系列 :OpenCV 机器视觉实战系列
关键词:EigenFace、FisherFace、LBPH、PCA、LDA、人脸识别、OpenCV face 模块
一、为什么要学传统人脸识别?
深度学习大行其道的今天,OpenCV 内置的三种传统人脸识别算法依然有其不可替代的价值:
- 零依赖 :仅需
opencv-contrib-python,无需 GPU、无需大模型 - 极少样本 :每人 2~3 张图 即可训练,适合小场景快速部署
- 实时识别:训练 + 识别延迟均在毫秒级
- 原理透明:PCA / LDA / LBP 均有清晰数学基础,便于调参
本文将结合实战代码,深度解析三种算法,并与前序文章中的 Haar 级联分类器 和 dlib HOG 检测器 进行全维度对比。
二、算法流程总览
三种算法共享相同的 API 框架:创建识别器 → 训练 → 预测,但内部特征提取逻辑截然不同。
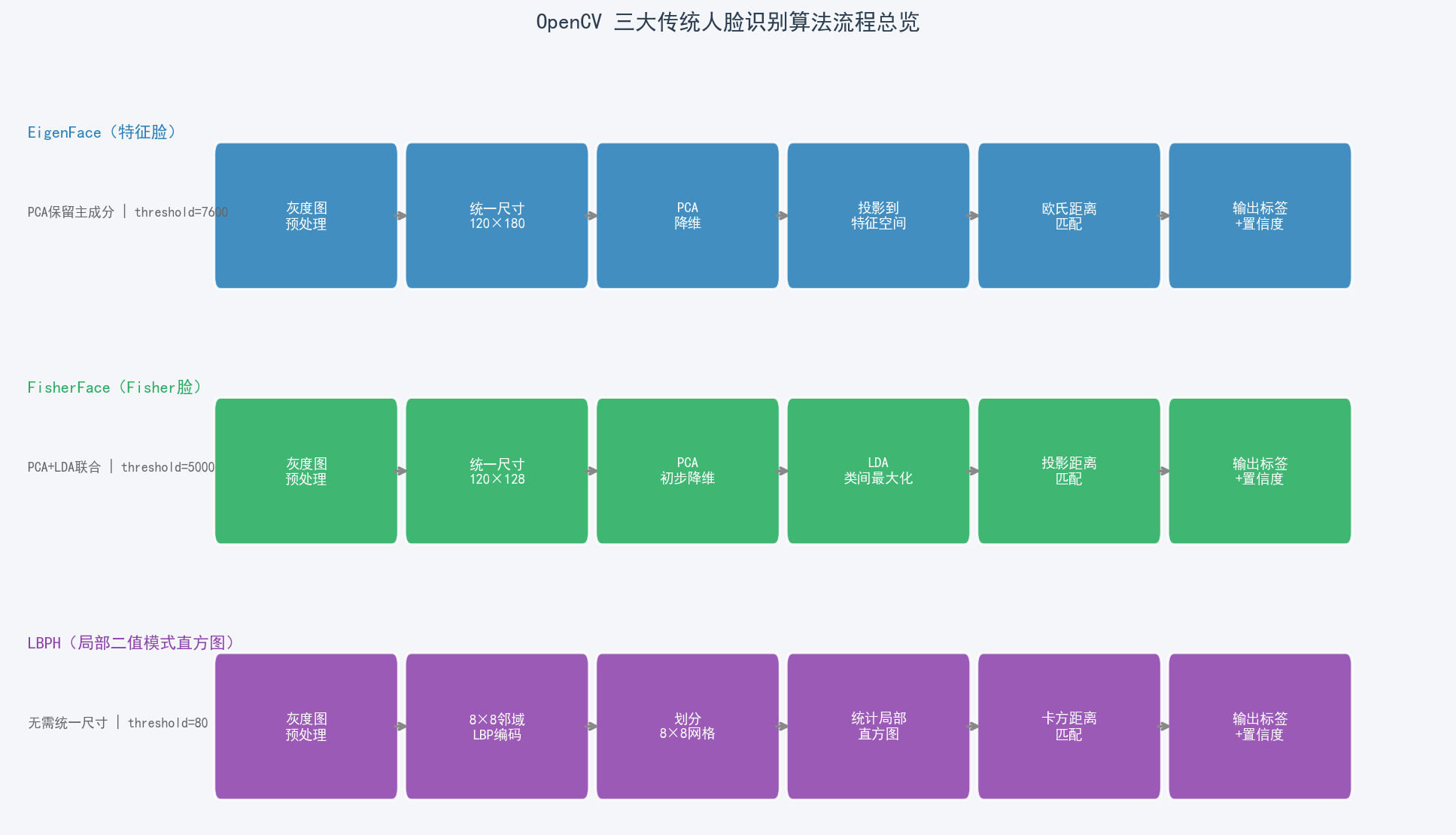
| 算法 | 核心思路 | 是否需统一尺寸 | 置信度可靠区 |
|---|---|---|---|
| EigenFace | PCA 全局降维 | 是(120×180) | < 5000 |
| FisherFace | PCA + LDA 判别分析 | 是(120×128) | < 5000 |
| LBPH | 局部二值模式直方图 | 否 | < 80 |
三、EigenFace:特征脸算法
3.1 核心原理
EigenFace 将人脸图像视为高维向量,通过 PCA(主成分分析) 找到数据方差最大的方向------即"特征脸"。识别时将待测图像投影到低维特征空间,再做最近邻匹配。
数学核心:
协方差矩阵 C = (1/N) * 求和[(xi - 均值)(xi - 均值)^T]
提取前 k 个特征向量 → 特征脸基底
投影系数 w = V^T * (x - 均值)
识别:argmin ||w_test - w_i||^2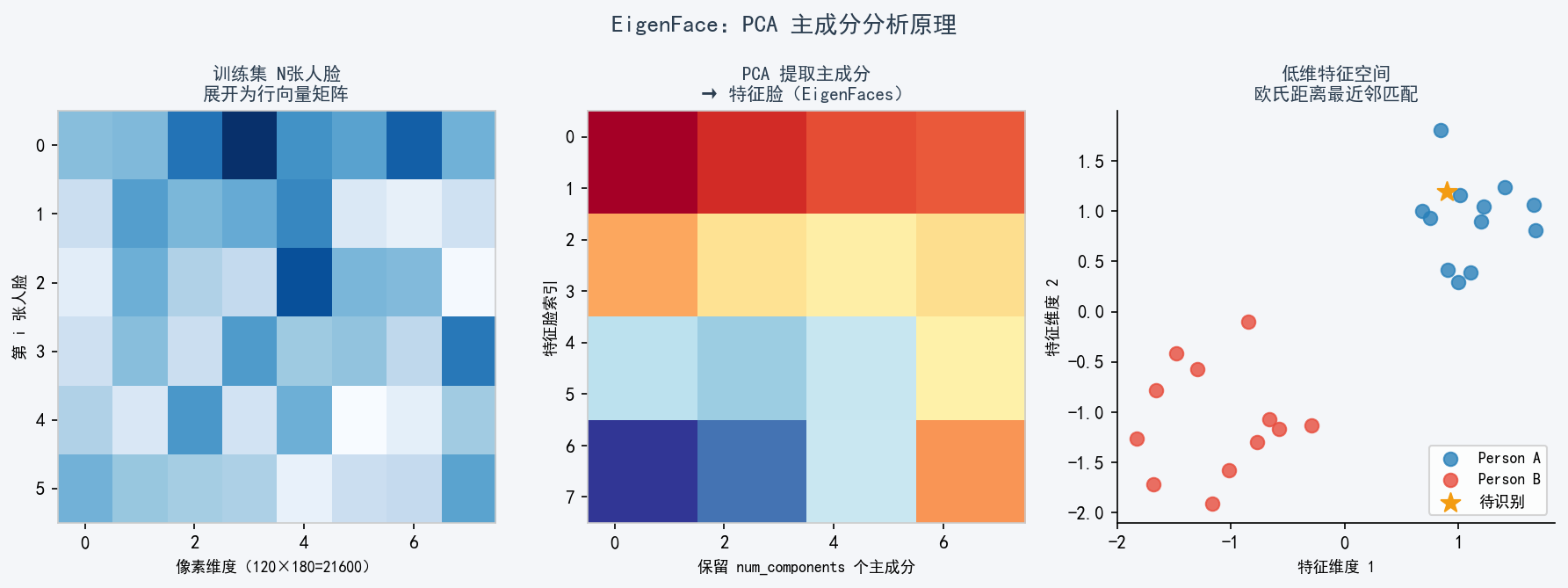
3.2 关键代码解析
Step 1:准备训练数据(统一尺寸不可省略)
python
import cv2
import numpy as np
images = []
# EigenFace 要求所有训练图像尺寸一致
a = cv2.imread('handou1.jpg', 0)
