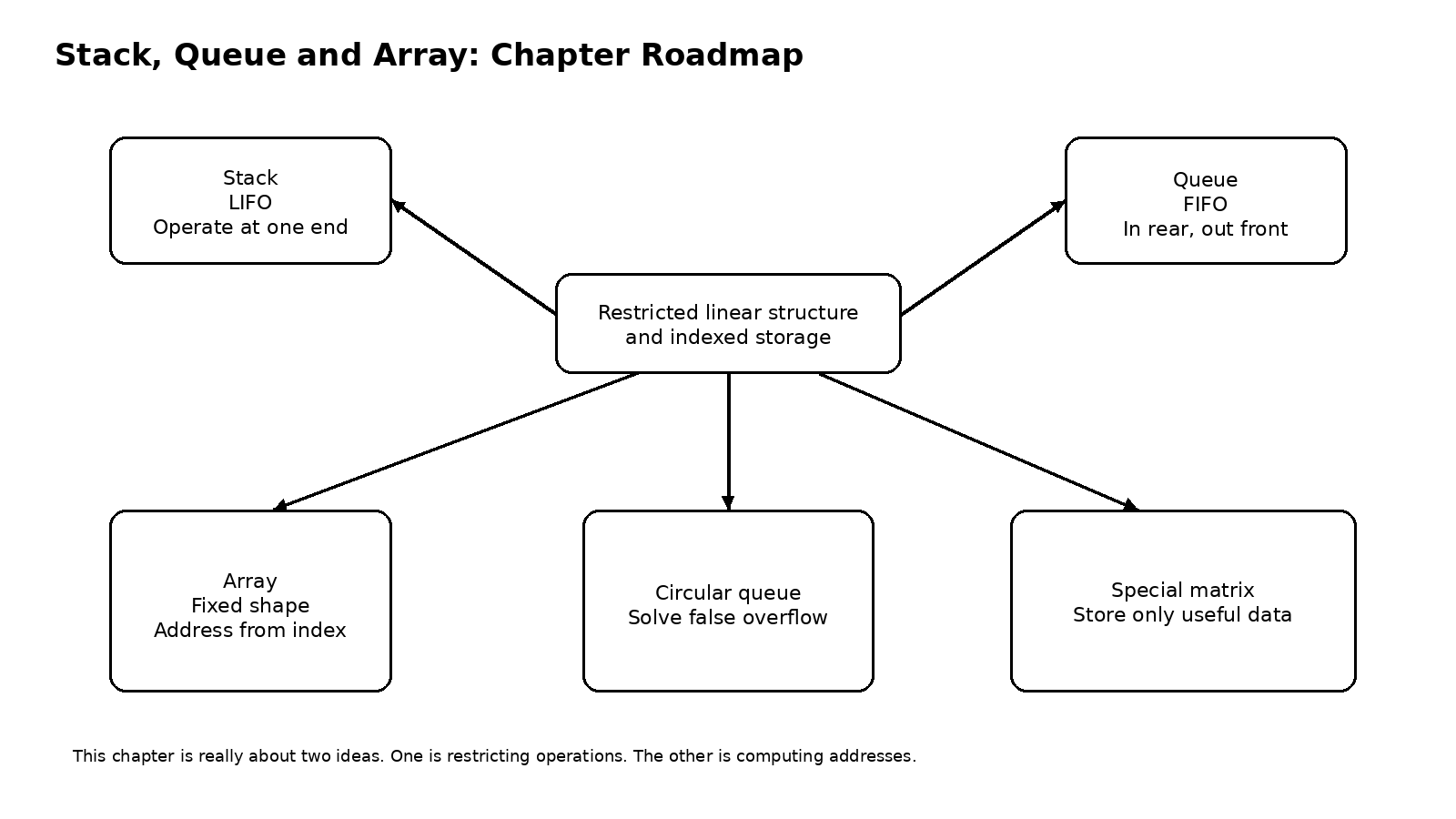
一、为什么栈会是后进先出
栈最容易记住的地方是后进先出,可真正要学懂,不能只停在这四个字上。栈的本质不是神秘,它只是一个只能在一端插入和删除的线性表。也正因为入口和出口是同一个地方,最后放进去的元素会最靠近这个唯一可操作的位置,于是它就会最先被取出来。换句话说,后进先出不是额外规定,而是由操作受限自然逼出来的结果。
所以,栈的定义并不难,难的是把这个约束和应用场景连起来。一旦你意识到栈只有一个口,很多现象都会突然变得非常自然。函数调用时,后调用的函数必须先返回,因为它位于调用路径的最上层。括号匹配时,最近遇到但还没有配对的左括号,必须最先等待检查。深度优先搜索和回溯时,最近进入但尚未走通的状态,也必须最先被撤回。你会发现,很多看起来不同的问题,本质上都带着一种明显的路径回退感,而这正是栈最擅长表达的节奏。
如果从实现的角度看,栈最常见的是顺序栈。顺序栈通常用一段连续存储空间来保存元素,再配一个栈顶指针记录当前最顶端的位置。这样做好处很直接,栈顶元素的入栈和出栈都只在顶端附近完成,不需要移动大量元素,因此时间代价通常是常数级的。顺序栈的核心从来都不是代码有多复杂,而是你要弄清楚 top 究竟指向哪里。有的写法让 top 指向当前栈顶元素,有的写法让 top 指向下一个可插入位置,只要整个实现保持一致,逻辑就是正确的。
