备考面试的过程里,我发现一件有意思的事:很多题目表面上考的是不同的知识点,但解题的起点其实是一样的------先搞清楚题目的结构,再选对应的模型。
后来我把这个过程提炼成四个问题,每次看到新题目,不管是面试题还是实际业务需求,都先把这四个问题过一遍。这篇文章把这四个问题展开来讲,每个配上真实的代码场景,是我整理这套思考框架的过程记录。
为什么需要判断框架
先说一个让我意识到这件事重要性的场景。
同样是"批量操作",有人问的是"批量审批,允许部分失败",有人问的是"批量上传,限制同时最多 3 个"。表面上都是批量,但前者的核心是容错并发 (Promise.allSettled),后者的核心是背压控制(并发池)。如果只靠关键词匹配,看到"批量"就想到同一个答案,就会答错。
判断框架的作用是:在选答案之前,先把题目的维度看清楚。
四个问题的完整决策树
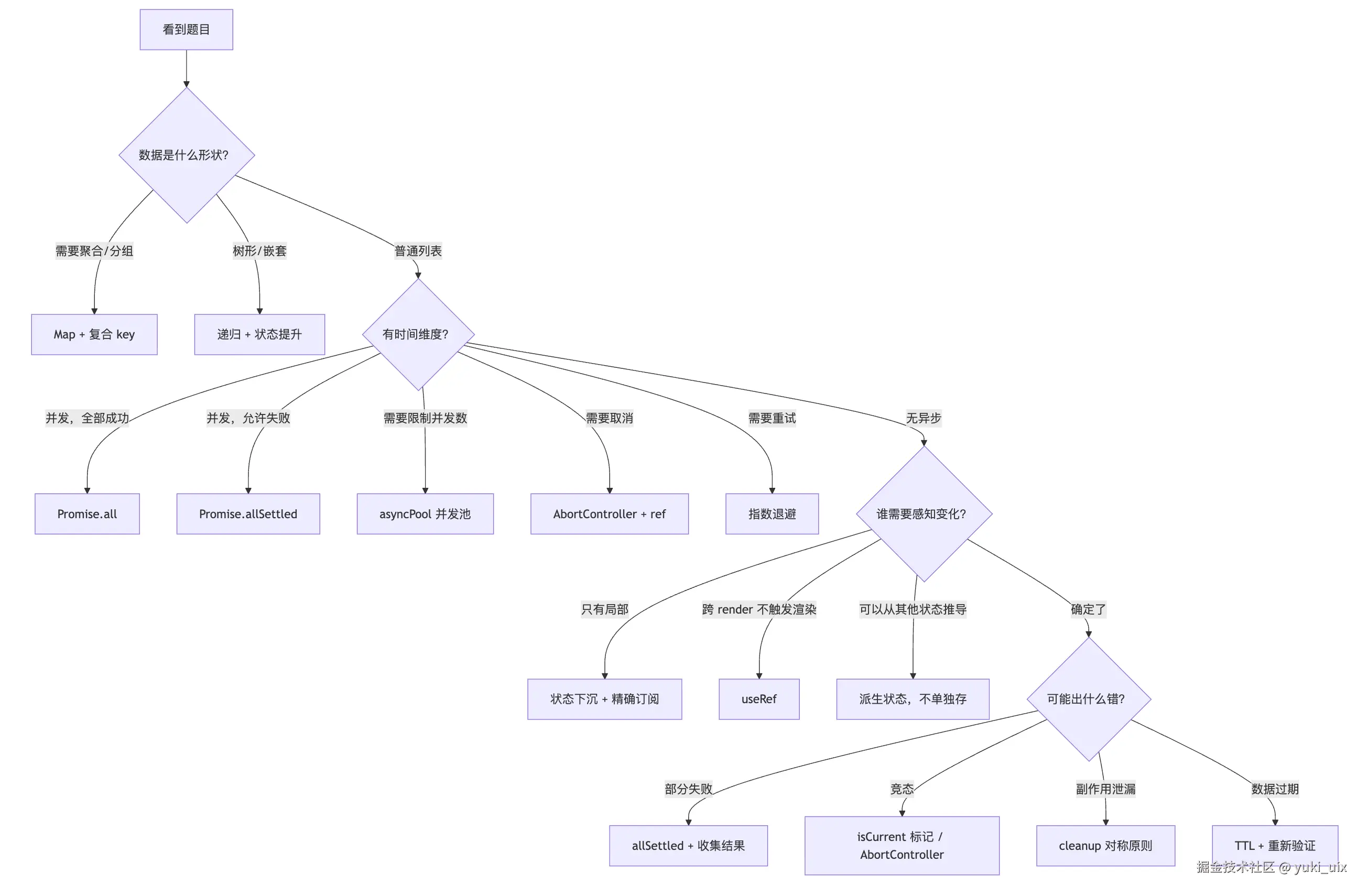
问题一:这里的数据是什么形状?
