Berkeley DB
Berkeley DB是一个嵌入式的键值对数据库,在bitcoin 0.1.0源中,使用的就是这个数据库存储钱包的公私钥,以及区块交易数据等。
为什么说它是嵌入式的,因为使用这个数据库跟我们使用openssl方法一样,你不需要安装数据库,你只要导入相关支持的库文件就可以使用。
那么它的头文件就是,在db.h里可以看到:
cpp
#include <db_cxx.h>项目中的db.h db.c就是数据库相关的源码。
我们在main.cpp可以看到这样一个函数:
cpp
vector<unsigned char> GenerateNewKey()
{
CKey key;
key.MakeNewKey();
if (!AddKey(key))
throw runtime_error("GenerateNewKey() : AddKey failed\n");
return key.GetPubKey();
}生成一个新钥函数,然后调用了AddKey,AddKey干了什么呢:
cpp
bool AddKey(const CKey& key)
{
CRITICAL_BLOCK(cs_mapKeys)
{
mapKeys[key.GetPubKey()] = key.GetPrivKey();
mapPubKeys[Hash160(key.GetPubKey())] = key.GetPubKey();
}
return CWalletDB().WriteKey(key.GetPubKey(), key.GetPrivKey());
}把新生成的公私钥,用键值对的方式,公钥当键,私钥当值,存到mapkeys,mapPubKeys,这两个具体做什么,我们先不管。系统运行时用到的。
CWalletDB钱包管理类
我们主要看后面一句,还存进了钱包里,调用CWalletDB钱包类写入硬盘。
那这个钱包类底层就是使用的Berkeley DB数据库,这个钱包类的定义在db.h里。
可以看到这一句:
cpp
class CWalletDB : public CDB这个类继承了CDB,CDB也是自己写的一个类,对Berkeley DB的功能进行了基础的封装,所以所有对数据库访问的类,比如存储交易区块数据的CTxDB类,也继承自该类,
cpp
class CTxDB : public CDBCDB基类
那么我们先来看一下CDB类的代码:
cpp
class CDB
{
protected:
Db* pdb;
string strFile;
vector<DbTxn*> vTxn;
explicit CDB(const char* pszFile, const char* pszMode="r+", bool fTxn=false);
~CDB() { Close(); }
public:
void Close();
private:
CDB(const CDB&);
void operator=(const CDB&);
protected:
template<typename K, typename T>
bool Read(const K& key, T& value)
{
if (!pdb)
return false;
// Key
CDataStream ssKey(SER_DISK);
ssKey.reserve(1000);
ssKey << key;
Dbt datKey(&ssKey[0], ssKey.size());
// Read
Dbt datValue;
datValue.set_flags(DB_DBT_MALLOC);
int ret = pdb->get(GetTxn(), &datKey, &datValue, 0);
memset(datKey.get_data(), 0, datKey.get_size());
if (datValue.get_data() == NULL)
return false;
// Unserialize value
CDataStream ssValue((char*)datValue.get_data(), (char*)datValue.get_data() + datValue.get_size(), SER_DISK);
ssValue >> value;
// Clear and free memory
memset(datValue.get_data(), 0, datValue.get_size());
free(datValue.get_data());
return (ret == 0);
}
template<typename K, typename T>
