1. 冯诺依曼体系结构
1.1 基础概念
冯・诺依曼体系结构是现代计算机的经典基础架构,核心思想是采用二进制、存储程序并由控制器自动执行。它主要由五大部件组成:输入设备、输出设备、运算器、控制器、存储器。该结构规定程序和数据以二进制形式共同存放在内存中, 即冯诺依曼体系结构当中的存储器,大家可以直接理解为内存。计算机按顺序自动读取指令并执行,奠定了现代计算机的基本工作模式。
我们常见的计算机,如笔记本、台式机等;不常见的计算机,如服务器。其大部分都遵守冯诺依曼体系:
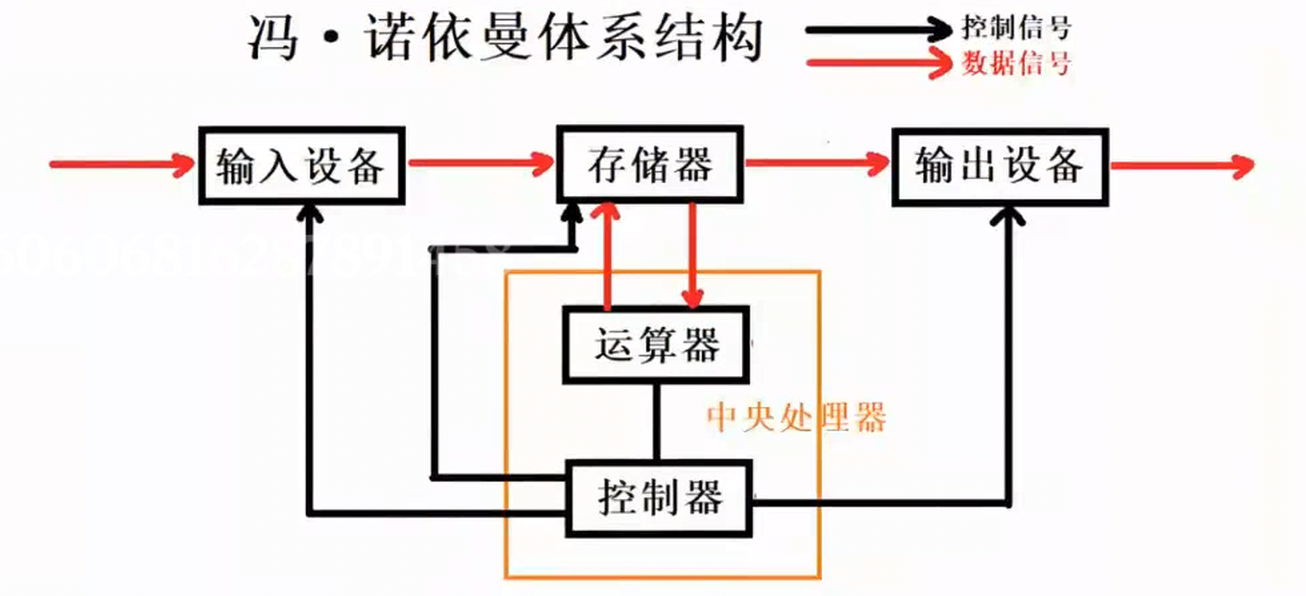
截至目前,我们所认识的计算机,都是由一个个的硬件组件组成:
输入单元 :包括键盘、鼠标、扫描仪、手写板等;中央处理器(CPU) :含有运算器和控制器等;输出单元:显示器、打印机等。
1.2 体系中内存的重要性
接下来有一个比较重要的问题:**为什么冯诺依曼体系结构当中需要内存?**为了能更好的理解这个问题,我们有两个前置知识点需要掌握:
1. 存储分级的问题
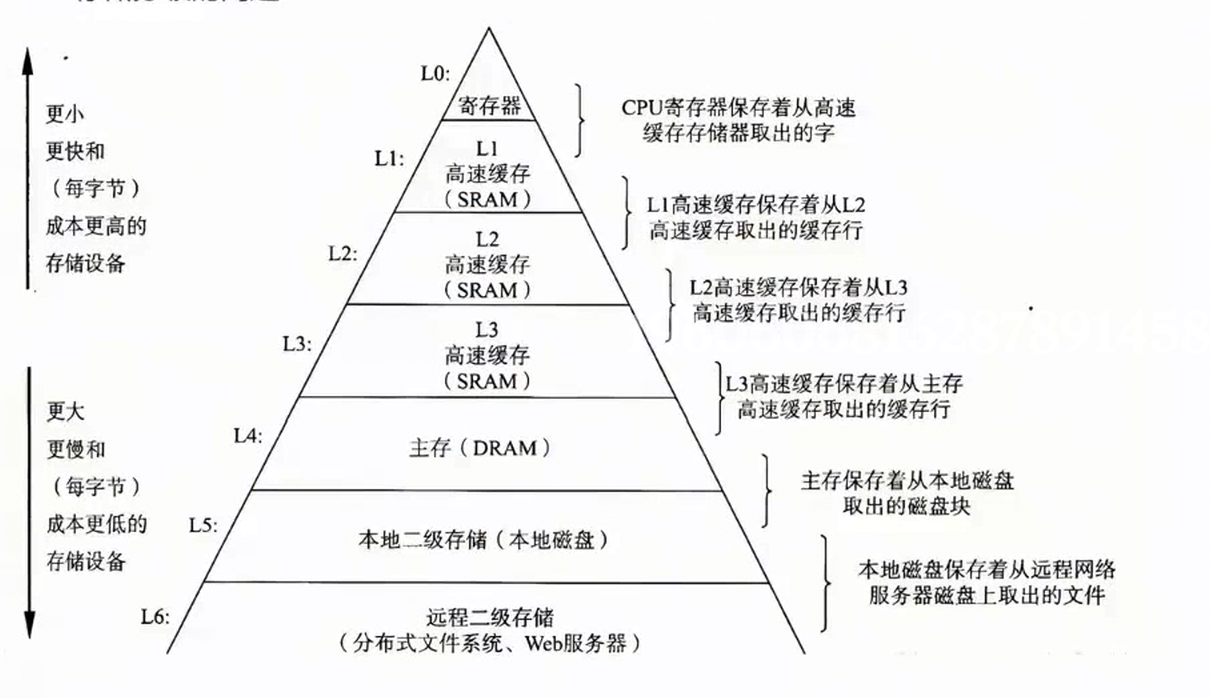
这张图片展示了计算机存储层次结构 ,核心特点是从上到下,速度变慢、容量变大、成本变低。
具体分级如下:
- L0 寄存器:处于最顶端,速度最快、容量最小、成本最高,由 CPU 直接使用。
- L1/L2/L3 高速缓存:依次围绕寄存器,均为 SRAM 材质,用于缓解 CPU 与主存的速度差,层级越高,容量越大、速度稍慢。
- L4 主存:即内存(DRAM),容量远大于缓存,是程序运行的主要内存空间,从磁盘加载数据供 CPU 使用。
- L5 本地二级存储:如本地磁盘,容量更大、速度更慢,用于长期保存数据。
- L6 远程二级存储:如远程服务器、网络文件系统,是最大规模的存储层级,通过网络访问。
整个结构通过数据逐级缓存的方式,平衡了存储设备速度与容量的矛盾,最大化提升计算机整体存储访问效率。
2.体系结构效率问题
因为输入设备的处理数据的速度是毫秒级,但是CPU的处理速度是纳秒级,如果说输入设备直接和CPU对接,就会导致数据处理时间的冗余。因为CPU一直要等输入设备把数据处理好发给它。因此就需要存储器来承担中间人的责任。存储器的作用就是暂时存放正在运行的程序和需要处理的数据,让 CPU 可以快速读写,避免一直等待慢速的外存。如果没有存储器,CPU 会频繁访问低速存储,整体效率会大幅下降。
至此,我们就可以解释到底为什么需要内存(存储器)了。首先,主存速度远快于外存,容量又比 CPU 内部的寄存器、缓存大得多,既解决了 CPU 与外存的速度鸿沟,又能支撑程序完整运行。如果没有高效的主存,CPU 会长期等待数据,整个体系结构的效率会急剧下降。并且因为主存速度相对较快,且容量大,价格相对寄存器更加便宜,就使计算机的制造变得更具有性价比,让普通人能以更合适的价格购买并使用计算机。
而一旦被普通人所更能接受,才能形成全球范围内的网民数量不断增多的迹象,才能形成互联网。
1.3 总结
在数据层面上CPU不会和外设直接打交道,CPU读写数据只会和内存打交道。那么我们口中的输入和输出是站在谁的角度考虑问题的?其实就是站在内存的角度,更准确的说是:站在加载到内存中的程序的角度。
大家在学习C语言和C++的时候,编写代码时都会包含头文件,比如:#include <stdio.h> 、 #include <iostream> ,这两个头文件里面都有 io ,实际上就是 Input 和 Output 。从输入设备到存储器的过程就叫 Input ,从存储器到输出设备的过程就叫 Output。
2. 操作系统
2.1 操作系统的概念
关于操作系统的概念我在之前的文章中已经讲过,为了保证文章的连续性,所以还需要提到这一题目,但详情内容请转至下面这篇文章:
2.2 操作系统的向下运作逻辑
我们首先要记住一句话:操作系统就是一个进行软硬件资源管理的软件。用下面这幅图做进一步解释:
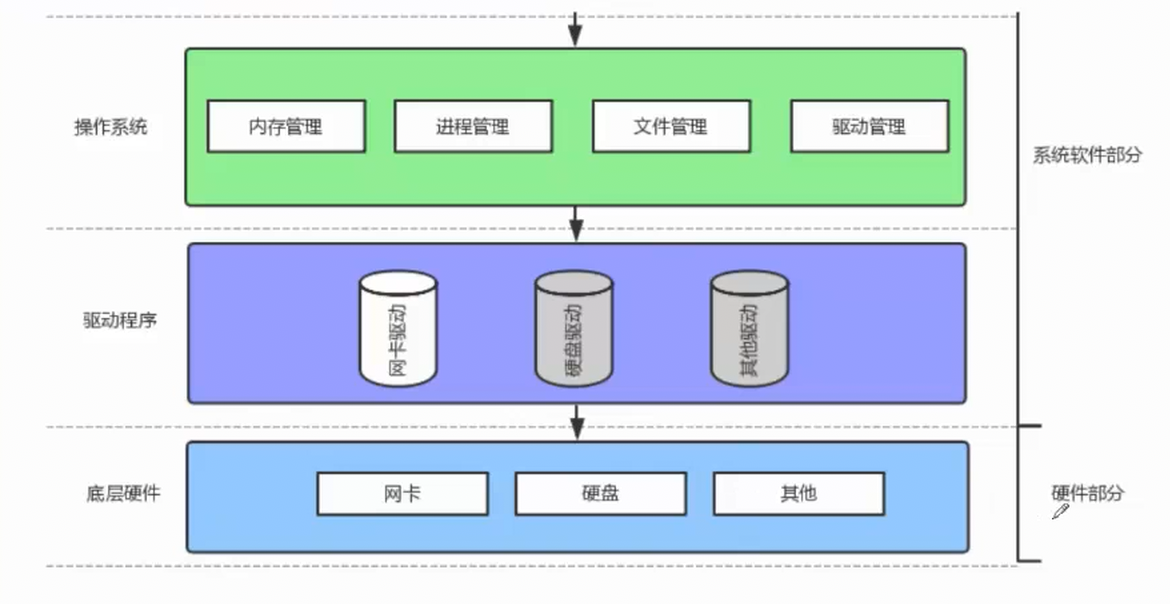
