目录
[😺Java 集合概览](#😺Java 集合概览)
[说说 List, Set, Queue, Map 四者的区别?](#说说 List, Set, Queue, Map 四者的区别?)
[Array(数组)vs ArrayList(动态数组)](#Array(数组)vs ArrayList(动态数组))
[ArrayList vs LinkedList](#ArrayList vs LinkedList)
[ArrayList 的扩容机制](#ArrayList 的扩容机制)
[集合中的 fail-fast 和 fail-safe 是什么?](#集合中的 fail-fast 和 fail-safe 是什么?)
[Comparable 和 Comparator 的区别](#Comparable 和 Comparator 的区别)
[HashSet、LinkedHashSet、TreeSet 有什么区别?](#HashSet、LinkedHashSet、TreeSet 有什么区别?)
[Queue(单端队列)和 Deque(双端队列)有什么区别?](#Queue(单端队列)和 Deque(双端队列)有什么区别?)
[ArrayBlockingQueue vs LinkedBlockingQueue](#ArrayBlockingQueue vs LinkedBlockingQueue)
[HashMap vs Hashtable](#HashMap vs Hashtable)
[HashMap vs TreeMap](#HashMap vs TreeMap)
[HashMap 的底层实现](#HashMap 的底层实现)
[HashMap 的长度为什么是 2 的幂次方](#HashMap 的长度为什么是 2 的幂次方)
[HashMap 多线程操作为什么会导致死循环](#HashMap 多线程操作为什么会导致死循环)
[HashMap 为什么线程不安全](#HashMap 为什么线程不安全)
[ConcurrentHashMap 和 Hashtable 的区别](#ConcurrentHashMap 和 Hashtable 的区别)
[JDK 1.7 和 JDK 1.8 的 ConcurrentHashMap 实现有什么不同?](#JDK 1.7 和 JDK 1.8 的 ConcurrentHashMap 实现有什么不同?)
[ConcurrentHashMap 能保证复合操作的原子性吗?](#ConcurrentHashMap 能保证复合操作的原子性吗?)
😺Java 集合概览
Java 集合,也叫作容器,主要是由两大接口派生而来:一个是 Collection接口,主要用于存放单一元素;另一个是 Map 接口,主要用于存放键值对。对于Collection 接口,下面又有三个主要的子接口:List、Set 、Queue。
