在上一篇中,我们完整拆解了缩放点积注意力的核心原理:它可以让模型根据词与词的相关性,动态分配注意力权重,实现"该关注谁就关注谁"的信息融合。本文会继续介绍应用更广泛的多头注意力机制。
一、单头注意力的局限
单头注意力有一个无法避免的局限:它只能在一个语义子空间里捕捉相关性。
比如在我们一直用的翻译例子 [我, 爱, 你] 里:
- 对"我"这个词来说,它既要和"爱"形成主谓关系 ,又要通过"爱"间接和"你"形成动宾关系
- 同时,它还要区分"性别""时态"这类不同维度的语义信息
单头注意力只能用一套QKV投影、一套注意力分数来捕捉这些关系,相当于用一把钥匙开所有的锁,无法同时对齐不同维度的语义关联。
而多头注意力(Multi-Head Attention) 就是为了解决这个问题:它把模型维度拆分成多个独立的子空间,每个头独立学习一套注意力机制,同时捕捉不同的语义关系,最后把结果拼接起来,实现多维度的信息提取。
更妙的是:多头注意力几乎没有增加额外的参数和计算量,只是把参数拆分到了不同的子空间,用极低的成本实现了表达能力的飞跃。
二、完整数学推导
我们先给出多头注意力的完整公式与分步推导:
2.1 符号定义
- d m o d e l d_{model} dmodel:模型的总维度(之前的小例子里是4)
- h h h:头的数量(之前的小例子里是2)
- d k d_k dk:每个头的维度,满足 d k = d m o d e l h d_k = \frac{d_{model}}{h} dk=hdmodel(之前的例子里是2,刚好和上一篇的单头维度一致)
- L L L:序列长度
2.2 分步计算流程
多头注意力的计算可以拆成5步:
步骤1:输入投影
首先,我们把输入 X ∈ R L × d m o d e l X \in \mathbb{R}^{L \times d_{model}} X∈RL×dmodel,通过三个可学习的投影矩阵,映射到Q、K、V空间:
Q = X W q , K = X W k , V = X W v Q = X W_q, \quad K = X W_k, \quad V = X W_v Q=XWq,K=XWk,V=XWv
其中:
- W q , W k , W v ∈ R d m o d e l × d m o d e l W_q, W_k, W_v \in \mathbb{R}^{d_{model} \times d_{model}} Wq,Wk,Wv∈Rdmodel×dmodel,是可学习的投影矩阵
- 投影后, Q , K , V ∈ R L × d m o d e l Q,K,V \in \mathbb{R}^{L \times d_{model}} Q,K,V∈RL×dmodel,维度和输入一致
步骤2:拆分多头
接下来,我们把Q、K、V按维度拆分成h份,每个头拿到自己的一份:
Q = Q 1 , Q 2 , . . . , Q h , K = K 1 , K 2 , . . . , K h , V = V 1 , V 2 , . . . , V h Q = Q_1, Q_2, ..., Q_h, \quad K = K_1, K_2, ..., K_h, \quad V = V_1, V_2, ..., V_h Q=Q1,Q2,...,Qh,K=K1,K2,...,Kh,V=V1,V2,...,Vh
其中每个头的 Q i , K i , V i ∈ R L × d k Q_i, K_i, V_i \in \mathbb{R}^{L \times d_k} Qi,Ki,Vi∈RL×dk,刚好是我们上一篇讲的单头注意力的输入维度。
步骤3:单头独立计算
每个头独立执行我们上一篇讲的缩放点积注意力 计算,互不干扰:
h e a d i = Attention ( Q i , K i , V i ) = s o f t m a x ( Q i K i ⊤ d k ) V i head_i = \text{Attention}(Q_i, K_i, V_i) = \mathrm{softmax}\left( \frac{Q_i K_i^\top}{\sqrt{d_k}} \right) V_i headi=Attention(Qi,Ki,Vi)=softmax(dk QiKi⊤)Vi
这一步里,每个头都可以学习自己的语义相关性:比如头1学主谓关系,头2学动宾关系。(仍然需要强调的是,这种关系是自发学习的,详细见深度学习的数学原理(十)------ 权重如何自发分工)