一个典型的顺序栈操作可以写成这样:
c
bool Push(SqStack &S, ElemType x) {
if (S.top == MaxSize - 1) return false;
S.data[++S.top] = x;
return true;
}
bool Pop(SqStack &S, ElemType &x) {
if (S.top == -1) return false;
x = S.data[S.top--];
return true;
}这段代码看起来很短,但它已经把顺序栈最重要的动作说透了。入栈时,先让栈顶上移,再把元素放进去;出栈时,先取出栈顶元素,再让栈顶回退。整个过程几乎没有额外动作,所以顺序栈的入栈和出栈都很轻。真正需要留意的,是空栈和满栈的判断条件,而不是操作本身。
当然,栈并不一定非要用顺序存储实现。链栈的思路和链表很接近,只不过我们只在表头一侧操作。这样做的好处是长度更加灵活,不容易受到预设容量的限制。只是从考试和实现习惯来看,顺序栈往往更常见,因为它结构更紧凑,也更符合栈只在一端变化的特点。共享栈则是顺序栈的一个很有代表性的优化思路,它把两个栈放在同一段数组里,一个从左向右长,一个从右向左长。这个设计很值得记住,因为它体现了栈的另一个核心特征,栈顶才是唯一不断变化的区域,其他位置基本保持稳定,因此空间可以被非常灵活地拼接和复用。