数据的形状决定了应该用什么数据结构和遍历方式。常见的两个场景:
场景 A:需要聚合/分组 → Map + 复合 key
触发信号是"按 X 统计 Y"、"分组"、"去重后计数"。
javascript
// 环境:浏览器 / Node.js
// 场景:统计每个用户每个月的消费金额
const records = [
{ userId: 'u1', month: '2024-01', amount: 300 },
{ userId: 'u1', month: '2024-01', amount: 200 },
{ userId: 'u1', month: '2024-02', amount: 150 },
{ userId: 'u2', month: '2024-01', amount: 400 },
];
// ✅ 复合 key + Map:O(1) 查询,结构清晰
function aggregateByUserAndMonth(records) {
const map = new Map();
for (const record of records) {
const key = `${record.userId}|${record.month}`;
map.set(key, (map.get(key) ?? 0) + record.amount);
}
return map;
}
const result = aggregateByUserAndMonth(records);
console.log(result.get('u1|2024-01')); // 500
console.log(result.get('u2|2024-01')); // 400为什么不用嵌套 reduce? 嵌套 reduce 能跑,但读起来难受------你要先理解"外层在做什么"再理解"内层在做什么"。Map + 复合 key 把两个维度拍平,逻辑是线性的,写的人和读的人都轻松。
场景 B:树形/嵌套结构 → 递归 + 状态提升
触发信号是"组织架构"、"分类目录"、"嵌套评论"。
javascript
// 环境:浏览器(React)
// 场景:部门树,展开状态集中管理,子节点只负责渲染
// 关键决策:展开状态存在父组件的 Set 里,不存在每个节点自己身上
// 好处:全部展开/折叠只需要操作父组件的 Set,不需要广播给所有节点
function DeptTree({ data }) {
const [expandedIds, setExpandedIds] = useState(new Set());
const toggle = useCallback((id) => {
setExpandedIds((prev) => {
const next = new Set(prev);
next.has(id) ? next.delete(id) : next.add(id);
return next;
});
}, []);
return data.map((node) => (
<DeptNode
key={node.id}
node={node}
expandedIds={expandedIds}
onToggle={toggle}
/>
));
}
// 递归节点:纯渲染,不持有状态
const DeptNode = React.memo(function DeptNode({ node, expandedIds, onToggle }) {
const isExpanded = expandedIds.has(node.id);
const hasChildren = node.children?.length > 0;
return (
<div style={{ paddingLeft: 16 }}>
<div onClick={() => hasChildren && onToggle(node.id)}>
{hasChildren ? (isExpanded ? '▼' : '▶') : '·'} {node.name}
</div>
{isExpanded && hasChildren && node.children.map((child) => (
<DeptNode
key={child.id}
node={child}
expandedIds={expandedIds}
onToggle={onToggle}
/>
))}
</div>
);
});问题二:这里的时间维度是什么?