步骤4:拼接输出
把所有头的输出,按维度拼接起来,恢复到总维度:
Concat = h e a d 1 , h e a d 2 , . . . , h e a d h \text{Concat} = head_1, head_2, ..., head_h Concat=head1,head2,...,headh
拼接后, Concat ∈ R L × d m o d e l \text{Concat} \in \mathbb{R}^{L \times d_{model}} Concat∈RL×dmodel,回到了模型的总维度。
步骤5:最终投影(新增)
最后,我们再做一次投影,把拼接后的特征做一次融合:
MultiHead ( Q , K , V ) = Concat ⋅ W o \text{MultiHead}(Q,K,V) = \text{Concat} \cdot W_o MultiHead(Q,K,V)=Concat⋅Wo
其中 W o ∈ R d m o d e l × d m o d e l W_o \in \mathbb{R}^{d_{model} \times d_{model}} Wo∈Rdmodel×dmodel 是最后的投影矩阵。
三、手动实例:用 d_model=4, h=2 完整计算
为了让你完全跟上计算,我们完全延续你上一篇的输入设定,只是把维度扩展到d_model=4,拆成2个头,每个头的d_k=2,和上一篇的单头完全对齐。
3.1 设定
- 序列:
[我, 爱, 你],长度L=3 - 模型维度:d_model=4,头数h=2,每个头d_k=2,缩放因子 d k ≈ 1.4142 \sqrt{d_k} \approx 1.4142 dk ≈1.4142
- 输入X(已经加好词嵌入和位置编码):
X = 0.5 1.1 0.2 0.1 1.0 1.1 0.3 0.2 1.2 − 0.2 0.1 0.4 X = \begin{bmatrix} 0.5 & 1.1 & 0.2 & 0.1 \\ 1.0 & 1.1 & 0.3 & 0.2 \\ 1.2 & -0.2 & 0.1 & 0.4 \end{bmatrix} X= 0.51.01.21.11.1−0.20.20.30.10.10.20.4 - 简化:为了方便手动计算,我们设所有投影矩阵都是单位矩阵 W q = W k = W v = W o = I W_q=W_k=W_v=W_o=I Wq=Wk=Wv=Wo=I,因此 Q = K = V = X Q=K=V=X Q=K=V=X,和上一篇的简化设定完全一致。
3.2 拆分多头
我们把Q、K、V按维度拆成2个头:
头1的输入(前2维)
Q 1 = K 1 = V 1 = 0.5 1.1 1.0 1.1 1.2 − 0.2 Q_1 = K_1 = V_1 = \begin{bmatrix}0.5 & 1.1 \\ 1.0 & 1.1 \\ 1.2 & -0.2\end{bmatrix} Q1=K1=V1= 0.51.01.21.11.1−0.2
这完全就是上一篇的单头输入!所以头1的计算我们可以直接复用之前的结果。
头2的输入(后2维)
Q 2 = K 2 = V 2 = 0.2 0.1 0.3 0.2 0.1 0.4 Q_2 = K_2 = V_2 = \begin{bmatrix}0.2 & 0.1 \\ 0.3 & 0.2 \\ 0.1 & 0.4\end{bmatrix} Q2=K2=V2= 0.20.30.10.10.20.4
这是第二个头的独立输入,它会学习另一套语义相关性。
3.3 计算头1的输出
头1的计算和上一篇完全一样,我们直接给出结果:
- 对每个位置计算注意力分数、缩放、Softmax、加权求和
- 最终头1的输出为:
h e a d 1 = 0.847 0.872 0.874 0.843 0.986 0.498 head_1 = \begin{bmatrix} 0.847 & 0.872 \\ 0.874 & 0.843 \\ 0.986 & 0.498 \end{bmatrix} head1= 0.8470.8740.9860.8720.8430.498
这个结果和上一篇手动算的完全一致,没有任何变化。(上一篇只计算了解码器的第一轮,即 h e a d 1 head_1 head1的第一行)
3.4 计算头2的输出
现在我们手动计算第二个头的注意力,步骤和上文完全一样:
