目录
[3.1 多基站部署策略](#3.1 多基站部署策略)
[3.2 基于梯度的网络分簇](#3.2 基于梯度的网络分簇)
[3.3 簇头选举机制](#3.3 簇头选举机制)
[3.4 能量消耗模型](#3.4 能量消耗模型)
[3.5 Q学习算法原理](#3.5 Q学习算法原理)
[3.5.1 状态空间定义](#3.5.1 状态空间定义)
[3.5.2 动作空间定义](#3.5.2 动作空间定义)
[3.5.3 奖励函数设计](#3.5.3 奖励函数设计)
[3.5.4 Q值更新规则](#3.5.4 Q值更新规则)
1.引言
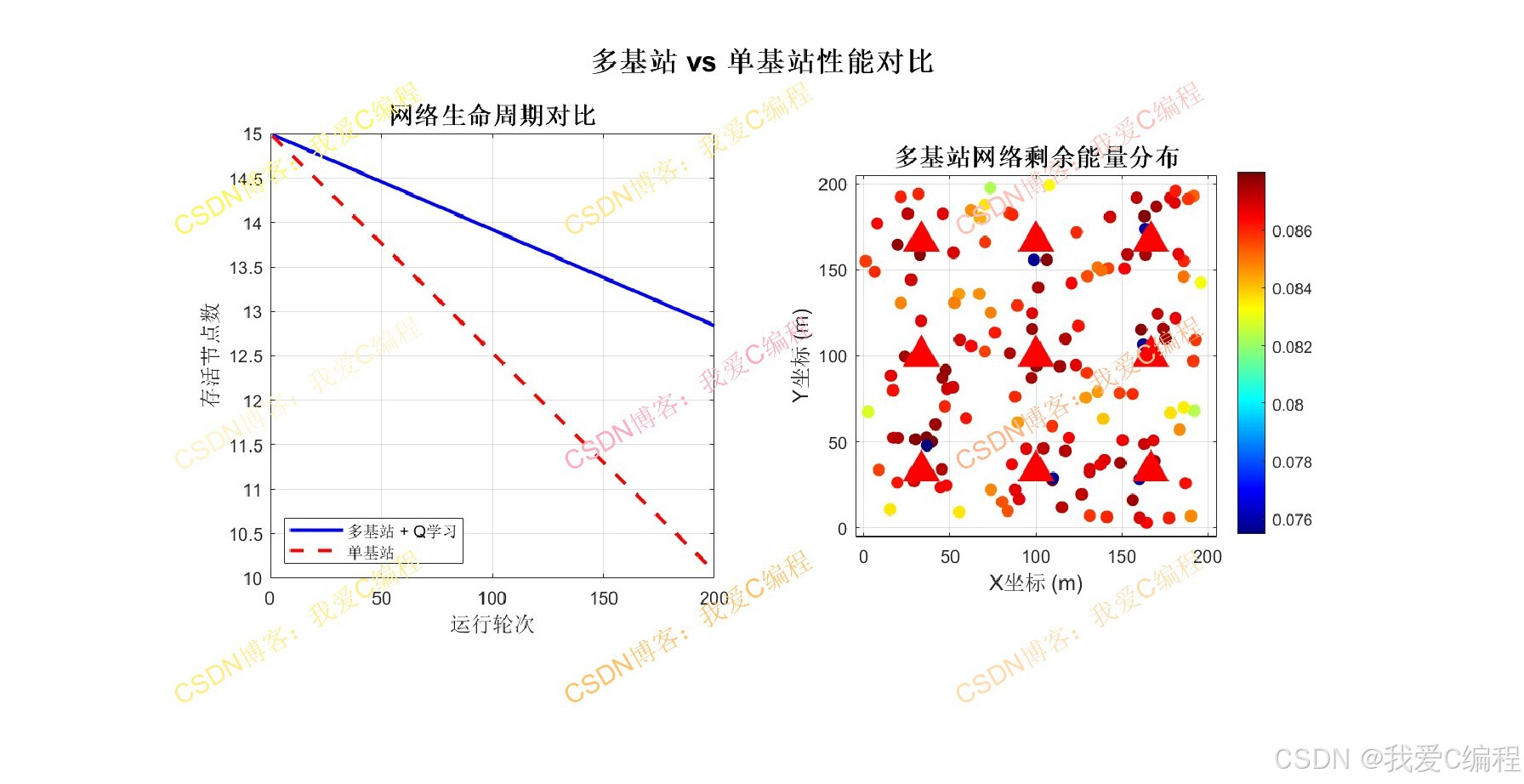
在无线传感器网络(Wireless Sensor Network, WSN)中,大量传感器节点通过自组织方式部署在监测区域内,将采集到的数据经多跳转发汇聚到基站(Base Station, BS)。传统单基站网络架构中,靠近基站的节点承担了大量转发任务,其能量消耗远高于远端节点,导致这些节点过早死亡,形成所谓的"能量空洞"(Energy Hole)现象。能量空洞不仅使得基站周围出现通信盲区,还会导致网络分割、数据传输时延急剧增加、网络生命周期大幅缩短等问题。