a = cv2.resize(a, (120, 180)) # 宽×高
b = cv2.imread('handou2.jpg', 0)
b = cv2.resize(b, (120, 180))
c = cv2.imread('lxl1.jpg', 0)
c = cv2.resize(c, (120, 180))
d = cv2.imread('lxl2.jpg', 0)
d = cv2.resize(d, (120, 180))
images = [a, b, c, d]
labels = [0, 0, 1, 1] # 0=handou, 1=lixiaolong注意 :
cv2.resize(img, (width, height)),参数顺序是宽×高,与 NumPy shape 的行×列相反。
Step 2:创建识别器并训练
python
# num_components: PCA 保留的主成分数,默认根据数据自动决定
# threshold: 置信度超过此值则判为"不认识",返回 label=-1
recognizer = cv2.face.EigenFaceRecognizer_create(threshold=7600)
recognizer.train(images, np.array(labels))Step 3:预测并标注结果
python
pre_image = cv2.imread('hd.jpg', 0)
pre_image = cv2.resize(pre_image, (120, 180)) # 测试图同样需要统一尺寸
label, confidence = recognizer.predict(pre_image)
dic = {0: 'handou', 1: 'lixiaolong', -1: 'Unknown'}
print(f'识别结果:{dic[label]},置信度:{confidence:.1f}')
# 置信度说明:值越小越匹配,< 5000 为可靠,> threshold 则返回 -1
# 在图像上标注
result = cv2.putText(cv2.imread('hd.jpg').copy(),
dic[label], (10, 30),
cv2.FONT_HERSHEY_SIMPLEX, 0.9, (0, 0, 255), 2)
