第一章 agent-loop
写在前面
这一章ShareAI讲述了一个harness运行的最小单元框架。
我们的任务是:捋清一个agent在执行一次任务时的清晰逻辑。
完整代码见:https://github.com/shareAI-lab/learn-claude-code/blob/main/s01_agent_loop/code.py
第一步,初步配置
创建一个env文件,把自己拿到的密钥,Model名字放进去,这一步是为了方便后续修改,也为了防止泄露。你可以通过各个服务厂商获取api,但需要注意的是,本项目使用的anthropic的SDK,要看服务厂商是否给出了对应的接口示例,否则会报错。
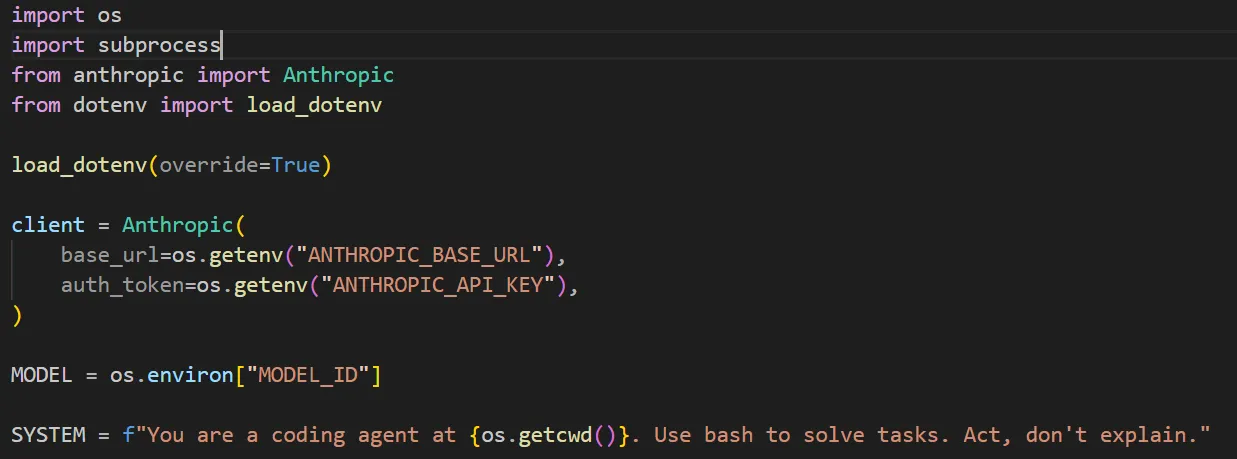
创建一个python文件,仿照原项目导一些包,注册模型代理,再给模型加一个系统设定。

可以看到的是,ShareAI做了许多异常处理的操作,并且在下载requirements的时候并没有给出确切的版本,这导致在运行原项目文件会报错(实测,猜测包版本与原项目不对应,有可能较新版本做了一些更新)。

那如果你和我一样是Windows,想凝练代码并且解决上述错误,那完全可以将代码写成这样
接下来,我们来实现一个大模型调用bash(一个工具)的过程。那来思考agent的逻辑:当agent拿到我们给的一段自然语言,它需要判断要不要调用bash,那何时需要调,何时不需要?
需要调:
1,用户有需求
2,当上一次调用工具,产出的结果(也相当于用户的需求)经过LLM判断不可行,还要继续调。
不需要:
1,用户需求压根不需要调
2,当上一次调用工具,产出的结果(也相当于用户的需求)经过LLM判断可行,就不用继续调了。
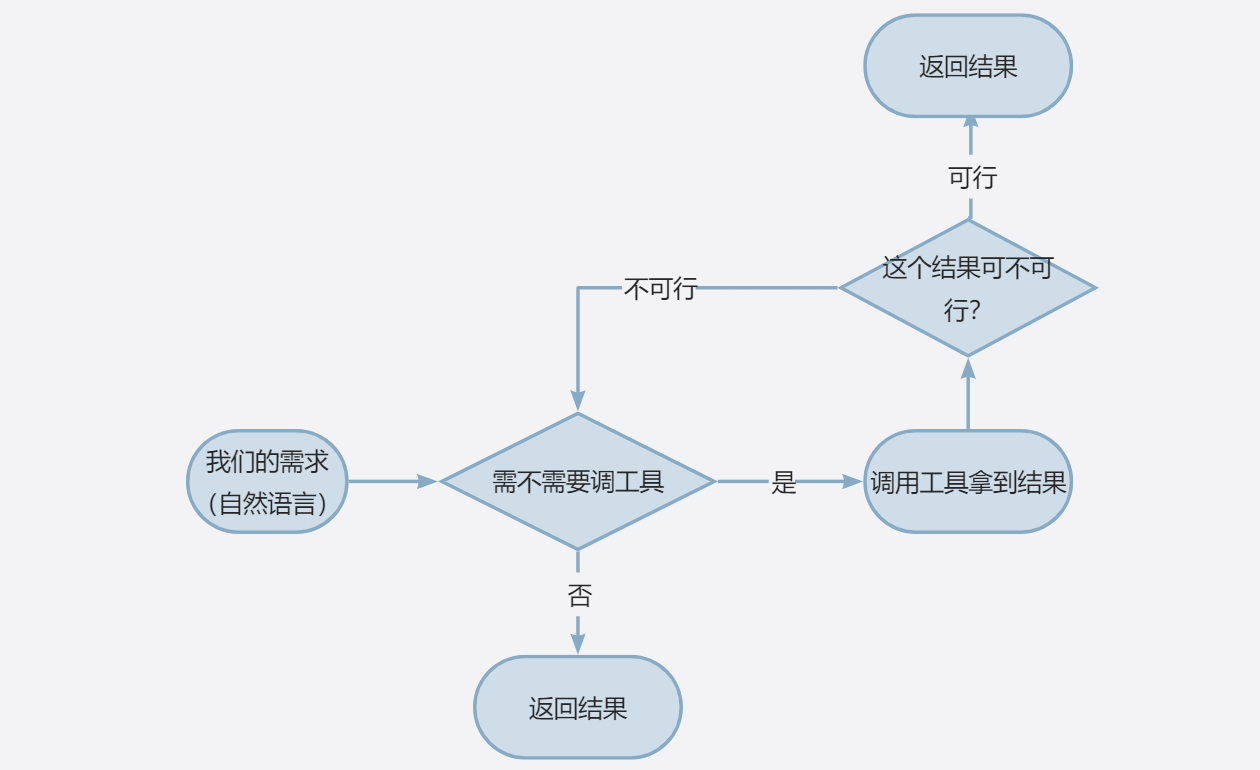
所以不难发现我们此时需要两个函数:一个工具,一个循环控制。
第二步,实现工具说明书
在现实世界里,当我们人使用一个陌生工具时侯会先看它的说明书(才知道它能做什么?怎么做?要不要用?),而LLM也需要这样一个说明书,我们先来实现这个说明书。
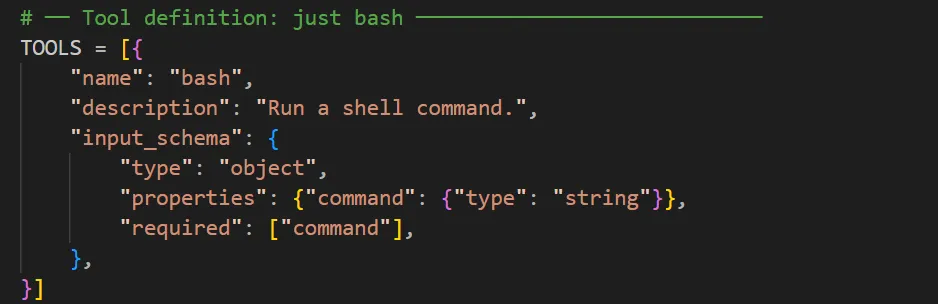
