218-深度学习基础概念下
一 function with unknown
1.1 New Model: More Features

这张图片是李宏毅机器学习课程中的一页PPT,标题为 "New Model: More Features"(新模型:更多特征)。
它展示了从简单的线性模型进化到复杂的神经网络模型的数学推导过程,核心逻辑是:通过引入非线性激活函数(Sigmoid)和多维特征,极大地提升了模型的表达能力。
以下是对图片中四个公式的详细层级分析:
1. 第一层:从"简单线性"到"非线性组合"(单特征)
- 公式 1(最上方): y=b+wx1y = b + w x_1y=b+wx1
- 含义: 这是最基础的线性回归模型。
- 解释: 只有一个输入特征 x1x_1x1,模型只能拟合一条直线。bbb 是偏置,www 是权重。
- 公式 2(第二行): y=b+∑icisigmoid(bi+wix1)y = b + \sum_i c_i \text{sigmoid}(b_i + w_i x_1)y=b+∑icisigmoid(bi+wix1)
- 进化点: 引入了**非线性激活函数(Sigmoid)*并进行*求和。
- 解释: 这对应了之前几张图的内容。模型不再是一条直线,而是由许多个 Sigmoid 曲线叠加而成。
- 意义: 即使是单特征 x1x_1x1,通过叠加多个 Sigmoid,模型现在可以拟合任意形状的曲线(比如之前的红色折线)。
2. 第二层:从"单特征"到"多特征"(线性版)
- 公式 3(第三行): y=b+∑jwjxjy = b + \sum_j w_j x_jy=b+∑jwjxj
- 进化点: 引入了更多特征。
- 解释: 输入不再只是 x1x_1x1,而是变成了一个向量(x1,x2,...x_1, x_2, ...x1,x2,...)。这是多变量线性回归。
- 意义: 模型可以处理更复杂的数据(例如预测房价时,不仅看房子的面积 x1x_1x1,还要看房龄 x2x_2x2、位置 x3x_3x3 等)。
3. 第三层:最终形态------神经网络(多特征 + 非线性)
- 公式 4(最下方): y=b+∑icisigmoid(bi+∑jwijxj)y = b + \sum_i c_i \text{sigmoid}(b_i + \sum_j w_{ij} x_j)y=b+∑icisigmoid(bi+∑jwijxj)
- 进化点: 结合了上述两者的优点。既有多特征输入 ,又有非线性变换。
- 解释: 这是典型的**单层神经网络(或多层感知机的一层)**的数学表达。
- 内部求和 (∑jwijxj\sum_j w_{ij} x_j∑jwijxj): 对所有输入特征进行加权求和(线性变换)。
- Sigmoid: 对加权和进行非线性激活。
- 外部求和 (∑i\sum_i∑i): 将多个神经元的输出再次加权求和,得到最终结果。
- 意义: 这是现代深度学习的基础。它不仅能处理高维数据(如图像的像素),还能拟合极其复杂的非线性关系。
总结
这张图非常精妙地展示了深度学习模型的设计思路:
- 如果数据是非线性的,我们加 Sigmoid。
