论文信息
- 标题:Accelerating DETR Convergence via Semantic-Aligned Matching
- 会议:CVPR 2022
- 单位:Nanyang Technological University, Singapore;SenseTime Research
- 代码:github.com/ZhangGongjie/SAM-DETR
- 论文:https://arxiv.org/pdf/2203.06883.pdf
一、前言:DETR 到底为什么训练得这么慢?
DETR 凭借端到端、无Anchor、无NMS 封神检测领域,但有个致命痛点:
收敛速度极慢,需要 500 epoch 才能训练好 ,是 Faster R-CNN 的 10 倍以上。
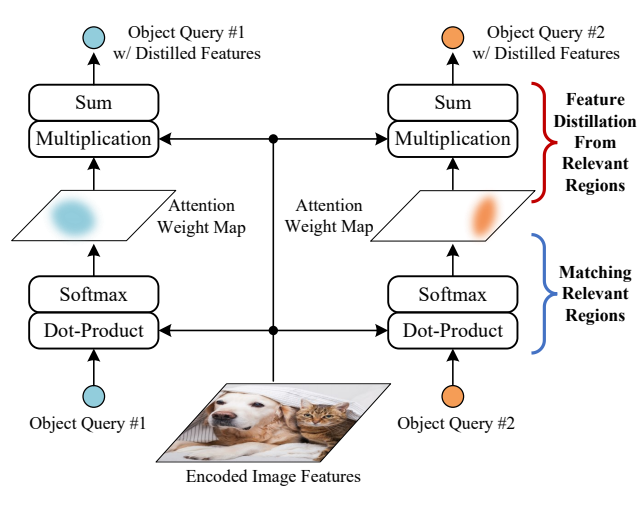
图1:在 DETR 的解码器中,交叉注意力模块可以被理解为一种"匹配与特征提炼"的过程。每个对象查询首先会匹配其在编码后的图像特征中的相关区域,然后从匹配的区域中提炼出特征,从而生成后续预测所需的输出。
过往工作都认为是:
- 注意力太全局
- 空间先验太弱
- 多尺度特征缺失
但本文直接戳穿真相:
慢的根源不是注意力,而是「匹配不对齐」!
物体查询与图像特征不在同一个语义空间,相似度计算毫无意义,模型根本不知道该"看哪里"。
于是 SAM-DETR 横空出世:
让查询与图像特征先做语义对齐,再做匹配!
再配合显式显著点搜索,进一步锁定关键特征。
最终效果:
✅ 12 epoch 逼近 Faster R-CNN 108 epoch 精度
✅ 收敛速度远超 DETR / Conditional DETR / Deformable DETR
✅ 即插即用,不改动原有注意力结构
✅ 可与 SMCA、Conditional 等方法叠加涨点
二、核心动机:语义不对齐 → 匹配全靠猜
DETR 的交叉注意力本质是:
先匹配 → 再提取特征
公式如下:
Q′=Softmax((QWQ)(FWK)Td)(FWV)Q' = \text{Softmax}\left(\frac{(QW_Q)(FW_K)^T}{\sqrt{d}}\right)(FW_V)Q′=Softmax(d (QWQ)(FWK)T)(FWV)
- QQQ:物体查询
- FFF:图像特征