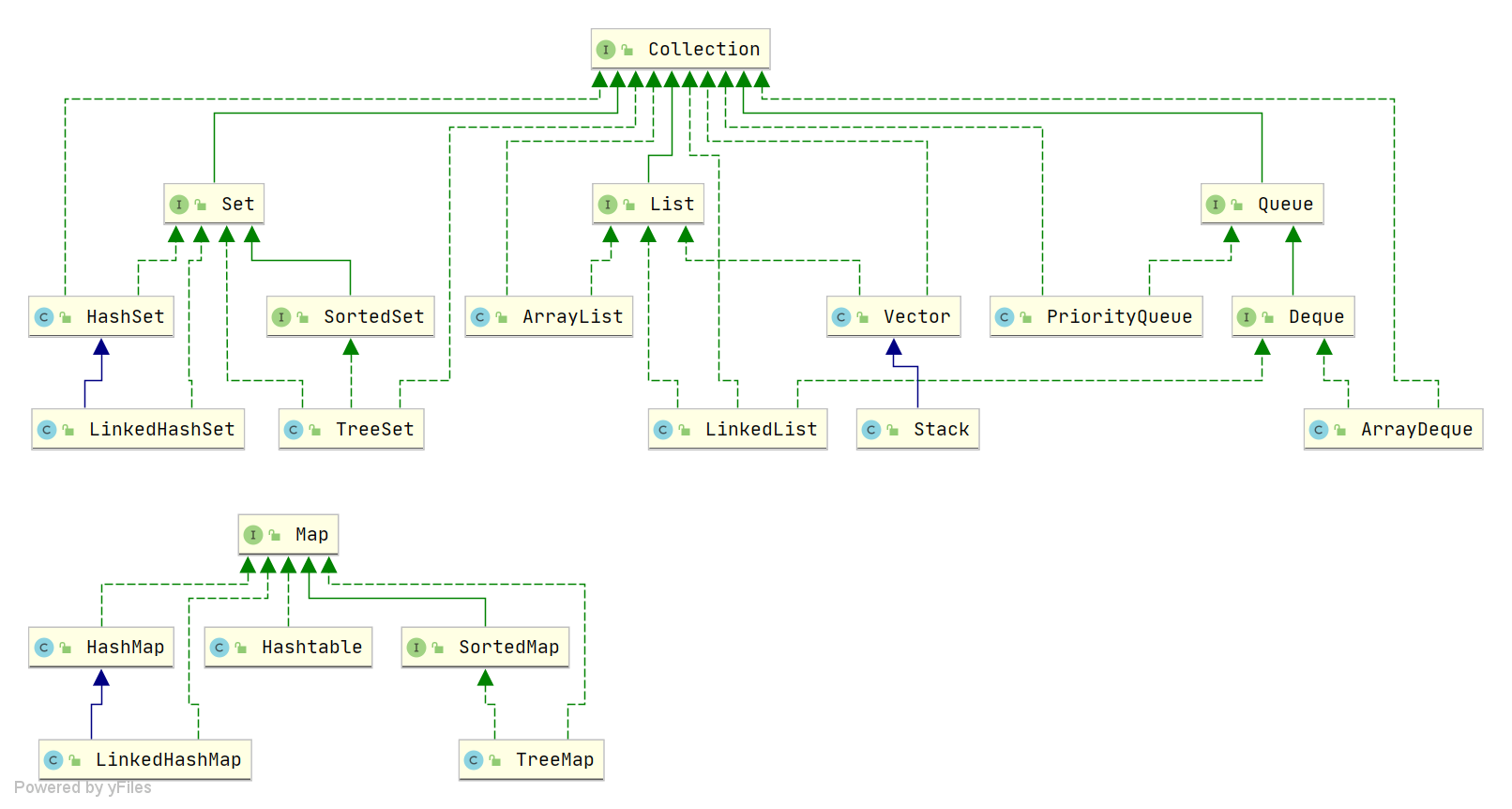
说说 List, Set, Queue, Map 四者的区别?
集合(Collection)是 Java 中专门用来存储多个数据的容器,一个"高级数组",比数组强很多,是**用来批量管理对象的数据结构。**相比数组,集合具有以下优势:
- 长度可动态扩容
- 提供丰富的增删改查操作
- 支持排序、去重
- 部分集合支持键值对存储
Java 集合你可以先分成两大体系:
1. Collection(单列集合)
-
List(有序、可重复、支持下标访问): ArrayList 动态数组 、LinkedList 双向链表 、Vector。
List<Integer> list = new ArrayList<>():底层Object\[\],查询快、尾部插入快、中间插入慢。
List<Integer> list = new LinkedList<>():底层双向链表,插入删除快、随机查询慢。
Vector:现在基本不用,大量使用synchronized,所以线程安全,但性能较低。 -
Set(无序、不可重复): HashSet 、LinkedHashSet、TreeSet。
HashSet:底层HashMap,所以去重本质依赖hashCode()、equals()。
LinkedHashSet:底层HashSet + 双向链表,保持插入顺序。
TreeSet:底层红黑树(自平衡二叉搜索树),自动排序、去重。 -
Queue(有序、可重复、先进先出): PriorityQueue、ArrayDeque。
PriorityQueue:底层Object\[\],默认小顶堆,即最小值优先出队。
ArrayDeque:底层动态循环数组,可以两头操作。
2. Map(双列集合 key-value)
-
Map(键值对,key唯一): HashMap 、LinkedHashMap、Hashtable、TreeMap 。
HashMap:底层数组 + 链表 + 红黑树,拉链法解决哈希冲突,链表转红黑树,目的提高查询效率。
LinkedHashMap:底层HashMap + 双向链表,保证插入顺序。
Hashtable:现在基本不用,大量使用synchronized,所以线程安全,但性能较低,底层数组 + 链表,保证插入顺序。
TreeMap:底层红黑树,key 自动排序。Collection
├── List
├── Set
└── QueueMap
├── HashMap
├── LinkedHashMap
└── TreeMap
Map<Integer,Integer>为什么是包装类?
