基本概念

STL六大组件

容器

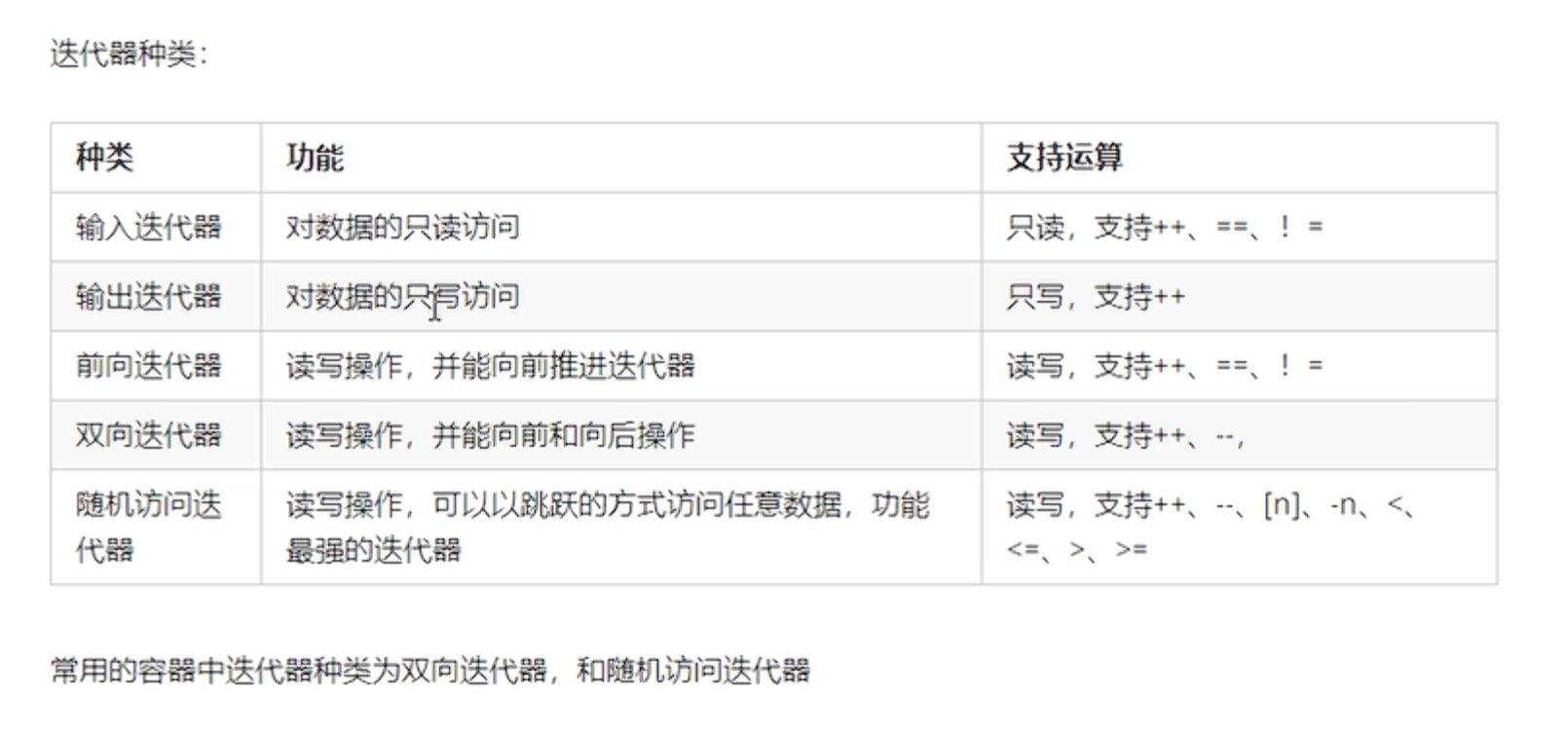
随机访问
可以随机访问即是无需遍历容器,通过下标 / 索引直接定位到容器中任意位置的元素,访问耗时恒定。
换句话说,可以随机访问要么元素本身连续(vector,string,array),要么有一个连续的索引表(deque)
算法

迭代器

迭代器头文件--#include <iterator>
next函数
迭代器中,某些容器可以通过it+数字来快速访问当前下标的元素,如vector、deque、array、string,这是因为这些容器内存是连续的,像数组一样,支持快速跳转。
vector<int> v; it = v.begin(); it = it + 3; //现在it相当是v容器中第四个元素的迭代器但是某些容器不支持这样操作,如set、map等,其所支持的访问如下:
#include <iostream> #include <set> #include <iterator> // 用于 next using namespace std; int main() { set<int> s = {10, 20, 30, 40, 50}; // 删除第 3 个元素 auto it = next(s.begin(), 2); s.erase(it); for (int x : s) cout << x << " "; // 输出:10 20 40 50 return 0; }同时next函数几乎支持所有STL库的容器的迭代。当你只需要最后一个元素时,也可以直接使用prev(s.end())
std::prev(s.end()) 的意思就是 "指向容器中最后一个元素的迭代器"
string容器--#include<string>
本质概念

构造函数

string s1; const char* s = " Hello,world"; string s2(s); cout << "s2 = " << s2 << endl; string s3(s2); cout << "s3 = " << s3 << endl; string s4(10, 'a'); cout << "s4 = " << s4 << endl; //s2 = Hello,world //s3 = Hello,world //s4 = aaaaaaaaaa //10个a
赋值操作

追加操作

查找和替换操作

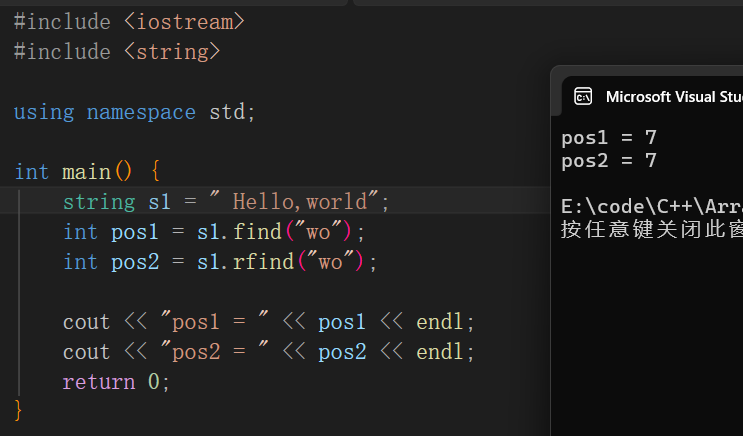
find和rfind查找后都是返回数组中元素的下标,当找不到字符串时返回-1
其中find是从左往右(第一位到最后一位),而rfind是从右往左(最后一位到第一位),但是都是返回需要查找的字符串符合要求的左边字符的下标,如下所示
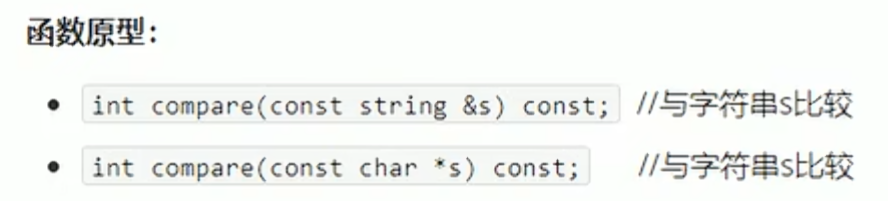
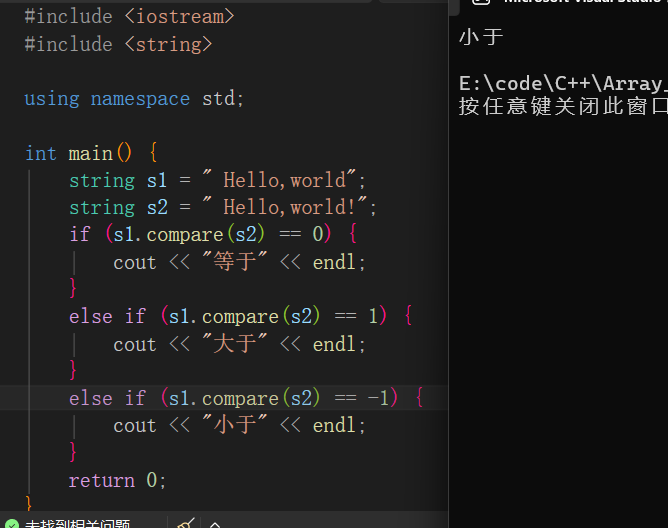
比较操作
比较字符串的AC码,等于返回0,大于返回1,小于返回-1
字符存取操作

