三种典型的词向量学习方法的梳理与比较:
一、基于统计的词频向量(如 TF-IDF)
-
基本原理
基于词在文档中的出现频率(TF)与在整个语料库中的逆文档频率(IDF)的乘积,构建文档-词矩阵,矩阵的行或列作为向量表示。
-
训练目标函数
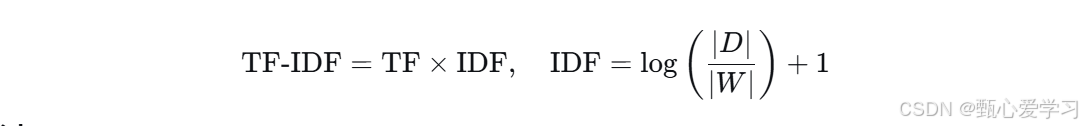

-
优点
- 简单、可解释性强
- 能有效评估词在文档中的重要性
- 适合文档级别任务
-
缺点
- 向量维度随文档数或词表大小增长,稀疏且高维
- 无法捕捉词之间的语义相似性
- 不适合捕捉上下文语义关系
-
适用场景
- 文本分类、信息检索、关键词提取等传统NLP任务
二、基于神经网络的预测模型(如 Word2Vec)
基本原理
- CBOW:用上下文词预测中心词
- Skip-gram:用中心词预测上下文词
- 训练一个浅层神经网络,隐层输出作为词向量
训练目标函数(CBOW示例)
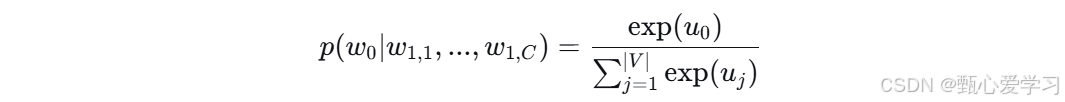
优点
- 生成低维、稠密的词向量
- 能捕捉语义和句法关系(如"国王-王后"="男人-女人")
- 训练效率高(尤其Skip-gram + 负采样)
缺点
- 只利用局部上下文,忽略全局共现统计
- 对低频词表现不佳
- 对多义词处理有限
适用场景
- 词类比、词相似度计算
- 下游任务的特征初始化(如情感分析、命名实体识别)
三、基于全局矩阵分解的词向量(如 GloVe)
-
基本原理
结合全局共现矩阵(词-词共现统计)与局部上下文窗口方法,通过最小化共现概率比的误差来训练词向量。
-
训练目标函数 (简化形式)
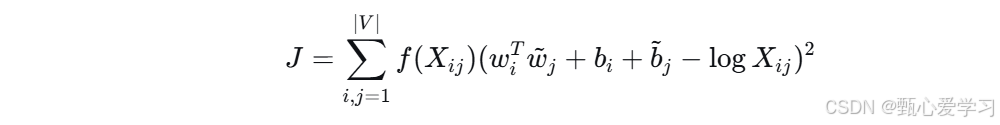
-
优点
- 同时利用全局统计信息与局部上下文
- 训练快,适合大规模语料
- 在词类比、相似度任务上表现优异
-
缺点
- 对所有共现词对同等建模,计算量仍较大
- 对高频无意义词(如"的")不够鲁棒
-
适用场景
- 需要高质量、通用词向量的任务
- 文本语义分析、词聚类、词汇语义演变分析
| 方法 | 基本原理 | 目标函数 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|---|
| TF-IDF | 词频 × 逆文档频率 | TF × IDF | 简单、可解释、适合文档级任务 | 稀疏、高维、无语义信息 | 文本分类、检索 |
| Word2Vec | 神经网络预测上下文 | Softmax 或负采样 | 低维、稠密、语义信息丰富 | 忽略全局统计、低频词差 | 词相似度、特征初始化 |
| GloVe | 全局共现矩阵分解 | 加权最小二乘 | 融合全局+局部、训练快 | 对高频噪音敏感 | 通用词向量、语义分析 |
知识点梳理
一、基础概念层
1. 语言单位
- 语素:最小的音义结合体,不可再分
- 词:可独立运用的最小语言单位
- 字:书写单位,记录语素或词
2. 词的意义属性
- 概念定义:基本内涵
- 联想定义:由基本义引申
- 社会性:受社会、时代、阶层等影响(如核心价值观)
- 色彩意义:情感、风格等附加义(如"暴君"带恐惧、厌恶)
二、词向量化的动机与基本表示
1. 动机
- 将符号空间映射到数值空间
- 保留语义和句法特征
2. 早期方法:基于词汇表的向量
独热编码(One-Hot)
- 维度 = 词表大小
- 每个词只有一个维度为1,其余为0
- 缺点:高维、稀疏、无语义相似度
词频向量(文档-词矩阵)
- 构建语料库的"文档-词"频率矩阵
- 列向量为词的向量,行向量为文档向量
- 缺点:维度随文档数或词数增长,稀疏
TF-IDF
- 公式:TF-IDF = TF × IDF