我们可以把整个计算机系统类比成一所学校,三者的层级和分工非常清晰:
1. 操作系统 = 校长
校长是学校的最高管理者,统筹全校所有事务,对应图中最上层的系统软件部分。就像校长负责全校的人员调度(进程管理)、资源分配(内存管理)、档案管理(文件管理)、对接各部门负责人(驱动管理)一样,操作系统是整个计算机的核心管理者,统一调度所有软硬件资源,给上层应用提供稳定的运行环境,同时向下对接所有硬件的管理需求。校长不会直接去管每一个学生的具体事务,只需要对接各部门的负责人。
2. 驱动程序 = 辅导员
辅导员是校长和学生之间的桥梁,对应图中中间的驱动程序层。就像每个辅导员负责对接特定的学生群体(比如网卡驱动对应网卡硬件、硬盘驱动对应硬盘硬件),驱动程序是操作系统和底层硬件之间的翻译官:它把操作系统下发的通用指令,翻译成对应硬件能听懂的专属命令,同时把硬件的状态、数据反馈给操作系统。没有辅导员,校长无法直接和学生沟通;没有驱动程序,操作系统无法直接操控硬件。
3. 底层硬件 = 学生
学生是学校的执行主体,对应图中最下层的硬件部分。就像网卡、硬盘、其他硬件是计算机的执行部件一样,学生负责完成具体的学习、活动任务:网卡负责收发网络数据,硬盘负责存储数据,就像学生完成辅导员布置的具体任务。学生只听从辅导员的安排,不会直接响应校长的指令;硬件只执行驱动程序下发的命令,无法直接和操作系统交互。
完整流程对应
校长(操作系统)下达 "发送消息" 的指令 → 辅导员(网卡驱动)把指令翻译成网卡能执行的操作 → 学生(网卡硬件)执行操作,完成网络数据发送;同时学生(网卡)把接收的数据反馈给辅导员(网卡驱动) → 辅导员整理后上报给校长(操作系统),完成整个数据流转。三者缺一不可,共同构成了计算机系统的完整运行链路。
用C语言中结构体的知识点来讲解就是:硬件是最底层的实体,比如键盘、网卡、显示器。每一种硬件,都可以看作一个结构体变量 。驱动程序,就是为这个结构体写的操作函数集合 。它定义了怎么初始化、怎么读、怎么写、怎么控制硬件。相当于结构体的成员方法。
操作系统,是一个更大的顶层结构体 。它里面包含了所有硬件的结构体、所有驱动的函数指针。操作系统不直接碰硬件,而是通过调用驱动函数来管理硬件。
至此,我们就可以得出一个结论,在操作系统当中,最重要的就是数据结构,因为只有依靠数据结构,才能去用其对应结构的增删查改的方法,更高效便利的处理数据。
那么就衍生出了一个问题:C++中为什么要有类和STL?因为我们说操作系统本质是一个进行软硬件资源管理的软件,所谓的管理就是先对对象进行描述,再组织合理的方式去执行。总结成六个字就是:先描述,再组织。
所以C++中之所以有类和STL,就是先用类把事物的属性和行为描述清楚,再用 STL 把这些对象高效地组织、管理起来。
类的作用是 "先描述"。它把数据和操作封装在一起,描述出一类对象长什么样、能做什么。没有类,就只能零散地写变量和函数,无法清晰描述一个完整实体。
STL 的作用是 "再组织"。有了描述好的对象后,需要容器、算法、迭代器来存放、遍历、处理它们。STL 提供统一、通用的结构,让我们不用重复写链表、排序等代码,直接组织已描述好的类对象。
所以总结就是:类负责描述世界,STL 负责组织数据;先通过类描述,再用 STL 组织,程序结构才清晰、复用性才强。
2.3 操作系统的向上运作逻辑
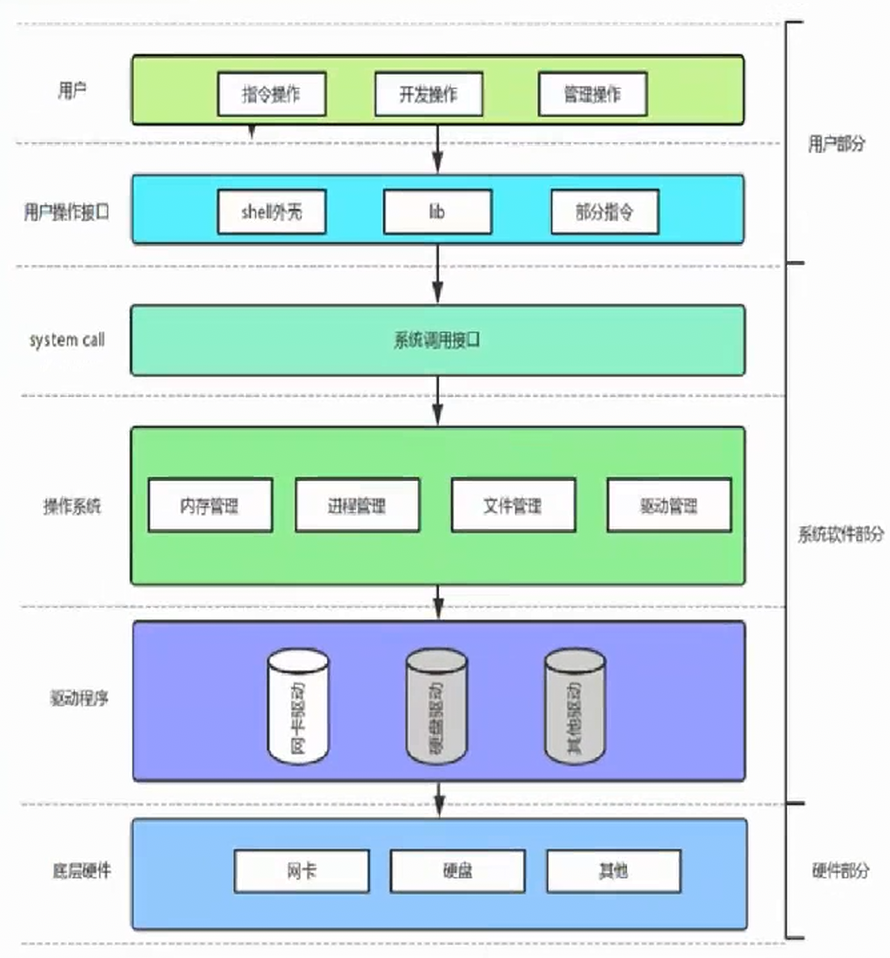
我们前面提到,操作系统要对底层硬件进行管理,本质上的目的,其实是为了给使用操作系统的用户提供一种更高效,更稳定,更安全的操作环境。那么这意味着我们可以随意使用操作系统了吗?它都给我提供安全高效的操作环境了。事实上是不行的。
用户没有办法直接去访问操作系统中的各个数据结构,而是需要通过 system call -- 系统调用接口去间接的使用操作系统,这也是为了保证操作系统内部的数据结构以及数据的安全,防止有用户恶意的去修改操作系统中的内容。
