1.爬虫:也称为网络爬虫(网络机器人),是一种按照一定的预设规则,自动浏览并抓取网络数据的程序或脚本。主要应用于:搜索引擎(百度、Google) 、舆情监控、商业分析(电商比价系统)、AI大模型训练语料 ......
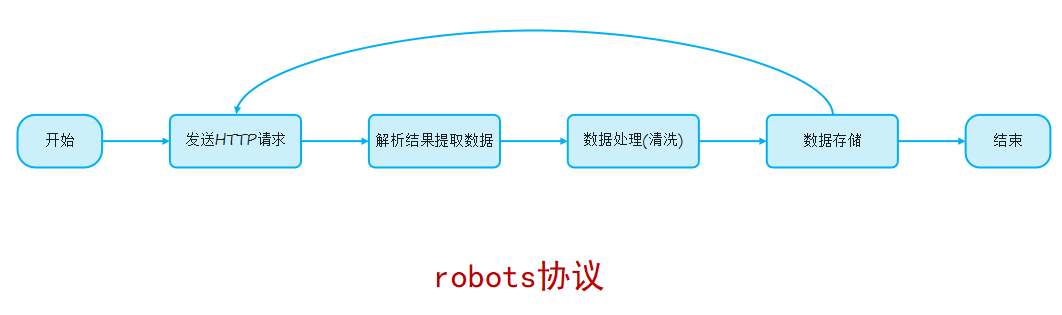
2.数据清洗:是指对采集到的原始数据进行处理、 修正、转换和标准化的过程,目的是让数据变得规范、准确 。
3.robots协议也称为爬虫协议、爬虫规则,是指网站根目录下存放的一份文本文件robots.txt,用于告诉爬虫哪些页面可以抓取,哪些页面不能抓取。(君子协议)
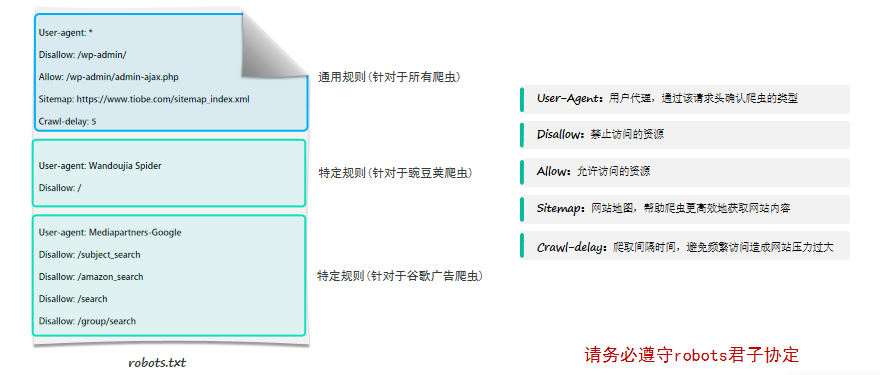
robots.txt 君子协定的数据获取规则:
User-Agent:用户代理,通过该请求头的标识,确认爬虫的身份
Disallow:不允许访问的资源
Allow:允许访问的资源
Sitemap:网站地图
Crawl-delay:访问的间隔时间
4.前端网页结构:一个网页是由三个部分组成的,分别是:HTML、CSS、JS(JavaScript)。
一个网页是由三个部分组成的,分别是:HTML、CSS、JS(JavaScript)。
(1) HTML:超文本标记语言,由一堆预设的标签(<h1>一级标题</h1>)构成。HTML负责网页的结构(页面元素和内容)
