声明:本文非广告!
文章目录
-
- 一、引言:时序数据爆发,选型成为关键命题
- 二、时序数据库选型的核心评估维度
-
- [2.1 数据模型与场景适配度](#2.1 数据模型与场景适配度)
- [2.2 写入性能与扩展能力](#2.2 写入性能与扩展能力)
- [2.3 存储压缩效率](#2.3 存储压缩效率)
- [2.4 查询能力与生态集成](#2.4 查询能力与生态集成)
- [2.5 端边云协同架构](#2.5 端边云协同架构)
- [2.6 开源生态与社区活跃度](#2.6 开源生态与社区活跃度)
- 三、国际主流时序数据库方案对比
-
- [3.1 InfluxDB:IT 运维监控领域的先行者](#3.1 InfluxDB:IT 运维监控领域的先行者)
- [3.2 TimescaleDB:关系型数据库的时序扩展](#3.2 TimescaleDB:关系型数据库的时序扩展)
- [3.3 对比总结](#3.3 对比总结)
- [四、Apache IoTDB:为工业时序数据而生的最优解](#四、Apache IoTDB:为工业时序数据而生的最优解)
-
- [4.1 自研 TsFile 存储格式:极致压缩的底层支撑](#4.1 自研 TsFile 存储格式:极致压缩的底层支撑)
- [4.2 树形层级数据模型:天然适配工业场景](#4.2 树形层级数据模型:天然适配工业场景)
- [4.3 百万级设备接入与线性扩展](#4.3 百万级设备接入与线性扩展)
- [4.4 端边云协同:一体化架构的独特优势](#4.4 端边云协同:一体化架构的独特优势)
- [4.5 深度集成大数据生态](#4.5 深度集成大数据生态)
- [4.6 Apache 顶级项目:开源治理的保障](#4.6 Apache 顶级项目:开源治理的保障)
- 五、选型建议:什么场景该选什么数据库
- 六、结语
一、引言:时序数据爆发,选型成为关键命题
随着工业物联网、车联网、智慧能源等领域的快速发展,全球时序数据正以每年超过 30% 的速度增长。据 IDC 预测,到 2025 年全球数据总量将突破 175ZB,其中超过 30% 为时序数据。面对海量、高频、多源的时序数据,传统关系型数据库在写入吞吐、存储压缩和时序查询方面已力不从心,时序数据库(Time Series Database, TSDB)应运而生并迅速成为大数据基础设施的核心组件。
然而,时序数据库市场产品众多,从开源到商业、从轻量级到分布式,选型成为企业大数据架构设计中最关键的决策之一。选型不当,轻则存储成本飙升、查询效率低下,重则系统架构推倒重来。本文将从大数据架构视角出发,对比国际主流时序数据库方案,深入解析 Apache IoTDB 的技术优势,为企业选型提供系统性参考。
二、时序数据库选型的核心评估维度
在进行时序数据库选型时,企业应从以下六个核心维度进行系统评估:
2.1 数据模型与场景适配度
时序数据库的数据模型直接决定了其对业务场景的适配能力。国际主流产品中,InfluxDB 采用 Tag-Value 模型,灵活但缺乏层级结构;TimescaleDB 基于 PostgreSQL 扩展,沿用关系模型,对时序场景并非原生优化。而工业物联网场景天然具有"设备-测点"的层级关系,树形数据模型更贴合实际业务需求。
2.2 写入性能与扩展能力
工业场景中,数百万设备同时上报数据,写入吞吐要求极高。单节点百万点/秒的写入能力已成为工业级时序数据库的基本门槛,而集群模式下的线性扩展能力则决定了系统能否应对业务增长。
2.3 存储压缩效率
时序数据量级庞大,存储成本往往是企业最大的运维支出之一。压缩比从 3:1 到 20:1 的差异,意味着同等数据量下存储成本可能相差数倍。高效的压缩算法不仅降低存储成本,还能减少 I/O 开销,提升查询性能。
2.4 查询能力与生态集成
时序数据的查询需求涵盖实时聚合、趋势分析、异常检测等多种模式。SQL 兼容性、窗口函数支持、与大数据生态(Spark、Flink、Hive)的集成能力,都是选型时需要重点考量的因素。
2.5 端边云协同架构
在工业物联网场景中,数据往往在边缘侧产生,需要在边缘节点进行预处理和缓存,再同步到云端进行集中分析。端边云一体化的架构设计,能够大幅降低数据传输成本和系统复杂度。
2.6 开源生态与社区活跃度
开源产品的社区活跃度直接影响问题响应速度、功能迭代节奏和长期技术保障。Apache 基金会顶级项目的背书,意味着更规范的开源治理和更可持续的发展路径。
三、国际主流时序数据库方案对比
3.1 InfluxDB:IT 运维监控领域的先行者
InfluxDB 是国际上最知名的时序数据库之一,在 IT 运维监控和 DevOps 领域拥有广泛的用户基础。其核心特点包括:
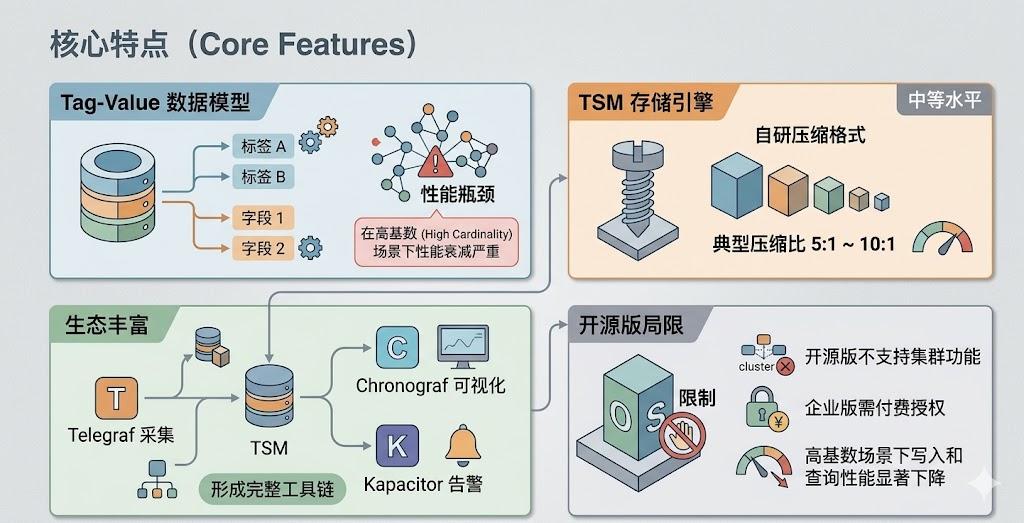
- Tag-Value 数据模型:通过标签(Tag)和字段(Field)组织数据,查询灵活,但在高基数(High Cardinality)场景下性能衰减严重
- TSM 存储引擎:自研压缩格式,典型压缩比 5:1 ~ 10:1,中等水平
- 生态丰富:Telegraf 采集、Chronograf 可视化、Kapacitor 告警,形成完整工具链
- 开源版局限:开源版不支持集群功能,企业版需付费授权;高基数场景下写入和查询性能显著下降
InfluxDB 适合中小规模的 IT 监控场景,但在工业物联网的海量设备接入、层级化数据管理和端边云协同方面存在明显短板。
3.2 TimescaleDB:关系型数据库的时序扩展
TimescaleDB 基于 PostgreSQL 扩展构建,最大的优势在于完整 SQL 支持和与关系型数据库生态的无缝集成:
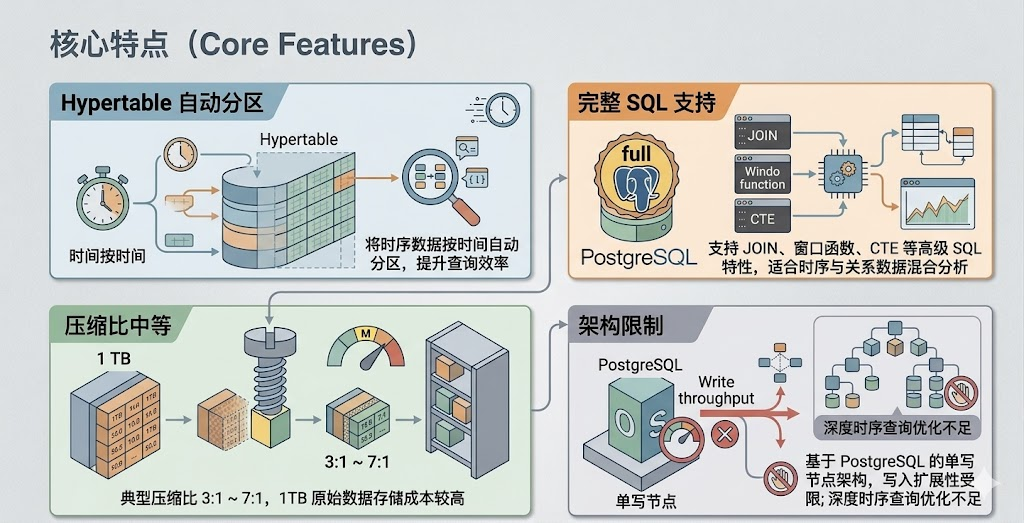
- Hypertable 自动分区:将时序数据按时间自动分区,提升查询效率
- 完整 SQL 支持:支持 JOIN、窗口函数、CTE 等高级 SQL 特性,适合时序与关系数据混合分析
- 压缩比中等:典型压缩比 3:1 ~ 7:1,1TB 原始数据存储成本较高
- 架构限制:基于 PostgreSQL 的单写节点架构,写入扩展性受限;深度时序查询优化不足
TimescaleDB 适合需要时序数据与业务数据联合查询的场景,但在纯时序数据的高吞吐写入和极致压缩方面并非最优解。
3.3 对比总结
| 评估维度 | Apache IoTDB | InfluxDB | TimescaleDB |
|---|---|---|---|
| 数据模型 | 树形层级(设备-测点) | Tag-Value | 关系型扩展 |
| 存储格式 | TsFile(自研列式) | TSM | PostgreSQL + 列式扩展 |
| 典型压缩比 | 10:1 ~ 20:1 | 5:1 ~ 10:1 | 3:1 ~ 7:1 |
| 单节点写入 | 百万点/秒 | 十万~百万点/秒 | 十万级点/秒 |
| 集群能力 | 开源支持分布式 | 开源版不支持 | 依赖 PG 扩展 |
| 端边云协同 | 原生支持 | 不支持 | 不支持 |
| SQL 兼容 | 支持 | InfluxQL/Flux | 完整 SQL |
| 大数据生态 | Spark/Flink/Hive | 有限 | PG 生态 |
对应代码示例(便于技术选型参考):
yaml
# InfluxDB 数据模型配置示例
# 采用 Tag-Value 扁平化结构,高基数场景性能衰减
measurement: "cpu_metrics"
tags:
host: "server-01"
region: "us-east"
datacenter: "dc-1"
fields:
usage: 75.4
idle: 24.6
# TimescaleDB 数据模型配置示例
# 基于 PostgreSQL 表结构,需手动创建 Hypertable
CREATE TABLE sensor_data (
time TIMESTAMPTZ NOT NULL,
device_id TEXT NOT NULL,
temperature DOUBLE PRECISION,
humidity DOUBLE PRECISION
);
SELECT create_hypertable('sensor_data', 'time');
sql
-- IoTDB 数据模型配置示例
-- 树形层级结构,天然适配工业设备层级
CREATE TIMESERIES root.factory1.line1.device1.temperature
WITH DATATYPE=DOUBLE, ENCODING=GORILLA, COMPRESSOR=ZSTD;
-- 批量写入示例
INSERT INTO root.factory1.line1.device1(timestamp, temperature)
VALUES (1720000000000, 25.6), (1720000001000, 25.8);
-- 层级查询示例(支持目录浏览)
SHOW TIMESERIES root.factory1.line1.*;
SELECT * FROM root.factory1.line1.device1 WHERE time > 1720000000000;四、Apache IoTDB:为工业时序数据而生的最优解
此时点击对应官网我们可以看到:

4.1 自研 TsFile 存储格式:极致压缩的底层支撑
IoTDB 从零自研了 TsFile 列式存储格式,专门针对时序数据特征进行深度优化。TsFile 集成了二阶差分编码、Gorilla 浮点压缩、ZSTD 通用压缩等多重算法,实现平均 12:1 的压缩比,时间戳压缩比更可达 20:1。这意味着 1TB 原始数据仅需约 67GB 存储空间,存储成本仅为通用数据库的 10%~20%。
相比之下,InfluxDB 的 TSM 压缩和 TimescaleDB 的 PostgreSQL 压缩在工业时序数据场景下的压缩效率明显不足,尤其是对浮点数和周期性时间戳的压缩效果差距更为显著。
4.2 树形层级数据模型:天然适配工业场景
IoTDB 采用"设备-测点"的树形数据模型,与工业场景中的设备层级关系天然对应。例如,root.factory.line1.device1.temperature 直观反映了工厂-产线-设备-测点的层级结构,支持目录浏览和模糊查询,大幅降低了数据管理的复杂度。
而 InfluxDB 的 Tag-Value 模型虽然灵活,但在表达层级关系时需要通过多个 Tag 组合实现,查询复杂且性能在高基数场景下急剧下降。TimescaleDB 的关系模型则需要通过表关联来模拟层级,增加了查询复杂度和运维成本。
4.3 百万级设备接入与线性扩展
IoTDB 单节点即可实现百万点/秒的写入吞吐,集群模式下支持线性扩展。2025 年 IoTDB 在 TPCx-IoT 测试中刷新世界纪录,性能较前纪录提升 60%,充分验证了其在海量设备场景下的处理能力。
在实际生产案例中,长安汽车基于 IoTDB 构建的车联网平台已接入约 57 万辆车辆设备,测点数约 8000 万,托管时间序列约 1.5 亿,写入量级达 150 万条/秒;国家电网的物联管理平台实现了千万级设备并发和千万点/秒的实时写入能力。
4.4 端边云协同:一体化架构的独特优势
IoTDB 是目前唯一原生支持端边云协同架构的开源时序数据库。边缘端以轻量化 TsFile 存储实现数据本地缓存和预处理,云端通过 IoTDB 集群进行集中管理和分析,边缘与云端之间支持数据自动同步。这种架构在博世力士乐的 ctrlX AUTOMATION 平台上得到了验证,实现了工业生产中计算资源受限下的海量数据处理和边缘侧与中心侧的数据同步。
InfluxDB 和 TimescaleDB 均不支持端边云协同,企业在构建边缘计算架构时需要额外引入数据同步中间件,增加了系统复杂度和故障风险。
4.5 深度集成大数据生态
IoTDB 与 Spark、Flink、Hive 等大数据组件深度集成,支持通过 Spark 读取 TsFile 进行批量分析,通过 Flink 实现流式计算,通过 Hive 进行离线查询。这种深度集成使得 IoTDB 能够无缝融入企业现有的大数据技术栈,实现"一套数据、多种计算"的架构目标。
下面可以进行下载并测试:
java
// IoTDB 与 Spark 集成示例:读取 TsFile 进行批量分析
import org.apache.iotdb.spark.tool.TimestampType;
import org.apache.iotdb.spark.tsfile.qp.exception.QueryProcessorException;
import java.io.IOException;
public class TsFileReadExample {
public static void main(String[] args) throws IOException, QueryProcessorException {
TsFileReadConfig config = new TsFileReadConfig.Builder()
.url("jdbc:iotdb://localhost:6667/")
.username("root")
.password("root")
.build();
Dataset<Row> df = spark.read()
.format("iotdb")
.option("url", config.getUrl())
.option("sql", "SELECT * FROM root.factory1.line1.* WHERE time > 1720000000000")
.load();
df.show();
}
}
sql
-- IoTDB 与 Flink 集成示例:流式写入
CREATE TABLE iotdb_sink (
device_id STRING,
temperature DOUBLE,
humidity DOUBLE,
ts BIGINT,
WATERMARK FOR ts AS ts - INTERVAL '5' SECOND
) WITH (
'connector' = 'iotdb',
'host' = 'localhost',
'port' = '6667',
'username' = 'root',
'password' = 'root',
'device' = 'root.sink.device',
'timestamp' = 'ts'
);4.6 Apache 顶级项目:开源治理的保障
Apache IoTDB 是 Apache 软件基金会顶级项目,遵循 Apache 2.0 协议完全开源,包括分布式集群功能。这意味着企业无需为集群功能支付额外授权费用,且社区治理规范、代码质量有保障。活跃的社区贡献者持续推动功能迭代和性能优化,为企业提供了长期的技术保障。
五、选型建议:什么场景该选什么数据库
基于以上分析,我们给出以下选型建议:
| 应用场景 | 推荐方案 | 核心理由 |
|---|---|---|
| 工业物联网/车联网/智慧能源 | Apache IoTDB | 树形数据模型、极致压缩、端边云协同、百万级设备接入 |
| IT 运维监控/DevOps | InfluxDB | 生态工具链完善,社区资源丰富,适合中小规模监控 |
| 时序+关系数据混合分析 | TimescaleDB | 完整 SQL 支持,降低学习成本,适合混合查询 |
| 大规模工业+企业级服务 | IoTDB 企业版(Timecho) | 商业支持、行业解决方案、高级功能 |
六、结语
时序数据库选型不是简单的技术参数对比,而是需要从业务场景出发,综合考虑数据模型适配度、写入性能、存储成本、查询能力、架构扩展性和生态集成等多维因素。在大数据与工业物联网深度融合的今天,Apache IoTDB 凭借自研 TsFile 存储格式的极致压缩、树形层级模型的场景适配、端边云协同的独特架构以及 Apache 开源生态的长期保障,正在成为工业时序数据管理的最优选择。
对于正在规划时序数据平台的企业,建议下载 IoTDB 进行实际场景的 PoC 验证,亲身感受其在写入性能、存储效率和查询速度上的技术优势。