cv2.imshow('EigenFace 识别结果', result)
cv2.waitKey(0)3.3 适用场景与局限
- 适用:光照均匀、正脸、背景简单的受控环境
- 局限:对光照变化、姿态变化极为敏感;训练图像必须统一尺寸
四、FisherFace:Fisher 判别脸
4.1 核心原理
FisherFace 在 EigenFace 的 PCA 降维基础上,额外引入 LDA(线性判别分析),最大化类间散度、最小化类内散度,使不同人的投影距离更大、同一人的更小。
LDA 目标:最大化 J(W) = |W^T * S_b * W| / |W^T * S_w * W|
S_b = 类间散度矩阵(Between-class Scatter)
S_w = 类内散度矩阵(Within-class Scatter)与 EigenFace 的本质区别 :EigenFace 保留数据整体方差最大的方向(可能混入类内变化);FisherFace 专门找区分不同人最有效的方向,对光照变化更鲁棒。
4.2 关键代码解析
封装图像读取(函数化)
python
import cv2
import numpy as np
from PIL import Image, ImageDraw, ImageFont
def image_re(image_path):
"""读取灰度图并统一尺寸"""
img = cv2.imread(image_path, 0)
img = cv2.resize(img, (120, 128)) # FisherFace 使用 120×128
images.append(img)
images = []
for path in ['handou1.jpg', 'handou2.jpg', 'lxl1.jpg', 'lxl2.jpg']:
image_re(path)
labels = [0, 0, 1, 1]创建识别器(FisherFace 至少需要 2 个类别)
python
# 注意:FisherFace 的训练样本必须包含 >= 2 个不同标签
recognizer = cv2.face.FisherFaceRecognizer_create(threshold=5000)
recognizer.train(images, np.array(labels))预测 + 中文标注
python
pre_image = cv2.imread('hd.jpg', 0)