- WQ,WK,WVW_Q,W_K,W_VWQ,WK,WV:线性映射矩阵
- ddd:特征维度
致命问题:
QQQ 和 FFF 被随机映射到不同空间,余弦相似度毫无意义 。
初期注意力完全散乱,模型要花几百轮慢慢"猜"该看哪里。
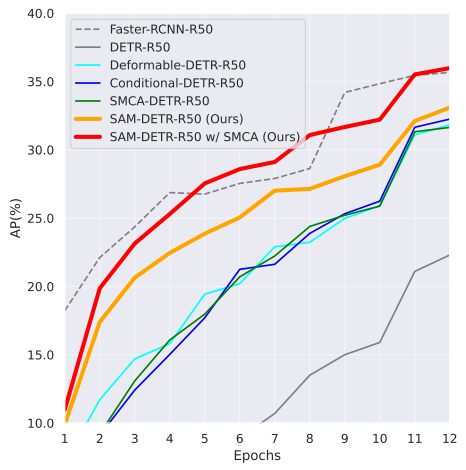
图2:在 12 个训练周期的方案下,我们提出的 SAM-DETR 与其它检测器在 COCO val 2017 数据集上的收敛曲线。所有竞争方法均为单尺度方法。SAM-DETR 的收敛速度比原始的 DETR 快得多,并且能够与现有的提升收敛速度的解决方案相辅相成,其收敛速度与 Faster R-CNN 相当。
横轴 Epoch,纵轴 AP。
可以看到:
- SAM-DETR 上升斜率远高于其他 DETR 变体
- 12 epoch 几乎追上 Faster R-CNN
- 完美验证:语义对齐 = 极速收敛
三、SAM-DETR 整体架构
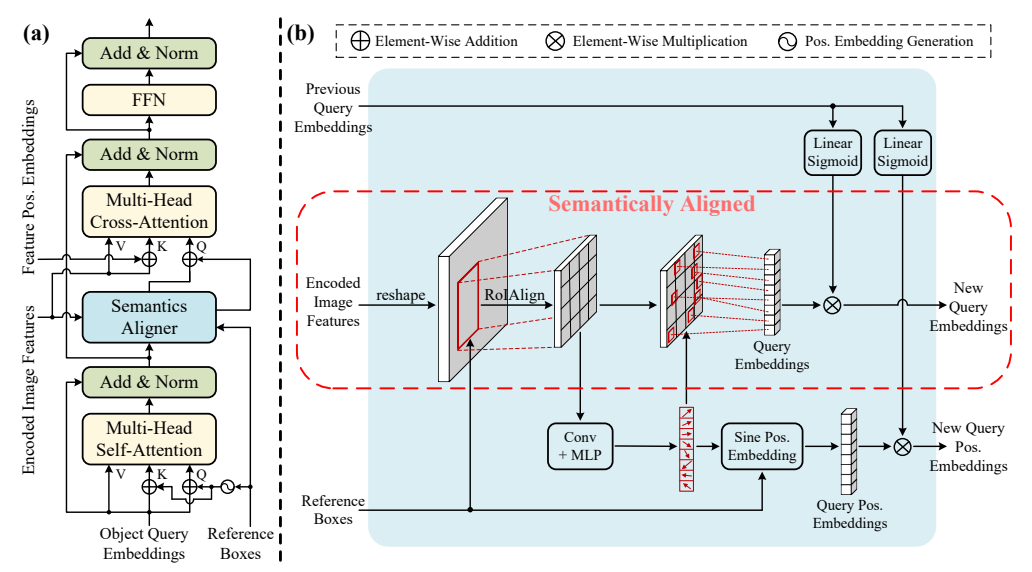
图3:所提出的语义对齐匹配 DETR(SAM-DETR)在 Transformer 解码器层中添加了一个语义对齐器。(a)SAM-DETR 中一个解码器层的架构。它为每个对象查询建模了一个可学习的参考框,其中心位置用于生成相应的位置嵌入。在参考框的引导下,语义对齐器生成与编码的图像特征在语义上对齐的新对象查询,从而便于其后续匹配。(b)所提出的语义对齐器的流程。为了简单起见,仅展示了一个对象查询。它首先利用参考框通过 RolAlign 从相应区域提取特征。然后,这些区域特征用于预测具有最具区分性特征的显著点的坐标。随后,提取这些显著点的特征作为具有对齐语义的新查询嵌入,这些嵌入还会通过之前的查询嵌入进行重新加权,以整合来自它们的有用信息。
结构非常干净:
在交叉注意力前插入一个 Semantics Aligner 模块,不改动任何注意力结构。
流程:
- 给每个查询生成参考框(Reference Box)
- 用参考框做 RoIAlign,在图像特征上裁剪对应区域
- 在区域内搜索显著点
- 用显著点特征生成语义对齐查询
- 送入原有交叉注意力
一句话:
先把查询"锚定"在图像区域,再做注意力匹配。
四、核心创新 1:语义对齐匹配(SAM)
4.1 原理
让查询不再是随机向量,而是直接从图像特征里采样出来 。
这样一来:
查询与特征天生在同一个空间!
