什么是Redis
Redis 是一个开源 的基于内存 的键值对数据库(非关系型数据库),它的主要特征和作用包括:
- 基于内存,读写速度极快,可以处理大量读写请求。
- 支持多种数据结构,如字符串、哈希、列表、集合、有序集合等,具有丰富的数据表示能力。
- 支持主从复制,提供数据冗余和故障恢复能力。
- 支持持久化,可以将内存数据保存到磁盘中。
- 支持事务,可以一次执行多个命令。
- 丰富的功能,可用于缓存、消息队列等场景。
主要应用场景包括:
1、缓存常见的使用场景,比如缓存查询结果、热点数据等,大大降低数据库负载。
2、处理大量的读写请求,比如访问统计、消息队列等。
3、排行榜、计数器等功能的实现。
4、pub/sub消息订阅。
5、QUE计划任务
6、分布式锁等。
综上,Redis是一个性能极高的内存数据库,支持丰富数据结构,提供持久化、事务等功能,非常适合缓存、消息队列等场景,被广泛应用于各种大型系统中。它的高性能、丰富功能使其成为非关系型数据库的重要选择之一。
Redis通用命令
Redis默认有16个数据库,切换到第2个数据库
sql
select 1查看当前数据库key的数量
sql
DBSIZE设置一个key为username,值为mike的数据
sql
set username mike获取key为username的值
sql
get username获取所有的key
sql
keys *清除当前数据库
sql
flushdb清除所有数据库
sql
flushallRedis基本命令
查询key为username是否存在
sql
exists username指定key为username移动到1号数据库
sql
move username 1指定key为username10s后过期
sql
expire username 10查看key为username还有多久过期
sql
ttl username查看key为username是什么类 型
