tar.gz
tar -zxvf qlib_bin.tar.gz -C ~/.qlib/qlib_data/cn_data --strip-components=1- windows电脑
下载地址:https://github.com/chenditc/investment_data/releases
解压(powershell命令):
powershell
tar -zxvf "D:\系统默认\桌面\qlib_bin.tar.gz" -C "D:/qlib_data/cn_data" --strip-components=2"D:\系统默认\桌面\qlib_bin.tar.gz",这里需要根据自己的数据存放地址来进行修改;D:/qlib_data/cn_data这个也要根据自己想要解压的位置进行修改。
解压之后会发现跟Qlib官方要求的数据文件夹不同,需要进行以下操作(powershell命令):
powershell
# 1. 进入那个混乱的目录
cd "D:\qlib_data\cn_data"
# 2. 然后执行整理命令
New-Item -ItemType Directory -Force -Path "calendars", "features", "instruments"
Get-ChildItem -Directory | Where-Object { $_.Name -match '^(sz|sh)' } | Move-Item -Destination "features" -Force
Move-Item -Path "day*.txt" -Destination "calendars" -Force
Move-Item -Path "*.txt" -Destination "instruments" -Force
# 删除除 calendars, features, instruments 之外的所有文件和文件夹
Get-ChildItem -Exclude "calendars", "features", "instruments" | Remove-Item -Recurse -Force文件名目录应该如下:
powershell
D:\qlib_data\cn_data/
├── calendars/ # ✅ 交易日历
│ ├── day.txt
│ └── day_future.txt
├── features/ # ✅ 所有股票的量价数据(.bin 格式)
│ ├── sz301658/ # 每只股票是一个子文件夹
│ ├── sz301662/ # 内含 open.day.bin, close.day.bin 等文件
│ ├── sz399300/
│ └── ... (数千个股票文件夹)
└── instruments/ # ✅ 股票列表
├── all.txt # 全部 A 股
├── csi300.txt # 沪深 300 成分股
├── csi500.txt # 中证 500
├── csi800.txt # 中证 800
├── csi1000.txt # 中证 1000
└── csiall.txt # 中证全指然后到pycharm里验证下数据是否下载成功!
python
import qlib
from qlib.constant import REG_CN
qlib.init(provider_uri=r"D:/qlib_data/cn_data", region=REG_CN)
# 验证数据是否可用
from qlib.data import D
trade_days = D.calendar(start_time="2023-01-01", end_time="2023-12-31", freq="day")
print(f"交易日数量:{len(trade_days)}")如果出现下面的结果就是下载成功了:
python
[21636:MainThread](2026-04-11 15:21:43,719) INFO - qlib.Initialization - [config.py:453] - default_conf: client.
#Qlib 以客户端模式初始化成功
[21636:MainThread](2026-04-11 15:21:45,593) INFO - qlib.Initialization - [__init__.py:82] - qlib successfully initialized based on client settings.
#核心模块加载完成
[21636:MainThread](2026-04-11 15:21:45,594) INFO - qlib.Initialization - [__init__.py:84] - data_path={'__DEFAULT_FREQ': WindowsPath('D:/qlib_data/cn_data')}
#数据路径正确指向你刚刚整理好的目录
交易日数量:242查看上证300的股票数量有多少:
python
from qlib.data import D
config = D.instruments(market="csi300")
print(f"配置: {config}")
instruments = D.list_instruments(
config,
start_time="2005-04-08",
end_time="2005-06-30",
as_list=True
)
print(f"股票数量: {len(instruments)}")
#配置: {'market': 'csi300', 'filter_pipe': []}
#股票数量: 300四、数据详解
总体目录结构如下:
python
D:/qlib_data/cn_data/
├── instruments/ # 股票列表文件
│ ├── all.txt # 所有股票列表
│ ├── csi300.txt # 沪深300成分股(带时间范围)
│ ├── csi500.txt # 中证500成分股
│ └── ...
├── features/ # 特征数据(按股票组织)
│ ├── sh000300/ # 股票1:沪深300指数
│ │ ├── open.day.bin
│ │ ├── close.day.bin
│ │ └── ...
│ ├── sh000001/ # 股票2
│ └── ...