插入和删除操作

子串获取操作

vector容器--#include<vector>
构造函数

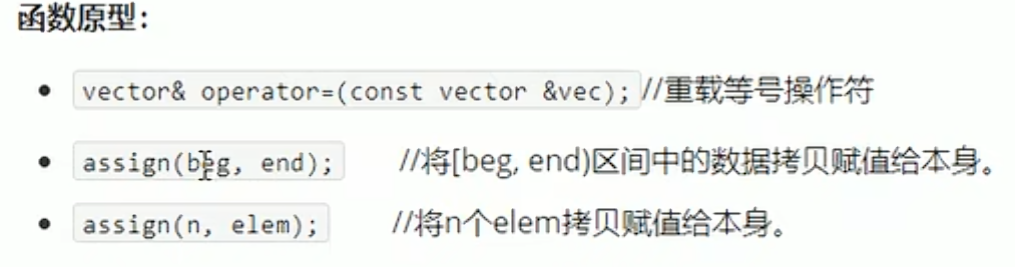
赋值操作
容量和大小

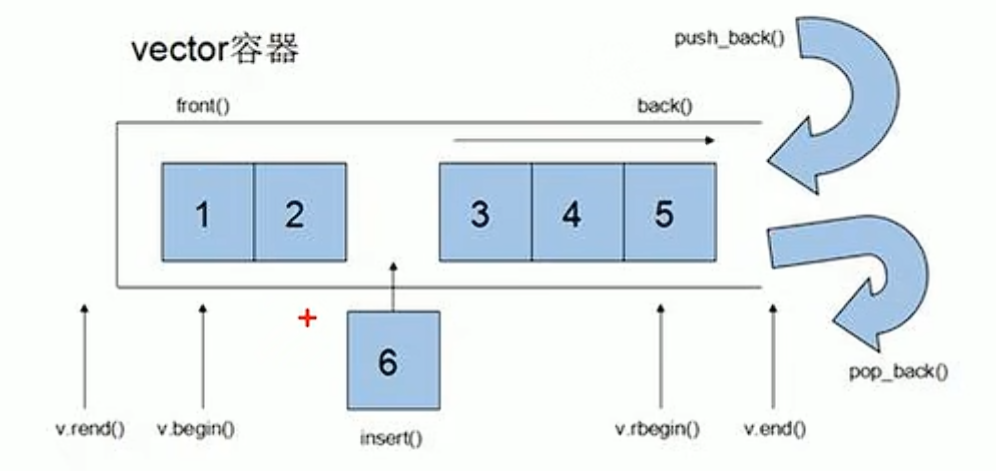
迭代器--iterator
vector<T>::iterator itBegin = v.begin()
vector<T>::iterator itEnd = v.end()
vector<string> v; //iterator为vector作用域下的迭代器 //begin为起始迭代器,指向容器第一个元素 vector<string>::iterator itBegin = v.begin(); //begin为结束迭代器,指向容器最后一个元素的下一个位置 vector<string>::iterator itEnd = v.end();
遍历方式
while循环
vector<string>::iterator itBegin = v.begin(); vector<string>::iterator itEnd = v.end(); while (itBegin != itEnd) { cout << *itBegin << endl; itBegin++; }
for循环
for (vector<string>::iterator it = v.begin();it != v.end(); it++) { cout << *it << endl; }对于自定义的数据类型,比如类或结构体等,*it表示的数据类型和赋值给vector容器的数据类型相同。
STL提供的遍历算法
void myPrint(string val) { cout << val << endl; } for_each(v.begin(), v.end(), myPrint);这个方法需要自定义一个函数,同时包含头文件<algorithm>
在自定义函数中,输出的数据与前面的输出不同,不使用指针传输,因此for_each内部的传输自带指针
_EXPORT_STD template <class _InIt, class _Fn> _CONSTEXPR20 _Fn for_each(_InIt _First, _InIt _Last, _Fn _Func) { _STD _Adl_verify_range(_First, _Last); auto _UFirst = _STD _Get_unwrapped(_First); const auto _ULast = _STD _Get_unwrapped(_Last); for (; _UFirst != _ULast; ++_UFirst) { _Func(*_UFirst); } return _Func; }可以看出for_each的内部也是使用的for循环输出指针,并且使用的是模板传入,以适配更多的数据类型。
const修饰迭加器
当你不想要外部修改容器中的值时,那么就需要使用const_iterator迭加器
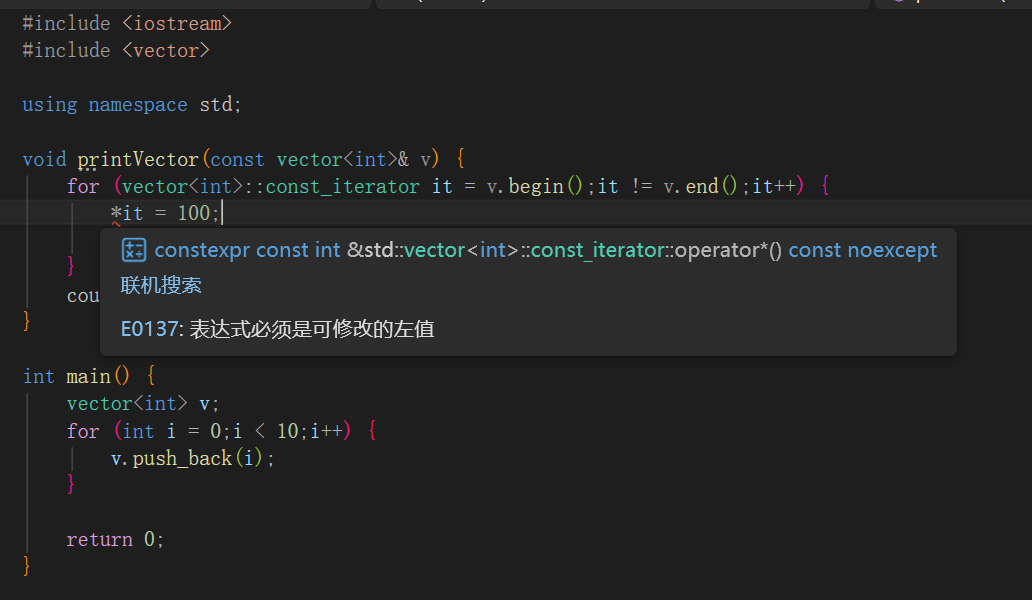
如上述代码,除了将迭加器修改为const_iterator以外,如果使用函数传入实参,也需要在传入时使用const修饰。
vector容器嵌套容器
#include <iostream> #include <vector> #include <algorithm> using namespace std; void test() { vector<vector<int>> v; vector<int> v1; vector<int> v2; v1.push_back(10); v1.push_back(20); v2.push_back(30); v2.push_back(40); v.push_back(v1); v.push_back(v2); for (vector<vector<int>>::iterator it = v.begin();it != v.end(); it++) { //*it=vector<int> for (vector<int>::iterator its = (*it).begin(); its != (*it).end(); its++) { cout << *its << " "; } cout << endl; } } int main() { test(); return 0; }
插入和删除操作