(2) CSS:层叠样式表。CSS负责网页的表现(页面元素的外观、位置等样式,如颜色、大小等)
(3) JS:全称为JavaScript,简称JS。负责网页的行为(交互效果)
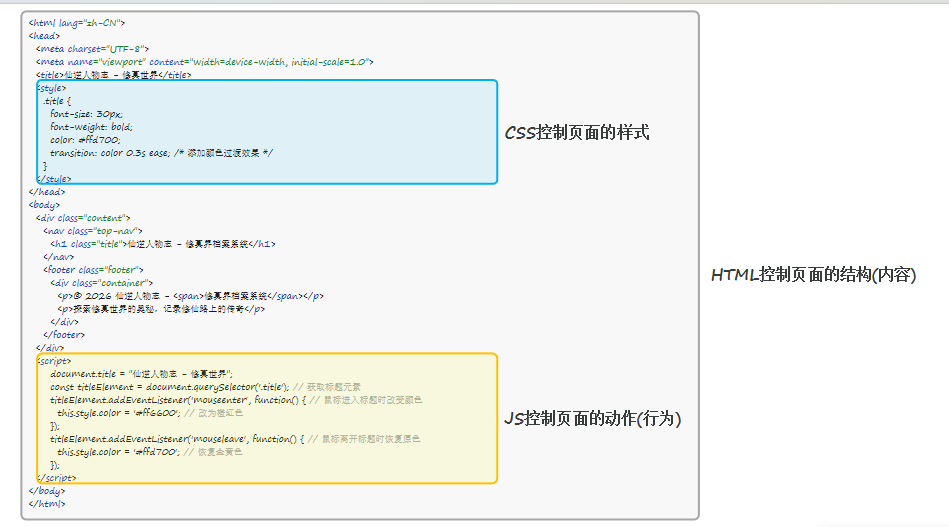
(1)HTML(HyperText Markup Language):超文本标记语言。
**超文本:**超越了文本的限制,比普通文本更强大。除了文字信息,还可以定义图片、音频、视频等内容。
**标记语言:**由标签 "<标签名>" 构成的语言
HTML标签都是预定义好的。例如:使用<h1>展示标题,使用<img>展示图片,使用<video>展示视频。
HTML代码直接在浏览器中运行,HTML标签由浏览器解析。
5.(1)网页解析:网页解析指的是从原始HTML文档中提取数据的过程,也是网络爬虫的关键步骤,从一堆标签文本中提取出需要的数据。
(2)lxml:是一个高性能的HTML/XML文档的解析库,支持基于Xpath语法来解析和获取网页数据。
python
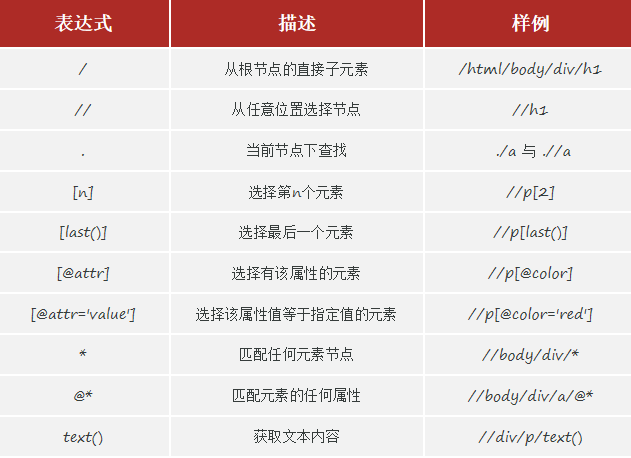
pip install lxml # 安装(3)Xpath:是一种用于在HTML/XML文档中导航或定位元素的查询语言,让你能够准确的定位文档中的特定元素、属性或文本 。
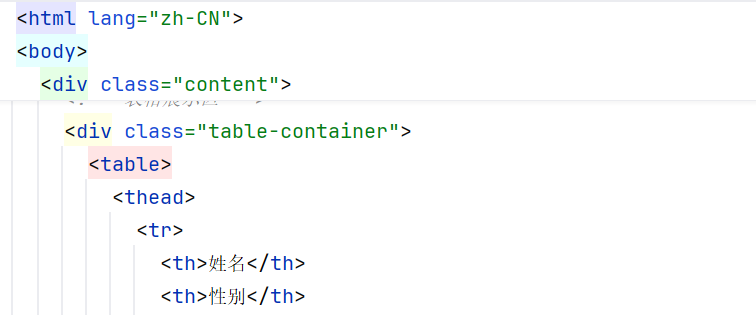
1.
