把 AI 装进"记忆宫殿":MemPalace 功能拆解与上手实战
tags:
- MemPalace
- AI记忆
- MCP
- RAG
- Claude
- ChatGPT
- 知识管理
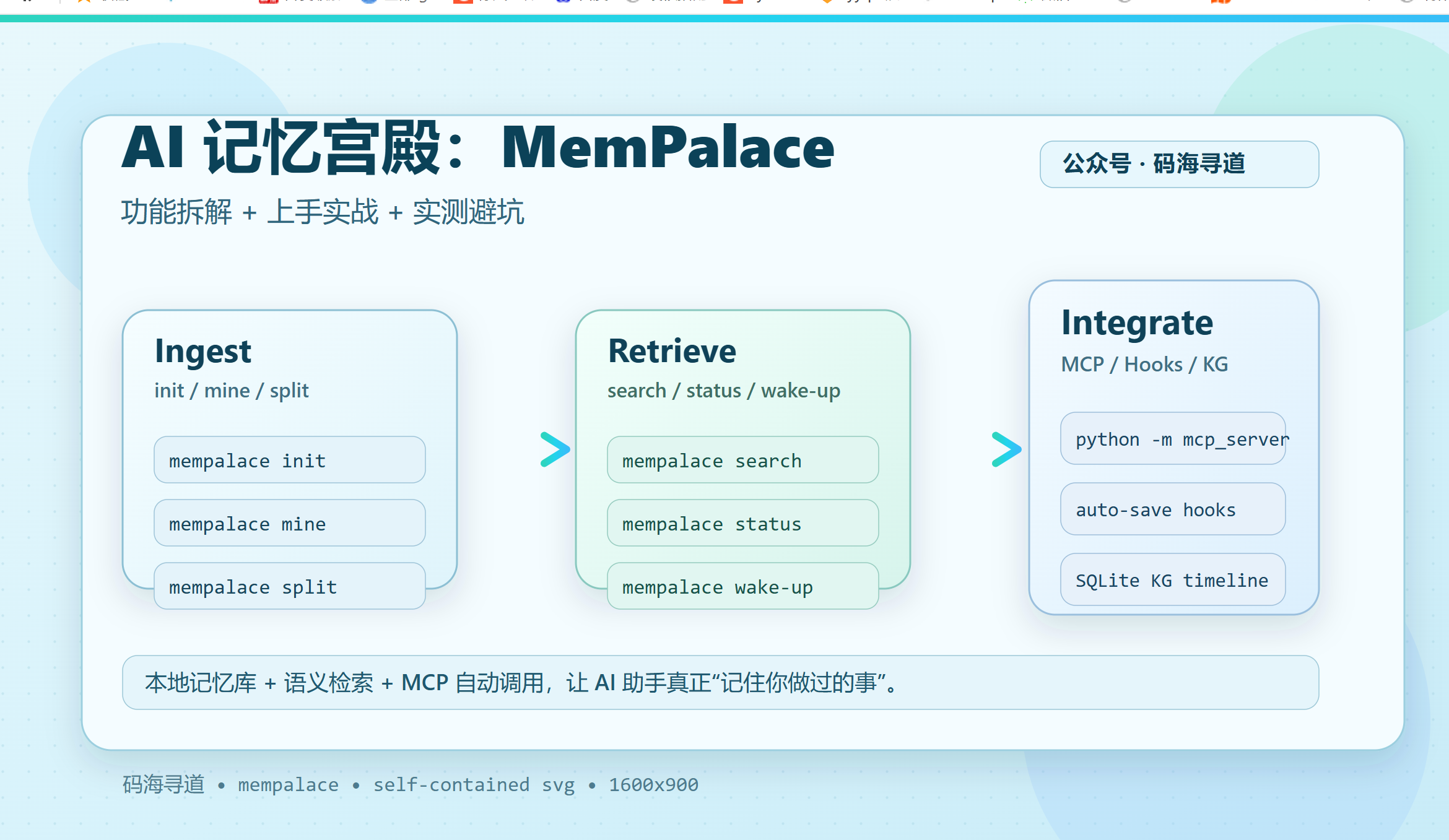
本文面向"已经在用 AI 助手写代码/做方案"的开发者,重点讲清
MemPalace到底解决什么问题、有哪些功能、如何从 0 到 1 安装使用。文中包含我在 Windows 环境(Python 3.13)上的实测结论(日期:2026-04-09)。
如果你已经把 AI 当成日常搭档,你大概率遇到过这个场景:
今天聊完的架构决策,下周就找不到;上个月讨论过的技术取舍,新会话还得重讲一遍。
我们缺的往往不是模型能力,而是一个能沉淀上下文的"长期记忆层"。
当我们每天都在和 Claude、ChatGPT、Cursor、Copilot 长对话时,会出现一个共同痛点:
- 关键决策散落在聊天窗口里
- 过两周就找不到"当时为什么这么做"
- 新会话里要反复喂背景,成本高且容易失真
MemPalace 就是为这件事设计的。
它不是新模型,也不是聊天 UI。
它更像一个给 AI 助手加上的"本地长期记忆层":
- 把项目文件和历史对话挖进本地记忆库
- 需要时做语义检索,把原始证据找回来
- 通过 MCP 让 AI 工具自动调用记忆,而不是手工查
一句话定位:
MemPalace = 本地可检索、可追溯、可自动调用的 AI 记忆基础设施。
一、这个项目能做什么
先从能力全景看,MemPalace 主要有 7 类功能。
1) 项目记忆挖掘(projects 模式)
把代码、文档、笔记、SOP 等文件挖进记忆库:
bash
mempalace init ~/projects/myapp
mempalace mine ~/projects/myapp这样以后你查"为什么换数据库""某个接口当时怎么定的",可以直接检索原文,而不是只看二手摘要。
2) 对话记忆挖掘(convos 模式)
支持把聊天导出文件(Claude / ChatGPT / Slack 等)挖进同一套记忆库:
bash
mempalace mine ~/chats/ --mode convos如果你的导出文件是"多会话拼在一个大文件",先用:
bash
mempalace split ~/chats/再挖掘,效果更稳。
3) 语义检索(search)
这是日常最常用能力:
bash
mempalace search "why did we switch to GraphQL"它会给出相关片段、来源文件和匹配分数。
可以按项目(wing)或主题房间(room)过滤。
4) 会话唤醒上下文(wake-up)
wake-up 用来生成"开场记忆上下文",适合新会话启动时给 AI 做背景注入:
bash
mempalace wake-up
mempalace wake-up --wing myapp本质上是把关键事实层(L0/L1)先送进上下文,让助手上来就"知道你是谁、项目在哪、最近做了什么"。
5) 压缩层(compress / AAAK)