这就好比你要到银行去办理业务,你要办的业务是取钱,那么你必须要到银行中的取钱的窗口,出示身份信息和银行卡等凭证,然后由工作人员帮你办理业务,从银行中取钱。如果没有了这个窗口,那难道让你自己去银行的金库里面直接拿钱吗?这是不现实的。
同样的,比如你现在想要申请开辟一块内存,就需要调用内存管理的系统接口,通过这个系统接口去访问操作系统,然后再给你开辟内存空间。不同的目的会对应不同的系统接口。
再拿银行举例,如果你想去银行办理某个业务,但是对银行的运营流程不太熟悉,此时银行内部的经理就会引导你,帮助你完成你所想要办理的业务,你只需要给他提供一些必要的信息即可。这个大堂经理的身份就相当于**用户操作接口。**就好比我们在学习C语言、C++的时候,调用的各个库函数,本质上就是对系统调用接口的一个封装,即用户操作接口。比如printf、scanf、cin、cout等等。
3. 进程
3.1 基本概念和基本操作
进程是操作系统分配资源和调度运行的基本单位 ,可以简单理解为正在运行的程序。
进程 = 内核数据结构 + 程序的代码和数据
内核数据结构:是操作系统为进程创建的管理信息,比如进程 ID、内存布局、打开的文件、状态等,系统靠它识别、管理、调度这个进程。即下图中的 struct。
程序的代码和数据:是磁盘上可执行文件加载到内存里的指令、变量、常量等,是进程真正要执行和处理的内容。即下图中内存里的可执行程序。
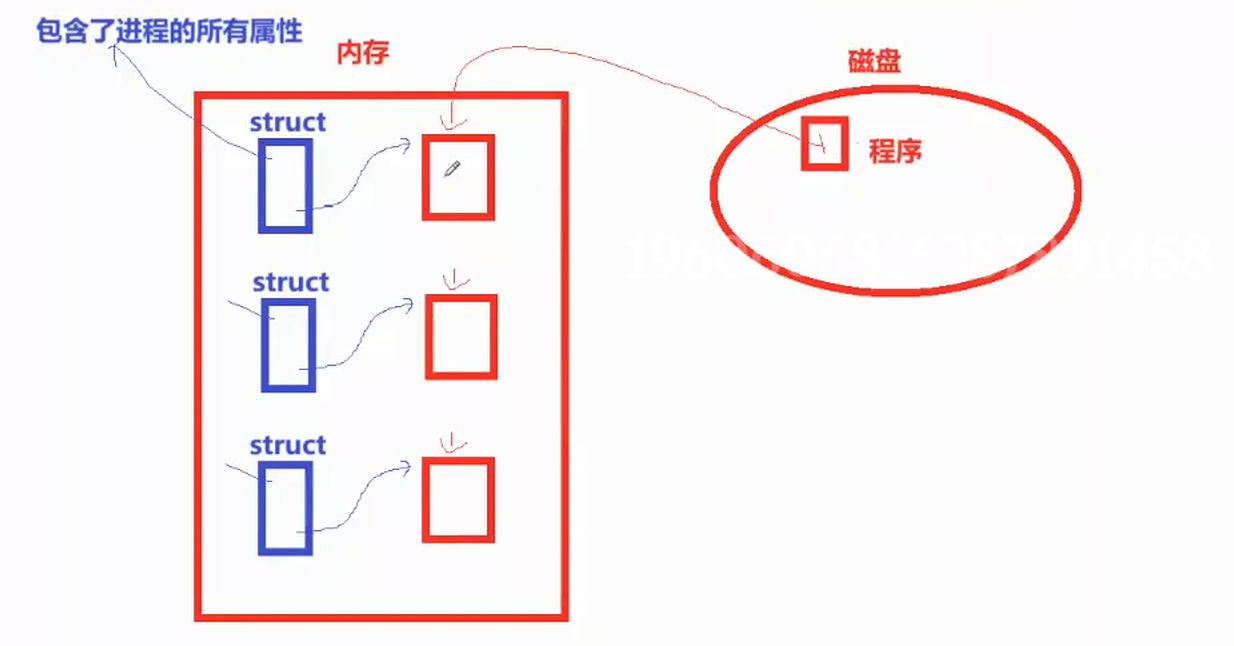
一个程序启动后,先由磁盘转入到内存,然后操作系统为它建立内核数据结构,把代码和数据载入内存,两者合在一起、独立运行、独立占有资源,这就是一个进程。只有内核数据结构,没有代码数据,就只是空壳;只有代码数据,没有内核管理结构,系统无法识别和运行。两者合在一起,被系统独立调度、独立运行的基本单位,就是进程。
因此,当我们在Xshell里输入 ./cmd 或者手机上点击 app 软件时,本质上都是在启动进程。
3.1.1 进程的描述------PCB
进程信息被放在⼀个叫做进程控制块的数据结构中,可以理解为进程属性的集合。前面我们说了 进程 = 内核数据结构 + 程序的代码和数据 ,那么把进程当作一个集合,PCB 就是描述进程的结构体,全称 Process Control Block(进程控制块)。它是进程在内核里的 "身份档案",没有 PCB,系统就不知道这个进程存在、也无法管理它。
PCB 是一个概念统称 :凡是操作系统里用来描述进程的那个结构体 ,都叫 PCB。不同操作系统,这个结构体的具体名字、实现、成员都不一样,但功能都是描述和管理进程。
PCB 这个结构体里一般包含这些成员:进程标识 :PID、状态(运行 / 就绪 / 阻塞);寄存器信息 :PC 程序计数器、通用寄存器等(切换进程用);内存信息 :代码段、数据段、栈段的地址;资源信息 :打开的文件、占用的设备、优先级;调度信息:时间片、排队信息等。
Linux操作系统下的PCB的名称叫做:task_struct。
3.1.2 task_struct
简单介绍一些task_struct中存储的内容:
- 标识符:描述本进程的唯一标识符,用来区别其他进程。
- 状态:任务状态,退出代码,退出信号等。
- 优先级:相对于其他进程的优先级。
- 程序计数器:程序中即将被执行的下一条指令的地址。
- 内存指针:包括程序代码和进程相关数据的指针,还有和其他进程共享的内存块的指针
- 上下文数据:进程执行时CPU处理器的寄存器中的数据。
- I/O 状态信息:包括显示的 I/O 请求,分配给进程的 I/O 设备和被进程使用的文件列表。
- 记账信息:可能包括处理器时间总和,使用的时钟数总和,时间限制,记账号等。
这是Linux内核的2.6.18版本的源代码,大家就可以看到 task_struct这个结构体:
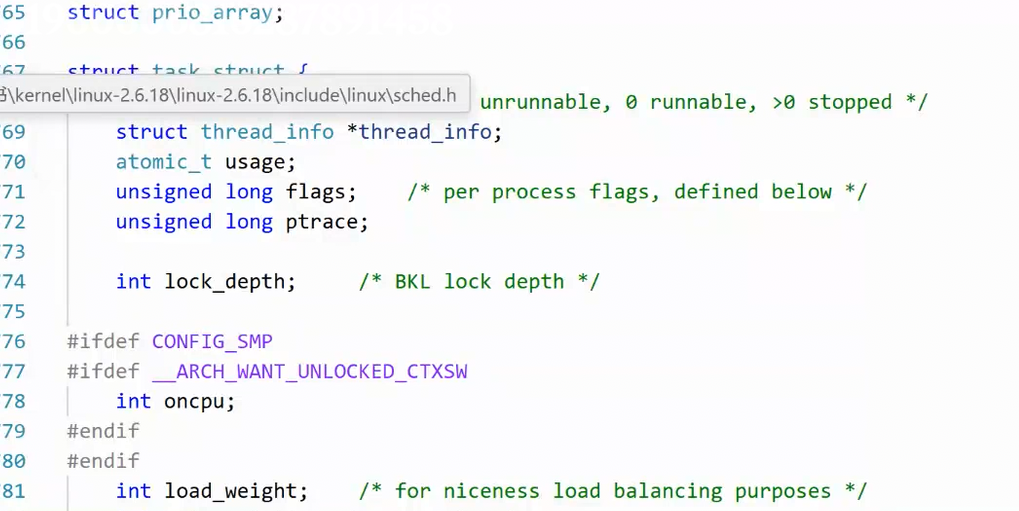