为解决上述问题,本算法引入多基站部署策略,结合分簇拓扑控制和Q学习强化学习方法,在网络中部署多个基站以均衡负载分布,通过图论和定向扩散中梯度的思想进行网络分簇,并利用Q学习算法对簇头节点进行周期性训练,在多条可达不同基站的路径中选择最优转发路径,从而有效延长网络生命周期并降低端到端时延,从而提升网络的寿命。
2.算法测试效果

3.算法涉及理论知识概要
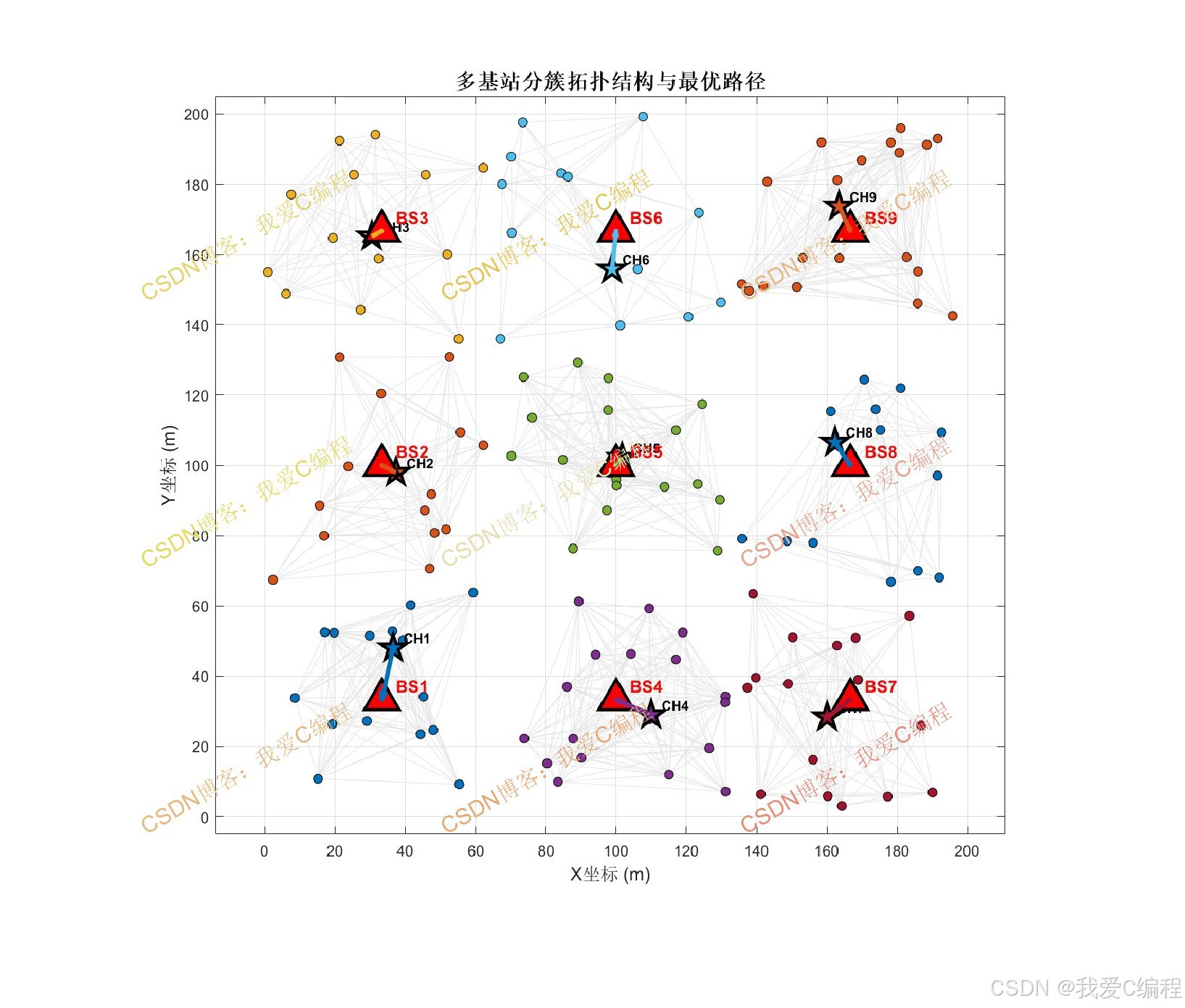
3.1 多基站部署策略
多基站部署的核心思想是:根据网络区域面积、节点密度和通信半径等参数,确定最优的基站数量与位置。设网络部署区域为边长为L的正方形区域,节点总数为N,节点通信半径为Rc。基站数目M的选择依据网络面积和通信覆盖需求确定:

其中α为覆盖冗余系数,一般取α∈3,8,用于调节基站密度以适应不同场景。基站位置采用均匀分布策略,将区域划分为M个等面积子区域,基站放置在每个子区域的几何中心。若基站数为 M=m×m,则第(i,j)个基站的坐标为:
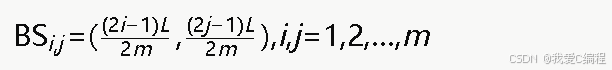
3.2 基于梯度的网络分簇
借鉴定向扩散协议中梯度的概念,本算法为每个传感器节点定义到每个基站的"梯度值",梯度值反映节点到基站的跳数距离。节点nk到基站BSj的梯度值G(nk,BSj)定义为节点到该基站的最小跳数:
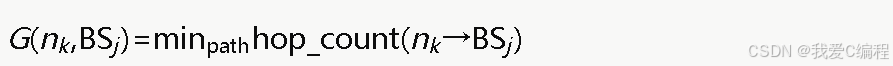