insert和erase的第一个元素均为迭加器
第一个元素为v.begin(),第二和三个元素分别为v.begin()+1和v.begin()+2
最后一个元素的后一位为v.end(),因此最后一位元素为v.end()-1
数据存取操作

互换操作

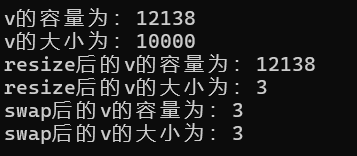
通过vect<int>(v).swap(v);可以收缩内存
#include <iostream> #include <vector> using namespace std; int main() { vector<int> v; for (int i = 0;i < 10000;i++) { v.push_back(i); } cout << "v的容量为:" << v.capacity() << endl; cout << "v的大小为:" << v.size() << endl; v.resize(3); cout << "resize后的v的容量为:" << v.capacity() << endl; cout << "resize后的v的大小为:" << v.size() << endl; vector<int>(v).swap(v); cout << "swap后的v的容量为:" << v.capacity() << endl; cout << "swap后的v的大小为:" << v.size() << endl; return 0; }可以看出使用swap后vector所占的容量减少,大大节省了内存空间。其本质如下:
vector<int> (v)--匿名对象,其可以通过v的大小初始化一个新的vector容器,这个容器的大小和容量均为3
调用swap后便将这两个容器互换,同时删除新建的vector容器,而之前的vector容器由于互换导致其大小和容量均变为了3,从而节省了内存空间
预留空间操作

vector 动态扩容时,若初始预留空间远不足10000个数据,会在填满时反复 "重新分配更大内存->复制原有元素->释放旧空间"。这会导致容器首地址频繁改变,使得之前指向容器的迭代器、指针或引用会全部失效,同时多次复制元素会带来显著的性能开销。
因此可以使用reserve预留出所需的空间,从而避免容器首地址的频繁改变,并减少多次复制元素带来的性能开销。
deque容器--#include<deque>
功能
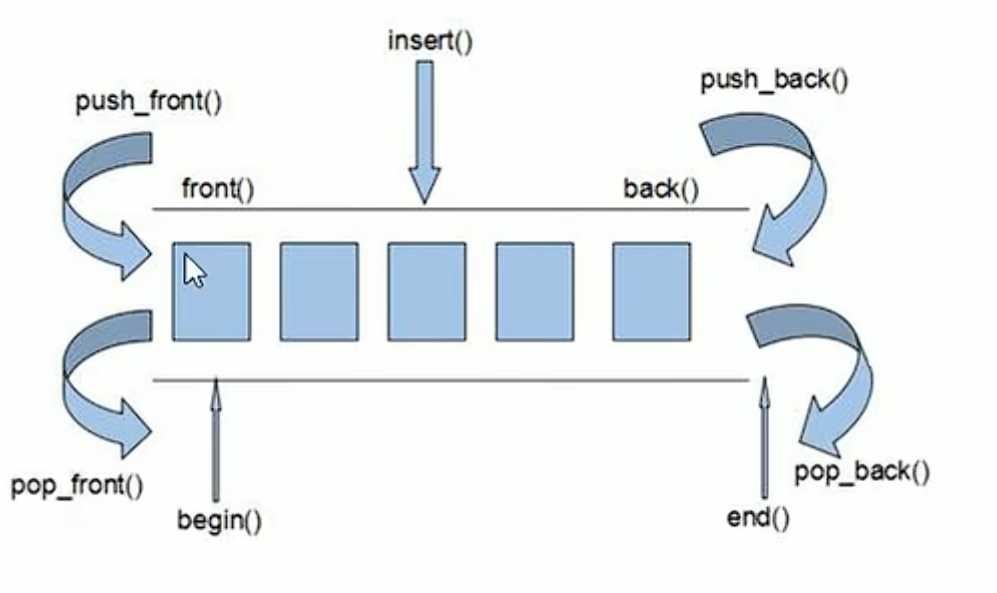
双端数组,可以对头端进行插入删除操作
deque与vector根本的不同在于对于数据的储存方式不同。
vector储存数据是将所有数据放置在一片连续的内存空间中,同时预留一部分容量,当其预留的容量仍无法完全储存当前数据时,开辟一个新的连续内存空间,直至可以将其完全储存。
而deque储存数据是将多个小的不连续的内存空间结合在一起,储存数据,保存每段内存空间的首地址以实现连续,当有无法储存的数据时,就开辟一个新的、与上述内存空间不连续的内存空间,因此可以实现首插入和尾插入。
因此我们也将deque的储存方式称为局部连续(缓冲区),整体分段(中控器)
和vector容器的区别
| 特性 | std::vector | std::deque |
|---|---|---|
| 内存结构 | 一段连续的内存块 | 分段连续内存(多缓冲区 + 中控器) |
| 随机访问 | 极快(O (1),直接指针偏移) | 快(O (1),但需计算段地址) |
| 插入 / 删除(头) | 极慢(需移动所有后续元素) | 极快 |
| 插入 / 删除(尾) | 极快(预留空间足够时) | 极快 |
| 插入 / 删除(中间) | 慢(需移动后续元素) | 慢(需移动元素) |
| 迭代器失效 | 扩容时全部失效;中间操作后后续失效 | 中间操作全部失效;头尾操作可能失效 |
| 内存释放 | 只增不减,需 swap 手动收缩 |
删除元素可自动释放部分缓冲区 |
| 缓存友好性 | 高(连续内存,CPU 缓存命中高) | 较低(分段内存,缓存跳转多) |
迭代器
构造函数

