
一、Stripe 每周千个 PR,我却连一个模块都不敢让 AI 独立写
前阵子社区被 Stripe 的一则消息刷屏:他们的 Minions 系统让 AI 每周产出上千个 PR,工程师只需要做代码审查。消息一出,一批人欢呼"AI 替代程序员进入倒计时",另一批人开始焦虑------我一个人/小团队,怎么才能跟上这个节奏?
说实话,我看完之后的第一反应不是焦虑,是疑惑:大厂是怎么做到让 AI 产出的 PR 能看的?
因为我自己试过太多次 Vibe Coding------就是打开 AI,凭感觉让它从头写一个功能。流程大概是这样:
- 打开 Claude Code / Cursor,甩一句"帮我实现 XX 功能"
- AI 兴致勃勃地开始生成,前两轮效果不错
- 第三轮开始出现接口名不一致、重复的工具函数、偶尔蹦出的幻觉 API
- 第五轮之后,整个模块开始"漂移"------我自己都快认不出这是我让它写的项目了
举一个最近刚踩的坑:上周我让 AI 给一个现成项目加"批量上传"子系统,前两轮输出干脆利落,到第四轮我突然发现它悄悄把我项目里已有的 FileUploader 类替换成了一个新造的 BatchUploadManager------接口签名都改了,调用点还散落在五六个文件里。我看到 diff 的时候直接骂出声------这下好了,一下午全得搭进去把这些"善意的重构"一个一个挑出来清理。

然后我就得花半天去清理。清理到最后我发现一个残酷的事实:我删掉的 AI 代码,比我留下的还多。
二、Vibe Coding 的失控,不是 AI 不够聪明,是起点错了
这篇文章的核心暴论先抛出来:
你让 AI 从零写一坨代码,它就一定会失控。这不是模型能力的问题,是上下文承载量的物理极限------而你给它的起点太低了。
这里面的门道是什么?我实测踩过的坑归纳下来三条硬道理:
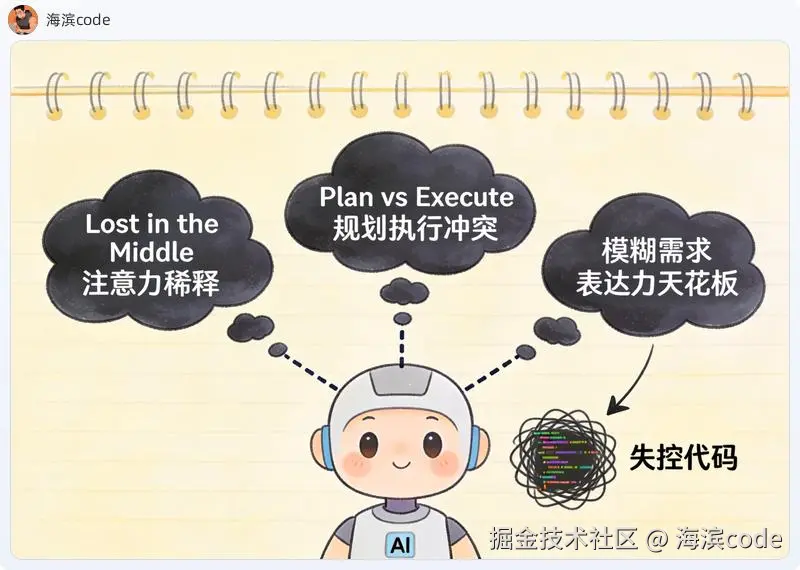
理由一:超长上下文里,AI 的"注意力"一定会掉档。
Stanford 2023年有篇论文(Lost in the Middle)把这个现象钉死了:大模型在长上下文里,两头的信息记得最牢,中间段位的信息被严重稀释。放到编码场景就更戏剧------不管你用的是 Claude、GPT 还是别的旗舰模型,一旦让它在几万行代码的上下文里做增量开发,到第三四轮就会出现"遗忘已有约定"的现象。前面定义过的接口签名会被它悄悄改成新名字,已经存在的 util 函数会被它重新造一个轮子。这不是 bug,是注意力机制的物理极限------上下文越长,关键信息被稀释得越厉害。
所以别再指望"我把整个项目扔进上下文,AI 就能看懂全局"------塞得越多,它漏得越狠。大上下文 ≠ 好结果,这是写 AI 编程文章的人不愿意告诉你的真相。
理由二:AI 在"规划"和"执行"两个任务上会互相干扰。
