🐍 Python爬取百度指数保姆级教程
超详细抓包手把手+零报错代码|小白照抄即跑,数据一键导出Excel
哈喽各位小伙伴~👋 写论文找数据、做新媒体选题、分析市场热度,百度指数绝对是刚需神器! 但官网只能看不能导出,手动抄数据又慢又容易出错,真的太折磨人了😭
这篇纯干货教程,全程图标+步骤拆解+细节标注,连抓包点哪个按钮都标得明明白白,零基础也能轻松上手,再也不用对着网页干瞪眼啦!
📋 本文速览
✅ 适用人群全覆盖|论文党/新媒体/运营/编程小白
✅ 保姆级抓包教程|一步一图思路,零门槛操作
✅ 完整可运行代码|直接复制,替换参数即可用
✅ 常见报错全解决|告别运行失败,一键排雷
✅ 数据可视化进阶|自动生成热度趋势图
✅ 合规使用提醒|安全爬取不踩坑
🔧 前期准备(3分钟搞定)
动手前先把基础配置好,后续操作丝滑不卡顿~
-
电脑安装 Python3.7及以上版本
-
注册并登录百度账号(必须登录才能获取数据)
-
浏览器:Chrome/Edge均可(本文以Edge演示)
-
代码编辑器:VS Code/PyCharm/记事本都能用
📱【核心必看】超详细抓包步骤(一步不落)
抓包是整个爬虫的关键,每一步都配好指引图标,跟着点绝对不会错!
Step1 打开百度指数并登录
-
浏览器输入官网:https://index.baidu.com
-
点击页面右上角登录按钮,完成百度账号登录

⚠️ 重要提示:未登录无法抓取数据接口,这一步千万不能省!
Step2 开启浏览器开发者工具