项目提供了 AAAK 压缩层(实验性):
bash
mempalace compress --wing myapp但这块要注意:截至 2026-04-09,README 已明确说明 AAAK 仍在迭代,当前评测里相对 raw 模式有回归。
实战建议是先把 raw 检索链路跑稳,再考虑 AAAK。
6) MCP Server(19 个工具)
这是 MemPalace 真正"无感使用"的关键。
接上 MCP 后,Claude/ChatGPT/Cursor/Gemini 可以直接调它的工具能力,例如:
mempalace_searchmempalace_statusmempalace_kg_querymempalace_kg_timeline
你问"上个月 auth 方案怎么定的",AI 可以自动检索记忆再回答,而不是你先手动查。
7) 知识图谱与时间线能力
仓库里有本地 SQLite 的事实关系层(knowledge graph),可做:
- 关系查询
- 事实增删改
- 时间线回放
适合"人-项目-决策-时间"这类关系追踪场景。
二、怎么理解它的内部结构
MemPalace 用了一个很形象的结构命名:
Wing:项目维度(例如某个 repo)Room:主题维度(例如 auth、docs、ops)Drawer:具体记忆条目(文本片段 + 来源)
你可以把它理解成:
- Wing = 哪个项目
- Room = 项目里的哪个主题
- Drawer = 这个主题下的一条可检索证据
好处是检索时可以先收窄范围,再做语义匹配,噪声更低。
三、从 0 到 1 上手(可复现流程)
下面是一套稳妥的上手路径。
1) 安装
推荐先用虚拟环境:
bash
python -m venv .venv
.venv\Scripts\activate
pip install mempalace如果你希望对齐仓库 main 分支最新代码(而不是 PyPI 发布版),可用源码安装。
2) 初始化项目
bash
mempalace init <项目目录>会生成 mempalace.yaml,定义项目对应的 wing/rooms。
3) 挖掘记忆
项目文件挖掘:
bash
mempalace mine <项目目录>对话挖掘:
bash
mempalace mine <对话目录> --mode convos4) 检索与状态检查
bash
mempalace search "数据库迁移原因"
mempalace status
mempalace wake-up这一步通过,基本就完成"可用闭环"了。
5) 接 MCP(让 AI 自动调记忆)
手工接入示例:
bash
claude mcp add mempalace -- python -m mempalace.mcp_server接好以后,很多场景不再需要你手打 mempalace search,而是让 AI 自动调用工具。
四、我在 Windows 上的实测结论(很重要)
环境:Windows + Python 3.13(测试日期 2026-04-09)