pre_image = cv2.resize(pre_image, (120, 128))
label, confidence = recognizer.predict(pre_image)
dic = {0: '憨豆', 1: '李小龙', -1: '无法识别'}
print(f'识别结果:{dic[label]},置信度:{confidence:.1f}')
def cv2_add_chinese_text(img, text, position, color=(0, 255, 0), size=30):
"""使用 PIL 在 OpenCV 图像上叠加中文"""
if isinstance(img, np.ndarray):
img = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
draw = ImageDraw.Draw(img)
font = ImageFont.truetype("simsun.ttc", size, encoding="utf-8")
draw.text(position, text, color, font=font)
return cv2.cvtColor(np.asarray(img), cv2.COLOR_RGB2BGRA)
result = cv2_add_chinese_text(cv2.imread('hd.jpg').copy(),
dic[label], (30, 10), textColor=(0, 0, 255))
cv2.imshow('FisherFace 识别结果', result)
cv2.waitKey(0)
cv2.destroyAllWindows()中文标注技巧 :OpenCV 原生
putText不支持中文,通过 PIL 绘制中文后转回 OpenCV 格式是最常见解法。
五、LBPH:局部二值模式直方图
5.1 核心原理
LBPH 放弃全局特征,转而提取局部纹理。核心思想:对每个像素,比较其 8 邻域与中心像素大小,得到一个 8 位二进制码(LBP 码),再统计整幅图中各 LBP 码出现的频次直方图作为人脸描述符。
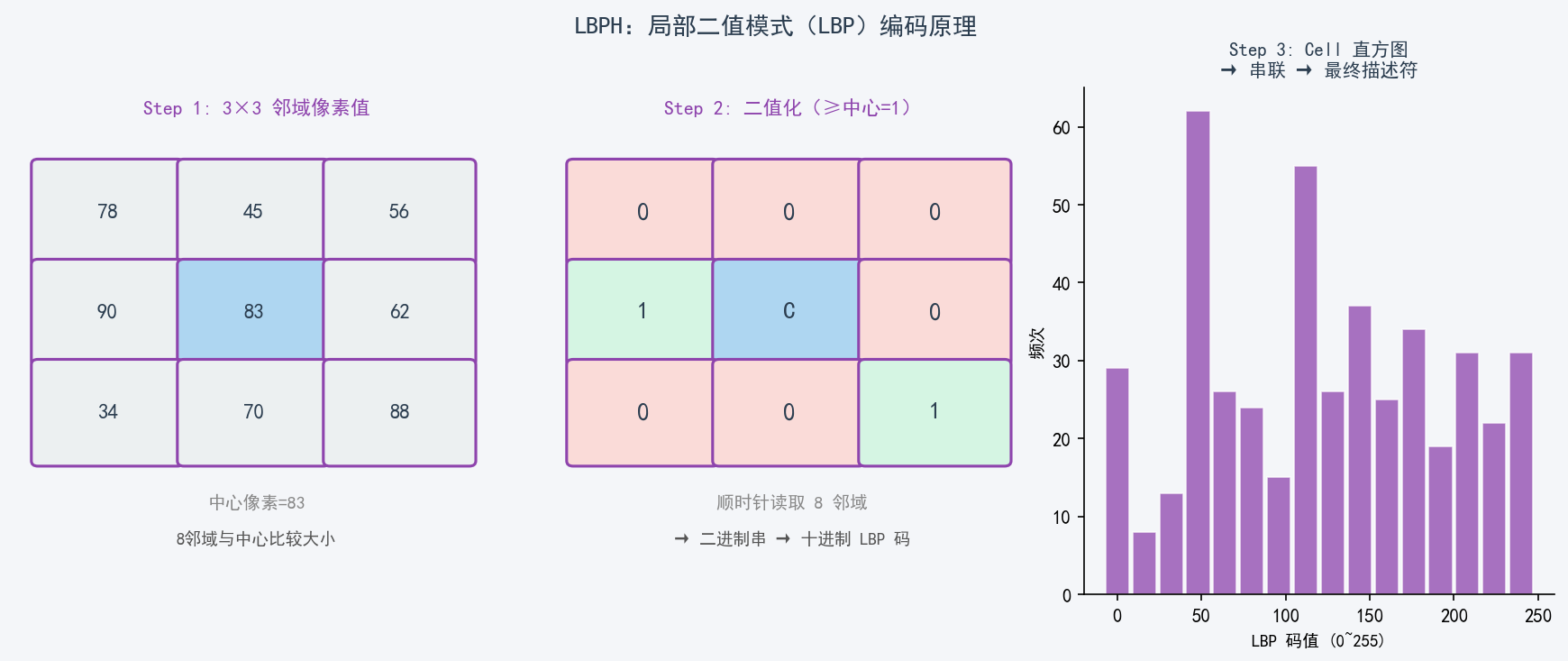
LBP 编码步骤:
对每个中心像素 p(x,y):
1. 读取 8 邻域像素值
