读者收益
阅读完本文,你将掌握ZooKeeper的核心原理,能够独立搭建生产级ZooKeeper集群,理解为什么分布式系统离不开它,彻底告别单机部署的生产隐患。
一、为什么需要ZooKeeper?
🎯 适用痛点
在分布式系统开发中,你是否遇到过这些场景?多个服务实例需要选举一个leader,但不知道如何实现。配置信息需要同步到所有服务节点,手动更新效率低且容易出错。分布式锁用Redis实现但经常出现死锁,不知道如何解决。服务注册中心需要知道哪些实例在线,动态感知上下线变化。
这些问题有一个共同的解决方案:ZooKeeper。
🏆 学完能做什么
通过本文的学习和实践,你将掌握以下能力:
- Leader选举:实现服务集群的自动Leader选举,无需人工干预
- 配置管理:实现跨服务的配置同步与动态更新
- 分布式锁:实现可靠的无死锁分布式锁
- 服务发现:实现服务实例的动态感知与负载均衡
⚠️ 前置要求
| 技能 | 要求级别 | 说明 |
|---|---|---|
| Linux基础 | 熟练 | 需能够执行命令行操作、编辑配置文件 |
| 网络基础 | 了解 | 理解IP、端口、SSH等基本概念 |
| Java基础 | 了解 | 了解ZooKeeper的Java客户端使用 |
| 环境要求 | - | 3台Linux服务器(建议奇数台) |
二、一分钟懂原理
💡 核心大白话比喻
ZooKeeper就像是一个分布式系统的"大脑"。它负责记住谁是小弟(服务注册)、谁是大哥(Leader选举)、大家该吃什么饭(配置管理)。所有服务都听它的调度,它来协调整个分布式系统的运行。
🧩 核心概念
ZNode(数据节点) :ZooKeeper中的最小数据单元,类似文件系统中的文件或目录。每个ZNode都有一个唯一的路径,如/service/leader。
Session(会话):客户端与ZooKeeper服务器的连接会话。Session超时时间由客户端设置,服务端保证在超时时间内检测到客户端失效。
Watcher(监听器):ZooKeeper的核心机制。客户端可以监听某个ZNode的变化,当ZNode数据变更、子节点变更时,服务器会通知客户端。
ZAB协议(ZooKeeper Atomic Broadcast):ZooKeeper的原子广播协议,保证集群中所有服务器的数据一致性。
🗺️ 架构流转图
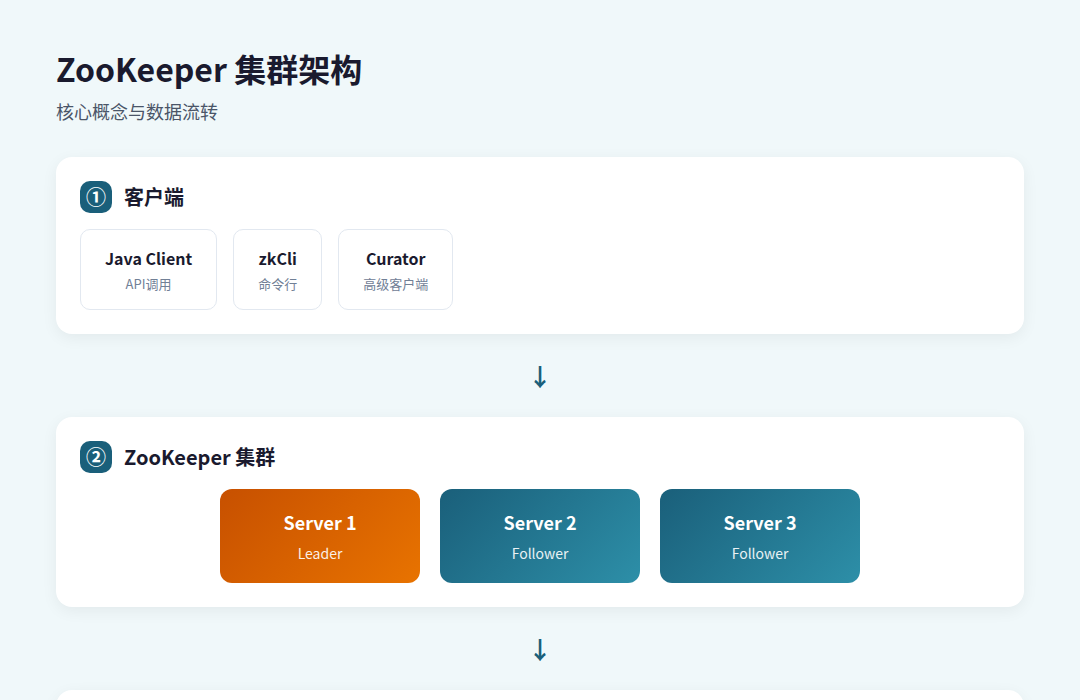
┌─────────────────────────────────────────────────────────────────┐
│ ZooKeeper 集群架构 │
├─────────────────────────────────────────────────────────────────┤
│ │
│ 客户端 ──────────┐ │
│ ├────→ ZooKeeper Server 1 (Leader) │
│ 客户端 ─────┐ │ ↑ │
│ ─┼────┼───────────┼──→ ZooKeeper Server 2 (Follower)│
│ 客户端 ─────┘ │ │ │
│ └───────────┼──→ ZooKeeper Server 3 (Follower)│
│ │
│ 读写流程: │
│ - 写请求 → Leader处理 → 同步到所有Follower → 返回确认 │
│ - 读请求 → 任意Server本地处理 → 返回结果 │
│ │
└─────────────────────────────────────────────────────────────────┘
三、极速起步:环境搭建与避坑
1. 环境准备
本文使用3台CentOS 7服务器进行演示:
| 角色 | IP地址 | 主机名 | 数据目录 |
|---|---|---|---|
| Leader | 192.168.1.101 | zk1 | /data/zookeeper |
| Follower1 | 192.168.1.102 | zk2 | /data/zookeeper |
| Follower2 | 192.168.1.103 | zk3 | /data/zookeeper |
注意:生产环境建议使用奇数台服务器(3、5、7),因为ZooKeeper的投票机制需要多数派同意。
2. 安装 ZooKeeper
在3台服务器上执行相同的安装步骤:
bash
# 创建zookeeper用户(生产环境不建议用root)
sudo useradd -m zookeeper
sudo passwd zookeeper
# 下载ZooKeeper
cd /opt
sudo wget https://archive.apache.org/dist/zookeeper/zookeeper-3.9.2/zookeeper-3.9.2.tar.gz
sudo tar -zxf zookeeper-3.9.2.tar.gz
sudo ln -s zookeeper-3.9.2 zookeeper
sudo chown -R zookeeper:zookeeper /opt/zookeeper
# 创建数据目录
sudo mkdir -p /data/zookeeper
sudo chown -R zookeeper:zookeeper /data/zookeeper3. 配置 ZooKeeper

创建配置文件:
bash
sudo vi /opt/zookeeper/conf/zoo.cfg添加以下内容:
