百度千帆 OCR(Qianfan-OCR) 是百度千帆团队于 2026 年 3 月发布的端到端统一文档智能大模型,主打 "单模型搞定全链路文档处理",与传统的多阶段OCR流水线(将独立的版面检测、文字识别和语言理解模块串联)不同,千帆-OCR 以4B所谓参数可执行 直接的图像到Markdown转换,并支持广泛的提示驱动任务------从结构化文档解析、表格提取,到图表理解、文档问答和关键信息抽取------全部由单一模型完成。在多项权威评测中登顶,且已开源。
一、资源链接
GitHub 仓库:https://github.com/baidubce/Qianfan-VL
论文链接:https://arxiv.org/pdf/2603.13398
模型下载:https://www.modelscope.cn/models/baidu-qianfan/Qianfan-OCR
博客文档:https://baidubce.github.io/Qianfan-VL/
二、核心创新
Qianfan-OCR 作为 4B 参数统一端到端模型,通过三大核心设计解决上述问题,实现文本识别、布局分析、语义理解的一体化:
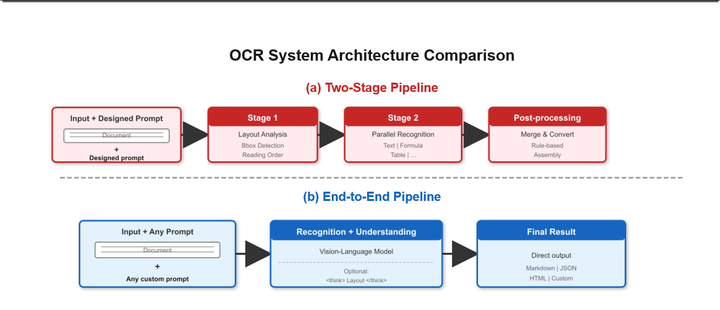
2.1.端到端架构(End-to-End Architecture)
将布局分析、文本识别、语义理解整合到单一视觉 - 语言模型中,消除阶段间误差传播,全程保留完整视觉上下文(空间关系、图表结构、格式信息);简单任务(如纯文本转录)可跳过布局预处理,直接输出结果,提升效率。
2.2.Layout-as-Thought
一项关键创新是 Layout-as-Thought:当输入中包含 ⟨think⟩ token 时,会触发一个可选的思维阶段,模型在此阶段先生成结构化的版面表示(边界框、元素类型、阅读顺序),再输出最终结果。
该机制具有双重作用:
- 功能性:在端到端范式内恢复版面分析能力------用户可直接获得结构化的版面分析结果
- 增强性:针对版面复杂、元素杂乱或阅读顺序非常规的文档,提供有针对性的精度提升
何时使用:对于包含混合元素类型的异构页面(如试卷、技术报告、报纸),建议启用思维模式;对于同质化文档(如单栏文本、简单表单),建议关闭以获得更优效果和更低延迟。
2.3. OCR 与文档理解的统一
突破传统 OCR 仅能字符级提取的局限,将OCR 专用级精度与语义推理能力结合,单模型支持从基础 OCR(手写、表格、公式)到高阶理解(图表分析、文档问答、关键信息抽取 KIE)的全链路任务,且支持提示词驱动的灵活控制。
三、模型架构与训练
3.1. 整体架构
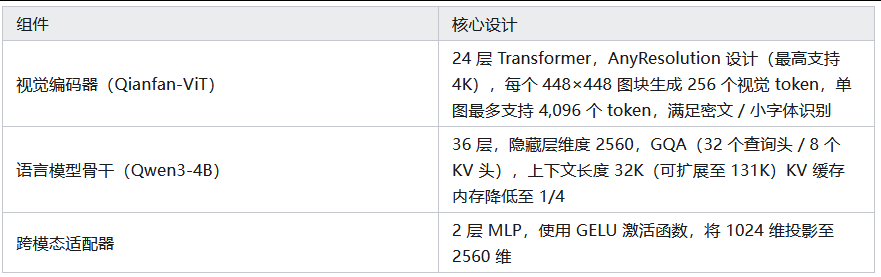
3.2. 大规模数据合成
构建 6 大专属数据合成流水线,覆盖文档解析、KIE、复杂表格、图表理解、公式识别、多语言 OCR,支撑模型全能力训练;关键设计包括:
- 采用 PaddleOCR-VL 的 25 类精细布局标签体系(优于粗粒度标签),提升下游任务效果;
- 多语言覆盖 192 种语言,针对不同书写体系(如阿拉伯语 RTL、汉字)做差异化处理;
- 针对文档图像做三级噪声增强(文本噪声、背景噪声、成像噪声)+ 旋转增强,提升鲁棒性。
3.3. 四阶段渐进式训练策略
从基础跨模态对齐到高阶推理,分阶段优化,全程以 OCR 为核心构建数据混合策略,避免灾难性遗忘:
- 跨模态对齐(50B token):仅训练适配器,快速实现视觉 - 语言基础对齐;
- 基础 OCR 训练(2T token):全参数训练,以 OCR 重数据为主(文档 OCR45%+ 场景 OCR25%+ 专用 OCR15%);
- 领域增强(800B token):针对企业核心场景优化(复杂表格 / 图表理解 / 多语言等),70% 领域数据 + 30% 通用数据;
- 指令调优与推理增强:基于数百万指令样本,覆盖全链路文档智能任务,提升提示词鲁棒性。
消融实验结论:大尺度通用预训练(阶段 2)是基础,领域增强中混合通用数据可防止过拟合,完整四阶段训练可实现 13.02% 的精度提升。
四、实验结果:全基准领先,端到端模型最优
论文在专用 OCR、通用 OCR、文档理解、KIE四大类基准测试中开展全面评估,对比流水线 OCR、端到端 OCR、通用 VLM、商业大模型,核心结论如下:
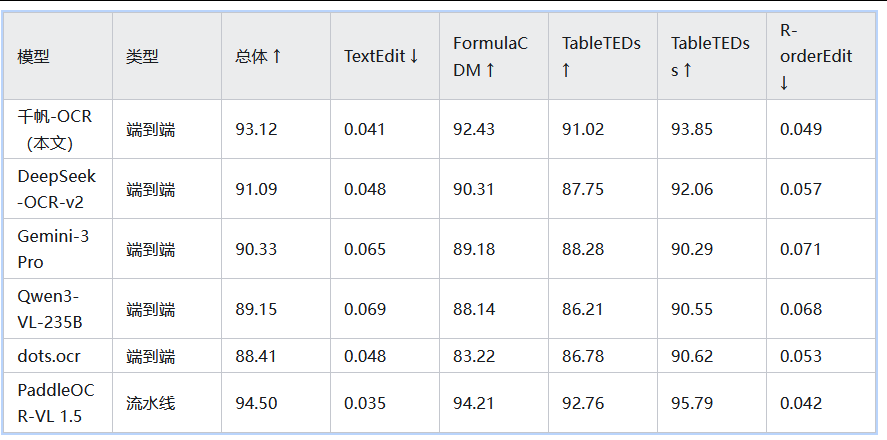
4.1. OmniDocBench v1.5(文档解析)
- OmniDocBench v1.5:总分 93.12,所有端到端模型中最高,超越
DeepSeek-OCR-v2(91.09)、Gemini-3 Pro(90.33),逼近顶级流水线模型 PaddleOCR-VL1.5(94.50); - OlmOCR Bench:总分 79.8,端到端模型第一,与顶级流水线模型PaddleOCR-VL(80.0)持平,在老旧扫描件识别中表现最优(42.0)。
4.2. 通用 OCR 基准测试
- OCRBench 总分 880,所有模型中最高;
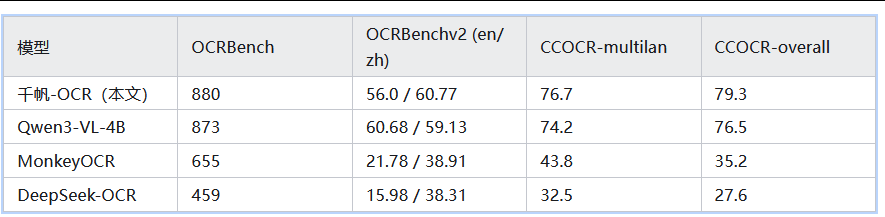
- 中文 OCRBenchv2 得分 60.77,显著领先所有专用 OCR;
- 多语言 CCOCR-multilan 得分 76.7,超越同尺寸通用 VLM Qwen3-VL-4B(74.2),支持 192 种语言的鲁棒识别。
4.3. 文档理解基准测试
两阶段 OCR+LLM 流水线因丢失视觉上下文,在图表理解、学术文档推理中性能暴跌(如 CharXiv 任务得 0 分),而 Qianfan-OCR 在 6/8 个基准中取得端到端模型最优:
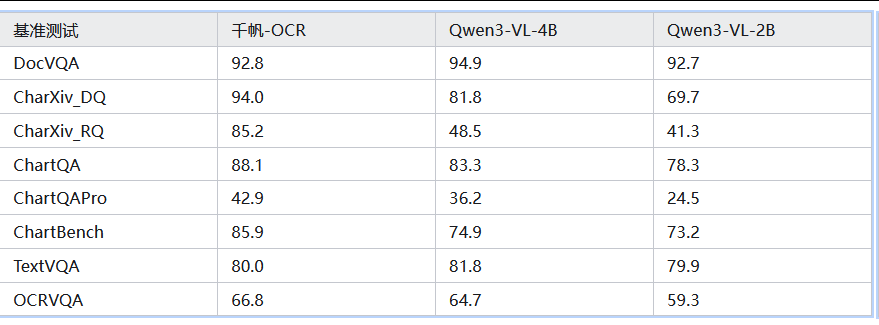
💡 两阶段 OCR+LLM 系统在 CharXiv(包括 DQ 和 RQ)上的得分为 0.0,表明在文本提取过程中被丢弃的图表结构对推理至关重要。
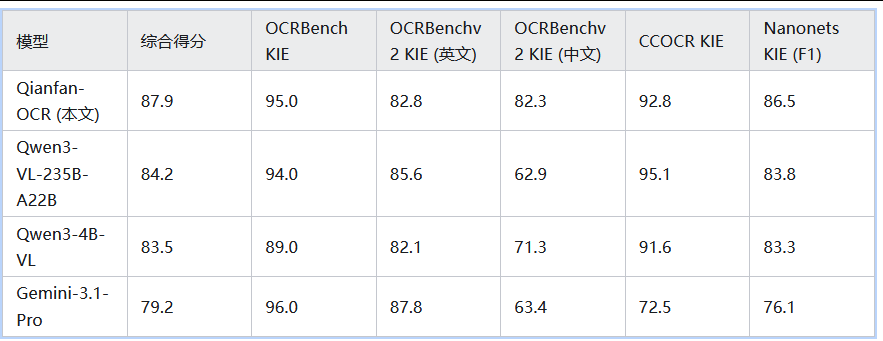
4.4. 关键信息抽取(KIE):全模型第一,多语言优势显著
在 5 个公共 KIE 基准中综合得分 87.9,超越所有对比模型(包括商业大模型 Gemini-3 系列、大尺寸开源 VLM Qwen3-VL-235B)
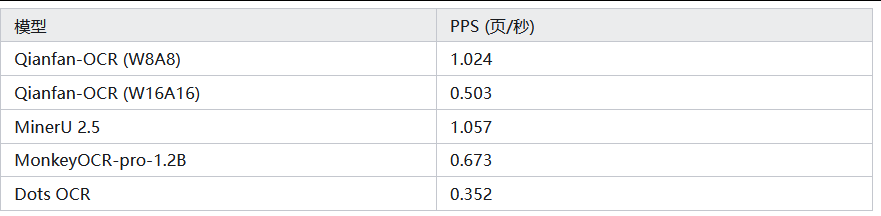
4.5. 推理吞吐量:部署效率比肩流水线 OCR
以每页 / 秒(PPS) 为核心指标(单 A100 GPU,OmniDocBench v1.5 数据集),W8A8 量化后 Qianfan-OCR 达1.024 PPS,与顶级流水线模型 PaddleOCR-VL(1.224 PPS)持平,远超其他端到端模型;
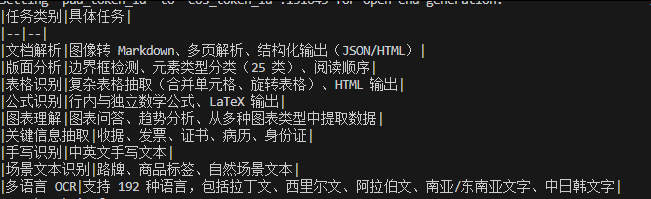