在这里要着重讲的是上下文数据 ,它就是用来保存进程暂停时 CPU 寄存器里的所有内容 ,目的是让进程下次能接着上次停下的地方继续运行。上下文数据被统一封装在了一个结构体当中,这个结构体中有很多个long类型的变量,比如eip、ebp.....等等,这些都是用来存储寄存器中的数据的变量,而寄存器是CPU中的硬件,是 CPU 内部集成的、速度极快的小型存储单元,是实实在在的物理电路,不是软件概念,这些存储单元可以存储数据。
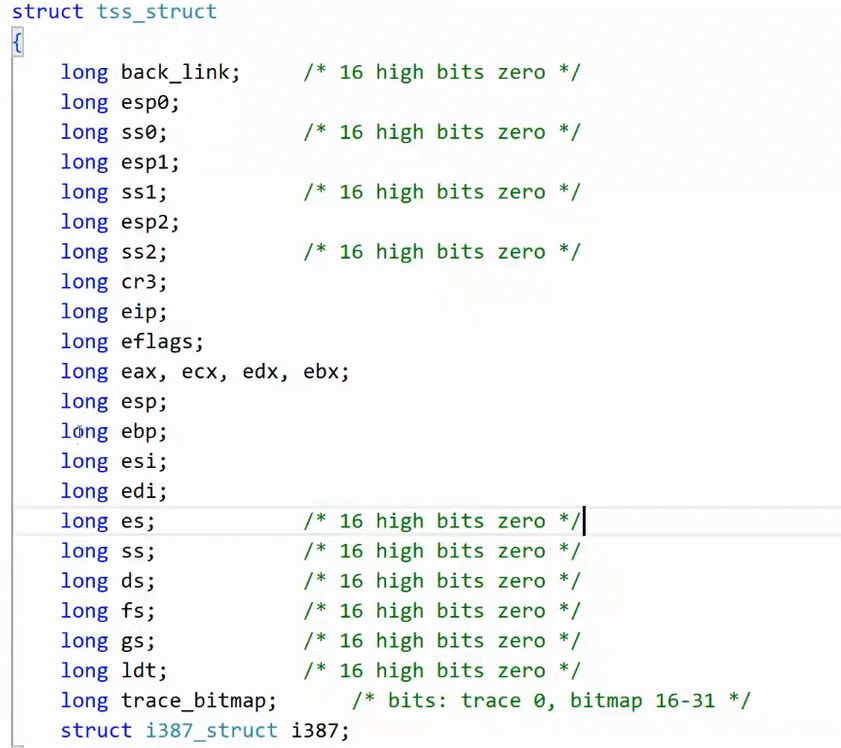
所以上下文数据和task_struct的关系是这样的:

接着要介绍一下时间片的概念,时间片就是操作系统给每个正在运行的进程分配的一小段 CPU 时间 ,比如几毫秒。在这段时间里进程独占 CPU 执行指令,时间片一结束,即分配的这段CPU时间结束了,但如果这个进程还没执行完,但时间片到了 ,操作系统就会直接把它暂停,切换去运行别的进程。
具体过程是这样的:
-
操作系统把当前 CPU 寄存器里的所有数据,保存到这个进程 PCB(task_struct)的上下文数据里,相当于给执行现场拍个快照。
-
把这个进程的状态从运行态改为就绪态,扔到就绪队列里排队。
-
挑选下一个进程,把它 PCB 里的上下文数据恢复到 CPU 寄存器,让它接着运行。
-
等下次 CPU 再次轮到这个进程时,操作系统会把之前保存的上下文数据重新加载回寄存器,进程就从上次暂停的位置继续执行,就像没被打断过一样,完全不会影响最终执行结果。
因为切换极快,人感觉不到停顿,就实现了多个程序 "同时运行" 的效果。时间片决定了进程每次能连续跑多久,是操作系统实现并发调度的核心机制。
所以上下文数据可以这样简单理解:进程在运行时,所有临时数据、运算中间值、当前执行位置,都存在 CPU 寄存器 里。当该进程的时间片结束了,操作系统要切换到别的进程时,必须把寄存器里的所有数据保存一份副本 ,这个副本就是上下文数据,存放在 task_struct 中。等下次该进程再次被调度运行时,内核会把这些数据重新放回 CPU 寄存器,进程就像没被打断过一样继续执行。
int add(int x, int y)
{
int z = x + y;
return z;
}
int main()
{
int result = add(1, 2);
return 0;
}以这段代码为例假设当前进程正在执行 add 函数,CPU 里的寄存器已经存了:x=1、y=2、z=3,正要执行 return z。这时候操作系统时间片到了,要切去别的进程运行。
内核就会把此刻 CPU 寄存器里的这些数据,全部保存到该进程 task_struct 的上下文数据 中。等下次该进程重新被调度时,内核再把这些值恢复回寄存器,进程就能继续执行 return,把 3 传给 result。
这里的上下文数据,就是进程被打断时寄存器里的现场快照,作用是保证切走再切回来后,运算状态不丢失、能接着运行。它只管进程切换时的状态保存恢复,不管函数之间怎么传值。
3.1.3 查看进程
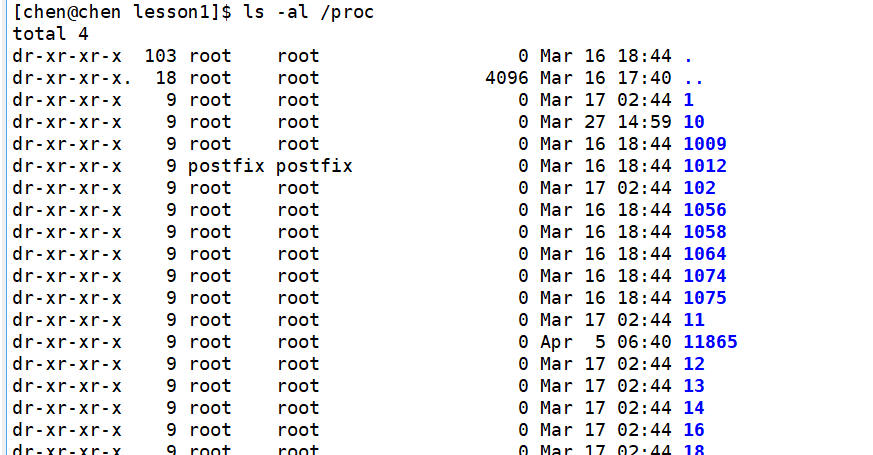
在我们的根目录当中,会存在着一个叫做 proc 的文件夹,它实际上就是 process 的意思。我们使用 ls -al /proc 的这个指令,就可以查看我们Linux中所有的进程,这些标蓝色的文件名,就是当前正在运行的进程的PID。
那么这个进程PID既然是个文件,里面装的是什么呢?
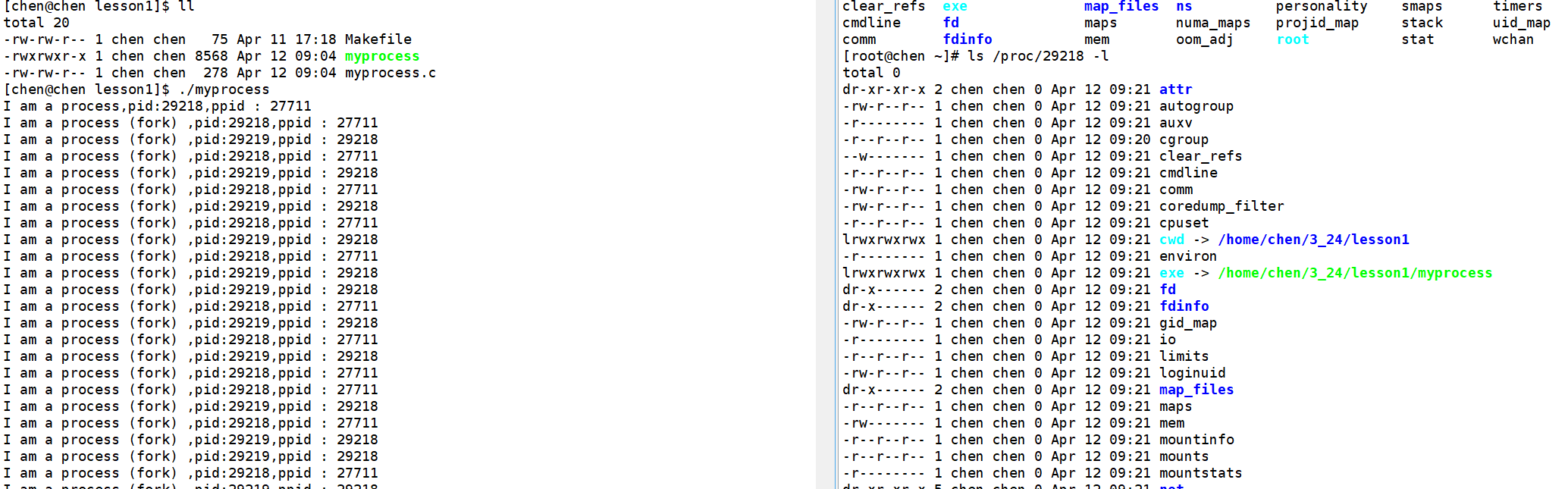
比如现在就有一个进程的PID叫29218,我们通过ls去查看,这里面存储的其实就是这个进程的 task_struct ,即进程的属性。
属性当中最着重要讲的是 cwd :
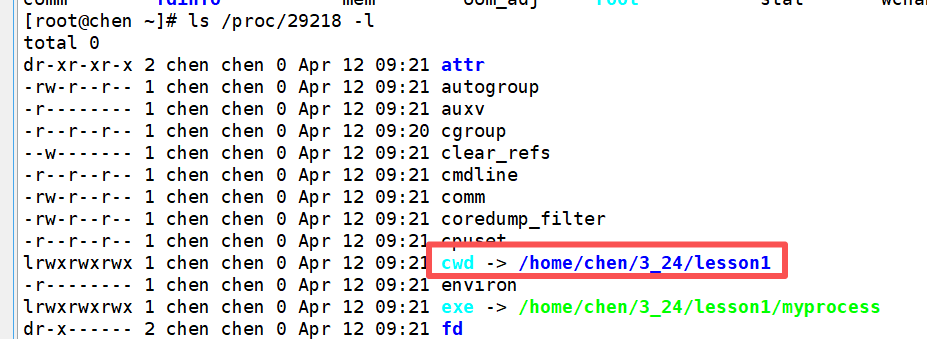
cwd 全称为 current working directory ,即当前工作目录,是 Linux 内核进程控制块 task_struct 中的核心属性,用于记录进程运行时所在的默认文件系统目录 ,是进程访问文件、解析相对路径的默认参照位置。每个进程独立拥有专属的 cwd,互不干扰,内核通过该字段完成进程的相对路径查找与文件定位,是 ./ 等相对路径能够正确生效的底层基础。