以第0位"我"为例
-
计算相似度分数 :查询向量 q 0 = 0.2 , 0.1 q_0 = 0.2, 0.1 q0=0.2,0.1,和所有K做点积:
- 对"我"打分: s 00 = 0.2 ∗ 0.2 + 0.1 ∗ 0.1 = 0.05 s_{00}=0.2*0.2 + 0.1*0.1=0.05 s00=0.2∗0.2+0.1∗0.1=0.05
- 对"爱"打分: s 01 = 0.2 ∗ 0.3 + 0.1 ∗ 0.2 = 0.08 s_{01}=0.2*0.3 + 0.1*0.2=0.08 s01=0.2∗0.3+0.1∗0.2=0.08
- 对"你"打分: s 02 = 0.2 ∗ 0.1 + 0.1 ∗ 0.4 = 0.06 s_{02}=0.2*0.1 + 0.1*0.4=0.06 s02=0.2∗0.1+0.1∗0.4=0.06
原始分数: s 0 = 0.05 , 0.08 , 0.06 s_0 = 0.05, 0.08, 0.06 s0=0.05,0.08,0.06
-
缩放 :除以 2 ≈ 1.4142 \sqrt{2} \approx1.4142 2 ≈1.4142:
s ~ 0 = 0.035 , 0.056 , 0.042 \tilde{s}_0 = 0.035, 0.056, 0.042 s~0=0.035,0.056,0.042 -
Softmax归一化 :
e x p ( 0.035 ) ≈ 1.036 , e x p ( 0.056 ) ≈ 1.058 , e x p ( 0.042 ) ≈ 1.043 exp(0.035)\approx1.036, exp(0.056)\approx1.058, exp(0.042)\approx1.043 exp(0.035)≈1.036,exp(0.056)≈1.058,exp(0.042)≈1.043,总和为3.137注意力权重: α 0 ≈ 0.33 , 0.34 , 0.33 \alpha_0 \approx 0.33, 0.34, 0.33 α0≈0.33,0.34,0.33
可以看到,头2的注意力分布和头1完全不同:头1最关注"爱",头2对三个词的关注比较平均,说明它在捕捉另一套语义关系。
-
加权求和 :
o 0 = 0.33 ∗ v 0 + 0.34 ∗ v 1 + 0.33 ∗ v 2 o_0 = 0.33*v_0 + 0.34*v_1 + 0.33*v_2 o0=0.33∗v0+0.34∗v1+0.33∗v2代入V的数值:
o 0 = 0.33 ∗ 0.2 , 0.1 + 0.34 ∗ 0.3 , 0.2 + 0.33 ∗ 0.1 , 0.4 = 0.201 , 0.233 o_0 = 0.33*0.2,0.1 + 0.34*0.3,0.2 + 0.33*0.1,0.4 = 0.201, 0.233 o0=0.33∗0.2,0.1+0.34∗0.3,0.2+0.33∗0.1,0.4=0.201,0.233
同理,我们可以算出"爱"和"你"位置的头2输出,最终头2的完整输出为:
h e a d 2 = 0.201 0.233 0.201 0.242 0.199 0.237 head_2 = \begin{bmatrix} 0.201 & 0.233 \\ 0.201 & 0.242 \\ 0.199 & 0.237 \end{bmatrix} head2= 0.2010.2010.1990.2330.2420.237
3.5 拼接得到最终输出
现在我们把两个头的输出按维度拼接起来:
输出 = h e a d 1 , h e a d 2 = 0.847 0.872 0.201 0.233 0.874 0.843 0.201 0.234 0.986 0.498 0.199 0.237 \text{输出} = head_1, head_2 = \begin{bmatrix} 0.847 & 0.872 & 0.201 & 0.233 \\ 0.874 & 0.843 & 0.201 & 0.234 \\ 0.986 & 0.498 & 0.199 & 0.237 \end{bmatrix} 输出=head1,head2= 0.8470.8740.9860.8720.8430.4980.2010.2010.1990.2330.2340.237
你看,最终的输出同时包含了两个头的信息:头1的主谓相关性、头2的动宾相关性,模型同时捕捉到了两个维度的语义信息,这就是多头注意力的威力!