"时间维度"是指:这个操作有没有等待、顺序、取消、重试的需求?有时间维度的题,核心都在异步控制。
场景 A:多个操作需要同时进行 → 并发模型
javascript
// 环境:浏览器 / Node.js
// 场景:页面初始化需要同时请求三个接口
// 需要全部成功才能渲染 → Promise.all(一个失败全部失败)
async function initDashboard() {
const [user, orders, stats] = await Promise.all([
fetchUser(),
fetchOrders(),
fetchStats(),
]);
return { user, orders, stats };
}
// 允许部分失败,每条都要有结果 → Promise.allSettled
async function batchExport(orderIds) {
const tasks = orderIds.map((id) =>
exportOrder(id)
.then(() => ({ id, ok: true }))
.catch((err) => ({ id, ok: false, reason: err.message }))
);
const results = await Promise.allSettled(tasks);
return results.map((r) => (r.status === 'fulfilled' ? r.value : r.reason));
}场景 B:需要限制并发数 → 并发池(背压控制)
javascript
// 环境:浏览器 / Node.js
// 场景:批量上传 100 个文件,同时最多 3 个并发
// 核心思路:维护一个"正在执行"的集合,完成一个立刻补充下一个
async function asyncPool(limit, tasks) {
const results = new Array(tasks.length);
const executing = new Set();
for (let i = 0; i < tasks.length; i++) {
const task = tasks[i];
const p = Promise.resolve().then(() => task()).then((result) => {
results[i] = result;
executing.delete(p); // 完成后从执行集合移除
});
executing.add(p);
// 达到上限时,等待任意一个完成再继续
if (executing.size >= limit) {
await Promise.race(executing);
}
}
// 等待所有剩余任务完成
await Promise.all(executing);
return results;
}
// 使用示例
const uploadTasks = files.map((file) => () => uploadFile(file));
const results = await asyncPool(3, uploadTasks);为什么此处的 const p 需要在 Promise.resolve().then() 中执行 task?
核心原因:控制执行时机
javascript
for (const p of promises) {
// ❌ 直接执行 - 会立即开始所有任务
const result = p.task();
// ✅ 延迟执行 - 按顺序控制并发
const result = Promise.resolve().then(() => p.task());
}具体场景对比
场景 1:直接执行(无 Promise.resolve().then)
javascript
const tasks = [task1, task2, task3];
for (const task of tasks) {
const p = task(); // 立即执行!
running.add(p);
}
// 结果:3 个任务同时开始执行(并发爆炸)场景 2:使用 Promise.resolve().then(延迟执行)
javascript
const tasks = [task1, task2, task3];
for (const task of tasks) {
const p = Promise.resolve().then(() => task()); // 延迟到微任务
running.add(p);
}
// 结果:先注册所有延迟任务,再按事件循环执行关键机制:事件循环
scss
同步代码(for 循环)→ 微任务队列(Promise.then)→ 执行 task()
↓ ↓ ↓
立即执行 注册回调但不执行 真正开始执行实际用途:并发控制
这种模式常见于 限制并发数 的场景:
javascript
async function* asyncPool(concurrency, tasks) {
const executing = new Set();
for (const task of tasks) {
// 关键:延迟执行,让控制器先"占坑"
const p = Promise.resolve().then(() => task());
executing.add(p);
// 清理完成的
p.then(() => executing.delete(p));
// 控制并发:满了就等一个完成
if (executing.size >= concurrency) {
await Promise.race(executing);
}
yield p;
}
await Promise.all(executing);
}
// 使用:最大 2 个并发
for await (const result of asyncPool(2, heavyTasks)) {
console.log(result);
}一句话总结
Promise.resolve().then()把 同步创建 和 异步执行 分离,让你有机会在任务真正开始前做控制(如限制并发、错误处理、取消等)。
如果没有这层包装,任务会在 for 循环遍历时就立即执行,失去了控制的机会。
场景 C:有取消需求 → AbortController + ref
javascript
// 环境:浏览器(React)
// 场景:搜索框,用户快速输入时取消上一个请求,只保留最新一个
function useSearch(query) {
const abortRef = useRef(null);
const [results, setResults] = useState([]);
useEffect(() => {
if (!query.trim()) return;
// 取消上一个还在进行的请求
abortRef.current?.abort();
const controller = new AbortController();
abortRef.current = controller;
fetch(`/api/search?q=${encodeURIComponent(query)}`, {
signal: controller.signal,
})
.then((res) => res.json())
.then(setResults)
.catch((err) => {
if (err.name !== 'AbortError') console.error(err);
// AbortError 是主动取消,不是错误,静默处理
});
return () => controller.abort();
}, [query]);
return results;
}场景 D:有重试需求 → 指数退避
javascript
// 环境:浏览器 / Node.js
// 场景:请求失败后重试,每次等待时间翻倍,避免持续打服务器
async function fetchWithRetry(url, options = {}, retries = 3) {
const { baseDelay = 1000, ...fetchOptions } = options;
for (let attempt = 0; attempt <= retries; attempt++) {
try {
const res = await fetch(url, fetchOptions);
if (!res.ok) throw new Error(`HTTP ${res.status}`);
return await res.json();
} catch (err) {
// 最后一次也失败,直接抛出
if (attempt === retries) throw err;
// 指数退避:1s → 2s → 4s,加随机抖动避免多个客户端同时重试
const delay = baseDelay * Math.pow(2, attempt) + Math.random() * 500;
await new Promise((resolve) => setTimeout(resolve, delay));
}
}
}问题三:这里谁需要感知变化?