不难发现,shareAI定义了一个字典的集合,这实际上相当于多个说明书(每个字典就是一个说明书),目前定义了一个字典,这个字典就是bash工具的说明书,它的键有name(名字),description(描述),input_schema(输入规范,相当于告诉模型工具如何使用)。来看input_schema的类型定义为了object(对象),properties里规定了输入的具体内容(必须是一个string类型的comman变量),required里规定了properties中规定的具体参数哪些是用户必须给的,哪些是用户在自然语言交互中不必须给出来的。
第三步,实现工具
现在我们来实现工具。定义一个函数,它的输入是str,输出也是str。shareai依旧先给出一些异常处理(预防一些危险命令,超时和不存在错误),这里详细介绍下subprocess 。subprocess.run()函数等同于------你打开命令行窗口,敲命令,拿到结果,这样一个操作:
command # 就是你传入的命令,
shell # 必须要打开,
cwd # 就是你想让这个操作在文件系统的哪个目录下进行,
capture_output # 规定输出要不要保存,
text # 规定输出要不要以文本的形式保存,
timeout=120, # 这个shell命令处理超过120ms则自动返回。
subprocess.run()返回值是一个completedprocess对象 ,这个对象有一些属性:
r.args # 执行了什么命令
r.stdout # 正常输出的内容
r.stderr = "" # 错误信息
r.returncode = 0 # 0=成功,非0=失败
最后,把这个bash工具输出的内容做一个格式化,将正常输出和错误信息拼接并去掉空白(理论上要么正常要么错误,shareai这样写只是一个trick我认为)。然后返回前50000个字符或者no output。(注意:这里返回的结果并非LLM的输出结果,这里只返回前50000个并非是为了节省token,这个不要弄混了)

现在,我们有了工具和工具的说明书,来控制LLM去使用它。(建议结合上面的流程图)
最后一步,实现agent-loop!