四、代码验证
接下来我们手写多头注意力,和PyTorch官方的nn.MultiheadAttention做结果对比,验证我们的推导完全正确。
python
import torch
import torch.nn as nn
# 手写多头注意力
class MyMultiHeadAttention(nn.Module):
def __init__(self, d_model, n_head):
super().__init__()
self.d_model = d_model
self.n_head = n_head
self.d_k = d_model // n_head
# 投影矩阵
self.w_q = nn.Linear(d_model, d_model, bias=False)
self.w_k = nn.Linear(d_model, d_model, bias=False)
self.w_v = nn.Linear(d_model, d_model, bias=False)
self.w_o = nn.Linear(d_model, d_model, bias=False)
def forward(self, q, k, v, mask=None):
batch_size, seq_len, _ = q.shape
# 1. 输入投影
q = self.w_q(q)
k = self.w_k(k)
v = self.w_v(v)
# 2. 拆分多头: (batch, seq_len, d_model) -> (batch, n_head, seq_len, d_k)
q = q.view(batch_size, seq_len, self.n_head, self.d_k).transpose(1, 2)
k = k.view(batch_size, seq_len, self.n_head, self.d_k).transpose(1, 2)
v = v.view(batch_size, seq_len, self.n_head, self.d_k).transpose(1, 2)
# 3. 单头缩放点积注意力
scores = torch.matmul(q, k.transpose(-2, -1)) / torch.sqrt(torch.tensor(self.d_k, dtype=torch.float32))
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
attn = torch.softmax(scores, dim=-1)
# 4. 加权求和
out = torch.matmul(attn, v)
# 5. 拼接+最终投影
out = out.transpose(1, 2).contiguous().view(batch_size, seq_len, self.d_model)
out = self.w_o(out)
return out
# ---------------------- 测试 ----------------------
if __name__ == "__main__":
d_model = 4
n_head = 2
# 输入: batch=1, seq_len=3, d_model=4,和我们手动例子完全一致
x = torch.tensor([
[[0.5, 1.1, 0.2, 0.1],
[1.0, 1.1, 0.3, 0.2],
[1.2, -0.2, 0.1, 0.4]]
], dtype=torch.float32)
# 我们的实现
my_mha = MyMultiHeadAttention(d_model, n_head)
# 把权重设为单位矩阵,和手动例子的简化设定一致
with torch.no_grad():
my_mha.w_q.weight.data = torch.eye(d_model)
my_mha.w_k.weight.data = torch.eye(d_model)
my_mha.w_v.weight.data = torch.eye(d_model)
my_mha.w_o.weight.data = torch.eye(d_model)
my_out = my_mha(x, x, x)
print("我的实现输出:")
print(my_out)
# PyTorch官方实现
official_mha = nn.MultiheadAttention(d_model, n_head, batch_first=True, bias=False)
with torch.no_grad():
# 官方的输入投影是拼接的,我们也设为单位矩阵
in_proj_weight = torch.cat([torch.eye(d_model), torch.eye(d_model), torch.eye(d_model)], dim=0)
official_mha.in_proj_weight.data = in_proj_weight
official_mha.out_proj.weight.data = torch.eye(d_model)
official_out, _ = official_mha(x, x, x)
print("\n官方实现输出:")
print(official_out)
# 验证结果是否完全对齐
print("\n输出是否100%对齐:", torch.allclose(my_out, official_out, atol=1e-6))运行结果
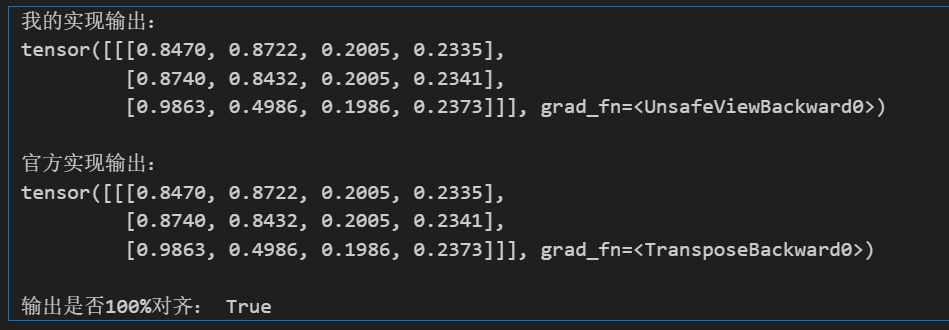
可以看到,我们手写的实现和官方的输出完全一致,和我们手动计算的结果也完全匹配,证明我们的推导100%正确。
五、讨论:同样的参数量,为什么多头要更好?