这个问题专门针对 React 组件里的状态设计。搞清楚"谁需要感知",能避免大量不必要的重渲染。
场景 A:变化只有局部需要感知 → 状态下沉 + 精确订阅
javascript
// 环境:浏览器(React)
// 场景:50 个订单卡片,只有状态变化的那张需要重渲染
// 依赖:zustand
import { create } from 'zustand';
const useOrderStore = create((set) => ({
statuses: {}, // { [orderId]: status }
update: (orderId, status) =>
set((state) => ({
statuses: { ...state.statuses, [orderId]: status },
})),
}));
// 每个 OrderCard 精确订阅自己那条
// 其他订单状态变化时,这个组件完全不感知,不重渲染
const OrderCard = React.memo(function OrderCard({ orderId }) {
const status = useOrderStore(
useCallback((state) => state.statuses[orderId], [orderId])
);
return (
<div className={`card status-${status}`}>
Order {orderId}: {status}
</div>
);
});场景 A-2:从零手写一个精确订阅 store
用 Zustand 能解决问题,但理解"精确订阅为什么能工作",需要从零实现一次。这道题是一个很好的切入点:实现一个点赞 store,要求每个 item 的订阅者只在自己那条数据变化时才被通知。
javascript
// 环境:浏览器 / Node.js
// 场景:轻量点赞 store,精确订阅------只通知真正变化的那条
function createLikeStore(initialLikes = {}) {
// 状态:点赞数据的真实来源
const likes = { ...initialLikes };
// 订阅表:每个 itemId 对应一个 listener Set
// 用 Map<itemId, Set<listener>> 而不是 Map<itemId, listener[]>
// 原因:Set 保证同一个 listener 不会被重复添加,且删除是 O(1)
const listenersById = new Map();
return {
// 返回快照(浅拷贝),防止外部直接修改内部状态
getState() {
return { ...likes };
},
toggleLike(itemId) {
const nextValue = !likes[itemId];
likes[itemId] = nextValue;
// 精确通知:只触发这个 itemId 的订阅者,其他 item 的订阅者完全不感知
const listeners = listenersById.get(itemId);
if (listeners) {
for (const listener of listeners) {
listener(nextValue);
}
}
return nextValue;
},
subscribeById(itemId, listener) {
// 懒初始化:第一次有人订阅这个 itemId 时才创建 Set
if (!listenersById.has(itemId)) {
listenersById.set(itemId, new Set());
}
listenersById.get(itemId).add(listener);
// 返回卸载函数------这个设计的必要性见下方说明
return () => {
const listeners = listenersById.get(itemId);
if (!listeners) return;
listeners.delete(listener);
// 当这个 itemId 没有任何订阅者时,清理 Map 中的条目
// 防止 Map 无限增长(内存泄漏)
if (listeners.size === 0) {
listenersById.delete(itemId);
}
};
},
};
}为什么 subscribeById 必须返回卸载函数?