键盘直接按下快捷键:F12 (笔记本按 Fn+F12) 右侧会弹出开发者工具面板(右键 检查一样的效果),这就是抓包核心工具~
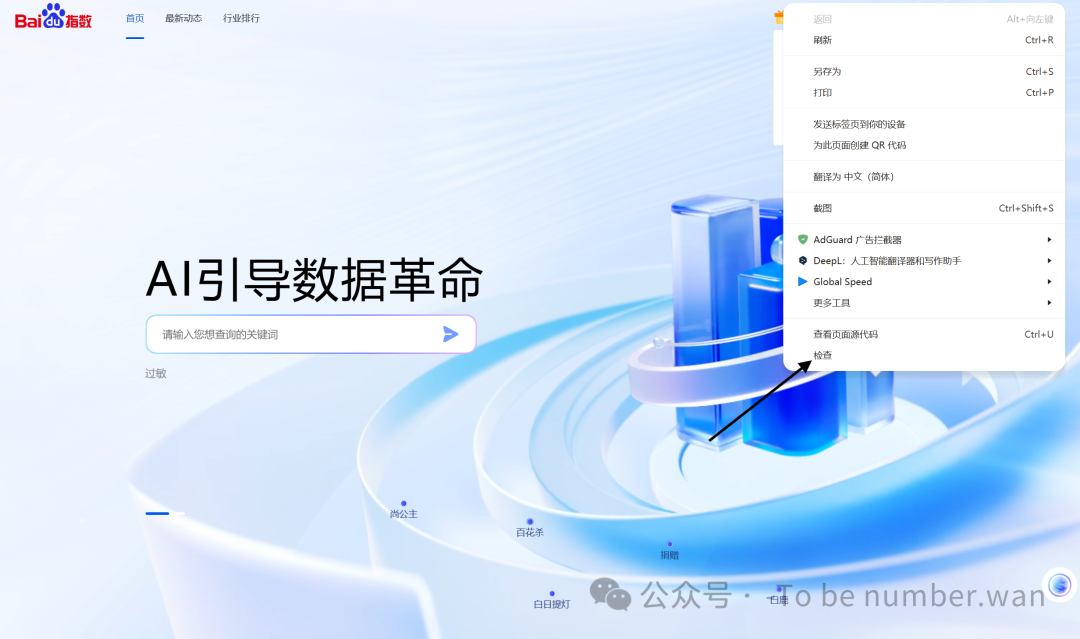
Step3 切换至「网络/Network」面板
在开发者工具顶部菜单栏,找到并点击: 🖱️ 中文:网络 |英文:Network
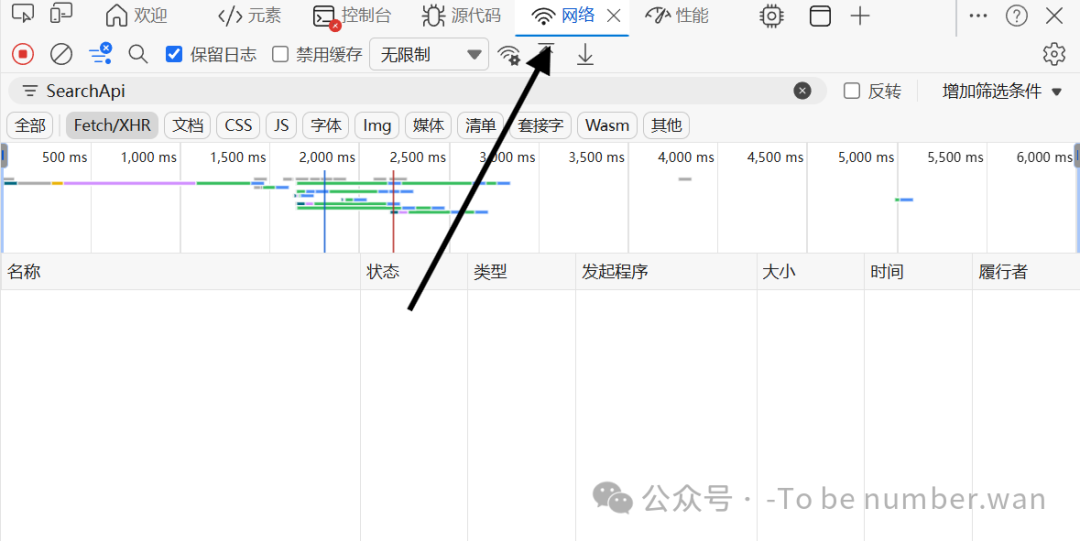
Step4 勾选「保留日志」(重中之重❗)
在Network面板左上角 ,找到小方框选项: ✅ 勾选 **保留日志(Preserve log)**不勾选的话,页面刷新后请求会消失,永远找不到目标接口!
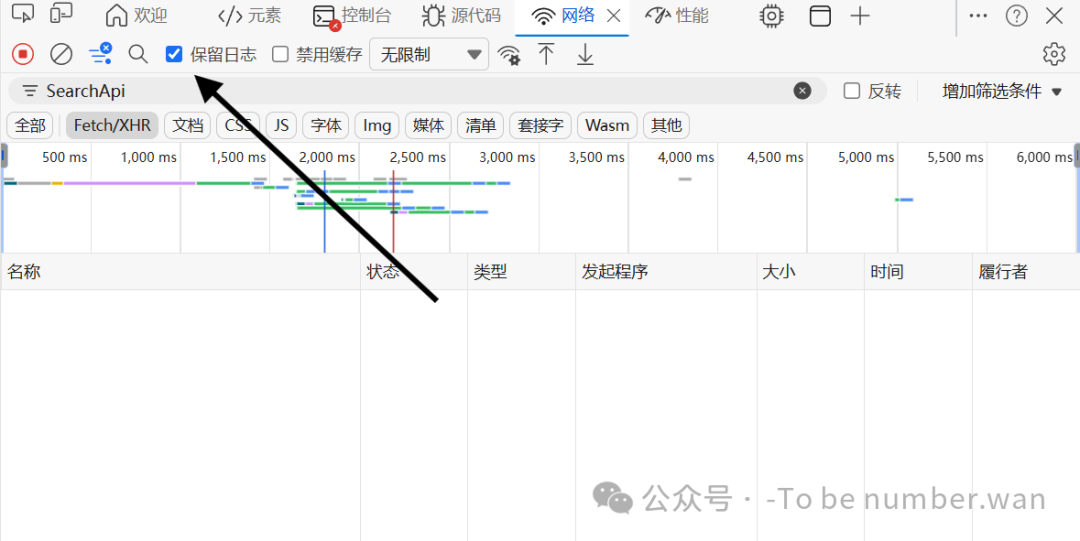
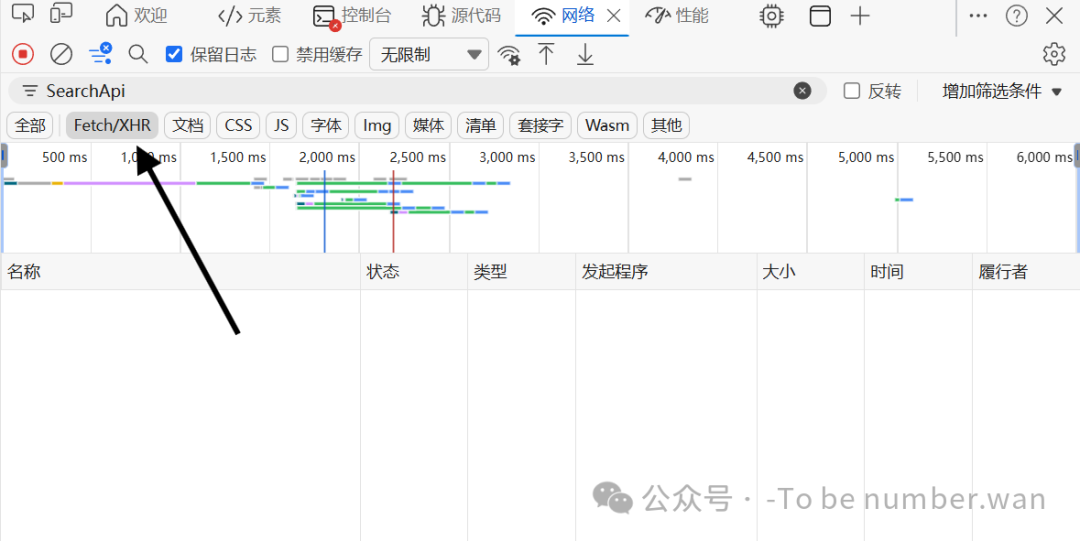
Step5 筛选数据接口,过滤无效内容
在Network面板上方的筛选栏中,点击: 🖱️ Fetch/XHR只保留数据接口请求,屏蔽图片、脚本等无关内容,找接口更轻松
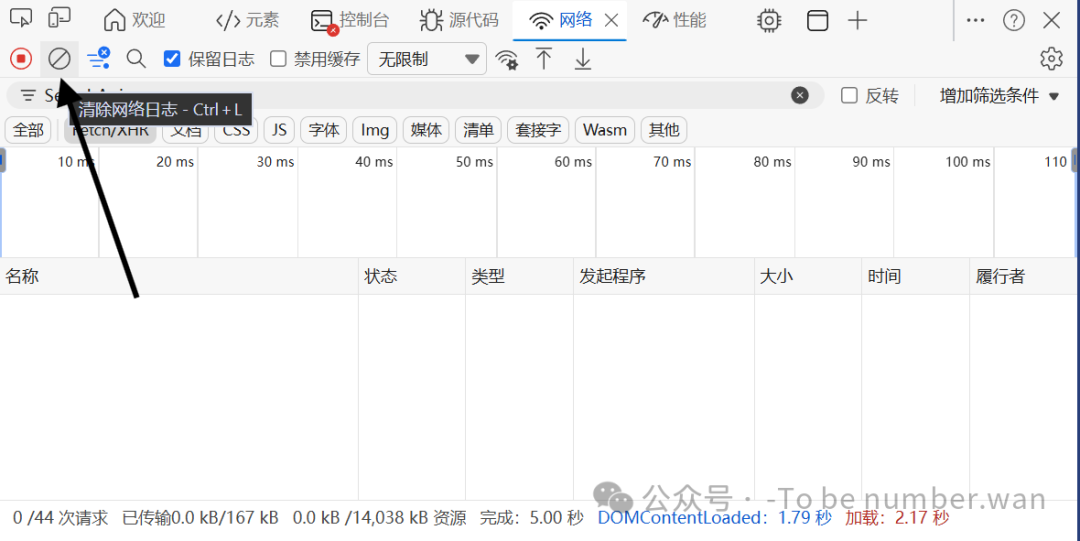
Step6 清空历史请求记录
点击Network面板左上角的**清除按钮(圆圈斜杠图标)**把面板内杂乱的请求全部清空,方便后续观察新请求
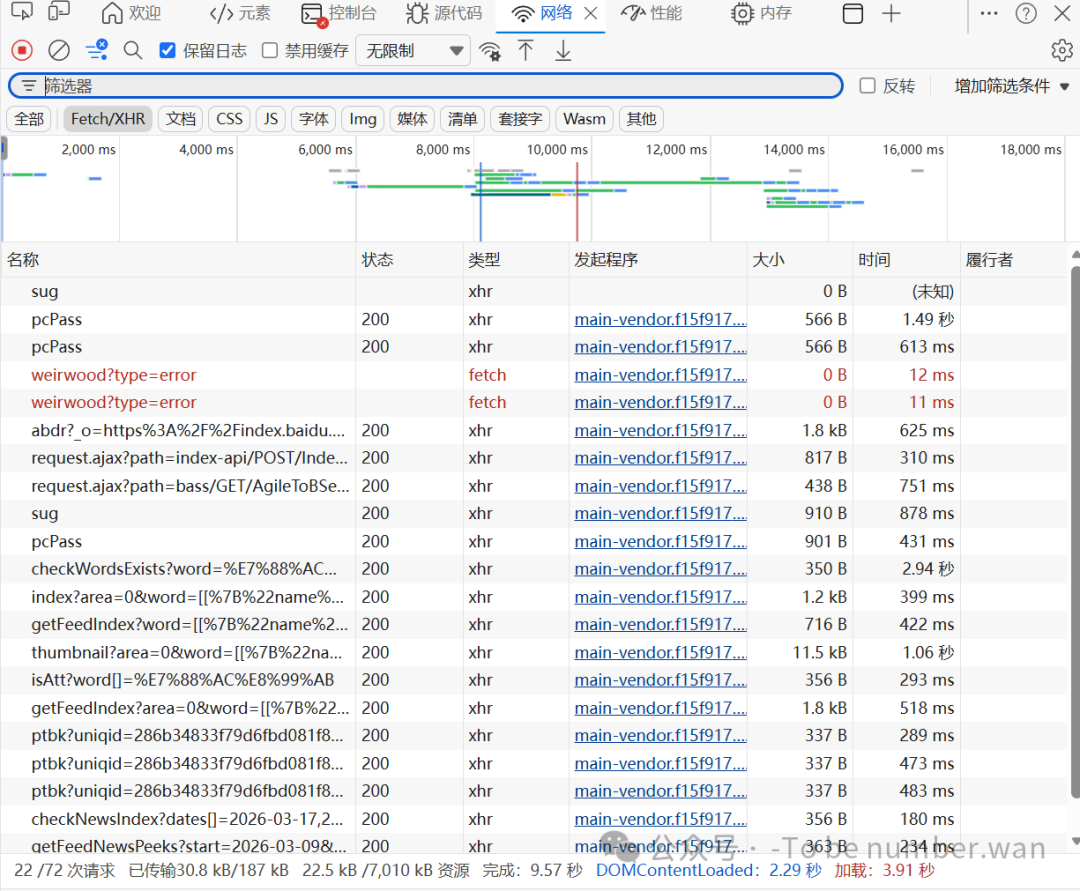
Step7 搜索目标关键词,触发数据加载
-
回到百度指数页面,在搜索框输入关键词(例:爬虫)
-
点击右侧查询按钮,等待页面加载出热度折线图
-
