本文面向:已读完第07章(上)基础篇,掌握 State/Node/Edge 概念,想进一步使用 LangGraph 构建生产级应用的开发者。
前期回顾
零、本章概述
上一篇解决了"LangGraph 是什么、为什么用"的问题。本篇解决"如何在关键节点暂停等人工确认 "和"如何让多个 AI 角色分工协作"这两个问题。
本章涉及的代码文件:
lessons/07_langgraph/04_checkpoint_hitl.py← 检查点 + 可视化 + 人工介入lessons/07_langgraph/03_multi_agent_graph.py← 多 Agent 协作
一、检查点(Checkpointer)------ 给工作流装上"保存进度"功能
1.1 什么是检查点?
检查点类似于游戏的"存档"功能:每次图执行到一个节点后,自动保存当前的完整状态。这样可以:
- 断点续传:从上次暂停的地方继续执行
- 状态回溯:查看历史某个时间点的状态
- Human-in-the-Loop(下一节详解):在暂停点让人工修改状态
1.2 MemorySaver ------ 内存中的检查点
python
from langgraph.checkpoint.memory import MemorySaver
# ── 创建内存检查点(适合开发/测试)──
memory = MemorySaver()
# ── 编译图时传入 checkpointer ──
graph = builder.compile(checkpointer=memory)
# ── 运行时必须提供 thread_id(用于标识不同的工作流实例)──
config = {"configurable": {"thread_id": "task_001"}}
result = graph.invoke(initial_state, config=config)thread_id 的作用:
ini
thread_id = "user_alice" → Alice 的独立对话历史(存档槽位1)
thread_id = "user_bob" → Bob 的独立对话历史(存档槽位2)
thread_id = "report_001" → 报告001的工作流(存档槽位3)
每个 thread_id 有自己独立的状态存档,互不影响1.3 生产环境的持久化 Checkpointer
MemorySaver 适合开发阶段,重启后数据丢失。生产环境用:
| Checkpointer | 安装 | 特点 |
|---|---|---|
MemorySaver |
内置 | 内存,重启丢失,适合开发/测试 |
SqliteSaver |
langgraph-checkpoint-sqlite |
SQLite 文件,单机持久化 |
PostgresSaver |
langgraph-checkpoint-postgres |
PostgreSQL,多实例共享 |
python
# 生产环境示例(SQLite)
from langgraph.checkpoint.sqlite import SqliteSaver
with SqliteSaver.from_conn_string("./checkpoints.db") as checkpointer:
graph = builder.compile(checkpointer=checkpointer)
result = graph.invoke(state, config={"configurable": {"thread_id": "task_001"}})二、Human-in-the-Loop ------ 在关键节点等待人工确认
2.1 为什么需要人工介入?
