目录
[高级篇 - 多级缓存 - 01 - 什么是多级缓存](#高级篇 - 多级缓存 - 01 - 什么是多级缓存)
[高级篇 - 多级缓存 - 02-JVM 进程缓存 - 导入 Demo 数据](#高级篇 - 多级缓存 - 02-JVM 进程缓存 - 导入 Demo 数据)
[高级篇 - 多级缓存 - 03-JVM 进程缓存 - 导入 Demo 工程](#高级篇 - 多级缓存 - 03-JVM 进程缓存 - 导入 Demo 工程)
[高级篇 - 多级缓存 - 04-JVM 进程缓存 - 初识 Caffeine](#高级篇 - 多级缓存 - 04-JVM 进程缓存 - 初识 Caffeine)
[高级篇 - 多级缓存 - 05-JVM 进程缓存 - 实现进程缓存](#高级篇 - 多级缓存 - 05-JVM 进程缓存 - 实现进程缓存)
[高级篇 - 多级缓存 - 06-Lua 语法 - 初识 Lua](#高级篇 - 多级缓存 - 06-Lua 语法 - 初识 Lua)
[高级篇 - 多级缓存 - 07-Lua 语法 - 变量和循环](#高级篇 - 多级缓存 - 07-Lua 语法 - 变量和循环)
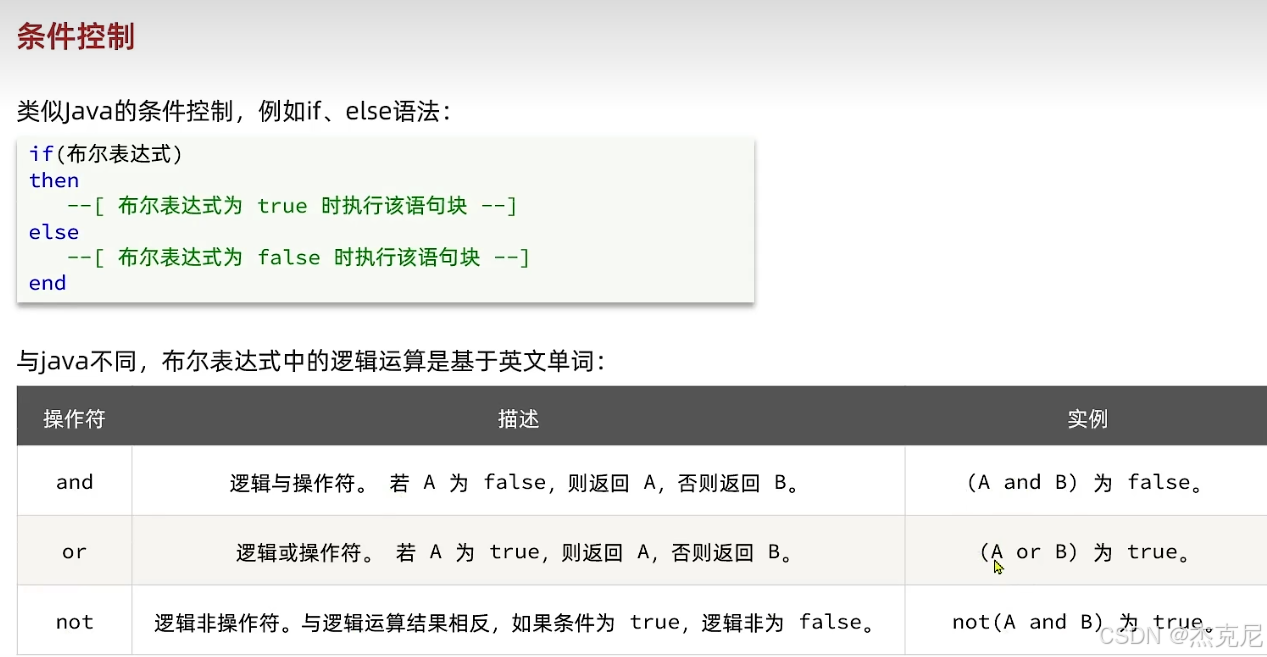
[高级篇 - 多级缓存 - 08-Lua 语法 - 函数和条件控制](#高级篇 - 多级缓存 - 08-Lua 语法 - 函数和条件控制)
[高级篇 - 多级缓存 - 09 - 安装 OpenResty](#高级篇 - 多级缓存 - 09 - 安装 OpenResty)
[高级篇 - 多级缓存 - 10-OpenResty 快速入门](#高级篇 - 多级缓存 - 10-OpenResty 快速入门)
[高级篇 - 多级缓存 - 11-OpenResty 获取请求参数](#高级篇 - 多级缓存 - 11-OpenResty 获取请求参数)
[高级篇 - 多级缓存 - 12 - 封装 Http 请求工具](#高级篇 - 多级缓存 - 12 - 封装 Http 请求工具)
[高级篇 - 多级缓存 - 13 - 向 tomcat 发送 http请求](#高级篇 - 多级缓存 - 13 - 向 tomcat 发送 http请求)
[高级篇 - 多级缓存 - 14 - 根据商品 id 对 tomcat集群负载均衡](#高级篇 - 多级缓存 - 14 - 根据商品 id 对 tomcat集群负载均衡)
[高级篇 - 多级缓存 - 15-Redis 缓存预热](#高级篇 - 多级缓存 - 15-Redis 缓存预热)
[高级篇 - 多级缓存 - 16 - 查询 Redis](#高级篇 - 多级缓存 - 16 - 查询 Redis)
[高级篇 - 多级缓存 - 17-nginx 本地缓存](#高级篇 - 多级缓存 - 17-nginx 本地缓存)
[高级篇 - 多级缓存 - 18 - 缓存同步 - 数据同步策略](#高级篇 - 多级缓存 - 18 - 缓存同步 - 数据同步策略)
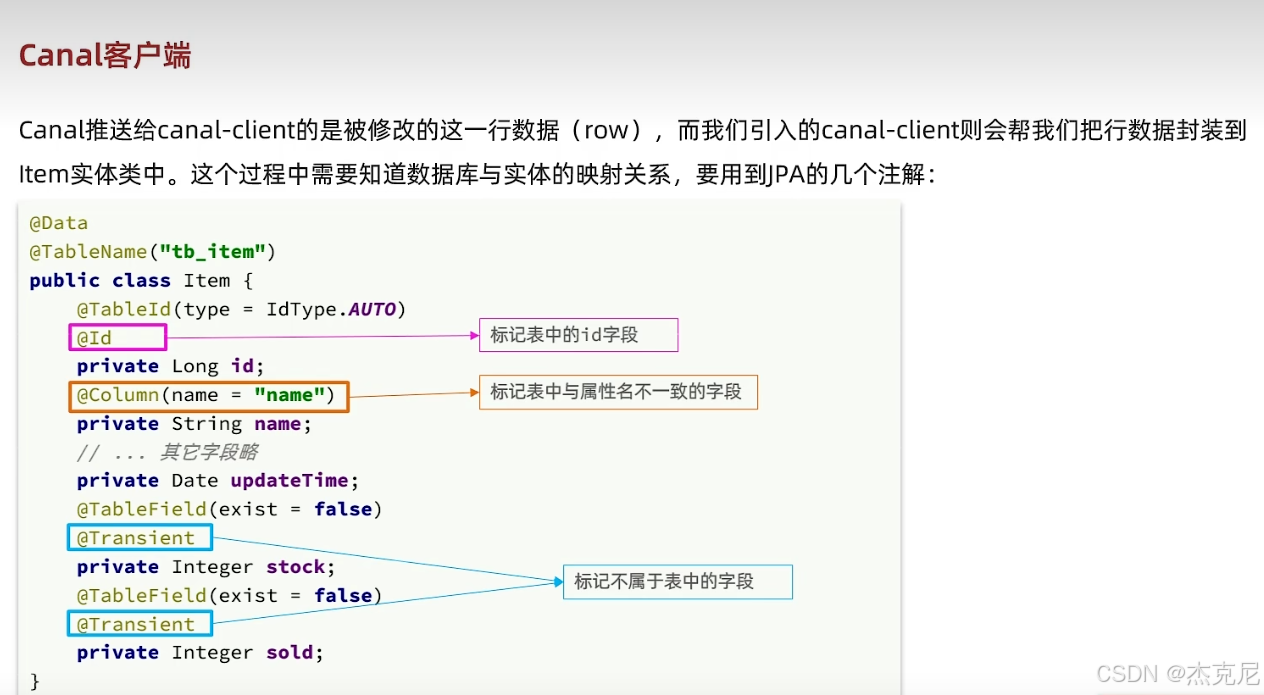
[高级篇 - 多级缓存 - 19 - 缓存同步 - 安装 Canal](#高级篇 - 多级缓存 - 19 - 缓存同步 - 安装 Canal)
[高级篇 - 多级缓存 - 20 - 缓存同步 - 监听 canal 实现缓存同步](#高级篇 - 多级缓存 - 20 - 缓存同步 - 监听 canal 实现缓存同步)
[高级篇 - 多级缓存 - 21 - 课程总结](#高级篇 - 多级缓存 - 21 - 课程总结)
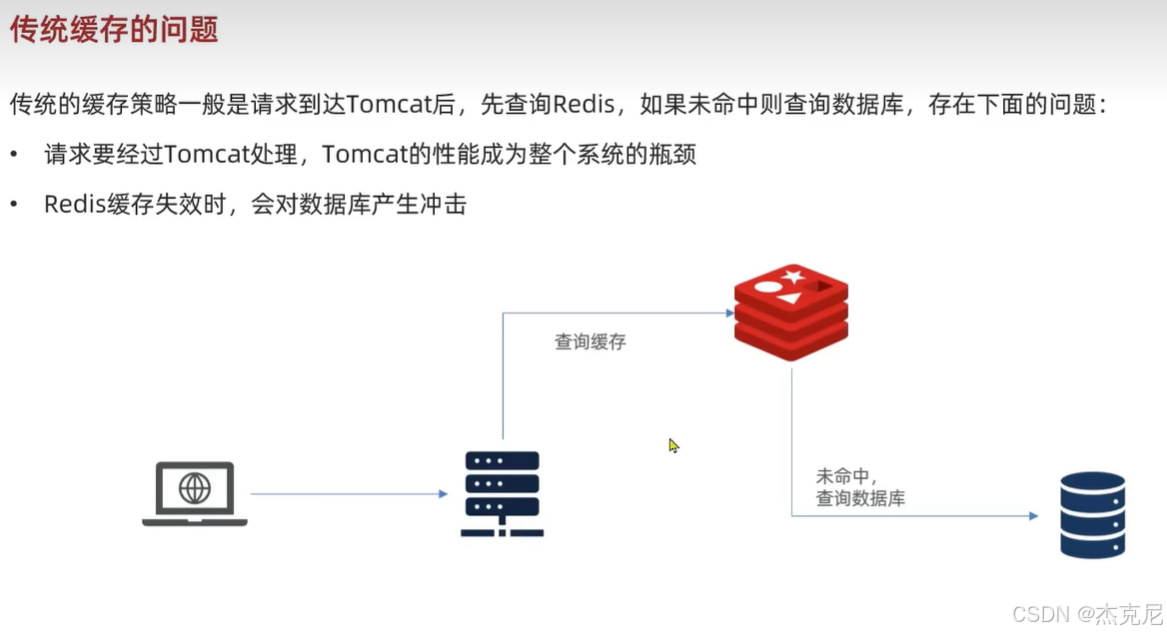
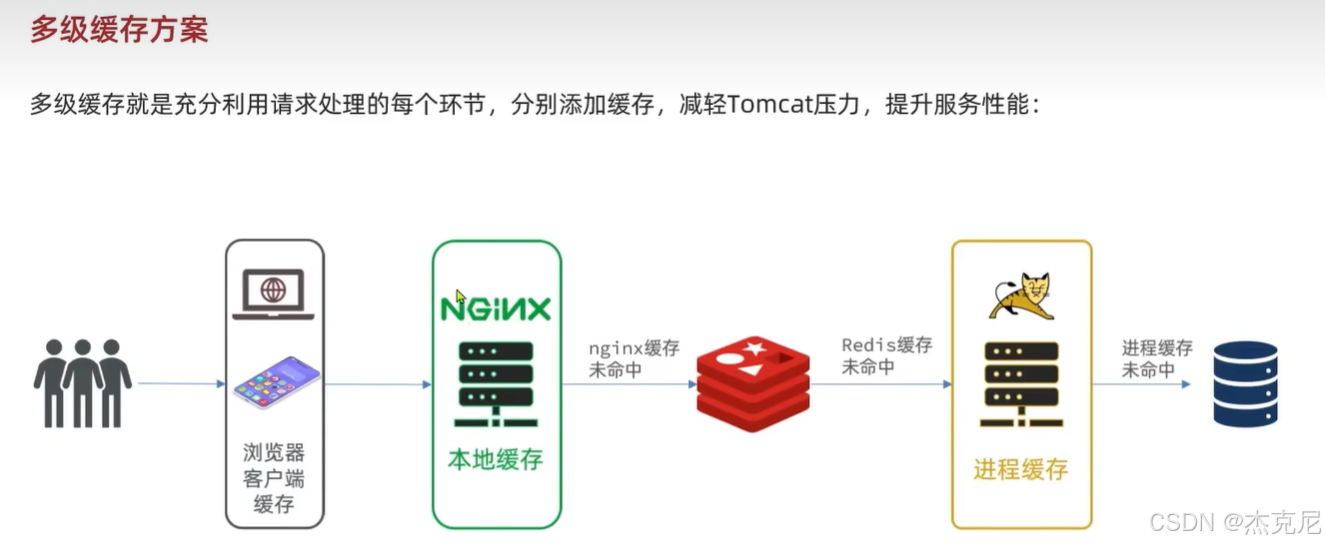
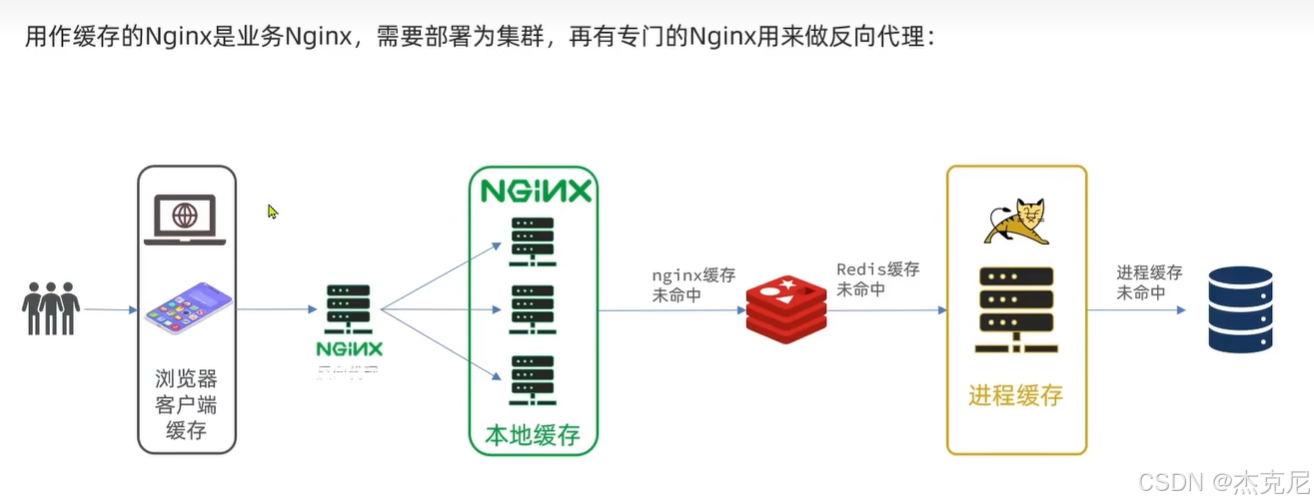
高级篇 - 多级缓存 - 01 - 什么是多级缓存