Java 的泛型是通过类型擦除实现的 。编译后,泛型信息会被擦除,类型参数 Integer 会被替换为它的上界(如果没有显式指定,就是 Object)。因此 Map<Integer, Integer> 在运行时实际变成了 Map,其中存储的键和值都是 Object 类型。
基本数据类型(如 int、double)不是 Object 的子类,无法被当作对象处理,所以不能放在泛型里。必须使用对应的包装类(如 Integer、Double),因为它们继承自 Object。
虽然声明时必须写 Integer,但使用时可以直接放 int 值,编译器会自动装箱(int → Integer)和拆箱(Integer → int),这让我们写代码时几乎感觉不到差异。
- 语法限制:泛型参数必须是 Object 的子类,基本类型不是。
- 实现机制:类型擦除后泛型被替换为 Object,基本类型无法匹配。
- 使用便利:自动装箱/拆箱弥补了写法上的不便。
为什么要使用集合?
为什么不用数组?
- 数组优点:查询快、结构简单、内存连续。
- 数组缺点:长度固定、功能太少(存、取、遍历)
先看业务需求,再选数据结构。
是否需要 key-value?需要Map,不需要Collection。
Map→是否需要排序?不需要HashMap,需要按 key 排序 TreeMap(红黑树)。
Collection→是否需要去重?需要唯一Set,不需要唯一List。
Set→不需要排序 HashSet,需要排序 TreeSet。
List→默认首选 ArrayList,频繁头部 / 中间插入删除 LinkedList。
😺List
Array(数组)vs ArrayList(动态数组)
| 特性 | Array(数组) | ArrayList |
|---|---|---|
| 长度 | 固定,创建时确定 | 动态,可扩容和缩容 |
| 类型 | 可以存基本类型或对象 | 只能存对象,基本类型需用包装类 |
| 泛型支持 | 不支持 | 支持泛型,类型安全 |
| 操作方式 | 只能按下标访问 | 提供丰富方法,如 add(), remove(), set() |
| 灵活性 | 较低,需要手动处理插入/删除 | 高,自动处理元素移动、扩容等 |
| 创建时大小 | 必须指定大小 | 可指定初始容量,也可默认 |
- ArrayList 使用灵活,适合绝大多数开发场景
- Array 使用简单,性能略高,适合固定长度和存储基本类型场景
ArrayList vs LinkedList
ArrayList 尾增尾删 O(1)、头增头删 O(n)、中间增删 O(n)
LinkedList 头尾插删 O(1)、中间插删 O(n)、随机访问 O(n)
| 对比项 | ArrayList | LinkedList |
|---|---|---|
| 底层结构 | 动态数组 | 双向链表 |
| 元素特点 | 有序、可重复、允许 null | 有序、可重复、允许 null |
| 查询访问 | 快(随机访问)O(1) | 慢(需遍历查找)O(n) |
| 增删效率 | 尾部快O(1) 头部和中间增删慢O(n),需移动元素 | 头尾增删快O(1),改指针即可 中间需要寻找O(n) |
| 内存占用 | 较小 | 较大(每个节点存前后引用) |
| 内存浪费 | 预留容量 | 单个元素更占内存 |
| 特有功能 | 普通列表操作 | 可做队列、双端队列、栈 |
| 常用方法 | add/get/remove/set | 与 ArrayList 一致 + offer/poll/peek/push/pop |
| 适用场景 | 查询多、增删少 | 增删多、需队列 / 栈功能 |
| 开发首选 | 日常开发默认优先使用 | 特定队列 / 栈场景使用 |
**LinkedList 为什么不能实现 RandomAccess?**因为 LinkedList 底层是链表,内存地址不连续,只能通过指针逐个遍历访问元素,不支持像数组那样通过索引快速随机访问,因此不能实现 RandomAccess 接口。
public interface RandomAccess {
}看源码发现 RandomAccess 里面什么都没有,所以属于标记接口(不提供功能,只提供身份标识),用于标识实现类支持快速随机访问。
因为实现了 RandomAccess,所以变快了 ,ArrayList 并不是因为实现了它才变快,而是因为底层数组本身就支持快速随机访问,所以才实现该接口作为标识。先天就快,所以实现这个接口做标记,能力来自底层数据结构,不是来自接口。
在 binarySearch() 方法中,它要判断传入的 list 是否 RandomAccess 的实例,通过标记接口实现策略选择:
- 如果是,调用基于索引的二分查找 indexedBinarySearch() 方法。
- 如果不是,那么调用迭代器方式遍历 iteratorBinarySearch() 方法。
ArrayList 的扩容机制
ArrayList 底层是动态数组,刚创建时容量 = 0,首次添加元素时扩容到 10,之后每次容量不足时按原容量的 1.5 倍扩容。
-- 什么时候第一次变成 10?为什么?