某些 AI 任务不能完全自动化,需要人工在关键节点确认:
| 场景 | 为什么需要人工 |
|---|---|
| 内容发布 | AI 草稿需要编辑审核后才能发布 |
| 资金操作 | 超过阈值的支出需要人工批准 |
| 敏感数据删除 | 不可逆操作必须人工确认 |
| 代码部署 | 生产环境部署需要技术负责人审批 |
2.2 interrupt_before ------ 在节点执行前暂停
python
# ── 编译时指定哪些节点前需要暂停 ──
graph = builder.compile(
checkpointer=memory,
interrupt_before=["review_node"], # 在 review_node 执行前暂停
# interrupt_after=["gen_node"], # 也可以在节点执行后暂停
)完整工作流示意: 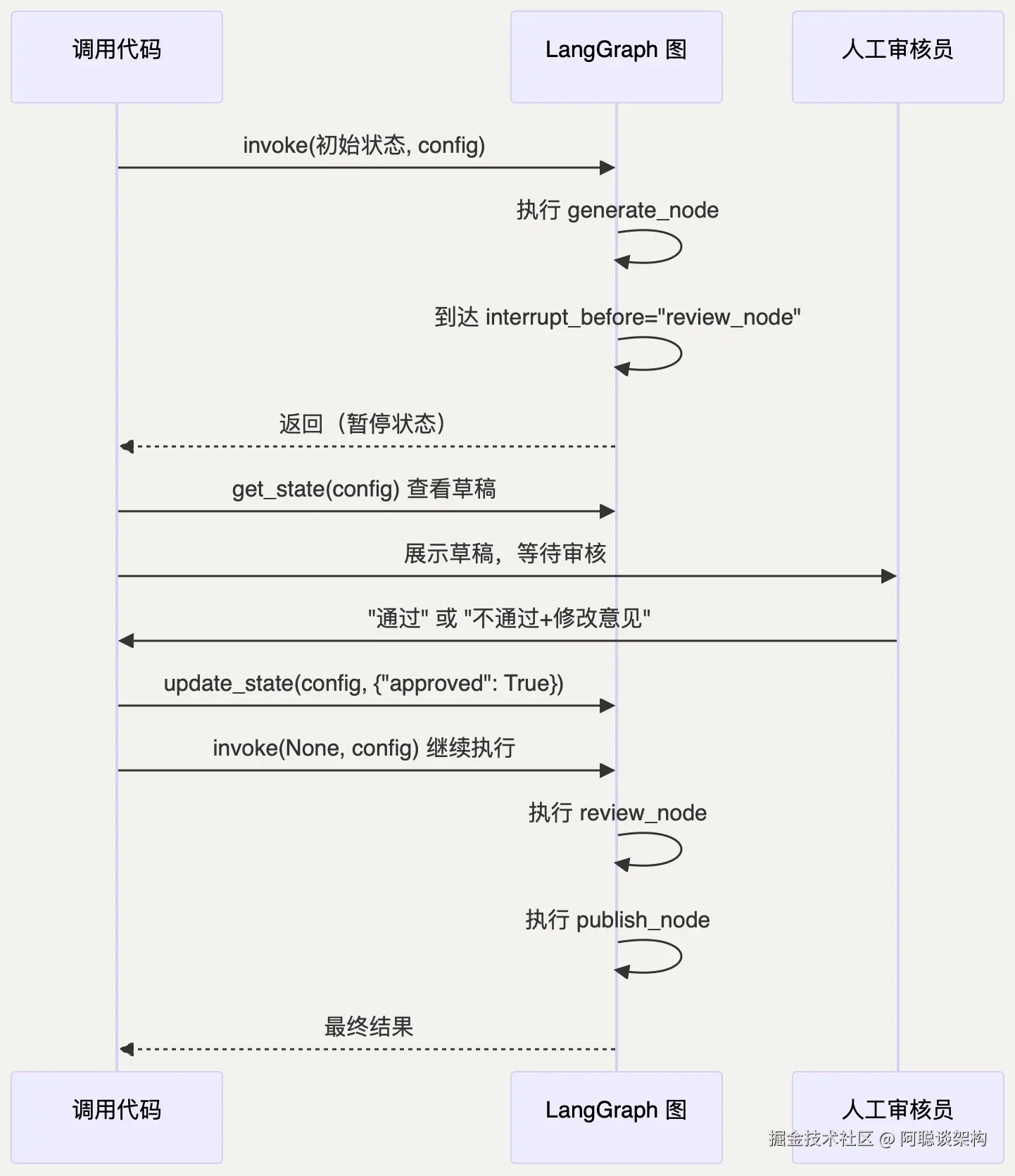
2.3 完整代码示例
代码文件:lessons/07_langgraph/04_checkpoint_hitl.py
python
from typing import TypedDict, Annotated
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
from langgraph.checkpoint.memory import MemorySaver
from langchain_core.messages import HumanMessage, AIMessage
# ── 1. 定义状态 ──
class ReviewState(TypedDict):
topic: str # 写作主题
draft: str # AI 生成的草稿
feedback: str # 人工审核意见(interrupt 后由人工填写)
approved: bool # 是否通过审核
final: str # 最终发布内容
messages: Annotated[list, add_messages]
# ── 2. 定义节点 ──
def generate_node(state: ReviewState) -> dict:
"""AI 生成草稿。"""
draft = llm.invoke(f"请写一篇关于'{state['topic']}'的300字短文").content
return {"draft": draft}
def review_check_node(state: ReviewState) -> dict:
"""
审核结果检查节点(在 interrupt_before 后执行)。
此时 state["approved"] 已由人工通过 update_state() 填写。
"""
if state.get("approved"):
print("✅ 人工已批准,准备发布")
else:
print(f"❌ 人工拒绝,理由:{state.get('feedback', '无')}")
return {} # 不需要修改状态,只检查
def publish_node(state: ReviewState) -> dict:
"""发布节点。"""
return {"final": state["draft"]}
# ── 3. 路由函数 ──
def route_after_review(state: ReviewState) -> str:
return "publish" if state.get("approved") else END
# ── 4. 构建图 ──
builder = StateGraph(ReviewState)
builder.add_node("generate", generate_node)
builder.add_node("review_check", review_check_node)
builder.add_node("publish", publish_node)
builder.add_edge(START, "generate")