高级篇 - 多级缓存 - 02-JVM 进程缓存 - 导入 Demo 数据
高级篇 - 多级缓存 - 03-JVM 进程缓存 - 导入 Demo 工程
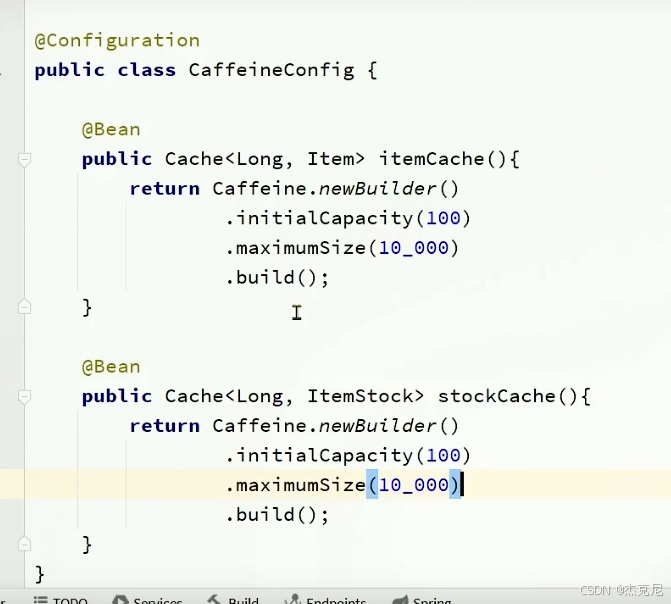
高级篇 - 多级缓存 - 04-JVM 进程缓存 - 初识 Caffeine




高级篇 - 多级缓存 - 05-JVM 进程缓存 - 实现进程缓存

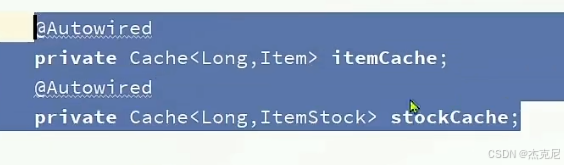
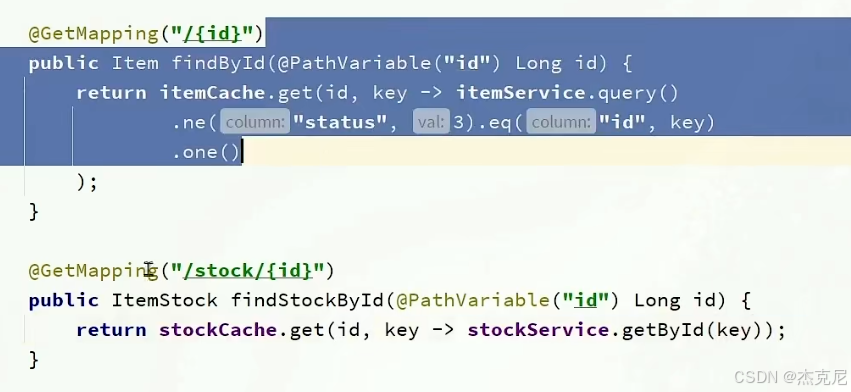
问题:怎么使用本地缓存?
使用autowired注入即可使用
高级篇 - 多级缓存 - 06-Lua 语法 - 初识 Lua

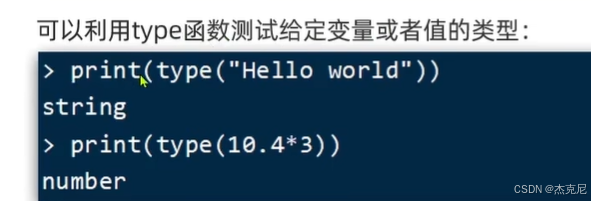
高级篇 - 多级缓存 - 07-Lua 语法 - 变量和循环

问题:Lua中local表示什么?
表示局部变量




高级篇 - 多级缓存 - 08-Lua 语法 - 函数和条件控制



高级篇 - 多级缓存 - 09 - 安装 OpenResty
OpenResty (全称 OpenResty®)是一个基于 Nginx 与 LuaJIT 的高性能 Web 应用平台 ,由章亦春(agentzh)于 2009 年创建。它将 Nginx 从传统的静态服务器 / 反向代理,升级为可直接运行动态业务逻辑的全功能 Web 应用服务器OpenResty®。