梯度值通过泛洪方式计算:每个基站向全网广播兴趣消息,消息中携带跳数计数器,初始值为零。节点收到消息后将跳数加一并记录,同时继续转发。若节点收到同一基站的多条路径消息,则保留跳数最小的作为该基站的梯度值。
分簇原则为:每个节点归属于梯度值最小的基站对应的簇。设节点nk对所有基站的梯度值集合为 {G(nk,BS1),G(nk,BS2),...,G(nk,BSM)},则节点nk的簇归属为:
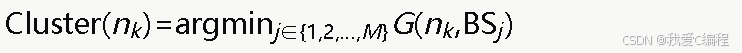
3.3 簇头选举机制
在簇内,采用基于剩余能量和位置因素的加权策略选举簇头。节点nk在第t轮的簇头竞选概率为:
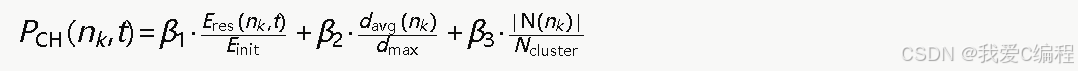
其中,Eres(nk,t)为节点当前剩余能量,Einit为初始能量,davg(nk)为节点与簇内其他节点的平均距离,dmax为簇内最大节点间距离,∣N(nk)∣为节点的邻居节点数,Ncluster为簇内总节点数。权重系数满足β1+β2+β3=1,通常设置β1=0.5,β2=0.3,β3=0.2,以强调剩余能量在簇头选举中的主导作用。
3.4 能量消耗模型
本算法采用一阶无线电能量消耗模型。节点发送l比特数据到距离d的接收节点,发送能耗为:
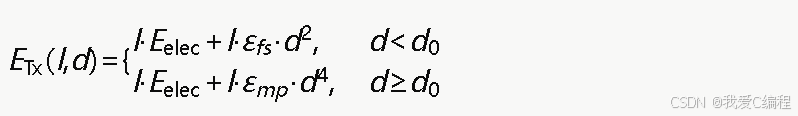