第一次执行 list.add 时。
calculateCapacity() 会 return Math.max(DEFAULT_CAPACITY, minCapacity);
DEFAULT_CAPACITY = 10,所以第一次扩成10。
-- 后续怎么扩容?
int newCapacity = oldCapacity + (oldCapacity >> 1); // 右移一位等价于除以 2
也就是 1.5 倍扩容。
-- 为什么不用其他扩容数量?空间和性能平衡。
扩太小,比如每次 +1:扩容次数太多,频繁复制数组,性能差,扩容是昂贵操作。
扩太大,比如每次 2 倍:浪费内存严重。
-- 扩容本质做了什么?
创建新数组 + 复制旧数组,时间复杂度O(n),所以扩容是昂贵操作。
-- ensureCapacity 的作用?
比如你明确知道要存 100 万条数据,就要一次性分配空间。list.ensureCapacity(1000000);
这样一次性分配空间,避免多次扩容、多次数组复制,性能更好。
这在批量导入、缓存预热里很常见。
ArrayList 默认不会自动缩容。如果每次删除都自动缩容,那就会频繁发生缩容、扩容,数组会不断复制,性能极差,所以 Java 设计上选择,宁可浪费一点空间,也不频繁复制数组。
不过可以采用手动缩容:java.util.ArrayList 的 trimToSize(),很少主动使用。
集合中的 fail-fast 和 fail-safe 是什么?
fail-fast:发现问题立刻报错 。
在遍历集合时,如果检测到集合被并发修改,立即抛出异常并终止运行。
典型代表:ArrayList、HashMap。
核心原理:modCount、expectedModCount。
集合每次结构修改时:modCount++。
迭代器在创建时记录:expectedModCount。
每次调用 next() 时都会校验:if (modCount != expectedModCount)。
若不一致,抛出:ConcurrentModificationException。
fail-safe:允许继续运行,安全失败 。
即使集合被修改,遍历过程仍可继续执行,不会抛异常。
典型代表:CopyOnWriteArrayList。
其底层采用:Copy-On-Write 写时复制。
即修改时复制出一个新数组,在新数组上完成修改,再替换原引用。
遍历时读取旧数组快照,因此不会受到并发修改影响。
核心区别:fail-fast 检查修改次数,fail-safe 使用快照副本。
实际开发怎么选:
普通单线程集合,这种场景根本没有线程安全问题,用 ArrayList、HashMap 性能最好。并发不能选,因为并发场景可能出现数据覆盖、数组越界、脏读、并发修改异常。
并发读多写少,用CopyOnWriteArrayList,它写操作时复制一份新数组,在新数组上修改,再替换原引用,读操作无锁,性能很高,特别适合高频读取场景。比如项目里店铺类型缓存列表、热门笔记标签 很适合,这些数据查询频率非常高,但更新很少,非常适合使用 CopyOnWriteArrayList。
CopyOnWriteArrayList 为什么线程安全?