高级篇-多级缓存-09-多级缓存-安装OpenResty_哔哩哔哩_bilibili
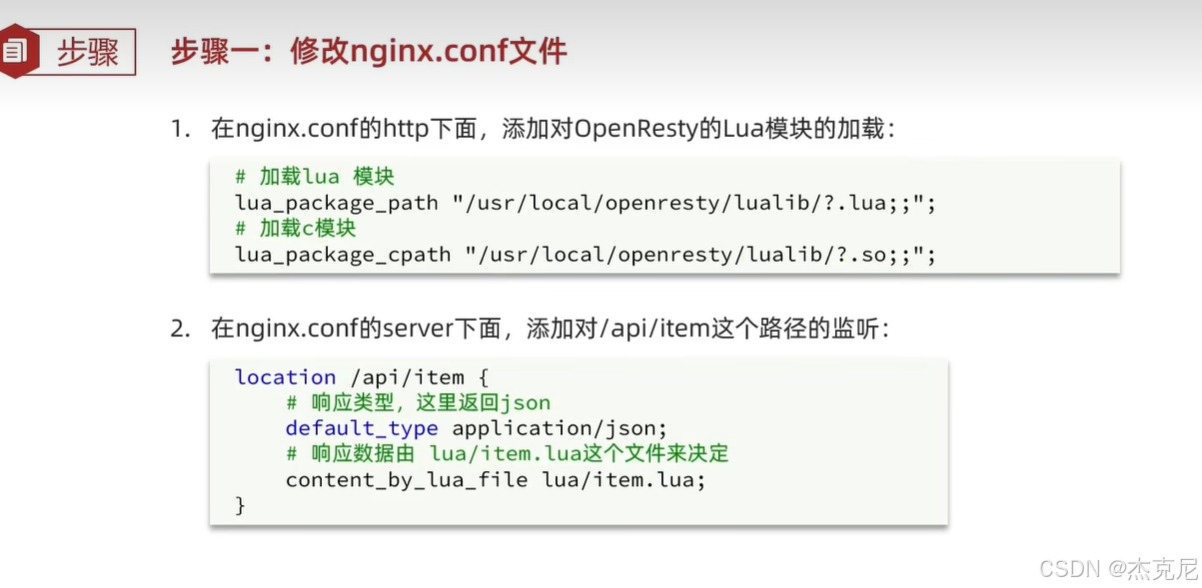
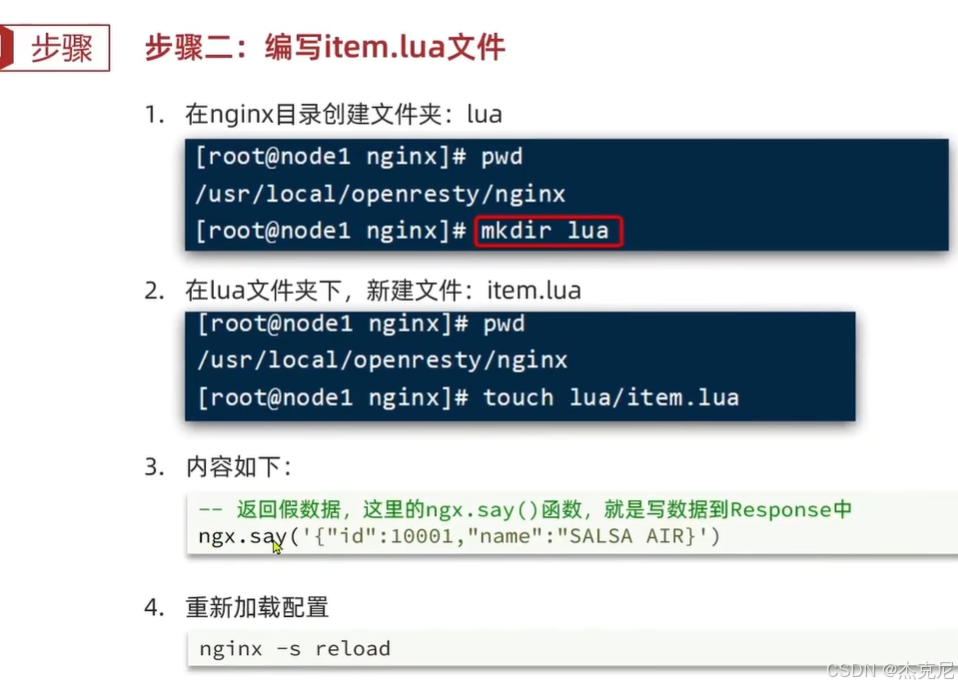
高级篇 - 多级缓存 - 10-OpenResty 快速入门

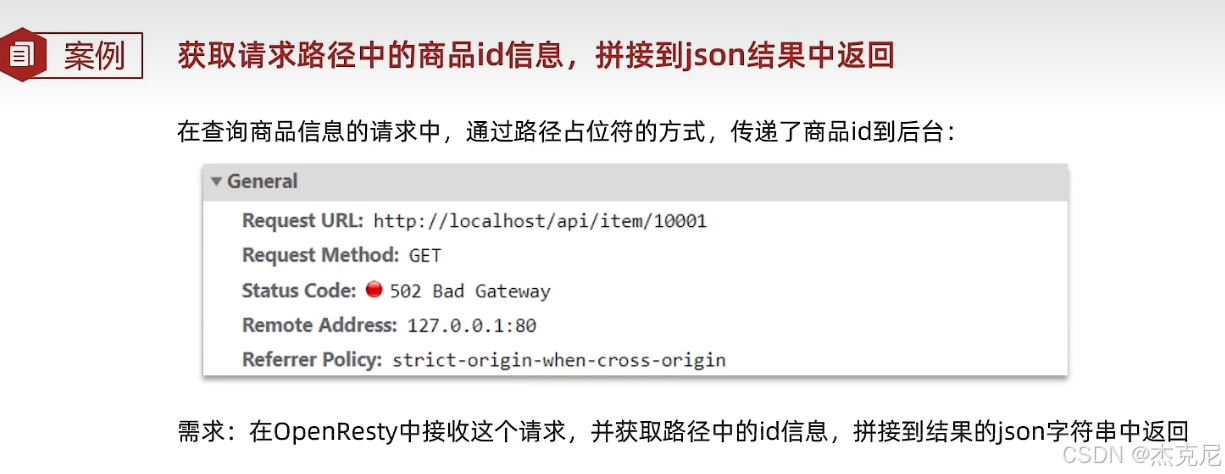
高级篇 - 多级缓存 - 11-OpenResty 获取请求参数

| 维度 | ngx.req.read_body()(读取) |
ngx.req.get_xxx()(获取) |
|---|---|---|
| 核心作用 | 加载请求体到 Nginx 缓冲区 | 从缓冲区提取 / 解析数据 |
| 执行顺序 | 必须先执行 | 必须在 read_body() 之后执行 |
| I/O 操作 | 涉及网络 / 磁盘 I/O(读取客户端数据) | 仅内存操作,无 I/O |
| 依赖关系 | 无前置依赖 | 依赖 read_body() 完成加载 |
| 适用场景 | 所有需要处理请求体的场景(POST、JSON 等) | 按数据类型提取对应参数 |
| GET 请求 | 无意义(GET 无请求体) | get_uri_args() 正常使用,无需 read_body() |
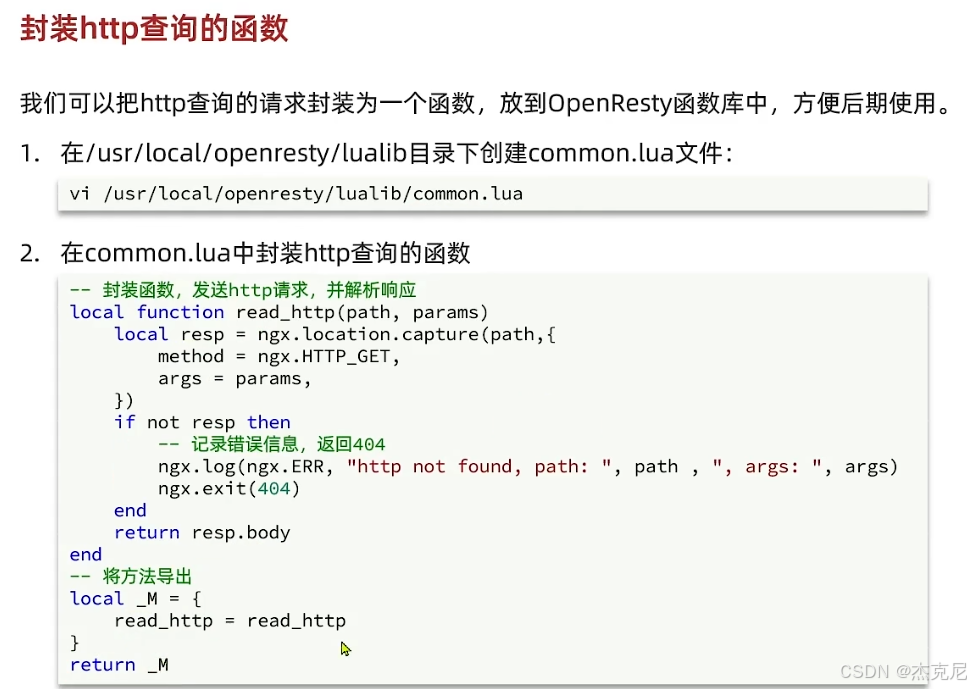
高级篇 - 多级缓存 - 12 - 封装 Http 请求工具
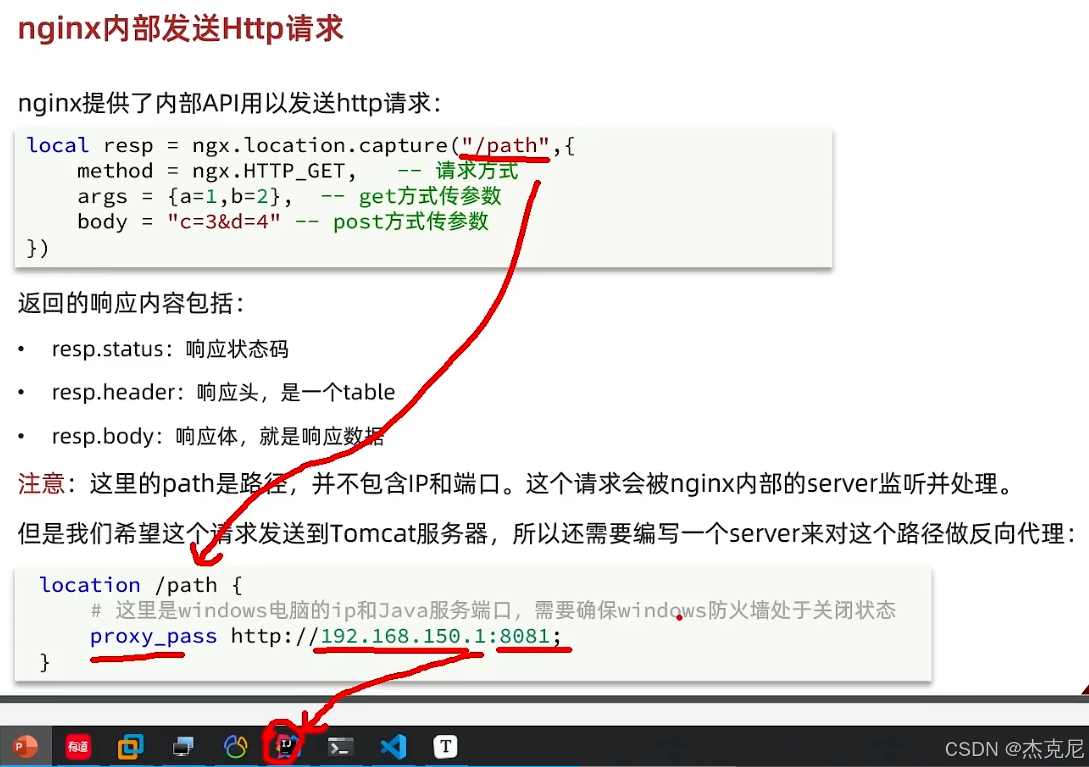

