Diffusion Policy(扩散策略) 是将扩散模型(Diffusion Model) 应用于机器人策略学习的方法。它的核心是:把机器人动作的生成,变成一个 "从随机噪声逐步去噪、还原出平滑动作序列" 的过程。
一、通俗理解
传统强化学习(PPO/TD3):
- 网络直接输出 "下一步该做什么动作"(单步、单点预测)
- 容易抖动、不稳定、难学复杂动作
Diffusion Policy(DP):
- 不直接输出单步动作,而是一次性生成未来一小段连续动作序列(比如 8~16 步)
- 生成方式:从纯高斯噪声 开始,经过十几步迭代去噪,慢慢 "净化" 成合理、平滑的动作序列
- 执行时只取第一步(窗口的长度)动作,下一步重新观测、重新生成 → 类似 "滚动窗口规划"
类比:
传统方法:盲人一步一步摸路走;
DP:每次先闭眼想象一段完整路径(去噪生成),再只迈第一步(窗口的长度),不断重复。
二、核心原理
2.1 前向扩散过程(训练用)
给真实、干净的动作序列 a₀ 逐步加高斯噪声,直到变成完全随机噪声 a_T。
- a₀ = 真实动作(比如机械臂关节轨迹)
- a₁ → a₂ → ... → a_T:每步加一点点噪声
- 公式:
表示第 t 步的动作序列,
训练目标 :训练一个噪声预测网络 ε_θ(, obs, t)
- 输入:带噪动作
- 输出:预测这一步加的噪声 ϵ̂
- 损失:MSE (ϵ̂, ϵ) → 让网络学会 "看带噪动作,猜出被加了多少噪声";
2.2 反向去噪过程(推理 / 控制用)
从纯随机噪声 a_T 开始,反向迭代 T 步去噪,逐步还原出 a₀(动作序列)。
每一步 t(从 T→1):
- 用网络预测噪声:ε̂ = ε_θ(
- 用公式 "减去噪声",得到更干净的
- 最后一步可加少量随机噪声保持探索
结果:
- 得到一整段平滑、连续、物理合理的动作序列 a₀₁, a₀₂, ..., a₀_H
- 机器人只执行第一个动作 a₀₁,剩下动作丢掉
- 下一时刻:新观测 → 重新生成一段 → 再执行第一步 → 循环
三、每部分的具体参数详解
整体框架图:
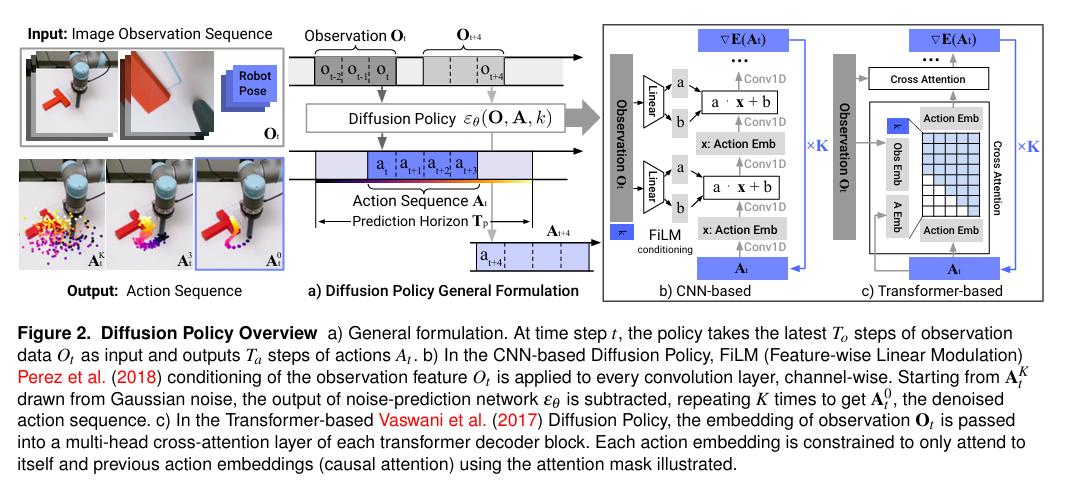
3.1 图 a:General Formulation 通用公式
1)输入的观测序列:
| 符号 | 含义 | 通俗解释 |
|---|---|---|
| Input: Image Observation Sequence | 输入:图像观测序列 | 图像会通过 CNN/ViT 编码器提取特征,Robot Pose(机器人关节角度、末端位姿、夹爪开合度等自身状态)通过 MLP 编码,最终融合成统一的观测嵌入 |
| Ot | 第 t 时刻的观测块 | 包含最近 To 步 的历史观测(Ot−2,Ot−1,Ot 等),是模型的条件输入 |
| To | Observation Horizon(观测窗口长度) | 模型一次看多少帧历史观测 |
| Robot Pose | 机械臂关节信息 | 除了图像,还会输入机械臂关节角、末端位姿等信息,作为观测的一部分 |
2)核心模型:Diffusion Policy参数
| 符号 | 含义 | 通俗解释 |
|---|---|---|
| εθ(O,A,k) | 噪声预测网络(Diffusion Policy 主体) | 整个模型的核心,参数为 θ,输入 3 个东西:1. 观测 O(条件)2. 带噪动作 A3. 扩散时间步 k输出:预测的噪声 ε^ |
| k | Diffusion Timestep(扩散时间步) | 对应我们之前说的 t,表示当前是第 k 步加噪 / 去噪,k=K 是完全噪声,k=0 是完全干净动作 |
| K | Total Diffusion Steps(总扩散步数) | 整个扩散过程的总步数,也就是去噪要迭代 K 次,常用 20/50/100 |
3)输出侧:动作序列
| 符号 | 含义 | 通俗解释 |
|---|---|---|
| At | 第 t 时刻预测的动作序列 | 模型输出的未来 Ta 步连续动作(at,at+1,at+2,...) |
| at | 第 t 时刻的单步动作 | 动作序列里的第 1 个动作,机器人只执行这一步 |
| Ta / Tp | Action Horizon / Prediction Horizon(动作预测窗口) | 模型一次生成多少步未来动作,也就是 At 的长度,常用 8/16/32 |