sql
type username五种数据结构类型
String类型
List集合类型
Set集合类型
Hash集合类型
Zset有序集合类型
Redis
相比MySQL等、读写速度非常快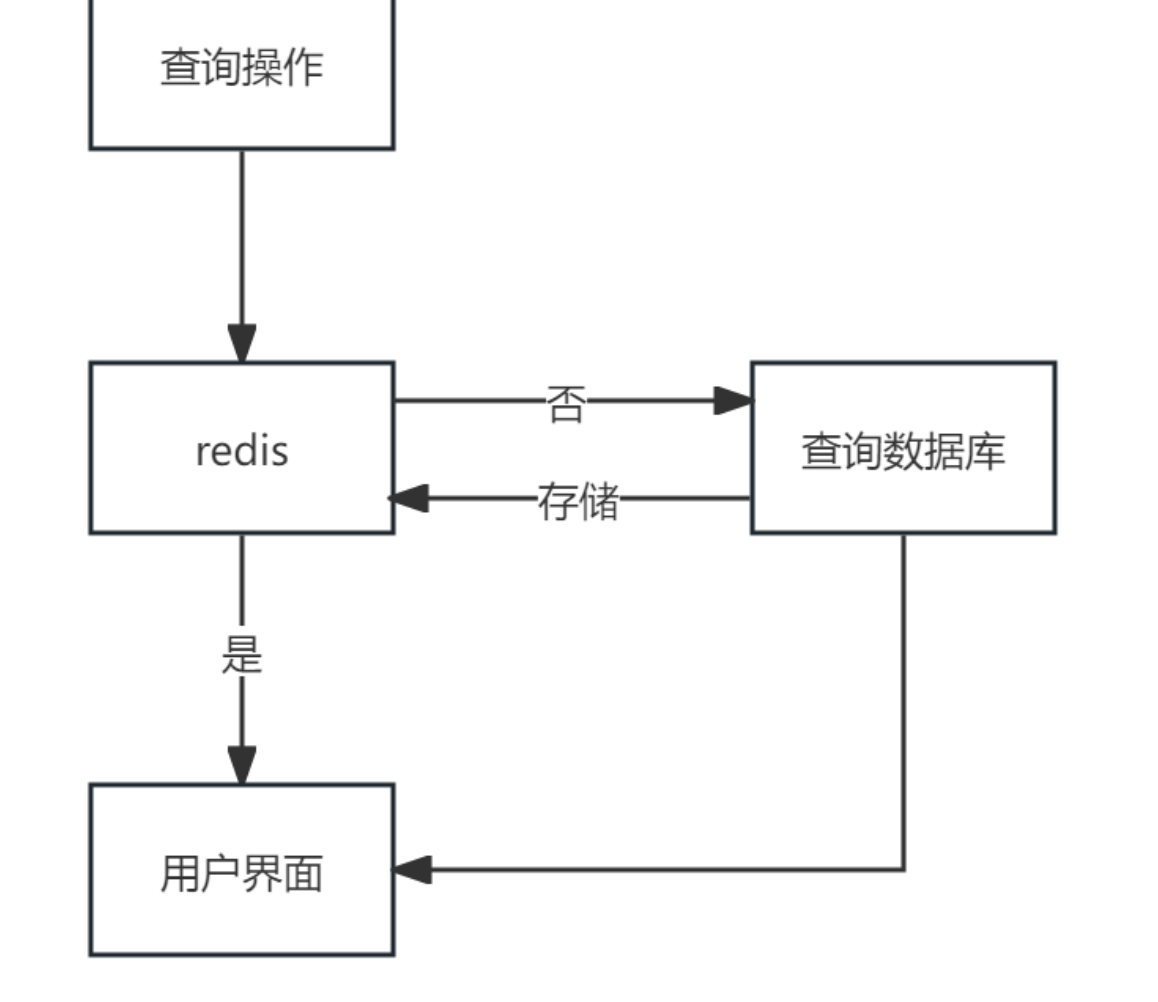
存在数据一致问题: 并不是每时每刻都与MySQL中的数据完全一样
所以,使用Redis的前提应该是:
- 需要高速的、高频率读写(可能包含写)
- 不太关注数据一致问题(偶尔不一致并不会带来严重后果)
什么时候,什么样的数据能够保存在Redis中?
-
使用越频繁,Redis保存这个数据越值得
-
保存在Redis中的数据一般不会是数据库中频繁修改的
-
数据量不能太大
缓存淘汰策略
Redis将数据保存在内存中, 内存的容量是有限的
如果Redis服务器的内存已经全满,现在还需要向Redis中保存新的数据,如何操作,就是缓存淘汰策略
- noeviction:返回错误**(默认)**
sql
maxmemory <bytes> # 设置淘汰触发机制
maxmemory-policy noeviction #设置淘汰策略- allkeys-random:所有数据中随机删除数据
- volatile-random:随机删除就将过期的数据
- volatile-ttl:删除剩余有效时间最少的数据
- allkeys-lru:所有数据中删除上次使用时间最久的数据
- volatile-lru:有过期时间的数据中删除上次使用时间最久的数据
- allkeys-lfu:所有数据中删除使用频率最少的
- volatile-lfu:有过期时间的数据中删除使用频率最少的
缓存穿透
正常业务下,一个请求查询到数据后,我们可以将这个数据保存在Redis。之后的请求都可以直接从Redis查询,就不需要再连接数据库了,如果一个请求查询的数据,数据库中没有会发生什么事情?