赋值操作

容器大小

这里出现一个和vector的区别,deque没有容量的限制,这是因为deque对于数据的储存方式是不连续的,某种程度来说,其的容量是整个内存的容量。
插入和删除

数据存取操作

list容器--#include<list>
概念
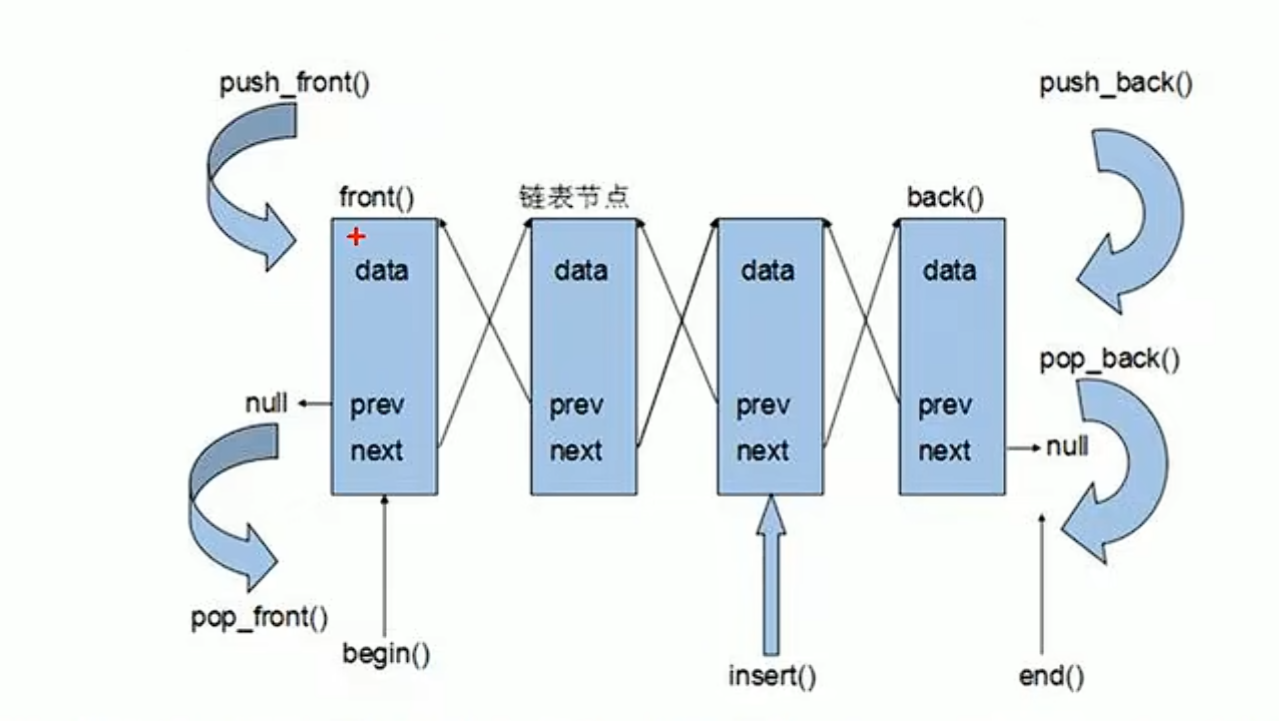
将数据进行链式储存

链表
链表(list)是一种物理存储单元上非连续的存储结构,数据元素的逻辑顺序是通过链表中的指针链接实现的
链表的组成:链表由一系列结点组成
结点的组成:一个是存储数据元素的数据域,另一个是存储下一个结点地址的指针域
list容器和deque容器最大的区别也在于数据的存储deque容器的数据存储是缓冲区中元素局部连续,中控区的指针整体分散的。
list容器的元素是完全分散的,每一个元素都是一个新的结点,因此内存还需要记录每一个元素在内存中的指针,同时还为了区分每个元素的先后顺序,每一个结点除了储存自身的指针外,还会储存指向下一个元素的指针。
因此list的内存开销非常大,但是list可以对任意位置进行极快的插入和删除
| 特性 | std::deque | std::list |
|---|---|---|
| 内存结构 | 分段连续内存(多缓冲区 + 中控器) | 双向链表(每个节点独立存储,含前后指针) |
| 随机访问 | 支持(O (1),需计算段地址) | 不支持(仅支持双向遍历,O (n)) |
| 插入 / 删除(头) | 极快 | 极快(O (1)) |
| 插入 / 删除(尾) | 极快 | 极快(O (1)) |
| 插入 / 删除(中间) | 慢(需移动后续元素) | 极快(O (1),只需调整指针) |
| 迭代器类型 | 随机访问迭代器 | 双向迭代器 |
| 迭代器失效 | 中间操作全部失效;头尾操作可能失效 | 仅失效指向被删除节点的迭代器 |
| 内存开销 | 较低(中控器 + 缓冲区) | 较高(每个节点需额外存储前后指针) |
| 缓存友好性 | 中等(分段连续,有一定缓存命中) | 低(节点分散,缓存跳转多) |
选vector:优先考虑内存效率和随机访问速度,且主要在尾部操作;
选list:优先考虑已知位置的插入 / 删除速度,且不需要随机访问;
选deque:需要头尾都快速插入 / 删除,且仍需随机访问,是两者的折中。
构造函数

赋值和交换操作

大小操作

插入和删除操作

数据存取操作

反转和排序操作

这里的sort()是list容器的成员函数,而非下面的算法中的函数,因此不需要包含算法的头文件,直接在list容器后面使用.进行调用即可。
list的sort函数一共有两个版本,默认是进行升序排列(l.sort()),其次是在sort函数中传递一个bool型的函数用以判断,传递的这个函数称为仿函数。
#include <iostream> #include <list> #include <string> using namespace std; class Person { public: string name; int age; int heigh; Person(string name, int age, int heigh):name(name), age(age), heigh(heigh){ } }; bool compare(Person& p1, Person& p2) { //按年龄大小升序排列,如果年龄相同则按身高升序排列 if (p1.age != p2.age) { return p1.age < p2.age; } else { return p1.heigh < p2.heigh; } } int main() { Person p1 = { "a", 13, 166}; Person p2 = { "b", 31, 175}; Person p3 = { "c", 20, 174}; Person p4 = { "d", 18, 189}; Person p5 = { "e", 18, 179}; list<Person> l; l.push_back(p1); l.push_back(p2); l.push_back(p3); l.push_back(p4); l.push_back(p5); l.sort(compare); for (list<Person>::iterator it = l.begin(); it != l.end(); it++) { cout << "姓名:" << (*it).name << "\t年龄:" << (*it).age << "\t身高:" << (*it).heigh << endl; } return 0; }
set/multiset容器--#include<set>
概念
所有的元素都会在自动插入时自动被排序
set/multiset容器的区别:

构造函数

赋值操作

大小和交换操作

插入和删除操作

与前面不同的是,set/multiset只有insert函数,但是没有push、pop等函数
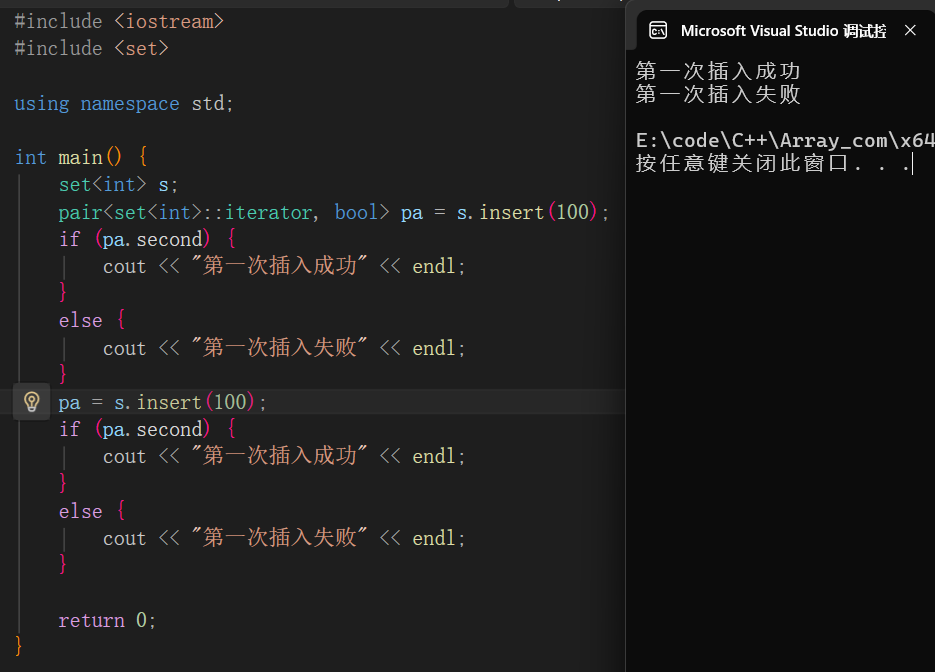
insert返回的pair对组
insert返回的对组是set容器判断插入的数据是否重复的重要依据,下述是set容器中insert的源码
template <bool _Multi2 = _Multi, enable_if_t<!_Multi2, int> = 0> pair<iterator, bool> insert(value_type&& _Val) { const auto _Result = _Emplace(_STD move(_Val)); return {iterator(_Result.first, _Get_scary()), _Result.second}; }该对组第一个元素是set的迭代器,第二个元素是bool类型的返回值,该返回值为ture则表示插入的数据没有重复,否则则是重复,不再插入
输出pair对组直接在对组后面使用first和second来实现即可
创建pair对组

查找和统计操作

由于set/multiset容器的特性,count统计出的元素个数只能为0或1
set容器的排序
由于set容器也是无法随机访问的容器,因此无法使用算法头文件中sort进行排序,但其内部有自己的排序成员函数。
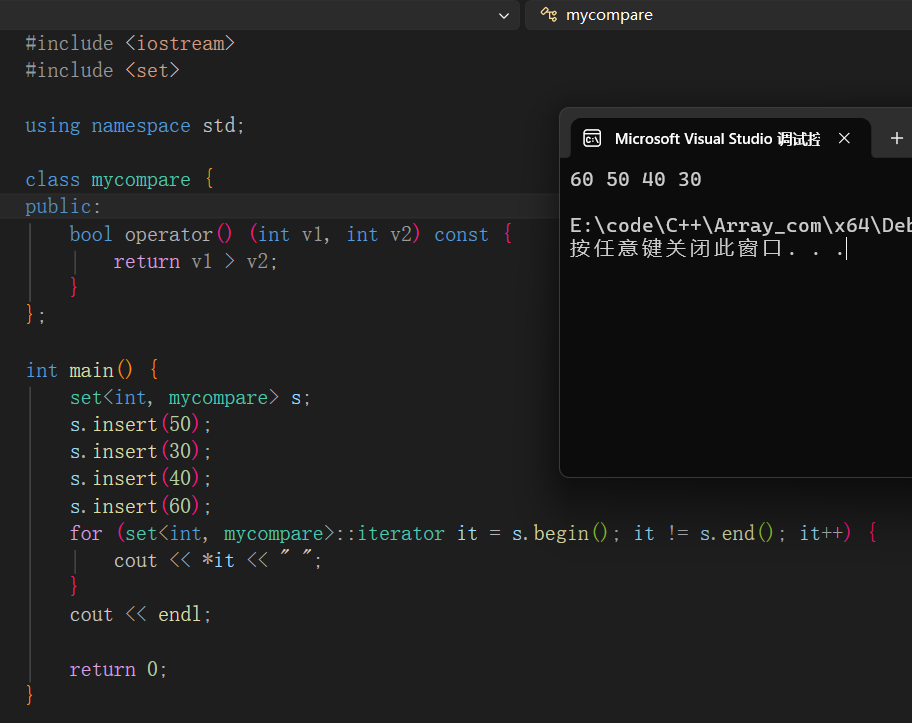
内置类型指定排序规则
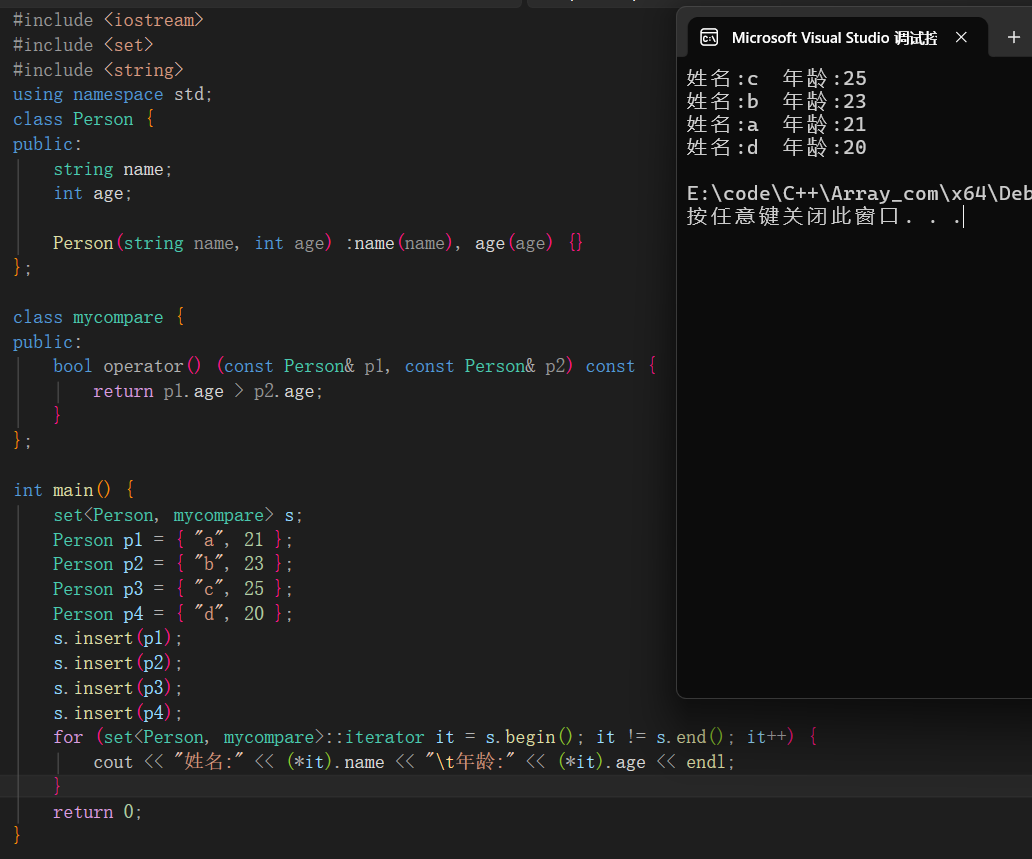
自定义数据类型指定排序规则
如果要给set容器中传入自定义的数据类型,那么就一定需要进行set函数排序的重新定义,因为set容器需要对传入的元素进行排序,但是默认排序无法适用于自定义的数据类型。
map/multimap容器--#include<map>
概念

