关于浏览器,之前写过很多篇:
- Chrome浏览器使用技巧
- AI浏览器概述:Atlas、Comet、Fellou、BrowserOS
- 浏览器自动化:Puppeteer、Playwright、Skyvern、StageHand
- AI浏览器技术栈:Browser Use、Computer Use、Mobile Use
本文继续汇总一些浏览器自动化相关的开源项目。
OmniParser
技术报告,微软开源(GitHub,24.6K Star,2.2K Fork)基于Python,把任意UI截图解析成结构化的可操作元素,支持与GPT-4V等主流多模态大模型集成,让AI能看懂界面。HF模型。
接收UI截图和用户任务描述,输出:
- 解析后的截图:在原图上叠加边界框和数字ID,标记出每一个可交互元素的位置
- 局部语义信息:提取屏幕上的文本内容,并为图标生成自然语言描述
底层使用模型:
- YOLO:负责检测屏幕上的可交互区域(按钮、图标、输入框等),速度快、精度高
- Florence:微软自研视觉模型,负责图标的语义理解和描述生成
- BLIP2:补充视觉-语言对齐能力,增强对复杂UI元素的理解
实战
bash
git clone https://github.com/microsoft/OmniParser.git
cd OmniParser
conda create -n "omni" python==3.12
conda activate omni
pip install -r requirements.txt
# 从HF下载模型
python gradio_demo.pyScrapeGraphAI
官网,开源(GitHub,23.3K Star,2k Fork)Python库,专为网页和本地文档(HTML、JSON、XML、Markdown等)设计的数据提取工具。解决传统爬虫的痛点:规则复杂、网站变动频繁、维护成本高。借助LLM能根据自然语言提示,自动生成抓取逻辑。
AI助手,输入需求,输出结构化数据;支持多语言文档和集成(如 Langchain)。
一种基于节点的管道系统,能处理单页、多页甚至生成脚本。
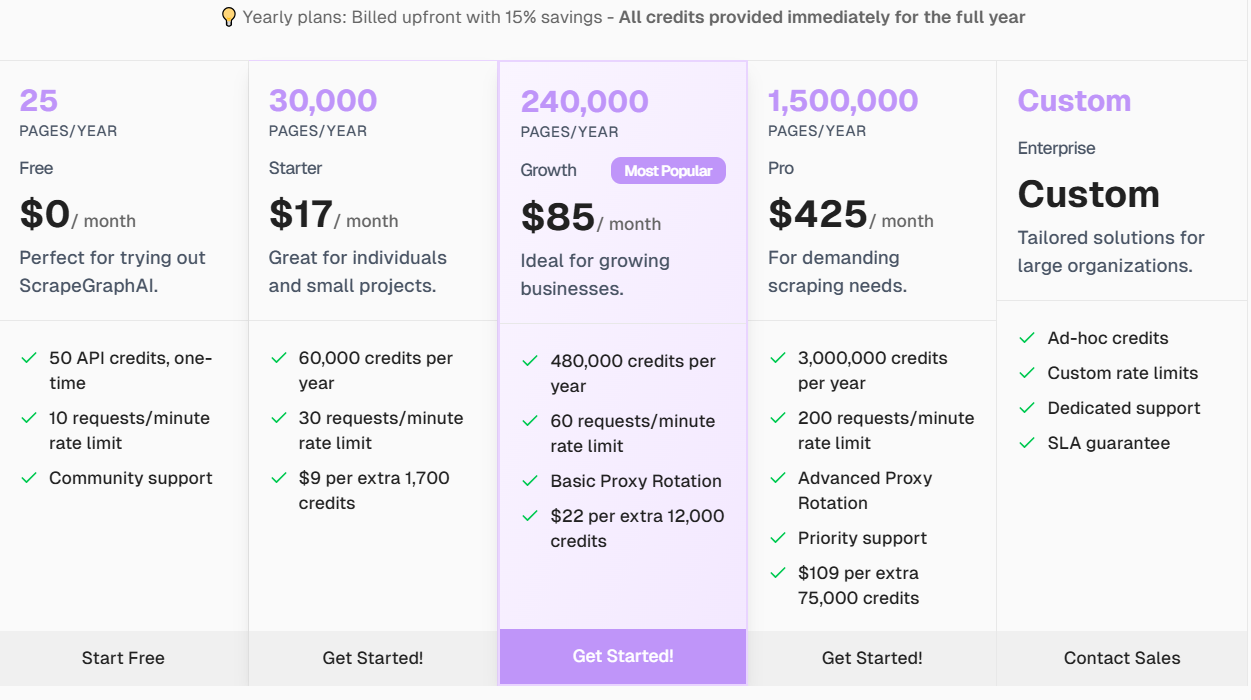
特性
- 智能单页抓取(SmartScraperGraph):只需提示和URL,就提取指定信息。如从公司官网拉取描述、创始人和社会媒体链接。支持JSON结构化输出。
- 多页/搜索抓取 (SearchGraph, OmniSearchGraph):能从搜索引擎top N结果中批量提取。想象爬取多个产品页的价格数据,一键搞定。
- 脚本和语音生成 (ScriptCreatorGraph, SpeechGraph):不止输出数据,还能生成Python脚本帮你自动化未来抓取。SpeechGraph甚至把结果转成音频文件,适合做播客或无障碍应用。
- 多格式支持:本地文件如JSON、XML、CSV也能处理。
MarkdownifyGraph,把网页转Markdown,完美适配笔记工具。 - LLM集成:兼容OpenAI、Groq、Ollama、Azure等。本地跑Ollama零成本,线上用Groq超快。
实战
安装
bash
pip install scrapegraphai
# 抓取网页内容
playwright installPython SDK集成
py
import json
from scrapegraphai.graphs import SmartScraperGraph
graph_config = {
"llm": {
"model": "ollama/llama3.2",
"model_tokens": 8192,
"format": "json",
},
"verbose": True,
"headless": False,
}
smart_scraper_graph = SmartScraperGraph(
prompt="Extract useful information from the webpage, including a description of what the company does, founders and social media links",