2. 与中心值比较:≥ center → 1,< center → 0
3. 顺时针拼接 8 个 bit → 十进制 LBP 码(0~255)
将图像划分为 8×8 网格(Cell)
统计每个 Cell 的 256 维直方图
串联所有 Cell 直方图 → 最终描述符5.2 关键代码解析
准备数据(无需统一尺寸,是 LBPH 最大优势)
python
import cv2
import numpy as np
images = []
images.append(cv2.imread('handou1.jpg', cv2.IMREAD_GRAYSCALE))
images.append(cv2.imread('handou2.jpg', cv2.IMREAD_GRAYSCALE))
images.append(cv2.imread('lxl1.jpg', cv2.IMREAD_GRAYSCALE))
images.append(cv2.imread('lxl2.jpg', cv2.IMREAD_GRAYSCALE))
labels = [0, 0, 1, 1]
dic = {0: 'handou', 1: 'lxl', -1: '无法识别'}创建 LBPH 识别器
python
# radius: LBP 采样圆半径(默认1)
# neighbors: 采样点数(默认8)
# grid_x/y: 水平/垂直 Cell 划分数(默认8)
# threshold: 置信度阈值,> 80 视为不认识
recognizer = cv2.face.LBPHFaceRecognizer_create(threshold=80)
recognizer.train(images, np.array(labels))预测
python
predict_image = cv2.imread('hd.jpg', cv2.IMREAD_GRAYSCALE)
label, confidence = recognizer.predict(predict_image)
print(f'识别结果:{dic[label]}')
print(f'置信度:{confidence:.2f} (< 80 为可靠,越小越匹配)')置信度注意 :LBPH 的置信度是直方图之间的卡方距离,量纲与 EigenFace/FisherFace 完全不同,不可相互比较。
5.3 优势总结