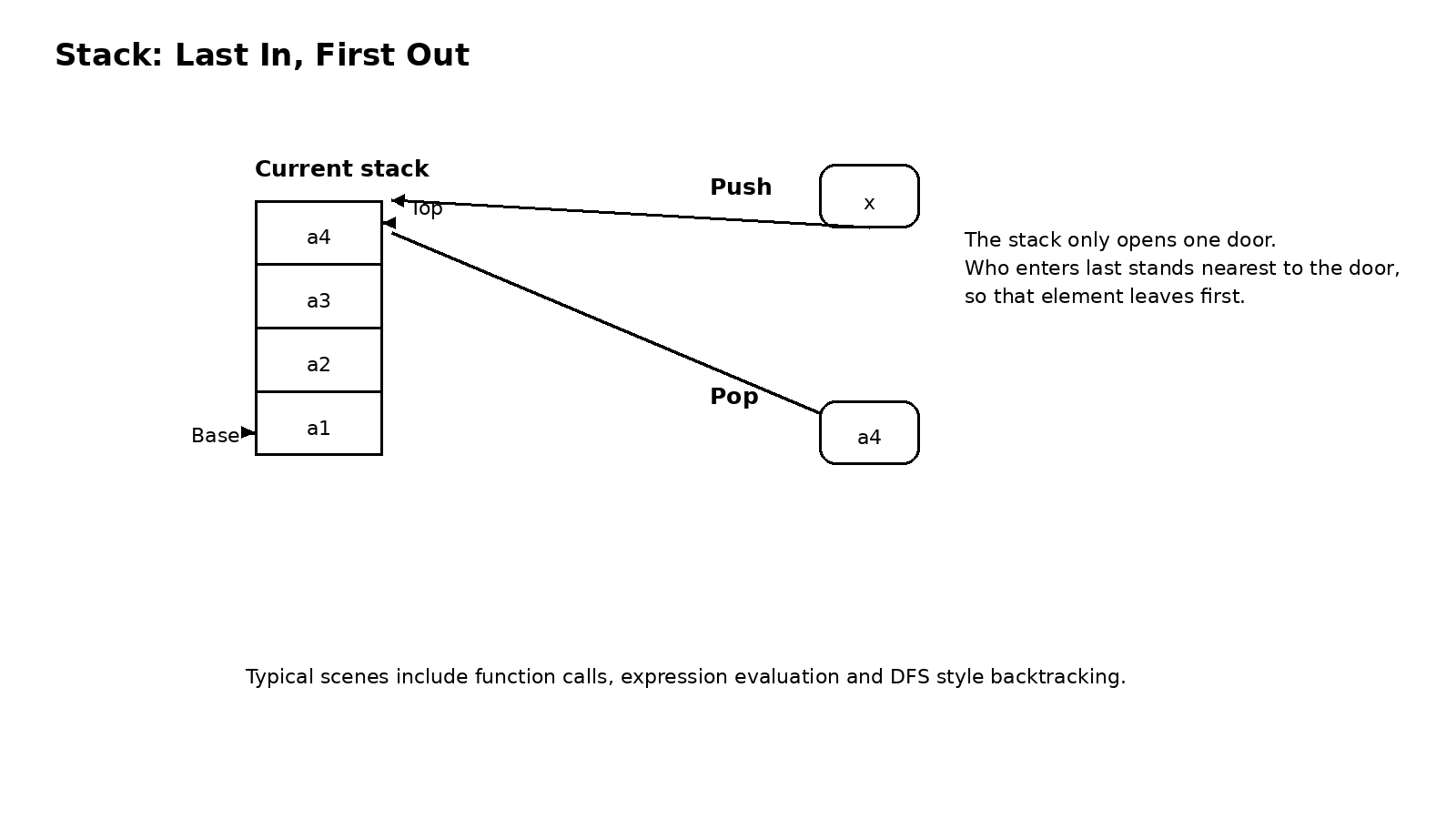
二、队列为什么看起来和栈相反,却不只是反过来那么简单
如果说栈的节奏是后进先出,那么队列的节奏就是先进先出。队列同样来自线性表,但它把插入和删除分配到了不同位置。新元素从队尾进入,旧元素从队头离开,于是最早进入的元素自然最先被删除。和栈相比,队列并不是简单地把顺序颠倒,而是把操作权分成了两个方向,这使它特别适合表达缓冲、排队、调度和按层推进这类过程。
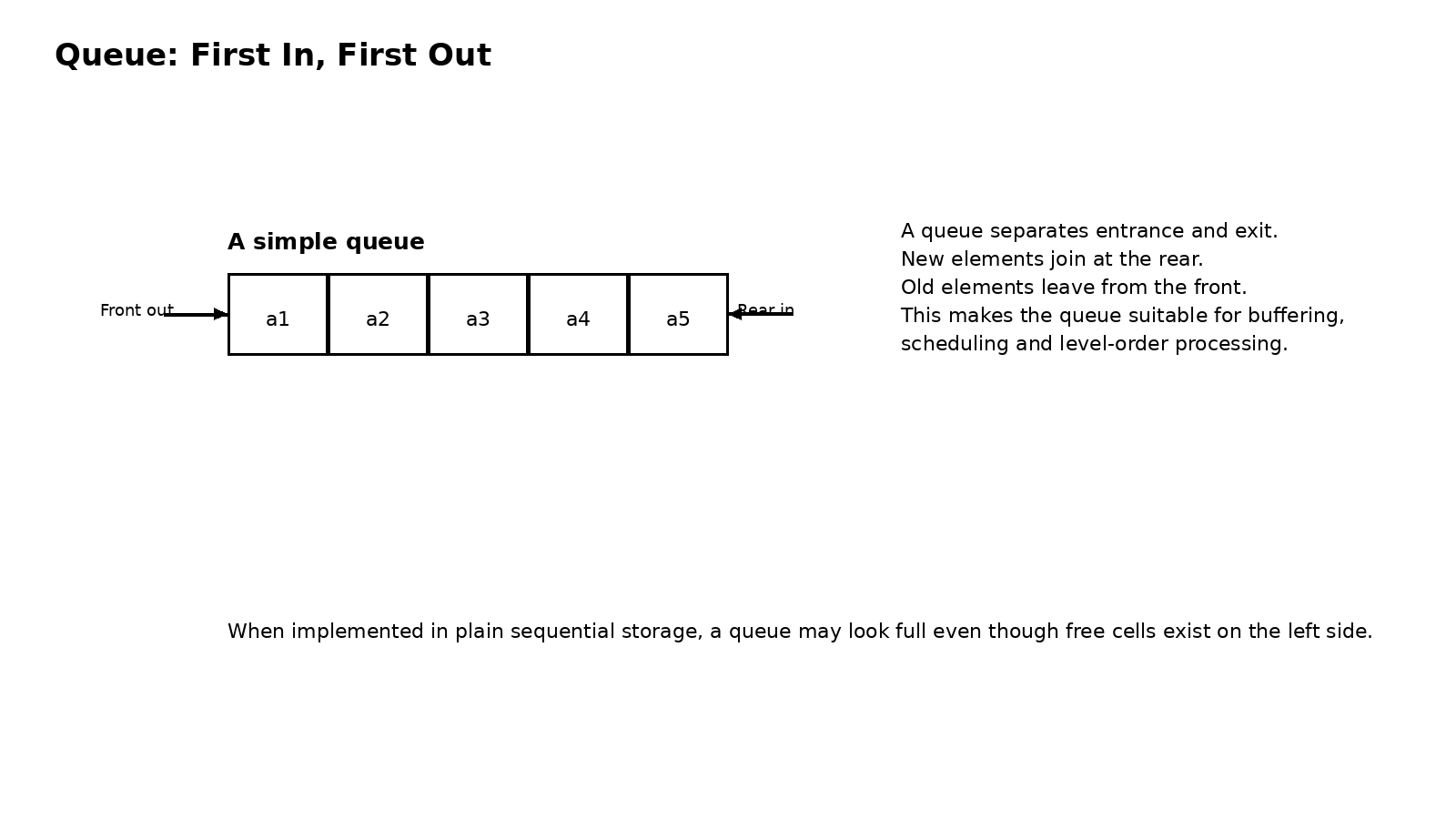
很多人刚学队列时,会觉得顺序队列似乎也不复杂,无非是一个 front 指针和一个 rear 指针。可真正让队列变得有辨识度的,并不是这个定义,而是假溢出问题。在线性顺序队列里,元素不断出队以后,数组前面会出现空位置,但 rear 指针只会向后移动,不会自动回收这些空位。结果就是,明明前面还有空单元,队列却可能被判断为满。这种现象不是逻辑上的满,而是存储方式带来的浪费。