4.2 实现步骤
- 参考框提取区域特征
FR=RoIAlign(F,Rbox)F_R = \text{RoIAlign}(F, R_{box})FR=RoIAlign(F,Rbox)
- FFF:编码器输出的图像特征
- RboxR_{box}Rbox:查询对应的参考框
- FRF_RFR:区域特征
- 显著点预测
RSP=MLP(ConvNet(FR))R_{SP} = \text{MLP}(\text{ConvNet}(F_R))RSP=MLP(ConvNet(FR))
- RSPR_{SP}RSP:每个查询的 M 个显著点坐标(M=头数)
- 约束:显著点必须在参考框内部
- 采样生成新查询
Qnew=Concat({FRx,y∣(x,y)∈RSP})Q^{new} = \text{Concat}(\{ F_Rx,y \mid (x,y) \in R_{SP} \})Qnew=Concat({FRx,y∣(x,y)∈RSP})
每个注意力头对应一个显著点,天然适配多头注意力。
4.3 通俗解释
相当于:
不给模型瞎猜的机会,直接告诉它"看这里、这里、这里"。
匹配难度直接降到 0。
五、核心创新 2:显著点匹配 + 重加权
5.1 显著点(Salient Points)
每个头关注一个关键点:中心点、顶角、边缘、局部纹理等。
让注意力更聚焦、更具判别性。
5.2 重加权模块
用旧查询信息做门控,增强有用特征:
Qnew=Qnew′⊗σ(QWRW1)Q^{new} = Q^{new\prime} \otimes \sigma(QW_{RW1})Qnew=Qnew′⊗σ(QWRW1)
Qposnew=Qposnew′⊗σ(QWRW2)Q_{pos}^{new} = Q_{pos}^{new\prime} \otimes \sigma(QW_{RW2})Qposnew=Qposnew′⊗σ(QWRW2)
- ⊗\otimes⊗:逐元素相乘
- σ\sigmaσ:Sigmoid 生成 0~1 权重
- WRW1,WRW2W_{RW1}, W_{RW2}WRW1,WRW2:线性层
作用:保留历史查询语义,让对齐更稳定。
六、核心创新 3:与现有方法完美兼容
SAM-DETR 是即插即用模块,不修改注意力,因此可以和:
- Conditional DETR
- SMCA DETR
- Deformable DETR
- DAB DETR
- Group DETR
直接叠加,获得双倍增益!
原文中 SAM+SMCA 组合实现了:
12 epoch 超越绝大部分 50 epoch 模型
七、核心代码(PyTorch 风格)
python
# ==============================
# SAM-DETR 核心:语义对齐器
# ==============================
class SemanticsAligner(nn.Module):
def __init__(self, hidden_dim, num_heads=8):
super().__init__()
self.num_heads = num_heads
self.conv = nn.Conv2d(hidden_dim, hidden_dim, 3, 1, 1)
self.mlp = nn.Linear(hidden_dim, num_heads * 2) # 预测(x,y)*num_heads
self.rw1 = nn.Linear(hidden_dim, hidden_dim)
self.rw2 = nn.Linear(hidden_dim, hidden_dim)
def forward(self, feat_map, ref_boxes, old_queries):
# feat_map: [B, C, H, W]
# ref_boxes: [B, N, 4]
B, N, _ = ref_boxes.shape
# 1. RoIAlign 提取区域特征
rois = _box2roi(ref_boxes)
feat_roi = roi_align(feat_map, rois, output_size=7)
feat_roi = feat_roi.view(B, N, -1, self.num_heads) # [B,N,7*7,C] -> head split
# 2. 预测显著点坐标
feat_pool = feat_roi.flatten(2).mean(-1)
delta = self.mlp(feat_pool).view(B, N, self.num_heads, 2)