python
from lxml import html
# 读取 html 文件
with open("resources/仙逆人物志.html", "r", encoding="utf-8") as f:
html_text = f.read()
# 解析html的文本, 将其转换为一个html文档对象
document = html.fromstring(html_text)
# 解析表头 - xpath语法
# /table/thead/tr/th/text() : 表示从根节点开始匹配
# //table/thead/tr/th/text(): 从任意位置开始匹配
# th_list = document.xpath("/html/body/div/div/table/thead/tr/th/text()")
# th_list = document.xpath("//table/thead/tr/th/text()")
th_list = document.xpath("//thead/tr/th/text()")
print("-------------------- 1 ------------------------")
print(th_list)-------------------- 1 ------------------------
'姓名', '性别', '头像', '修为', '技能', '身份地位', '师承', '法宝'
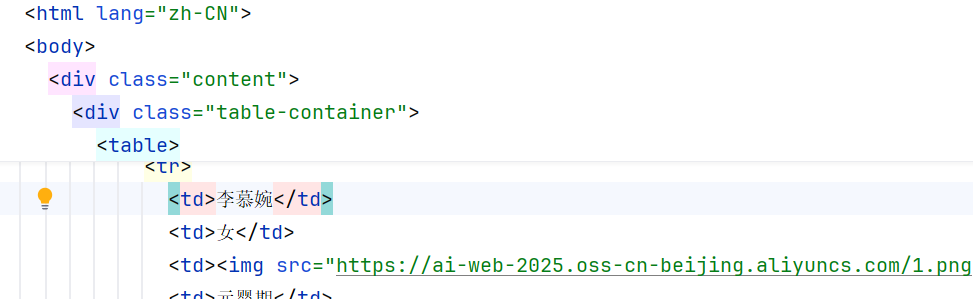
2.
python
# tr[2] : 表示匹配第2个tr标签
td_list = document.xpath("//tbody/tr[2]/td/text()")
print("-------------------- 2 ------------------------")
print(td_list)-------------------- 2 ------------------------
'李慕婉', '女', '元婴期', '冰系神通、寒气凝霜', '天逆宗长老', '家族传承', '寒冰玉镯、雪蚕丝袍'
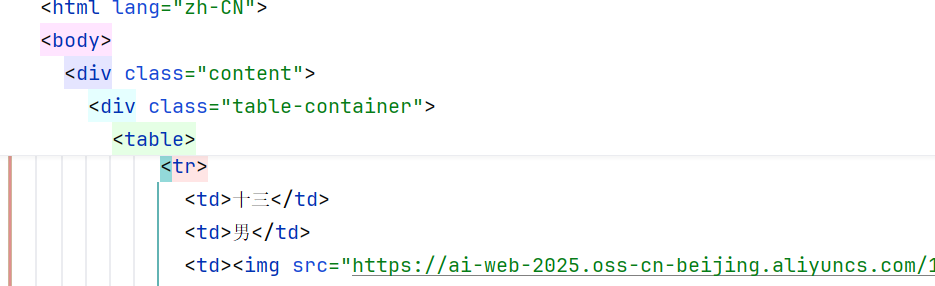
3.