也正因为如此,循环队列才显得格外重要。它不是在原有队列外面额外套一个技巧,而是彻底改变了顺序空间的使用方式。既然数组是一段首尾分明的线性空间,那我就通过取模运算,把它逻辑上接成一个环。这样一来,队头走过的位置,队尾以后依然可以重新利用,原本的假溢出问题就自然消失了。循环队列的美感就在这里,它没有增加什么复杂结构,只是换了一个看待空间的方式,就让原本僵硬的顺序存储重新活了起来。
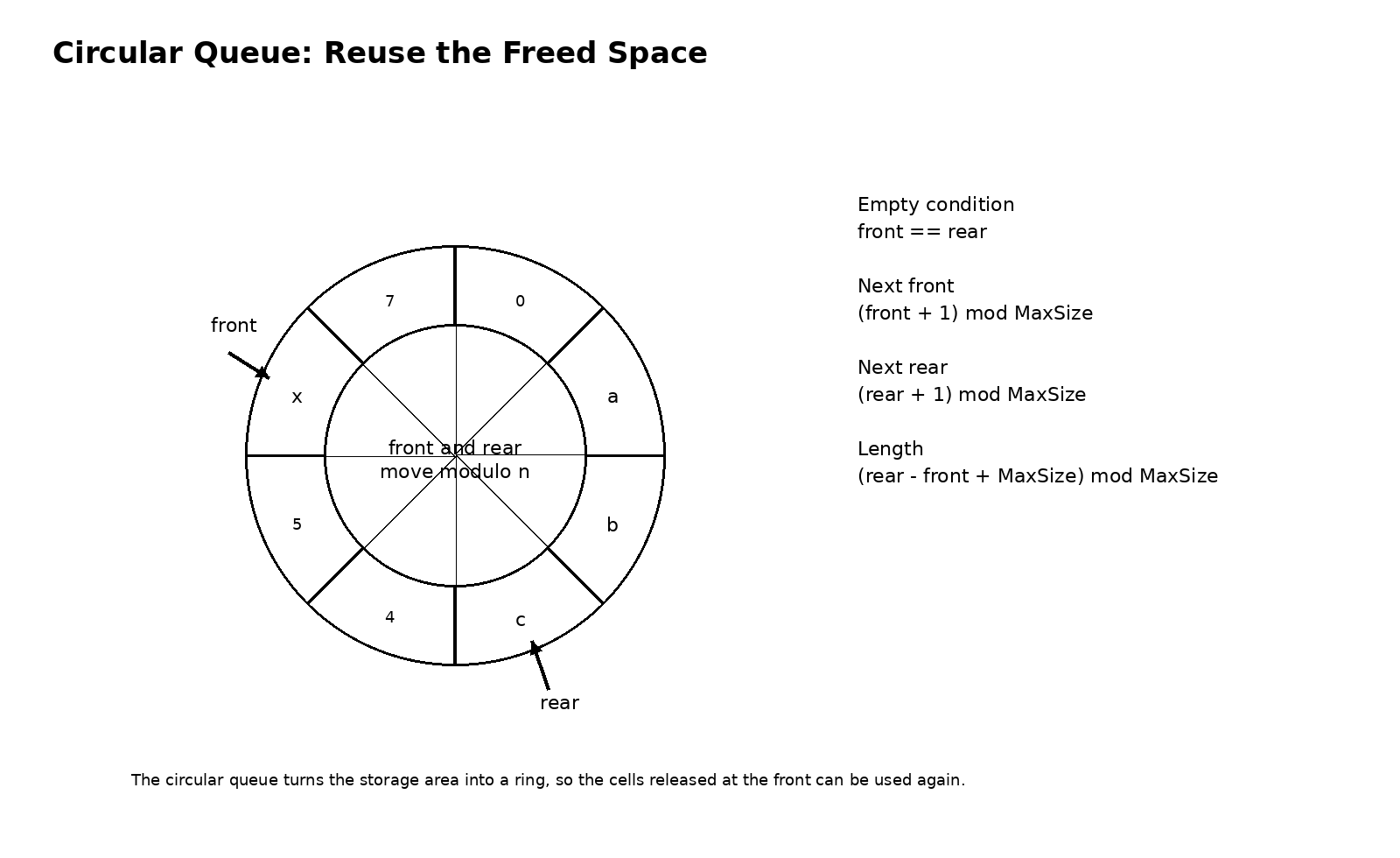
复习循环队列时,最值得真正想透的不是几个公式本身,而是这些公式为什么长成这样。队空通常写成 front 和 rear 相等,因为这意味着队头和队尾落在同一位置,队列中没有有效元素。指针前进要写成加一后再对数组长度取模,是因为逻辑上我们允许它越过数组末端回到开头。队列长度写成 (rear - front + MaxSize) % MaxSize,本质上是在一个环形空间里计算两点间的相对距离。只要你把存储区真正想象成一个环,这些表达式都不再需要死记硬背。
一个典型的循环队列入队和出队可以写成下面这样:
c
bool EnQueue(SqQueue &Q, ElemType x) {
if ((Q.rear + 1) % MaxSize == Q.front) return false;
Q.data[Q.rear] = x;