它会先查询Redis,Redis没有会查询数据库,数据库也没有 这就是缓存穿透。
因为数据库中没有数据,所以Redis也无法保存数据,如果这个请求反复出现,就会反复连接数据库,严重的导致数据库性能降低甚至宕机。
业界主流解决方案:布隆过滤器
布隆过滤器的使用步骤
- 针对现有所有数据,生成布隆过滤器
- 在业务逻辑层,判断Redis之前先检查这个id是否在布隆过滤器中
- 如果布隆过滤器判断这个id不存在,直接返回
- 如果布隆过滤器判断id存在,在进行后面业务执行
具体步骤参考: https://blog.51cto.com/u_15905482/6164135
缓存击穿
一个计划在Redis保存的数据,业务查询,查询到的数据Redis中没有,但是数据库中有
这种情况要从数据库中查询后再保存到Redis ,这就是缓存击穿
但是这个情况也不是异常情况,因为我们大多数数据都需要设置过期时间,而过期时间到时,这些数据一定会从数据库中再次同步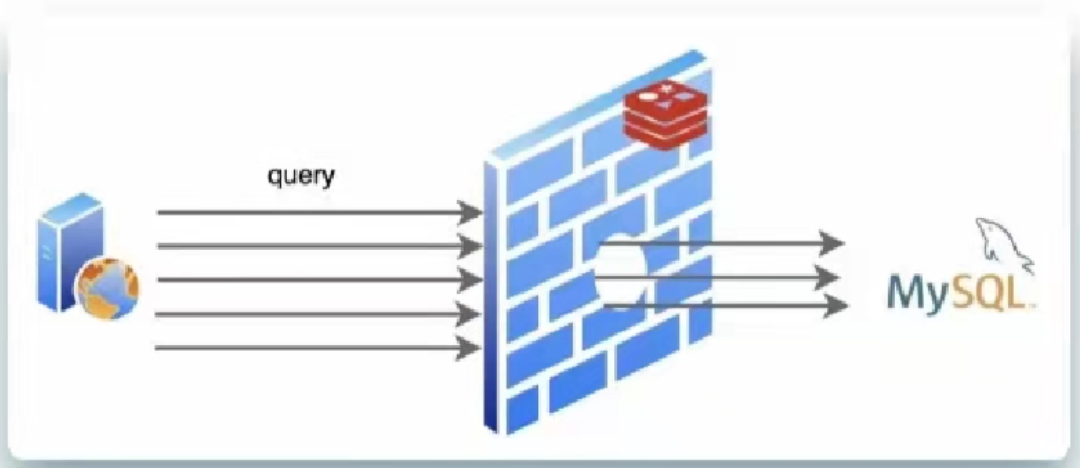
缓存雪崩
上面讲到击穿现象
同一时间发生少量击穿是正常的
但是如果出现同一时间大量击穿现象就会如下图
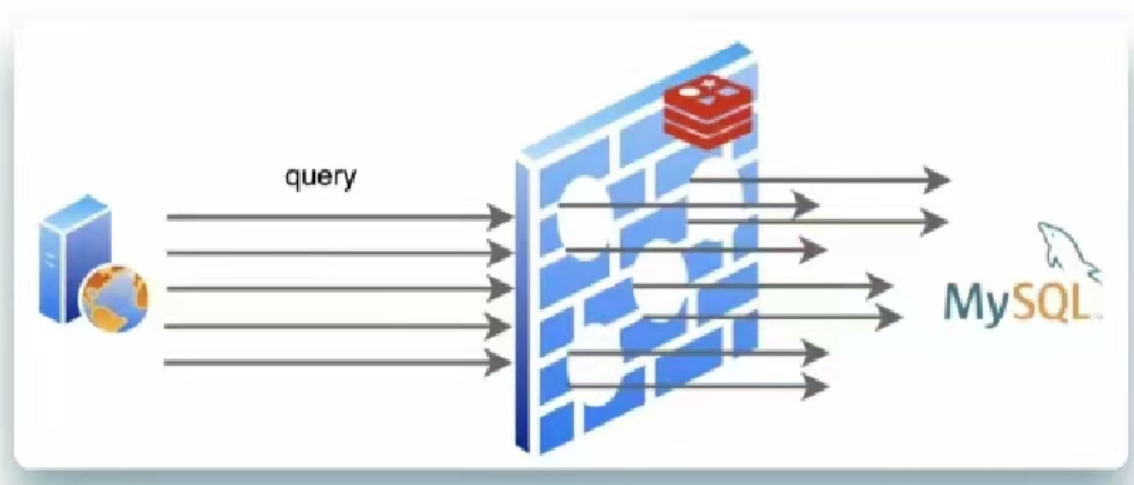
上图同时大量缓存失效,导致请求都压在mysql上,mysql承担不了,非常可能导致异常