properties
# 基础配置
tickTime=2000
dataDir=/data/zookeeper
clientPort=2181
# 集群配置
initLimit=10
syncLimit=5
# 服务器列表(注意:myid与server编号对应)
server.1=192.168.1.101:2888:3888
server.2=192.168.1.102:2888:3888
server.3=192.168.1.103:2888:3888参数说明:
tickTime:ZooKeeper的时间单元,2000ms一次心跳dataDir:数据快照存储目录initLimit:Follower连接Leader的超时次数(10 × 2000ms = 20s)syncLimit:Follower与Leader同步的超时次数server.1:1号服务器,2888是数据同步端口,3888是选举端口
4. 设置 myid
在每台服务器的dataDir目录下创建myid文件:
bash
# 在192.168.1.101上
echo "1" | sudo tee /data/zookeeper/myid
# 在192.168.1.102上
echo "2" | sudo tee /data/zookeeper/myid
# 在192.168.1.103上
echo "3" | sudo tee /data/zookeeper/myid5. 启动集群
bash
# 在每台服务器上启动
sudo -u zookeeper /opt/zookeeper/bin/zkServer.sh start
# 检查状态
sudo -u zookeeper /opt/zookeeper/bin/zkServer.sh status正常输出类似:
Mode: leader # 或 follower6. ⚠️ 新手必看避坑区
🚨 常见问题预警
问题一:无法选举Leader
ERROR [QuorumPeer:1] java.lang.AssertionError: Could not find file原因 :各服务器的myid未正确设置,或dataDir权限不足
解决:
bash
# 确认myid文件
cat /data/zookeeper/myid
# 确认权限
ls -la /data/zookeeper/
sudo chown -R zookeeper:zookeeper /data/zookeeper问题二:端口被占用
java.net.BindException: Address already in use原因 :2888或3888端口被其他进程占用
解决:
bash
# 检查端口占用
netstat -tlnp | grep -E '2888|3888'
# 杀掉占用进程
kill -9 <PID>问题三:集群脑裂
原因 :网络分区导致集群分裂成多个小集群,各有小leader
解决:生产环境使用5台或7台服务器,并配置3节点TieBreaker
四、主线任务:客户端连接与基本操作
Step 1:连接 ZooKeeper 集群
使用自带的命令行客户端:
bash
# 连接任意一台服务器
/opt/zookeeper/bin/zkCli.sh -server 192.168.1.101:2181
# 连接后进入交互界面
[zk: 192.168.1.101:2181(CONNECTED) 0]Step 2:创建与查询节点
bash
# 创建持久节点
create /service "service registry"
create /service/leader "server-1"
create /service/leader/ephemeral "temp"
# 创建临时节点(服务下线自动删除)
create -e /service/online/server-1 "192.168.1.101:8080"
# 查询节点
ls /service
ls -s /service/leader # -s 显示详细信息
# 获取节点数据
get /service/leader🎯 预期效果:能够创建、查询、获取节点数据,理解持久节点与临时节点的区别。
Step 3:Watch 监听机制
bash
# 监听节点变化
get -w /service/leader
# 在另一个客户端修改数据
set /service/leader "new-server-2"
# 第一个客户端会收到通知
WATCHER ::
WatchedEvent state:SyncConnected eventtype:NodeDataChanged path:/service/leader🎯 预期效果:理解Watch机制,能够实现配置变更的实时通知。
Step 4:Java 客户端操作
java
import org.apache.zookeeper.*;
import org.apache.zookeeper.data.Stat;
import java.util.concurrent.CountDownLatch;
public class ZkClientDemo {
private static final String CONNECT_STRING = "192.168.1.101:2181,192.168.1.102:2181,192.168.1.103:2181";
private static final int SESSION_TIMEOUT = 30000;