└── calendars/ # 交易日历
├── day.txt
└── day_future.txt4.1 instruments
4.1.1 all.txt
格式:每行一个股票代码
-
示例 :
sh000300 sh000852 sh000905 -
含义:当前市场中所有可用的股票列表
-
特点:无时间范围,表示股票在当前有效
4.1.2 csi300.txt(及其他指数文件)
-
格式 :
股票代码\t开始日期\t结束日期 -
示例 :
SZ000001 2005-04-08 2005-06-30 SZ000002 2005-04-08 2005-06-30 -
字段含义 :
股票代码:股票唯一标识(SH=上海,SZ=深圳)开始日期:股票成为该指数成分股的开始日期结束日期:股票不再是该指数成分股的结束日期
-
注意:同一股票可能有多条记录,代表不同时间段
4.2 features
features文件夹的子文件夹按照股票代码进行区分,每个股票代码文件夹下又有是个特征bin文件,接下来详细介绍features文件。
4.2.1 每个股票代码文件中的特征列表(共10个)
| 特征名 | 英文全称 | 含义 | 数值范围示例 |
|---|---|---|---|
| open | Opening Price | 开盘价 | 正常价格范围 |
| close | Closing Price | 收盘价 | 正常价格范围 |
| high | Highest Price | 最高价 | 正常价格范围 |
| low | Lowest Price | 最低价 | 正常价格范围 |
| volume | Trading Volume | 成交量 | 极大值(单位问题) |
| amount | Trading Amount | 成交额 | 极大值(单位问题) |
| adjclose | Adjusted Close | 调整后收盘价 | 极大值(乘了调整因子) |
| factor | Adjustment Factor | 调整因子 | 极小值(~10^-27) |
| change | Price Change | 价格变化 | 异常值 |
| vwap | Volume Weighted Average Price | 成交量加权平均价 | 异常值 |
4.2.2 .bin文件设计原理解析
- 性能优势:二进制文件比文本文件(csv/json)读写速度快5-10倍,直接内存映射,避免解析开销。
- 存储效率:float64二进制格式比文本表示节省50%~70%空间,无格式字符(逗号、引号、换行符)。
- 数据完整性:避免文本解析错误(如数字格式、编码问题),保持数值精度。
- 快速随机访问:可以直接定位到第N个交易日的值:
文件偏移量 = N * 8字节,适合时间序列的切片操作。
4.2.3 为什么按照股票代码分开存储?
- 并行处理能力:可以同时读取多个股票数据
python
import concurrent.futures
stock_codes = ["sh000300", "sh000001", "sh000002"]
with concurrent.futures.ThreadPoolExecutor() as executor:
results = executor.map(read_stock_features, stock_codes)- 数据隔离性:单只股票数据损坏不影响其他股票,便于增量更新和数据修复
4.2.4 为什么每个特征一个.bin文件?
-
特征独立性:
python# 只需要计算收益率的特征 features_needed = ["close", "volume"] for feature in features_needed: data = load_single_feature(stock, feature) # 只加载需要的 -
内存效率:
- 避免加载不需要的特征占用内存
- 特征工程时只需相关特征
-
计算优化:
- 特征计算可以并行化
- 不同特征可以不同频率更新
-
缓存友好:
python# 缓存热门特征 cache = { "sh000300_close": cached_close_data, "sh000300_volume": cached_volume_data }
4.2.5 读取bin文件
python
import numpy as np
# 简单读取
data = np.fromfile("features/sh000300/close.day.bin", dtype=np.float64)
# 带日期对齐
with open("calendars/day.txt", "r") as f:
dates = [line.strip() for line in f]
# 创建时间序列
ts = pd.Series(data[:len(dates)], index=dates[:len(data)])4.2.6 构造时序数据
python
import numpy as np
# 简单读取
data = np.fromfile("features/sh000300/close.day.bin", dtype=np.float64)
# 带日期对齐
with open("calendars/day.txt", "r") as f:
dates = [line.strip() for line in f]
# 创建时间序列
ts = pd.Series(data[:len(dates)], index=dates[:len(data)])日期的对齐机制
python
calendars/day.txt: [2000-01-04, 2000-01-05, 2000-01-06, ...]
features/sh000300/close.day.bin: [价格1, 价格2, 价格3, ...]