map/multimap容器的性能较快,但是所需的内存开销也非常的大

构造函数

赋值操作

大小和交换操作

插入和删除操作

查找和统计操作

map容器的排序
#include <iostream> #include <map> #include <string> using namespace std; class Person { public: string name; int age; Person(string name, int age) :name(name), age(age) {} }; class mycompare { public: bool operator() (const Person& p1, const Person& p2) const { return p1.age > p2.age; } }; int main() { map<Person, int, mycompare> s; Person p1 = { "a", 21 }; Person p2 = { "b", 23 }; Person p3 = { "c", 25 }; Person p4 = { "d", 20 }; s.insert(pair<Person, int>(p1, 1)); s.insert(pair<Person, int>(p2, 2)); s.insert(pair<Person, int>(p3, 3)); s.insert(pair<Person, int>(p4, 4)); for (map<Person, int, mycompare>::iterator it = s.begin(); it != s.end(); it++) { cout << "姓名:" << (*it).first.name << "\t年龄:" << (*it).first.age << endl; } return 0; }
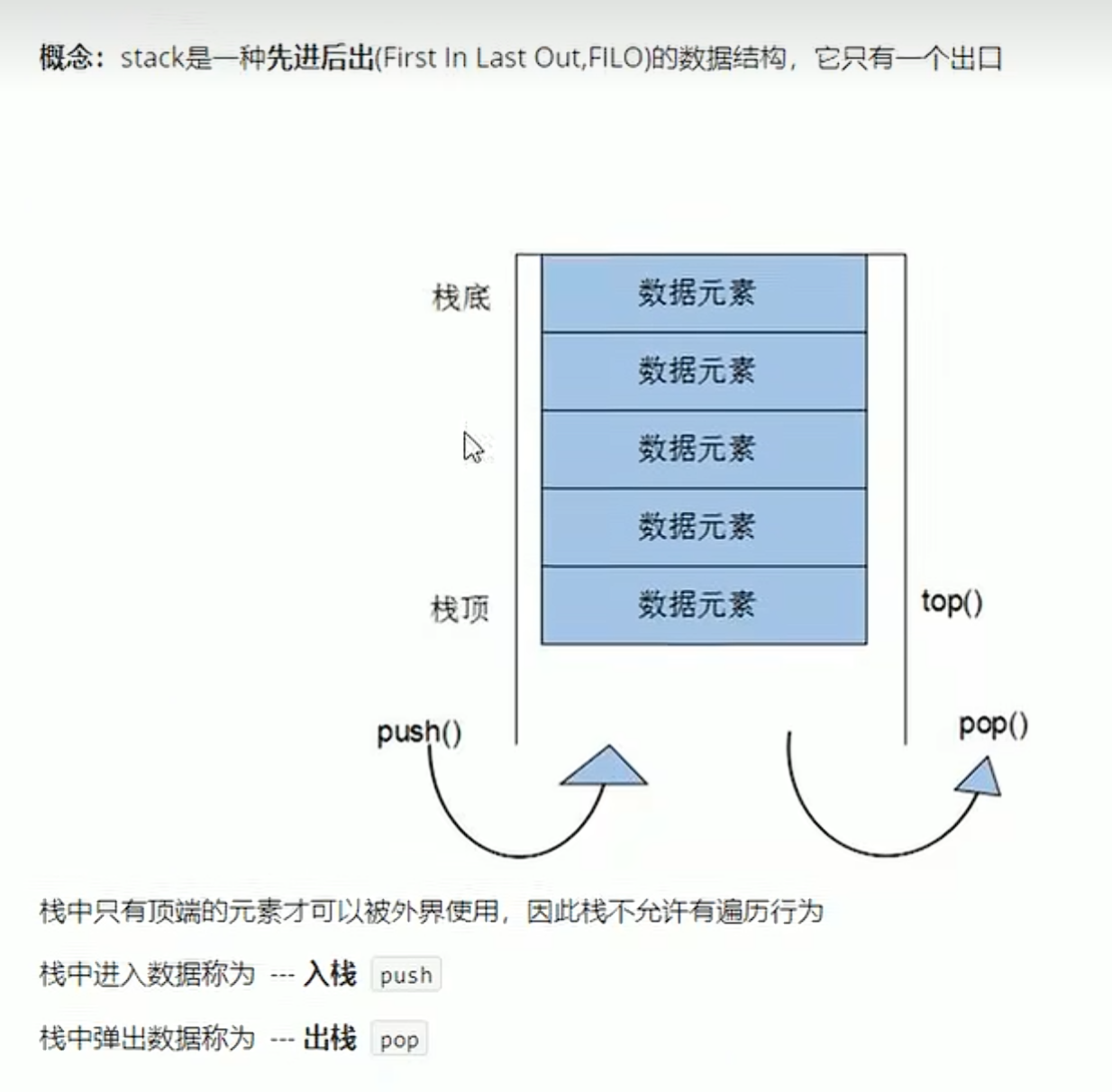
stack容器--#include<stack>
概念
构造函数

