1.执行流程
管理连接, 权限校验
语法/词法分析
生成语法树
"选择「主键索引」
为最优执行计划"
是"命中缓存"
否"缓存未命中"
"客户端发送 SQL:
SELECT * FROM user WHERE id = 10"
连接器
分析器
优化器
执行器
"InnoDB Buffer Pool
中是否存在目标数据页?"
"直接从Buffer Pool
返回记录"
"根据主键B+树
定位到叶子节点数据页"
"从磁盘读取数据页
加载到 Buffer Pool"
"执行器将结果集
返回给客户端"
连接器
客户端使用连接池技术来复用连接,而 MySQL 服务端使用线程池技术来管理连接处理。
连接器:
-
与客户端进行 TCP 三次握手建立连接;
-
校验客户端的用户名和密码,如果用户名或密码不对,则会报错;
-
如果用户名和密码都对了,会读取该用户的权限,然后后面的权限逻辑判断都基于此时读取到的权限;
解析器
-
**词法分析:**根据输入的字符串识别出关键字出来,例如,SQL 语句 select username from userinfo,在分析之后,会得到 4 个 Token,其中有 2 个 Keyword,分别为 select 和 from。
-
语法分析: 根据词法分析的结果,语法解析器会根据语法规则,判断输入的这个 SQL 语句是否满足 MySQL 语法,如果没问题就会构建出 SQL 语法树,这样方便后面模块获取 SQL 类型、表名、字段名、 where 条件等等。如果我们输入的 SQL 语句语法不对,会报错:You have an eeror in your SQL syntax;
预处理器
-
检查 SQL 查询语句中的表或者字段是否存在;
-
将
select *中的*符号,扩展为表上的所有列;
优化器
优化器主要负责将 SQL 查询语句的执行方案确定下来,比如在表里面有多个索引的时候,优化器会基于查询成本的考虑,来决定选择使用哪个索引。
执行器
- 主键索引查询
存储引擎(InnoDB)的工作 - 核心步骤
-
定位索引根页面 :InnoDB 引擎从数据字典 中找到
user表的主键索引(聚簇索引)的根页(Root Page)所在位置。 -
B+ 树导航:
-
主键索引是一棵 B+ 树,非叶子节点存储键值(主键 ID)和指向子页的指针,叶子节点按顺序存储完整的行数据。
-
引擎从根页开始,使用二分查找法,沿着
id = 10这个键值在 B+ 树中进行搜索。 -
例如,根页可能存有
(5, P1), (20, P2)的指针,那么10在5和20之间,所以导航到P1指针指向的子页。如此递归,直至找到对应的叶子节点页。
-
-
访问缓冲池(Buffer Pool):
-
InnoDB 不会直接读写磁盘。它首先在内存中的 Buffer Pool 里查找这个叶子节点页是否已经被缓存。
-
如果缓存命中,则直接在内存中获取数据。
-
如果缓存未命中 ,则需要发起一次 I/O 操作 ,从磁盘(。ibd 文件)中将包含
id = 10这行记录的整个数据页加载到 Buffer Pool 中。
-
-
行记录获取 :在内存的数据页中,引擎快速定位到
id = 10的这行记录,并将其返回给上一层的执行器。
执行器返回结果
-
执行器从存储引擎拿到第一行(也是唯一一行)数据。
-
在拿到数据后,它还会根据 SQL 语句的
SELECT *部分,对这行记录做一次"格式化"(例如,字段的转换处理等,本例中很简单)。 -
最终,执行器将结果存入结果集,通过连接返回给客户端。
-
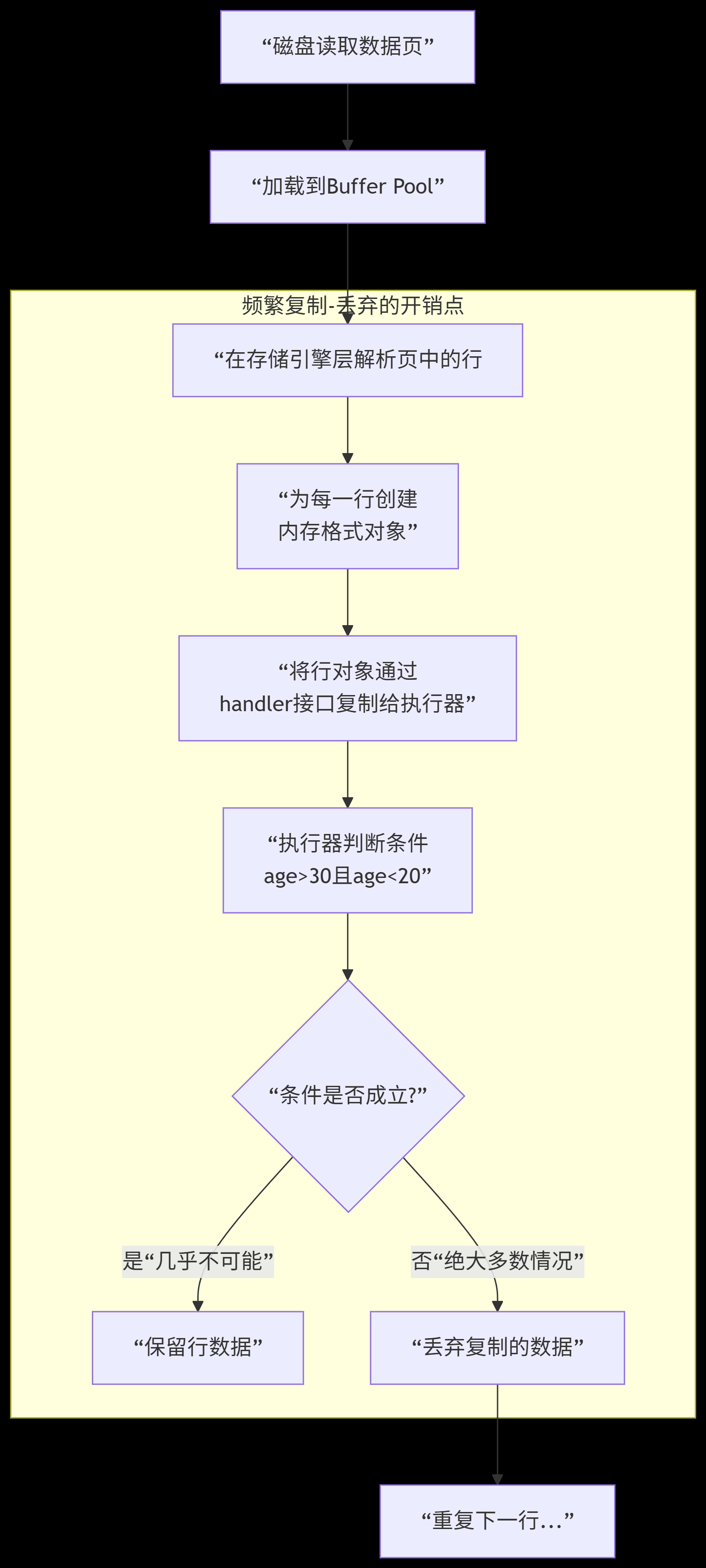
全表扫描:在执行全表扫描时,存在着大量的行数据"复制-传递-丢弃"的开销。
存储引擎(InnoDB)的全表扫描循环关键点 :InnoDB 的全表扫描,并不是杂乱无章地读取磁盘上的行。而是利用聚簇索引(主键索引)的叶子节点链表 进行顺序扫描。
-
定位起点 :执行器首次调用存储引擎接口时 ,存储引擎会定位到聚簇索引 B+ 树最左边的叶子节点页(即主键值最小的记录所在的页)。
-
顺序遍历叶子节点链表:
-
存储引擎将该页从磁盘加载到 Buffer Pool(如果不在内存中)。
-
然后从该页的第一条记录开始,依次读取每一条行记录。
-
每读出一条记录,就返回给执行器。
-
-
页间跳转 :当一个数据页的所有记录都读完,存储引擎会通过 B+ 树叶子节点间的双向链表指针,找到下一个数据页,继续同样的顺序读取过程。这个过程会一直持续,直到遍历完整个叶子节点链表,即扫描了表中的所有行。
执行器的过滤与收集:
-
对于存储引擎返回的每一行数据 ,执行器都会根据 SQL 语句中的
WHERE age > 30条件进行判断。 -
如果条件满足,执行器会将这行数据放入结果集。
-
如果条件不满足,执行器会丢弃这行数据。
-
这个过程会持续到存储引擎返回 "没有更多数据了"(即已扫描所有行)。
执行器返回结果
- 当全表扫描循环结束后,执行器将收集到的所有满足条件的行构成最终结果集,返回给客户端。