我们之前一直使用的 cd 指令,可以实现跳转到指定的路径当中, 而 cd 命令的本质就是通过 chdir ( )系统调用,动态修改当前 bash 进程的 cwd。同时,子进程通过 fork() 创建时会完整继承父进程的 cwd,这也是终端中运行的程序默认工作目录与 bash 完全一致的核心原因。
大家可以回想一下在学习C语言的时候,一定学习过文件管理的内容,那一定会遇到过这样的语句:FILE *fp = fopen ( " xxx.txt","w"); 这个语句当中,我们并没有指定这个文件要放在哪个位置,但系统会自动调用cwd中的信息,将此时的进程的工作路径添加到 xxx.txt 前面。这就是我们创建文件时,会默认放在当前路径下的原因。
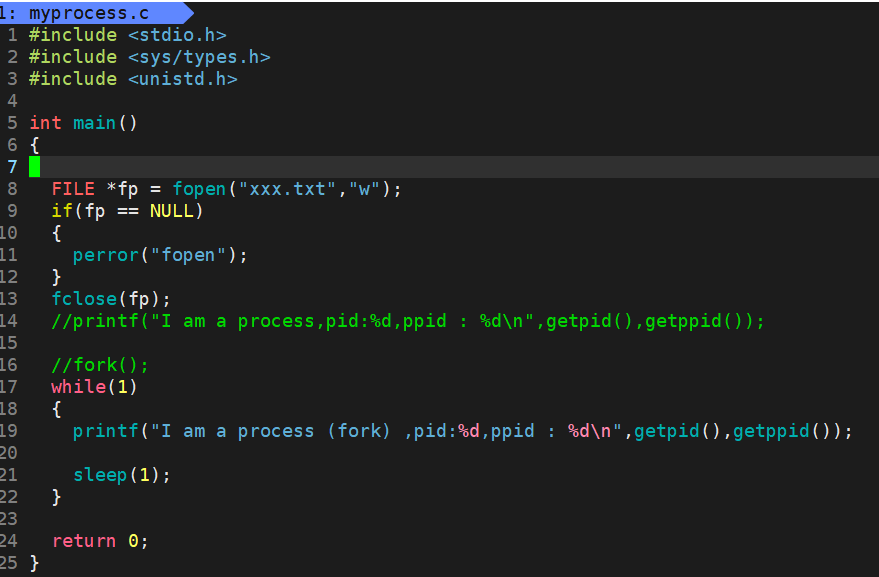

所以当我执行这个程序的时候,就可以直接将 xxx.txt 这个文件直接放在我们的当前路径下。同时,还可以直接调用 chadir 去手动的修改我们要保存的文件的位置:
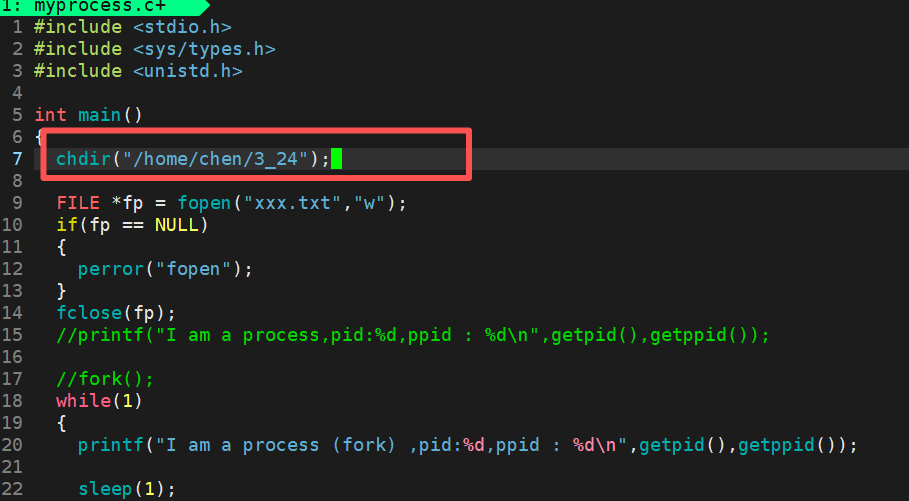

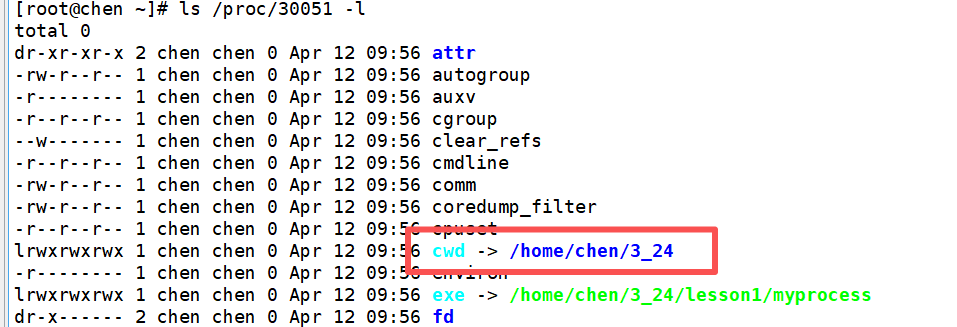
并且此时的进程的 cwd 也被修改了。
3.1.4 进程创建机制
前面我们讲解了进程的概念,那么现在就看看在实际操作系统当中,进程到底怎么表示出来,长什么样子:
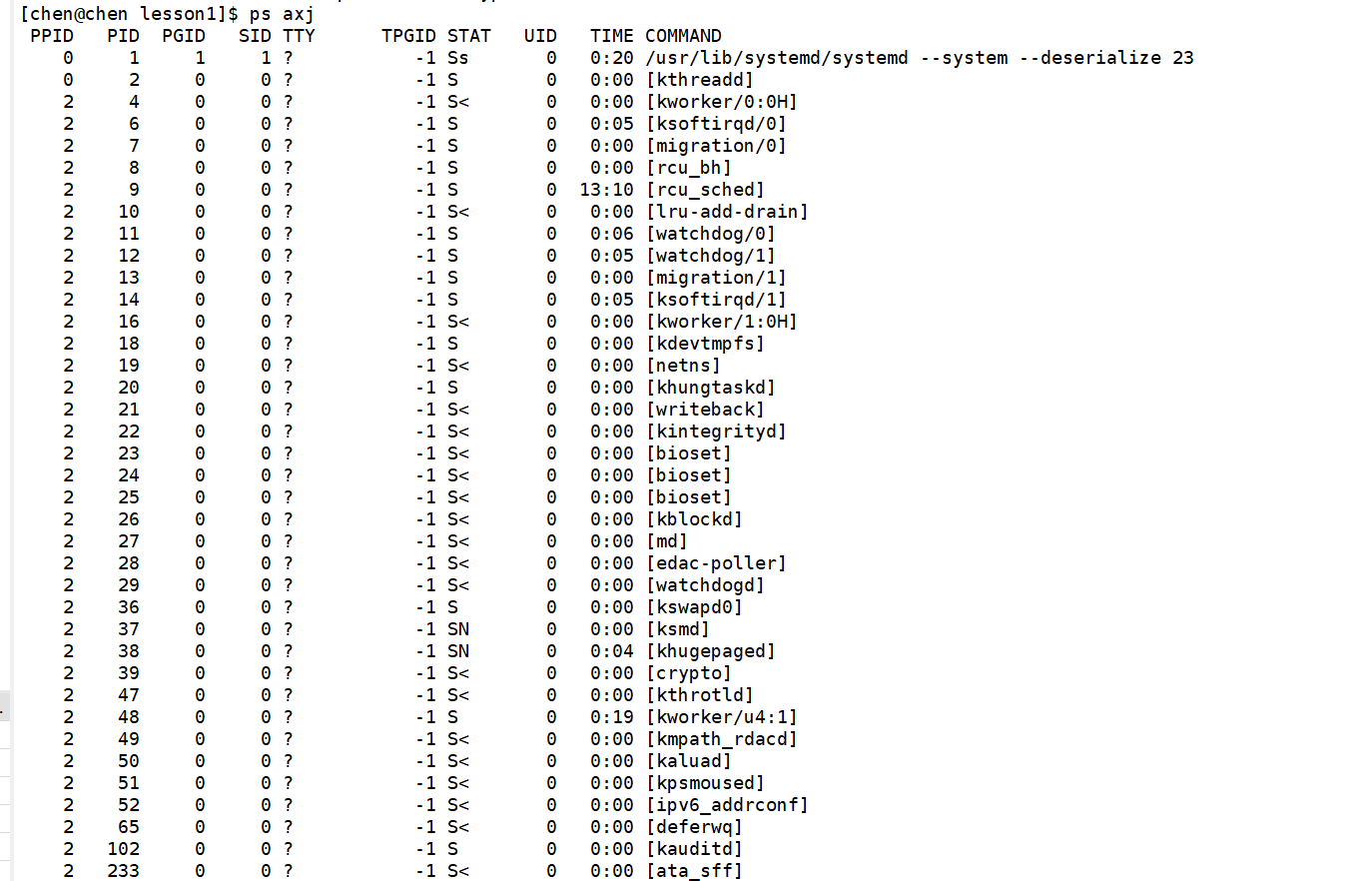
ps axj 是 Linux 下查看进程关系与详细信息的命令,每个字母含义如下:
单个参数含义
- a:显示所有用户的进程(不只当前终端)
- x:显示没有控制终端的进程(后台守护进程)
- j :显示任务控制 / 作业相关信息 ,重点展示:
- PPID(父进程 ID)
- PID(进程 ID)
- PGID(进程组 ID)
- SID (会话 ID)用来清晰看出父子进程关系、进程组、会话
这里ps出来得到的进程的信息,其实就是上面在查看进程中提到的,存储在proc目录下的对应PID文件中的属性信息。
我们先创建一个可执行程序 myprocess:
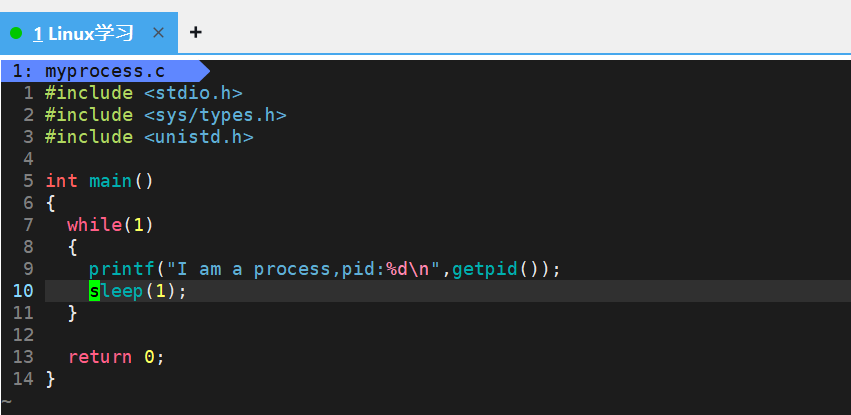
编译后,我们使用组合命令来查找我们编写的可执行程序 myprocess :

大家就可以看到我们可以找到指定的进程。
但是上面还提到了一个PPID,这代表父进程,我们来调用看看:
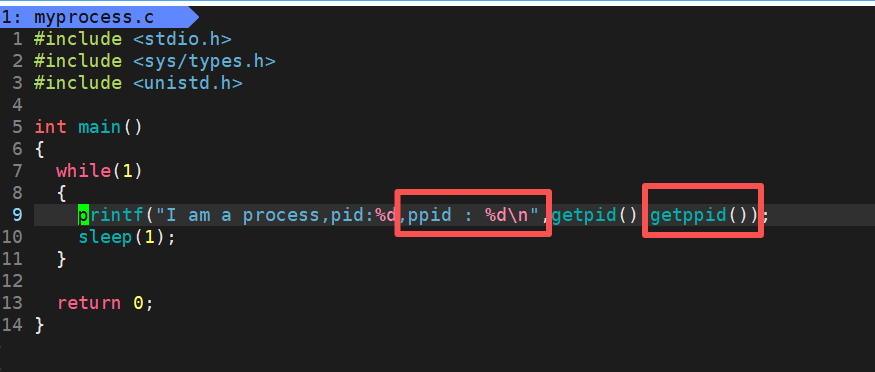
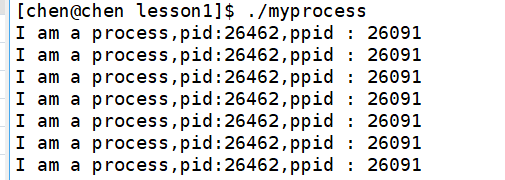
大家会发现父进程ID是一个不同于进程ID的东西,并且如果当我们多次执行myprocess可执行程序时,进程ID会发生变化,但父进程ID会一直保持不变:
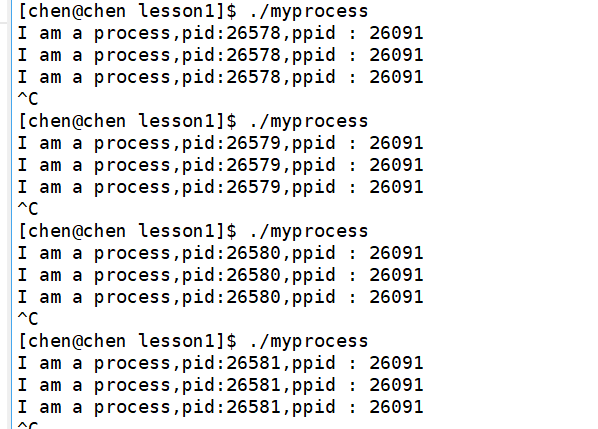
进程ID从26578变化到26581,但是父进程ID一直保持是26091。
首先要解释一下,这里的进程ID之所以会呈现递增的样子,是因为:Linux 内核在创建新进程时,会从上一次分配的 PID 往后继续找最小可用值 ,而不是每次都从 1 开始扫。在此场景中,前序进程退出后 PID 立即空闲,新进程直接接续分配,所以呈现 26091 → 26078 → 26058 → 26579 → 26580 → 26581 这样的连续递增。
其次我们来看看这个父进程到底是什么:

大家可以看到这里的父进程是一个 bash 的文件。bash 是 Linux/macOS 系统里最常用的「命令行解释器(Shell)」,就是我们打开的Linux的窗口终端背后的程序,负责把我们输入的命令翻译成系统能执行的操作。
讲到这里,我们现在就具有几个问题:
-
我们一直使用的 ./文件名 这里的 **./**的含义到底是什么?