要想避免这种情况,就需要避免大量缓存同时失效
大量缓存同时失效的原因:通常是同时加载的数据设置了相同的有效期导致的
那么我们需要在设置有效期时添加一个随机数,大量数据就不会同时失效了
Redis 持久化
Redis将信息保存在内存 。内存的特征就是一旦断电,所有信息都丢失,对于Redis来讲,所有数据丢失,就需要从数据库重新查询所有数据,这个是慢的
更有可能,Redis本身是有新数据的,还没有和数据库同步就断电了
所以Redis支持了持久化方案,在当前服务器将Redis中的数据保存在本地硬盘上
Redis持久化策略有两种
- RDB
RDB全称Redis Database Backup file(Redis数据备份文件),也被叫做Redis数据快照。简单来说就是把内存中的所有数据都记录到磁盘中。当Redis实例故障重启后,从磁盘读取快照文件,恢复数据。快照文件称为RDB文件,默认是保存在当前运行目录。
执行时机
RDB持久化在四种情况下会执行:
- 执行save命令
执行下面的命令,可以立即执行一次RDB: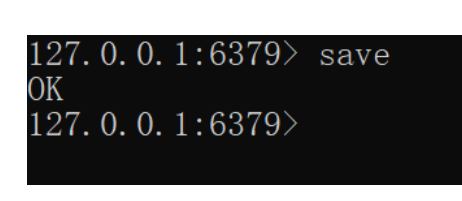
save命令会导致主进程执行RDB,这个过程中其它所有命令都会被阻塞。只有在数据迁移时可能用到。 - 执行bgsave命令
