本次工作主要围绕法律文书智能辅助系统的后端持久化存储、双栏阅读交互、示例库管理及多项性能优化展开。完成了历史记录与批注从浏览器本地存储向后端JSON及SQLite的迁移,实现了全RESTful API对接;新增双栏阅读界面,支持文本选中与批注联动;构建自定义示例库,实现示例与源文档的生命周期同步,并通过路由跳转与ID缓存机制大幅提升示例加载速度;同时解决了MD5文件去重、ChromaDB同步删除、时区显示错误等关键技术问题,提升了系统的稳定性与团队协作效率。
具体内容
1.历史记录与批注的持久化存储
实现文档管理与历史记录的持久化存储,实现批注功能的持久化存储
对于历史记录,一开始只是记录在浏览器本地,但如果换了浏览器,就看不到相应的历史记录,因此这里把历史记录存储到后端 backend/data中,每次都可以架子啊
同理,批注也是会存储在这里,保证后来打开后能重新加载出来
【这里改动后,重新提交了gitee代码,保证团队代码同步】
对于后端
新增架构 Models: 在 schemas.py 为前端的无类型对象引入了强类型的 Pydantic Validator,例如 HistoryItem, Annotation, AnnotationCreate 等
Services: 新增加了 services/storage_service.py 读写控制模块,会自动在 data/ 目录下生成和管理 history.json 和对应的 annotations_{doc_id}.json
API: 在 api/storage.py 追加一整套 RESTful CRUD 接口给前端使用,并注册至 FastAPI 应用主干
对于前端
通过新文件 api/storage.ts 替换了曾经的 utils/storage.ts,改变了存储交互流向(网络 Axios 调用取代了同步 LocalStorage)。 将 HistoryPanel.vue (历史中心)、DocumentView.vue (文档触发点)、AnnotationPanel.vue (批注交互) 的代码改造成了 async / await 的规范协程写法。 清除了原有的 utils/storage.ts。
考虑到数据量问题,批注与评论同步迁移到sqlite,而浏览器中的历史记录仍然用json格式存储
2.删除文档chormaDB同步
在vector_store中添加 delete_chunks() 函数:
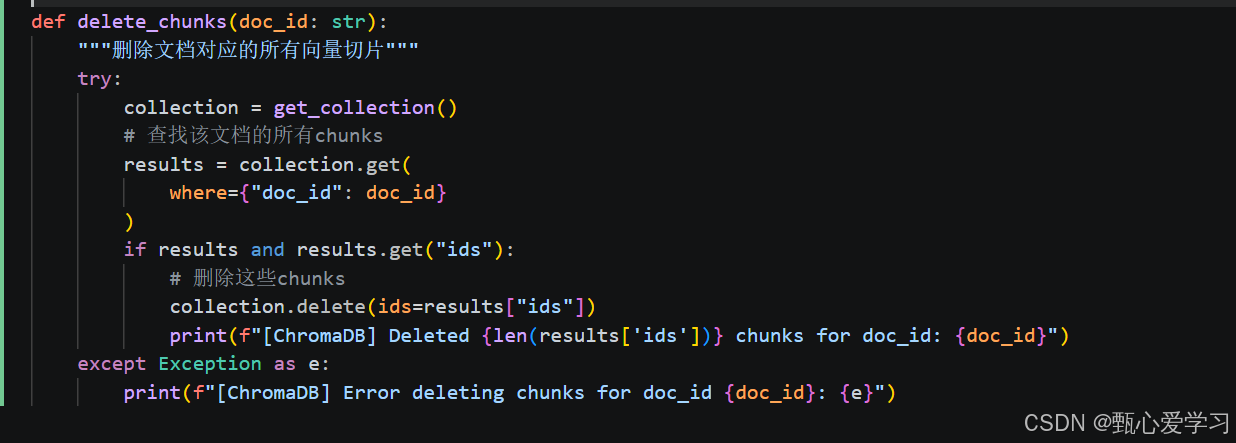
documents中删除文档时同步清理ChromaDB
实现:
3.实现历史记录功能
HistoryPanel.vue组件在mounted生命周期通过getHistory API获取历史记录列表展示在table组件中。用户可通过输入框搜索文件名、文档ID或案件类型过滤历史记录,点击查看按钮通过useRouter导航到文档详情页面。用户点击"清空历史"按钮调用clearHistory API清空所有历史记录。历史记录数据结构包含doc_id、filename、case_type和timestamp字段
GET /api/storage/history端点调用storage_service.get_history方法从local的history.json文件读取并返回历史记录列表。POST /api/storage/history端点接收前端发送的HistoryItem数据,add_history服务方法会先去重相同doc_id的旧记录、自动添加毫秒级时间戳、将新记录插入列表顶部、只保留最新50条记录,最后写入history.json文件。DELETE /api/storage/history端点调用clear_history方法清空history.json文件内容。