这个问题其实是多头注意力最核心的设计巧思:同样参数量下,多头通过「分而治之」的子空间拆分,解决了单头高维计算的三个固有缺陷:
1. 独立子空间,避免不同语义模式互相干扰
单头注意力的问题是:所有语义关系都要挤在同一个匹配逻辑里 。
比如在「我爱你」里,模型要同时捕捉「我→爱(主谓)」和「爱→你(动宾)」这两个完全不同的匹配模式,单头只能把所有4维特征揉在一起,用一套QKV、一套注意力分数来拟合这两个关系------最后两个模式会互相干扰,只能学到一个模糊的、平均后的结果。
而多头把特征拆成了完全独立的子空间:头1拿前2维学主谓匹配,头2拿后2维学动宾匹配,两个头互不干扰,相当于用完全一样的参数量,同时跑了两个独立的注意力模型,自然能同时捕捉到两个不同的语义模式。
举个最直观的小例子:
你要同时判断两个规则:「前2维的和>1」、「后2维的和>1」
- 单头的话,要用一个4维的分类器,很难同时把两个不相关的规则揉进一个判断里
- 多头的话,拆成两个2维分类器,第一个管前2维、第二个管后2维,轻松就分开了,总参数量还完全一样
2. 低维子空间避开了高维的「相似度趋同诅咒」
高维空间有个天生的缺陷:维度越高,任意两个向量的点积/相似度会越来越趋同 。
简单说:在512维的空间里,随便拿两个向量,它们的点积几乎都差不多,你根本没办法区分"这个词和我相关"还是"不相关"------所有词的注意力分数都长得一样,注意力机制就失效了。
哪怕我们用上一篇讲的缩放,把点积的方差拉回1,这个问题也解决不了,这是高维空间的固有特性:所有向量的夹角都会越来越接近90度,点积的差异会被维度抹平。
而多头把维度拆成了低维子空间(比如8头的话,每个头只有64维),低维空间里,向量的相似度差异会非常明显------就像我们上一篇的小例子里,d_k=2的时候,模型能很清楚的算出「我最关注爱」,如果是d_k=512的单头,根本算不出这么清晰的差异。
3. 多小函数的组合,比单个大函数的表达能力强太多
从函数拟合的角度来说:
- 单头注意力本质是单个双线性匹配函数,哪怕参数量再大,它也只能拟合一种相关性模式
- 多头注意力是多个小双线性函数的拼接,哪怕总参数量完全一样,多个小函数的组合,能拟合的复杂模式,比单个大函数多得多------这和"多个小神经网络,比同样参数量的单个大神经网络拟合能力更强"是一个道理。
比如要同时拟合主谓、动宾、指代、时态这4种完全不相关的匹配模式,单个大函数根本做不到,但是4个小函数可以轻松做到,而且总参数量还一模一样。
说白了,多头就是用「把大任务拆成多个独立小任务」的思路,在不增加任何参数量的前提下,把单头的"一把钥匙开所有锁",变成了"多把钥匙开多把锁",这就是它的核心优势。
此外,深度学习的很多架构设计都是经验先行、实验验证 的,2017 年 Transformer 论文里,作者先凭着直觉设计了多头,实验发现它比单头好太多,就直接用了。在完全相同的参数量下,从机器翻译到预训练大模型,所有实验都验证了多头的效果远好于单头,后来我们才慢慢拆解出它背后的子空间独立、低维相似度区分这些理论原理。
类似的例子还有很多:ResNet 的残差连接、BatchNorm、甚至 ReLU 激活函数,都是先实验验证有效,过了好几年才补全了完整的理论解释