异步执行RDB: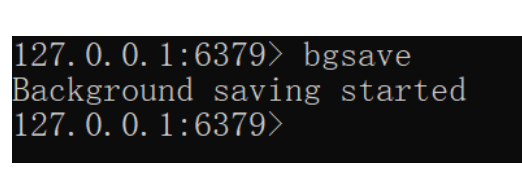
这个命令执行后会开启独立进程完成RDB,主进程可以持续处理用户请求,不受影响。 - Redis停机时
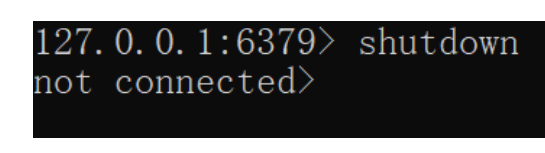
Redis停机时会执行一次save命令,实现RDB持久化。 - 触发RDB条件时
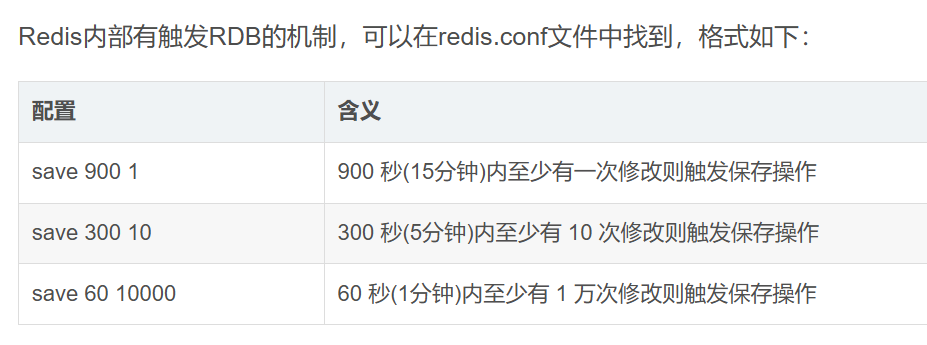
sql
# 是否压缩 ,建议不开启,压缩也会消耗cpu,磁盘的话不值钱
rdbcompression yes
# RDB文件名称
dbfilename dump.rdb
# 文件保存的路径目录
dir ./ RDB原理
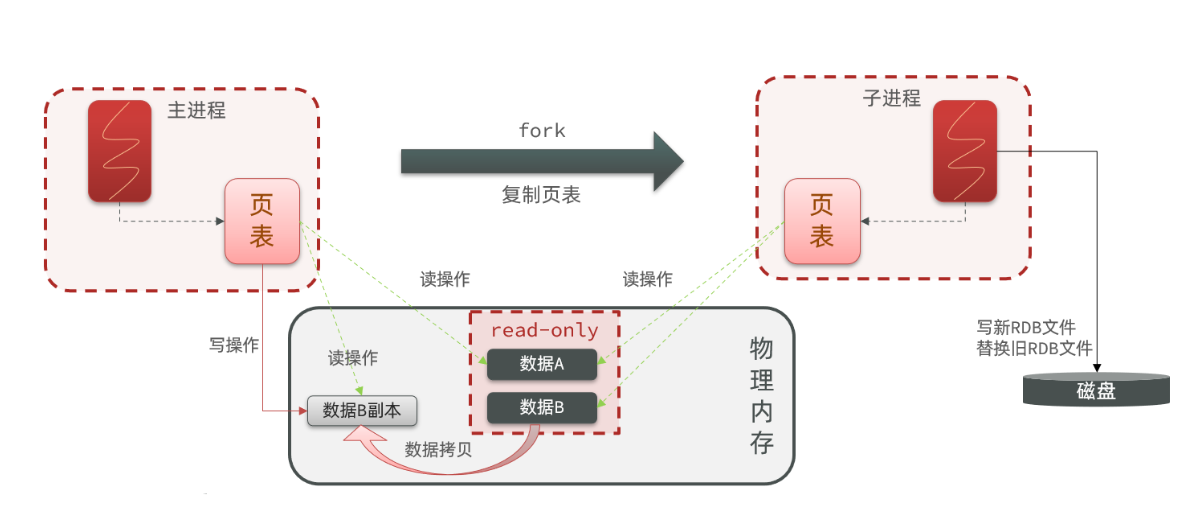
bgsave开始时会fork 主进程得到子进程,子进程共享主进程的内存数据。
fork在计算机中时非常常用的一个术语,创建一个新线程的意思
完成fork后读取内存数据并写入 RDB 文件。
fork采用的是copy-on-write技术:
- 当主进程执行读操作时,访问共享内存;
- 当主进程执行写操作时,则会拷贝一份数据,执行写操作。
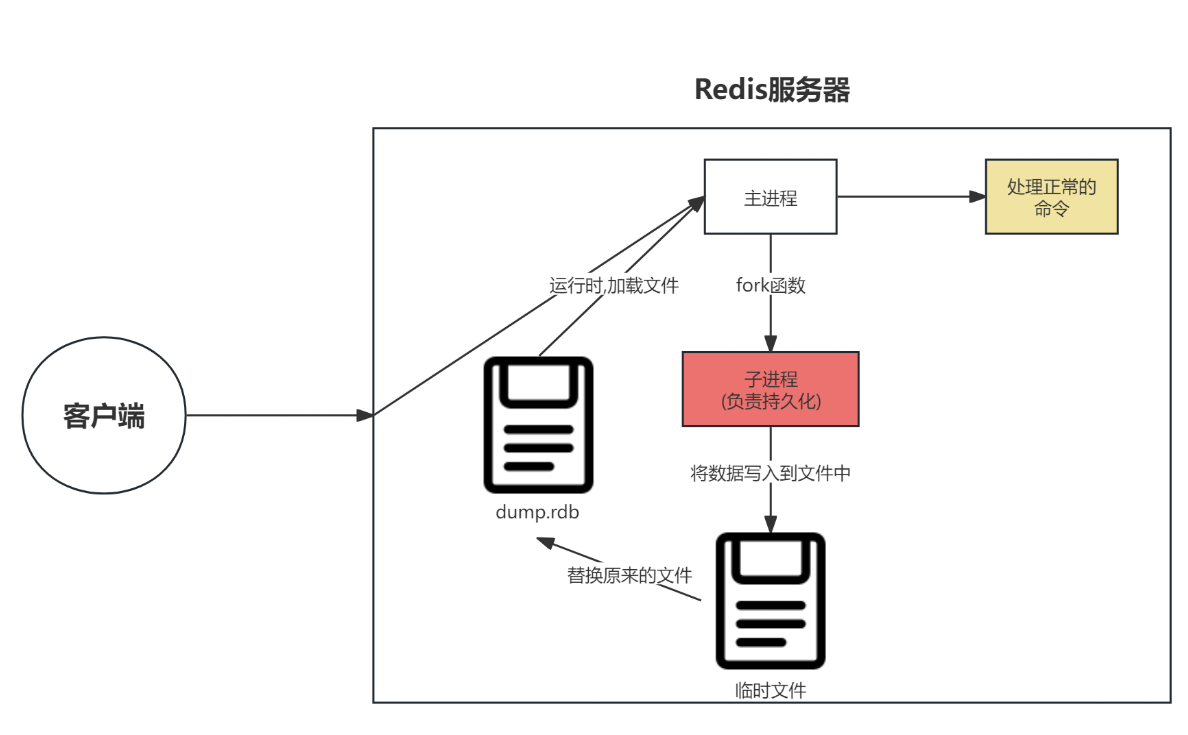
RDB方式bgsave的基本流程?