builder.add_edge("generate", "review_check")
builder.add_conditional_edges("review_check", route_after_review, {"publish": "publish", END: END})
builder.add_edge("publish", END)
# ── 5. 编译:启用检查点 + 人工介入 ──
memory = MemorySaver()
graph = builder.compile(
checkpointer=memory,
interrupt_before=["review_check"], # 在 review_check 前暂停
)
# ── 6. 运行流程 ──
config = {"configurable": {"thread_id": "article_001"}}
# 第一次调用:执行到 generate_node 后暂停(因为下一个是 review_check)
print("第1步:AI 生成草稿...")
graph.invoke({
"topic": "人工智能对医疗的影响",
"draft": "", "feedback": "", "approved": False, "final": "",
"messages": [HumanMessage(content="请写文章")],
}, config=config)
# 查看当前状态(图已暂停)
current_state = graph.get_state(config)
draft = current_state.values["draft"]
print(f"\n草稿:{draft[:200]}")
print(f"下一步将执行:{current_state.next}") # ('review_check',)
# 人工审核:模拟通过
print("\n第2步:人工审核...")
graph.update_state(config, {"approved": True, "feedback": "很好,可以发布"})
# 继续执行(传 None 表示不改变起始状态,从暂停点继续)
print("\n第3步:继续执行...")
final = graph.invoke(None, config=config)
print(f"发布内容:{final['final'][:100]}")运行方式:
bash
python lessons/07_langgraph/04_checkpoint_hitl.py2.4 多轮对话记忆(检查点的另一个用途)
检查点不只用于 Human-in-the-Loop,也是实现多轮对话记忆的基础:
python
# 同一个 thread_id 的多次调用会自动积累消息历史
config = {"configurable": {"thread_id": "user_alice"}}
# 第1轮:自我介绍
r1 = graph.invoke({"messages": [HumanMessage(content="我叫Alice,我喜欢编程")]}, config=config)
# 第2轮:基于第1轮记忆提问(无需重传历史,checkpointer 自动恢复)
r2 = graph.invoke({"messages": [HumanMessage(content="你还记得我的名字吗?")]}, config=config)
# AI 回答:当然记得,你叫Alice!
# 不同 thread_id = 独立的对话,没有跨对话污染
config_bob = {"configurable": {"thread_id": "user_bob"}}
r3 = graph.invoke({"messages": [HumanMessage(content="你知道刚才那个人叫什么吗?")]}, config=config_bob)
# AI 回答:对不起,我不知道(Bob 的对话看不到 Alice 的历史)三、多 Agent 协作 ------ 分工协作的 AI 团队
3.1 为什么要多 Agent 协作?