python
# last() : 表示匹配倒数第二个
td_list = document.xpath("//tbody/tr[last()-1]/td/text()")
print("-------------------- 3 ------------------------")
print(td_list)-------------------- 3 ------------------------
'十三', '男', '筑基初期', '隐匿追踪、暗杀之术', '神秘杀手', '未知', '暗影匕首、隐身符'
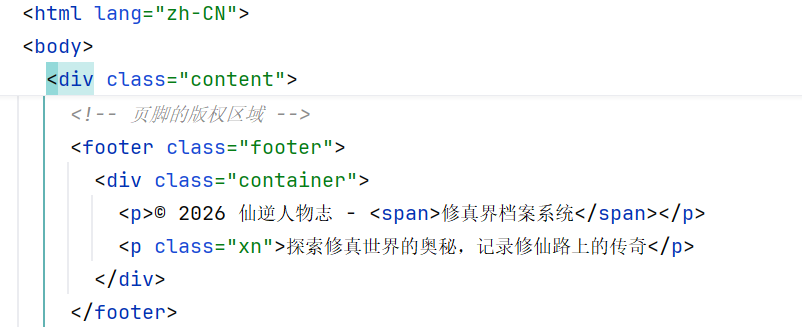
4.
python
# p[@class]: 表示匹配class属性为p的标签
# p_list = document.xpath("//p/text()") 所有p标签的文本
p_list = document.xpath("//p[@class]/text()")
print("-------------------- 4 ------------------------")
print(p_list)-------------------- 4 ------------------------
'探索修真世界的奥秘,记录修仙路上的传奇'
5.
python
# p[@class='xn']: 表示匹配class属性为xn的p标签
p_list = document.xpath("//p[@class='xn']/text()")
print("-------------------- 5 ------------------------")
print(p_list)-------------------- 5 ------------------------
'探索修真世界的奥秘,记录修仙路上的传奇'
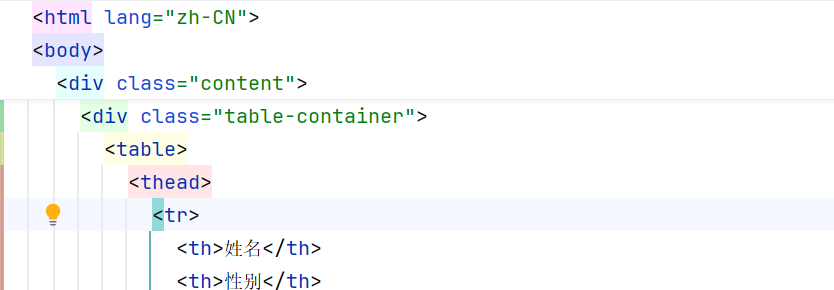
python
# * : 表示匹配任意标签
th_list = document.xpath("//thead/tr/*/text()")
print("-------------------- 6 ------------------------")
print(th_list)-------------------- 6 ------------------------
'姓名', '性别', '头像', '修为', '技能', '身份地位', '师承', '法宝'
7.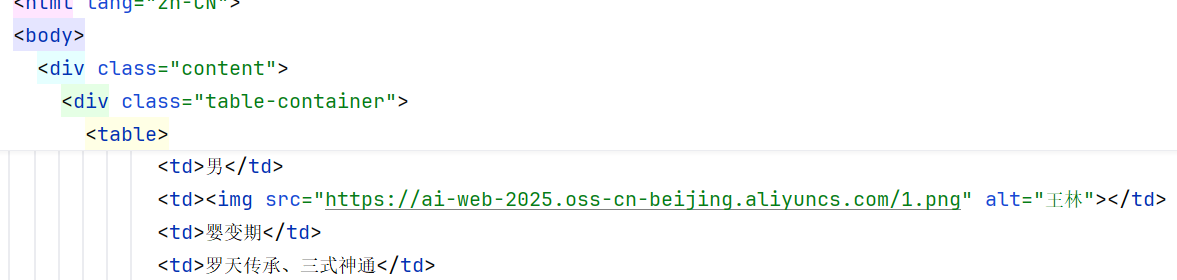
python
# @src: 表示匹配src属性
# @* : 表示匹配任意属性
# a_list = document.xpath("//td/img/@src")
a_list = document.xpath("//td/img/@*")
print("-------------------- 7 ------------------------")
print(a_list)-------------------- 7 ------------------------
