@tpc(MySQL B+树与复合索引完全指南:从底层原理到高性能优化)
引言:从"图书馆的索书号"到"数据库的索引"
假设你走进一家巨大的图书馆,里面藏书数亿本。你想找一本叫《MySQL性能优化》的书。如果没有索引,你只能一本一本翻找------这就是全表扫描 ,需要数亿次检查。如果图书馆有一套索书号系统 ,你根据"计算机→数据库→MySQL"的层级找到对应书架,再按编号顺序定位到那本书------这就是B+树索引的工作方式。
在数据库世界里,B+树是MySQL InnoDB存储引擎的索引基石。本文将带你从磁盘IO的原理开始,深入B+树的数据结构,并围绕复合索引展开:存储结构是什么?为什么遵循最左前缀法则?如何设计高效的复合索引?以及如何识别和避免索引失效的陷阱。
一、前置知识:为什么需要索引?磁盘IO的瓶颈
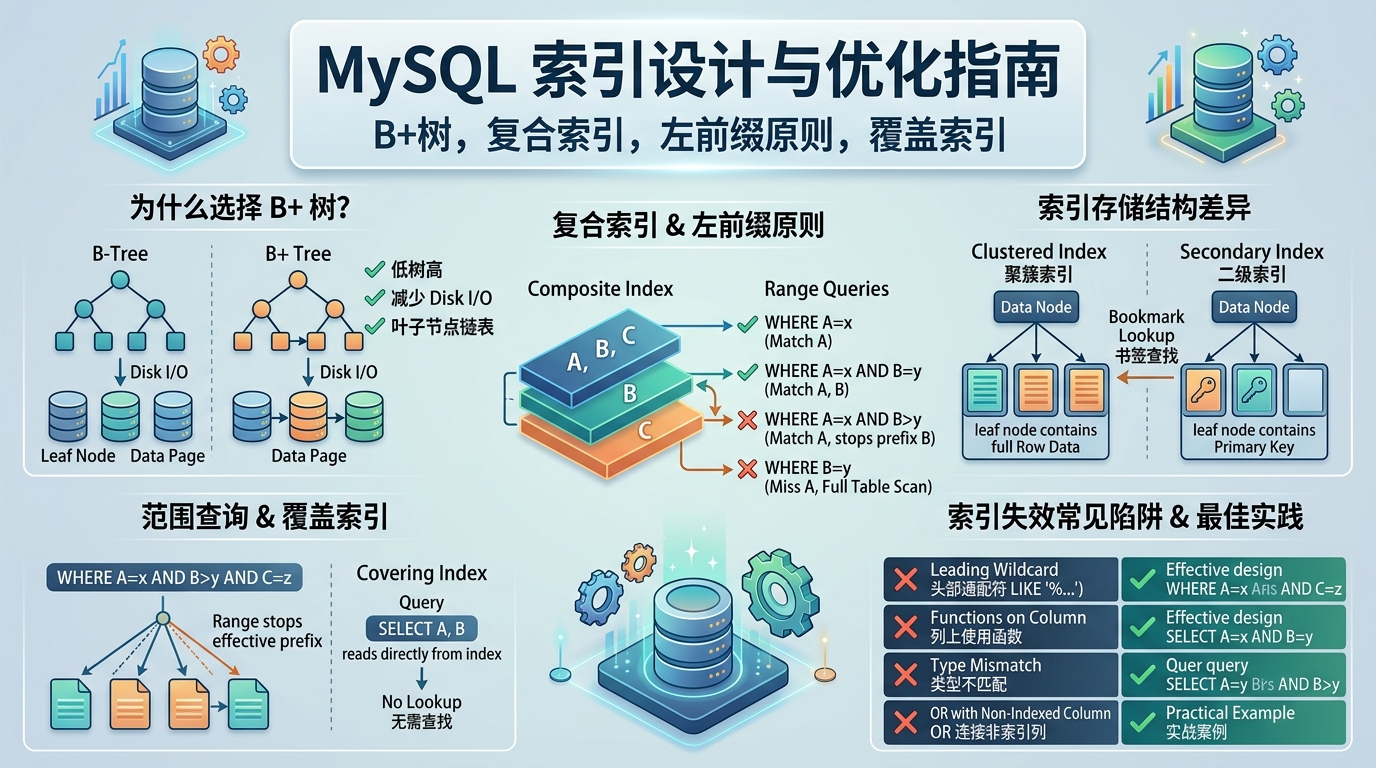
在深入B+树之前,我们先简单复习一下计算机读取磁盘数据的方式 。数据存储在磁盘上,数据库每次读取数据的最小单位是页 (通常为16KB)。磁盘IO是非常缓慢的操作,因此,数据库索引的核心目标就是:用尽可能少的磁盘IO,定位到目标数据。
为了达到这个目的,索引需要做到:
- 树高尽量低:树的高度决定了查询需要的磁盘IO次数
- 叶子节点能快速遍历:范围查询需要高效扫描连续数据
- 节点存储密度高:每个磁盘页能容纳尽可能多的索引项
二、B+树 vs B树 vs 红黑树:数据结构之战
2.1 核心差异对比
| 特性 | B+树 | B树 | 红黑树 |
|---|---|---|---|
| 数据存储位置 | 仅叶子节点 | 所有节点 | 所有节点 |
| 非叶子节点内容 | 只存索引(键+指针) | 键+数据+指针 | 键+数据+颜色 |
| 叶子节点结构 | 有序双向链表 | 无链表 | 无链表 |
| 树高 | 最低 | 中等 | 最高 |
| 磁盘IO次数 | 最优 | 中等 | 最差 |
| 范围查询性能 | 极优(链表遍历) | 差(需多次回溯) | 差 |
| 适用场景 | 数据库索引 | 文件系统 | 内存结构 |
2.2 为什么B+树是数据库索引的"天选之子"
原因一:非叶子节点不存数据,节点更小 → 树高更低 → 磁盘IO更少