bool Write(const K& key, const T& value, bool fOverwrite=true)
{
if (!pdb)
return false;
// Key
CDataStream ssKey(SER_DISK);
ssKey.reserve(1000);
ssKey << key;
Dbt datKey(&ssKey[0], ssKey.size());
// Value
CDataStream ssValue(SER_DISK);
ssValue.reserve(10000);
ssValue << value;
Dbt datValue(&ssValue[0], ssValue.size());
// Write
int ret = pdb->put(GetTxn(), &datKey, &datValue, (fOverwrite ? 0 : DB_NOOVERWRITE));
// Clear memory in case it was a private key
memset(datKey.get_data(), 0, datKey.get_size());
memset(datValue.get_data(), 0, datValue.get_size());
return (ret == 0);
}
template<typename K>
bool Erase(const K& key)
{
if (!pdb)
return false;
// Key
CDataStream ssKey(SER_DISK);
ssKey.reserve(1000);
ssKey << key;
Dbt datKey(&ssKey[0], ssKey.size());
// Erase
int ret = pdb->del(GetTxn(), &datKey, 0);
// Clear memory
memset(datKey.get_data(), 0, datKey.get_size());
return (ret == 0 || ret == DB_NOTFOUND);
}
template<typename K>
bool Exists(const K& key)
{
if (!pdb)
return false;
// Key
CDataStream ssKey(SER_DISK);
ssKey.reserve(1000);
ssKey << key;
Dbt datKey(&ssKey[0], ssKey.size());
// Exists
int ret = pdb->exists(GetTxn(), &datKey, 0);
// Clear memory
memset(datKey.get_data(), 0, datKey.get_size());
return (ret == 0);
}
Dbc* GetCursor()
{
if (!pdb)
return NULL;
Dbc* pcursor = NULL;
int ret = pdb->cursor(NULL, &pcursor, 0);
if (ret != 0)
return NULL;
return pcursor;
}
int ReadAtCursor(Dbc* pcursor, CDataStream& ssKey, CDataStream& ssValue, unsigned int fFlags=DB_NEXT)
{
// Read at cursor
Dbt datKey;
if (fFlags == DB_SET || fFlags == DB_SET_RANGE || fFlags == DB_GET_BOTH || fFlags == DB_GET_BOTH_RANGE)
{
datKey.set_data(&ssKey[0]);
datKey.set_size(ssKey.size());
}
Dbt datValue;
if (fFlags == DB_GET_BOTH || fFlags == DB_GET_BOTH_RANGE)
{
datValue.set_data(&ssValue[0]);
datValue.set_size(ssValue.size());
}
datKey.set_flags(DB_DBT_MALLOC);
datValue.set_flags(DB_DBT_MALLOC);
int ret = pcursor->get(&datKey, &datValue, fFlags);
if (ret != 0)
return ret;