['https://ai-web-2025.oss-cn-beijing.aliyuncs.com/1.png', '王林',
'https://ai-web-2025.oss-cn-beijing.aliyuncs.com/1.png', '李慕婉',
'https://ai-web-2025.oss-cn-beijing.aliyuncs.com/1.png', '王卓',
'https://ai-web-2025.oss-cn-beijing.aliyuncs.com/1.png', '柳眉',
'https://ai-web-2025.oss-cn-beijing.aliyuncs.com/1.png', '张虎',
'https://ai-web-2025.oss-cn-beijing.aliyuncs.com/1.png', '木冰眉',
'https://ai-web-2025.oss-cn-beijing.aliyuncs.com/1.png', '司徒南',
'https://ai-web-2025.oss-cn-beijing.aliyuncs.com/1.png', '天运子',
'https://ai-web-2025.oss-cn-beijing.aliyuncs.com/1.png', '云雀子',
'https://ai-web-2025.oss-cn-beijing.aliyuncs.com/1.png', '罗天星',
'https://ai-web-2025.oss-cn-beijing.aliyuncs.com/1.png', '藤化元',
'https://ai-web-2025.oss-cn-beijing.aliyuncs.com/1.png', '孙泰',
'https://ai-web-2025.oss-cn-beijing.aliyuncs.com/1.png', '墨智',
'https://ai-web-2025.oss-cn-beijing.aliyuncs.com/1.png', '十三',
'https://ai-web-2025.oss-cn-beijing.aliyuncs.com/1.png', '莫厉海']
6.案例(1):读取TIOBE官网排行前20的编程语言的信息
(1)查看TIOBE网站的robots.txt文件,明确资源获取的规则
(2)安装requests库,用于发送网络请求 (pip install requests)
(3)编写python代码,访问TIOBE网站,获取数据
注:Requests库是Python中最流行、最优雅的HTTP客户端库,让Python代码发送HTTP请求变得极其简单
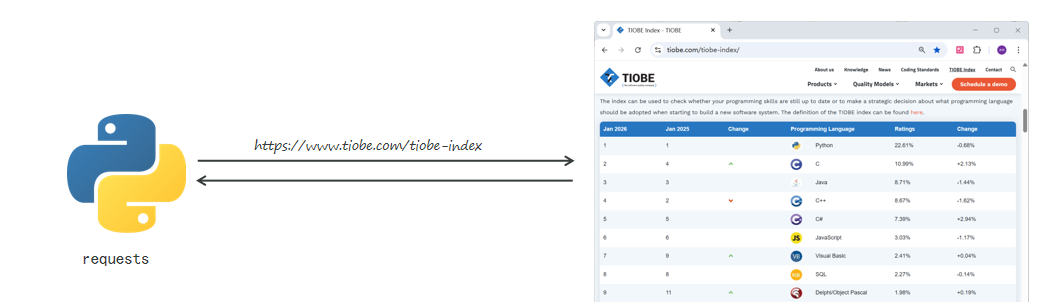
python
import requests
from lxml import html
# 定义url
target_url = "https://www.tiobe.com/tiobe-index/"
# 发送请求, 获取数据
response = requests.get(target_url)
# 输出数据到控制台
#print(response.text)