赋值操作

数据存取操作

大小操作

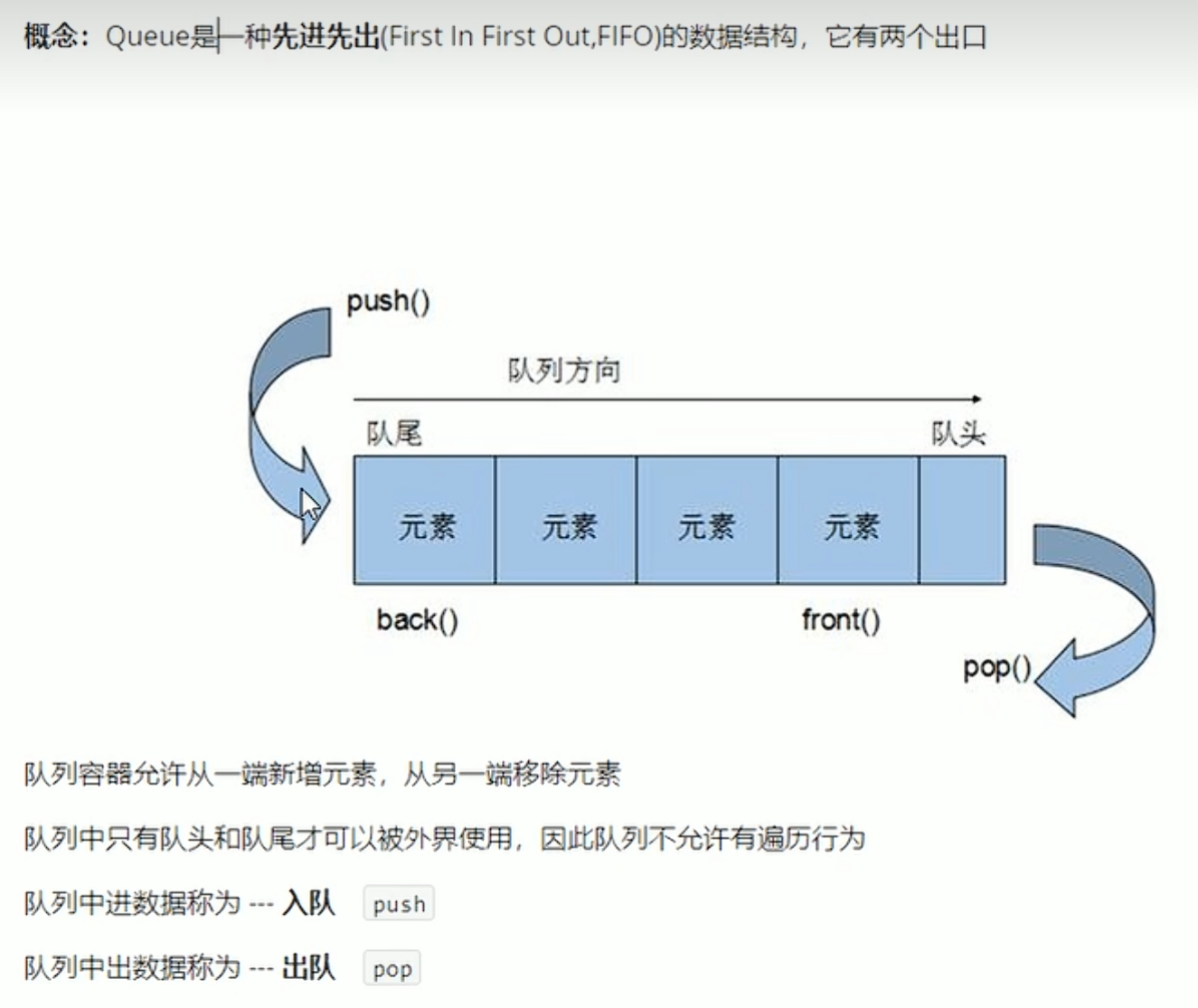
queue容器--#include<queue>
概念
构造函数

赋值操作

数据存取操作

大小操作

函数对象(仿函数)
概念
 特点
特点

#include <iostream> #include <string> using namespace std; class myAdd { public: //函数对象超出普通函数的概念,函数对象可以有自己的状态 int v1; int v2; //函数对象在使用时,可以像普通函数那样调用,可以有参数,可以有返回值 int operator()(int v1, int v2) { return v1 + v2; } }; int main() { myAdd a(20, 20); //函数对象可以作为参数传递 cout << a(10, 20) << endl; cout << a.v1 << endl; return 0; }
谓词--Pred
概念

内建函数对象
用法

算数仿函数

关系仿函数

前面所有实现自定义排序时,使用的仿函数都是关系仿函数
但是如果你使用的是自定义的数据类型,比如class、struct等,那么在必须自己重载所要用到的符号,否则就自己重载一个关系仿函数
class Person { public: string name; int age; Person(string name, int age) : name(name), age(age) {} bool operator>(const Person& other) const { // 按年龄降序比较 return this->age > other.age; } }; int main() { set<Person, greater<Person>> s; s.insert(Person("a", 21)); s.insert(Person("b", 23)); s.insert(Person("c", 20)); for (const auto& p : s) { cout << p.name << " " << p.age << endl; } return 0; }
逻辑仿函数
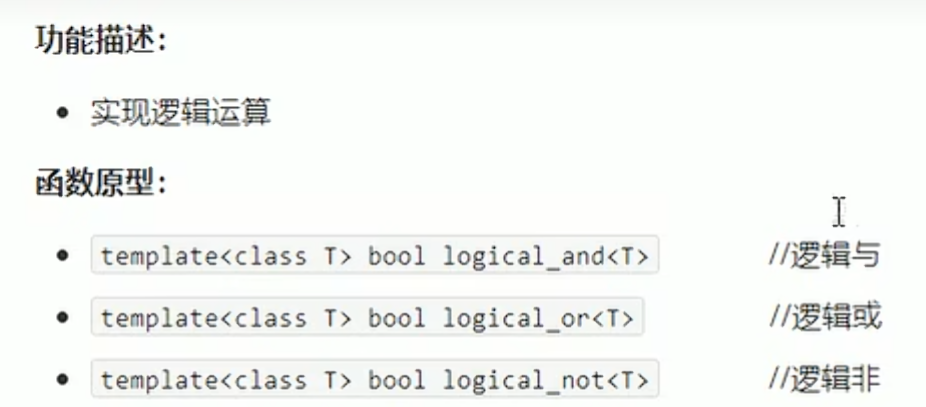
算法--#include<algorithm>
算法需要包含#include <algorithm>
遍历算法
遍历容器--for_each

搬运容器--transform

在搬运容器中,需要对目标容器进行resize赋予容量,否则程序会崩溃,一般使用size()函数进行开辟空间。
同时在搬运自定义数据时,直接使用resize进行赋值会导致程序发生错误
这是因为使用resize操作强制要求元素必须有默认无参构造函数。因此要么再写一个默认的无参构造函数,如下:
Person() = default;或者使用back_inserter()来进行传递,这个函数会自动调用push_back插入元素,但是需要包含头文件#include <iterator>
#include <iostream> #include <string> #include <vector> #include <algorithm> #include <iterator> using namespace std; class Person { public: string name; int age; //Person() = default; //默认无参构造函数 Person(string name, int age):name(name), age(age){} }; class trans { public: string name; int age; //姓名+_new,年龄+1 Person operator()(const Person& p) { return Person(p.name + "_new", p.age + 1); } }; int main() { Person p1("aaa", 11); Person p2("bbb", 22); vector<Person> v; v.push_back(p1); v.push_back(p2); vector<Person> v1; transform(v.begin(), v.end(), back_inserter(v1), trans()); return 0; }

查找算法
自定义类型的容器使用查找算法时,都需要重载==运算符,如下find函数实例。
这个不是绝对的,当只需要对比一部分,或者需要一定限制条件时,也可以直接使用谓词函数或匿名函数,如下find_if实例。
查找元素--find

当查找自定义数据类型时,需要重载==符号,否则无法找到元素
#include <iostream> #include <string> #include <vector> #include <algorithm> using namespace std; class Person { public: string name; int age; Person(string name, int age):name(name), age(age){} //重载==使得find函数内部可以对Person类进行对比 bool operator==(const Person& p) { if ((this->name == p.name) && (this->age == p.age)) { return true; } return false; } }; int main() { Person p1("aaa", 11); vector<Person> v; v.push_back(p1); vector<Person>::iterator it = find(v.begin(), v.end(), p1); if (it == v.end()) { cout << "没有找到" << endl; } else { cout << "找到 姓名:" << (*it).name << "\t年龄:" << (*it).age << endl; } return 0; }
按条件查找元素--find_if