else if (datKey.get_data() == NULL || datValue.get_data() == NULL)
return 99999;
// Convert to streams
ssKey.SetType(SER_DISK);
ssKey.clear();
ssKey.write((char*)datKey.get_data(), datKey.get_size());
ssValue.SetType(SER_DISK);
ssValue.clear();
ssValue.write((char*)datValue.get_data(), datValue.get_size());
// Clear and free memory
memset(datKey.get_data(), 0, datKey.get_size());
memset(datValue.get_data(), 0, datValue.get_size());
free(datKey.get_data());
free(datValue.get_data());
return 0;
}
DbTxn* GetTxn()
{
if (!vTxn.empty())
return vTxn.back();
else
return NULL;
}
public:
bool TxnBegin()
{
if (!pdb)
return false;
DbTxn* ptxn = NULL;
int ret = dbenv.txn_begin(GetTxn(), &ptxn, 0);
if (!ptxn || ret != 0)
return false;
vTxn.push_back(ptxn);
return true;
}
bool TxnCommit()
{
if (!pdb)
return false;
if (vTxn.empty())
return false;
int ret = vTxn.back()->commit(0);
vTxn.pop_back();
return (ret == 0);
}
bool TxnAbort()
{
if (!pdb)
return false;
if (vTxn.empty())
return false;
int ret = vTxn.back()->abort();
vTxn.pop_back();
return (ret == 0);
}
bool ReadVersion(int& nVersion)
{
nVersion = 0;
return Read(string("version"), nVersion);
}
bool WriteVersion(int nVersion)
{
return Write(string("version"), nVersion);
}
};我们来看这个类的核心部分,read write读写函数里面的代码:
cpp
Dbt datKey(&ssKey[0], ssKey.size());
Dbt datValue(&ssValue[0], ssValue.size());
int ret = pdb->put(GetTxn(), &datKey, &datValue, (fOverwrite ? 0 : DB_NOOVERWRITE));这三句,put方法是写入数据,这里定义了两个Dbt对象,分别对应key和value,这个Dbt这是数据库文件里的类型。一个结构体,说明要把键值对写进数据库里,需要把数据转换成Dbt的形式,方法就是定义一个Dbt对象,然后构造函数传数据的起始地址和数据的大小,两个参数。
这个源码兼容的版本是Berkeley DB 4.8。
我们去下载4.8版本的lib库,即在网络上寻找 Berkeley DB 4.8,然后下载对应windows 64位的。预编译好的lib文件。不要源码那种的。
在网上找了一圈,找不到适合的预编译版本,这里我准备了老平台下载源码,自己编译出库文件,用win7系统vs2005版本的,编译出64位的文件后,再放到我的vs2022里来用,事实上如果你仅为了使bitcoin代码运行起来,你可以选择老平台,包括系统。然后下载对应的那个时代的代码,兼容性会非常好。我们这侧重代码,所以有些东西是无所谓的,包括以后我可能就是那个ui部分,我可能会弃用,不去兼容它。全改为控制台操作。或者以后用新的ui框架代替。
编译db4.8库
我们从网上下载好这db库源码后,找到windows版本,然后用vs2005打开其下的Berkeley_DB.sln项目解决方案文件:
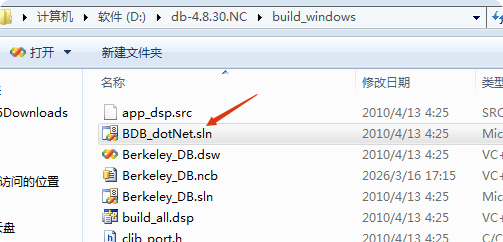
然后我们来试一下生成32位版本的:选release(发行版,非调试版),win32