4.双栏阅读
加入初步的双栏阅读功能,后续会进一步完善功能
双栏阅读功能由ReaderView.vue组件实现,采用左右分栏布局。用户进入阅读模式后,前端同时通过getDocument和getBlocks两个API函数异步获取文档的完整信息(包括元数据和提取的结构化字段)以及所有文本块(TextBlock)。左栏显示文档的完整文本内容,右栏集成AnnotationPanel.vue表现层组件用于管理批注。当用户选中左栏的任意文本时,触发mouseup事件调用annotationRef的handleTextSelect方法,该方法通过window.getSelection()API获取选中的文本内容,自动填充到批注表单中。用户在批注对话框中填写批注内容、选择标记颜色后点击保存按钮,前端调用saveAnnotation函数向后端POST请求保存批注数据。批注保存成功后,前端重新调用getAnnotations API获取该文档的最新批注列表并更新右栏显示,同时支持删除功能通过deleteAnnotation API调用后端删除接口实现。
后端在storage.py中定义了完整的批注管理API。POST /api/storage/annotations端点负责创建新批注,接收前端发送的AnnotationCreate模型数据(包含doc_id、selectedText、comment、color等字段),服务端自动生成8位十六进制ID和毫秒级时间戳,调用storage_service.save_annotation方法将批注数据持久化存储到本地JSON文件。GET /api/storage/annotations/{doc_id}端点调用storage_service.get_annotations方法返回指定文档的所有批注集合,AnnotationPanel前端组件使用该API在mounted生命周期获取初始批注列表。DELETE /api/storage/annotations/{doc_id}/{annotation_id}端点通过storage_service.delete_annotation服务方法删除指定ID的批注记录。PUT /api/storage/annotations/{doc_id}/{annotation_id}端点支持批注内容和颜色的更新操作。所有批注数据结构包含id、doc_id、page、selectedText、comment、color和timestamp字段,持久化存储采用文档隔离的JSON格式,确保支持多用户并发操作和批量导出。
5.自定义示例库管理功能
由于预置的示例会通过创建 Blob 重新走一遍上传解析流程,将使自定义示例遵循相同的逻辑。
下面是具体涉及修改的文件和模块:
后端层 (Database & Services)
MODIFY backend/app/database.py
- 新增
custom_samples数据库表,包含字段:id,name,type,content,created_at。 - 增加针对
custom_samples表的基础 CRUD 数据库操作函数 (如add_custom_sample,get_all_custom_samples,delete_custom_sample,update_custom_sample)。