让 AI 从零写一个模块,它同时要做两件事:想清楚应该怎么设计(规划),和把设计翻译成代码(执行)。这两件事在一次对话里反复切换,会让它的整体产出质量塌方。你仔细看失控后的代码,常常是"每一段单看都对,合在一起逻辑自相矛盾"。
理由三:Vibe Coding 的上限是你自己的表达能力,不是 AI 的能力。
我见过太多人抱怨"AI 写的代码不能用",仔细一追,需求本身就描述得模糊。AI 不是没给你最好的答案,是没人告诉它什么叫好------而你自己也没想清楚。
三、成熟模块的真正价值,是给 AI 减负
上面的三条理由听起来像是"AI 编程的死路",但其实它们都指向同一条出路------不要让 AI 从零开始。
我在这里想抛出一个可能更反直觉的观点:
软件工程过去二十年积累的那堆成熟开源模块、业务组件、通用工具库,它们今天最大的价值不是"省你时间",而是"给 AI 减负"。
过去我们用开源模块,想的是"别重复造轮子"。现在 AI 参与进来之后,价值发生了升级------预验证过的成熟模块,等于给 AI 一块"不用再理解"的既定地基。AI 不需要搞清楚这个模块内部怎么实现的、有没有坑、边界条件怎么处理,它只需要知道接口长什么样、怎么调。这些信息量只有原始代码的零头。
一句话:把 AI 要处理的 10 万行代码减负到只需要理解 20% 的胶水。注意力焦点一旦收窄,幻觉和漂移立刻降一个数量级。
这不是什么新思路,它就是传统软件工程里"复用优先"的老道理。但放到 AI 编程时代,它突然变得极其关键------因为 AI 最怕的就是"从零到一",它最擅长的恰恰是"在既定约束下做微调"。换句话说:AI 擅长修修补补,不擅长白手起家。那你就别让它白手起家。
举一个我前阵子的实测小例子:同样是"给一个项目加 HTTP 请求重试能力",让 AI 从零写,它会把 urllib 封装、退避算法、异常分类一套全重新实现一遍,动辄两三百行还未必对;但如果我先在提示里告诉它"项目里已经有 tenacity 装饰器、一个统一日志工具、一个自定义异常基类"------这些都是预验证过的成熟模块------AI 最后只写了不到三十行的业务胶水就解决了。十倍的代码量差距背后,是 AI 注意力焦点的断崖式收窄:它不用再去"发明"什么,只需要"连接"什么。
道理讲完了,但操作上还有三个老大难挡在路上:你知道有一堆开源模块可以用,但在哪儿找? 每次开新功能就要开五个标签页翻 GitHub、npm/PyPI、社区推荐,一小时过去了正事还没开始。就算找到了,把多个模块"胶水"到一起,工作量不小 ------每个模块的 API 风格、初始化方式、异常处理都不同,跨三四个模块的胶水就是两天。更要命的是,已有的大项目里其实已经沉淀了一堆可复用模块,但你自己都记不全有哪些。换个新需求过来,你想复用自己的资产,却发现连翻找的成本都高到让人放弃。

所以我后来就在想:能不能有个工具,把"找模块 + 评估 + 装配 + 胶水"这些脏活全自动化?我只负责告诉它我要做什么,它直接产出一个可以丢给 AI 去执行的八十分起点?
四、GufaForge 的思路:把"给 AI 减负"做成一条流水线