fork主进程得到一个子进程,共享内存空间
子进程读取内存数据并写入新的RDB文件
用新RDB文件替换旧的RDB文件
RDB会在什么时候执行?save 60 1000代表什么含义?默认是服务停止时
代表60秒内至少执行1000次修改则触发RDB
RDB的缺点?RDB执行间隔时间长,两次RDB之间写入数据有丢失的风险
fork子进程、压缩、写出RDB文件都比较耗时
- AOF
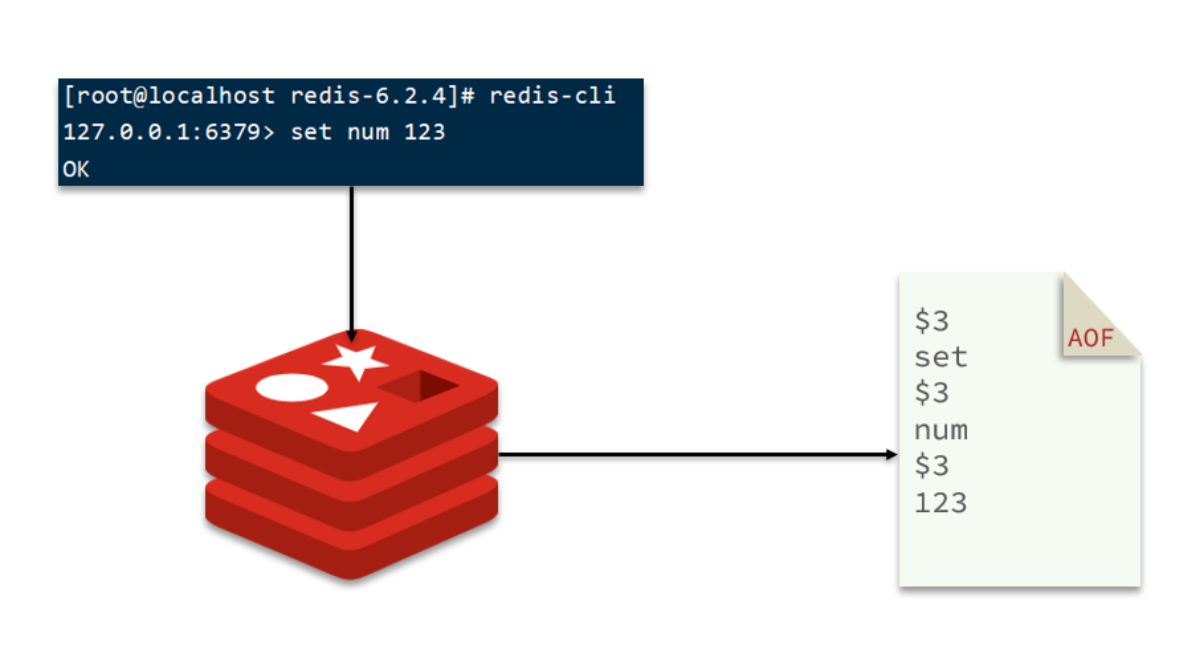
AOF全称为Append Only File(追加文件)。Redis处理的每一个写命令都会记录在AOF文件,可以看做是命令日志文件。
Redis集群
Redis集群搭建(了解)
下次接着写。。。