Q.rear = (Q.rear + 1) % MaxSize;
return true;
}
bool DeQueue(SqQueue &Q, ElemType &x) {
if (Q.front == Q.rear) return false;
x = Q.data[Q.front];
Q.front = (Q.front + 1) % MaxSize;
return true;
}这里最容易混淆的是满队条件。很多教材为了区分空和满,会故意牺牲一个存储单元,让队列最多只能放 MaxSize - 1 个元素。这样做不是浪费,而是换取判断条件的清晰。你可以把它理解成,循环队列为了让状态判定不打架,主动留出了一格缓冲地带。
除了顺序实现,队列也可以做成链式结构。链队列通常会维护两个指针,一个指向队头,一个指向队尾。入队时把新结点挂到尾部,出队时从头部删去结点。它的好处和链表类似,长度更灵活,不必预先申请一整段大块连续空间。只是理解链队列时,一定不要忘了两个边界状态。队列为空时,front 和 rear 往往同时为空。若删除的是最后一个结点,那么出队完成之后,这两个指针都要一起回到空状态,否则结构会残留错误信息。
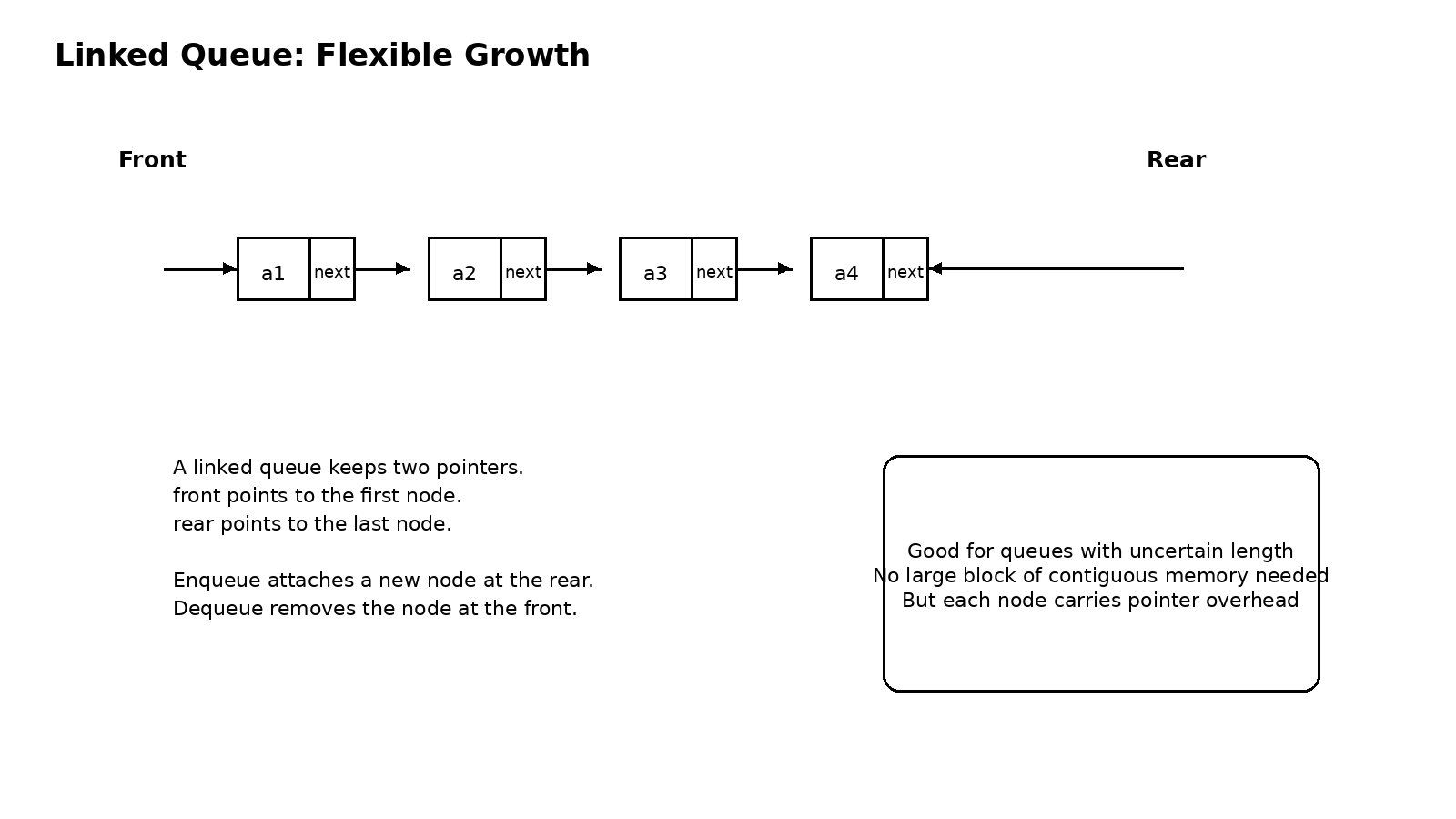