我已经在本机跑通 init -> mine -> search -> status -> wake-up,结论是"可用",但有 3 个坑要提前知道。
坑 1:init --yes 在当前版本里可能仍触发交互
CLI 帮助里有 --yes,但实测仍可能进入 input()。
如果你在非交互环境执行,会出现 EOFError。
实操建议:先在交互终端执行初始化;或者在自动化里做输入兜底。
坑 2:Windows 默认编码导致 mine 报错
实测遇到:
UnicodeEncodeError: 'gbk' codec can't encode character '\u2713'
原因是 CLI 输出里的 ✓ 字符与默认编码冲突。
修复方式是在命令前设 UTF-8:
powershell
$env:PYTHONIOENCODING='utf-8'
mempalace mine <项目目录>坑 3:版本号显示可能不一致
我本机看到:
pip show mempalace显示3.0.0mempalace.__version__显示2.0.0
另外,GitHub main 的 pyproject.toml 版本已是 3.0.14。
这意味着"PyPI 发布版"和主分支可能存在节奏差异。
如果你要稳定复现,用 PyPI 版;
如果你要追新功能,建议源码安装并锁定 commit。
五、适合谁用,不适合谁用
适合:
- 高频使用 AI 助手做工程决策的团队
- 需要追溯"当时为什么这么做"的项目
- 希望本地化、可控、低成本记忆层
不太适合:
- 几乎不依赖历史上下文的短平快问答
- 完全不愿维护本地记忆库和数据治理的人
- 期望"零配置、零维护、绝对准确"的用户
六、你可以直接照抄的最小命令集
bash
# 1) 安装
pip install mempalace
# 2) 初始化
mempalace init ~/projects/myapp
# 3) 挖掘(项目)
mempalace mine ~/projects/myapp
# 4) 检索
mempalace search "why did we switch to PostgreSQL"
# 5) 查看状态
mempalace status
# 6) 会话唤醒
mempalace wake-up --wing myapp如果你主要处理聊天导出:
bash
mempalace split ~/chats/
mempalace mine ~/chats/ --mode convos结语
MemPalace 的价值不在于"又一个 AI 工具",而在于它把过去最容易丢失的资产补上了:
- 决策过程
- 失败经验
- 讨论上下文
这些内容以前很难系统化保存,现在可以被本地挖掘、检索、回放,并通过 MCP 进入 AI 助手的日常工作流。
如果你已经每天和 AI 深度协作,MemPalace 值得至少跑一次最小闭环。
这里是 码海寻道。
如果你准备在自己的工作流里尝试 MemPalace,欢迎留言聊聊你现在的阶段:
- 只想先做个人记忆库(本地检索为主)
- 想接入 Claude/Cursor 做 MCP 自动调用
- 想在团队里做统一记忆治理(权限、隔离、审计)