这是这道题里最值得单独理解的设计决策。
想象一个商品列表页,有 100 个商品卡片,每个都订阅了自己的点赞状态。用户从这个页面跳转到详情页,列表页的 100 个组件全部卸载。如果没有卸载函数:
javascript
// 没有卸载函数时会发生什么
// 组件挂载时订阅
useEffect(() => {
store.subscribeById(itemId, (nextValue) => {
setIsLiked(nextValue); // 更新已卸载组件的 state
});
// 没有返回卸载函数
}, [itemId]);
// 问题一:内存泄漏
// listenersById 里仍然持有 100 个已卸载组件的 listener 引用
// 这 100 个闭包无法被垃圾回收,页面停留越久内存占用越高
// 问题二:调用已卸载组件的 setState
// 用户在详情页点了某个商品的赞,store 触发通知
// 那个已卸载的 listener 还在,被调用后尝试 setIsLiked
// React 会报警告:Can't perform a React state update on an unmounted component有了卸载函数,就能在 useEffect 的 cleanup 里调用它:
javascript
// 环境:浏览器(React)
// 场景:组件卸载时自动清理订阅,避免内存泄漏
function LikeButton({ itemId, store }) {
const [isLiked, setIsLiked] = useState(
() => store.getState()[itemId] ?? false
);
useEffect(() => {
// 订阅这个 item 的状态变化
const unsubscribe = store.subscribeById(itemId, (nextValue) => {
setIsLiked(nextValue);
});
// cleanup:组件卸载时调用 unsubscribe
// → listener 从 Set 中删除
// → 如果这个 itemId 没有其他订阅者,Map 中的条目也被清理
return unsubscribe;
}, [itemId, store]);
return (
<button onClick={() => store.toggleLike(itemId)}>
{isLiked ? '❤️' : '🤍'}
</button>
);
}这个模式在 React 生态里几乎无处不在------useEffect 返回的 cleanup 函数,本质上就是在调用"注册时拿到的卸载句柄"。Redux 的 store.subscribe、RxJS 的 subscription.unsubscribe、浏览器原生的 removeEventListener,都是同一个模式:注册时拿到句柄,卸载时用句柄清理。
这也是为什么"cleanup 对称原则"(问题四的场景 C)和这里的"卸载函数设计"是同一个底层思想------你开了什么,就要有对应的关闭路径。
场景 B:变化需要跨 render 保留,但不触发渲染 → useRef
判断标准只有一句话:这个值变化时需要更新 UI 吗? 需要 → useState,不需要 → useRef。
javascript
// 环境:浏览器(React)
// 场景:轮询实现,timer id 变化不需要触发渲染
function usePolling(fetchFn, interval = 5000) {
const timerRef = useRef(null); // timer id → 不需要触发渲染 → useRef
const [data, setData] = useState(null); // 数据 → 需要更新 UI → useState
useEffect(() => {
const tick = async () => {
const result = await fetchFn();
setData(result);
};
tick(); // 立即执行一次
timerRef.current = setInterval(tick, interval);
// cleanup:组件卸载时停止轮询
return () => clearInterval(timerRef.current);
}, [fetchFn, interval]);
return data;
}场景 C:派生状态 → 不要单独存一份 state
javascript
// 环境:浏览器(React)
// 场景:购物车,"是否全选"可以从 items 推导,不需要单独管理
function Cart() {
const [items, setItems] = useState([
{ id: 1, name: 'Item A', selected: true },
{ id: 2, name: 'Item B', selected: false },
]);
// ✅ 派生状态:从 items 计算,不单独存 state
// 避免 items 和 isAllSelected 不同步的 bug
const isAllSelected = items.every((item) => item.selected);
const selectedCount = items.filter((item) => item.selected).length;
const toggleAll = () => {
setItems((prev) =>
prev.map((item) => ({ ...item, selected: !isAllSelected }))
);
};
return (
<div>
<label>
<input type="checkbox" checked={isAllSelected} onChange={toggleAll} />
全选(已选 {selectedCount} 件)
</label>
{/* 渲染列表 */}
</div>
);
}问题四:这里可能出什么错?