双端队列则是队列思想的进一步延伸。它允许两端都进行插入和删除,因此比普通队列更灵活,也更容易和某些受限规则组合出题。双端队列本身不难,真正容易混淆的是输入受限和输出受限的差别。学这部分时,不必把它看成一个孤立知识点,更好的办法是把它看成队列在操作权限上的再次调整。只要你始终抓住一个问题,哪些端点能进,哪些端点能出,很多性质都能顺着推出来。
三、数组真正厉害的地方,不是能放很多元素,而是地址可以直接算
前面讲栈和队列时,核心一直是操作限制。到了数组,关注点突然从操作位置切换到了地址映射。数组中的元素类型相同,大小一致,且在内存中连续存放,这使得数组最重要的能力不是动态变化,而是可以根据下标直接定位元素地址。也正因为如此,数组特别适合表达那些形状固定、坐标清楚的数据对象。
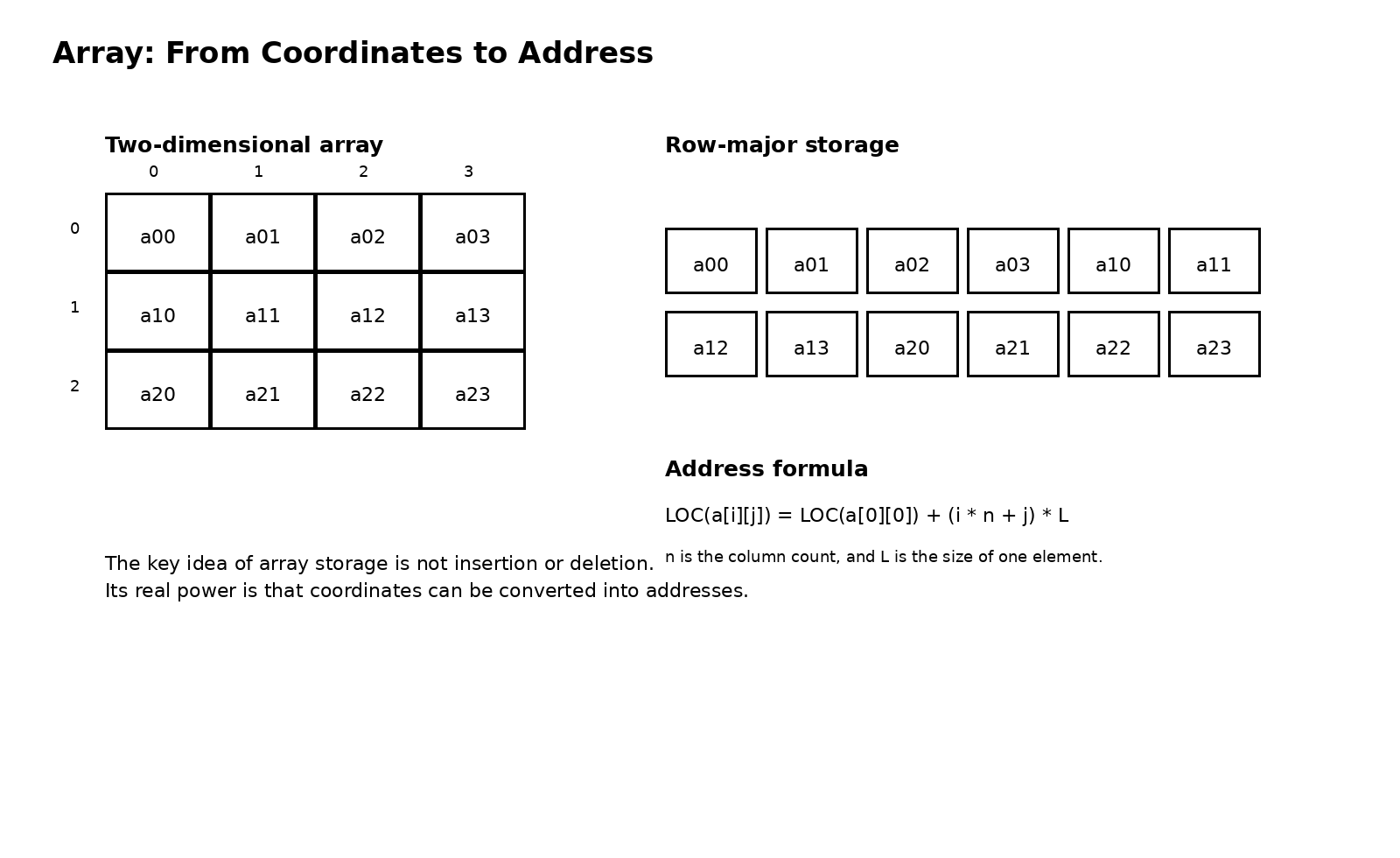
一维数组比较直观,只要知道首地址、元素大小和下标,就可以直接得到元素位置。真正让很多人开始紧张的是二维数组和多维数组,因为公式一下子多了起来。其实二维数组并没有变得更神秘,它只是把二维坐标映射回一维存储。计算机内存仍然是一条线,所以无论你看到的是几行几列,最终都必须落到一段线性地址上。所谓按行优先或者按列优先,本质上是在回答同一个问题,先让哪一个维度变化得更快。