arduino
单个 Agent 问题(扮演多角色时):
同一个 LLM 实例同时扮演"研究员"+"写作者"+"审核者"
→ 角色混乱,行为不稳定
→ 提示词复杂,维护困难
多 Agent 方案:
每个 Agent 专注一个角色,有独立的系统提示
→ 行为更稳定,更容易调试
→ 各 Agent 可以有不同的工具和权限3.2 典型的多 Agent 模式
协调器(Supervisor)模式:
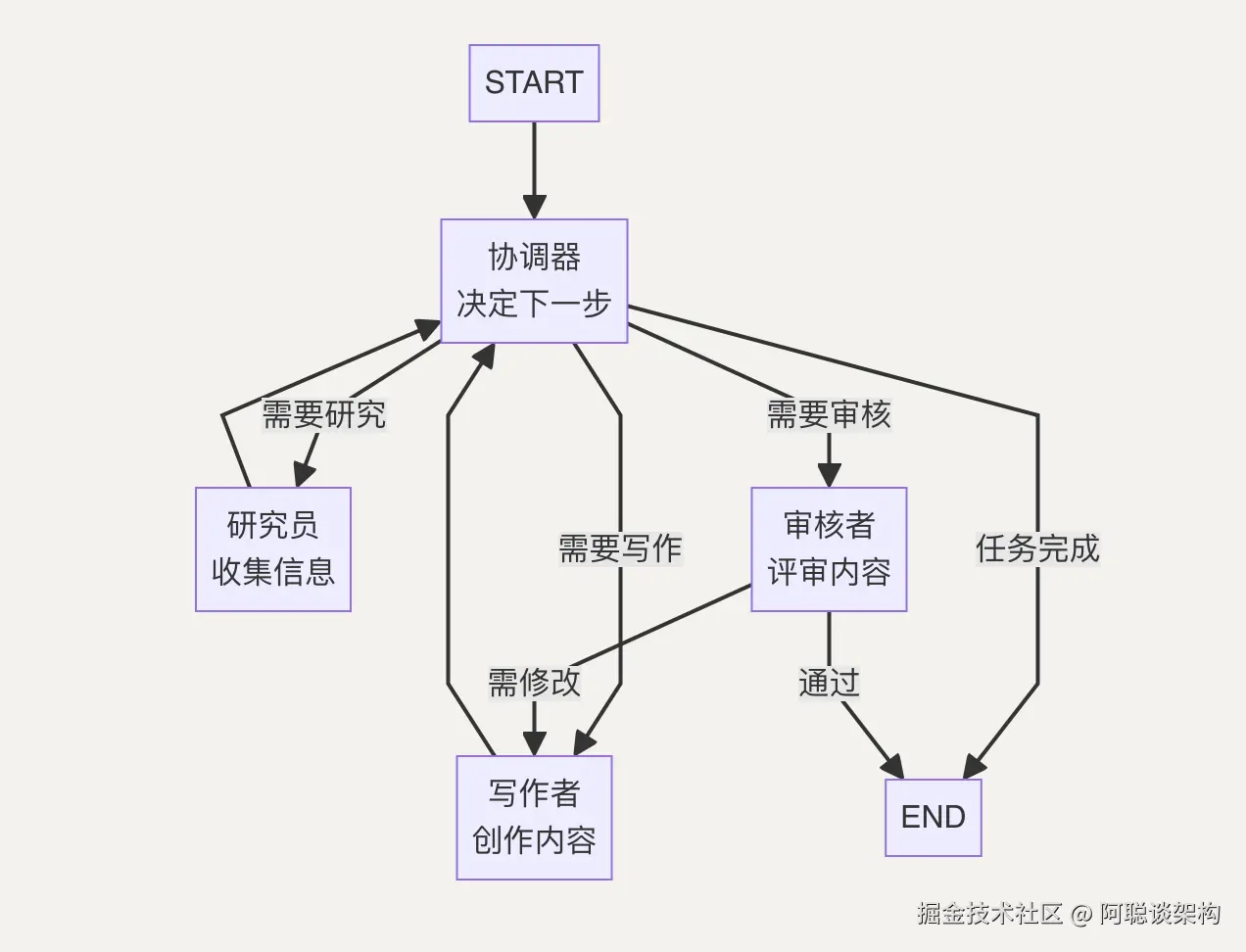
特点:
- 协调器(Coordinator)= 大脑,负责决策
- 各专业 Agent = 执行者,只负责自己的专长领域
- 通过共享 State 传递信息,不需要 Agent 之间直接"说话"
3.3 多 Agent 状态设计
python
from typing import TypedDict, Annotated, Optional
from langgraph.graph.message import add_messages
class MultiAgentState(TypedDict):
task: str # 原始任务(所有 Agent 都可以读)
research_notes: str # 研究员写入,写作者读取
draft_content: str # 写作者写入,审核者读取
final_content: str # 审核通过后的最终内容
feedback: str # 审核者的反馈意见
current_agent: str # 协调器写入:下一步谁来处理
iteration: int # 迭代次数(防止无限循环)
messages: Annotated[list, add_messages]状态设计原则:
- 每个 Agent 只写自己负责的字段
- 通过字段名称区分谁的输出
- 用
iteration防止无限循环
3.4 完整代码讲解
代码文件:lessons/07_langgraph/03_multi_agent_graph.py
python
# ── 定义协调器(核心路由逻辑)──
def create_coordinator(llm):
"""
协调器:分析当前任务完成情况,决定下一步由谁处理。
返回值:researcher / writer / reviewer / done
"""
prompt = ChatPromptTemplate.from_messages([
("system", """你是任务协调者,判断下一步应该由谁执行:
- 没有研究资料 → 返回 "researcher"
- 有资料没草稿 → 返回 "writer"
- 有草稿没审核 → 返回 "reviewer"
- 已完成 → 返回 "done"
只返回一个词。"""),
("human", "任务:{task}\n资料:{research_notes}\n草稿:{draft_content}\n反馈:{feedback}"),