- 如果数据维度很高,我们加 更多特征 (xjx_jxj)。
- 最终模型就是这两者的结合:对多维特征进行加权求和,通过非线性函数激活,最后再汇总。
1.2 简单的神经网络模型(单隐层前馈神经网络)
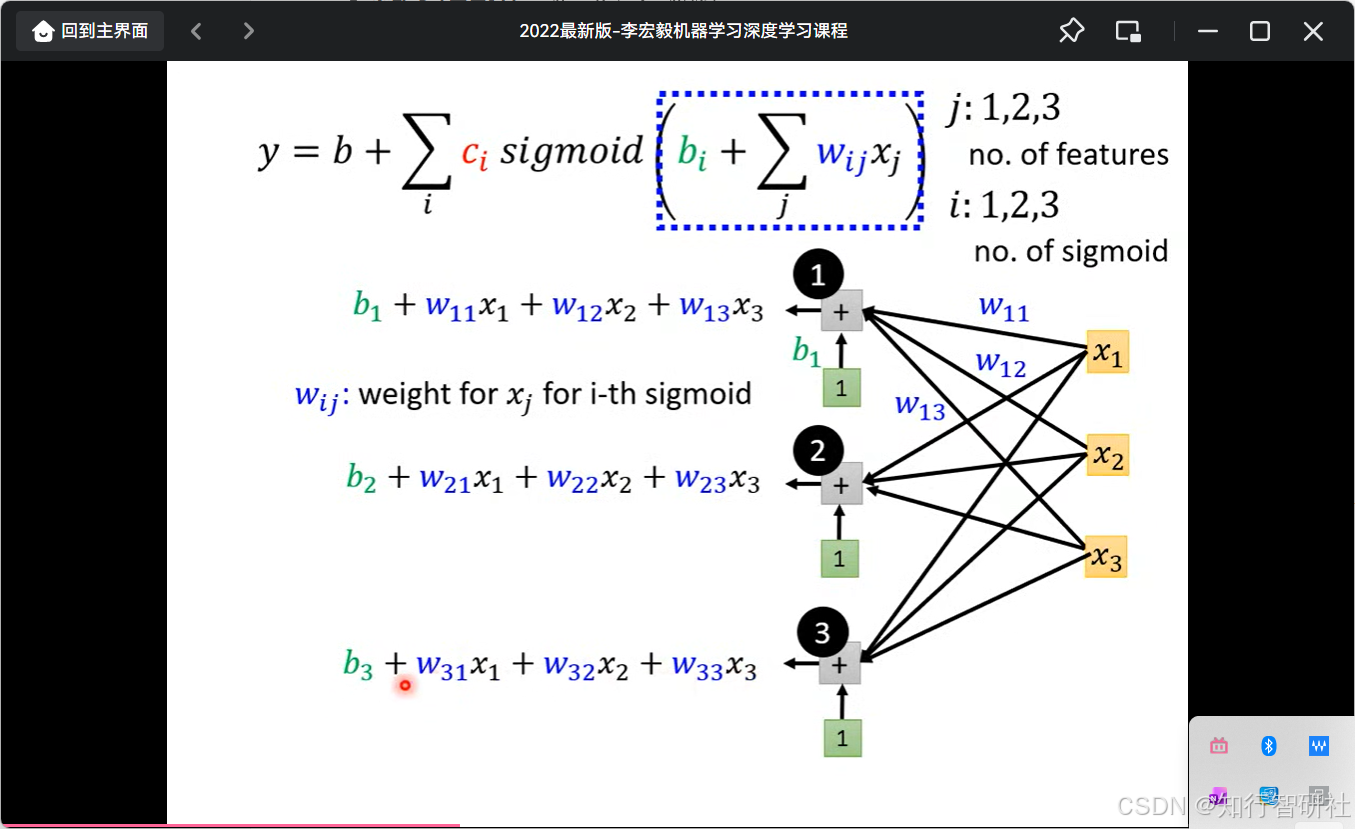
这张图片展示了一个**简单的神经网络模型(单隐层前馈神经网络)**的数学公式和对应的网络结构示意图,以下是详细分析:
1. 数学公式部分
公式为: y=b+∑ici⋅sigmoid(bi+∑jwijxj) y = b + \sum_{i} c_i \cdot \text{sigmoid}\left( b_i + \sum_{j} w_{ij} x_j \right) y=b+i∑ci⋅sigmoid(bi+j∑wijxj)
- 符号含义 :
- xjx_jxj:输入特征(图中有 x_1, x_2, x_3 ,共3个特征,对应 j:1,2,3 )。
- w_{ij} :权重参数,表示第 i 个 Sigmoid 神经元对第 j 个输入特征 xjx_jxj 的权重。
- b_i :第 i 个 Sigmoid 神经元的偏置项(类似线性模型的截距)。
- \\text{sigmoid}(\\cdot) :激活函数(Sigmoid 函数,将输入压缩到 (0,1) 区间,引入非线性)。
- c_i :第 i 个 Sigmoid 神经元输出的权重(用于加权求和)。
- bbb:最终输出的全局偏置项。
- 求和符号 \\sum_{i} :表示对所有 Sigmoid 神经元(图中 i:1,2,3 ,共3个)的输出进行加权求和。
2. 网络结构示意图(右侧)
图中展示了一个单隐层神经网络的结构,包含:
- 输入层:3个输入节点 x_1, x_2, x_3 (对应3个特征)。
- 隐层:3个 Sigmoid 神经元(标记为1、2、3),每个神经元接收所有输入特征的加权求和 + 偏置,再通过 Sigmoid 激活。
- 输出层 :最终输出 y ,由隐层3个神经元的输出加权求和 + 全局偏置 bbb 得到。
3. 隐层神经元的计算细节(左侧公式展开)
每个隐层神经元的输入(激活前的线性组合)为:
- 第1个神经元: b_1 + w_{11}x_1 + w_{12}x_2 + w_{13}x_3
- 第2个神经元: b_2 + w_{21}x_1 + w_{22}x_2 + w_{23}x_3
- 第3个神经元: b_3 + w_{31}x_1 + w_{32}x_2 + w_{33}x_3
这些线性组合经过 Sigmoid 激活后,再乘以权重 c_i ,最后求和并加上全局偏置 bbb,得到最终输出 y 。
4. 模型本质
这是一个浅层神经网络(单隐层),通过 Sigmoid 激活函数引入非线性,能够拟合比线性模型更复杂的函数关系。结构上属于"全连接"(每个隐层神经元与所有输入特征连接)。
简单来说,这个模型通过"输入特征加权求和→Sigmoid激活→加权求和+偏置"的流程,实现对输入特征的非线性组合,从而完成预测任务(如回归或分类,取决于输出层的处理)。
5.线性代数表示

6.sigmoid
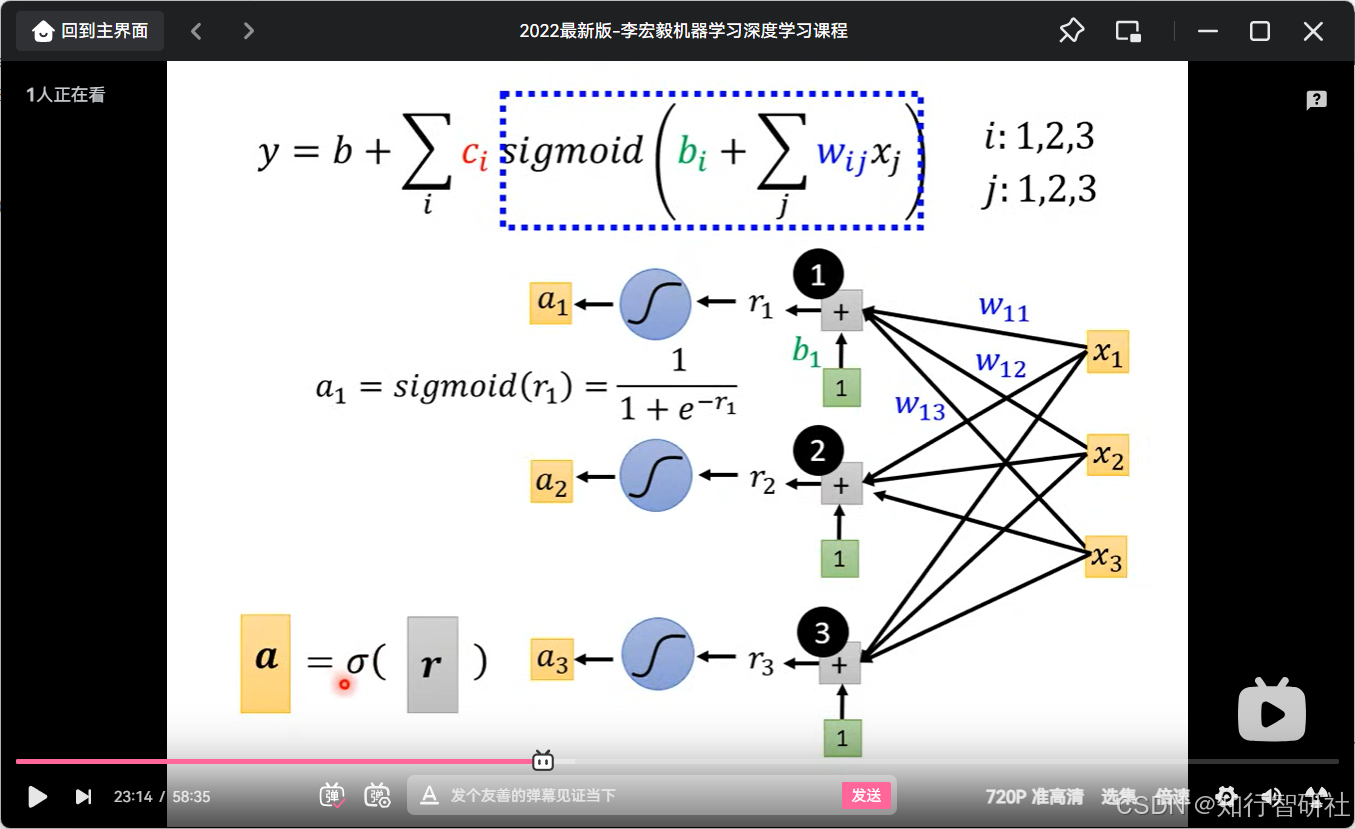