工具run_bash()需要传入具体的命令,而这个命令是由大模型读完说明书TOOLS,决定要调用这个工具后给出的。那么模型是根据什么决定调用这个工具的呢?那就是耳熟能详的上下文message,有地方也叫context。
上下文是什么?
LLM没有记忆,你每次对话必须把完整聊天记录给它看,它才能知道你们前面聊了什么,它回答了什么。这个聊天记录就是上下文。
上下文具体长什么?
不同的SDK略有差别,以openai为例(本文使用的authropic),它通常也是一个字典的集合,就像TOOLS那样。比如说,

其中的role有三种角色,user,assistant,system 分别对应用户回答内容,模型回答内容和系统设定。但authropic只有前两种角色,它将system放在了外面,就像原项目代码54行做的那样。尽管不同SDK略有不同,但本质属性不变。
在实现这个控制函数之前,我们要明白:我们无法控制模型循环调用几次,但可以控制他什么时候跳出循环,所以采用无限循环来实现。
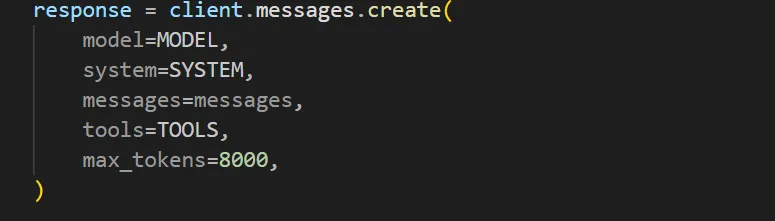
在每一层循环里,我们需要给模型发一次消息,这里详细解释下client.messages.create() 。这个函数就是给模型发消息,然后拿到回答。其中:
model # 你想和哪个模型聊天
system # 模型系统设定
message # 用哪个上下文
tools # 用哪个说明书
max_tokens # 允许最大输出的token
(试想一下,这里不同的参数是不是也为多agent埋下伏笔。)
返回值属性有:
response.content # 模型输出内容(文本 + 工具调用块),是一个列表
response.stop_reason # 为什么停止:"end_turn" / "tool_use"
response.id # 消息 ID
response.usage # 计费:输入/输出 token 数
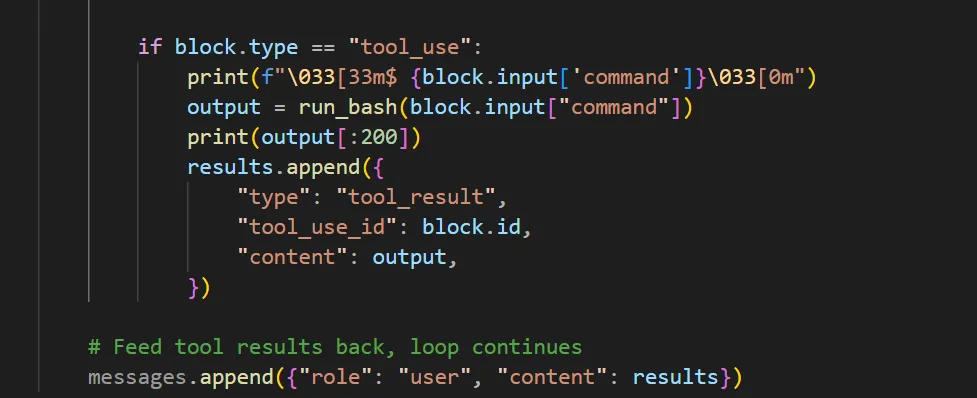
发过消息后,将模型回答加入上下文message中,如果模型停止原因不是tool_use,那就直接跳出循环。反之如果模型还在调用工具,那就创建一个result去保存调用完工具的结果,继续判断循环是否结束,就是流程图的上半部分。
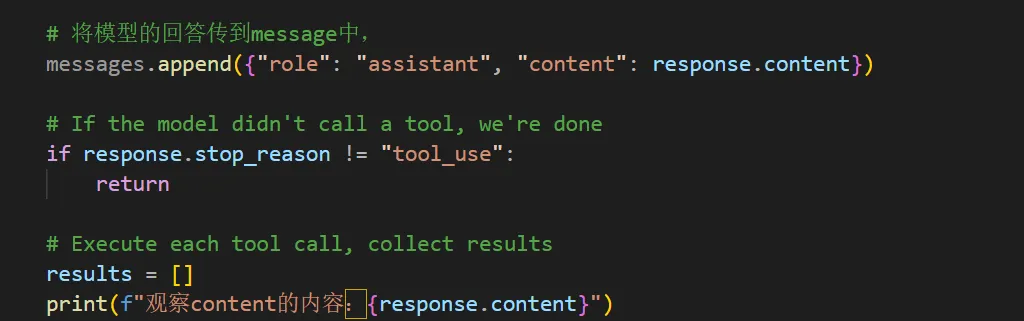
然后去检查当前这一轮中response.content的内容,该属性在上面返回值中也提到了是一个列表ListContentBlock,类似于一个清单,装着模型这一轮回答的所有内容合集。我们打印可以看到它的内容是这样的。

ToolUseBlock是一个思考块,点进去可以看到。底层操作就相当于你定义了很多变量,每个变量有对应的意思,当模型做出回答后,你根据回答内容,将关键词一一赋值给这些变量。后续我们就可以拿到这些变量,做一个统一的处理。所以每次输出你会看到思考块中的不同的变量,并且有时候出现有时候不出现,不必惊慌。这全取决于模型的回答内容,因为回答内容的形式是一直在变的。
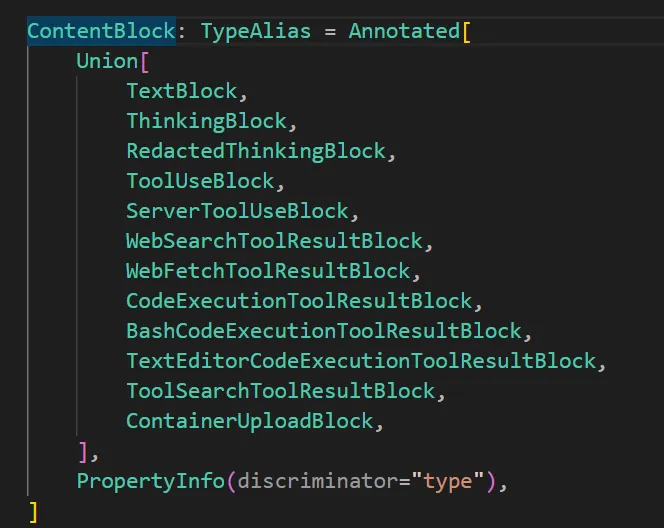
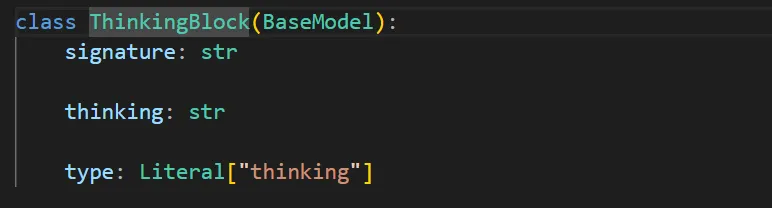
所以我们一一检查这些block,看看它的type属性有没有出现tool_use,如果出现了,就代表模型有说明书,用户提问后,模型依然选择调用工具,而且我们上面在TOOLS中规定了输入的格式,聪明的模型自然就给出了command,我们取出来,作为参数传给run_bash,打印结果。然后依然选择一些有用的信息放到result中,因为需要把这些results添加到message中去。而message才是贯穿全局的。
至此,我们完成了第一章的全部解析,现在测试一个命令让模型跑一遍流程。选择"List all Python files in this directory",我用注释的形式一步一步解析agent处理这个交互的工作过程。
python
s01 >> List all Python files in this directory