按行优先时,二维数组的一整行会被依次放入连续空间中。若数组为 a[m][n],元素大小为 L,那么 a[i][j] 的地址通常写成
text
LOC(a[i][j]) = LOC(a[0][0]) + (i * n + j) * L这条式子并不难理解。前面已经完整经过了 i 行,每行有 n 个元素,再在当前行里向右走 j 个位置,于是总偏移量就是 i * n + j 个元素。真正建议你记住的,不是公式外形,而是这个推导过程。只要过程清楚,多维数组的地址公式本质上都能一层层推出。
也正是在这里,数组和前面的栈队列形成了一个很有意思的对照。栈和队列讨论的是,哪些操作被允许,因此结构会呈现什么行为;数组讨论的是,元素的位置有明确坐标,因此地址能否被直接计算。一个强调操作规则,一个强调空间映射。这两条思路看似不同,其实都在回答同一个更底层的问题,数据一旦有了限制条件,我们能从中榨出什么效率优势。
四、特殊矩阵的压缩存储,本质上是在和冗余空间谈判
当数组从一维走到二维,再走到矩阵,我们就会慢慢发现一个现实问题。并不是每个矩阵都值得老老实实按完整二维数组去存。有些矩阵天生带有很强的规律性,如果仍然按普通方式存储,就会浪费大量空间。特殊矩阵的压缩存储,正是在这样的背景下出现的。它的核心不是某种复杂技巧,而是一种很朴素的判断,哪些位置的信息其实是重复的,哪些位置根本没有必要存。