高级篇 - 多级缓存 - 13 - 向 tomcat 发送 http请求
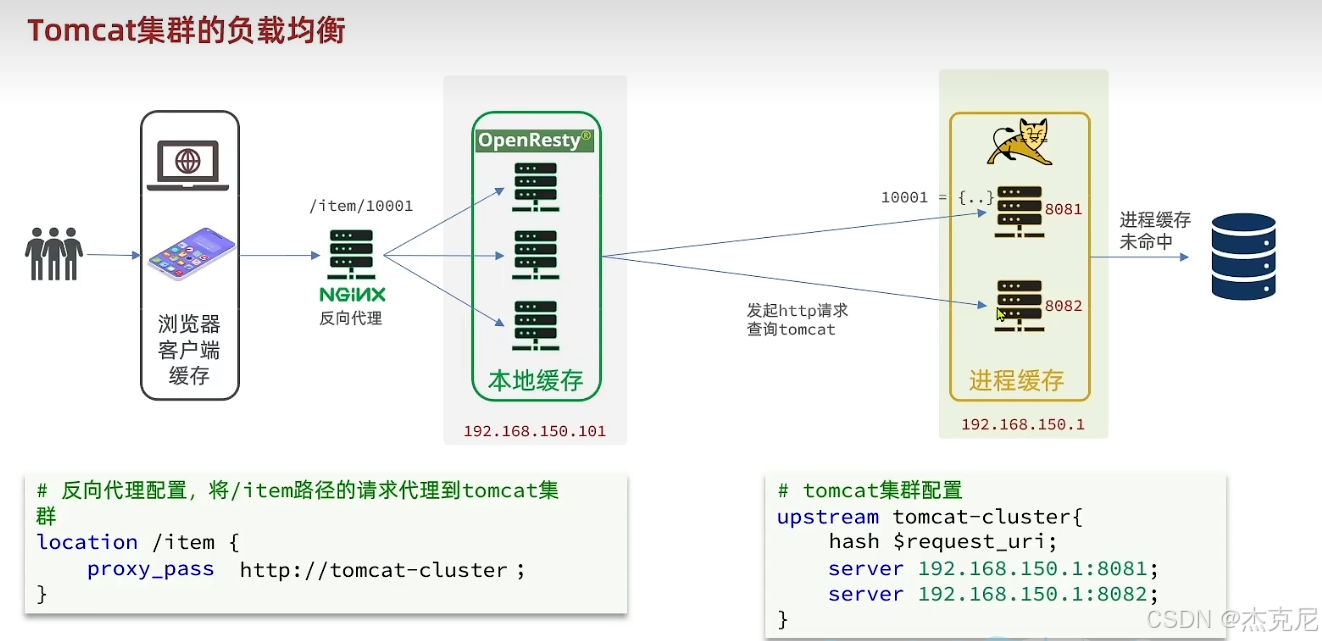
高级篇 - 多级缓存 - 14 - 根据商品 id 对 tomcat集群负载均衡
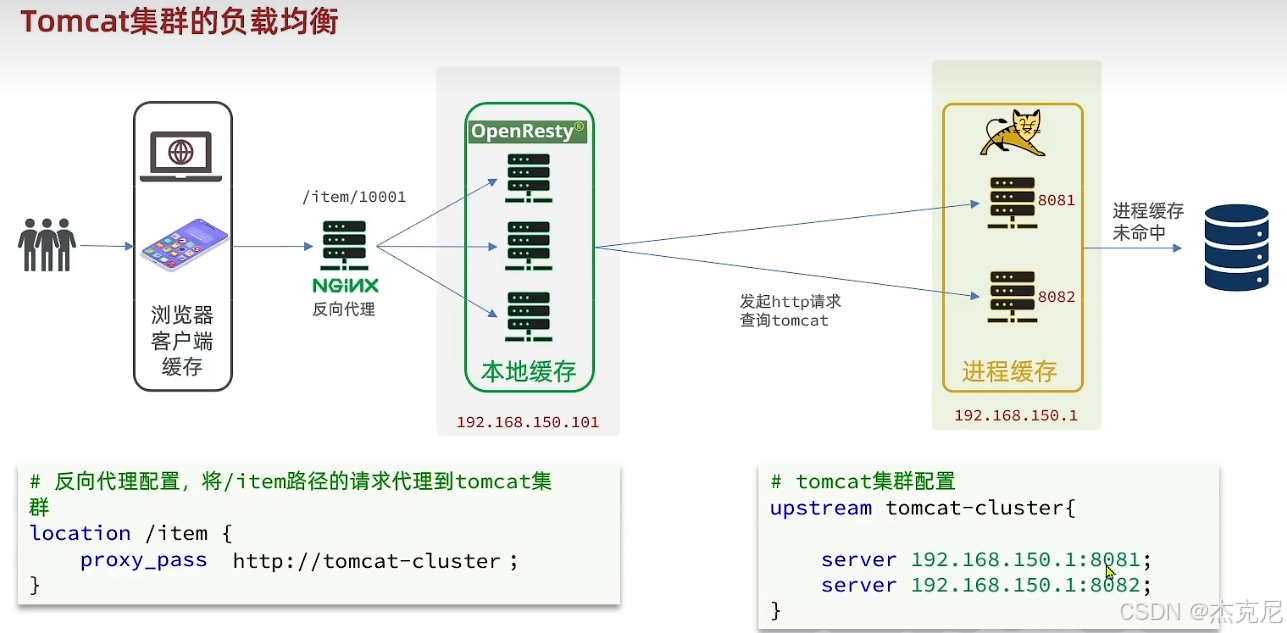
问题:下图加hash有什么用?
hash $request_uri就是给 Tomcat 集群加了一把「请求路由锁」,让同一个请求永远走同一台 Tomcat ,核心是为了提升本地缓存命中率、减少数据库压力、保证会话一致性,完美适配图中的缓存架构场景。
高级篇 - 多级缓存 - 15-Redis 缓存预热

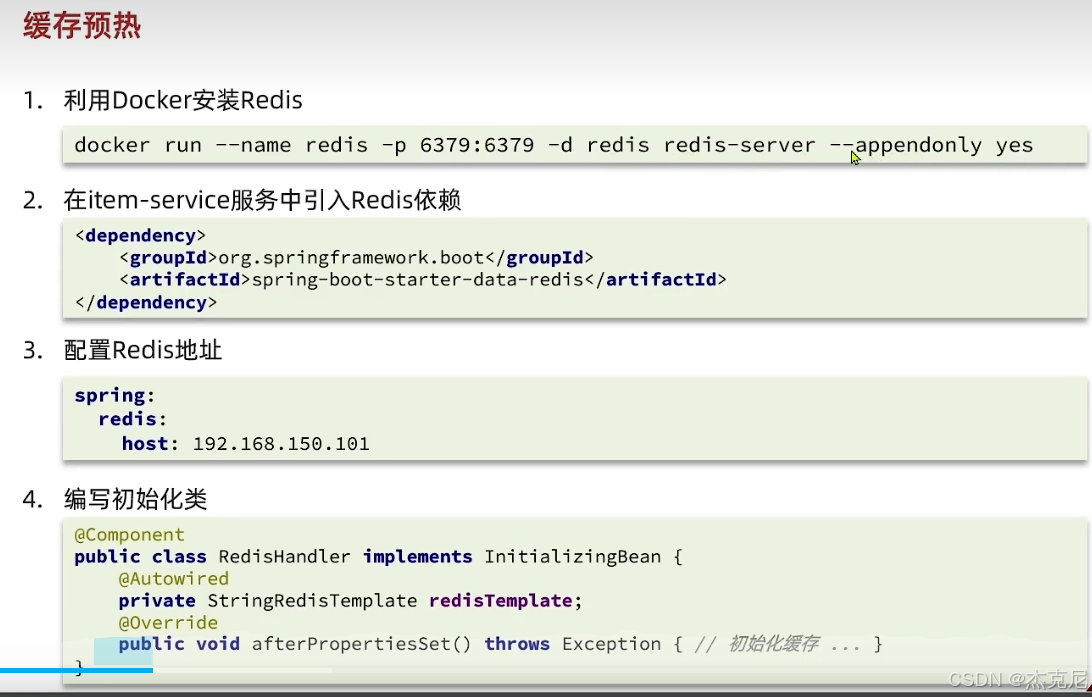
高级篇 - 多级缓存 - 16 - 查询 Redis


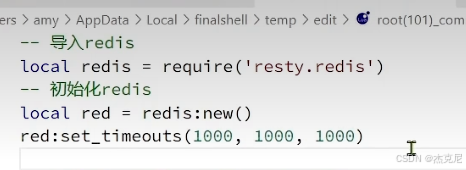
问题:这里写三个1000是什么意思?
- 第 1 个
1000:连接超时(connect_timeout) 指建立 TCP 连接到 Redis 服务器的最大等待时间。如果 1000ms(1 秒)内无法完成三次握手,直接返回连接失败,不会无限阻塞。- 第 2 个
1000:发送超时(send_timeout) 指向 Redis 发送命令(如 GET/SET)的最大等待时间。如果网络拥塞导致 1 秒内无法把请求数据完整发出去,直接报错,避免挂死。- 第 3 个
1000:读取超时(read_timeout) 指等待 Redis 返回响应结果的最大等待时间。如果 Redis 处理慢、网络延迟高,1 秒内没收到完整响应,直接超时返回,防止请求长时间占用 Nginx worker 进程。