delta = delta.tanh() # 范围 [-1,1],限制在参考框内
# 3. 双线性采样显著点特征
aligned_queries = self.sample_feat(feat_roi, delta)
# 4. 重加权
weight_q = self.rw1(old_queries).sigmoid()
aligned_queries = aligned_queries * weight_q
return aligned_queries八、实验结果与全表格解析
表格1:COCO 主实验(全文最重要)
表格1(来自原文 Table 1)
| 方法 | Epoch | AP | AP50 | APS | APM | APL |
|---|---|---|---|---|---|---|
| Faster-RCNN | 12 | 35.7 | 56.1 | 19.2 | 40.9 | 48.7 |
| DETR | 12 | 22.3 | 39.5 | 6.6 | 22.8 | 36.6 |
| Deformable DETR | 12 | 31.8 | 51.4 | 15.0 | 35.7 | 44.7 |
| Conditional DETR | 12 | 32.2 | 52.1 | 13.9 | 34.5 | 48.7 |
| SMCA DETR | 12 | 31.6 | 51.7 | 14.1 | 34.4 | 46.5 |
| SAM-DETR | 12 | 33.1 | 54.2 | 13.9 | 36.5 | 51.7 |
| SAM-DETR+SMCA | 12 | 36.0 | 56.8 | 15.8 | 39.4 | 55.3 |
分析:
- SAM-DETR 12epoch 超越所有单模型 DETR
- SAM+SMCA 组合 逼近 Faster R-CNN
- 大目标 APL 暴涨:从 48.7 → 55.3
- 完美验证语义对齐+显著点的巨大收益
表格2:消融实验(核心设计验证)
表格2(来自原文 Table 2)
| SAM | Avg | Max | SP×1 | SP×8 | RW | AP | AP50 |
|---|---|---|---|---|---|---|---|
| 22.3 | 39.5 | ||||||
| ✓ | ✓ | 28.6 | 50.3 | ||||
| ✓ | ✓ | 32.0 | 53.4 | ||||
| ✓ | ✓ | 30.3 | 52.0 | ||||
| ✓ | ✓ | 33.1 | 54.2 |
分析:
- SAM 本身带来巨幅提升:+6.3 AP
- 最大池化 > 平均池化(关键特征更重要)
- 8个显著点 > 1个显著点(多头匹配更强)
- 全套组合达到 33.1 AP,登顶消融
表格3:显著点范围约束
表格3(来自原文 Table 3)
| 范围 | AP | AP50 |
|---|---|---|
| 图像全局 | 30.0 | 52.3 |
| 参考框内 | 33.1 | 54.2 |
分析:
约束在参考框内,搜索范围更小、匹配更准,涨点 3+ AP。
九、可视化:注意力精准聚焦

图4:展示了 SAM-DETR 所搜索的显著点及其注意力权重图。所搜索的显著点大多位于目标物体内部,并准确地指出了对于物体识别和定位具有最具区分性特征的位置。与原始的 DETR 相比,SAM-DETR 的注意力权重图更加精确,这表明我们的方法有效地缩小了匹配的搜索空间,并促进了收敛。相比之下,原始的 DETR 的注意力权重图更加分散,这表明其在匹配相关区域和提取独特特征方面效率低下。
- 上:SAM-DETR
- 下:原生 DETR
对比清晰:
- SAM-DETR:显著点落在物体上,注意力紧凑、精准、对齐边缘
- DETR:注意力散乱、弥散、无聚焦
直观说明:
语义对齐 + 显著点 = 收敛加速的终极密码
十、全文总结(最精炼)
- 痛点 :DETR 查询与特征语义空间不对齐,导致匹配极难、收敛极慢
- 解法 :SAM-DETR 通过 RoI 采样 + 显著点搜索 ,实现查询-特征语义同源
- 结构 :即插即用,不改动注意力,兼容所有 DETR 变体
- 效果 :12 epoch 极速收敛,超越 Conditional/Deformable/SMCA
- 组合 :SAM+SMCA 可达到 12 epoch 接近 Faster R-CNN
- 定位 :DETR 收敛加速领域轻量、高效、通用的里程碑插件