-
为什么 ./ 就能做到执行一个可执行程序,并且这个程序的进程的父进程还是 bash?
-
为什么一定要有父进程?而不能直接创建一个进程。
这时因为,在 Linux 系统中,输入**./文件名 并不是 ./ 本身具有 "执行" 的魔力,./ 仅表示当前目录**,作用是告诉 Shell 在当前路径下查找可执行文件,避免系统去环境变量 .PHONY 中搜索。真正触发程序运行的,是当前终端的 Shell(通常是 bash)在识别到这是一个可执行文件后,通过调用操作系统内核提供的系统调用完成的。
具体执行流程如下:
- 用户在终端输入
./可执行文件并回车; - bash 解析命令,确认这是一个可执行程序;
- bash 调用**fork ()**系统调用,创建一个与自身相同的子进程;
- 子进程立即调用 exec( ) 系列函数,将自身的代码段、数据段替换为目标可执行文件的内容;
- 最终子进程运行目标程序,而父进程依然是 bash。
因此,我们看到的现象是:每次运行程序,PID 都会变化,但 PPID 始终不变。
至于为什么必须通过父进程创建新进程,而不能 "凭空" 创建一个进程,是由 Linux 的进程机制决定的:Linux 中除了 1 号系统进程(init/systemd)之外,所有用户进程都必须通过 fork() 从已有进程复制产生,操作系统内核并不提供直接 "凭空创建" 进程的接口。
这里的 1 系统进程就是:在 Linux 系统启动过程中,内核完成初始化后,会主动创建第一个用户态进程 ,这个进程的 PID 固定为 1,通常被称为 1 号进程。
早期 Linux 系统中,1 号进程是 init;现代主流发行版(如 Ubuntu、CentOS 7+、Debian 等)则统一使用 systemd 作为 1 号进程。它是整个系统中唯一没有父进程、由内核直接创建的进程,也是系统中所有其他进程的 "共同祖先"。
1 号进程的主要作用包括:
- 负责启动系统各项基础服务(如网络、日志、设备管理、服务守护等);
- 管理系统的启动、运行、关机流程;
- 作为所有孤儿进程的 "养父",回收退出进程的资源,避免产生僵尸进程;
- 维护整个系统的进程树结构。
我们在终端中运行的程序,父进程是 bash;而 bash 的父进程,最终也会追溯到 1 号进程 systemd。