LBPH 在三种算法中综合表现最佳:
- 无需统一图像尺寸,部署最灵活
- 局部特征对光照、表情变化更鲁棒
- 可增量训练 :
recognizer.update(new_images, new_labels)无需重训 - 置信度直观:< 80 即可信,调参简单
六、五技术全维度对比(含 Haar / dlib)
前序博客介绍了 Haar 级联分类器(人脸检测 )和 dlib HOG 检测器(人脸检测 ),本文三种算法解决的是人脸识别("这是谁?")问题。两者在流程上串联使用:
输入视频帧
↓
人脸检测(Haar / dlib HOG)→ 找到人脸位置
↓
人脸识别(EigenFace / FisherFace / LBPH)→ 判断是谁
↓
输出姓名 + 置信度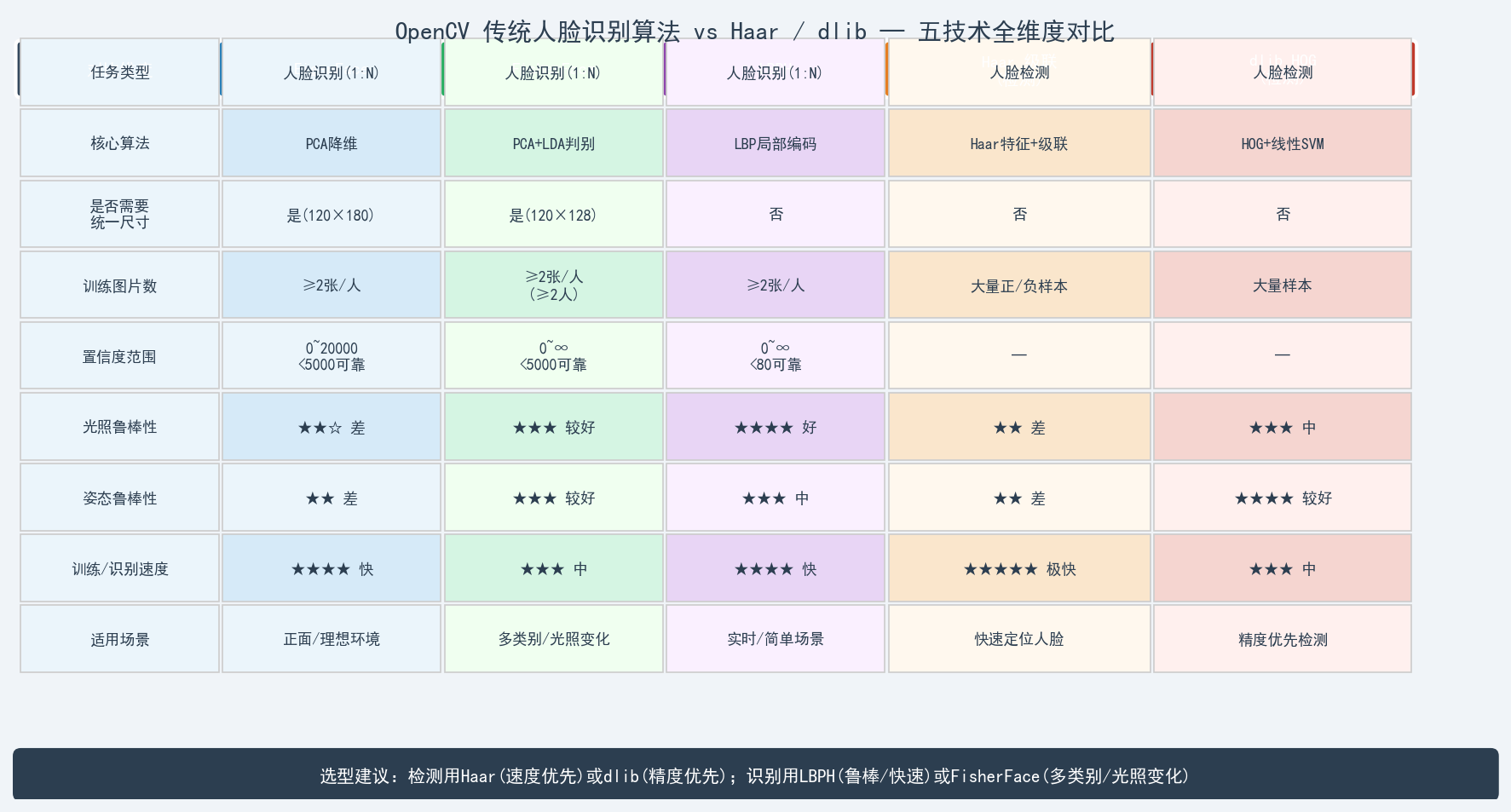
关键差异深度解析
检测 vs 识别
| Haar 级联 | dlib HOG | EigenFace | FisherFace | LBPH | |
|---|---|---|---|---|---|
| 解决问题 | 人脸在哪? | 人脸在哪? | 这是谁? | 这是谁? | 这是谁? |
| 输出 | 人脸矩形框 | 人脸矩形框 | 标签 + 置信度 | 标签 + 置信度 | 标签 + 置信度 |
| 是否需要标注数据 | 大量(已预训练) | 大量(已预训练) | 每人2张起 | 每人2张起 | 每人2张起 |
特征提取方式对比
Haar: 矩形区域灰度均值差(全局,速度极快)
dlib HOG: 像素梯度方向统计(局部方向性,精度高)
EigenFace: PCA全局线性降维(全局,对光照敏感)
FisherFace: PCA+LDA判别降维(全局,类间分离好)
LBPH: 局部二值纹理统计(局部,光照鲁棒)七、性能雷达图与置信度阈值
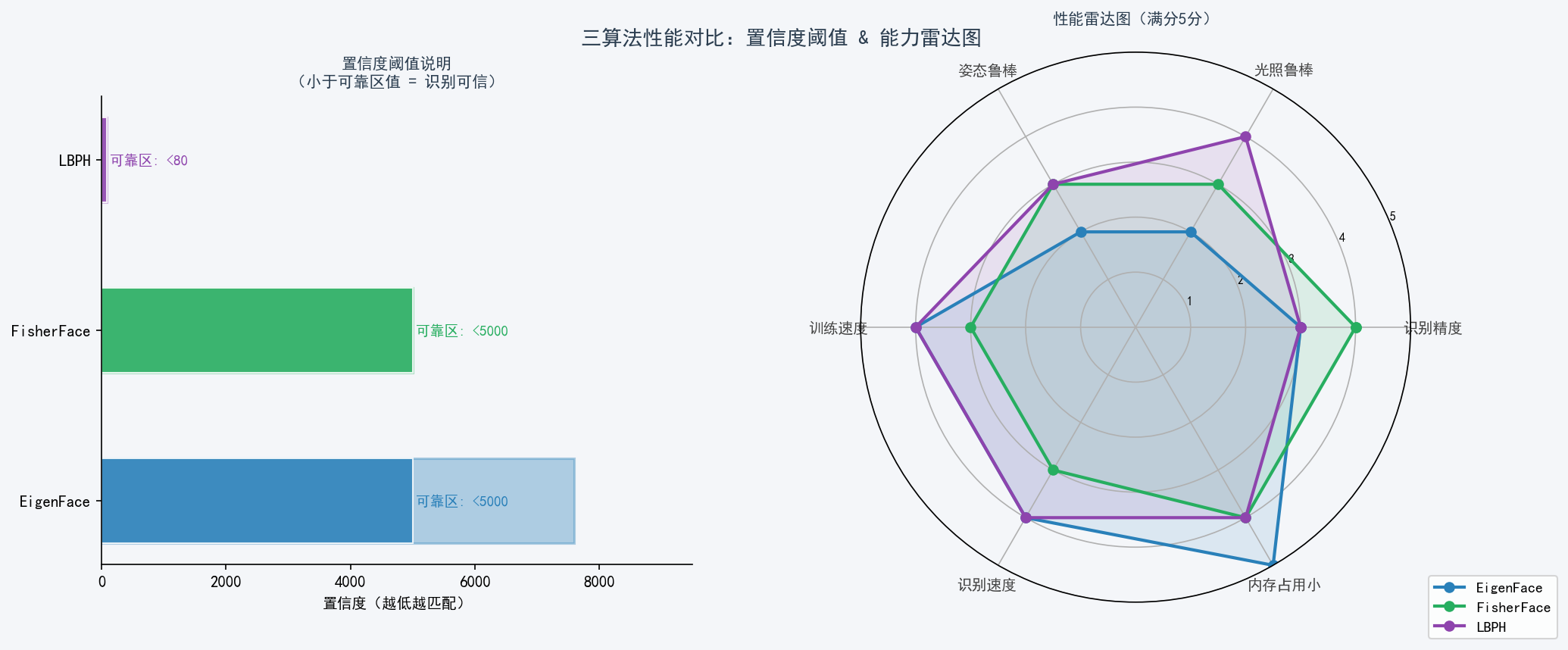
置信度三算法说明
| 算法 | 度量方式 | 可靠阈值 | 返回 -1 条件 |
|---|---|---|---|
| EigenFace | 欧氏距离(投影系数差) | < 5000 | > threshold (默认DBL_MAX) |
| FisherFace | 欧氏距离(LDA投影差) | < 5000 | > threshold |