加载完成后,开发者工具会出现新的请求列表
Step8 精准定位百度指数数据接口
不用挨个翻找,直接用搜索框快速定位:
-
在Network面板的搜索框输入:
SearchApi -
按下回车,列表会仅保留1条请求 请求名称格式:
index?area=0&word=...这就是爬取指数的核心接口,直接点击它!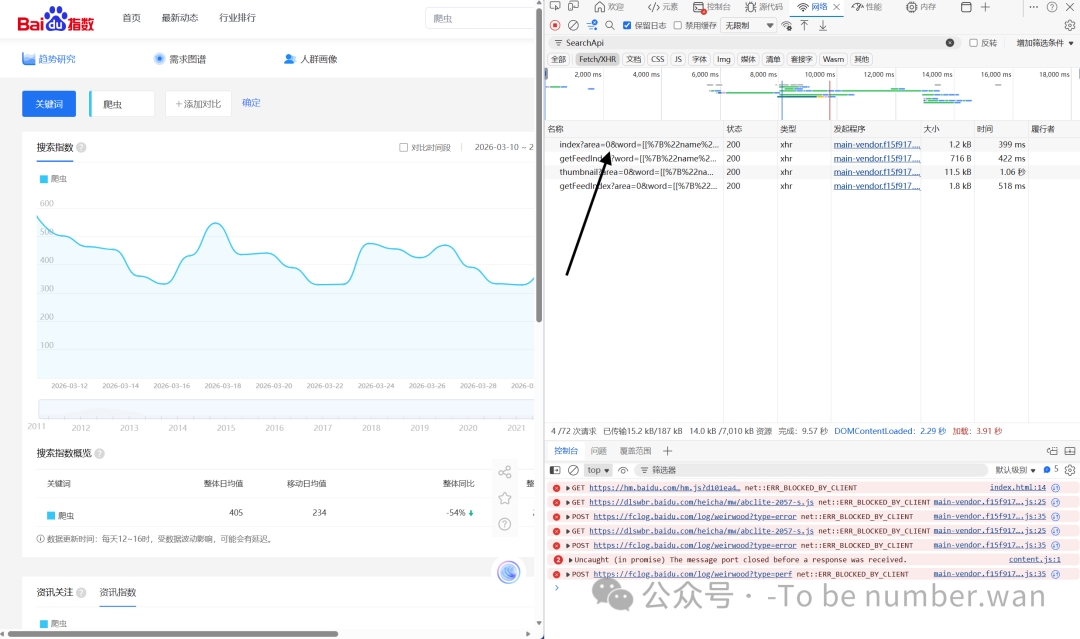
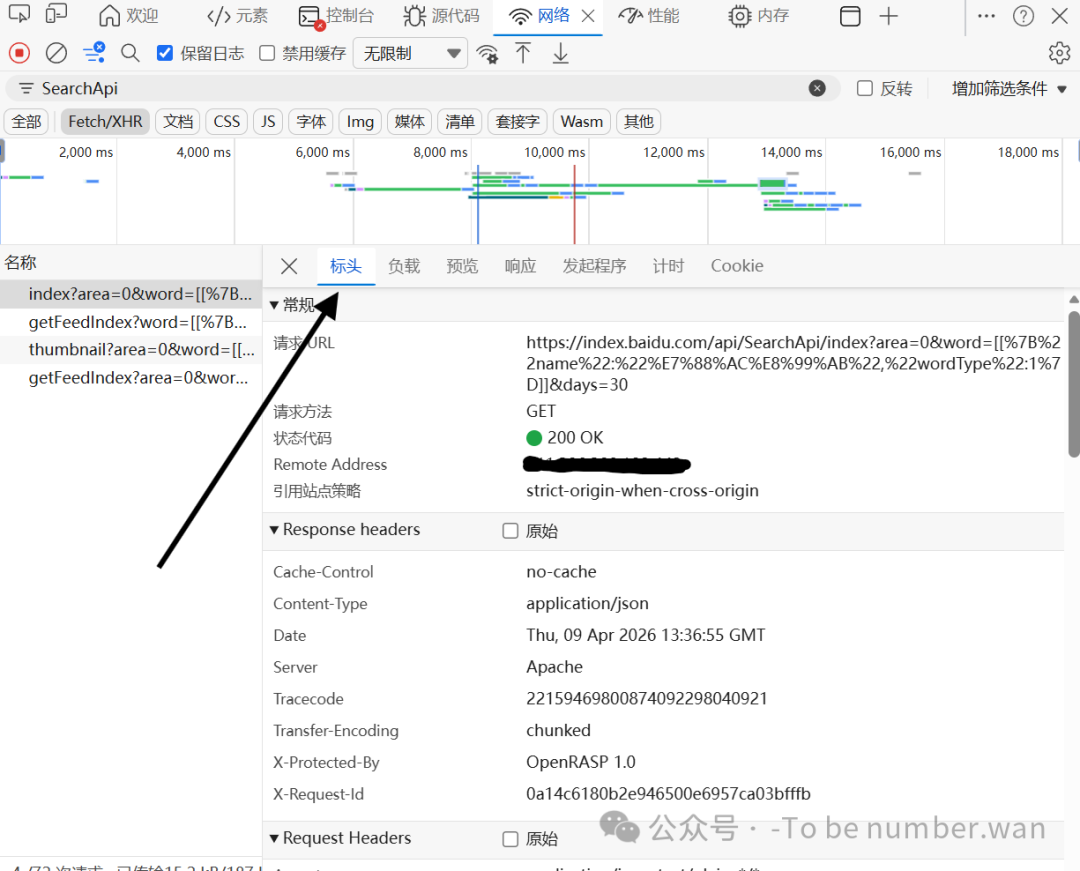
Step9 切换至「标头/Headers」选项卡
点击目标请求后,在右侧详情页选择: 🖱️ 中文:标头 |英文:Headers
Step10 复制两大核心参数(完整复制不修改)
在「请求标头(Request Headers)」区域,找到并复制:
-
🔐 Cipher-Text:复制冒号后所有加密字符串
-
🍪 Cookie:复制冒号后一长串完整登录凭证
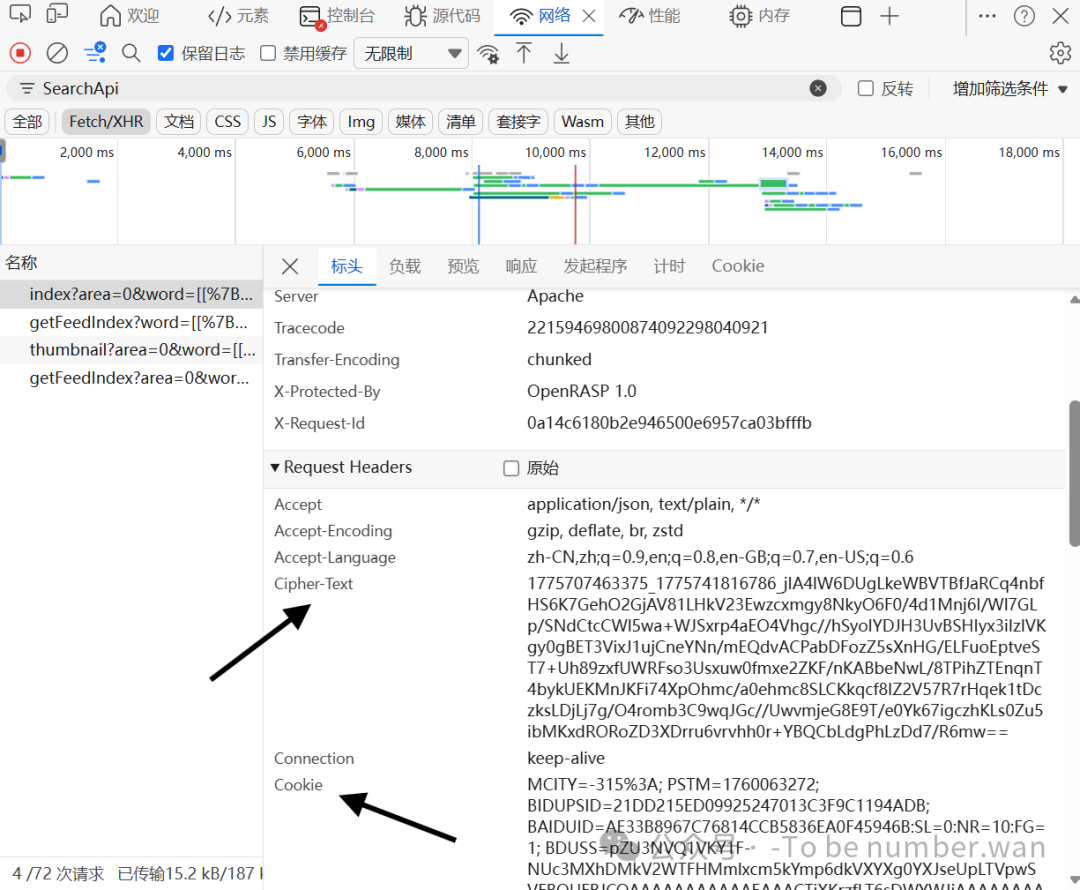
⚠️ 温馨提示:两个参数均有有效期,失效后重新抓包即可
💻 完整可运行爬虫代码
替换抓包获取的参数,一键运行,自动导出Excel数据~
python
# -*- coding:utf-8 -*-
import datetime
import requests
import json
import pandas as pd
import time