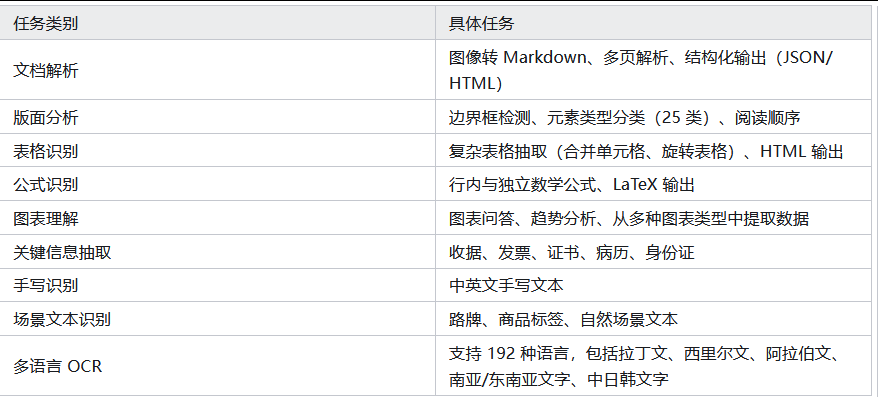
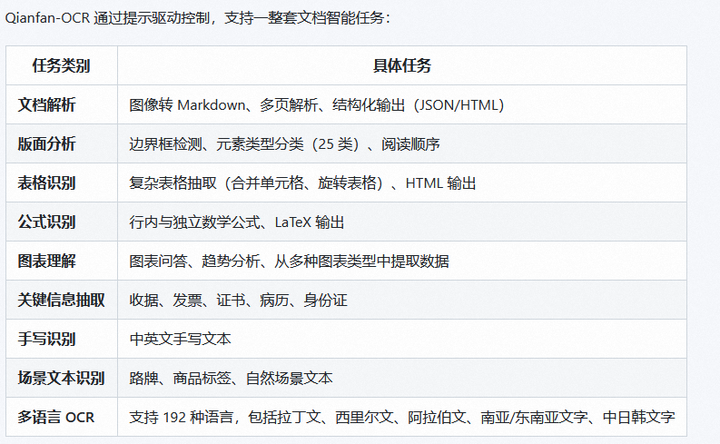
4.6.支持的任务
Qianfan-OCR 通过提示驱动控制,支持一整套文档智能任务:
五、本地部署测试
5.1.测试代码
python
import torch
import torchvision.transforms as T
from torchvision.transforms.functional import InterpolationMode
from modelscope import AutoModel, AutoTokenizer
from PIL import Image
IMAGENET_MEAN = (0.485, 0.456, 0.406)
IMAGENET_STD = (0.229, 0.224, 0.225)
def build_transform(input_size):
MEAN, STD = IMAGENET_MEAN, IMAGENET_STD
transform = T.Compose([
T.Lambda(lambda img: img.convert('RGB') if img.mode != 'RGB' else img),
T.Resize((input_size, input_size), interpolation=InterpolationMode.BICUBIC),
T.ToTensor(),
T.Normalize(mean=MEAN, std=STD)
])
return transform
def find_closest_aspect_ratio(aspect_ratio, target_ratios, width, height, image_size):
best_ratio_diff = float('inf')
best_ratio = (1, 1)
area = width * height
for ratio in target_ratios:
target_aspect_ratio = ratio[0] / ratio[1]
ratio_diff = abs(aspect_ratio - target_aspect_ratio)
if ratio_diff < best_ratio_diff:
best_ratio_diff = ratio_diff
best_ratio = ratio
elif ratio_diff == best_ratio_diff:
if area > 0.5 * image_size * image_size * ratio[0] * ratio[1]:
best_ratio = ratio
return best_ratio
def dynamic_preprocess(image, min_num=1, max_num=12, image_size=448, use_thumbnail=False):
orig_width, orig_height = image.size
aspect_ratio = orig_width / orig_height
# calculate the existing image aspect ratio
target_ratios = set(