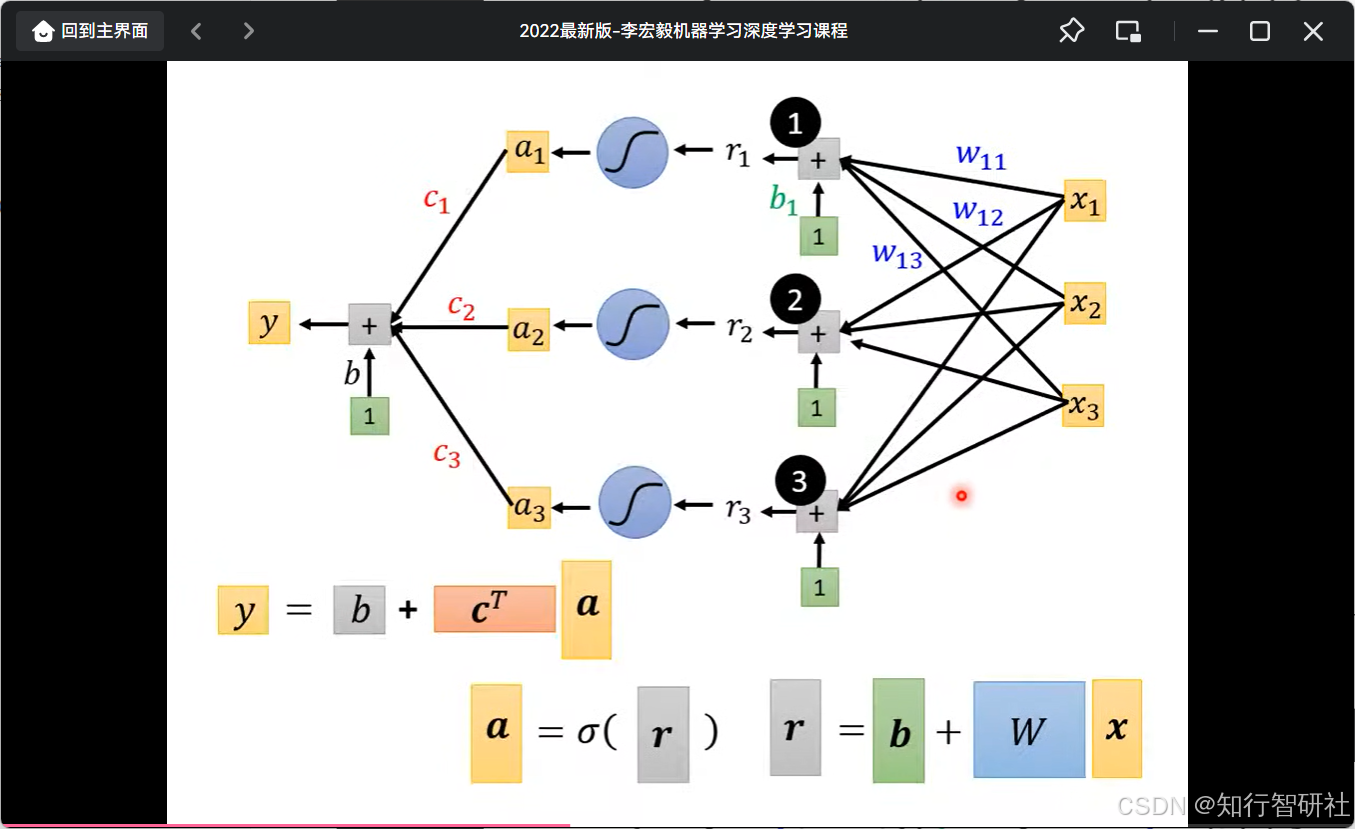
7 整体线性代数表示
二 define loss from training data

2.1 损失函数

这张图片展示了机器学习中**损失函数(Loss Function)**的核心概念,它解释了模型如何通过比较预测值与真实值来评估自身性能,并以此指导参数优化。
📌 核心概念解析
图片顶部的两行文字点明了损失函数的本质:
- 损失是参数的函数 :记作 L(θ)L(\theta)L(θ),其中 θ\thetaθ 代表模型的所有可学习参数(如权重 WWW、偏置 bbb、输出层权重 cTc^TcT)。
- 损失衡量参数的好坏:损失值越小,代表当前这组参数让模型的预测越接近真实情况,模型表现越好。
🧩 图中流程详解
图片中央的图示清晰地展示了从输入到计算损失的完整流程:
- 输入与参数 :
- 特征(feature) :蓝色方块 xxx,代表输入数据。
- 参数(parameters) :灰色 bbb、橙色 cTc^TcT、黄色 WWW、绿色 bbb。这些是模型需要学习的"可调旋钮"。
- "Given a set of values":虚线箭头表明,当给定一组具体的参数值时,模型就能进行计算。
- 前向传播与预测 :
- 模型根据公式 y=b+cTσ(b+Wx)y = b + c^T \sigma(b + Wx)y=b+cTσ(b+Wx) 计算出一个预测值 y 。
- 这个公式与前两张图展示的神经网络结构完全对应:输入 xxx 经过隐层(WWW 和 bbb)和激活函数 σ\sigmaσ,再经过输出层(cTc^TcT 和 bbb)得到最终输出 y 。
- 误差计算 :
- 将模型的预测值 y 与数据的真实标签(label) y^\hat{y}y^ 进行比较。
- 两者之间的差异就是误差(error) ,记作 eee。这个误差是损失函数的基础。
- 损失函数定义 :
- 图片底部的公式 L=1N∑nenL = \frac{1}{N} \sum_{n} e_nL=N1∑nen 定义了整体损失。
- 它表示对所有 NNN 个训练样本的误差 ene_nen 求平均。这个平均误差就是我们要最小化的目标。
🎯 总结与意义
这张图的核心思想是:机器学习的目标就是找到一组最优的参数(W,b,cTW, b, c^TW,b,cT),使得损失函数 L(θ)L(\theta)L(θ) 的值最小。
- 训练过程:通过不断调整参数,计算新的损失,再根据损失的大小和方向(梯度)来更新参数,这个过程就是"学习"。
- 评估标准:损失函数是衡量模型在当前参数下表现好坏的"标尺"。
简单来说,这张图揭示了神经网络"学习"的本质:通过计算预测与真实的差距(损失),并反向调整内部参数,让这个差距越来越小。
2.2 模型优化

这张图片展示了机器学习中**模型优化(Optimization)的核心数学原理,具体讲解了如何使用梯度下降法(Gradient Descent)**来寻找最优参数。
以下是详细分析:
1. 优化的目标
图片左上角的公式定义了整个优化过程的目标: θ∗=argminθL \theta^* = \arg \min_{\theta} L θ∗=argθminL