MODIFY backend/app/api/samples.py
- 扩展
GET /list接口,使其返回预置示例列表与自定义示例列表的合并结果(或将自定义标记独立出来)。 - 修改
GET /{sample_id}接口,当在预置示例中找不到时,从数据库的custom_samples表中获取内容。 - 新增
POST /custom接口:接收名称、类型、文本内容,并生成 ID 存入数据库。 - 新增
PUT /custom/{sample_id}接口:用于重命名(和修改类型)。 - 新增
DELETE /custom/{sample_id}接口:用于删除自定义示例。
前端层 (API & UI)
MODIFY frontend/src/api/samples.ts
- 新增
addCustomSample,updateCustomSample,deleteCustomSample的 axios 请求函数。 - 更新相关的类型定义,以便在前端区分哪些是内置示例,哪些是自定义示例。
MODIFY frontend/src/views/DocumentView.vue
- 在顶部操作栏
header-actions(目前有"导出"、"删除")旁边,新增一个 "设为示例" 的按钮。 - 点击时弹出一个对话框,要求输入示例名称(默认填充当前文件名)及案件类型。
- 确认时,提取当前文档全文(遍历拼接
blocks.content),调用addCustomSample添加至示例库。
MODIFY frontend/src/components/SampleLoader.vue
- 优化 UI 展示:如果有自定义示例,可以在列表中加入标识,或是分为"预置示例"与"自定义示例"两个小节。
- 针对自定义示例,在加载按钮旁添加 "重命名" (编辑小图标)和 "删除"(垃圾桶小图标)功能操作。
- 实现对应的弹窗和 API 请求交互逻辑。
展示:
- 端在数据库增加了一个查询,前端在每次进入文档界面时(
onMounted)会自动带上当前的doc_id向后端发起查验请求。 - 状态同步: 如果这个文书记录此时已经存在于"自定义示例库"中,它的高亮状态就会被重新加载激活,立刻显示为黄色的实心星星
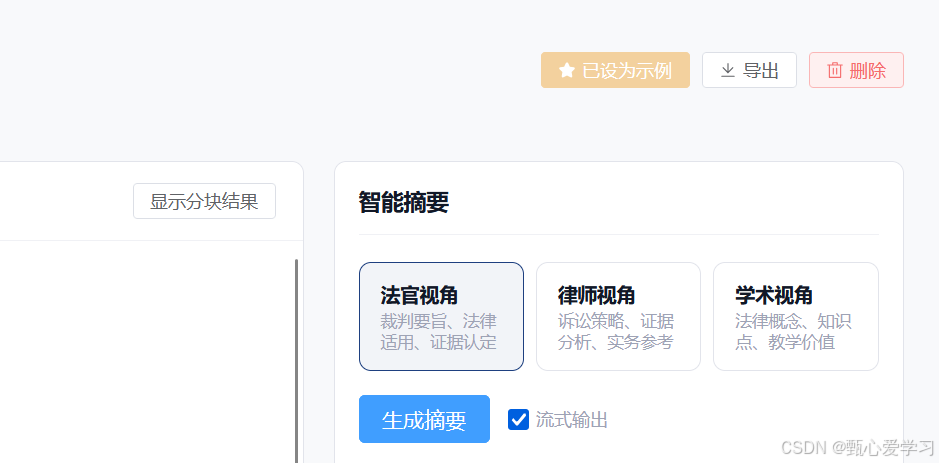
其他内容
1.整理团队进度开发文档
2.提升示例加载速度
加载某个示例(无论是预置还是自定义)的底层逻辑,其实是把示例的"纯文本"重新走了一遍完整的"上传、解析、LLM 信息抽取、向量化"流程。
只要有文本进入 upload,后端就会调用大模型进行实体提取(原被告、案由等)、多维度文书分类、以及分块(chunk)存入向量数据库,这些大模型调用和特征向量计算过程通常会耗时好几秒
针对自定义示例: 既然它本身就是从一份已经解析好的文书转化而来的,且我们不久前刚刚实现了"原文档删除时自动删除示例"以保持它们生命周期的同步。这意味着:原文档一定存在 。 我们完全可以直接获取它的 doc_id,点击"加载"时,不要再去上传,而是直接前端路由跳转到这篇文档页,速度瞬间变为 0 秒(几乎等同于点击历史记录)。
针对系统预置示例(民事、刑事、行政): 目前每次加载预置示例都会发给大模型重新解析一次,完全没必要。 我们可以在后端进行拦截处理:比如第一次加载"民事判决书"时,程序赋予它一个固定的 ID(如 doc_builtin_civil)走一遍缓慢的解析解析并存入数据库。之后任何人再点击加载,直接检测数据库里存在这个固定 ID 的记录,立刻返回该 ID 跳过所有大模型调用。
