很多市场宣传把 AI ENC、AEC 描述成一种"万能净化器",仿佛无论环境多恶劣,都能把人声完美剥离出来。但从声学与信号处理的本质来看,这其实是一种典型误解。
为什么"AI 降噪"并不等于"任何环境都能听清人声"
在 AI 语音行业中,一个越来越常见的误区正在被不断放大:
"既然已经做了 AI 降噪、AEC 消回音,那环境噪音再大也不应该影响人声。"
甚至很多客户会直接提出一种近乎"违反物理规律"的要求:
- 扬声器紧贴麦克风;
- 风扇、电机、广播喇叭距离麦克风只有几厘米;
- 讲话人却在 1 米甚至更远的位置;
- 同时要求"人声必须依旧完整、清晰、无失真"。
这类期待的背后,本质上是对"降噪"与"语音恢复"之间概念的混淆。
AI 降噪很强,但它不是魔法。
真正理解这一点,需要先回到声音本身。
一、声音首先是"能量竞争"
麦克风并不理解"什么是人声"。对于麦克风而言,它接收到的只是空气中的振动能量。谁距离更近,谁声压更大,谁频率更突出,谁就更容易主导最终的采样结果。这意味着:当一个高音量扬声器距离麦克风仅 3cm,而讲话人距离麦克风 1 米时,
麦克风收到的并不是:
"一个清晰人声 + 一点噪音"
而往往是:
"一个极强的扬声器声波"
"一个已经被淹没的人声残留"
此时的问题已经不是"降噪能力够不够"。而是:人声本身是否还真实存在于采样信号里。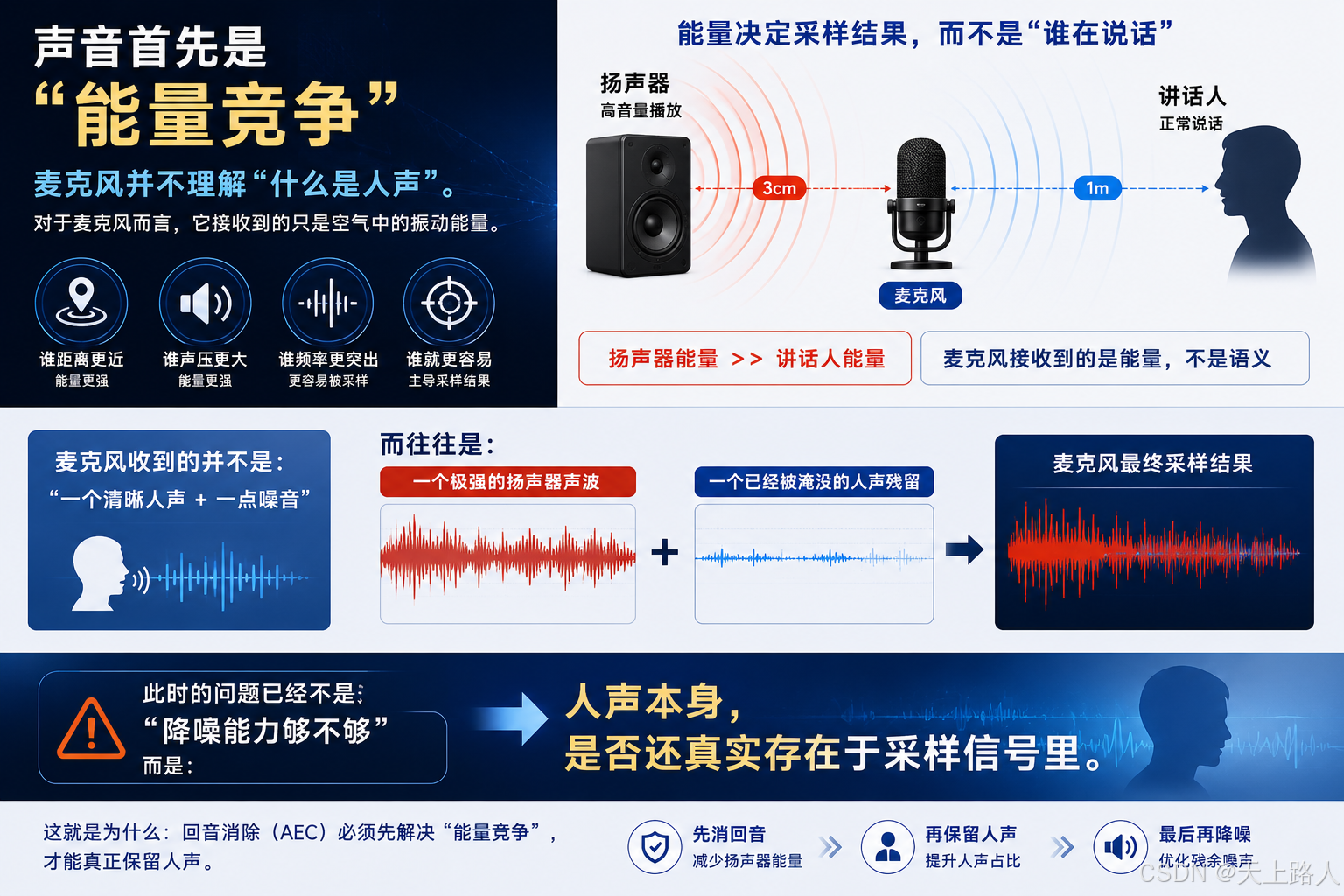