public static void main(String[] args) throws Exception {
CountDownLatch latch = new CountDownLatch(1);
// 创建连接
ZooKeeper zk = new ZooKeeper(CONNECT_STRING, SESSION_TIMEOUT, event -> {
if (event.getState() == Watcher.Event.KeeperState.SyncConnected) {
System.out.println("连接成功");
latch.countDown();
}
});
latch.await();
// 创建节点
String path = zk.create("/lock", "lock".getBytes(),
ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
System.out.println("创建节点: " + path);
// 获取数据
Stat stat = new Stat();
byte[] data = zk.getData("/lock", false, stat);
System.out.println("节点数据: " + new String(data));
// 监听节点变化
zk.getData("/lock", event -> {
System.out.println("节点变化: " + event.getPath());
}, stat);
// 关闭连接
zk.close();
}
}🎯 预期效果:能够使用Java客户端连接ZooKeeper集群,执行基本的CRUD操作。
五、脱稚气:生产环境进阶配置
场景一:Leader选举实现
Leader选举是ZooKeeper最核心的功能,用于分布式系统的Leader选举和状态同步。
java
public class LeaderElection {
private ZooKeeper zk;
private String lockPath = "/leader/election";
private String currentNode;
public void electLeader() throws Exception {
// 创建临时顺序节点
currentNode = zk.create(lockPath + "/candidate_",
"".getBytes(),
ZooDefs.Ids.OPEN_ACL_UNSAFE,
CreateMode.EPHEMERAL_SEQUENTIAL);
// 获取所有子节点
List<String> children = zk.getChildren(lockPath, false);
// 排序,找出最小的节点作为Leader
children.sort(String::compareTo);
if (children.get(0).equals(currentNode.substring(currentNode.lastIndexOf("/") + 1))) {
System.out.println("我成为Leader!");
} else {
System.out.println("我成为Follower");
// 监听前一个节点的变化
watchPreviousNode(children);
}
}
private void watchPreviousNode(List<String> children) throws Exception {
int myIndex = children.indexOf(currentNode.substring(currentNode.lastIndexOf("/") + 1));
String previousNode = children.get(myIndex - 1);
zk.exists(lockPath + "/" + previousNode, event -> {
if (event.getType() == Watcher.Event.EventType.NodeDeleted) {
try {
electLeader(); // 重新选举
} catch (Exception e) {
e.printStackTrace();
}
}
});
}
}场景二:分布式锁实现
利用临时顺序节点实现无死锁的分布式锁:
java
public class DistributedLock {
private ZooKeeper zk;
private String lockPath = "/distributed_lock";
private String currentNode;
public void lock() throws Exception {
// 创建临时顺序节点
currentNode = zk.create(lockPath + "/lock_",
"".getBytes(),
ZooDefs.Ids.OPEN_ACL_UNSAFE,
CreateMode.EPHEMERAL_SEQUENTIAL);
while (true) {
List<String> children = zk.getChildren(lockPath, false);
children.sort(String::compareTo);
int myIndex = children.indexOf(currentNode.substring(currentNode.lastIndexOf("/") + 1));