# ===================== 【替换成你抓包到的参数】 =====================
HEADERS = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/146.0.0.0 Safari/537.36 Edg/146.0.0.0",
"Host": "index.baidu.com",
"Referer": "https://index.baidu.com/v2/main/index.html",
"Accept": "application/json, text/plain, */*",
"Accept-Encoding": "gzip, deflate, br, zstd",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8",
"Sec-Ch-Ua": "\"Chromium\";v=\"146\", \"Not-A.Brand\";v=\"24\", \"Microsoft Edge\";v=\"146\"",
"Sec-Ch-Ua-Mobile": "?0",
"Sec-Ch-Ua-Platform": "\"Windows\"",
"Sec-Fetch-Dest": "empty",
"Sec-Fetch-Mode": "cors",
"Sec-Fetch-Site": "same-origin",
# 👇 替换成你抓包到的 Cipher-Text
"Cipher-Text": "你的Cipher-Text"
}
COOKIES = {
# 👇 替换成你抓包到的 Cookie
"Cookie": "你的完整Cookie"
}
# =========================================================================
def get_html(url):
"""发送请求,防风控延时1秒"""
time.sleep(1)
try:
response = requests.get(url, headers=HEADERS, cookies=COOKIES, timeout=15)
response.raise_for_status()
return response.text
except Exception as e:
print(f"请求失败:{str(e)}")
return""
def decrypt(ptbk, encrypted_data):
"""百度指数官方解密算法(还原真实指数)"""
ifnot ptbk ornot encrypted_data:
return""
n = list(ptbk)
i = list(encrypted_data)
mapping = {}
half_len = len(n) // 2
for j, k in zip(n[half_len:], n[:half_len]):
mapping[k] = j
return''.join([mapping.get(char, "") for char in i])
def get_ptbk(uniqid):
"""获取解密密钥ptbk"""