document = html.fromstring(response.text)
# 解析数据
# 解析表头
# th_list = document.xpath("//table[@id='top20']/thead/tr/th/text()")
# th_list = document.xpath("/html/body/section/div/article/table[1]/thead/tr/th/text()")
th_list = document.xpath("//*[@id='top20']/thead/tr/th/text()")
print(th_list)
# //*[@id="top20"]/thead/tr/th[1]
# //*[@id="top20"]/tbody/tr[1]
# 解析表格中的数据
tr_list = document.xpath("//table[@id='top20']/tbody/tr")
for tr in tr_list:
td_list = tr.xpath("./td/text()")
print(td_list)读取结果:
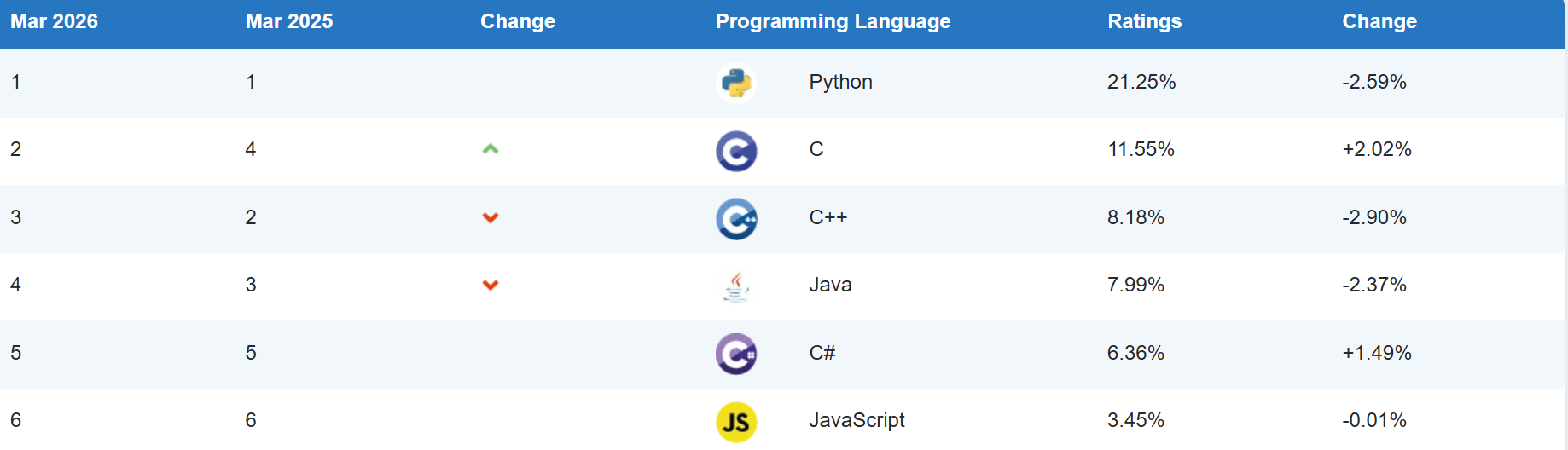
'Mar 2026', 'Mar 2025', 'Change', 'Programming Language', 'Ratings', 'Change'
'1', '1', 'Python', '21.25%', '-2.59%'
'2', '4', 'C', '11.55%', '+2.02%'
'3', '2', 'C++', '8.18%', '-2.90%'
'4', '3', 'Java', '7.99%', '-2.37%'
'5', '5', 'C#', '6.36%', '+1.49%'
'6', '6', 'JavaScript', '3.45%', '-0.01%'
'7', '9', 'Visual Basic', '2.50%', '-0.02%'
'8', '8', 'SQL', '2.00%', '-0.57%'
'9', '16', 'R', '1.88%', '+0.94%'
'10', '10', 'Delphi/Object Pascal', '1.80%', '-0.36%'
'11', '24', 'Perl', '1.75%', '+1.05%'
'12', '12', 'Scratch', '1.63%', '-0.03%'
'13', '11', 'Fortran', '1.45%', '-0.25%'
'14', '14', 'Rust', '1.31%', '+0.09%'
'15', '15', 'MATLAB', '1.29%', '+0.31%'
'16', '7', 'Go', '1.29%', '-1.49%'
'17', '17', 'Assembly language', '1.29%', '+0.42%'
'18', '13', 'PHP', '1.23%', '-0.25%'
'19', '18', 'Ada', '1.10%', '+0.25%'