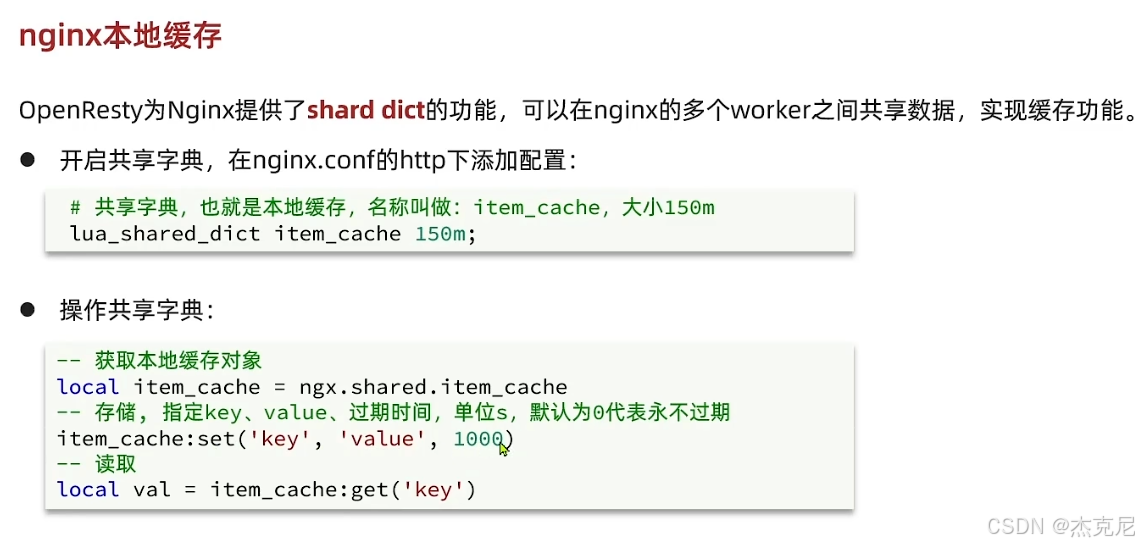
高级篇 - 多级缓存 - 17-nginx 本地缓存


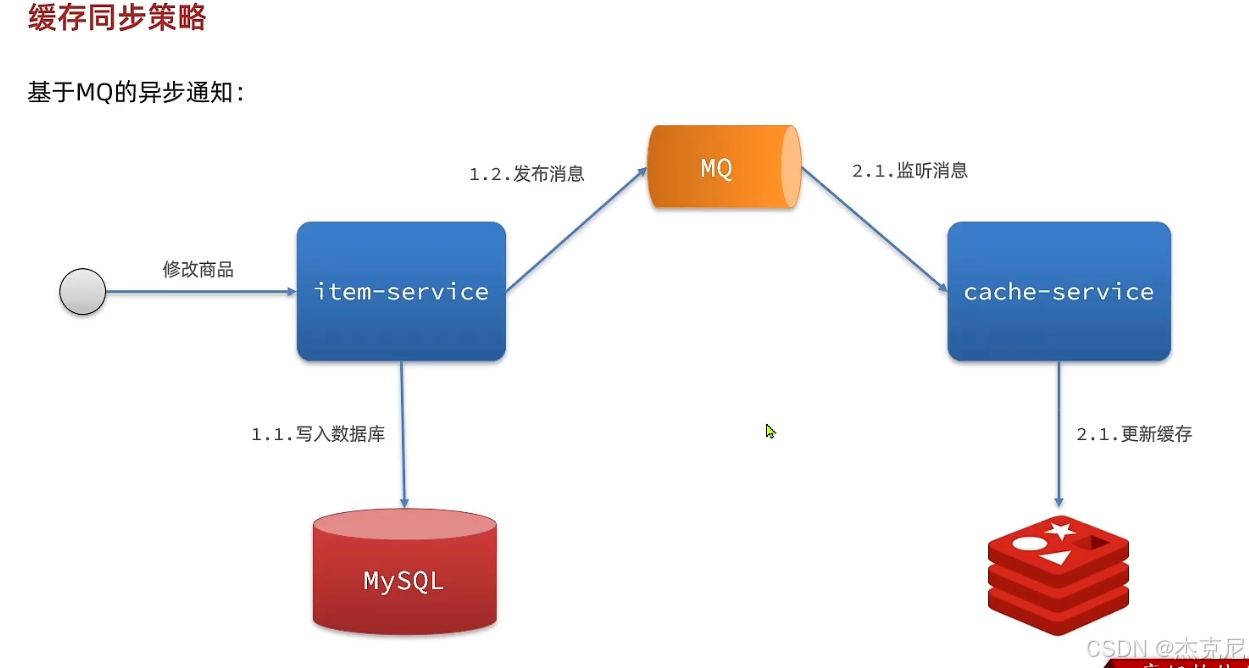
高级篇 - 多级缓存 - 18 - 缓存同步 - 数据同步策略

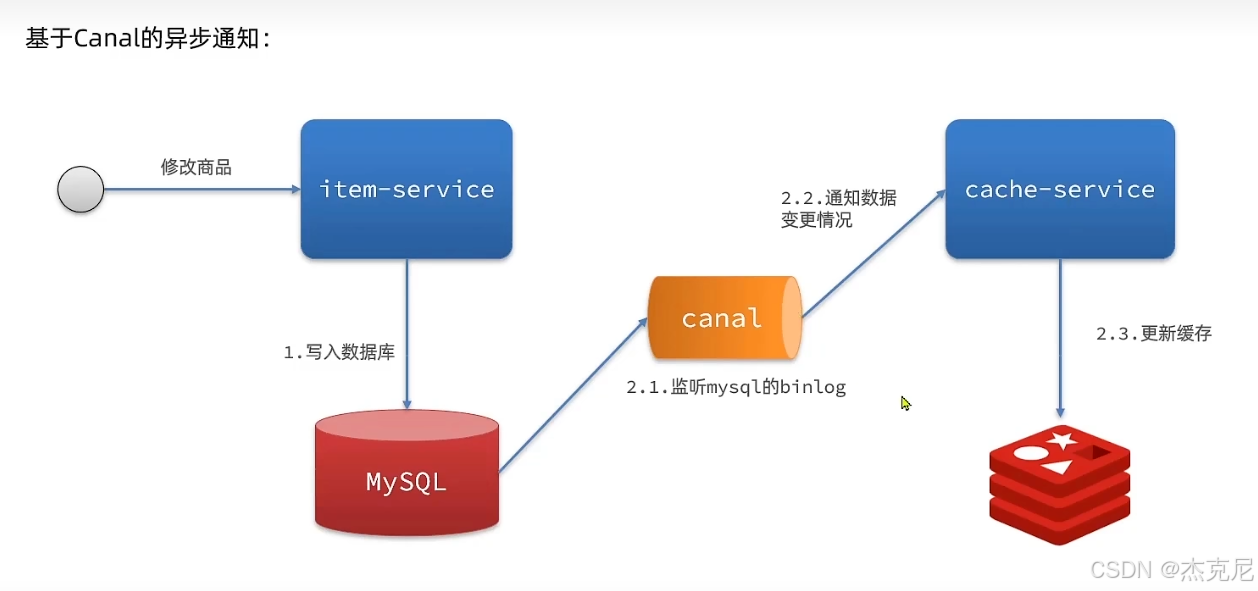
高级篇 - 多级缓存 - 19 - 缓存同步 - 安装 Canal
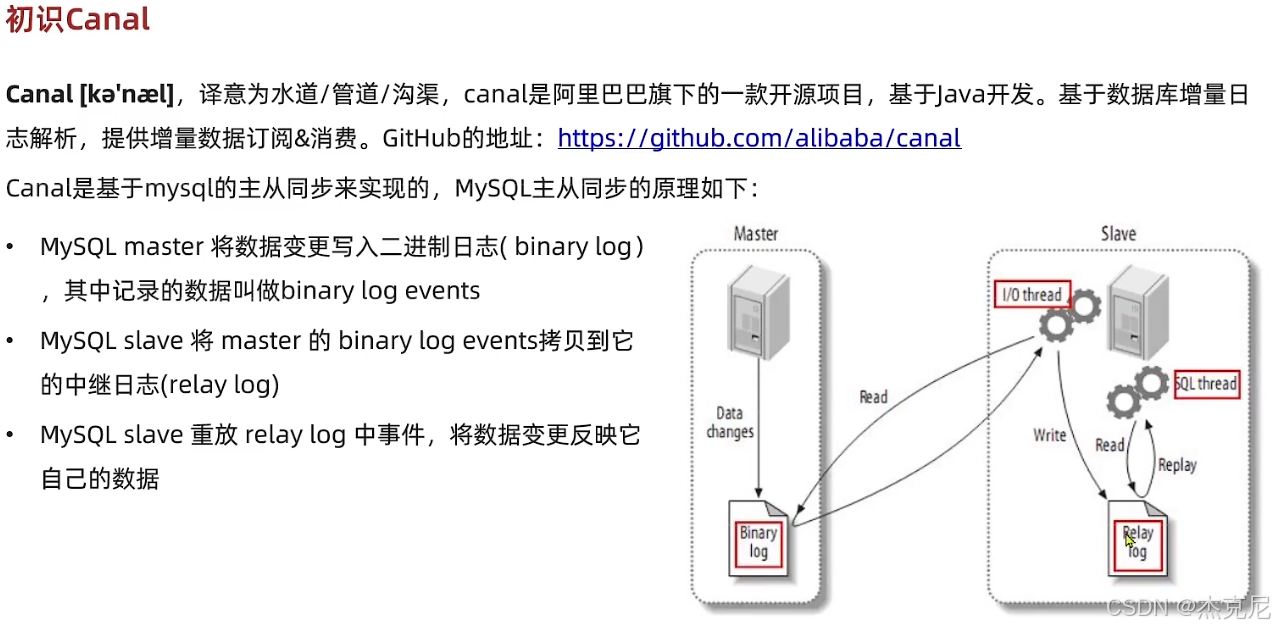
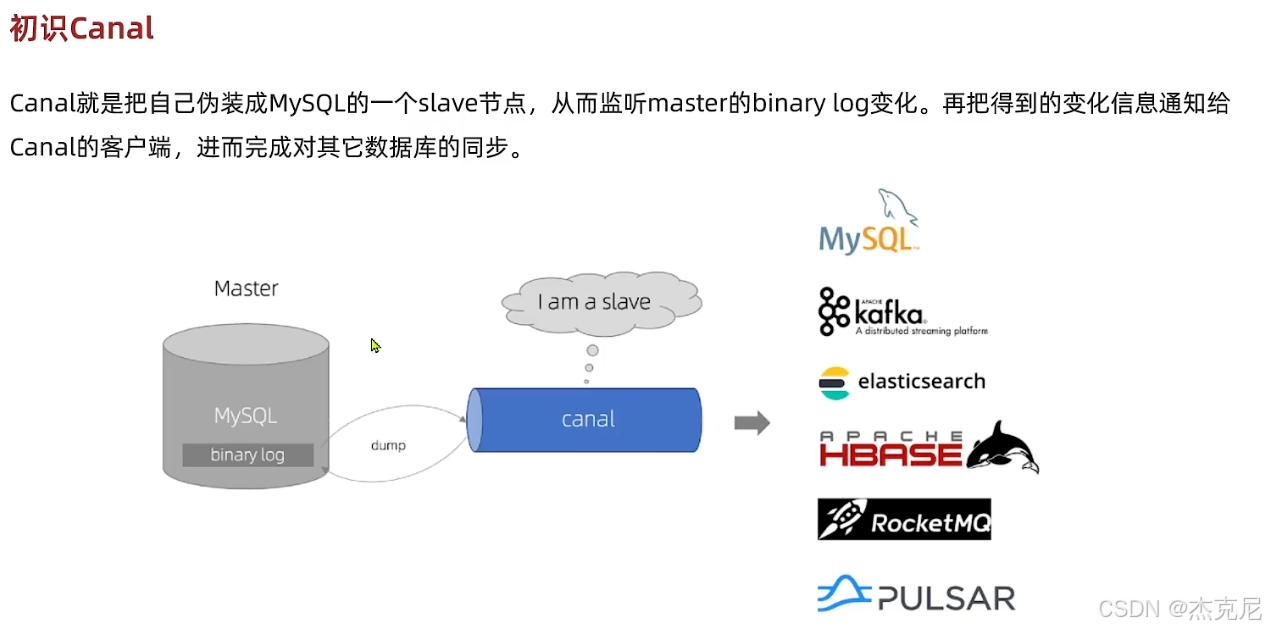
高级篇 - 多级缓存 - 20 - 缓存同步 - 监听 canal 实现缓存同步