3.历史记录与文书管理去重
POST /api/documents/upload 接口加装了 MD5 文件哈希去重机制:
- 现在如果用户真的去手动上传一份本地的 PDF / Word 文件。
- 系统会提取这盘二进制文件专属的 MD5 哈希指纹并比对数据库。
- 如果数据库里已经存在一模一样的哈希值,系统会直接拦截大模型处理全流程,并跳出一条"文件已存在,秒传成功"的提示,直接让该用户跳转进已经存好的文档详情页面里,不会拜拜消耗系统资源
遇到的问题及解决方法
1.历史记录无法正确保存
在后端的终端日志中,有一条记录: INFO: 127.0.0.1:57536 - "POST /api/storage/history HTTP/1.1" 422 Unprocessable Entity

原因: 在前端打开一个文档(比如 civil_sample.txt)时,前端会通过 POST 请求向后端写入一条历史记录。问题出在后端数据校验中,后端的 HistoryItem 模型强制要求前端必须传一个 timestamp,但是在重构前端 storage.ts时,让所有的时间戳都在后端由服务器自动统一生成了, 只给了后端去传除时间以外的信息,两者发生了矛盾,FastAPI 进行强制拦截,抛出了 422 错误,导致 历史记录根本没有顺利被写入到 history.json 中。
解决方法:修改了 c:\legal_system\app\backend\app\models\schemas.py,将 timestamp 设置为了有默认值的可选字段:
class HistoryItem(BaseModel): 、
... 其他字段
timestamp: float = 0.0
修改后可以成功存储:
通过doc_id索引到对应的法律文书
2. 解决团队合作中的代码冲突
-
main.py 保留初始化数据库与注册存储 API 的两行导入。确保业务逻辑完整,两个功能入口均正常运行。
-
backend/.env 执行删除操作。该文件包含敏感 API 密钥 OPENAI_API_KEY 且已在 .gitignore 声明,不应进入版本控制,由开发者本地自行创建。
-
前端组件 统一切换为 API 调用模式。彻底删除 utils/storage.ts 本地存储方案,实现前端通过后端 API 写入数据库的完整链路。
-
新增与修改文件 提交所有关于批注功能从 JSON 迁移至 SQLite 的新实现,包括后端 API 接口、服务层逻辑及前端视图更新。
(为方便提交,我们团体暂时使用github存储代码,最后会提交到gitee)
3.批注保存报错
在 storage.py 的 create_annotation 端点(第 36-41 行)中:
annotation_in.dict()产生{'selectedText': ...}- 传给
storage_service.save_annotation(),该方法把selectedText转为selected_text并修改了原字典 (pop) - 然后
return annotation_dict返回的字典已经没有selectedText了,只有selected_text - FastAPI 用
Annotation模型验证返回值,找不到selectedText就报错