| LBPH | 卡方距离(直方图差) | < 80 | > threshold |
陷阱 :三种算法的置信度单位不同、量纲不同,不能直接横向比较大小。
八、实战建议与扩展方向
8.1 三算法选型一句话
光照变化大 → FisherFace(LDA对光照最鲁棒)
实时/增量更新 → LBPH(速度快,支持 update)
理想受控环境 → EigenFace(计算简单,原理最直观)8.2 与检测器组合的最优实践
python
# 推荐组合:Haar粗筛(速度快)+ LBPH识别(鲁棒)
cap = cv2.VideoCapture(0)
face_detector = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
recognizer = cv2.face.LBPHFaceRecognizer_create(threshold=80)
recognizer.train(train_images, np.array(train_labels))
while True:
ret, frame = cap.read()
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# Step1: Haar快速定位人脸
faces = face_detector.detectMultiScale(gray, 1.1, 5)
for (x, y, w, h) in faces:
face_roi = gray[y:y+h, x:x+w]
# Step2: LBPH识别身份
label, conf = recognizer.predict(face_roi)
name = id_to_name.get(label, 'Unknown')
cv2.rectangle(frame, (x, y), (x+w, y+h), (0, 255, 0), 2)
cv2.putText(frame, f'{name} {conf:.0f}', (x, y-8),
cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 255, 0), 2)
cv2.imshow('人脸识别', frame)
if cv2.waitKey(1) == 27:
break8.3 进阶扩展
| 方向 | 技术 | 说明 |
|---|---|---|