source="https://scrapegraphai.com",
config=graph_config
)
result = smart_scraper_graph.run()
print(json.dumps(result, indent=4))仓库用Repomix打包成单Markdown,方便分析。核心在smart_scraper_graph.py定义基类和具体Graph。每个Graph继承openai.py处理API调用。统一接口,切换模型只需改config。
utils/:工具箱。包括清理 HTML、代理旋转、token 计算等。CI用GitHub Actions。.env.example到ollama pull llama3.2下载模型。
新建 python scrape.py,输出 JSON 结果。OpenAI 用户换 config 为 headless: False 看浏览器过程。
实际应用场景:从数据分析到 AI 代理
ScrapeGraphAI 不止玩具,它在实战场上发光。举几个场景:
市场调研:用 SearchGraph 抓取竞品网站的价格/评论,生成报告。结合 Pandas 分析,帮电商监控市场。
内容聚合:MarkdownifyGraph 转网页为 Markdown,集成 Notion 或 Obsidian。扩展:建 RSS 替代,自动汇总新闻。
AI 代理集成:接 Langchain/CrewAI,建聊天机器人。场景:用户问"这个公司创始人是谁?",代理用 ScrapeGraphAI 实时抓取回答。
批量处理:SmartScraperMultiGraph 处理 CSV 列表的 URLs,适合爬取 GitHub repos 数据做趋势分析。
进阶玩法:加OCR节点,抓取图片文本;或集成VectorDB,建知识图谱。
Magnitude
大多数浏览器自动化工具(如Selenium、Playwright)依赖于DOM结构来定位元素,存在两大痛点:
- 依赖DOM结构:若页面元素的属性或层级发生变化,脚本就会失效
- 指令僵化:只能执行固定流程,遇到意外情况无法自主调整
Magnitude凭借两大创新旨在解决上述问题:
- 视觉优先架构:通过多模态LLM直接分析页面截图,基于像素坐标执行操作,完全不依赖DOM结构
- 可控且可重复的自动化:支持从精细操作到复杂流程的不同抽象级别,结合自定义提示词,既灵活又可预测。
Magnitude推出,项目官网,作为一款基于AI视觉的开源(GitHub,4K Star,223 Fork)Web自动化框架,摆脱传统自动化工具对DOM结构的依赖,通过模拟人类视觉和交互方式来操控浏览器。不是通过查找元素的ID或类名来操作页面,而是像人一样看界面并做出反应。
在WebVoyager评测中获得94%的高分,这意味着它在处理各种复杂Web任务时具有接近人类的能力。
提供四大核心能力,覆盖Web自动化的全场景需求:
- 智能导航(Navigate):理解任何网页界面,并规划操作操作路径
- 精准交互(Interact):通过鼠标和键盘执行精确操作
- 数据提取(Extract):智能提取结构化数据
- 结果验证(Verify):内置测试运行器,支持强大的视觉断言
适用场景:
- 前端Web自动化测试任务
- 在无API的应用之间进行集成
- 网页数据提取和分析
- 跨应用数据同步和工作流自动化
- 作为自定义浏览器代理的构建块
- 辅助开发人员进行重复性操作
实战
创建新项目,并引导完成Magnitude的设置,生成一个可立即运行的示例脚本
bash
npx create-magnitude-app在现有项目中使用测试运行器
bash
npm i --save-dev magnitude-test && npx magnitude init初始化后会生成:
magnitude.config.ts:配置文件example.mag.ts:示例测试文件
API 设计非常直观,支持从高层任务到底层操作的各种需求:
ts
# 处理高层任务
await agent.act('创建一个任务', {
data: {
title: '使用 Magnitude',
description: '运行"npx create-magnitude-app"并跟随指示',