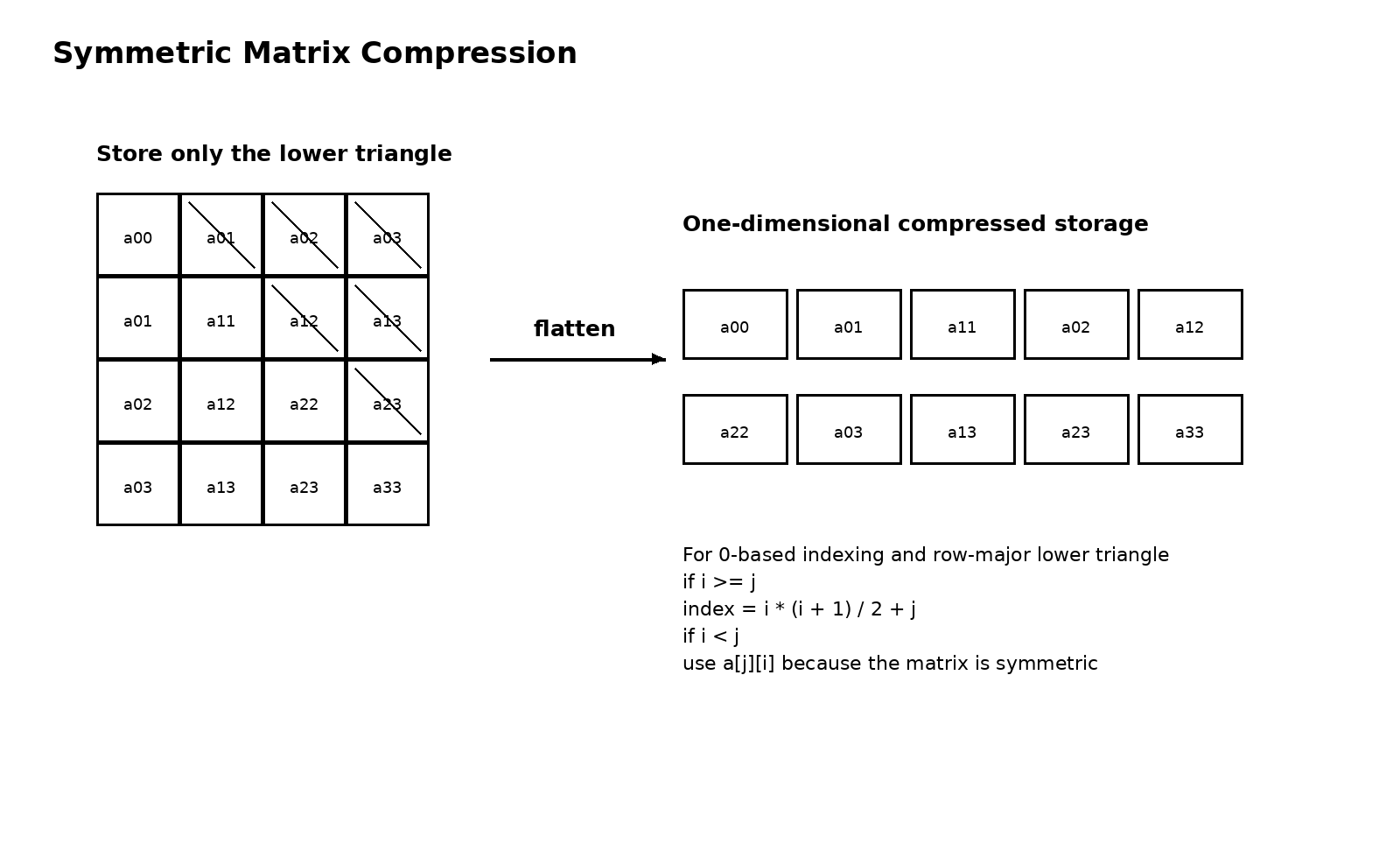
对称矩阵是最典型的例子。若 a[i][j] = a[j][i],那么主对角线两侧的信息是完全镜像的。这意味着你根本不需要把整个矩阵都存下来,只保留下三角或上三角中的一半即可。等到访问另一半时,再利用对称关系折回去取值就行。这样一来,原本需要 n^2 个单元的矩阵,只需保存大约一半的数据,空间开销会明显下降。
复习这部分时,最容易出错的是下标映射公式。其实不妨先把它想成编号过程。若按行优先存储下三角,并采用从零开始的下标,那么在第 i 行之前,一共已经存了 1 + 2 + ... + i = i(i+1)/2 个元素,所以 a[i][j] 在压缩数组中的位置就是这个累计量再加上当前行内的偏移 j。于是你会得到一个很自然的映射式,而不是一串凭空记下来的符号。
特殊矩阵里,三角矩阵和对角矩阵的处理思路与此相近,重点都是利用大量固定值或无效值来省空间。稀疏矩阵则更进一步,它往往不再按规则保留一整块三角区域,而是只记录非零元素及其坐标。你会发现,特殊矩阵压缩存储真正训练的能力并不是公式推演本身,而是先识别数据里的结构性冗余,再决定用什么方式把这种冗余删掉。这个思想其实很重要,因为它会在后面的图、哈希甚至数据库存储中不断重复出现。