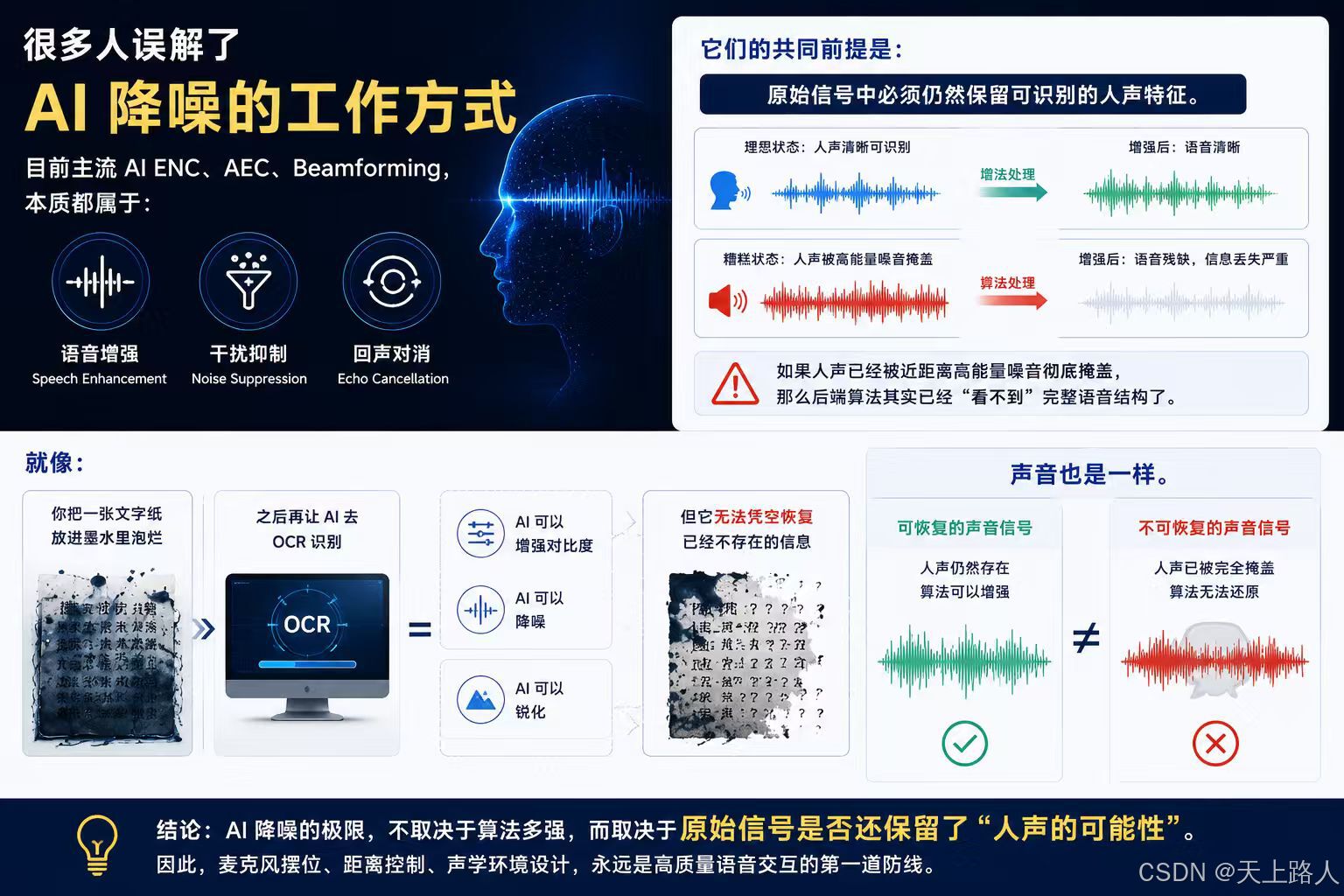
二、很多人误解了 AI 降噪的工作方式
目前主流 AI ENC、AEC、Beamforming,本质都属于:
- 语音增强(Speech Enhancement)
- 干扰抑制(Noise Suppression)
- 回声对消(Echo Cancellation)
它们的共同前提是:原始信号中必须仍然保留可识别的人声特征。
如果人声已经被近距离高能量噪音彻底掩盖,那么后端算法其实已经"看不到"完整语音结构了。
就像:你把一张文字纸放进墨水里泡烂,之后再让 AI 去 OCR 识别。
AI 可以增强对比度,可以降噪,可以锐化,但它无法凭空恢复已经不存在的信息。
声音也是一样。
三、为什么"近距离噪音"杀伤力极强
很多工程师低估了距离带来的影响。声压级并不是线性衰减,而是近似遵循平方反比规律。距离增加一倍,声压会显著下降。
举例:
**扬声器距离麦克风:**5cm
人嘴距离麦克风:100cm
两者距离相差 20 倍。
实际声压差可能达到:20dB30dB****甚至更高
这意味着:即使讲话人与扬声器"听起来一样响",对于麦克风而言,扬声器可能已经强了几十倍。
最终 ADC 采样时:
扬声器波形占据主要动态范围
人声被压缩到极低幅度
语音细节丢失
高频辅音被掩盖
共振峰结构被破坏
而这些,恰恰是 AI 识别人声最关键的信息。
四、为什么"强降噪"反而会损伤人声
这是行业里另一个常见误解:
"降噪越狠越好。"