fork() 的设计思想就是 "复制父进程 → 创建子进程",子进程再通过 exec() 切换成真正要运行的程序。这也就意味着,任何用户态可执行程序,在运行时必然存在父进程,而在终端中运行的程序,其父进程就是负责解析命令、管理任务的 bash 进程。
上面的解释当中一直提到 fork ( ) ,这个函数到底是什么呢?
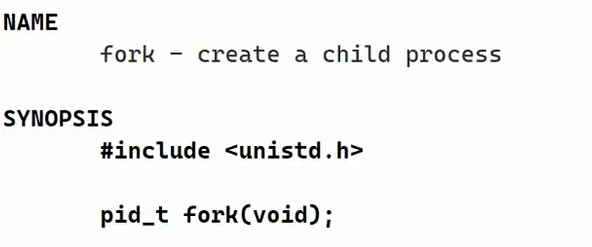
3.1.5 初识 fork ( )
fork ( ) 是 Linux 中用于创建进程的系统调用:在用户态以 C 标准库函数的形式供程序调用,底层通过 CPU 特权指令触发内核态执行,完成子进程的创建与资源分配。
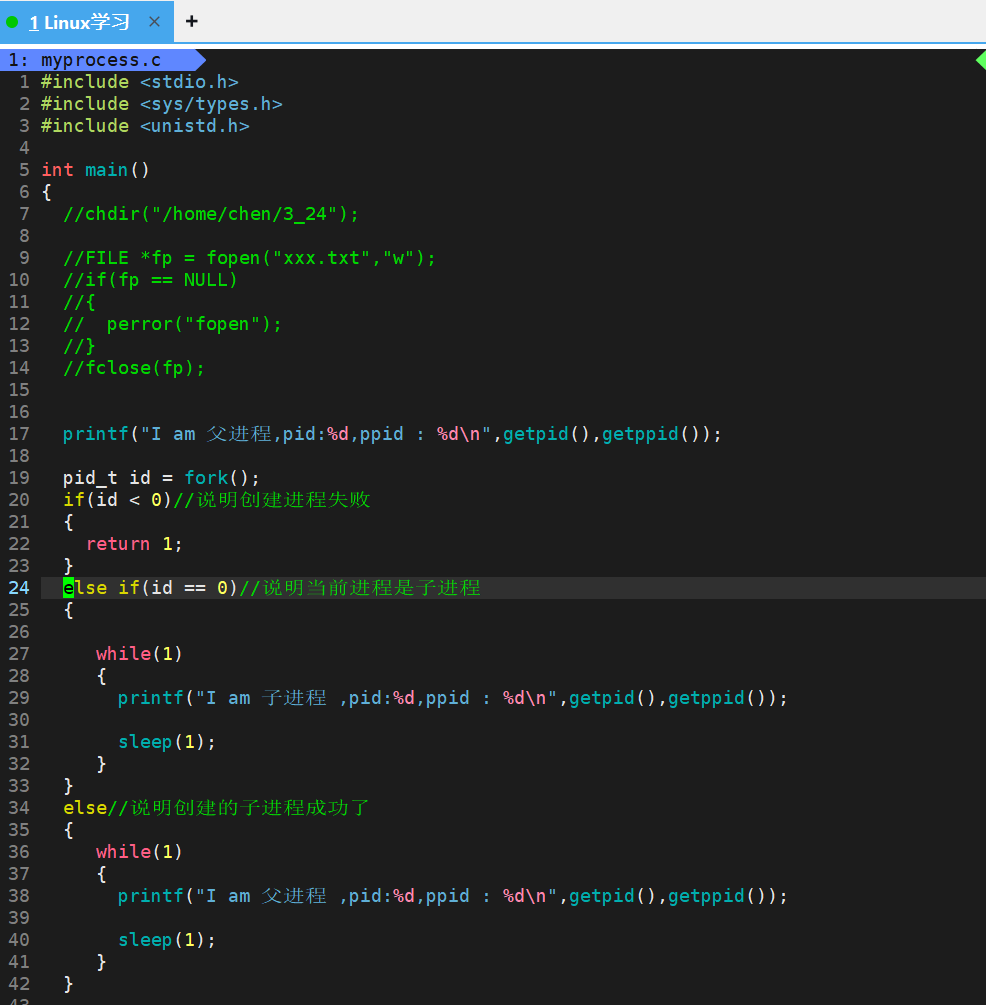
我们用下面的代码先来看看fork的效果:
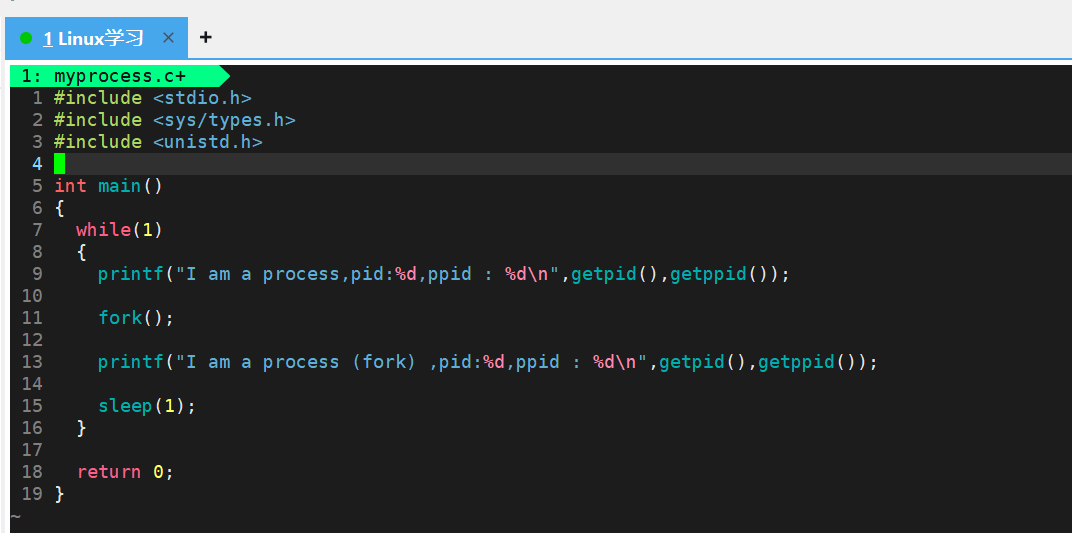
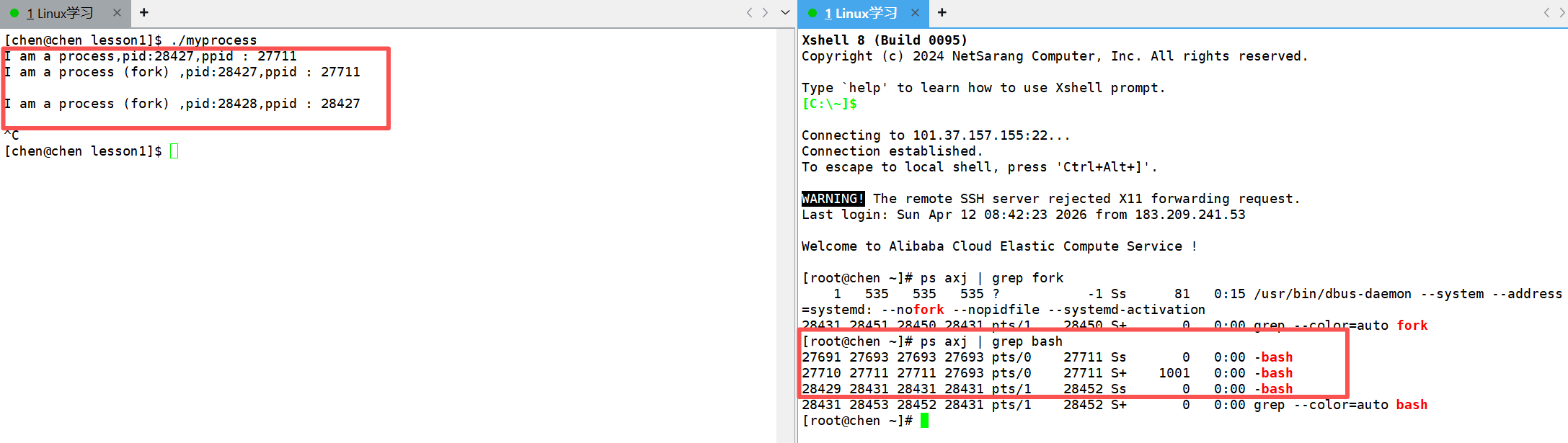
我们会发现,我们源代码中明明只写了两个printf的语句,但是打印出来确是三个语句,并且前两个语句的PID和PPID都相同,第三句语句的PID和PPID和前两个语句的都不相同,并且它的PPID是前两个语句的PID。
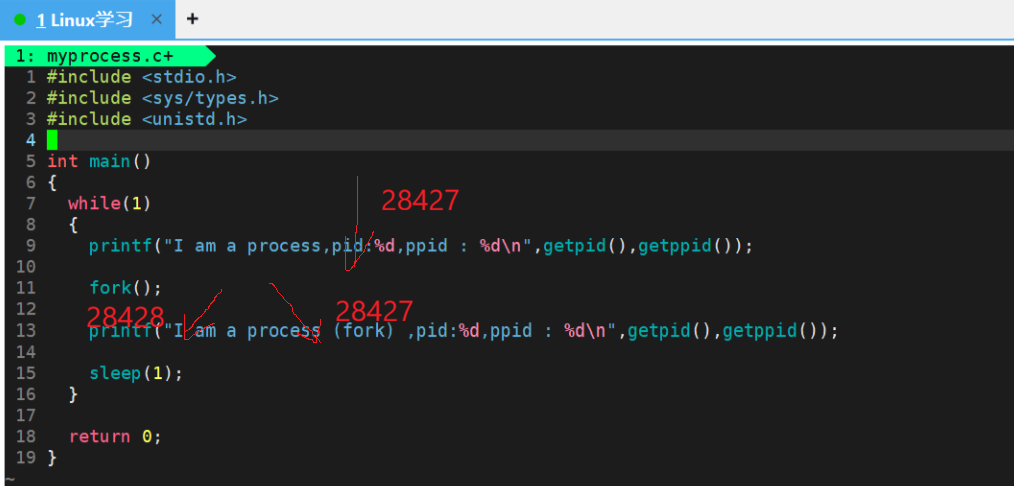
这是因为,程序运行时,bash 首先通过 fork() + exec() 创建 PID 为 28427 的父进程,执行 main 函数中的代码。当父进程执行到 fork() 系统调用时,会复制自身创建一个 PID 为 28428 的子进程,两个进程拥有独立的执行流与 PCB,从 fork() 调用处开始各自独立执行后续代码 。因此,父进程(28427)与子进程(28428)会分别执行两次 printf 输出,最终呈现出两组不同 PID、相同 PPID 的打印结果。
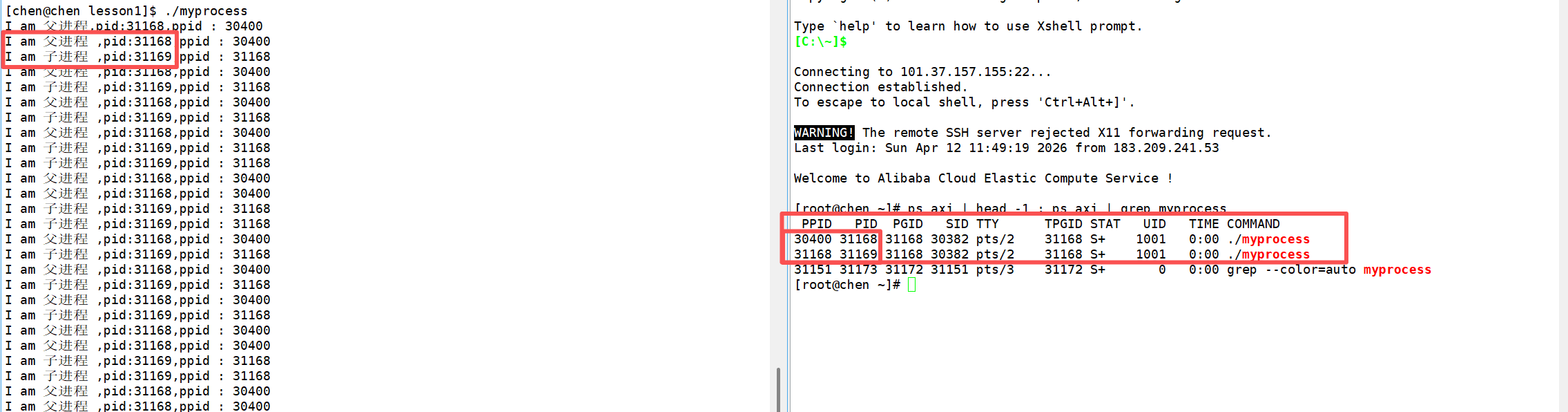
接着我们来改一下代码:
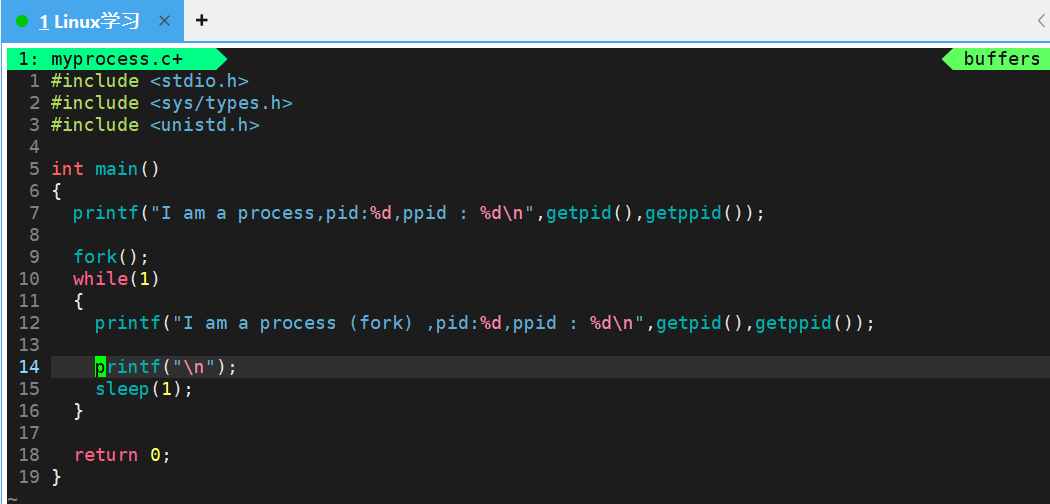
编译运行之后,就会出现这个现象:
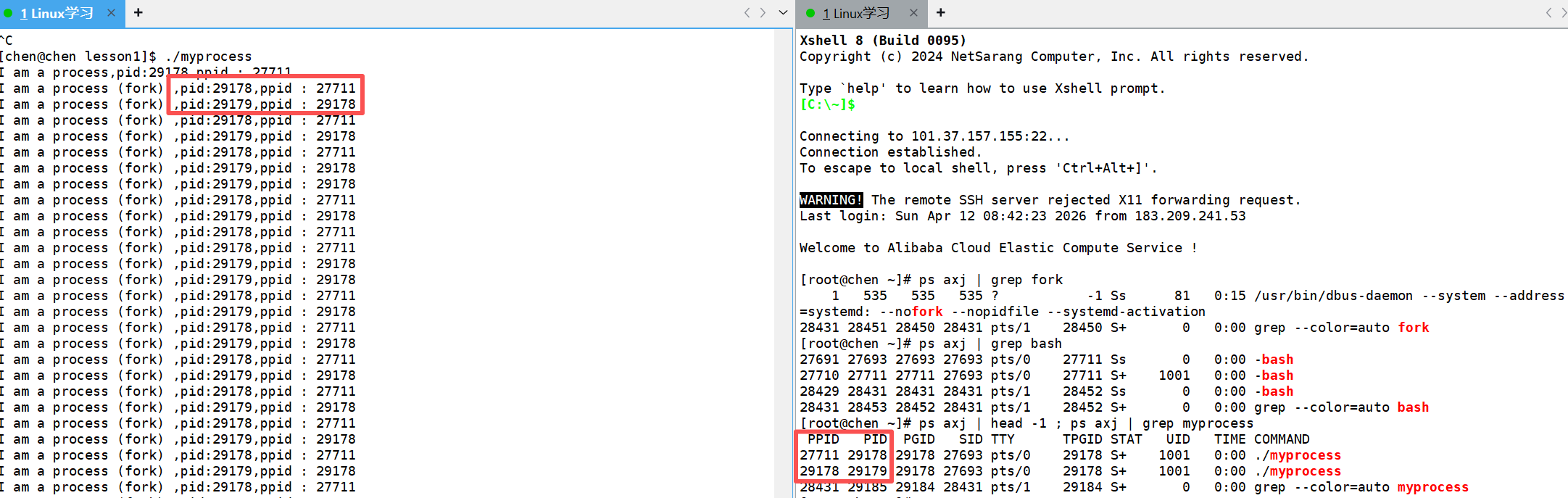
大家会发现,连续的两个fork后的printf语句打印出来的 PID 和 PPID 属于是父子关系,我们通过查看进程,发现也确实存在两个./myprocess ,那么第一个./myprocess的父进程又是谁呢?