- IDF = log(|D| / |W|) + 1
- 特点:评估词在文档中的重要性,具有特异性
- 用途:比较词或文档的相似度
三、分布式表示(核心)
定义
- 将词汇信息分布存储到向量的各个维度中
- 低维、稠密、易于获取句法和语义信息
分类
- 基于矩阵分解的分布式表示
- 基于聚类的分布式表示
- 基于神经网络的分布式表示
四、基于矩阵分解的分布式表示
1. 共现矩阵
- 基于滑动窗口统计词与词在同一窗口内的共现次数
- 行和列均为词,元素为共现次数
- 缺点:稀疏、高维
2. 奇异值分解(SVD)
- A = UΣVᵀ
- 左奇异矩阵U的每行:词的k维稠密向量
- 右奇异矩阵V的每列:文档的k维向量
- 优点:降维、去噪、保留主要信息
五、基于神经网络的分布式表示:Word2Vec
核心思想
- 出现在相似上下文中的词,语义相似
- 低维稠密向量(通常200维左右)
两种模型
| 模型 | 输入 | 输出 | 适用场景 |
|---|---|---|---|
| CBOW | 上下文词 | 中心词 | 较大词表 |
| Skip-gram | 中心词 | 上下文词 | 较小语料、低频词效果好 |
训练流程(以CBOW为例)
- 对上下文词做独热编码
- 乘以输入矩阵W,得到嵌入向量
- 求和平均得到隐向量h
- 乘以输出矩阵W',得到每个词的得分u
- Softmax得到概率分布,预测中心词
- 计算交叉熵损失,反向传播更新W和W'
六、模型优化方法
问题
- Softmax计算量大,需在整个词表上归一化
解决方案
1. 层次化Softmax(Hierarchical Softmax)
- 使用哈夫曼树代替扁平神经网络
- 叶节点:词
- 内部节点:隐藏层神经元
- 计算路径概率乘积,复杂度降为O(log|V|)
2. 负采样(Negative Sampling)
- 保留正样本(真实中心词与上下文)
- 从噪声分布中采样k个负样本
- 训练目标:最大化正样本的sigmoid概率,最小化负样本的
- 噪声分布常用unigram的3/4次幂,以增加低频词采样概率
- k值:小数据集520,大数据集25
七、GloVe:全局向量
定位
- 结合全局矩阵分解 (如LSA)与局部上下文窗口(如Word2Vec)的优点
对比表(来自图片)
| 类型 | 代表方法 | 优点 | 缺点 |
|---|---|---|---|
| 全局矩阵分解 | LSA, HAL | 利用全局统计信息;训练快 | 高频词信息量低;缺少句子结构 |
| 局部上下文窗口 | Skip-gram, CBOW | 表现优异;可捕捉复杂模式(语义线性子结构、句法成分) | 全局统计信息利用效率低 |
GloVe目标函数(简化)
- 基于共现概率比,最小化加权平方误差
八、整体关系图
语言单位: 语素/词/字
词的意义: 社会性/色彩
词向量化动机
独热编码
词频向量/TF-IDF
分布式表示
基于矩阵分解: 共现矩阵 + SVD
基于神经网络: Word2Vec
GloVe: 融合全局+局部
CBOW
Skip-gram
优化: 层次化Softmax / 负采样
对比LSA与Skip-gram
捕获语义线性子结构
九、总结:知识点关系主线
- 从语言基础(语素、词、字)出发,理解词的意义属性。
- 为什么需要词向量:符号空间到数值空间,保留语义。
- 早期简单方法:独热、词频、TF-IDF(高维稀疏,语义弱)。
- 分布式表示思想:低维稠密,上下文决定语义。
- 实现路径一:矩阵分解(共现矩阵 + SVD)。
- 实现路径二:神经网络(Word2Vec的CBOW/Skip-gram + 优化)。
- 融合路径:GloVe,结合全局统计与局部预测的优点。