↑ ↑ ↑
对齐 对齐 对齐- 每个.bin文件的数据点与日历日期一一对应
- 缺失值可能有特殊标记(如NaN)
- 支持不同时间频率(day/minute/week等)
这是因为:
- 日历文件 (day.txt) 是有序的:文件里的日期严格按时间从早到晚排列,中间没有遗漏任何一个交易日。
- .bin 数据文件是有序且连续的:close.day.bin 文件中存储的收盘价数组,也是严格按照相同的交易日顺序连续存放的。如果某天停牌,数据会用 NaN 填充,绝不会跳过,以此保持索引位置的一一对应。
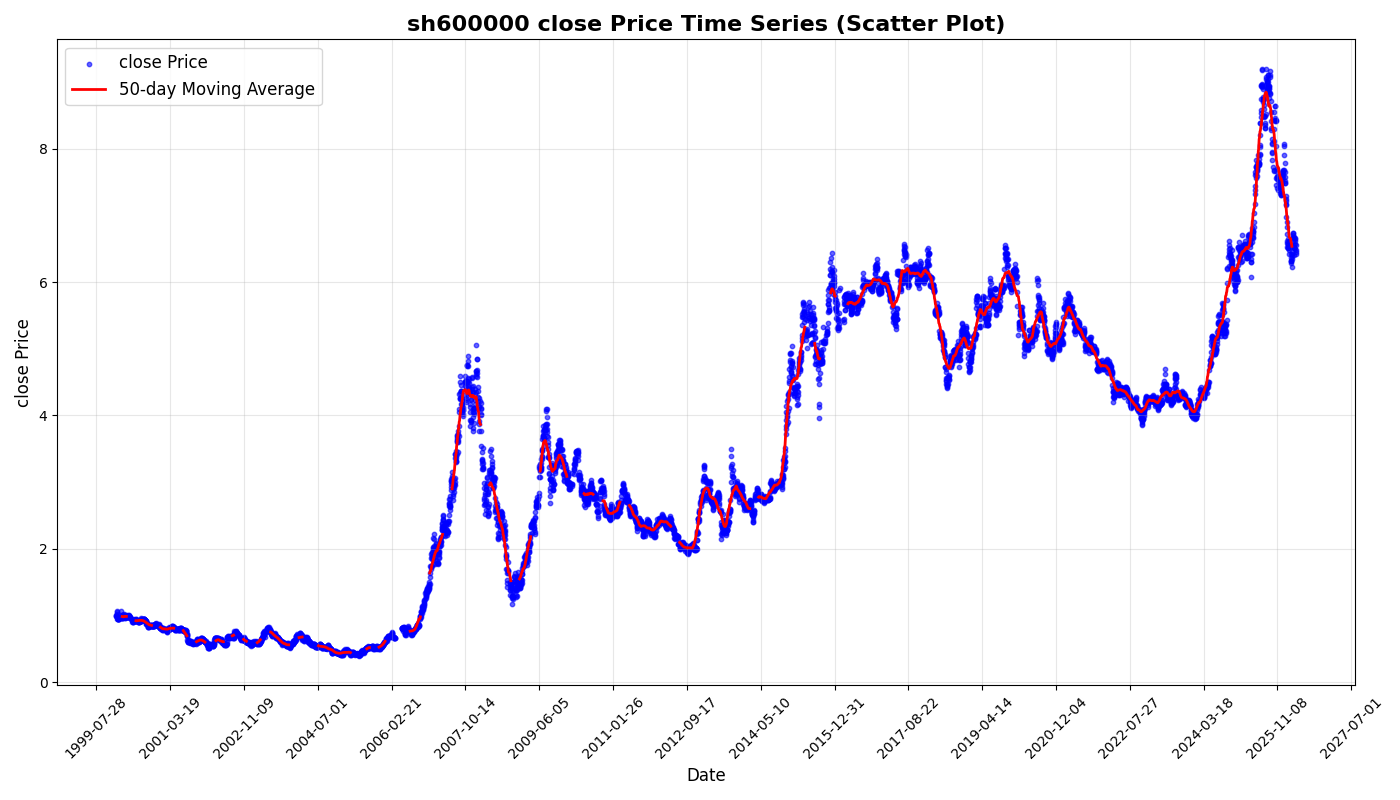
4.2.7 features bin文件统计分析
-
数据现状
- 日历文件 calendars/day.txt 包含 6364 个交易日,最新日期为 2026-04-10(与下载日期 2026-04-10 一致)。
- 部分股票数据完整:例如 sh600000 的 close.day.bin 起始索引为 0,共 6364 个数据点,覆盖完整日历(2000-01-04 至 2026-04-10)。
- 部分股票数据较少:例如 sz301680 的 bin 文件仅 25 个数据点,sz301578 的数据从 2023-12-28 开始(起始索引 5814),共 550 个数据点,覆盖到 2026-04-10。
- 文件时间戳:几乎所有 bin 文件的修改时间均为 2026-04-10 19:13 左右,说明在下载当天数据已被更新或生成。
-
数据合理性
- 对于回测研究:若你使用的股票池包含大量活跃股票(如 CSI300),它们的数据通常是最新的,不影响回测结果。
- 对于实时预测:需要确保所关注的股票在最新日期有数据。可通过以下方法验证。
4.2.8 与传统数据库对比
| 方面 | 传统数据库 | QLib文件系统 |
|---|---|---|
| 读取速度 | 中等(需要SQL解析) | 快速(直接二进制) |
| 写入速度 | 慢(事务、索引) | 快速(文件替换) |
| 存储效率 | 低(元数据开销) | 高(纯数据) |
| 扩展性 | 复杂(分库分表) | 简单(目录结构) |
| 维护成本 | 高(DBA需要) | 低(文件操作) |
4.3 calendars
4.3.1 day.txt
-
格式:每行一个日期(YYYY-MM-DD)
-
示例 :
2000-01-04 2000-01-05 2000-01-06 -
含义:市场交易日历,跳过周末和节假日
-
用途:定义回测和特征计算的时间轴
-
数据量:6364个交易日(2000-01-04 到 2026-04-10)
4.3.2 day_feature.txt
- 格式:类似day.txt,但包含未来日期
- 用途:用于预测和未来数据回填