'20', '26', 'Swift', '1.04%', '+0.44%'
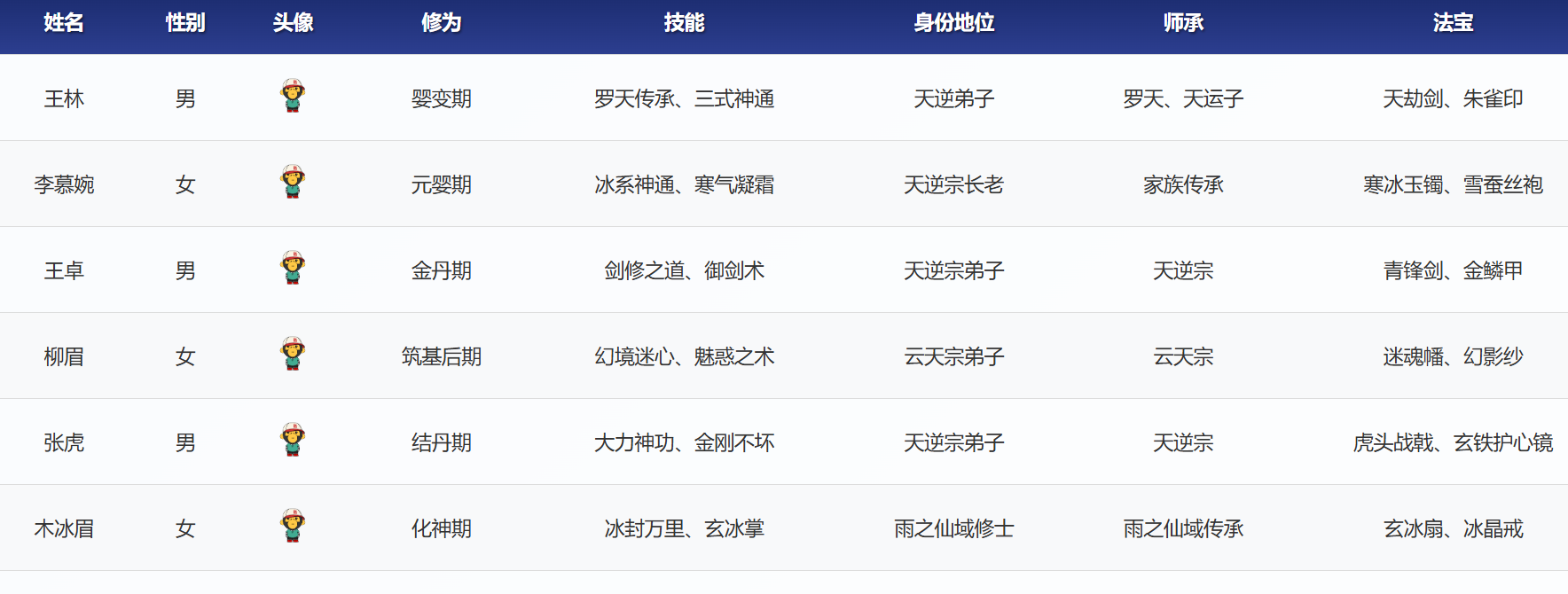
7.案例(2):读取本地网页信息
python
from lxml import html
# 读取 html 文件
with open("resources/仙逆人物志.html", "r", encoding="utf-8") as f:
html_text = f.read()
# 解析html的文本, 将其转换为一个文档对象
document = html.fromstring(html_text)
# 解析表头 - xpath语法
th_list = document.xpath("//table/thead/tr/th/text()")
print(th_list)
# 解析表格中的数据 - xpath语法
# 获取第一行数据
# td_list = document.xpath("//table/tbody/tr[1]/td/text()")
# print(td_list)
# 获取所有行数据
tr_list = document.xpath("//table/tbody/tr")
for tr in tr_list:
td_list = tr.xpath("./td/text()")
print(td_list)读取结果:
'姓名', '性别', '头像', '修为', '技能', '身份地位', '师承', '法宝'
'王林', '男', '婴变期', '罗天传承、三式神通', '天逆弟子', '罗天、天运子', '天劫剑、朱雀印'
'李慕婉', '女', '元婴期', '冰系神通、寒气凝霜', '天逆宗长老', '家族传承', '寒冰玉镯、雪蚕丝袍'
'王卓', '男', '金丹期', '剑修之道、御剑术', '天逆宗弟子', '天逆宗', '青锋剑、金鳞甲'
'柳眉', '女', '筑基后期', '幻境迷心、魅惑之术', '云天宗弟子', '云天宗', '迷魂幡、幻影纱'
'张虎', '男', '结丹期', '大力神功、金刚不坏', '天逆宗弟子', '天逆宗', '虎头战戟、玄铁护心镜'
'木冰眉', '女', '化神期', '冰封万里、玄冰掌', '雨之仙域修士', '雨之仙域传承', '玄冰扇、冰晶戒'
'司徒南', '男', '化神后期', '南宫剑诀、遁甲术', '南宫世家家主', '南宫世家传承', '南宫剑、遁甲符'
'天运子', '男', '问鼎中期', '天运神通、推演之术', '天运宗宗主', '自创天运之道', '天运珠、问鼎印'
'云雀子', '男', '问鼎后期', '雀羽飞剑、风雷遁', '踏天峰传人', '踏天峰传承', '云雀剑、风雷翼'
'罗天星', '男', '婴变前期', '星辰之力、星移斗转', '罗天星域守护者', '星辰古神传承', '星河图、星辰链'
'藤化元', '男', '元婴大圆满', '藤蔓束缚、化神之术', '藤家老祖', '藤家传承', '化神藤鞭、元婴护盾'
'孙泰', '男', '筑基后期', '沙土遁术、黄沙漫天', '沙家族长', '沙家传承', '黄沙印、遁地符'