在B+树中,非叶子节点只存储键(索引值)和指向子节点的指针,不存储完整数据行。这意味着每个磁盘页可以容纳更多的索引键,同一层能覆盖更广的数据范围。同样是存储2亿条数据,B+树通常只需要3-4层,而红黑树可能需要20多层。树高决定了磁盘IO次数------查询只需要3-4次IO,而红黑树需要20多次reference:0。
原因二:叶子节点有序链表 → 范围查询效率极高
B+树的所有叶子节点通过双向指针连接,形成一个有序链表。当执行WHERE age BETWEEN 18 AND 25时,只需在B+树中找到18的位置,然后沿着链表向后扫描直到25,无需回溯到上层节点reference:1。而B树的叶子节点没有链表连接,范围查询需要反复在树中查找,效率低下。
原因三:查询性能稳定
B+树的所有数据都在叶子节点,每个查询都必须走到叶子节点,因此所有查询的路径长度(IO次数)相同,性能稳定。B树的数据分布在各层,有的查询可能在非叶子节点就命中,有的需要走到叶子节点,性能波动大。
三、复合索引的底层存储结构
3.1 单列索引 vs 复合索引
单列索引的B+树叶子节点存储的是一列的值。而复合索引 是多列组合的B+树,叶子节点存储的是索引字段组合 + 主键值 ,按左到右依次排序存储reference:2reference:3。
3.2 复合索引B+树存储示意图
根节点
(20, 'C', ...) 等组合键
内部节点
(10, 'A', ...)等组合键
内部节点
(30, 'D', ...)等组合键
叶子节点
(10, 'A', ...) + PK + 双向指针
叶子节点
(15, 'B', ...) + PK + 双向指针
叶子节点
(30, 'D', ...) + PK + 双向指针
叶子节点
(40, 'E', ...) + PK + 双向指针
3.3 聚簇索引 vs 辅助索引(复合索引)
| 索引类型 | 叶子节点存储内容 | 查询方式 |
|---|---|---|
| 聚簇索引(主键索引) | 整行数据 | 直接获取完整数据 |
| 辅助索引(普通索引/复合索引) | 索引字段值 + 主键值 | 需回表查询聚簇索引 |
创建复合索引INDEX idx_name_age(name, age)时,叶子节点存储的是(name, age, 主键值)。如果查询只涉及name和age字段,可以直接从索引获取数据(覆盖索引 );如果需要*或其他字段,则必须先拿到主键值,再通过主键索引回表查询完整数据reference:4reference:5。
四、最左前缀法则:从B+树排序逻辑理解
4.1 为什么必须遵循最左前缀法则?