查看之后,发现是 bash ,所以这就印证了进程创建的一个父子关系机制。
我们现在已经知道了fork的大致概念,但fork到底有什么实际作用呢?
fork() 的实际作用是复制当前调用它的进程,生成一个子进程 ,从而让系统中从一条执行流分裂为两条独立的执行流 。子进程会继承父进程的大部分运行环境,包括代码段、数据段、堆栈、当前工作目录 cwd、文件描述符、用户权限与环境变量等信息,二者仅在 PID、PPID 等少数标识属性上存在区别。 fork() 被调用后会有两次返回:在父进程中返回新创建子进程的 PID,在子进程中返回 0,程序可以通过返回值区分父子进程并执行不同逻辑。
那既然如此,我们就可以实现利用fork创建子进程,来达到父子进程分流,以解决不同情况下的问题。
不过讲到这里,我们至少有三个问题要问:
1. 为什么给子进程返回的是0,给父进程返回的是子进程的pid?
2. fork() 系统调用,怎么做到返回两次值的?
3. 一个id,怎么能接受两个不同的值? 因为我们代码中的else和else if语句都执行了,即 == 0,又 > 0?
首先回答第一个问题:
之所以给子进程返回的是 0 ,是因为:子进程在 fork () 执行完成后,已经拥有了自己独立的 PID,且可以通过 getpid ()、getppid () 系统调用直接获取自身 PID 和父进程 PID,无需再通过 fork () 的返回值获取自身PID,返回 0 作为子进程的专属标识,用来让程序区分「我现在是子进程」,且不会和任何PID发生命名冲突,因为系统中的进程ID是从 1 开始的。
而给父进程返回的是子进程的PID,是因为一个父进程可以拥有多个子进程,返回一个子进程的PID,可以区分其子进程的身份,以满足进程管理的实际需求。这样操作,才能给父子进程建立联系。
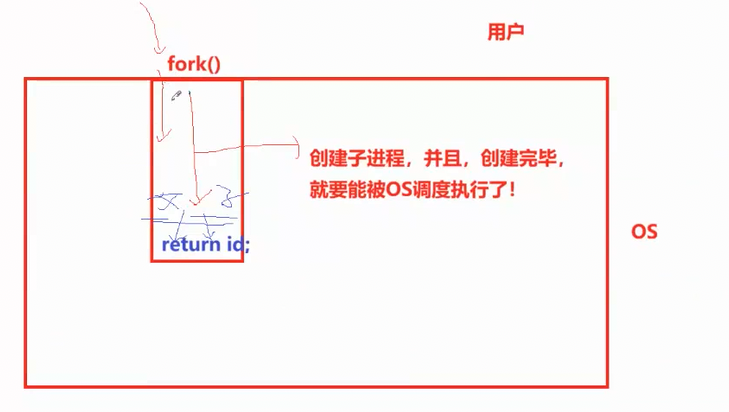
第二个问题:
因为 fork() 执行过程中 会创建出一个全新的独立进程,让两个不同的进程 分别执行了一次 return 操作。当父进程调用 fork() 时,内核会复制父进程的地址空间、执行流与上下文环境,创建出一个几乎完全相同的子进程,父子进程会共享 fork() 调用之后的所有代码逻辑;当进程创建完成后,原本的父进程从 fork() 中返回一次 ,新创建的子进程也从 fork() 中返回一次,两个进程拥有独立的执行流与返回值,从外部视角看就形成了 "一个函数调用返回两次" 的现象,这并不是同一个进程返回了两次,而是两个独立进程分别完成了一次返回。
第三个问题:
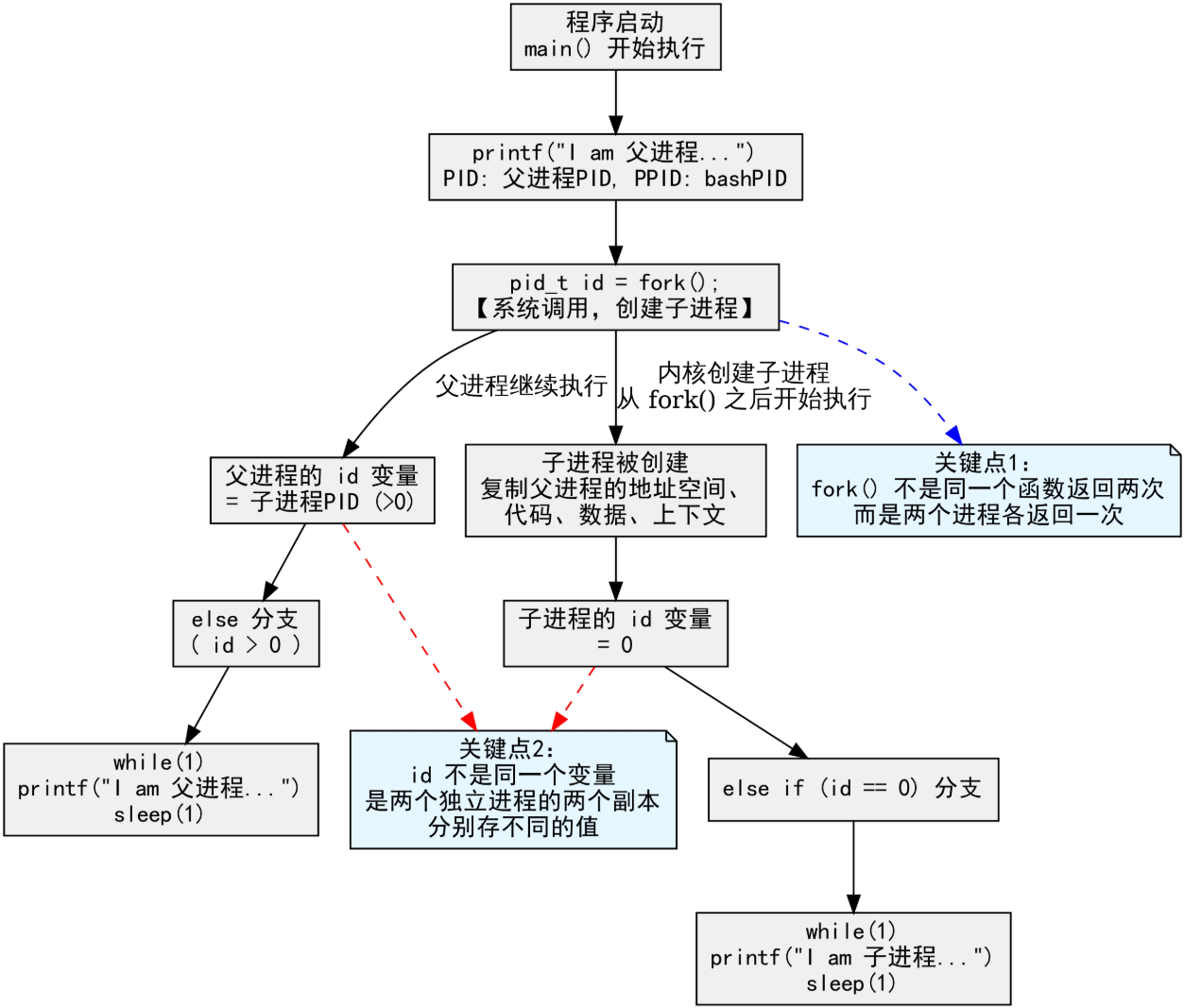
同一个 id 变量能同时等于 0 又大于 0,本质上并不是同一个变量在同一个进程里存了两个值 ,而是 fork() 创建了两个独立进程,每个进程都拥有自己独立的 id 变量副本,两个副本分别存储了不同的返回值,在各自的执行流中独立生效。
当父进程执行 fork() 时,内核会复制父进程的地址空间、栈区数据与执行上下文,创建出几乎完全相同的子进程,id 变量作为栈上的局部变量,会被完整复制到子进程的地址空间中,形成两个完全独立、互不干扰的变量副本。fork() 执行完成后,父进程的 id 变量被赋值为子进程的 PID(大于 0),因此会进入 else 分支执行父进程逻辑;子进程的 id 变量被赋值为 0,因此会进入 else if(id == 0) 分支执行子进程逻辑。从代码视角看,仿佛是同一个 id 变量同时满足了两个条件,但实际上是两个独立进程的两个独立变量,分别存储了不同的值,各自执行对应的分支,不存在同一个变量同时存两个值的情况。
大家可以先这么去理解,因为"内核会复制父进程的地址空间、栈区数据与执行上下文,创建出几乎完全相同的子进程",这句话还是有一点偏于表面,如果我们要从底层角度去深入理解创建子进程的过程,需要讲解虚拟地址空间 和写时拷贝的知识,这两块知识会在后面的段落中提到。
本文到此结束,感谢各位读者的阅读,如果有讲解的不到位或者错误的地方,欢迎各位读者的批评或指正。