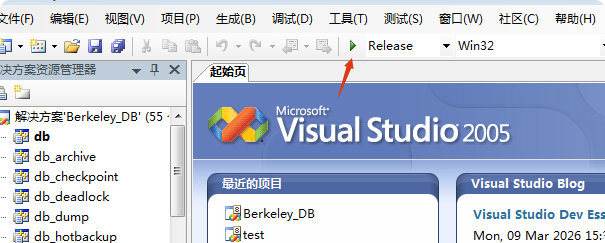
点编译,然后后面会让你选择可执行文件,取消就行,因为这个项目不是exe的,是库文件。所以会出来这种问题,如果不想这样编译,也可以右击项目解决方案,然后选择生成解决方案也行(会生成动静两个版本)。
然后我们可以在目录下看到,生成了一个win32文件夹,然后是release下:
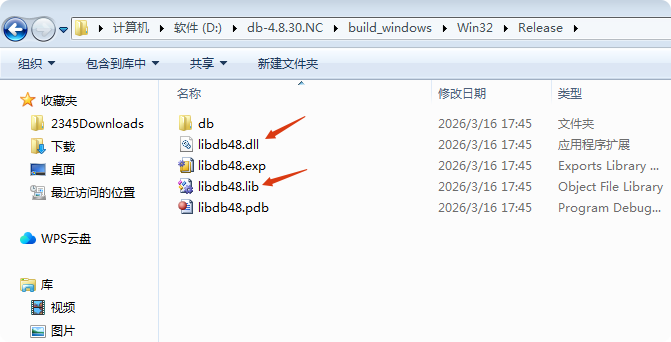
然后我们就得到了lib和dll文件了,注意有lib和dll是动态链接的,当然我们也可以生成静态lib。默认是动态的,我们这里也用动态。
接着我们来生成64位的,也就是将win32改成x64,但是这里我碰到了一个问题,一改成x64,编译按钮就变成灰色的,我在配置平台也看到x64,我不知道是源码问题,还是编译器问题。
最终我新建一个控制台项目,发现x64选项直接没有了。那么就是编译器不支持x64,而db4.8是支持x64的,它的解决方案带x64,所以导致有x64选项但是用不了。
我们打开控制面板,在程序管理那里,选中vs2005,然后选择卸载和更改,等安装程序出来,选择添加和删除功能,将x64的勾给打上就行了:
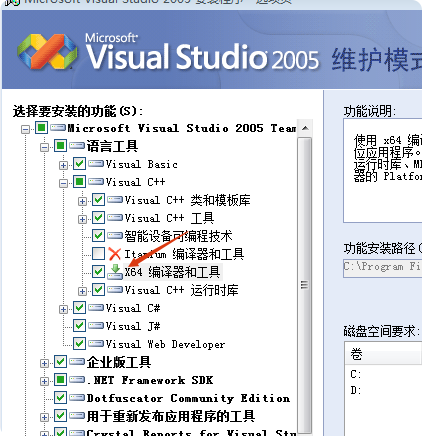
重启vs2005,打开项目,然后将编译那里的win32改成x64编译就行。
就会生成x64文件夹,这是64位版本的 ,也就是接下来我们项目中要用的版本(兼容我原先的openssl 64位):
有需要的可以下载:
https://download.csdn.net/download/d3582077/92739566
测试db4.8库
接下来我们新建一个控制台项目,来测试一下这个库。
新建项目后,我们在项目目属性配置里,还是三步走。
1.包含头文件所在目录,db_cxx.h头文件就在build_windows目录下,所以附加包含目录是
C:\build_windows (我将build_windows复制到c盘下了)
2.附加库目录是 :C:\build_windows\x64\Release 选择64位版本的。
3.附加依赖项(库名):libdb48.lib
然后呢,这是动态链接的,所以还有个dll,将libdb48.dll复制到你程序所有同名目录,或者系统目录,让程序能找到这个dll调用。
我们来个例子测试一下:
cpp
#include <iostream>
#include <string>
#include <db_cxx.h>
int main() {
try {
// 1. 创建 Db 对象(构造函数)
Db db(NULL, 0); // 推荐方式:无环境、无特殊标志
// 2. 打开数据库
db.open(
NULL, // 事务指针(这里无事务,用 NULL)
"example.db", // 数据库文件路径(会自动创建)
NULL, // 逻辑数据库名(单数据库文件时用 NULL)
DB_BTREE, // 访问方法:BTree(最常用)
DB_CREATE,// 标志:创建 如果文件不存在则创建
0 // 文件权限(0 使用默认,通常 0666)
);
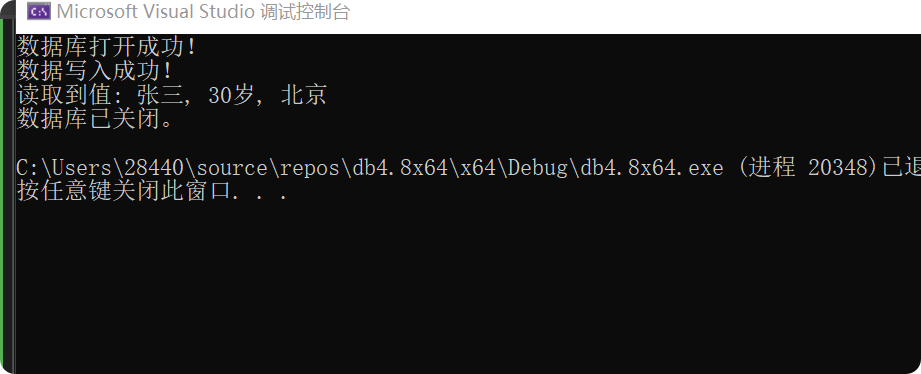
std::cout << "数据库打开成功!" << std::endl;
// 3. 写入数据(put)
Dbt key((void *)"user001", 7); // 键(字符串,长度必须指定)
Dbt value((void *)"张三, 30岁, 北京", 16); // 值(字符串,长度必须指定)
db.put(
NULL, // 事务指针(无事务用 NULL)
&key,
&value,
0 // 标志(0 表示普通 put)
);
std::cout << "数据写入成功!" << std::endl;
// 4. 读取数据(get)
Dbt read_key((void *)"user001", 7);
Dbt read_value; // 值会自动分配内存
db.get(
NULL, // 事务
&read_key,
&read_value,
0 // 标志(0 普通 get)
);
// 注意:read_value.get_data() 返回 void*,需要转换
std::string retrieved_value(
static_cast<char*>(read_value.get_data()),
read_value.get_size()
);
std::cout << "读取到值: " << retrieved_value << std::endl;