])
chain = prompt | llm | StrOutputParser()
def coordinator_node(state: MultiAgentState) -> dict:
decision = chain.invoke({
"task": state["task"],
"research_notes": state["research_notes"] or "(无)",
"draft_content": state["draft_content"] or "(无)",
"feedback": state["feedback"] or "(无)",
}).strip().lower()
# 解析决策(健壮性处理)
if "researcher" in decision:
next_agent = "researcher"
elif "writer" in decision:
next_agent = "writer"
elif "reviewer" in decision:
next_agent = "reviewer"
else:
next_agent = "done"
print(f" [协调器] 决定:→ {next_agent}")
return {"current_agent": next_agent}
return coordinator_node
# ── 研究员节点 ──
def create_researcher(llm):
chain = ChatPromptTemplate.from_messages([
("system", "你是资深研究员,收集主题相关资料,分点列出关键事实。"),
("human", "收集资料:{task}"),
]) | llm | StrOutputParser()
def researcher_node(state: MultiAgentState) -> dict:
print(" [研究员] 收集资料中...")
notes = chain.invoke({"task": state["task"]})
return {"research_notes": notes}
return researcher_node
# ── 写作者节点 ──
def create_writer(llm):
chain = ChatPromptTemplate.from_messages([
("system", "你是专业作者,基于资料创作流畅文章。如有审核反馈请按反馈修改。"),
("human", "任务:{task}\n资料:{research_notes}\n{feedback_section}\n请创作:"),
]) | llm | StrOutputParser()
def writer_node(state: MultiAgentState) -> dict:
print(" [写作者] 写作中...")