接收l比特数据的能耗为:

其中Eelec为电子电路能耗,εfs为自由空间信道模型参数,εmp为多径衰落信道模型参数,d0为阈值距离。
3.5 Q学习算法原理
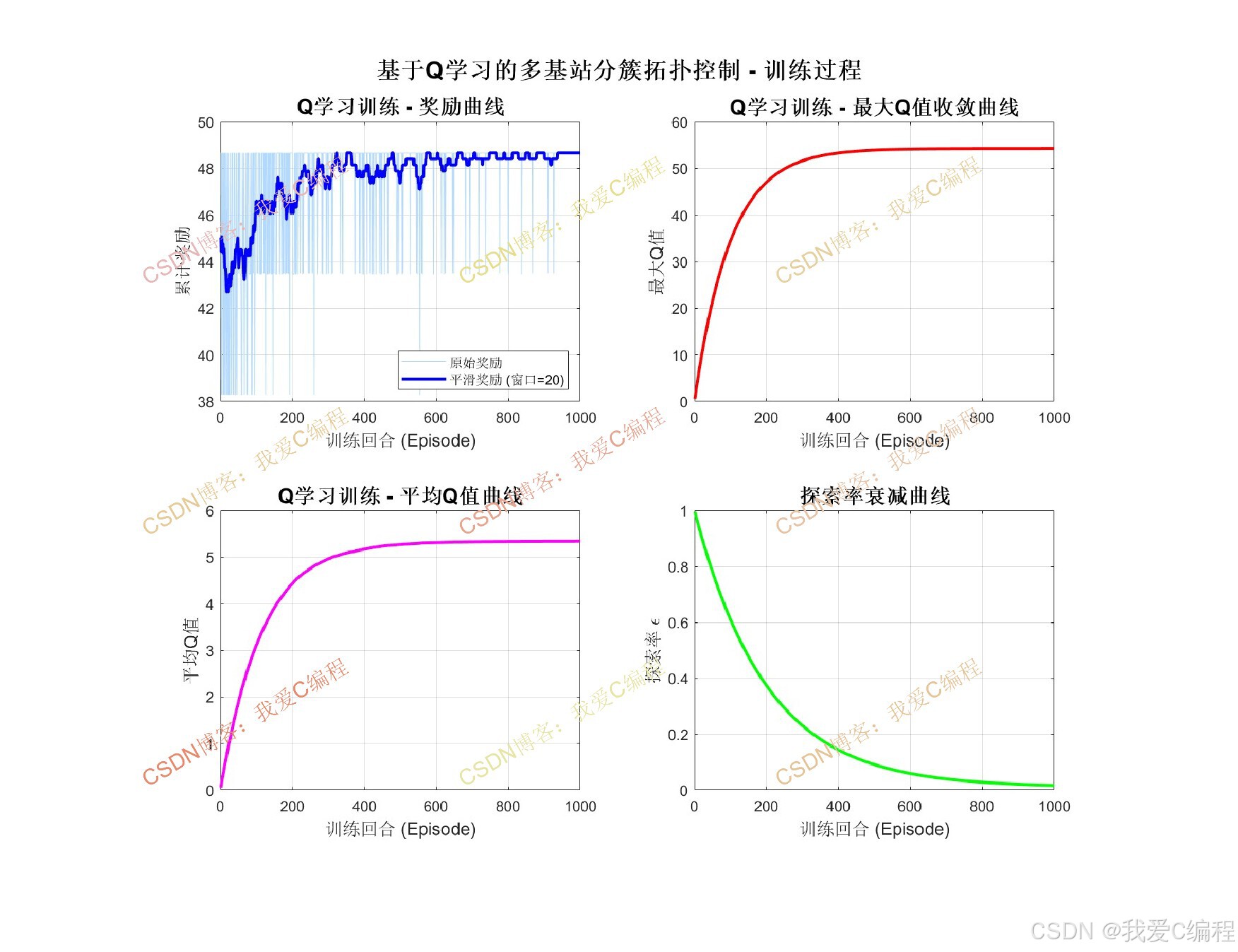
Q学习是一种无模型的强化学习算法,通过"试错"机制让智能体在与环境交互过程中学习最优策略。在本算法中,每个簇头节点作为一个智能体,其目标是从多条可达不同基站的路径中选择能量效率最高、时延最低的最优转发路径。
3.5.1 状态空间定义
簇头节点nk的状态s由其当前剩余能量等级和到各基站的梯度值组合构成。剩余能量被离散化为 QE个等级:
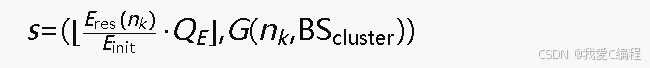
3.5.2 动作空间定义
每个簇头的动作a是选择其下一跳转发节点。对于簇头nk,其可选动作集合为邻居簇头节点集合或直接可达的基站集合:
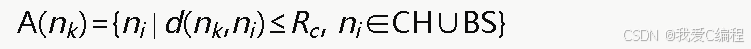
3.5.3 奖励函数设计
奖励函数综合考虑能量消耗、网络剩余能量均衡度和传输时延三个因素:

其中nnext为动作a对应的下一跳节点,ω1、ω2、ω3为权重系数且满足ω1+ω2+ω3=1。若动作直接到达基站,则给予额外正向奖励Rbonus。
3.5.4 Q值更新规则
每个簇头维护一个Q表Q(s,a),采用时序差分方法更新:

4.MATLAB核心程序
% 网络参数
L = 200; % 区域边长(m)
N = 150; % 传感器节点数
Rc = 50; % 通信半径(m)
M_sqrt = 3; % 基站分布 2x2
M = M_sqrt^2; % 基站数目
E_init = 0.1; % 初始能量(J)
l_bits = 4000; % 数据包大小(bits)
% 能量模型参数
E_elec = 50e-9; % 电子电路能耗(J/bit)
eps_fs = 10e-12; % 自由空间模型参数
eps_mp = 0.0013e-12; % 多径衰落模型参数
d0 = sqrt(eps_fs/eps_mp); % 阈值距离
% Q学习参数
alpha_lr = 0.1; % 学习率
gamma = 0.9; % 折扣因子
epsilon_max = 1.0; % 初始探索率
epsilon_min = 0.01; % 最小探索率
lambda_decay = 0.005; % 衰减系数
num_episodes = 1000; % 训练回合数
num_energy_levels = 10; % 能量离散等级5.完整算法代码文件获得
完整程序见博客首页左侧或者打开本文底部GZH名片
( V关注后回复码 :X130)
V