// 5. 关闭数据库
db.close(0); // 0 表示普通关闭
std::cout << "数据库已关闭。" << std::endl;
}
catch (DbException& e) {
std::cerr << "DbException: " << e.what() << " (" << e.get_errno() << ")" << std::endl;
return 1;
}
catch (std::exception& e) {
std::cerr << "异常: " << e.what() << std::endl;
return 1;
}
return 0;
}执行成功,说明我的们库文件都没问题:
这里我们大概了解一下代码:
Db()
想使用数据库,我们需要先定义一个Db db对象,然后构造函数有两个参数,默认可以填null,0。
cpp
Db db(NULL, 0); // 推荐方式:无环境、无特殊标志第一个参数是数据库环境指针,在bitcoin源码,这个参数是使用了的,在db.h文件中可以看到有定义:
cpp
DbEnv dbenv;然后传进了db的构造函数中,我们这里为简便,使用了null。
Db构造函数的第二个参数,是标志位,默认为0,如果是多线程操作的,则需要填DB_THREAD,代表多线程标志。
然后你就用Db创造了一个操作数据库的句柄,你可以这么看。
db.open
接着,我们调用Db的open方法,指定数据库名,你可以创建或打开一个数据文件。
我们来看一下参数:
cpp
// 2. 打开数据库
db.open(
NULL, // 事务指针(这里无事务,用 NULL)
"example.db", // 数据库文件路径(会自动创建)
NULL, // 逻辑数据库名(单数据库文件时用 NULL)
DB_BTREE, // 访问方法:BTree(最常用)
DB_CREATE,// 标志:创建 如果文件不存在则创建
0 // 文件权限(0 使用默认,通常 0666)
);这里的第一个参数事务指针为null。
第二个就是数据库名,这里没有指定绝对路径的话,那么这个数据库文件就在你的程序同目录下面。
第三个参数,逻辑数据库名我们不使用。
第四个参数,就是DB_BTREE,这个参数指明了数据库的存储方式,使用B+树存储数据,以及查询的时候也是这个结构,这样查询操作的时候,会快很多。可以看成是按一定格式的索引存储,默认使用这个。其它不介绍。
第五个参数,DB_CREATE,表示如果文件不存在则创建,如果存在则打开,这个标志还可以和其它混用,比如:
DB_CREATE | DB_EXCL:如果文件已存在,则 open 失败(返回错误,如 DB_FILEEXISTS),
DB_CREATE | DB_TRUNCATE:如果文件已存在,则清空所有数据(逻辑上像新建一个空数据库),原有内容被丢弃(但文件本身不会被物理删除,只是内容清零)。
第六个参数:默认为0,只在创建文件的时候有用,就是你这个文件只读,还是可读可写。默认0就是可读可写。
db.put db.get
然后就是写数据put方法,读数据get方法,这个在前面有介绍,就不详细说明了,可以看代码理解。
只说一下它们最后的那个参数,定义了put的一些行为,比如默认就是,如果这个键已经存在了,则进行覆盖,没有则创建。
那么:
db.put(NULL, &key, &value, DB_NOOVERWRITE);设置为DB_NOOVERWRIE后,如果这个键存在,则返回错误,返回 DB_KEYEXIST,你可以 catch 并处理。
而get也是定义的它的读取行为,比如不是读key的值,而传进去的key和value,必须键值完全一致,仅有这个键user001还不行,还必须这个键的值也是"张三, 30岁, 北京",才能成功,可以判断有无这样的键值,当然还有其它的读法,不怎么常用,只提一下,默认值就行。
事务DbTxn
在代码中,我们看到,open,put,get方法,都有事务指针这个参数。
它是DbTxn的对象,可以看到,在bitcoin源码中,put和get是使用了这个参数的,有定义。
使用事务,必须引入 DbEnv(环境)指明。
事务是用来干什么的呢?保证多个put和get操作一致性,如果它们用的同一个事务,则要么全部成功,要么全部失败,如果写到一半,程序崩溃出错,能保证数据回滚。
比如一般情况下:
cpp
1. db.put(null, &key, &value, 0);
2. 崩溃
3. db.put(null, &key, &value, 0); //另一条数据。那么第一条数据,成功写入了。
加入事务后,用的同一个事务:
cpp
代码...