高级篇 - 多级缓存 - 21 - 课程总结
末尾页
一、基础概念类
1. 什么是多级缓存?为什么要用多级缓存?
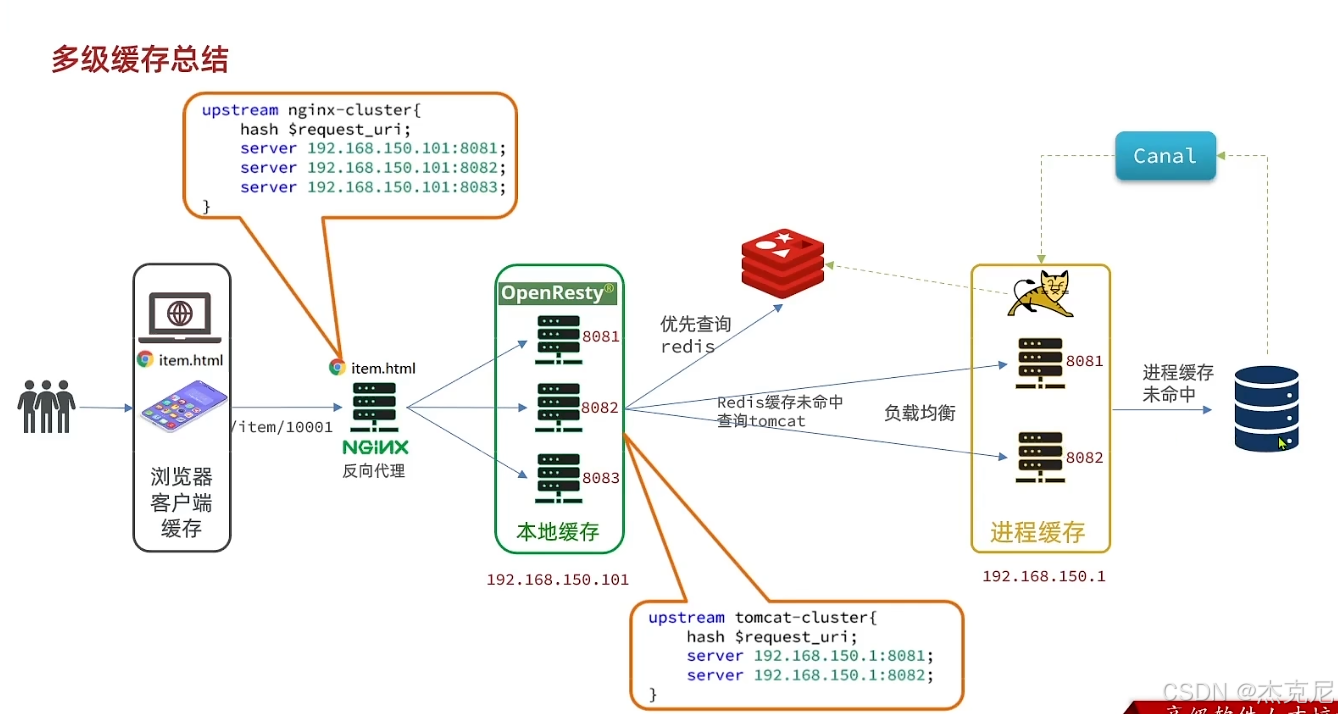
精简版 :多级缓存是在请求链路中分层部署缓存,从客户端到数据库逐层拦截请求,减少 DB 压力、提升响应速度。面试口语版:多级缓存就是把缓存分层,比如「浏览器缓存 → Nginx/OpenResty 本地缓存 → Redis 分布式缓存 → JVM 进程缓存 → 数据库」,每一层都拦截一部分请求,越靠近用户的缓存,响应越快,能极大提升系统吞吐量,扛住高并发,同时保护数据库不被打挂。
2. 典型的多级缓存架构是怎样的?
精简版 :客户端缓存 → 网关 / 代理层缓存(Nginx/OpenResty) → 分布式缓存(Redis) → 应用本地缓存(Caffeine) → 数据库面试口语版:标准的多级缓存是分层递进的:
- 最上层:浏览器 / 客户端缓存,拦截重复请求
- 网关层:Nginx/OpenResty 做本地缓存,直接在入口拦截,不用穿透到后端
- 分布式层:Redis 做全局共享缓存,解决本地缓存数据不一致问题
- 应用层:JVM 进程缓存(Caffeine),做热点数据的极致加速
- 最底层:数据库,只处理真正的穿透请求
3. JVM 本地缓存、Redis 缓存、Nginx 缓存分别解决什么问题?
表格
| 缓存层 | 核心作用 |
|---|---|
| JVM 本地缓存 | 热点数据极致加速,零网络开销,提升单实例吞吐量 |
| Redis 分布式缓存 | 全局共享缓存,解决本地缓存集群不同步问题,做数据兜底 |
| Nginx/OpenResty 缓存 | 入口层拦截,减少后端服务压力,扛住大流量 |
| 面试口语版: |
- JVM 本地缓存:存热点数据,直接在应用内存里读,零网络开销,响应最快,提升单实例性能
- Redis:做全局分布式缓存,所有实例共享,解决本地缓存集群数据不一致的问题,是多级缓存的核心兜底
- Nginx/OpenResty:在网关入口做缓存,直接在入口拦截请求,不用穿透到后端 Tomcat,极大减少服务压力,扛住高并发
4. 多级缓存的核心优势是什么?
精简版 :极致性能、高吞吐量、保护数据库、分层容错、抗高并发面试口语版:核心优势有 4 点:
- 极致性能:越靠近用户的缓存,响应越快,多级拦截让大部分请求在入口就返回
- 高吞吐量:分层分担压力,单台服务器能扛住更高的并发
- 保护数据库:99% 的请求被缓存拦截,只有极少请求打到 DB,避免 DB 被打挂
- 分层容错:某一层缓存挂了,下一层可以兜底,系统可用性更高
二、本地缓存(Caffeine/Guava)相关
5. 为什么要用 JVM 本地缓存?和 Redis 区别是什么?
精简版 :本地缓存零网络开销,性能极致;Redis 是分布式共享,解决集群一致性。面试口语版:用本地缓存核心是为了极致性能:它直接存在 JVM 内存里,没有网络开销,读性能是 Redis 的几十上百倍,适合存热点数据,把 Redis 的压力也降下来。和 Redis 的核心区别:
- 本地缓存:进程内私有,集群不共享,数据不一致,但性能极致
- Redis:分布式共享,集群数据一致,但有网络开销,性能不如本地缓存
6. 本地缓存的缺点有哪些?
精简版 :数据不一致、内存占用、无法共享、容量有限、缓存一致性难保障面试口语版:本地缓存的核心问题是「私有性」带来的:
- 集群数据不一致:每个实例的缓存是独立的,更新后其他实例感知不到
- 内存占用:缓存存在 JVM 堆里,会占用应用内存,大对象容易引发 OOM
- 无法跨实例共享:不同服务、不同实例的缓存不能互通
- 容量有限:受限于 JVM 内存,不能存大量数据
- 缓存一致性难保障:需要额外机制(如 Canal、MQ)同步更新
7. Caffeine 为什么比 Guava Cache 性能更好?
精简版 :Caffeine 基于 Window TinyLFU 算法,命中率更高,并发性能更优。面试口语版:Caffeine 是目前 Java 本地缓存的性能天花板,核心原因:
- 算法更优:用了 Window TinyLFU 淘汰算法,比 Guava 的 LRU 命中率高很多,缓存利用率更高
- 并发优化:基于 Java 8 的 ConcurrentHashMap 优化,读操作无锁,并发性能远高于 Guava
- 异步刷新:支持异步加载缓存,不会阻塞主线程,性能更稳
- 内存优化:对缓存对象做了内存优化,减少 GC 压力
8. 本地缓存过期策略有哪些?
精简版 :LRU、LFU、FIFO、TTL、随机淘汰,Caffeine 默认 Window TinyLFU面试口语版:常见的淘汰策略有:
- LRU:最近最少使用,淘汰最久没访问的
- LFU:最不经常使用,淘汰访问次数最少的
- FIFO:先进先出,按存入顺序淘汰
- TTL:按时间过期,到期自动淘汰
- 随机淘汰:随机删除Caffeine 用的是优化后的 Window TinyLFU,结合了 LRU 和 LFU 的优点,命中率最高。
9. 本地缓存什么时候适合用?什么时候不适合用?
精简版 :适合:热点数据、读多写少、一致性要求低;不适合:写频繁、一致性要求高、大数据量面试口语版:✅ 适合用的场景:
- 热点数据,读多写少(比如商品详情、配置信息)
- 对性能要求极高,能接受短暂的数据不一致
- 数据量小,不会占用太多内存❌ 不适合用的场景:
- 写频繁,一致性要求高(比如订单、库存)
- 数据量大,容易占满 JVM 内存
- 需要跨实例共享的数据
三、Nginx/OpenResty 缓存相关
10. Nginx 本地缓存(proxy_cache)和 OpenResty Lua 共享内存缓存(shared_dict)有什么区别?
精简版 :proxy_cache 是磁盘缓存,适合大体积、静态内容;shared_dict 是内存缓存,适合小体积、高频访问的动态数据。面试口语版:核心区别:
- 存储位置:proxy_cache 存在磁盘,shared_dict 存在 Nginx worker 共享内存
- 适用场景:proxy_cache 适合大体积、静态资源(图片、文件);shared_dict 适合小体积、高频访问的动态接口(商品详情)
- 性能:shared_dict 是内存操作,性能远高于磁盘的 proxy_cache
- 过期控制:shared_dict 可以用 Lua 灵活控制过期、更新,proxy_cache 是配置驱动,灵活性差
11. 为什么要在 Nginx 层做缓存?好处是什么?
精简版 :入口层拦截,减少后端压力,提升响应速度,扛高并发面试口语版:在 Nginx 层做缓存,相当于在系统入口加了一道防火墙:
- 直接拦截请求:大部分请求在 Nginx 层就返回,不用穿透到后端 Tomcat、Redis,极大减少服务压力
- 极致性能:Nginx 本身是高性能服务器,本地缓存响应速度极快
- 保护后端:即使后端服务挂了,Nginx 缓存还能兜底,保证系统可用
- 扛高并发:能承接远高于后端服务的并发量,适合秒杀、大促场景
12. Nginx 做缓存时,如何保证缓存一致性?
精简版 :主动过期、Canal 监听、版本号控制、定时刷新面试口语版:Nginx 缓存一致性的核心方案:
- 主动过期:数据更新时,主动调用接口删除 Nginx 对应缓存
- Canal 监听:监听 MySQL binlog,数据变更时自动清除 Nginx 缓存
- 版本号控制:给缓存加版本号,更新时版本号变更,缓存自动失效
- 短过期时间:给缓存设置较短的 TTL,即使不一致也能快速恢复
13. proxy_cache 缓存的是静态内容还是动态接口?
精简版 :都可以,默认适合静态,动态接口需要配置缓存键、过期时间面试口语版 :proxy_cache 不仅能缓存静态资源(图片、HTML、JS),也能缓存动态接口的响应。只要配置好缓存键(比如$request_uri)、过期时间、缓存条件,就能把动态接口的返回结果缓存起来,实现接口级别的加速,这也是多级缓存中 Nginx 层的核心用法。
四、Redis 多级缓存实战类
14. 标准多级缓存查询流程是什么?
精简版 :先查本地缓存 → 查 Nginx 缓存 → 查 Redis → 查 DB,逐层回写面试口语版:标准的查询流程是「从上到下,逐层回写」:
- 先查 JVM 本地缓存(Caffeine),命中直接返回
- 未命中,查 Nginx/OpenResty 本地缓存,命中返回,回写 JVM 缓存
- 未命中,查 Redis 分布式缓存,命中返回,回写 Nginx 和 JVM 缓存
- 未命中,查数据库,命中后回写 Redis、Nginx、JVM 缓存,最终返回这样每一层都能拦截请求,最大化性能。
15. 缓存穿透、击穿、雪崩在多级缓存架构下分别怎么解决?