if (myIndex == 0) {
System.out.println("获取锁成功");
return;
} else {
// 监听前一个节点
String previousNode = children.get(myIndex - 1);
zk.exists(lockPath + "/" + previousNode, event -> {
if (event.getType() == Watcher.Event.EventType.NodeDeleted) {
// 前一个节点删除,尝试获取锁
try {
lock();
} catch (Exception e) {
e.printStackTrace();
}
}
});
Thread.sleep(1000);
}
}
}
public void unlock() throws Exception {
zk.delete(currentNode, -1);
}
}场景三:配置中心实现
利用Watch机制实现配置动态更新:
java
public class ConfigCenter {
private ZooKeeper zk;
private Map<String, String> configCache = new ConcurrentHashMap<>();
public void init(String configPath) throws Exception {
// 确保配置节点存在
if (zk.exists(configPath, false) == null) {
zk.create(configPath, "".getBytes(),
ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
}
// 初始化配置缓存
byte[] data = zk.getData(configPath, event -> {
// 配置变更回调
if (event.getType() == Watcher.Event.EventType.NodeDataChanged) {
try {
refreshConfig(configPath);
} catch (Exception e) {
e.printStackTrace();
}
}
}, null);
configCache.put(configPath, new String(data));
}
private void refreshConfig(String path) throws Exception {
byte[] data = zk.getData(path, false, null);
configCache.put(path, new String(data));
System.out.println("配置已更新: " + new String(data));
}
public String getConfig(String key) {
return configCache.get(key);
}
}场景四:集群监控与告警
bash
#!/bin/bash
# ZooKeeper 集群健康检查脚本
ZK_HOME=/opt/zookeeper
ZOOKEEPER_HOSTS="192.168.1.101,192.168.1.102,192.168.1.103"
check_zk_health() {
for host in $(echo $ZOOKEEPER_HOSTS | tr ',' ' '); do
result=$(echo "ruok" | nc -w 3 $host 2181)
if [ "$result" = "imok" ]; then
echo "✓ $host: 健康"
else
echo "✗ $host: 异常"
# 发送告警通知
curl -X POST "https://alert.example.com/webhook" -d "host=$host&status=error"
fi
done
}
check_zk_health六、复盘与彩蛋
🧠 记忆卡片
| 步骤 | 核心动作 | 一句话口诀 |
|---|---|---|
| 安装 | 解压+软链 | 3台起步,奇数台 |
| 配置 | zoo.cfg | tickTime/数据目录/集群列表 |
| 启动 | zkServer.sh | 启动看Mode确认角色 |
| 操作 | zkCli.sh | create/get/set/ls四件套 |
| 生产 | 3节点TieBreaker | 防止脑裂 |
📚 进阶补给站
- 📖 官方文档:https://zookeeper.apache.org/doc/current/
- 🎬 视频教程:尚硅谷ZooKeeper教程
- 🔥 延伸阅读:《从Paxos到ZooKeeper》- 倪超著
⚠️ 常见误区
- 单机部署用于生产:单机无法保证高可用,生产必须3台以上
- 忽视时钟同步:ZooKeeper对时间敏感,集群内必须保持时钟同步
- 数据目录磁盘不足:生产环境要使用SSD或高速磁盘
- 不做监控:必须监控连接数、延迟、堆积等指标
💬 互动话题
你在使用ZooKeeper的过程中,遇到过哪些奇葩问题?有没有什么独家的排坑技巧?araf 在评论区留言,帮助大家避坑!
如果觉得本文有帮助,记得点个赞。需要本文的完整Demo代码吗?可以私信我获取。
本文相关配置和脚本已整理在GitHub仓库中,有需要的朋友可以自取。