实际上:当噪音与人声严重混叠时,算法无法百分百准确地区分:
- 哪部分是噪音
- 哪部分是语音
于是系统会进入一种"保守抑制"状态。
结果就是:噪音确实下去了,但人声也一起被削掉了。最终表现为:
- 人声发闷
- 发空
- 机械感严重
- 高频缺失
- 尾音断裂
- 吃字
- 含糊
- AI 识别率下降
很多客户会说:
"怎么降噪后反而不像人说话了?"
原因并不是算法差。而是:
人声在前端采集阶段已经受到了不可逆破坏。
后端再强,也无法完整恢复。
五、AEC 消回音同样遵循物理边界
很多人认为:
**"100dB AEC"
就意味着扬声器贴着麦克风也绝对没问题。**
这是对 AEC 指标的典型误读。
AEC 的核心前提是:
- 回声路径稳定
- 参考信号准确
- 麦克风未过载
- 人声仍具有足够信噪比
如果扬声器过近:
- 麦克风前端可能已经饱和
- ADC 已经削波
- 回声与人声完全重叠
- 非线性失真急剧增加
这时:AEC 不再是在"消除回声",而是在处理一个已经失真的混合灾难信号。结果自然会出现:
- 回声残留
- 人声抽吸
- 双讲失真
- 通话断续
六、真正优秀的语音系统,从来不是"只靠算法"
成熟的声学系统首先解决的是:
1. 空间布局
包括:
- 麦克风与扬声器隔离
- 指向性设计
- 避免正对耦合
- 腔体隔振
2. 声学结构
包括:
- 导音结构
- 防风噪设计
- 共振控制
- 吸音材料
3. 前端信噪比
包括:
- 麦克风灵敏度