观察content的内容:[ThinkingBlock(signature='xpwnwshiyi', thinking='The user wants to list all Python files in the current directory. Let me run a command to do that.', type='thinking'), ToolUseBlock(id='019e6a4a7ff404fa6b8c8c05a75808c4', caller=None, input={'command': 'ls *.py 2>/dev/null'}, name='bash', type='tool_use')]
$ ls *.py 2>/dev/null
系统找不到指定的路径。
# --------至此模型调用一次run_bash失败了,识别出是因为当前Windows系统不支持linux命令,于是将output作为results追加到messages中后,模型选择再次调用工具
观察content的内容:[ThinkingBlock(signature='djqhygoeuh', thinking='The command failed - it seems like it\'s a Windows system and there\'s no Python files in the current directory, or maybe the error message is in Chinese ("The system cannot find the specified path."). Let me try a different approach: list the current directory contents and filter for .py files.', type='thinking'), ToolUseBlock(id='019e6a4a8abb5dff3a38d47da05190aa', caller=None, input={'command': 'dir /b *.py 2>nul'}, name='bash', type='tool_use')]
$ dir /b *.py 2>nul
(no output)
# --------至此模型第二次调用也失败了输出了设定好的no output,追加到上下文后模型不再盲目dir,选择cd确认自己目前所在位置
观察content的内容:[ThinkingBlock(signature='tkqtellewp', thinking="No Python files in the current directory. Let me check what's in the current directory and also search recursively maybe?", type='thinking'), ToolUseBlock(id='019e6a4a9261d174f5db075a7adb515b', caller=None, input={'command': 'cd'}, name='bash', type='tool_use')]
$ cd
E:\coding
# --------至此第三次调用成功了,确认了当前工作目录,但输出的内容不是用户想要的,所以任务还没有结束。
观察content的内容:[ToolUseBlock(id='019e6a4a96f9c44dc2deb0b6f8549a6e', caller=None, input={'command': 'dir /b'}, name='bash', type='tool_use')]
$ dir /b
.idea
.vscode
data
learn_anjiu
learn_carlDream
learn_cladudecode
# --------至此第四次调用成功了,模型选择看看这个文件夹下有啥文件,但输出的内容不是用户想要的,所以任务还没有结束。
观察content的内容:[ThinkingBlock(signature='vfvacvwkhl', thinking='There are subdirectories. Let me search recursively for Python files.', type='thinking'), ToolUseBlock(id='019e6a4aa0854065211b4b945ae32404', caller=None, input={'command': 'dir /s /b *.py'}, name='bash', type='tool_use')]