DbTxn *txn = nullptr;
代码...
1. db.put(txn, &key, &value, 0);
2. 崩溃
3. db.put(txn, &key, &value, 0); //另一条数据。不成功的话,数据回滚,第一条数据不会写入成功。
具体实例就不举了,我们在bitcoin源码看到这种用法,明白就行。
DbEnv环境
在前面说到了,使用事务必须要用到DbEnv,那么这个DbEnv可不仅仅支持事务功能,它还可以支持并发,以及日志记录数据恢复等。在使用的时候,通过标志位指定功能,比如通常的写法:
cpp
DbEnv env(0); // 创建环境句柄
env.open("./my_env_dir", // 环境目录(必须存在或 DB_CREATE 创建)
DB_CREATE | DB_INIT_MPOOL | DB_INIT_LOCK | DB_INIT_LOG | DB_INIT_TXN, // 初始化所有子系统
0);
// 然后用 env 创建 Db
Db db(&env, 0); // 关联环境这样就创建了环境,环境目录是my_env_dir,如果没有则创建,那么指定了环境之后,你的日志还有其它相关文件都会在my_env_dir目录下,包括你后面创建的数据库文件,默认也在该目录下。
结束....end
附:最后再奉上string写法的代码:
cpp
#include <iostream>
#include <db_cxx.h> // Berkeley DB C++ API
int main() {
try {
// 创建数据库环境(可选,这里用默认环境)
Db db(nullptr, 0); // 第一个参数为环境指针,nullptr表示不使用环境
// 打开或创建数据库
db.open(nullptr, // 事务指针
"test.db", // 数据库文件名
nullptr, // 数据库逻辑名称
DB_BTREE, // 使用 BTree 存储
DB_CREATE, // 如果不存在则创建
0); // 文件权限,0 使用默认
// 写入数据
std::string keyStr = "name";
std::string valueStr = "ZhengYong";
Dbt key((void*)keyStr.c_str(), keyStr.size() + 1); // +1 保留 '\0'
Dbt value((void*)valueStr.c_str(), valueStr.size() + 1);
db.put(nullptr, &key, &value, 0); // 写入数据
std::cout << "写入完成: " << keyStr << " => " << valueStr << std::endl;
// 读取数据
Dbt readValue;
int ret = db.get(nullptr, &key, &readValue, 0); // 读取数据
if (ret == 0) {
std::cout << "读取到数据: " << keyStr << " => "
<< static_cast<char*>(readValue.get_data()) << std::endl;
}
else if (ret == DB_NOTFOUND) {
std::cout << "未找到键: " << keyStr << std::endl;
}
else {
std::cerr << "读取数据出错: " << ret << std::endl;
}
// 关闭数据库
db.close(0);
}
catch (DbException& e) {
std::cerr << "数据库异常: " << e.what() << std::endl;
return 1;
}
catch (std::exception& e) {
std::cerr << "标准异常: " << e.what() << std::endl;
return 1;
}
return 0;
}事实上写数据的时候,不加1,不保留\0,我这里也没问题,获取的时候输出,ZhengYong后面并不会跟一串乱码,这里只是碰巧,系统在你的数据缓冲区后面做了清零操作,所以如果是输出字符串,我们还是+1,保留\0,不依赖于不稳定的事。如果是其它数据,该写多少,该读多少就多少。都是指定的,而不是cout输出字符,然后根据\0来结束。不用到cout输出,影响都不大。不必太过关注。