},
});
# 也能处理底层操作
await agent.act('将"使用 Magnitude"拖拽到"进行中"列的顶部');
# 智能提取数据
const tasks = await agent.extract(
'列出进行中的任务',
z.array(z.object({
title: z.string(),
description: z.string(),
difficulty: z.number().describe('难度评级1-5')
})),
);
test('使用有效凭据登录', {url: "https://qa-bench.com"})
.step('登录应用')
.data({username: "test-user@magnitude.run"})
.secureData({password: "test"})
.check('能看到仪表盘')
.step('创建新公司')
.data("前两个值随意,其余用默认")
.check("公司添加成功");WebRPA
开源(GitHub,1.6K Star,146 Fork)可视化网页自动化工具。
功能特性:
- 开箱即用,免配环境:自带Python 3.13和
Node.js环境,下载解压即可运行,彻底告别繁琐的环境配置。 - 260+内置模块:涵盖网页操作、数据采集(JSON/正则/Excel)、基于FFmpeg的50多种音视频格式转换。只需要像搭积木一样把它们拖拽连线,全流程不用敲一行代码。
- 底座:浏览器自动化底层基于Playwright,支持CSS选择器和XPath定位;AI模型支持OpenAI、智谱、通义千问。
- 触发器系统:支持Webhook、定时任务、文件监控、甚至是热键监听等10种触发方式。
OpenBrowserClaw
官网,开源(GitHub,583 Star,79 Fork)纯浏览器原生的个人AI助手;零基础设施:浏览器就是服务器。
技术
- 极致的本地存储与任务调度
- 状态存储:使用IndexedDB安全存储聊天记录和系统配置。
- 文件系统:巧妙利用OPFS(浏览器本地私有文件系统)为AI提供工作目录。AI可以自由读写文件,摆脱
Node.js依赖。 - 主线程调度:自带任务调度器,只要网页开着,定时自动化任务就会精准执行。
- 浏览器里的原生Linux沙箱
AI助手需要执行系统命令来完成复杂任务。OpenBrowserClaw通过WASM(WebAssembly技术),直接在浏览器里启动Alpine Linux虚拟机- Bash工具:LLM可在这个沙箱里直接执行
shell命令 - JS环境:支持在独立Web Worker中安全执行JS脚本代码
- Bash工具:LLM可在这个沙箱里直接执行
- 纯 HTTPS驱动的Telegram无缝接入:无需配置复杂Webhook或反向代理。它完全通过浏览器发起HTTPS请求与Telegram Bot互通。浏览器在后台挂着,你就能在手机上随时随地下发任务。
对比
| 对比维度 | NanoClaw(传统架构) | OpenBrowserClaw(纯前端架构) |
|---|---|---|
| 运行环境 | Node.js进程 | 纯浏览器标签页 |
| 沙箱环境 | Docker容器 | Web Worker+WASM虚拟机 |
| 数据库 | SQLite | IndexedDB |
| 部署方式 | 自建服务器部署 | 任意静态托管(如GitHub Pages) |
实战
bash
git clone https://github.com/your-repo/openbrowserclaw.git
cd openbrowserclaw
npm install
npm run dev自动打开浏览器新标签页http://localhost:5173,填写API Key。密钥使用AES-256-GCM算法加密,保存在浏览器本地,绝不上传任何第三方服务器。
想让AI帮你执行底层系统命令?你需要下载v86的WASM文件和Alpine系统镜像,并将它们放到项目的指定目录中。
bash
public/assets/v86.wasm
public/assets/v86/libv86.js
public/assets/alpine-rootfs.ext2