| AtK | 第 t 时刻、第 K 步的带噪动作 | 初始完全随机的高斯噪声,是去噪的起点 |
| At0 | 第 t 时刻、第 0 步的干净动作 | 经过 K 次去噪后,最终得到的完美、平滑的动作序列 |
| Output: Action Sequence | 输出:动作序列 | 图左下角的彩色轨迹,从噪声(左,杂乱)→ 去噪(中,收敛)→ 最终轨迹(右,平滑),直观展示去噪过程 |
执行顺序:
- 模型在时刻 t,输入最近 To 步观测 Ot,输出未来 Ta 步动作 At
- 下一个时刻 t+4(图中窗口长度为3),输入新的观测 Ot+4,重新生成新的动作序列 At+4
- 机器人只执行每个序列的第 1 步,实现滚动窗口闭环控制,保证鲁棒性
3.2 图 b:CNN-based Diffusion Policy(CNN 架构实现)
这是 Diffusion Policy 原论文的默认骨干网络 (U-Net 结构),核心是用 FiLM 做条件注入:
| 符号 / 模块 | 含义 | 通俗解释 |
|---|---|---|
| Observation Ot | 观测输入 | 先通过编码器(CNN/MLP)把图像 / 状态变成观测特征向量 |
| k | 时间步嵌入 | 把扩散步数 k 编码成特征,告诉网络当前是第几步去噪 |
| FiLM conditioning | Feature-wise Linear Modulation(特征 - wise 线性调制) | 把观测特征 Ot 和时间步 k 融合,生成缩放系数 γ(图中的 a)和偏置 β(图中的 b) |
| a⋅x+b | FiLM 公式 | 对卷积层的特征 x 做:y=γ⋅x+β,用观测信息调整每一层的特征,通过x来调整出特征对哪个特征更关注(对a更关注则x比较大,对b更关注x比较小) |
| Conv1D | 一维卷积层 | 处理动作序列的时序特征,提取动作的时间相关性 |
| At | 带噪动作输入 | 第 k 步的带噪动作序列,作为网络的输入 |
| ∇E(At) | 噪声预测输出 | 网络预测的噪声梯度(等价于预测噪声 ε^),用来做去噪计算 |
| ×K | 迭代 K 次 | 从 AtK(纯噪声)开始,重复 K 次去噪,最终得到 At0(干净动作) |
3.3 图 c:Transformer-based Diffusion Policy(Transformer 架构实现)
这是 Diffusion Policy 的Transformer 变体,用交叉注意力做条件注入:
| 符号 / 模块 | 含义 | 通俗解释 |
|---|---|---|
| Observation Ot | 观测输入 | 编码成 Obs Emb(观测嵌入),作为交叉注意力的 Key/Value |
| k | 时间步嵌入 | 把扩散步数 k 编码,和观测嵌入融合 |
| At | 带噪动作输入 | 编码成 Action Emb(动作嵌入),作为交叉注意力的 Query |
| Cross Attention | 交叉注意力层 | 让动作嵌入 **"看到" 观测嵌入 **,实现 "根据当前观测生成动作" 的条件控制 |
| Causal Attention Mask(因果注意力掩码) | 图中的网格掩码 | 强制动作嵌入只能关注自己和之前的动作,不能看未来的动作,保证时序因果性,避免信息泄露 |
| ∇E(At) | 噪声预测输出 | 和 CNN 版一致,输出预测的噪声,用于去噪 |
| ×K | 迭代 K 次 | 同样迭代 K 次去噪,得到最终动作序列 |
四、为什么 Diffusion Policy 比传统 RL 强
4.1 输出平滑动作序列
-
预测一个动作序列窗口(如16步),但只执行第一个滑动窗口的动作,下一窗口时刻重新观测规划。通过此规则实现输出平滑动作序列。
-
类比:就像开车时只关注前方一段路,不断根据新情况调整方向。
而传统RL则是单步单点预测,直接输出下一个动作。
4.2 能学多模态、复杂动作分布
- 传统策略输出单点高斯,容易单峰、卡死
- DP 建模整个分布,可学 "多条可行路径"(比如绕开障碍的多种抓法)
4.3 训练更稳定、梯度更干净
- 训练目标是简单的噪声预测 MSE,比策略梯度好训
- 不容易崩溃、遗忘、抖动
4.4 支持长时序依赖
- 一次生成 H 步动作,自带时序相关性
- 适合抓取、装配、开门等需要连续多步配合的任务。