- 模拟链路噪声
- ADC 动态范围
- 前级增益设计
4. 阵列与波束成形
通过:
- 双麦
- 多麦
- 空间滤波
提升目标方向的人声能量。
5. 最后才是 AI 算法
AI 的真正作用是:
**在"还能分辨人声"的前提下,
尽可能提升语音质量。**
而不是:
凭空从灾难信号里创造清晰语音。

七、行业真正需要的是"尊重物理规律"
今天很多 AI 语音产品,营销已经开始脱离声学本质。
仿佛:
- AI 可以无视距离
- 可以无视声压
- 可以无视动态范围
- 可以无视硬件结构
但现实是:声音依旧遵循物理规律。麦克风听到什么,算法才能处理什么。如果前端采集阶段,人声已经被彻底掩盖,那么再强的 AI,也只能"猜测"人声,而不是"恢复"人声。
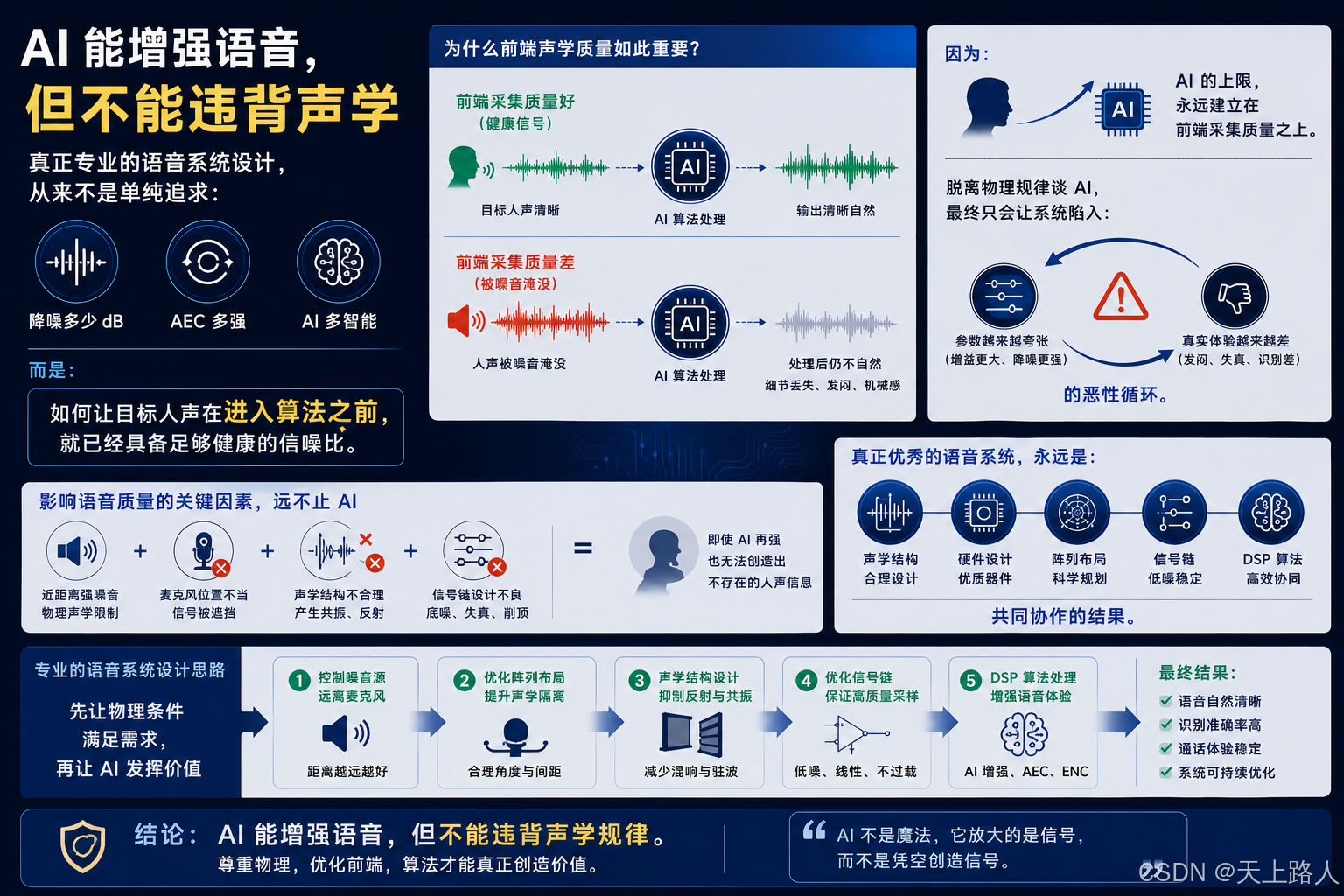
八、结语:AI 能增强语音,但不能违背声学
真正专业的语音系统设计,从来不是单纯追求:
"降噪多少 dB"
"AEC 多强"
"AI 多智能"
而是:
**如何让目标人声在进入算法之前,
就已经具备足够健康的信噪比。**
因为:
**AI 的上限,
永远建立在前端采集质量之上。**
脱离物理规律谈 AI,最终只会让系统陷入:"参数越来越夸张,但真实体验越来越差"的恶性循环。
真正优秀的语音系统,永远是:
- 声学结构
- 硬件设计
- 阵列布局
- 信号链
- DSP 算法
共同协作的结果。而不是一句:"AI 会自动解决一切。"