精简版:
- 穿透:布隆过滤器、缓存空值
- 击穿:互斥锁、热点数据永不过期
- 雪崩:随机过期时间、多级缓存兜底、熔断降级面试口语版:
- 缓存穿透(查询不存在的数据,直接打 DB):用布隆过滤器拦截无效请求,或者给不存在的数据缓存空值,设置短过期时间
- 缓存击穿(热点 key 过期,大量请求打 DB):给热点数据设置永不过期,或者加互斥锁,只让一个请求去查 DB,其他等待
- 缓存雪崩(大量 key 同时过期,打 DB):给缓存设置随机过期时间,避免同时失效;多级缓存兜底,Redis 挂了用本地缓存扛;加熔断降级,保护 DB
16. 为什么要做缓存预热?怎么做?
精简版 :提前把热点数据加载到缓存,避免上线后大量请求打 DB;定时任务、Canal、启动时加载面试口语版:缓存预热就是在系统上线前,把热点数据提前加载到各级缓存里,避免上线瞬间大量请求穿透到数据库,把 DB 打挂。常见做法:
- 定时任务:凌晨低峰期,把热点数据全量加载到 Redis、本地缓存
- Canal 监听:监听 MySQL 数据变更,实时同步到缓存
- 启动加载:应用启动时,自动加载热点数据到本地缓存
- 手动触发:大促前手动执行预热脚本
17. Redis 作为二级缓存,如何设置过期时间?
精简版 :分层设置,热点数据长过期,普通数据短过期,加随机偏移量面试口语版:Redis 过期时间要结合业务分层设置:
- 热点数据:设置较长的过期时间(比如 24 小时),甚至永不过期,减少缓存失效
- 普通数据:设置中等过期时间(比如 1 小时)
- 冷数据:设置短过期时间(比如 5 分钟),节省内存
- 加随机偏移量:给过期时间加 ±10% 的随机值,避免大量 key 同时过期,引发雪崩
18. 为什么要在 Redis 前加一层本地缓存?直接用 Redis 不行吗?
精简版 :本地缓存零网络开销,性能更高,减少 Redis 压力,扛高并发面试口语版:直接用 Redis 不是不行,但加本地缓存是性能和架构的最优解:
- 性能差距大:本地缓存是内存操作,没有网络开销,读性能是 Redis 的几十倍
- 减少 Redis 压力:热点数据在本地缓存就拦截,不用每次都请求 Redis,降低 Redis 负载
- Redis 兜底:本地缓存只存热点,Redis 存全量,本地缓存失效了还有 Redis 兜底
- 抗高并发:多级缓存能承接更高的并发,比单 Redis 架构更稳
五、缓存一致性 & 同步(高频)
19. 多级缓存最大的问题是什么?
精简版 :数据一致性问题,多层缓存数据不同步面试口语版 :多级缓存最大的痛点就是数据一致性:每一层缓存都是独立的,数据更新后,需要同步更新所有层级的缓存,一旦某一层没更新,就会出现数据不一致,影响业务正确性。
20. 如何保证本地缓存 + Redis + 数据库三者一致?
精简版 :先更新 DB,再删缓存;Canal 监听 binlog 同步;MQ 通知失效面试口语版 :主流方案是「先更新数据库,再删除缓存」,配合 Canal 做兜底:
- 业务流程:更新数据库 → 删除 Redis 缓存 → 通知所有实例删除本地缓存
- 兜底方案:用 Canal 监听 MySQL binlog,数据变更时自动删除各级缓存,保证最终一致
- 补充:用 MQ 发送缓存失效通知,确保所有实例都能收到,删除本地缓存
- 最终一致性:允许短暂的不一致,通过兜底机制保证最终数据一致
21. 常见的缓存更新策略有哪些?
精简版 :Cache Aside(旁路缓存)、Write Through(写穿透)、Write Back(写回缓存)面试口语版:三种主流策略:
- Cache Aside(最常用):先更 DB,再删缓存,读时回写缓存,适合读多写少场景
- Write Through(写穿透):先更缓存,再更 DB,缓存和 DB 同步,适合写多场景
- Write Back(写回缓存):先更缓存,异步批量更 DB,性能最高,但一致性差,适合对一致性要求低的场景我们项目用的是 Cache Aside,配合 Canal 兜底,保证最终一致。
22. 为什么推荐「先更新数据库,再删除缓存」?
精简版 :避免缓存脏数据,一致性更高,容错性更好面试口语版:对比「先删缓存,再更 DB」,先更 DB 再删缓存的优势:
- 避免脏数据:如果先删缓存,DB 更新前有请求读缓存,会把旧数据回写缓存,造成脏数据;先更 DB 再删缓存,即使有并发,最多是短暂的旧数据,不会出现永久脏数据
- 容错性更好:如果删缓存失败,DB 已经更新,下次缓存失效会加载新数据,不会出现永久不一致
- 实现简单:逻辑清晰,适合大部分业务场景
23. 使用 Canal 监听 MySQL binlog 实现缓存同步的原理是什么?
精简版 :Canal 模拟 MySQL 从库,拉取 binlog,解析后触发缓存更新 / 删除面试口语版 :Canal 的核心原理是模拟 MySQL 从节点:
- Canal 向 MySQL 主库发送 dump 协议,请求拉取 binlog 日志
- MySQL 主库把 binlog 推送给 Canal,Canal 解析 binlog,提取数据变更(增删改)
- 当监听到数据变更时,Canal 触发对应的缓存操作:删除 Redis 缓存、清除 Nginx 缓存、通知应用删除本地缓存
- 实现数据库变更后,各级缓存自动同步,保证最终一致性,不用业务代码侵入
24. 分布式场景下,如何通知所有实例清除本地缓存?
精简版 :MQ 发布订阅、Redis 发布订阅、Canal 回调、配置中心面试口语版:常见方案:
- MQ 发布订阅:数据更新后,发送 MQ 消息,所有实例监听消息,收到后删除本地缓存
- Redis 发布订阅:用 Redis 的 pub/sub 功能,发布缓存失效通知,所有实例订阅后删除缓存
- Canal 回调:Canal 解析 binlog 后,调用所有实例的接口,通知删除缓存
- 配置中心:用 Nacos 等配置中心,发布配置变更,实例监听后删除缓存
六、架构设计 & 高并发场景
25. 商品详情页高并发,你怎么设计多级缓存?
精简版 :浏览器缓存 → Nginx/OpenResty 缓存 → Redis → Caffeine 本地缓存 → DB,配合 Canal 同步面试口语版:商品详情页是典型的读多写少场景,多级缓存设计如下:
- 客户端层:设置 HTTP 缓存头,让浏览器缓存静态资源,拦截重复请求
- 网关层 :OpenResty 做本地缓存,用
hash $request_uri做负载均衡,保证同一请求到同一 Tomcat,提升缓存命中率 - 分布式层:Redis 做全量商品缓存,设置合理过期时间,做缓存预热
- 应用层:Caffeine 做本地缓存,存热点商品,零网络开销加速
- 同步层:用 Canal 监听 MySQL binlog,商品数据变更时,自动清除各级缓存,保证一致性
- 兜底层:加熔断降级,缓存全失效时,用默认数据兜底,保护 DB
26. Nginx 负载均衡加 hash $request_uri 作用是什么?
精简版 :同一请求 URI 固定转发到同一 Tomcat,提升本地缓存命中率,减少 DB 压力面试口语版 :这个配置是基于 URI 的一致性哈希负载均衡 ,核心作用:让同一个请求 URI(比如/item/10001),永远转发到同一台 Tomcat 实例。这样 Tomcat 的本地缓存就能命中,不用每次都查 Redis、查 DB,极大提升缓存命中率,减少数据库压力,同时避免同一商品在不同 Tomcat 重复缓存,浪费内存。
27. 为什么要在 OpenResty 里直接查 Redis,而不是全部转发到后端?
精简版 :减少链路转发,提升性能,减少后端压力,扛高并发面试口语版:在 OpenResty 里直接查 Redis,相当于把缓存层提前到网关:
- 减少链路:不用转发到 Tomcat,再由 Tomcat 查 Redis,直接在网关层返回,链路更短,延迟更低
- 减少后端压力:大部分请求在网关层就返回,Tomcat 只处理缓存未命中的请求,极大减少服务压力
- 极致性能:OpenResty 的 Lua 操作 Redis 是非阻塞的,性能极高,能扛住更高并发
- 架构解耦:网关层统一处理缓存,后端服务不用关心缓存逻辑,专注业务
28. 大促、秒杀场景下,多级缓存如何防止数据库被打挂?
精简版 :多级缓存拦截、热点数据本地缓存、熔断降级、限流、缓存预热面试口语版:大促秒杀的核心是「层层拦截,保护 DB」:
- 多级缓存全链路拦截:Nginx、Redis、本地缓存三层拦截,99.9% 的请求在缓存层返回
- 热点数据本地缓存:把秒杀商品提前加载到所有实例的本地缓存,零网络开销,直接返回
- 缓存预热:大促前把所有商品数据全量预热到 Redis、Nginx 缓存
- 限流熔断:在网关层加限流,超过阈值直接拒绝,保护后端;加熔断,DB 压力大时自动降级