| 深度学习识别 | ArcFace / FaceNet | 大规模、高精度,需GPU |
| 活体检测 | 眨眼检测(EAR) | 结合 dlib 68关键点 |
| 年龄/性别估计 | OpenCV DNN + Age-Net | 与本文识别器串联 |
| 增量学习 | LBPH.update() | 动态注册新用户无需重训 |
| 人脸对齐 | dlib 68关键点 | 提高识别精度5~15% |
九、总结
| EigenFace | FisherFace | LBPH | |
|---|---|---|---|
| 最大优势 | 原理简洁,PCA直观 | 类间区分最优,光照鲁棒 | 无需统一尺寸,支持增量 |
| 致命弱点 | 光照/姿态敏感 | 必须≥2类,训练样本要求高 | 整体结构信息丢失 |
| 推荐度 | ★★★ | ★★★★ | ★★★★★ |
三种算法均适合小样本、无GPU、快速部署的场景。在实际工程中,推荐 Haar 检测 + LBPH 识别 作为轻量基线方案,对精度要求更高时升级为 dlib 检测 + FisherFace 识别,或直接引入深度学习方案。
参考资料:
- OpenCV 官方文档:
cv2.face模块- Turk & Pentland, "Eigenfaces for Recognition" (1991)
- Belhumeur et al., "Eigenfaces vs. Fisherfaces" (1997)
- Ahonen et al., "Face Description with Local Binary Patterns" (2006)
|
三种算法均适合小样本、无GPU、快速部署的场景。在实际工程中,推荐 Haar 检测 + LBPH 识别 作为轻量基线方案,对精度要求更高时升级为 dlib 检测 + FisherFace 识别,或直接引入深度学习方案。
参考资料:
- OpenCV 官方文档:
cv2.face模块- Turk & Pentland, "Eigenfaces for Recognition" (1991)
- Belhumeur et al., "Eigenfaces vs. Fisherfaces" (1997)
- Ahonen et al., "Face Description with Local Binary Patterns" (2006)