复合索引的B+树按照索引列的顺序从左到右依次排序 reference:6。以索引(a, b, c)为例:
- 首先按
a排序 a相同的情况下,再按b排序a和b都相同的情况下,再按c排序
因此,B+树只保证a列的有序性。如果查询条件跳过了a,直接使用b,那么b在全局是无序的,B+树无法快速定位。
4.2 命中与失效场景详解(索引(a, b, c))
| WHERE条件 | 命中索引列 | 原因 |
|---|---|---|
WHERE a = 1 |
a |
从最左列开始 |
WHERE a = 1 AND b = 2 |
a, b |
前缀匹配 |
WHERE a = 1 AND b = 2 AND c = 3 |
a, b, c |
全列匹配 |
WHERE a = 1 AND c = 3 |
a |
b被跳过,c无法使用 |
WHERE b = 2 |
❌ 不命中 | 跳过最左列 |
WHERE b = 2 AND c = 3 |
❌ 不命中 | 跳过最左列 |
WHERE a = 1 AND b > 2 AND c = 3 |
a, b |
范围查询阻断后续列 |
4.3 正反案例
✅ 命中案例:
sql
-- 使用索引的全部三列
SELECT * FROM t WHERE a = 1 AND b = 2 AND c = 3;
-- 使用索引的前两列
SELECT * FROM t WHERE a = 1 AND b = 2;❌ 失效案例:
sql
-- 跳过最左列,无法使用索引
SELECT * FROM t WHERE b = 2;
-- 范围查询阻断后续列,c无法使用索引
SELECT * FROM t WHERE a = 1 AND b > 2 AND c = 3;4.4 范围查询的阻断效应
当查询条件中出现范围查询 (>, <, BETWEEN, LIKE 'A%')时,该列之后的索引列将无法被使用reference:7。以索引(a, b, c)为例:
WHERE a = 1 AND b > 2 AND c = 3:只能用到a和b,c无法使用WHERE a = 1 AND b LIKE 'A%' AND c = 3:只能用到a和b,c无法使用
五、复合索引设计与优化
5.1 字段顺序设计:等值查询优先,范围查询靠后
设计复合索引时,应遵循**"等值查询字段放左侧,范围查询字段放右侧"**的原则reference:8。
案例对比 :假设业务查询为WHERE studio = 'online' AND audit_time < '2025-08-01'
- ❌ 错误索引
(audit_time, studio):audit_time是范围查询,阻断studio的索引使用 - ✅ 正确索引
(studio, audit_time):studio精确匹配后,再对audit_time进行范围扫描reference:9
5.2 覆盖索引:避免回表
覆盖索引是指查询需要的所有字段都包含在索引中,此时MySQL可以直接从索引获取数据,无需回表查询聚簇索引reference:10。
性能对比:
- ❌ 非覆盖索引:
SELECT * FROM users WHERE name = 'Alice'→ 先在辅助索引找到主键 → 回表查询完整数据 → 约3-5次IO - ✅ 覆盖索引:
SELECT name, age FROM users WHERE name = 'Alice'→ Extra显示Using index→ 仅1-2次IOreference:11
5.3 索引的代价:不是越多越好
索引会显著降低INSERT、UPDATE、DELETE的性能。每次数据变更都需要同步维护索引,写入性能可能下降2-8倍reference:12。因此,索引设计需要权衡查询频率和写入频率。
5.4 复合索引的设计边界
| 原则 | 说明 |
|---|---|
| 高频查询前置 | 最常用的查询条件放在索引最左边 |
| 等值查询优先 | 等值查询字段放在范围查询字段之前 |
| 高区分度靠前 | 区分度高的列放在前面,快速缩小范围 |
| 避免冗余索引 | 已有索引(a, b)可覆盖(a),无需重复创建 |
六、索引失效的七大陷阱
| 失效场景 | 错误示例 | 正确写法 |
|---|---|---|
| 使用函数 | WHERE YEAR(create_time)=2023 |
WHERE create_time BETWEEN '2023-01-01' AND '2023-12-31' |
| 隐式类型转换 | WHERE phone = 123456(phone是varchar) |
WHERE phone = '123456' |
| 前导模糊匹配 | WHERE name LIKE '%abc' |
WHERE name LIKE 'abc%' |
| OR条件混用 | WHERE a=1 OR b=2 |
拆分为UNION |
| 负向条件 | WHERE status != 'active' |
WHERE status IN ('inactive', 'pending') |
| 跳过最左前缀 | WHERE b=2(索引(a,b,c)) |
按最左顺序使用 |
| NULL值判断 | WHERE col IS NULL |
设置默认值避免NULL查询reference:13 |
七、总结
| 核心知识点 | 关键结论 |
|---|---|
| B+树的优势 | 非叶子节点不存数据 → 树高低、磁盘IO少;叶子节点有序链表 → 范围查询高效 |
| 复合索引存储 | 按左到右顺序排序,叶子节点存索引字段+主键值 |
| 最左前缀法则 | 查询必须从最左列开始;范围查询会阻断后续列 |
| 覆盖索引 | 查询字段全在索引中时,Extra显示Using index,无需回表 |
| 索引设计原则 | 等值查询放左边,范围查询放右边;高区分度前置 |
| 索引失效陷阱 | 函数、类型转换、前导模糊、跳过前缀等都会导致索引失效 |
一句话总结:B+树通过非叶子节点只存索引的设计,用更低的树高换来了更少的磁盘IO;复合索引的B+树按左到右顺序排序,因此查询必须遵循最左前缀法则才能命中索引。理解这些底层原理,是写出高效SQL和设计优秀索引的基础。