修复方法:在 create_annotation 返回前确保字段名正确
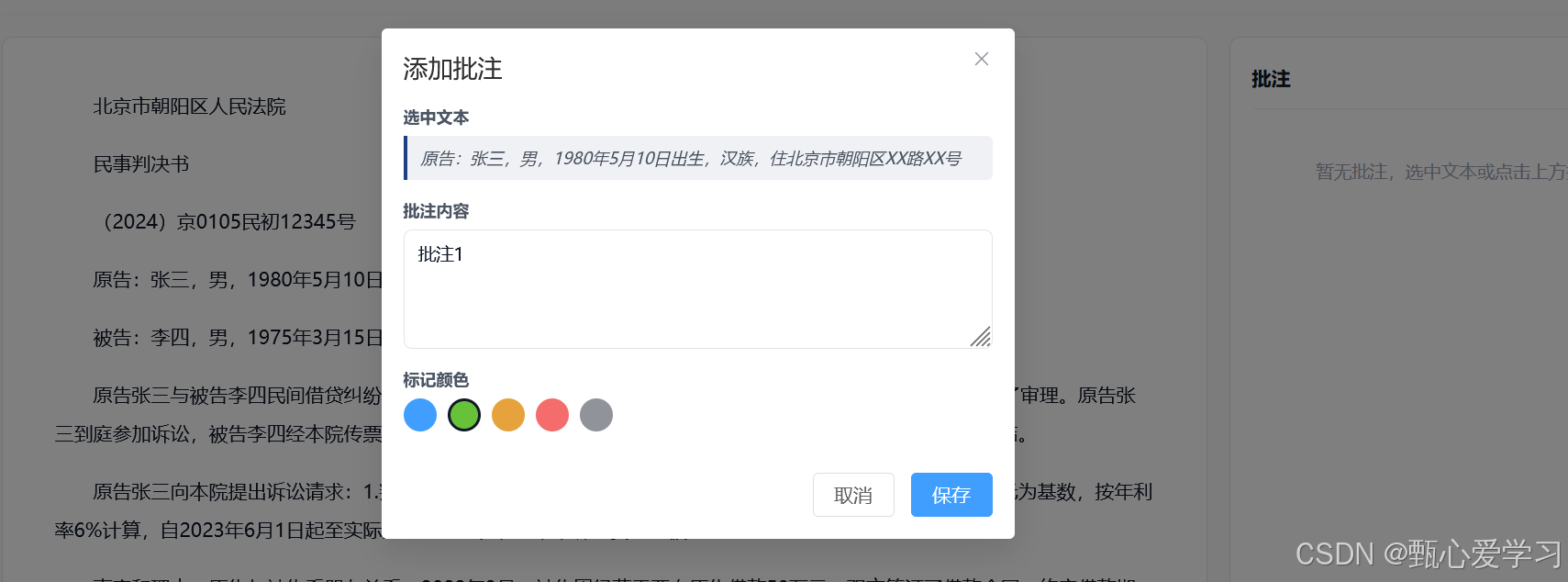
另外,批注的时间出了一些问题:
SQLite 的 CURRENT_TIMESTAMP 存的是 UTC 时间 (比北京时间早 8 小时),之前代码把它当本地时间解析,所以显示的时间少了 8 小时。现在加了 .replace(tzinfo=timezone.utc) 明确指定为 UTC,前端 toLocaleString('zh-CN') 就会自动转成北京时间显示了。
4.自定义文档无法同步删除
- 历史记录 (History) 同步删除
- 后端新增了
remove_history_by_doc支持对 localStorage 中镜像的历史记录 JSON 文件进行清洗。 - 在
DELETE /api/documents/{doc_id}时,自动顺带清除对应的那条历史记录。
- 自定义示例 (Custom Samples) 同步删除
- 为 SQLite 数据库的
custom_samples表强行注入了doc_id追踪列。 - 您在前端执行"设为示例"的动作时,系统会自动把
doc_id绑定到那份新示例上。 - 现在只要该文档被删除,数据库会使用相同的
doc_id匹配连同示例库中的项一并删除(对于本次修复之后生成的示例立刻生效)。
个人小结
提交代码时候,可以频繁commit,但是push的时候可以一段时间后再push
经过本次迭代,我主要完成了历史记录与批注的持久化存储改造、ChromaDB同步删除、双栏阅读功能、自定义示例库管理以及多项性能优化。在存储方面,后端新增了schemas.py中的强类型校验模型、storage_service.py读写控制模块以及完整的RESTful CRUD接口,前端将原有的LocalStorage同步调用替换为基于Axios的网络异步请求,实现了历史记录和批注在后端data目录的持久化。同时批注数据迁移至SQLite,历史记录仍使用JSON格式存储。在文档删除时,vector_store中新增delete_chunks函数同步清理ChromaDB中的向量数据。双栏阅读功能通过ReaderView.vue实现左右分栏布局,左栏展示文档全文,右栏集成批注组件,支持文本选中自动填充批注表单。自定义示例库在数据库新增custom_samples表,前端提供设为示例、重命名、删除等交互,且示例加载时针对自定义示例直接跳转已有文档页面,预置示例采用固定ID缓存机制,避免重复的大模型调用,显著提升了加载速度。
在开发过程中,我遇到并解决了若干关键技术问题。历史记录保存时因后端HistoryItem模型强制要求timestamp字段而前端未传递,导致422错误,通过将timestamp设为可选默认值解决。批注保存时因字段名selectedText与selected_text不一致导致返回验证失败,通过在API返回前统一字段名修复。批注时间显示因SQLite的CURRENT_TIMESTAMP存储UTC时间而被误解析为本地时间,导致显示少8小时,通过明确指定时区为UTC并在前端使用toLocaleString转换解决。自定义示例无法随文档同步删除,因custom_samples表缺少doc_id追踪列,通过新增该字段并建立关联实现级联删除。团队协作中遇到代码冲突,通过加强前后端接口定义沟通和频繁同步解决。整体上,本次迭代完善了数据持久化、提升了系统响应速度,并增强了团队协作的规范性。