CopyOnWriteArrayList 通过"写时复制(Copy-On-Write)"机制实现线程安全:读操作无锁直接访问旧数组,写操作加锁并复制新数组修改,最后替换引用,从而保证读写互不干扰。它的缺点是写操作成本较高,需要复制整个数组,因此适用于读多写少的场景。
😺Set
Comparable 和 Comparator 的区别
Comparable 位于 java.lang 包,核心方法是compareTo(T o) ,特点是由类自身实现排序规则,适用于对象的默认自然排序且一种排序规则。
Comparator 位于 java.util 包,核心方法是compare(T o1, T o2) ,特点是由外部定义排序规则,适用于临时排序或多种排序规则场景,例如同一个 Person 类,今天可以按年龄排序,明天可以按姓名排序。
java
class Person implements Comparable<Person> {
private String name;
private int studentId;
@Override
public int compareTo(Person o) {
// 重写 Comparable 接口中的 compareTo 方法后,
// Person 对象就具备了"默认排序规则"
// 返回负数:当前对象排前面
// 返回 0:认为两个对象相等
// 返回正数:当前对象排后面
return this.studentId - o.studentId;
}
}
// 之后就可以直接使用默认排序规则
List<Person> list = new ArrayList<>();
list.add(new Person("Tom", 1002));
list.add(new Person("Jerry", 1001));
// 1)Collections.sort(list)
Collections.sort(list); // 会自动调用 compareTo,按 studentId 升序排序
// 2)List 自带 sort 方法(Java 8 常用)
list.sort(null); // 传 null 表示使用对象默认排序规则
// 3)stream 排序时也可以直接使用自然排序
list.stream().sorted().forEach(System.out::println);
// 4)Arrays.sort 也可以用于对象数组默认排序
Person[] arr = {
new Person("Tom", 1002),
new Person("Jerry", 1001)
};
Arrays.sort(arr); // 同样调用 compareTo
// 也可以作为 TreeSet / TreeMap 的排序依据
Set<Person> set = new TreeSet<>();
set.add(new Person("Tom", 1002));
set.add(new Person("Jerry", 1001));
java
List<Person> list = new ArrayList<>();
list.sort(new Comparator<Person>() {
@Override
public int compare(Person o1, Person o2) {
return o1.getAge() - o2.getAge();
}
});
// lambda 表达式版本
list.sort((o1, o2) -> o1.getAge() - o2.getAge());Comparable:内部默认排序。Comparator:外部自定义排序。
如果一个类只有一种固定排序方式,通常使用 Comparable。
如果需要多种排序规则,例如按年龄、姓名、成绩排序,通常使用 Comparator。
无序性和不可重复性的含义是什么?
- 无序性
无序性并不等于随机性,它的真正含义是元素在底层存储时,并不是按照插入顺序或数组索引顺序存放,而是由元素的哈希值决定存储位置。
例如 HashSet 底层基于 HashMap 实现,元素的位置由hashCode()计算得到,因此遍历时不保证顺序。
- 不可重复性
不可重复性是指集合中不能存在逻辑相等的元素 。判断是否重复时,通常先比较hashCode(),若哈希值相同,再调用equals(),若返回 true,则认为元素重复,不会再次加入集合。
注意:为了正确保证不可重复性,自定义对象通常需要同时重写equals()、hashCode(),否则可能导致重复元素判断失效。
HashSet、LinkedHashSet、TreeSet 有什么区别?
最大的区别:怎么存储?
| 集合 | 底层 | 顺序 | 时间复杂度 |
|---|---|---|---|
| HashSet | HashMap | 无序 | O(1) |
| LinkedHashSet | LinkedHashMap | 插入顺序 | O(1) |
| TreeSet | 红黑树 | 自动排序 | O(log n) |
😺Queue
Queue(单端队列)和 Deque(双端队列)有什么区别?
Queue 是单端队列,通常一端入队、一端出队,遵循 FIFO,常用方法:offer() poll() peek()。
Deque 是双端队列,头尾两端都可以进行插入和删除操作,同时可以模拟队列和栈,常用方法offerFirst() offerLast() pollFirst() pollLast() peekFirst() peekLast() 。
PriorityQueue
它与普通 Queue 的主要区别在于元素出队顺序与优先级相关,而不是插入顺序,可以理解为Vip队列,优先级最高的元素总是最先出队。
底层实现:二叉堆(Heap),堆的底层是可变长数组,默认实现为小顶堆
为什么底层不用链表?
因为堆适合用数组按下标快速定位父子节点,链表无法高效随机访问。
时间复杂度:插入O(log n)、删除堆顶O(log n) 、获取堆顶元素O(1)
为什么是 O(logn)?因为底层是堆结构,插入时需要上浮,最多移动树高层数,即 logn。
可通过 Comparator 自定义优先级规则,比如怎么改成大顶堆?