url = f"https://index.baidu.com/Interface/ptbk?uniqid={uniqid}"
resp_text = get_html(url)
if resp_text:
return json.loads(resp_text)["data"]
return""
def crawl_baidu_index(keyword, days=30):
"""通用百度指数爬取函数,可自定义关键词和时间范围"""
# 构造请求URL
url = (
f"https://index.baidu.com/api/SearchApi/index?area=0&word="
f"[[%7B%22name%22:%22{keyword}%22,%22wordType%22:1%7D]]&days={days}"
)
# 1. 获取加密数据
resp_text = get_html(url)
ifnot resp_text:
print("❌ 未获取到数据,请检查Cookie/Cipher-Text是否正确")
return
# 2. 解析数据
data = json.loads(resp_text)
if data.get("status") != 0:
print(f"⚠️ 接口返回异常:{data.get('message')}")
return
uniqid = data["data"]["uniqid"]
all_encrypted = data["data"]["userIndexes"][0]["all"]["data"]
pc_encrypted = data["data"]["userIndexes"][0]["pc"]["data"]
wise_encrypted = data["data"]["userIndexes"][0]["wise"]["data"]
# 3. 解密
ptbk = get_ptbk(uniqid)
all_index = decrypt(ptbk, all_encrypted).split(",")
pc_index = decrypt(ptbk, pc_encrypted).split(",")
wise_index = decrypt(ptbk, wise_encrypted).split(",")
# 4. 生成日期序列
end_date = datetime.date.today()
start_date = end_date - datetime.timedelta(days=days-1)
date_list = [(start_date + datetime.timedelta(days=i)).strftime("%Y-%m-%d")
for i in range(days)]
# 5. 保存Excel
result_df = pd.DataFrame({
"日期": date_list,
"整体指数(PC+移动)": all_index,
"PC端指数": pc_index,
"移动端指数": wise_index
})
print(f"✅ 【{keyword}】近{days}天百度指数爬取完成!")