- 含义 :我们要找到一组参数 θ∗\theta^*θ∗,使得损失函数 LLL(Loss)的值最小。
- θ\thetaθ :代表模型的所有参数集合(如权重和偏置)。右上角的矩阵图示表明 θ\thetaθ 是一个向量,包含 θ1,θ2,θ3...\theta_1, \theta_2, \theta_3 \dotsθ1,θ2,θ3... 等多个具体的参数。
2. 优化步骤(梯度下降法)
图片下半部分详细拆解了梯度下降的第一步迭代过程:
第一步:随机初始化
- 文字说明 :
(Randomly) Pick initial values θ⁰ - 含义 :在开始训练前,先随机给参数赋一组初始值,记为 θ0\theta^0θ0(θ\thetaθ 上标 0 代表第 0 次迭代)。
第二步:计算梯度
- 公式 : g=∇L(θ0) g = \nabla L(\theta^0) g=∇L(θ0)
- 矩阵展开 :左侧的长矩阵展示了梯度向量 ggg 的具体构成。它是损失函数 LLL 对每一个参数 θi\theta_iθi 的偏导数(Partial Derivative)组成的向量。 g=∂L∂θ1∣∗θ=θ0 ∂L∂θ2∣∗θ=θ0 ⋮ g = \begin{bmatrix} \frac{\partial L}{\partial \theta_1} |*{\theta=\theta^0} \ \frac{\partial L}{\partial \theta_2} |*{\theta=\theta^0} \ \vdots \end{bmatrix} g=∂θ1∂L∣∗θ=θ0 ∂θ2∂L∣∗θ=θ0 ⋮
- 物理意义:梯度指向了损失函数增长最快的方向(上坡方向)。
第三步:更新参数
- 公式 : θ1←θ0−ηg \theta^1 \leftarrow \theta^0 - \eta g θ1←θ0−ηg
- 详细展开 :中间的公式展示了向量形式的更新,右侧则进一步展开了每个分量的计算: θ11 θ21 ⋮←θ10 θ20 ⋮−η∂L∂θ1∣∗θ=θ0 η∂L∂θ2∣∗θ=θ0 ⋮ \begin{bmatrix} \theta_1^1 \ \theta_2^1 \ \vdots \end{bmatrix} \leftarrow \begin{bmatrix} \theta_1^0 \ \theta_2^0 \ \vdots \end{bmatrix} - \begin{bmatrix} \eta \frac{\partial L}{\partial \theta_1} |*{\theta=\theta^0} \ \eta \frac{\partial L}{\partial \theta_2} |*{\theta=\theta^0} \ \vdots \end{bmatrix} θ11 θ21 ⋮←θ10 θ20 ⋮−η∂θ1∂L∣∗θ=θ0 η∂θ2∂L∣∗θ=θ0 ⋮
- 关键符号 :
- η\etaη (Eta) :学习率(Learning Rate)。它控制了我们沿着梯度反方向(下坡方向)迈出的步子有多大。