PriorityQueue<Integer> pq = new PriorityQueue<>((a,b)->b-a);
典型应用:堆排序、Top K 问题
BlockingQueue(阻塞队列)
其核心特点是支持线程在特定条件下阻塞等待,主要体现在两个方面:
- 队列为空时阻塞
当消费者线程执行取元素操作(如 take())时,如果队列为空,线程会进入阻塞状态,直到队列中有新的元素可取。 - 队列已满时阻塞
当生产者线程执行放元素操作(如 put())时,如果队列已满,线程会进入阻塞状态,直到队列中有空位。
因此,BlockingQueue 非常适合实现生产者-消费者模型。
在该模型中:
- 生产者线程负责向队列中放入数据
- 消费者线程负责从队列中取出数据并处理
常用方法:
放元素:put():满了会阻塞。offer():不阻塞,失败返回 false。
取元素:take():空了会阻塞。poll():不阻塞,空返回 null。
为什么线程池喜欢用 BlockingQueue?
因为任务提交和工作线程消费任务天然符合生产者-消费者模型,可以实现线程间安全通信和任务缓冲。
ArrayBlockingQueue vs LinkedBlockingQueue
ArrayBlockingQueue 和 LinkedBlockingQueue 都是 Java 并发包中常用的阻塞队列实现,并且都是线程安全的。
底层实现不同:ArrayBlockingQueue 基于数组实现,LinkedBlockingQueue 基于链表实现。
是否有界:ArrayBlockingQueue 是有界队列,创建时必须指定容量,new ArrayBlockingQueue<>(10)。LinkedBlockingQueue 默认可以看作无界队列。
锁机制不同:ArrayBlockingQueue 使用的是同一把锁,因此生产和消费不能真正并行执行。LinkedBlockingQueue 使用的是两把锁分离机制,即生产者和消费者可以并发执行,减少锁竞争,提高吞吐量。
Q:为什么 LinkedBlockingQueue 性能通常更好?
A:因为它采用 putLock 和 takeLock 两把锁,生产和消费可以并行执行,减少锁竞争。
Q:为什么线程池常用 LinkedBlockingQueue?
A:因为其支持较高并发吞吐量,且默认容量很大,适合作为任务缓冲队列。
😺Map
HashMap vs Hashtable
HashMap 和 Hashtable 都是用于存储键值对(key-value)的哈希表实现,但它们有以下几个核心区别:
线程安全性不同:HashMap 是 线程不安全, Hashtable 是 **线程安全,**原因是 Hashtable 的大部分方法都使用了 synchronized 修饰。
性能不同:由于 Hashtable 使用了 synchronized 加锁机制,因此性能通常低于 HashMap,所以实际开发中 HashMap 使用远多于 Hashtable。
底层数据结构不同:HashMap 使用数组 + 链表 + 红黑树,当链表长度超过 8 且数组长度大于等于 64 时,会转为红黑树,目的是降低查找时间复杂度,即 O(n) -> O(logn)。Hashtable 没有红黑树优化机制,仍主要使用数组 + 链表。
哈希算法不同:HashMap 会对 hashCode 进行扰动处理,h ^ (h >>> 16),目的是让高位参与运算,减少哈希冲突。Hashtable 基本直接使用 key 的 hashCode。因此 HashMap 哈希分布通常更均匀。
HashMap vs TreeMap
**底层数据结构不同:**HashMap 基于哈希表(数组 + 链表 + 红黑树),TreeMap 基于红黑树。
**是否有序:**HashMap 无序,TreeMap 默认按 key 升序排序,也可以自定义 Comparator。
**时间复杂度:**HashMap 查找、插入平均 O(1),TreeMap 查找、插入 O(log n)。
**功能差异:**TreeMap 支持范围查询(subMap、headMap、tailMap),TreeMap 支持导航操作(ceiling、floor、higher、lower)。
适用场景:HashMap 高效查找,无需排序,TreeMap 需要排序或范围查询。
Q1:TreeMap 为什么是有序的?
A:因为底层使用红黑树结构,每次插入 key 时都会按照比较规则(Comparable 或 Comparator)进行排序维护。
Q2:HashMap 为什么能做到 O(1) 查找?
A:通过 hash 函数计算 key 的位置,直接定位数组索引,减少遍历。
Q3:TreeMap 和 LinkedHashMap 有什么区别?