最后这个问题是防御性思维------在写"正常路径"的代码之前,先想清楚异常路径。
场景 A:部分操作可能失败 → allSettled + 结果收集
javascript
// 环境:浏览器 / Node.js
// 场景:批量发送通知,有些用户可能发送失败,需要知道哪些失败了
async function sendBatchNotifications(userIds, message) {
const tasks = userIds.map((userId) =>
sendNotification(userId, message)
.then(() => ({ userId, success: true }))
.catch((err) => ({ userId, success: false, error: err.message }))
);
const settled = await Promise.allSettled(tasks);
const succeeded = [];
const failed = [];
for (const result of settled) {
// allSettled 不会 reject,每个结果都是 fulfilled
// value 里才是我们自己封装的成功/失败信息
if (result.status === 'fulfilled' && result.value.success) {
succeeded.push(result.value.userId);
} else {
failed.push(
result.status === 'fulfilled'
? result.value
: { userId: 'unknown', error: result.reason }
);
}
}
return { succeeded, failed };
}场景 B:异步操作可能竞态 → 标记最新请求
竞态的本质是:多个异步操作在同一个"目标"上竞争,需要决定哪个的结果有效,过期的丢弃。
处理竞态有三种方案,力度递增:
方案一:isCurrent 标记 结果回来了,但我忽略它(被动丢弃,React 组件内)
方案二:requestId 计数器 结果回来了,但我忽略它(被动丢弃,框架无关)
方案三:AbortController 结果还没回来,我让它停止(主动取消)方案一: isCurrent ------ React 组件内的局部标记
javascript
// 环境:浏览器(React)
// 场景:Tab 切换时快速加载不同内容,只展示最后一次请求的结果
function useTabData(activeTab) {
const [data, setData] = useState(null);
useEffect(() => {
// 标记活在这次 effect 的闭包里,只属于"这一次"
// 每次 activeTab 变化,产生新的闭包和新的 isCurrent
let isCurrent = true;
fetchTabData(activeTab).then((result) => {
if (isCurrent) setData(result); // 过期就不更新
});
return () => {
isCurrent = false; // cleanup 让这次请求过期
};
}, [activeTab]);
return data;
}isCurrent 是二值凭证------只有有效/无效两种状态。标记的生命周期和单次 effect 绑定,cleanup 执行就过期,下次 effect 重新产生一个新的。
方案二:requestId 计数器 --- 框架无关的通用包装
javascript
// 环境:浏览器 / Node.js
// 场景:包装任意异步函数,只让最新一次调用的结果被应用
// 可在 React 组件外使用,适合封装成通用工具
function createLatestOnlyRunner(asyncFn) {
// 计数器活在外层闭包,跨所有调用共享
// 每次新调用让计数器加一,旧调用的 id 永久地比最新 id 小
let latestRequestId = 0;
return async (...args) => {
const requestId = ++latestRequestId; // 拿到这次调用的"身份 id"
try {
const value = await asyncFn(...args);
// 结果回来时,检查自己是不是还是最新的那次
if (requestId !== latestRequestId) {
return { applied: false }; // 已过期,丢弃结果
}
return { applied: true, value };
} catch (e) {
// 失败时也要判断:是最新请求的失败才需要处理
if (requestId !== latestRequestId) {
return { applied: false }; // 过期请求的失败,静默丢弃
}
throw e; // 最新请求的失败,正常抛出
}
};
}
// 使用示例:搜索场景
const searchRunner = createLatestOnlyRunner(fetchSearchResults);
async function handleSearch(query) {
const result = await searchRunner(query);
if (result.applied) {
renderResults(result.value); // 只有最新请求的结果才渲染
}
// applied: false 的直接忽略
}requestId 是单调递增的数字凭证------通过大小关系自动判断新旧,不需要手动让旧的过期,新调用天然让旧调用失效。标记的生命周期和 runner 整个生命周期绑定。
两种方案的核心差异对比
bash
isCurrent 方案 requestId 方案
标记存在哪里 useEffect 闭包(局部) 外层闭包(全局共享)
生命周期 和单次 effect 绑定 和 runner 整个生命周期绑定
过期机制 cleanup 主动设为 false 新调用让旧 id 自然过期
能否在组件外用 不能(依赖 useEffect) 能(纯函数,任何地方可用)