承接上一篇我提到的 GufaForge(古法锻造------"古法"就是 AI 出现之前人手工写的那些经过验证的代码),这篇正好可以聊清楚它到底在解决什么问题。
先把定位讲清楚 :它不是又一个代码生成工具,也不是套壳 Claude Code 的 IDE 插件。它解决的是一个更底层的问题------在 AI 动手之前,先替它把注意力减负做完。你可以把它理解成 AI 的"前置工作台":扫描、评估、装配、产出清单------所有让 AI 头疼的"理解已有代码"的脏活都在这里做完,AI 最终拿到的只是一份边界清晰的装配计划。
整条流水线串起来就是一条"从需求到八十分起点"的自动化路径:先对你本地代码库做一次资产盘点(扫描模块边界、输入输出、依赖关系,打成可检索的索引),再拿你的自然语言需求去匹配------能复用的自家模块先填上,缺什么再去外部生态(GitHub / npm / PyPI)检索候选,最后把完整的装配计划导出成一份结构化的 MD 文档。
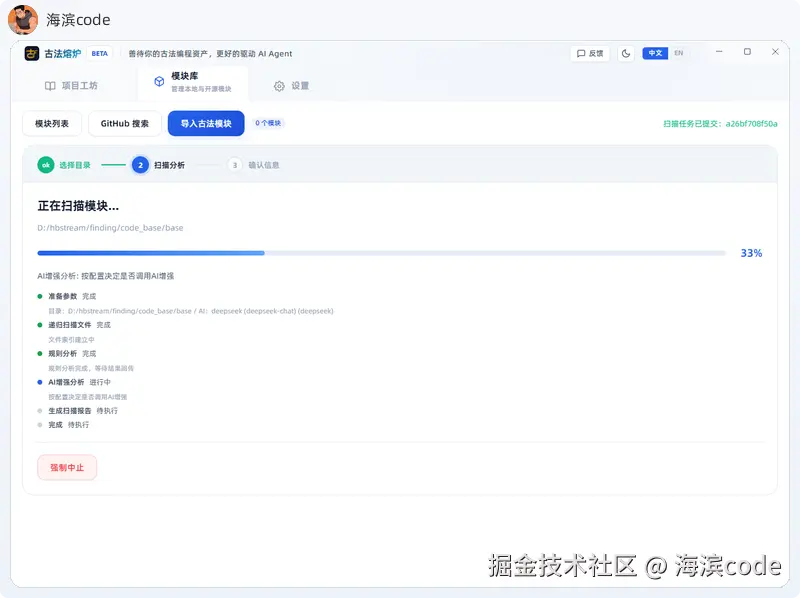
关键是到最后一步为止,还没有生成任何一行真正的代码------GufaForge 只在做"规划"这件事,它产出的不是代码,是一张可执行的蓝图。
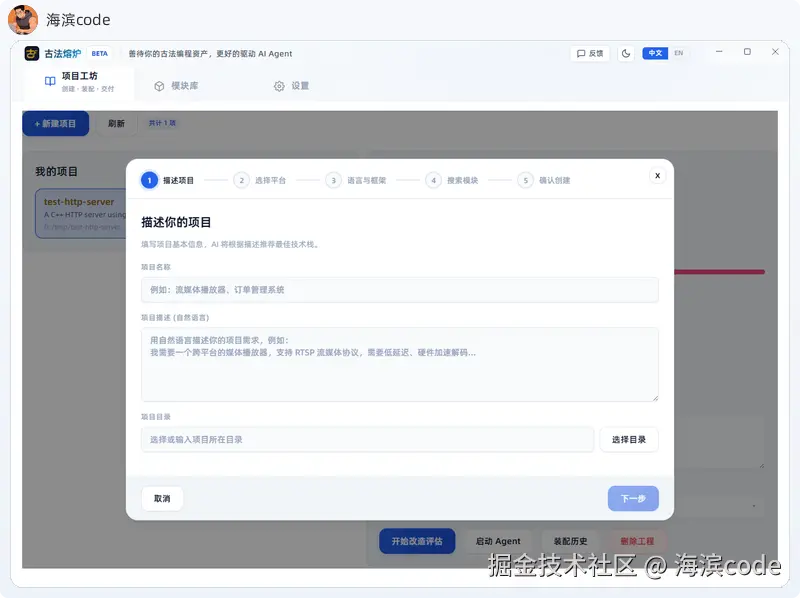
这份 MD 就是你递给 AI Agent 的"从八十分开始的起点"。Agent 拿到它,看到的不是"你从零实现一个 XX",而是"这里有 80% 的骨架,请按清单把剩下 20% 的胶水代码补完"。从白纸到代码 vs 从清单到代码,AI 的失控率差了一个量级------前者要它同时做规划和执行两件事,这俩在一次对话里会互相干扰;后者只让它做最擅长的"按约束填代码",规划的脏活 GufaForge 已经替它做完了。
五、同一个功能,两种起点,差距有多大
说这么多不如看实际对比。我拿同一个功能需求------"给现有项目加一个文件批量处理的子系统,支持并发、错误重试、进度回调"------分别用两种方式交给 AI 实现。
一个下午的 A/B 对比做下来,差距大到我自己都没想到:
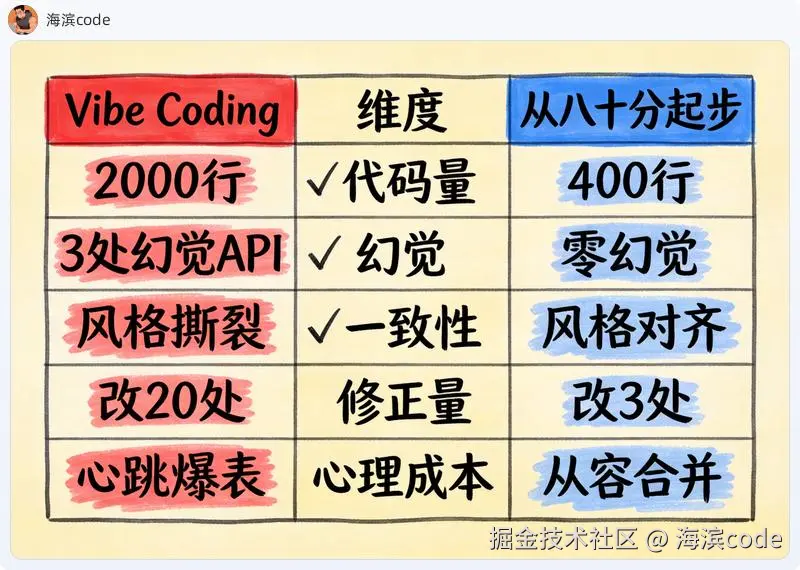
- Vibe Coding 方案:AI 吐出一个两千多行的实现,其中一半是重复造轮子(项目里其实已经有并发池工具),三个地方用了根本不存在的 API,接口风格和项目其他部分完全不一致。我花了一个下午做审查和清理
- 从八十分起步方案:AI 拿到装配清单后只补了约四百行业务胶水代码,复用了项目里已有的并发池 + 重试装饰器 + 日志模块,接口风格天然一致。我花了半小时过一遍就合并了
具体到几个可量化的维度,差距大到不像同一个 AI 写的:
- 代码行数:两千多行 vs 四百行,差 5 倍以上。不是 AI 变懒了,是它不用再实现那些项目里已经有的工具函数