A:TreeMap 按 key 排序(红黑树),LinkedHashMap 按插入顺序或访问顺序(双向链表 + 哈希表)
HashMap 的底层实现
HashMap 本质是一个数组,每个位置是一个桶(bucket),每个桶中可能存:1个节点、链表、红黑树。
拉链法解决哈希冲突:hash 冲突时,用链表挂在同一个桶下面。
JDK8 关键升级(红黑树):当链表过长时,默认链表长度 > 8 并且数组长度 ≥ 64,链表会转成红黑树,链表查找O(n),红黑树查找O(log n)。
为什么不是直接转红黑树?①先扩容更划算,扩容可以减少 hash 冲突,数据重新分布,比维护红黑树成本低。②红黑树维护成本高,结构复杂,不适合小规模数据。经验阈值(8 + 64)。
HashMap 的长度为什么是 2 的幂次方
第一,提高运算效率。
当数组长度是 2 的幂次方时,就可以把取余运算转化成位运算,位运算效率高于取模运算。
hash % length = hash & (length - 1)第二,保证元素分布均匀。扩容之后,在旧数组元素 hash 值比较均匀的情况下,新数组元素也会被分配的比较均匀,最好的情况是会有一半在新数组的前半部分,一半在新数组后半部分。
第三,提高扩容效率。扩容后只需检查哈希值高位的变化来决定元素的新位置。
Q:HashMap 默认长度是多少?
A:默认长度是 16。
HashMap 多线程操作为什么会导致死循环
根本原因是 HashMap 本身线程不安全,并且在扩容迁移链表节点时采用了头插法。当多个线程同时对同一个桶中的链表进行扩容迁移时,可能同时修改节点的 next 指针,导致链表反转过程中形成环形链表。一旦形成环形链表,后续执行 get() 查询时会沿着 next 指针无限遍历,最终导致程序陷入死循环。
在 JDK1.8 中,HashMap 将扩容迁移方式改为尾插法,避免了链表反转,从而解决了死循环问题。
但需要注意,JDK1.8 的 HashMap 依然不是线程安全的,在并发环境下仍可能出现数据覆盖和数据丢失问题,因此不建议在多线程场景下使用。
并发环境推荐使用:ConcurrentHashMap。
HashMap 为什么线程不安全
HashMap 不是线程安全的,在多线程环境下进行并发 put / remove 操作时,可能导致以下问题:
- 数据丢失:并发 put 操作可能导致一个线程的写入被另一个线程覆盖。
- 数据覆盖(丢失写入):HashMap 发生 hash 冲突时,多个线程可能同时操作同一个桶位置。由于 put 操作不是原子性的(包含:计算 hash、判断桶位置、插入节点等多个步骤),线程切换可能导致后一个线程覆盖前一个线程写入的数据,从而产生数据丢失。
- size 统计不准确:HashMap 的 size++ 操作不是原子操作,在多线程环境下可能发生"丢失更新"。多个线程同时执行 ++size,会导致实际插入多个元素,但 size 增长次数小于实际插入次数。
- 无限循环:在 JDK 7 及以前的版本中,并发扩容时,由于头插法可能导致链表形成环,从而在 get 操作时引发无限循环,CPU 飙升至 100%。
JDK1.8 虽然优化了扩容方式(尾插法),避免了死循环问题,但仍然无法保证线程安全。
Q:HashMap 为什么会发生数据覆盖?
A:因为 put 操作不是原子性的,多线程同时操作同一个桶时可能互相覆盖节点。
Q:size 为什么会不准确?
A:因为 ++size 不是原子操作,多个线程同时执行会发生丢失更新。
Q:JDK1.8 是否解决了所有线程问题?