(i, j) for n in range(min_num, max_num + 1) for i in range(1, n + 1) for j in range(1, n + 1) if
i * j <= max_num and i * j >= min_num)
target_ratios = sorted(target_ratios, key=lambda x: x[0] * x[1])
# find the closest aspect ratio to the target
target_aspect_ratio = find_closest_aspect_ratio(
aspect_ratio, target_ratios, orig_width, orig_height, image_size)
# calculate the target width and height
target_width = image_size * target_aspect_ratio[0]
target_height = image_size * target_aspect_ratio[1]
blocks = target_aspect_ratio[0] * target_aspect_ratio[1]
# resize the image
resized_img = image.resize((target_width, target_height))
processed_images = []
for i in range(blocks):
box = (
(i % (target_width // image_size)) * image_size,
(i // (target_width // image_size)) * image_size,
((i % (target_width // image_size)) + 1) * image_size,
((i // (target_width // image_size)) + 1) * image_size
)
# split the image
split_img = resized_img.crop(box)
processed_images.append(split_img)
assert len(processed_images) == blocks
if use_thumbnail and len(processed_images) != 1:
thumbnail_img = image.resize((image_size, image_size))
processed_images.append(thumbnail_img)
return processed_images
def load_image(image_file, input_size=448, max_num=12):
image = Image.open(image_file).convert('RGB')
transform = build_transform(input_size=input_size)
images = dynamic_preprocess(image, image_size=input_size, use_thumbnail=True, max_num=max_num)
pixel_values = [transform(image) for image in images]