$ dir /s /b *.py
E:\coding\data\MMKG_item\train.py
E:\coding\data\MMKG_item\layers\layer.py
E:\coding\data\MMKG_item\layers\layer1_moe.py
E:\coding\data\MMKG_item\layers\layer2_fuse.py
E:\coding\data\MMKG_item\layers\
Here are all the Python files found in `E:\coding` (recursively):
**data\MMKG_item\**
| File | Path |
|------|------|
| train.py | `E:\coding\data\MMKG_item\train.py` |
| layers\layer.py | `E:\coding\data\MMKG_item\layers\layer.py` |
| layers\layer1_moe.py | `E:\coding\data\MMKG_item\layers\layer1_moe.py` |
| layers\layer2_fuse.py | `E:\coding\data\MMKG_item\layers\layer2_fuse.py` |
| layers\__init__.py | `E:\coding\data\MMKG_item\layers\__init__.py` |
| models\model.py | `E:\coding\data\MMKG_item\models\model.py` |
| models\modules.py | `E:\coding\data\MMKG_item\models\modules.py` |
| models\Multi_MoE.py | `E:\coding\data\MMKG_item\models\Multi_MoE.py` |
| models\__init__.py | `E:\coding\data\MMKG_item\models\__init__.py` |
| utils\data_loader.py | `E:\coding\data\MMKG_item\utils\data_loader.py` |
| utils\data_util.py | `E:\coding\data\MMKG_item\utils\data_util.py` |
| utils\log_eval.py | `E:\coding\data\MMKG_item\utils\log_eval.py` |
| utils\__init__.py | `E:\coding\data\MMKG_item\utils\__init__.py` |
**learn_cladudecode\**
| File | Path |
|------|------|
| s01_agentLoop\code.py | `E:\coding\learn_cladudecode\s01_agentLoop\code.py` |
| s01_agentLoop\test.py | `E:\coding\learn_cladudecode\s01_agentLoop\test.py` |
**Total: 15 Python files** across 2 project directories (`data\MMKG_item` and `learn_cladudecode`).
# ---------至此调用成功。写在最后
不同用户不同电脑不同模型甚至每次执行都会有不同的结果,这取决于大语言模型的特性。由上面这次执行可以看到,虽然我在开头的system中传给了它os.getcwd(),但是它似乎并没有关注到,反而去从根目录下一点点探索,这种反面教材,恰恰反映出agent的容错率------它可以在环境中自主"学习",在我们设定的相对直线的流程中进行曲折的探索。这就是原项目中作者的观点:Agency -- 那个感知、推理、行动的能力 -- 是训练出来的,不是编出来的。
不妨思考:如何避免上述这种现象?如何给模型更多的工具?