A:没有,只解决了 JDK1.7 的死循环问题,但仍存在数据竞争问题。
ConcurrentHashMap 和 Hashtable 的区别
ConcurrentHashMap 和 Hashtable 都是线程安全的 Map 实现,但它们在实现方式和性能上有本质区别。
- 底层数据结构不同
Hashtable:数组 + 链表(无红黑树优化)。ConcurrentHashMap:JDK1.7 为 Segment 分段数组 + 链表;JDK1.8 为 Node 数组 + 链表 / 红黑树 - 线程安全实现方式不同(核心重点)
Hashtable:使用一把全局锁(synchronized 修饰方法),所有操作都竞争同一把锁,并发度极低
ConcurrentHashMap:JDK1.7:分段锁(Segment),不同段可以并发访问。JDK1.8:CAS + synchronized(锁粒度缩小到桶级别)。 - 性能差异
Hashtable:同一时刻只允许一个线程操作,吞吐量低。ConcurrentHashMap:支持更高并发,性能远高于 Hashtable。 - 扩容与结构演进(JDK1.8)
Hashtable = 一把锁(粗粒度锁)
ConcurrentHashMap = 分段/桶级别锁(细粒度锁)+ CAS
Q:Hashtable 为什么性能差?
A:因为所有操作都使用同一把锁,导致多线程串行执行。
Q:ConcurrentHashMap JDK1.8 为什么取消 Segment?
A:Segment 粒度较粗,难以提升并发度,改为 CAS + synchronized 提高性能。
ConcurrentHashMap
ConcurrentHashMap 在 JDK1.7 和 JDK1.8 中采用了不同的方式来实现线程安全。
JDK1.7 中,ConcurrentHashMap 采用 Segment 分段锁机制:整个 Map 被分成多个 Segment,每个 Segment 继承 ReentrantLock,相当于一把独立的锁。多个线程可以同时访问不同 Segment,从而实现高并发访问。每个 Segment 内部结构类似 HashMap(数组 + 链表),锁粒度是 Segment 级别。
JDK1.8 中,ConcurrentHashMap 取消了 Segment 结构,改为 Node 数组 + 链表 / 红黑树 + CAS + synchronized 实现线程安全。其核心思想是:
- 通过 CAS 保证无冲突情况下的原子操作(如初始化、插入空桶)
- 当发生冲突时,对桶的首节点加 synchronized 锁(桶级别锁)
- 锁粒度进一步缩小,提高并发性能
同时,当链表长度超过阈值(默认 8)时,会转为红黑树,以提升查询效率(O(n) → O(log n))。
Q:JDK1.8 为什么要取消 Segment?
A:因为 Segment 粒度较大,限制并发度,改为桶级锁 + CAS 可以进一步提升并发性能。
Q:synchronized 锁的是整个 Map 吗?
A:不是,只锁当前桶的首节点,锁粒度非常细。
JDK 1.7 和 JDK 1.8 的 ConcurrentHashMap 实现有什么不同?
线程安全实现方式不同
JDK1.7:采用 Segment 分段锁机制(把一个大 Map 拆成多个小 Map),每个 Segment 继承 ReentrantLock(每个 Segment 本身就是一把锁),实现分段加锁,提高并发度。
JDK1.8:取消 Segment,改为 Node 数组 + CAS + synchronized(桶级锁)实现线程安全。
底层数据结构不同
JDK1.7:Segment + HashEntry(数组 + 链表)。
JDK1.8:Node 数组 + 链表 + 红黑树(和 HashMap 基本一样,链表过长会树化)。
锁粒度不同
JDK1.7:锁粒度是 Segment 级别,粒度还是偏大。
JDK1.8:锁粒度是桶(Node)级别,只锁链表或红黑树头节点。
并发能力不同
JDK1.7:并发度受 Segment 数量限制(默认16个Segment,所以也默认支持16线程并发)。
JDK1.8:并发粒度更细,因为锁的是桶,桶数量远远大于16,并发能力更强。
ConcurrentHashMap 能保证复合操作的原子性吗?
ConcurrentHashMap 线程安全 ≠ 复合操作安全
复合操作是指由多个基本操作(如put、get、remove、containsKey等)组成的操作,例如先判断某个键是否存在containsKey(key),然后根据结果进行插入或更新put(key, value)。这种操作在执行过程中可能会被其他线程打断,导致结果不符合预期。
如何保证复合操作原子性?ConcurrentHashMap 提供了专门方法:putIfAbsent、computeIfAbsent
Q1:为什么 containsKey + put 不安全?
A:因为两个操作之间可能被线程切换打断。
Q2:computeIfAbsent 为什么安全?
A:因为内部是原子操作(CAS + 同步控制),不会被插入打断。
Q3:能不能用 synchronized 保证?
A:可以,但会退化为粗粒度锁,性能下降,不推荐。