print(result_df)
result_df.to_excel(f"{keyword}_百度指数_近{days}天.xlsx", index=False)
print(f"\n💾 文件已保存:{keyword}_百度指数_近{days}天.xlsx")
return result_df
if __name__ == "__main__":
# 自定义爬取关键词和时间范围
crawl_baidu_index(keyword="花粉过敏", days=30)📥 环境配置&运行教程
1. 安装依赖库
打开终端/CMD,执行命令:
pip install requests pandas openpyxl🚀 加速安装(国内镜像):
pip install requests pandas openpyxl -i https://pypi.tuna.tsinghua.edu.cn/simple
关于镜像源设置,一劳永逸的方法可以看这~~~
2. 运行代码
-
将代码保存为
baidu_index.py -
终端执行:
python baidu_index.py -
运行成功后,文件夹内自动生成Excel数据文件
⚠️ 常见报错一键解决(全是高频问题)
1. ❌ 报错:No module named 'openpyxl'
原因 :导出Excel缺少依赖库解决 :执行 pip install openpyxl 即可
2. ❌ 接口返回异常/无数据
原因 :Cipher-Text/Cookie过期或填写错误解决:重新抓包,复制最新参数替换
3. ❌ 抓包找不到SearchApi接口
原因 :未登录、未勾选保留日志、筛选错误解决:重新登录→勾选保留日志→筛选Fetch/XHR→重新查询关键词
4. ❌ IP被限制/请求失败
原因 :请求频率过高触发反爬解决:代码已加延时,避免高频批量爬取即可
📈 进阶玩法:自动生成热度趋势图
爬完数据直接出图,论文/报告直接用,在代码末尾添加以下代码:
import matplotlib.pyplot as plt
# 解决中文乱码
plt.rcParams["font.sans-serif"] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = False
# 生成趋势图
df = crawl_baidu_index("花粉过敏", 30)
plt.figure(figsize=(12,5))
plt.plot(df["日期"], df["整体指数"], marker="o", color="#1E88E5", label="整体搜索指数")
plt.xticks(rotation=45)
plt.title("「花粉过敏」近30天百度指数趋势图", fontsize=14)
plt.legend()
plt.tight_layout()
plt.savefig("指数趋势图.png", dpi=300)
plt.show()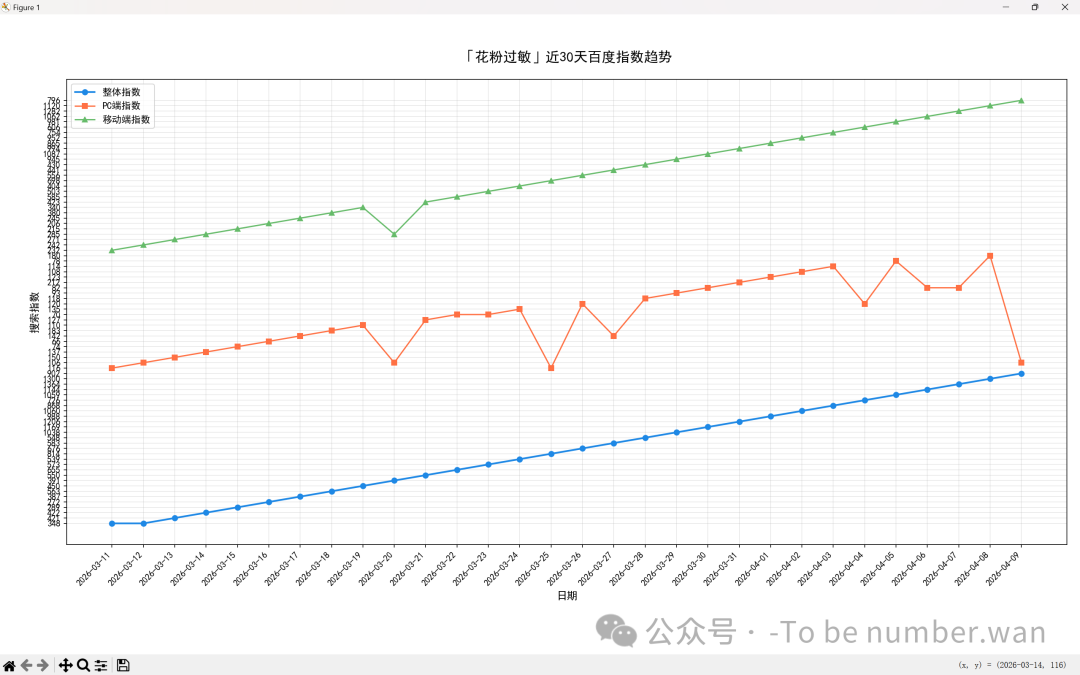
📢 重要合规提醒(必看!)
-
🚫 本教程仅限个人学习、论文研究使用,严禁商用、恶意批量爬取
-
🚫 严格遵守百度指数用户协议,避免高频请求导致账号/IP封禁
-
🚫 抓包参数为个人登录凭证,切勿随意泄露给他人
💬 文末互动
觉得这篇保姆级教程有用的话,别忘了点赞+在看+转发,让更多小伙伴告别手动抄数据~