适合场景 React 组件内的异步请求 通用工具函数、非 React 环境两者的底层思想完全相同:给每次操作打上身份凭证,结果回来时验证凭证是否仍然是最新的。 差异只在凭证的形态和管理方式。
方案三:AbortController --- 主动取消,不等结果回来
javascript
// 环境:浏览器(React)
// 场景:搜索框,用户继续输入时直接取消上一个网络请求
// 不只是忽略结果,而是中止请求,节省服务器和网络资源
function useSearch(query) {
const abortRef = useRef(null);
const [results, setResults] = useState([]);
useEffect(() => {
if (!query.trim()) return;
abortRef.current?.abort(); // 取消上一个请求
const controller = new AbortController();
abortRef.current = controller;
fetch(`/api/search?q=${encodeURIComponent(query)}`, {
signal: controller.signal,
})
.then((res) => res.json())
.then(setResults)
.catch((err) => {
if (err.name !== 'AbortError') console.error(err);
});
return () => controller.abort();
}, [query]);
return results;
}AbortController 是主动取消凭证 ------不只是标记"这个结果过期了",而是直接发出取消信号,让网络层停止这个请求。代价更低(请求未完成就终止),但依赖 fetch 原生支持 signal 参数。
三种方案的选择建议
在 React 组件里,请求和组件生命周期绑定
→ isCurrent 标记,最简单,足够用
需要在组件外复用,或包装第三方异步函数
→ createLatestOnlyRunner,框架无关,可测试
请求体积大、耗时长,取消能节省明显资源
→ AbortController,主动中止,力度最强场景 C:副作用可能泄漏 → cleanup 对称原则
javascript
// 环境:浏览器(React)
// 场景:WebSocket 连接,组件卸载时必须关闭,否则内存泄漏
function useOrderMonitor(orderId) {
const [status, setStatus] = useState(null);
useEffect(() => {
const ws = new WebSocket(`wss://api.example.com/orders/${orderId}`);
ws.onmessage = (event) => {
const { status } = JSON.parse(event.data);
setStatus(status);
};
// 启动了 WebSocket → cleanup 里就关闭 WebSocket
// 对称原则:你在 effect 里做了什么,cleanup 里就撤销什么
return () => ws.close(1000, 'component unmounted');
}, [orderId]);
return status;
}场景 D:数据可能过期 → TTL + 重新验证
javascript
// 环境:浏览器
// 场景:缓存接口数据,超过有效期后重新请求
const cache = new Map(); // key → { data, timestamp }
const CACHE_TTL = 5 * 60 * 1000; // 5 分钟
async function fetchWithCache(url) {
const cached = cache.get(url);
if (cached) {
const isExpired = Date.now() - cached.timestamp > CACHE_TTL;
if (!isExpired) return cached.data; // 缓存有效,直接返回
}
// 缓存不存在或已过期,重新请求
const data = await fetch(url).then((r) => r.json());
cache.set(url, { data, timestamp: Date.now() });
return data;
}延伸与发散
整理这四个问题的过程里,我发现它们之间有一些有趣的交叉:
问题三和问题四的交叉 :竞态问题(问题四)本质上也是"谁应该感知变化"的问题(问题三)------当两个异步操作都想更新同一个状态时,你需要决定"只有最新的那个有资格更新"。isCurrent 标记和 AbortController 都是在回答这个问题。
问题二和问题四的交叉:需要取消和需要重试,本质上都是"时间维度里的异常路径"。一个是"有更新的请求来了,旧的不需要了";一个是"这个请求失败了,隔一段时间再试"。两者都是对异步操作生命周期的管理。
还有一类题目这四个问题都没有完全覆盖:乐观更新。先更新 UI,再发请求,失败时回滚。这既涉及"谁感知变化"(状态管理),也涉及"可能出什么错"(失败回滚),是一个跨维度的场景。这个模型值得单独展开讨论。
小结
这四个问题不是一套算法,不能保证"输入题目,输出答案"。它们更像是一套减少遗漏的检查清单------帮助你在开始写代码之前,把题目的关键维度都想到。
实际使用时,四个问题往往不是顺序回答的,而是同时浮现的。看到"批量上传",同时会想到"时间维度(并发)"和"可能出错(部分失败)"。这种并行思考是熟练之后自然发生的,不需要刻意按顺序走。
如果你有其他觉得有用的判断维度,欢迎交流------这套框架本身也是在持续迭代的。
参考资料
- MDN - Promise.allSettled() - 容错并发的官方说明
- MDN - AbortController - 请求取消的标准 API
- React 官方文档 - useEffect cleanup - 副作用清理的官方指南
- Zustand 文档 - selector - 精确订阅避免不必要重渲染
- AWS - Exponential Backoff and Jitter - 指数退避与抖动的工程实践