- 幻觉 API 数量 :Vibe Coding 方案里至少有三处 AI 自己编出来的 API(比如调用了根本不存在的
ConcurrentPool.batch_submit_async()),八十分方案里一个都没有------因为能用的 API 都在清单里给它定死了 - 接口风格一致性:Vibe Coding 方案里新老代码风格撕裂感明显(有的用 snake_case 有的用 camelCase),八十分方案因为复用了项目既有工具,风格天然对齐
- 手动修正次数:前者改了不下二十处,后者两三处就收尾了
- 心理成本:前者每次合并前我都要反复自问"这段 AI 代码真的能跑吗",后者因为边界清晰,合并前的心跳明显低一档------这个感受看起来软,但它才是真正能把人和 AI 长期绑在一起的东西
一个人开发者能不能长期和 AI 协作下去,关键不在 AI 写得有多快,而在你每次合并前心跳有多低。
不是说 AI 变聪明了,是它的任务被压缩到了它最擅长的粒度------"在既定约束下做微调"。
六、这个方法什么时候不好使
新项目第一天你手里没有任何可复用的模块,这招就用不上;你得愿意写"薄胶水层"而不是追求完美抽象;Agent 执行阶段你还是得自己过一遍,人工审查这一关谁也省不掉。
但它能帮你做到的事非常具体:让 AI 从"灾难型合作者"变成"靠谱的初级工程师",让你写过但遗忘的历史代码资产重新激活,让"一个人的工程量"追上"小团队的节奏"------最后这条是我自己最在乎的点。

GufaForge 目前还在内部打磨,工程化在持续完善。开源时间我暂时不想承诺------这个工具对我自己太重要,我想等它稳到我敢每天自用再放出来。
不过如果你对"从八十分开始"这个思路感兴趣,有几件事可以立刻做:
- 花半小时写一份"本项目模块清单"------核心工具类/通用组件/已有的装饰器,每条一行注明"做什么 + 从哪调用"------把这份清单塞到 Claude Code / Cursor 的项目级 instructions 里,下次让 AI 写功能时它自然会先去复用而不是瞎造
- 下次写新功能时,别直接甩给 AI,先自己搭个骨架再让 AI 填肉------哪怕骨架只是个空函数签名列表,你会发现失控率立刻降一半
- 关注我后续的更新------下一篇我打算写"从八十分开始"在真实项目上跑一圈后踩到的新坑(有的坑只有规模化用了才会出现)
对我自己来说,从去年开始我就在纠结一个问题:一个人怎么才能做出十个人的工程量,而不是被 AI 拖进"写一堆又要删一堆"的循环里。"从八十分开始"是我目前能想到的最靠谱的答案。
如果你和我一样,看着 Stripe 的千 PR 公告一边兴奋一边焦虑,那欢迎一起走这条路。先把起点抬到八十分,剩下的交给 AI------这个分工方式我已经自己跑了几个月,到今天为止,它是我用过的唯一一条不让人抓狂的 AI 编程路径。
关于作者:10年+码农,曾任某互联网大厂技术专家。常年专注于原生应用和高性能服务器开发、视频传输和处理技术以及AI个人生产力研究。