- 减号(-) :因为梯度指向的是函数增长最快的方向,为了让 Loss 变小,我们需要向梯度的反方向移动。
- θ1\theta^1θ1:更新后的新参数,用于下一次迭代。
总结
这张图完整地描述了神经网络训练中**"一次迭代"**的数学逻辑:先随机猜一个参数位置,算出当前位置的坡度(梯度),然后沿着坡度最陡的反方向走一步(由学习率控制步长),从而让模型的误差(Loss)逐渐降低。
2.3 模型优化迭代

这张图片展示了机器学习中**模型优化(Optimization)的核心过程,具体讲解了如何使用梯度下降法(Gradient Descent)**通过迭代来寻找最优参数。
以下是详细分析:
1. 优化的目标
图片最上方的公式定义了整个过程的终极目标: θ∗=argminθL \theta^* = \arg \min_{\theta} L θ∗=argθminL
- 含义 :我们的目的是找到一组最优的参数 θ∗\theta^*θ∗,使得损失函数 LLL(Loss)的值最小。
2. 迭代更新过程
图片中间部分通过三个步骤展示了参数是如何一步步更新的,这是一个典型的**迭代(Iterative)**过程:
第 0 步:初始化
- 操作 :
(Randomly) Pick initial values θ⁰ - 解释 :在训练开始前,随机初始化一组参数值,记为 θ0\theta^0θ0。
第 1 次更新
- 计算梯度 :
Compute gradient g = ∇L(θ⁰)- 计算当前参数 θ0\theta^0θ0 处的梯度 ggg。
- 更新参数 :
θ¹ ← θ⁰ - ηg- 利用梯度 ggg 和学习率 η\etaη 更新参数,得到新的参数 θ1\theta^1θ1。
- 注意这里的减号,因为梯度指向的是函数增长最快的方向,我们要减去它才能往函数减小的方向走。
第 2 次更新
- 计算梯度 :
Compute gradient g = ∇L(θ¹)- 基于新的参数 θ1\theta^1θ1,再次计算梯度。
- 更新参数 :
θ² ← θ¹ - ηg- 再次更新得到 θ2\theta^2θ2。
第 3 次更新
- 计算梯度 :
Compute gradient g = ∇L(θ²) - 更新参数 :
θ³ ← θ² - ηg- 继续更新得到 θ3\theta^3θ3。
3. 核心要素总结
- θ\thetaθ (Theta):代表模型的参数(如神经网络的权重和偏置)。
- LLL (Loss):损失函数,用来评估模型预测的好坏。
- ggg (Gradient):梯度,即损失函数对参数的偏导数,指示了"上坡"的方向。
- η\etaη (Eta):学习率(Learning Rate),控制每次更新的步长大小。
这张图直观地演示了模型是如何通过**"计算梯度 -> 更新参数 -> 再计算梯度 -> 再更新"**的循环,一步步逼近最优解的。
2.4 随机梯度下降

这张幻灯片主要讲解了**随机梯度下降(Stochastic Gradient Descent, SGD)**以及训练过程中的关键术语:Batch(批次)**和**Epoch(轮次)。
这是对之前"标准梯度下降"的优化版本,主要解决了数据量过大时计算太慢的问题。
以下是详细分析:
1. 核心思想的变化
之前的梯度下降是计算所有数据的总误差,然后更新一次参数。而这张图展示的是**小批量(Mini-batch)**的做法:
- 右侧图示 :
- 整个数据集的总量为 NNN。
- 将 NNN 个数据切分成很多小块,每一块称为一个 Batch(批次)。
- 一个 Batch 中包含的数据量通常用 BBB 表示。
2. 迭代更新流程(左侧公式)
这个过程展示了参数是如何利用不同的 Batch 进行更新的:
- 第 1 步(利用第 1 个 Batch) :
Compute gradient g = ∇L¹(θ⁰):计算梯度时,不再是基于所有数据,而是只基于第 1 个 Batch 的数据来计算损失 L1L^1L1 和梯度 ggg。θ¹ ← θ⁰ - ηg:利用这个梯度更新参数,得到 θ1\theta^1θ1。- 优势:计算速度非常快,因为只看了一小部分数据。
- 第 2 步(利用第 2 个 Batch) :
Compute gradient g = ∇L²(θ¹):接着,利用第 2 个 Batch 的数据计算损失 L2L^2L2 和梯度。θ² ← θ¹ - ηg:再次更新参数。
- 第 3 步(利用第 3 个 Batch) :
- 同理,利用第 3 个 Batch 的数据继续更新参数得到 θ3\theta^3θ3。
3. 关键术语定义
图片底部给出了一个非常重要的定义:
1 epoch = see all the batches once
- Epoch(轮次) :当模型把所有 的 Batch(也就是整个数据集 NNN)都看了一遍,就称为完成了 1 个 Epoch。
- 含义:这意味着模型已经利用了所有的训练数据更新了一轮参数。通常训练一个模型需要跑很多个 Epoch(例如 100 个 Epoch),即把所有数据反复看好几遍。
总结
这张图的核心在于解释训练策略:
- 数据分块:把大数据集切成小块(Batch)。
- 频繁更新:每看一个小块就更新一次参数,而不是看完所有数据才更新。
- Epoch 概念:看完了所有小块才算跑完一圈(1 Epoch)。
2.5 SIGMOD--》Relu

这张图片展示了深度学习中激活函数从 Sigmoid 向 ReLU (Rectified Linear Unit) 演变的过程,并解释了 ReLU 的数学表示方法。
以下是详细分析:
1. 核心主题:Sigmoid → ReLU
标题表明这是一个关于激活函数选择的讨论。在早期的神经网络(如前几张图所示)中,常用 Sigmoid 函数作为激活函数。但现代深度学习中,ReLU 因其计算简单和缓解梯度消失问题的特性,已逐渐取代 Sigmoid 成为默认选择。
2. ReLU 函数的图形表示(上图)
- 蓝色曲线 :展示了 ReLU 函数的典型形状。
- 当输入 x1x_1x1 小于某个阈值(通常是0,或者是 −b/w-b/w−b/w)时,输出恒为 0(水平线)。
- 当输入 x1x_1x1 大于该阈值时,输出随输入线性增加(斜线)。
- "How to represent this function?":提出问题,如何用数学公式表达这种"一半是0,一半是直线"的函数?
3. ReLU 的数学定义(下图)
图片下半部分给出了 ReLU 的通用数学公式: y=c⋅max(0,b+wx1) y = c \cdot \max(0, b + w x_1) y=c⋅max(0,b+wx1)
- max(0,... )\max(0, \dots)max(0,...) :这是 ReLU 的核心。它表示取括号内两个数(0 和 b+wx1b + w x_1b+wx1)中的较大值。
- 如果 b+wx1<0b + w x_1 < 0b+wx1<0,则输出 0。
- 如果 b+wx1>0b + w x_1 > 0b+wx1>0,则输出 b+wx1b + w x_1b+wx1。
- 参数含义 :
- www (weight):控制斜线的斜率。
- bbb (bias):控制转折点的横坐标位置。
- ccc (coefficient):控制最终输出的缩放比例。
4. 变体与组合(最下方的图)
图片最下方还展示了另一个公式: y=c′⋅max(0,b′+w′x1) y = c' \cdot \max(0, b' + w' x_1) y=c′⋅max(0,b′+w′x1)
- 这表示 ReLU 函数可以通过调整参数 c′,b′,w′c', b', w'c′,b′,w′ 变成不同的形状(例如斜率向下,或者转折点不同)。
- 结合上方的图,这暗示了通过组合多个 ReLU 函数(或者使用不同的参数配置),可以拟合出非常复杂的非线性曲线。
总结
这张图的核心在于介绍 ReLU 激活函数 。它通过图形直观展示了 ReLU 的"折线"特性,并给出了其数学定义 y=c⋅max(0,b+wx)y = c \cdot \max(0, b + wx)y=c⋅max(0,b+wx),强调了它是如何通过简单的线性组合和取最大值操作来构建非线性模型的。
2.6 sigmoid VS ReLU

这张图片对比了神经网络中两种不同的激活函数:Sigmoid 和 ReLU,并以一个开放性问题结尾,引发对两者优劣的思考。
核心公式对比
图片展示了两个结构相似但激活函数不同的神经网络输出公式:
Sigmoid 版本(上式)
y=b+∑ici⋅sigmoid(bi+∑jwijxj) y = b + \sum_{i} c_i \cdot \text{sigmoid}\left(b_i + \sum_{j} w_{ij} x_j\right) y=b+i∑ci⋅sigmoid(bi+j∑wijxj)
这是一个单隐层神经网络的输出表达式,其中 sigmoid 函数将输入映射到 (0, 1) 区间,形成平滑的S型曲线。
ReLU 版本(下式)
y=b+∑ici⋅max(0,bi+∑jwijxj) y = b + \sum_{i} c_i \cdot \max\left(0, b_i + \sum_{j} w_{ij} x_j\right) y=b+i∑ci⋅max(0,bi+j∑wijxj)
该公式将激活函数替换为 ReLU,即 max(0, x)。当输入大于0时,输出原值;否则输出0,形成一个分段线性函数。
关键差异与优势
- 计算效率 :ReLU 的
max(0, x)运算比 Sigmoid 的指数运算简单得多,计算速度更快。 - 梯度问题:Sigmoid 在输入值很大或很小时,梯度接近于0,容易导致深层网络训练困难(梯度消失)。ReLU 在正区间梯度恒为1,有效缓解了这一问题。
- 稀疏激活:ReLU 会将一部分神经元输出置为0,使得网络具有稀疏性,有助于防止过拟合。
结论
这张图通过公式对比,清晰地展示了神经网络中激活函数的演进趋势:用更简单、更高效的 ReLU 替代复杂的 Sigmoid,以适应现代深度学习对大规模、深层次网络的需求。
2.7 深度神经网络矩阵算法
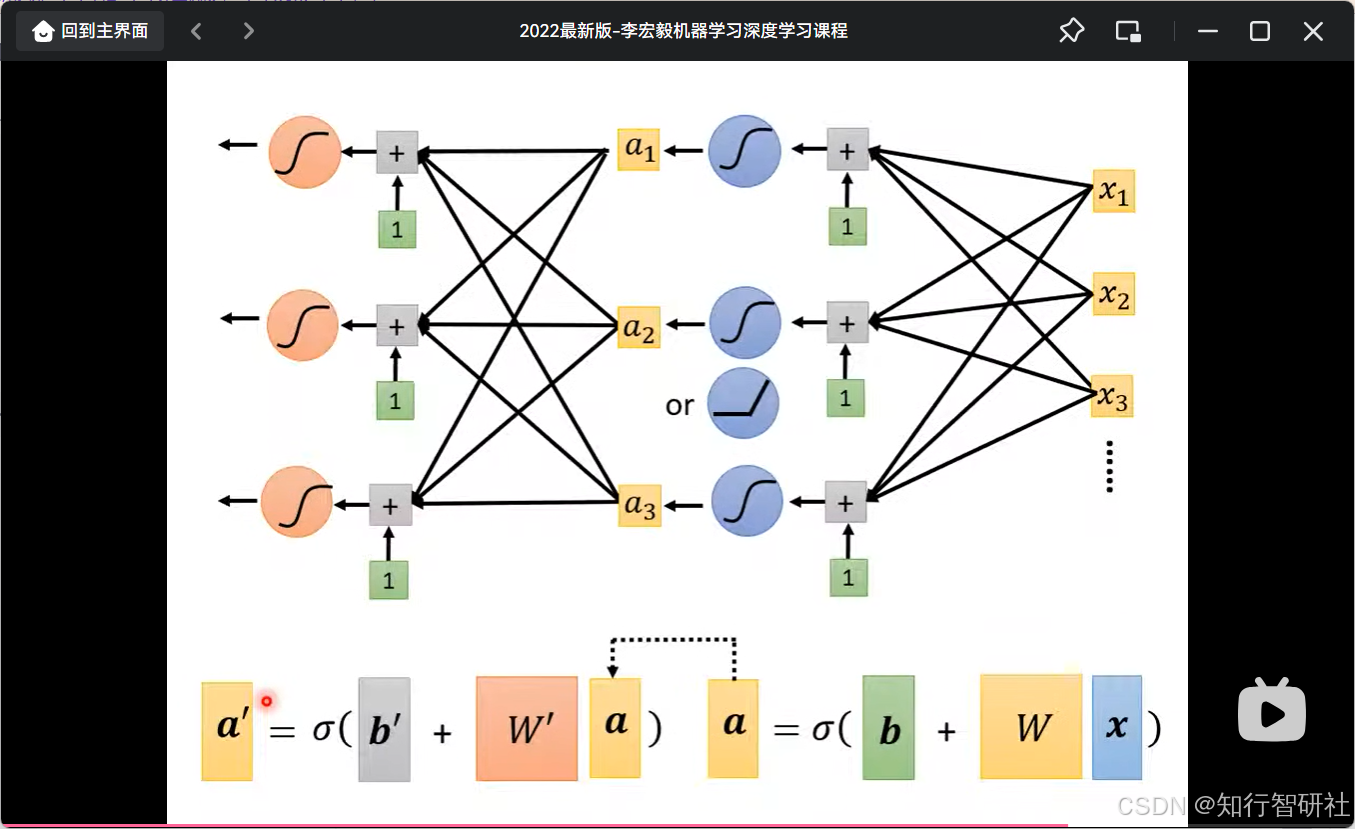
这张图片展示了**深度神经网络(Deep Neural Network)**的矩阵运算表示方法,旨在说明如何通过矩阵乘法来高效地计算多层神经网络的输出,而不是逐个神经元进行计算。
以下是对图片内容的详细分析:
1. 神经网络结构图(上半部分)
这部分展示了一个典型的多层感知机(MLP)结构,包含输入层、隐藏层和输出层。
- 右侧(输入层 -> 隐藏层) :
- 输入 xxx :输入向量包含 x1,x2,x3,...x_1, x_2, x_3, \dotsx1,x2,x3,...。
- 加权求和(灰色方块 "+") :每个神经元接收所有输入 xxx,乘以对应的权重(连线),并加上偏置(绿色的 "1" 方块)。
- 激活函数(蓝色圆圈) :求和后的结果通过激活函数。图中展示了两种选择:
- Sigmoid(S形曲线符号):传统的激活函数。
- ReLU(折线符号):标注了 "or",表示可以用 ReLU 替代 Sigmoid。
- 隐藏层输出 aaa :经过激活函数后,输出 a1,a2,a3a_1, a_2, a_3a1,a2,a3。
- 左侧(隐藏层 -> 输出层) :
- 结构与前一层类似。隐藏层的输出 aaa 作为下一层的输入。
- 再次进行加权求和(灰色方块)和激活函数处理(橙色圆圈,这里统一画成了 Sigmoid 形状,但原理通用)。
- 最终输出向左箭头指出的结果。
2. 矩阵化表示(下半部分)
这部分是将上述繁琐的神经元连接图转化为简洁的矩阵运算公式,这是深度学习框架(如 PyTorch, TensorFlow)底层的核心逻辑。
第一个公式(对应输入层到隐藏层)
a=σ(b+Wx) a = \sigma(b + Wx) a=σ(b+Wx)
- xxx(蓝色块):输入向量。
- WWW(黄色块):权重矩阵。它包含了所有从输入层到隐藏层的连线权重。
- bbb(绿色块):偏置向量。对应图中那些绿色的 "1"。
- σ\sigmaσ:激活函数(Sigmoid 或 ReLU),作用于向量中的每个元素。
- aaa (黄色块):隐藏层的输出向量(即图中的 a1,a2,a3a_1, a_2, a_3a1,a2,a3)。
第二个公式(对应隐藏层到输出层)
a′=σ(b′+W′a) a' = \sigma(b' + W'a) a′=σ(b′+W′a)
- aaa:上一层的输出,作为这一层的输入。
- W′W'W′(橙色块):第二层的权重矩阵。
- b′b'b′(灰色块):第二层的偏置向量。
- a′a'a′:最终的输出向量。
3. 核心思想总结
这张图的核心目的是展示**向量化(Vectorization)**的威力:
- 并行计算 :不需要写循环去计算每一个神经元的输出(a1,a2,a3a_1, a_2, a_3a1,a2,a3),而是直接通过矩阵乘法 WxWxWx 一次性算出所有神经元的加权和。
- 代码简洁 :无论网络层有多少个神经元,都可以用同一个简单的公式 a=σ(Wx+b)a = \sigma(Wx + b)a=σ(Wx+b) 来表示一层的前向传播。
- 灵活性:图中的 "or" 符号和不同颜色的激活函数暗示了激活函数是可以灵活替换的模块(Sigmoid vs ReLU),而矩阵运算的结构保持不变。