'墨智', '男', '化神初期', '悟道意境、墨染虚空', '神秘强者', '自创意境之道', '悟道笔、意境画卷'
'十三', '男', '筑基初期', '隐匿追踪、暗杀之术', '神秘杀手', '未知', '暗影匕首、隐身符'
'莫厉海', '男', '元婴初期', '烈焰神通、火海无边', '火焚国国主', '火焚国传承', '烈焰刀、火灵珠'
8.CSV:(Comma-Separated Values,逗号分隔值),是一种简单、通用的文本文件格式,用于存储表格数据,可以直接使用Excel打开 。
(1)法一:
python
# csv操作 - 方式一:文件操作的原始方式
# 写
with open("csv_data/01.csv", "w", encoding="utf-8") as f:
f.write("姓名,年龄,性别,爱好\n") # 写入表头
f.write("小王,18,男,'football,Java'\n") # 写入数据
f.write("小李,18,女,Python\n")
f.write("小张,18,男,C++\n")
f.write("小王,20,男,Go\n")
# 读
with open("csv_data/01.csv", "r", encoding="utf-8") as f:
for line in f:
print(line.strip())line.strip() 是 Python 中用于处理字符串的常用方法,其主要作用是移除字符串开头和结尾处的指定字符 。当
strip()方法不带任何参数时,它会移除字符串两端 的所有空白字符。空白字符包括:空格、换行符 (\n)、回车符 (\r)、制表符 (\t) 等。
(2)法二:csv (推荐)
python
# csv操作 - 方式二:csv (推荐)
import csv
# 写
with open("csv_data/02.csv", "w", encoding="utf-8", newline="") as f:
writer = csv.DictWriter(f, fieldnames=["姓名", "年龄", "性别", "爱好"])
writer.writeheader() # 写入表头
writer.writerow({"姓名": "小王", "年龄": 18, "性别": "男", "爱好": "football,Java"}) # 写入数据
writer.writerow({"姓名": "小李", "年龄": 18, "性别": "女", "爱好": "Python"})
writer.writerow({"姓名": "小张", "年龄": 18, "性别": "男", "爱好": "C++"})
writer.writerow({"姓名": "涛哥", "年龄": 19, "性别": "男", "爱好": "Python,Java"})
# 读
with open("csv_data/02.csv", "r", encoding="utf-8") as f:
reader = csv.DictReader(f)
for row in reader:
print(row)