feedback_section = (
f"审核反馈(请改进):{state['feedback']}"
if state.get("feedback") else ""
)
draft = chain.invoke({
"task": state["task"],
"research_notes": state["research_notes"],
"feedback_section": feedback_section,
})
return {"draft_content": draft}
return writer_node
# ── 审核者节点 ──
def create_reviewer(llm):
chain = ChatPromptTemplate.from_messages([
("system", """你是内容审核专家。
如果内容好,回答以 "APPROVED:" 开头。
如果需要改进,回答以 "REVISION_NEEDED:" 开头并说明原因。"""),
("human", "任务:{task}\n草稿:{draft_content}\n请审核:"),
]) | llm | StrOutputParser()
def reviewer_node(state: MultiAgentState) -> dict:
print(" [审核者] 审核中...")
review = chain.invoke({"task": state["task"], "draft_content": state["draft_content"]})
iteration = state.get("iteration", 0) + 1
if "APPROVED" in review.upper() or iteration >= 2: # 最多修改2次
print(" [审核者] ✅ 通过!")
return {"final_content": state["draft_content"], "feedback": "", "iteration": iteration}
else:
feedback = review.replace("REVISION_NEEDED:", "").strip()
print(f" [审核者] ⚠️ 需修改:{feedback[:50]}")
return {"feedback": feedback, "iteration": iteration}
return reviewer_node
# ── 路由函数 ──
def route_after_coordinator(state: MultiAgentState) -> str:
return state.get("current_agent", "researcher")
def route_after_reviewer(state: MultiAgentState) -> str:
"""通过则结束,否则发回给写作者修改。"""
return END if state.get("final_content") else "writer"
# ── 构建多 Agent 图 ──
builder = StateGraph(MultiAgentState)
builder.add_node("coordinator", coordinator)
builder.add_node("researcher", researcher)
builder.add_node("writer", writer)
builder.add_node("reviewer", reviewer)
builder.add_edge(START, "coordinator")
builder.add_conditional_edges(
"coordinator", route_after_coordinator,
{"researcher": "researcher", "writer": "writer", "reviewer": "reviewer", "done": END}
)
# 研究员/写作者完成后回到协调器(让协调器决定下一步)
builder.add_edge("researcher", "coordinator")
builder.add_edge("writer", "coordinator")
# 审核者完成后:通过→结束,不通过→直接发回写作者
builder.add_conditional_edges(
"reviewer", route_after_reviewer, {END: END, "writer": "writer"}
)运行方式:
bash
python lessons/07_langgraph/03_multi_agent_graph.py3.5 多 Agent 图的执行过程
运行以上代码时,控制台会看到:
css
任务:写一篇关于人工智能对教育影响的500字文章
============================================================
[协调器] 决定:→ researcher
[研究员] 收集资料中...
[协调器] 决定:→ writer
[写作者] 写作中...
[协调器] 决定:→ reviewer
[审核者] 审核中...
[审核者] ⚠️ 需修改:请增加具体的教育应用案例...
[写作者] 写作中... ← 根据反馈修改
[审核者] 审核中...
[审核者] ✅ 通过!