pixel_values = torch.stack(pixel_values)
return pixel_values
# Load model
MODEL_PATH = "baidu-qianfan/Qianfan-OCR"
model = AutoModel.from_pretrained(
MODEL_PATH,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
device_map="auto"
).eval()
tokenizer = AutoTokenizer.from_pretrained(MODEL_PATH, trust_remote_code=True)
# Load and process image
pixel_values = load_image("./Qianfan-OCR/examples/document.png").to(torch.bfloat16)
# Inference
prompt = "Parse this document to Markdown."
with torch.no_grad():
response = model.chat(
tokenizer,
pixel_values=pixel_values,
question=prompt,
generation_config={"max_new_tokens": 16384}
)
print(response)如果需要使用 Layout-as-Thought(思考模式),修改代码如下:
python
# Enable Layout-as-Thought by appending <think> token to query
pixel_values = load_image("./Qianfan-OCR/examples/complex_document.jpg").to(torch.bfloat16)
prompt = "Parse this document to Markdown.<think>"
with torch.no_grad():
response = model.chat(
tokenizer,
pixel_values=pixel_values,
question=prompt,
generation_config={"max_new_tokens": 16384}
)
print(response)
# The model will first generate structured layout analysis, then produce the final output关键信息抽取代码如下:
python
pixel_values = load_image("./Qianfan-OCR/examples/invoice.jpg").to(torch.bfloat16)
prompt = "请从图片中提取以下字段信息:姓名、日期、总金额。使用标准JSON格式输出。"
with torch.no_grad():
response = model.chat(
tokenizer,
pixel_values=pixel_values,
question=prompt,
generation_config={"max_new_tokens": 16384}
)
print(response)5.2.测试结果
测试图像:

测试结果截图:
测试图像:
测试结果截图: