文章目录
- Pre
- [一、 为什么你需要一套「可执行的计划语言」](#一、 为什么你需要一套「可执行的计划语言」)
- 二、整体工作流:计划在开发流水线中的位置
- 三、核心理念:为一位「零上下文工程师」写计划
- 四、从头开始:计划文档的标准头部
- 五、文件结构映射:先定「地盘」,再谈任务
- [六、细粒度拆分:2--5 分钟一个步骤的 TDD 循环](#六、细粒度拆分:2–5 分钟一个步骤的 TDD 循环)
- [七、任务内部结构:Files 块、步骤与提交](#七、任务内部结构:Files 块、步骤与提交)
-
- [1. Files 块:精确到行号的变更声明](#1. Files 块:精确到行号的变更声明)
- [2. 步骤内容:写「真代码」,不给「脑补空间」](#2. 步骤内容:写「真代码」,不给「脑补空间」)
- [3. 提交步骤:格式统一的 Commit Message](#3. 提交步骤:格式统一的 Commit Message)
- 八、严格的「禁用占位符」规则:不留任何模糊空间
- 九、自审与审查:把问题堵在计划阶段
- 十、范围检查与计划拆分:拒绝「巨型单体计划」
- [十一、执行交接:子代理驱动 vs 内联执行](#十一、执行交接:子代理驱动 vs 内联执行)
- 十二、存储约定:把计划当作正式工程资产
- 十三、实战示例:如何为一个功能写出合格的计划
-
- [1. 头部示意](#1. 头部示意)
- [2. 文件映射示意](#2. 文件映射示意)
- [3. 任务与步骤示意](#3. 任务与步骤示意)
- 十四、把方法论落地到你的团队
- [十五、小结:计划是连接人和 Agent 的「共同语言」](#十五、小结:计划是连接人和 Agent 的「共同语言」)
Pre
Superpowers - 01 让 AI 真正"懂工程":Superpowers 软件开发工作流深度解析
Superpowers - 02 用 15 个技能给你的 AI 装上「工程大脑」:Superpowers 快速开始深度解析
Superpowers - 03 一文搞懂 Superpowers:面向多平台 AI 编码助手的安装与实践指南
Superpowers - 04 从"会写代码"到"会做工程":Superpowers 工作流引擎架构深度剖析
Superpowers - 05 构建一个"会自己找插件用"的 Agent:深入解析 Superpowers 的技能发现与激活机制
Superpowers - 06 从文档到"结构契约":Superpowers 技能剖析与 Frontmatter 深度解读
Superpowers - 07 从 SessionStart Hook 看 Superpowers:把「技能库」变成「行为操作系统」
Superpowers - 08 在 AI 时代重写「需求评审会」:深入解读 Superpowers 的头脑风暴与设计规范机制
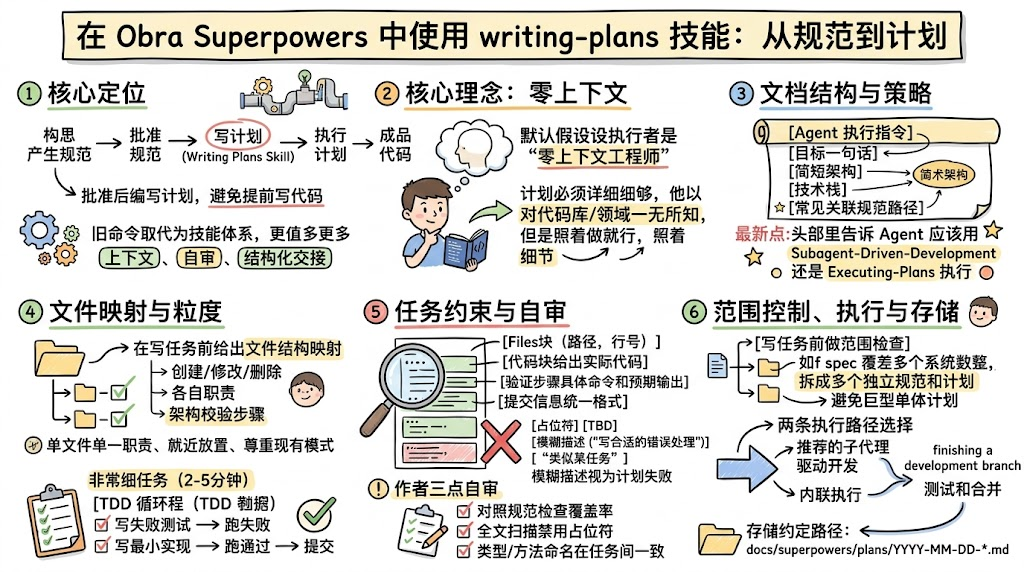
在 AI 参与软件开发的时代,「怎么写代码」已经不是最大的问题,「怎么让人和 Agent 都能稳定地把复杂需求落到实处」才是关键。 本文围绕 obra Superpowers 中的 writing-plans 技能,系统拆解一套面向「零上下文工程师」的计划编写方法论,帮助你把模糊的设计规范,转化为任何人、任何 Agent 都能照着执行的工程实施计划。
一、 为什么你需要一套「可执行的计划语言」
writing-plans 被设计成一座桥梁:一端是已经评审通过的设计规范,另一端是由人类或 Agent 实际执行的开发任务列表。 在 obra Superpowers 的开发工作流中,它夹在「头脑风暴与设计规范」和「Subagent 驱动开发 / 内联执行计划」之间,是整个流水线的关键咽喉节点。
面向读者主要分三类:
- 日常需要拆需求、带团队、做 Code Review 的工程师 / Tech Lead
- 正在尝试用 AI 助手接管部分开发任务的团队
- 对 Agentic 开发、自动化流水线感兴趣的研究者和技术爱好者
如果用一句话概括本文的核心价值:帮你学会写出一种 对人和 Agent 都友好的「执行说明书」,让每个需求都能走完「规范 → 计划 → 实施 → 合并」的闭环,而不是停在 PPT 或脑子里。
二、整体工作流:计划在开发流水线中的位置
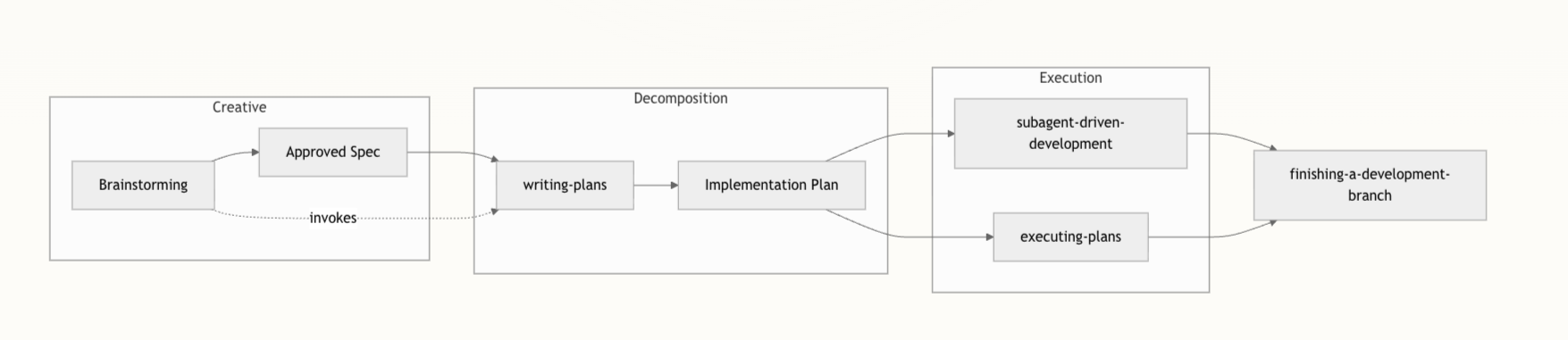
在 Superpowers 设计里,每个功能都要走完一条严格的线性管线:
- 构思产生设计规范(brainstorming + design spec)
- 使用
writing-plans将规范拆成可执行任务列表 - 通过
subagent-driven-development或executing-plans消费这些任务 - 最后通过
finishing-a-development-branch完成测试、PR 和合并流程
旧时代的 /write-plan、/execute-plan 斜杠命令已经被彻底弃用,原因是它们无法提供足够的上下文注入、自审循环和规范化的交接协议。 基于技能(skill)的系统则以更结构化的方式表达:技能 frontmatter、Hook 注入、上下游技能依赖,从而让整条链路可以被 Agent 和人类稳定消费。
这里有一个非常重要的约束:
- 没有「已批准的规范」,就不能写计划
- 没有「完成的计划」,就不能启动实施
这听上去有点「刻意增加流程」,但它直接干掉了最常见的失败模式:Agent 或工程师在需求没讲清楚、范围没收敛时就直接下场写代码,最终导致返工和难以收尾的技术债。
三、核心理念:为一位「零上下文工程师」写计划
writing-plans 最与众不同的地方,是它假设执行者是一名「零上下文工程师」:
一名熟练的开发者,但对我们的工具集或问题域几乎一无所知,而且也不一定擅长测试设计。
这套假设背后有几个现实考虑:
- AI 的上下文窗口是有限的,计划经常要跨会话执行,之前的聊天记录不可靠
- 接手计划的人可能不是原作者,也可能压根没参与需求讨论
- 很多开发者并不天然擅长 TDD,需要「被计划」强制走一遍规范流程
因此,计划必须在文档里把所有关键信息写全:
- 精确文件路径、文件职责
- 完整代码块(不是伪代码,也不是口头描述)
- 精确的测试命令和预期输出
- 推荐的执行技能(子代理开发还是内联执行)
你可以把它理解为:这是一种面向「匿名未来执行者」的工程说明语言,目标是让任何人在没有上下文、没有陪跑的前提下,也能靠这份文档从零把功能做完。
四、从头开始:计划文档的标准头部
要让计划成为可靠的「协议」,首先得有一个稳定的头部结构。Superpowers 要求每个计划都以统一的头部块开篇,用来向人和 Agent 声明计划的元信息:
| 字段 | 用途 | 示例 |
|---|---|---|
| Agent 执行指令 | 告诉 Agent 应使用哪个技能 | REQUIRED SUB-SKILL: Use superpowers:subagent-driven-development |
| 目标 | 一句话描述计划要达成的结果 | "Make worktree skills work in Codex App's sandboxed environment" |
| 架构 | 2--3 句话总结技术方案 | "Read-only environment detection at skill start..." |
| 技术栈 | 涉及的技术和库 | "Git, Markdown"等 |
| 规范(可选但常见) | 所依据的设计规范路径 | docs/superpowers/specs/2026-03-23-...-design.md |
其中最关键的是 Agent 执行指令 :它明确告诉任何接手计划的 Agent 接下来要调用的是 subagent-driven-development 还是 executing-plans。 如果缺少这一行,Agent 就无法知道下一步的正确协议,相当于链路被掐断。
这个 design 很像 API 的 versioning 和 contract:头部不只是文档装饰,而是机器可读、流程可路由的协议头。
五、文件结构映射:先定「地盘」,再谈任务
在写任何任务前,writing-plans 要求先给出一份清晰的「文件结构映射」:
- 哪些文件会被创建
- 哪些会被修改或删除
- 每个文件的职责是什么
并配套三条设计原则:
- 单文件单一职责:每个文件的目的要单一清晰
- 就近放置:一起变更的文件应该靠近,按职责而非技术层次划分
- 尊重现有模式:不强行重构已有成熟结构,除非被修改文件已明显臃肿
文件映射通常有两种表达形式:
- 表格:列出路径、操作(创建 / 修改 / 删除)、职责
- 扁平列表:带动作动词的列表,如 "Create
skills/.../SKILL.md:描述 X 功能"
官方明确强调:文件结构映射不仅是组织信息,更是一个 架构校验步骤。如果这一部分写不清楚,后续的任务边界几乎必然混乱,执行时就会出现「到底是哪个文件负责这块逻辑」之类的问题。
六、细粒度拆分:2--5 分钟一个步骤的 TDD 循环
writing-plans 的招牌特性,就是极其强调「任务粒度」。在它的世界观里,一个好的任务应该被拆成若干 每步 2--5 分钟可完成 的具体操作。
在 TDD 场景下,典型的五步循环如下:
| 步骤 | 操作 | 验证 |
|---|---|---|
| 1 | 编写失败测试 | --- |
| 2 | 运行测试确认失败 | 预期:FAIL + 特定错误信息 |
| 3 | 编写最小实现 | --- |
| 4 | 运行测试确认通过 | 预期:PASS |
| 5 | 提交 | --- |
每一个步骤在计划文档中对应一个复选框(- [ ]),方便执行者逐项打勾。 这种粒度带来的收益非常直接:
- 上下文容易装入:每步涉及的改动和信息量足够小,适合丢给子代理完整消化
- 失败易定位:如果某一步失败,可以非常精准地回溯到该步的修改
- 提交频率可控:每个 TDD 循环完成一次提交,历史清晰、回滚简单
- 文档即意图:测试名与预期输出天然记录了行为意图
「2--5 分钟」并不是硬性 SLA,而是一种校准用的心里尺:当你写完一个步骤后,问自己------一位对上下文一无所知的工程师,能否在不额外做决策的前提下,直接执行完?如果答案是否定的,那就再拆。
七、任务内部结构:Files 块、步骤与提交
每个任务内部也有一套固定的「小结构」,贯穿整个仓库的示例计划。
1. Files 块:精确到行号的变更声明
任务的开头是一个 Files 块,明确描述本任务将操作的文件及范围,例如:
Create: docs/superpowers/plans/2026-03-23-codex-app-compatibility.mdModify: skills/using-git-worktrees/SKILL.md:14-15
这种写法有几个好处:
- 消除「到底改哪个文件、哪段代码」的歧义
- 为自动化或半自动化静态检查提供基础
- 帮助代码评审者快速对齐本任务修改的「边界」
2. 步骤内容:写「真代码」,不给「脑补空间」
每个步骤内部如果涉及代码,必须给出 实际将写入文件的完整代码块,而不是「大致描述」或伪代码。 同样,验证步骤必须列出:
- 要执行的具体 shell 命令
- 预期的输出或至少关键片段
例如,不写「运行测试确保全部通过」,而是写:
- 运行:
npm test -- my-feature.spec.ts - 预期:用例
should handle empty input通过,suite 状态为 PASS
这背后的逻辑是:只要你让执行者自己去脑补「怎么写」,计划就失去了「可机械执行」的属性。对人可能勉强可行,对 Agent 来说则几乎等于失败。
3. 提交步骤:格式统一的 Commit Message
每个任务的最后往往是一个提交步骤,使用带作用域前缀的约定式 commit 格式,例如:
feat(worktree-skills): support Codex sandbox detection
正文则用一两句话描述本任务的具体改动。这个统一格式,有利于后续审计、查找和自动化工具的解析。
八、严格的「禁用占位符」规则:不留任何模糊空间
writing-plans 明确列出了一份「禁用模式清单」,凡是出现这些写法的计划,都被视为 计划失败:
| 禁用模式示例 | 失败原因 |
|---|---|
| "TBD""TODO""implement later""fill in details" | 实施者没有可执行内容 |
| "Add appropriate error handling / validation" | 「适当」完全没有被定义 |
| "Write tests for the above"(不写测试代码) | 执行者可能写出完全不同的测试 |
| "Similar to Task N"(不重复代码) | 任务可能被乱序阅读,丢上下文 |
| 单纯描述「做什么」但不展示「怎么做」 | 执行者必须猜细节 |
| 引用从未在任何任务中定义的类型或方法 | 执行者无法解析引用 |
这套规则本质上是在保护那位假想中的「零上下文工程师」:任何未经定义的引用、模糊的修饰词,都意味着执行者不得不暂停、上下求索、甚至去问原作者,这与「计划可直接执行」的目标背道而驰。
在 Agent 执行的语境下,executing-plans 甚至会明确指示:一旦遇到不明确的说明,应停下来请求人类澄清,而不是自作主张补完。 这进一步放大了写计划时「不要偷懒」的重要性。
九、自审与审查:把问题堵在计划阶段
当计划初稿写完后,writing-plans 要求计划作者自己完成一轮三项自审:
- 规范覆盖率检查:逐条浏览原始规范,确认每一项需求都能在某个任务中找到对应实现;发现遗漏要明确记下并补上。
- 占位符扫描:在计划中搜索所有禁用模式(如 TODO、TBD 等),确保不存在模糊指令。
- 类型一致性检查 :确认所有任务中使用的类型名、方法签名、字段名称保持一致,例如不要一处叫
clearLayers(),另一处叫clearFullLayers()。
值得注意的是:官方建议是「就地修复并继续------无需重新审查」,说明自审更像是一个高效的 checklist,而不是昂贵的审计流程。
除此之外,还可以选择启动一个专门的「计划文档审查者」子代理,按照四个维度进行第二重检查:
| 维度 | 检查内容 | 标准 |
|---|---|---|
| 完整性 | 是否存在 TODO、未完成任务、缺失步骤 | 每个步骤必须有真实内容 |
| 规范对齐 | 是否覆盖规范、是否范围蔓延 | 无遗漏需求,无过度设计 |
| 任务分解 | 边界是否清晰,步骤是否可执行 | 每步可独立执行 |
| 可构建性 | 工程师是否能不「卡住」完成执行 | 无歧义引用、无缺失上下文 |
有趣的一点是:审查者被明确要求「只标记会在实施阶段造成真实问题的项」,风格和措辞类的建议一律视为非阻塞性 advisory。 这让审查流程保持聚焦,而不会滑向纯粹的文风争论。
十、范围检查与计划拆分:拒绝「巨型单体计划」
在开始拆任务之前,writing-plans 要求先对规范做一次 范围检查:
- 如果规范覆盖了多个相对独立的子系统或功能域,就应该在构思阶段就拆成多个子项目规范
- 如果构思阶段没有拆好,计划编写者也应该及时建议拆分成多份独立计划,每个都对应一段可独立构建、可测试的软件
这是为了避免「一个计划试图覆盖整个平台」的反模式:这种计划不仅难写、难审、难执行,还很容易在执行过程中不断扩张,变成永远完不成的「大项目」。
brainstorming 技能在上游也会强调这一点:一旦察觉范围过大,就要尽早拆出子项目,并让每个子项目走完整的「规范 → 计划 → 实施」流程。
十一、执行交接:子代理驱动 vs 内联执行
当计划写好、存好之后,writing-plans 还要求作者在文档末尾明确给出两种执行策略供选择:
-
子代理驱动开发(推荐)
- 为每个任务起一个新的子代理实例,当前会话派发任务
- 在任务之间做两阶段审查:先检查规范对齐,再检查代码质量
- 优点是上下文隔离更好,每个子代理只需要关注自己那一小段计划
-
内联执行计划
- 使用
executing-plans在同一会话中批量执行任务 - 适合子代理不可用或希望「一路做到底」的场景
- 使用
不论使用哪一条路径,最终都要收敛到 finishing-a-development-branch,统一做测试验证、创建 PR 和合并操作。 两种方式的差异主要体现在体验上(交互式 vs 批量式),而不是产出结果。
十二、存储约定:把计划当作正式工程资产
为了保证可发现性和可追溯性,writing-plans 建议将计划统一存储在:
docs/superpowers/plans/YYYY-MM-DD-<slug>.md
规范文档则位于:
docs/superpowers/specs/
历史上还有一个旧的 docs/plans/ 目录,存放的是约定标准化之前的计划文件。 通过这种路径约定,可以:
- 按时间顺序快速定位近期计划
- 清晰地区分规范、计划和其他文档
- 让上游(brainstorming)和下游(执行技能)都能用路径互相引用
对于团队来说,这也意味着「计划文档」被视为一等公民工程资产,而不是临时聊天记录。
十三、实战示例:如何为一个功能写出合格的计划
结合上述原则,我们可以用一个简化的示例,来演示如何编写一份满足 writing-plans 要求的计划(示意风格,非原文复刻)。
1. 头部示意
markdown
REQUIRED SUB-SKILL: Use superpowers:subagent-driven-development
目标:为 Codex App 的沙盒环境增加 Git worktree 能力检测与降级处理
架构:在 worktree 相关技能启动时检测文件系统是否只读;若检测失败或权限不足,退化为 no-op 并记录日志。通过新增兼容性文档说明行为差异。
技术栈:Node.js、Git、Markdown
规范:docs/superpowers/specs/2026-03-23-codex-app-compatibility-design.md这种写法紧扣文档中的真实示例结构:通过一段简短的架构说明,把关键策略讲清楚,而把细节留给后续的文件映射和任务列表。
2. 文件映射示意
markdown
# Files
- Create: docs/superpowers/plans/2026-04-12-codex-worktree-compat.md
- 记录 Codex 沙盒兼容性计划
- Modify: skills/using-git-worktrees/SKILL.md
- 增加只读环境检测与降级逻辑说明
- Modify: skills/using-git-worktrees/index.ts
- 在运行时注入文件系统检测与降级实现
- Modify: tests/using-git-worktrees/compat.spec.ts
- 覆盖只读环境下的行为这与文档中要求的「路径 + 操作 + 职责」高度一致,并在最上层锁定了架构决策。
3. 任务与步骤示意
以「为只读环境行为写测试」为例:
markdown
## Task 1:为只读环境行为添加测试
Files:
- Modify: tests/using-git-worktrees/compat.spec.ts:1-120
- [ ] 步骤 1:为只读环境添加失败测试
- 在 `compat.spec.ts` 中新增 `it('disables worktree skills in read-only FS', ...)` 测试用例,断言在只读环境下 skill 返回特定错误消息。
- [ ] 步骤 2:运行测试确认失败
- 运行:`npm test -- using-git-worktrees/compat.spec.ts`
- 预期:新用例失败,错误消息包含 `read-only filesystem` 字样。
- [ ] 步骤 3:提交
- 提交信息:`test(worktrees): add failing spec for read-only FS`注意这里没有任何 TODO、TBD,也没有「写一个合适的错误处理」这种模糊话术。 执行者只需要按指示写出完整的测试代码,就可以进入实现阶段。
十四、把方法论落地到你的团队
如果你想把 writing-plans 的思路引入自己的团队(不管有没有用 Superpowers),可以从这几步开始:
- 统一文档头部:先约定一套类似的头部字段(目标、架构、技术栈、规范链接),让每一份计划都「长得像计划」。
- 强制文件映射:规定所有计划必须包含「文件结构映射」,并在 Code Review 里重点看这一节是否合理。
- 逐步压缩任务粒度:从「一个任务一天」慢慢过渡到「一个步骤 10--20 分钟」,再向 2--5 分钟靠拢。
- 落实禁用占位符:在文档模板和 Review Checklist 里写上「禁止 TODO/TBD 等模糊指令」,鼓励写「实际要改的代码」。
- 引入自审清单:让计划作者在提交前自查规范覆盖率、占位符和类型一致性,减少 Review 轮次里的「低级问题」。
当你把这些实践坚持一段时间后,你会发现团队在几个方面的明显变化:
- 新同事 onboarding 的速度会显著提升
- 跨时区协作时,不再高度依赖临场口头沟通
- AI 工具可以更可靠地参与到真实业务代码的开发中,而不是停留在玩票级别
十五、小结:计划是连接人和 Agent 的「共同语言」
writing-plans 所提出的一整套约束------零上下文假设、标准化头部、文件结构映射、2--5 分钟粒度、禁用占位符、自审与审查------看似给开发流程增加了不少「形式感」,但它换来的,是 在高度异质的执行主体之间(人类开发者与各类 Agent)建立一种共同的可执行语言。
在 AI 广泛参与开发的未来,谁能先建立起一套严谨的「计划语言」,谁就能更好地把智能能力转化为可控、可审计、可迭代的生产力。writing-plans 给出的,正是这样一份可操作又经过实战打磨的范本,值得每一个关心工程效能与 AI 协作的人认真研究和实践。