============================================================
最终输出:
(500字文章内容)四、生产环境建议
4.1 防止无限循环
python
MAX_ITERATIONS = 5
def reviewer_node(state: MultiAgentState) -> dict:
iteration = state.get("iteration", 0) + 1
# 达到最大迭代次数,强制通过(避免无限循环)
if iteration >= MAX_ITERATIONS:
print(f"⚠️ 达到最大迭代次数({MAX_ITERATIONS}),强制结束")
return {"final_content": state["draft_content"], "iteration": iteration}
# ... 正常审核逻辑4.2 使用持久化 Checkpointer
python
# 开发环境
from langgraph.checkpoint.memory import MemorySaver
checkpointer = MemorySaver()
# 生产环境(SQLite,单机)
from langgraph.checkpoint.sqlite import SqliteSaver
checkpointer = SqliteSaver.from_conn_string("./prod_checkpoints.db")
# 生产环境(PostgreSQL,多机共享)
# from langgraph.checkpoint.postgres import PostgresSaver
# checkpointer = PostgresSaver.from_conn_string("postgresql://...")4.3 流式输出
python
# 实时流式输出每个节点的中间结果
for chunk in graph.stream(initial_state, config=config):
# chunk 是一个字典,key 是节点名,value 是该节点的输出
for node_name, node_output in chunk.items():
print(f"[{node_name}] 输出: {node_output}")4.4 生产环境检查清单
python
部署前检查:
□ 所有节点都有 try/except 错误处理
□ 循环图有最大迭代次数限制
□ 敏感操作节点设置了 interrupt_before
□ 使用持久化 Checkpointer(非 MemorySaver)
□ thread_id 管理策略(防冲突:如 f"user_{user_id}_{task_id}")
□ 所有节点都有打印/日志,方便排查问题
□ 测试了各种条件边的路由场景(边界情况)
□ 验证了图结构(print_ascii 或 draw_mermaid)五、常见问题解答
Q: MemorySaver 在生产环境够用吗?
不够用。MemorySaver 存在内存中,服务重启后丢失。生产环境用 SqliteSaver(单机)或 PostgresSaver(多机)。
Q: 多个 Agent 共享同一个 LLM 实例可以吗?
可以,只要 LLM 是无状态的(ChatOpenAI 是无状态的)。各 Agent 的系统提示通过 state_modifier 或 prompt 传入,LLM 实例本身不保存状态。
Q: 如何在 Web 服务中集成 LangGraph?
python
# FastAPI 示例
@app.post("/start_task")
async def start_task(topic: str):
thread_id = f"task_{uuid.uuid4()}"
config = {"configurable": {"thread_id": thread_id}}
# 异步运行,避免阻塞
result = await graph.ainvoke(initial_state, config=config)
return {"thread_id": thread_id, "result": result}
@app.get("/get_state/{thread_id}")
async def get_state(thread_id: str):
config = {"configurable": {"thread_id": thread_id}}
state = graph.get_state(config)
return state.valuesQ: 图执行过程中某个节点报错怎么处理?
python
def safe_node(state: MyState) -> dict:
try:
result = risky_operation(state)
return {"result": result, "error": ""}
except Exception as e:
# 写入错误信息,让路由函数决定如何处理
return {"result": "", "error": str(e)}
# 路由函数检查错误
def route_after_node(state: MyState) -> str:
if state.get("error"):
return "error_handler" # 路由到错误处理节点
return "next_node"六、本章知识点总结
scss
LangGraph 进阶
├── 检查点(Checkpointer)
│ ├── MemorySaver ← 开发/测试用,内存存储
│ ├── SqliteSaver ← 单机生产环境
│ └── PostgresSaver ← 多机生产环境
│
├── Human-in-the-Loop(人工介入)
│ ├── interrupt_before=["node"] ← 节点前暂停
│ ├── get_state(config) ← 查看当前状态
│ ├── update_state(config, {}) ← 人工修改状态
│ └── invoke(None, config) ← 从暂停点继续
│
├── 多 Agent 协作
│ ├── 协调器模式(Supervisor Pattern)
│ ├── 共享 State 传递信息(各写各的字段)
│ ├── iteration 字段防止无限循环
│ └── 各 Agent 独立提示词(稳定,可调试)
│
└── 代码文件
├── 04_checkpoint_hitl.py ← 可视化 + 检查点 + 人工介入
└── 03_multi_agent_graph.py ← 多 Agent 协作📌 下一章预告 :第08章学习 MCP(模型上下文协议),这是 AI 工具生态的统一接口标准,让你的 AI 应用轻松接入外部工具和数据源。
作者:阿聪谈架构公众号:阿聪谈架构 (分享后端架构 / AI / Java 技术文章)
相关代码关注公众号:【阿聪谈架构】 回复:AI专栏代码