- 一致性哈希 :用
hash $request_uri保证同一请求到同一 Tomcat,提升缓存命中率 - 兜底降级:缓存全失效时,返回默认数据,不查 DB,保护数据库
29. 缓存热点 key 问题怎么解决?
精简版 :本地缓存、拆分 key、多级缓存、读写分离、限流面试口语版:热点 key 是指某个 key 的访问量极高,打垮 Redis,解决方案:
- 本地缓存兜底:把热点 key 提前加载到所有实例的本地缓存,不用每次请求 Redis
- 拆分 key:把一个热点 key 拆成多个子 key,分散压力
- 多级缓存拦截:Nginx 层缓存热点 key,直接在入口拦截
- Redis 读写分离:热点 key 的读请求走从库,写请求走主库
- 限流:对热点 key 的请求做限流,避免打垮 Redis
- 永不过期:给热点 key 设置永不过期,用 Canal 监听更新,避免缓存失效
七、坑点 & 生产问题类
30. 本地缓存 + Redis 会出现什么问题?
精简版 :数据不一致、内存溢出、缓存穿透、热点 key、缓存雪崩面试口语版 :核心问题是数据一致性,还有这些坑:
- 数据不一致:本地缓存和 Redis 数据不同步,出现脏数据
- 内存溢出:本地缓存存大对象,占满 JVM 内存,引发 OOM
- 缓存穿透:本地缓存和 Redis 都没命中,大量请求打 DB
- 热点 key:某个 key 访问量极高,打垮 Redis
- 缓存雪崩:大量本地缓存、Redis key 同时过期,请求全打 DB
- 缓存更新不及时:数据更新后,缓存没同步,出现脏数据
31. 缓存过期瞬间流量打到数据库怎么办?
精简版 :随机过期时间、互斥锁、热点数据永不过期、多级缓存兜底面试口语版:解决方案:
- 随机过期时间:给缓存过期时间加 ±10% 的随机值,避免大量 key 同时过期
- 互斥锁:缓存过期时,只让一个请求去查 DB,其他请求等待,避免并发打 DB
- 热点数据永不过期:给热点 key 设置永不过期,用 Canal 监听更新,避免缓存失效
- 多级缓存兜底:Redis 过期了,还有本地缓存兜底,不用直接打 DB
- 异步刷新:缓存快过期时,异步加载新数据,不阻塞主线程
32. Redis 挂了,多级缓存架构会怎样?如何兜底?
精简版 :本地缓存兜底,熔断降级,保护 DB;快速恢复 Redis面试口语版:Redis 挂了,多级缓存不会直接崩:
- 本地缓存兜底:所有请求走本地缓存,直接返回,不用查 Redis、查 DB
- 熔断降级:检测到 Redis 不可用,自动熔断,不再请求 Redis,直接走本地缓存
- 保护数据库:本地缓存拦截所有请求,DB 不会被打挂
- 快速恢复:Redis 恢复后,异步回写缓存,恢复正常流程
- 监控告警:Redis 挂了立即告警,快速排查恢复
33. Nginx 缓存失效,流量直接冲到 Tomcat 怎么办?
精简版 :Redis 兜底、限流、互斥锁、本地缓存、预热面试口语版:解决方案:
- Redis 兜底:Nginx 缓存失效了,请求到 Tomcat,先查 Redis,Redis 命中直接返回
- 本地缓存兜底:Tomcat 的本地缓存拦截请求,不用查 Redis、查 DB
- 限流:在 Nginx 层加限流,缓存失效时限制流量,避免冲垮 Tomcat
- 互斥锁:缓存失效时,只让一个请求去查 DB,其他等待,避免并发
- 缓存预热:提前把热点数据加载到 Nginx 缓存,避免集中失效
34. 为什么不建议在本地缓存存大对象?
精简版 :占用 JVM 内存,引发 OOM,GC 压力大,性能下降面试口语版:核心原因:
- 内存占用高:大对象会占满 JVM 堆内存,引发 OOM,导致应用崩溃
- GC 压力大:大对象会触发 Full GC,导致应用停顿,性能下降
- 缓存效率低:本地缓存适合存小体积、高频访问的热点数据,大对象缓存利用率低
- 内存浪费:大对象缓存会挤占其他缓存的内存空间,导致其他缓存被淘汰所以本地缓存只存小体积的热点数据,大对象存在 Redis 里。
八、结合你课程的专属面试题(最容易被问)
35. 你们项目里多级缓存结构是怎样的?
精简版 :浏览器缓存 → OpenResty 本地缓存 → Redis 分布式缓存 → Caffeine JVM 本地缓存 → MySQL,Canal 做缓存同步面试口语版:我们项目的多级缓存是标准的四层架构:
- 客户端层:浏览器缓存,拦截重复请求
- 网关层 :OpenResty 做本地缓存,同时用
hash $request_uri做 Tomcat 集群负载均衡,提升缓存命中率 - 分布式层:Redis 做全局共享缓存,做全量数据兜底,做缓存预热
- 应用层:Caffeine 做 JVM 本地缓存,存热点商品数据,零网络开销加速
- 同步层:用 Canal 监听 MySQL binlog,数据变更时自动清除各级缓存,保证最终一致性
- 兜底层:加熔断限流,保护数据库不被打挂
36. 为什么用 OpenResty 而不是普通 Nginx?
精简版 :OpenResty 支持 Lua 脚本,可编程,能直接操作 Redis、做缓存、封装 HTTP 请求,灵活性更高面试口语版 :用 OpenResty 而不是普通 Nginx,核心是可编程能力:
- Lua 脚本扩展:可以用 Lua 直接操作 Redis、封装 HTTP 请求、处理请求参数,不用转发到后端
- 灵活做缓存:可以用 Lua 实现自定义缓存逻辑,比普通 Nginx 的 proxy_cache 更灵活
- 网关能力:可以在 OpenResty 里做认证、限流、路由,实现 API 网关能力
- 性能一致:基于 Nginx 核心,性能和普通 Nginx 一样,同时多了动态逻辑能力我们项目里用 OpenResty 直接查 Redis,做缓存拦截,不用转发到 Tomcat,极大提升了性能。
37. red:set_timeouts(1000,1000,1000) 三个参数分别代表什么?
精简版 :连接超时、发送超时、读取超时,单位毫秒面试口语版 :这是 OpenResty 的lua-resty-redis库的方法,三个参数都是毫秒:
- 第一个 1000:连接超时,建立 TCP 连接到 Redis 的最大等待时间,1 秒连不上就失败
- 第二个 1000:发送超时,向 Redis 发送命令的最大等待时间,1 秒发不出就失败
- 第三个 1000:读取超时,等待 Redis 返回响应的最大等待时间,1 秒收不到就失败核心作用是防止 Redis 操作阻塞 Nginx worker 进程,避免服务雪崩。
38. Nginx 负载均衡加 hash $request_uri 作用是什么?
(同第 26 题,精简版)精简版 :同一请求 URI 固定转发到同一 Tomcat,提升本地缓存命中率,减少 DB 压力面试口语版 :这个配置是基于 URI 的一致性哈希负载均衡,让同一个请求(比如/item/10001)永远转发到同一台 Tomcat。这样 Tomcat 的本地缓存就能命中,不用每次都查 Redis、查 DB,极大提升缓存命中率,减少数据库压力,同时避免同一商品在不同 Tomcat 重复缓存,浪费内存。
39. Canal 在你们多级缓存里做什么?
精简版 :监听 MySQL binlog,数据变更时自动清除各级缓存,保证缓存一致性面试口语版 :Canal 在我们的多级缓存里是缓存同步的核心兜底组件:
- 模拟 MySQL 从库,拉取并解析 MySQL 的 binlog 日志
- 当监听到商品数据等业务数据变更时,自动触发缓存操作:删除 Redis 缓存、清除 OpenResty 缓存、通知应用删除本地缓存
- 实现数据库变更后,各级缓存自动同步,保证最终一致性,不用业务代码侵入,避免手动删缓存的遗漏
40. 如何保证 JVM 本地缓存与 Redis 同步?
精简版 :先更 DB 再删缓存、Canal 监听、MQ 通知、定时刷新面试口语版:保证本地缓存和 Redis 同步的方案:
- 业务流程:更新数据库 → 删除 Redis 缓存 → 发送 MQ 通知所有实例删除本地缓存
- Canal 兜底:监听 MySQL binlog,数据变更时自动删除 Redis 和本地缓存,避免业务代码遗漏
- 定时刷新:给本地缓存设置较短的过期时间,定时自动刷新,保证最终一致
- 版本号控制:给缓存加版本号,更新时版本号变更,缓存自动失效
- 最终一致性:允许短暂的不一致,通过兜底机制保证最终数据一致
补充:面试加分项(主动说)
如果面试官问完,你可以主动补充:
我们这套多级缓存架构,核心是「分层拦截、极致性能、最终一致」,用 OpenResty 做网关缓存,Caffeine 做本地热点缓存,Redis 做全局兜底,Canal 做缓存同步,既扛住了高并发,又保证了数据一致性,同时保护了数据库,适合商品详情这类读多写少的高并发场景。