这个同上也需要重载==运算符,如果不重载运算符,则可以传递函数对象。同时也可以使用匿名函数
#include <iostream> #include <string> #include <vector> #include <algorithm> using namespace std; class Person { public: string name; int age; Person(string name, int age):name(name), age(age){} }; class iffind{ public: bool operator()(const Person& p) { return p.age > 20; } }; int main() { Person p1("aaa", 11); Person p2("bbb", 22); vector<Person> v; v.push_back(p1); v.push_back(p2); vector<Person>::iterator it = find_if(v.begin(), v.end(), iffind()); if (it == v.end()) { cout << "没有找到" << endl; } else { cout << "找到 姓名:" << (*it).name << "\t年龄:" << (*it).age << endl; } return 0; } //匿名函数 find_if(v.begin(), v.end(), [](const Person& p) { return p.age > 20; });
查找相邻重复元素--adjacent_find

二分查找法--binary_search

与单纯的find查找元素的方法来说,其速度更快,但是无序序列(stack、queue)无法使用,同时其只能返回bool类型,无法返回元素的位置。
一般使用binary_search的容器有vector、deque、array,而list是双向迭代器,无法直接跳转到中间位置,会导致其效率变得很低。
而如set、map等容器时,其内部为红黑数,本身便是有序的,因此直接使用专门的find成员函数(不是上述的find函数)效率更高、兼容性更好。
统计元素个数--count

按条件统计元素个数--count_if

排序算法
排序--sort(支持随机访问的容器)
对于所有支持随机访问的迭代器的容器,都可以使用sort完成升序操作

后面可以不加谓词,默认为升序排列,若要使用自定义类型的排序,则需要重载谓词或者直接使用functional库中的内建函数对象
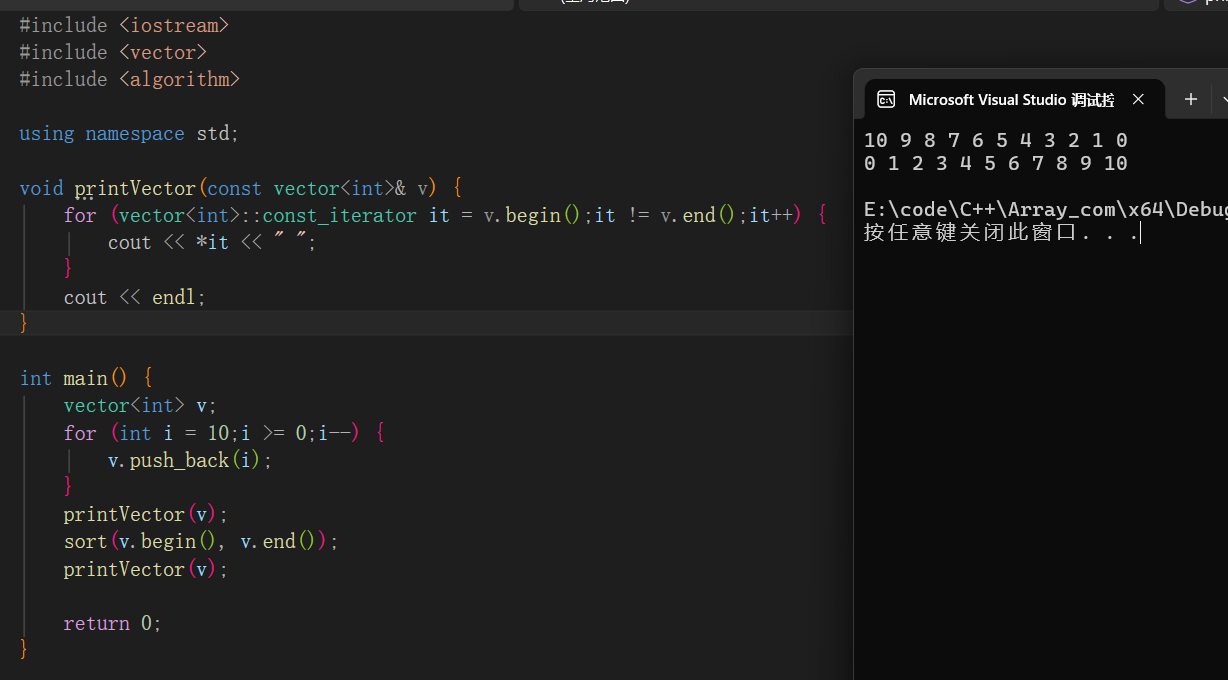
打乱顺序--random_shuffle

这一函数现在使用较少,一般都直接使用shuffle进行打乱
#include <iostream> #include <vector> #include <algorithm> // shuffle 头文件 #include <random> // 随机数引擎头文件 #include <ctime> // time(0) 头文件 using namespace std; int main() { vector<int> v = {1, 2, 3, 4, 5}; // 初始化随机数引擎(用当前时间作为种子) mt19937 rng(time(0)); // 调用 shuffle,传入随机数引擎 shuffle(v.begin(), v.end(), rng); // 每次运行顺序都不同 for (int num : v) { cout << num << " "; } cout << endl; return 0; }
容器元素合并--merge

合并到的容器和之前一样,一定要提前使用resize分配内存。
合并的两个容器可以是不一样的类型,但是其数据类型必须相同,同时排序方式也必须相同
针对于不同的数据类型,假如一个是vector<int>,另一个为deque<Person>,这个Person是一个类,如果要实现这两个容器的合并,必须满足三个条件,一是Person中必须含有int的成员变量,二是必须写一个仅传入int类型所运行的构造函数,三是重载排序运算符使得两个容器的排序方式相同
class Person { public: string name; // 条件1 包含int数据类型 int age; // 条件2 支持从 int 隐式构造(为了让 int 能转为 Person) Person(int age) : name("Unknown"), age(age) {} Person(string name, int age) : name(name), age(age) {} // 条件3 支持按 age 比较(让 int 和 Person 能按同一规则排序) bool operator<(const Person& other) const { return this->age < other.age; } };
反转指定范围的元素-reverse

拷贝和替换算法
元素拷贝--copy

一般情况都不需要重载=运算符,但是当你的原自定义类型中有成员变量是new创建是,便需要重载=运算符。
通过前面的知识可以知道,new创建的成员变量在析构函数中需要释放,但浅拷贝会完全拷贝这变量的所有信息,导致析构函数new区的重复释放,使得程序崩溃,因此这时就需要重载=运算符使得其为深拷贝。
元素替换--replace

replace相比于前面的copy函数,由于其内部存在一个==的对比,所有需要重载==运算符。
指定范围满足条件替换元素--replace_if

replace_if可以很好的替代replace,当replace需要重载==运算符时,直接使用replace_if在谓词中写出函数即可。
互换两个容器--swap

只能互换相同容器的相同类型。
算术生成算法
使用该算法时,不仅需要包含#include <algorithm>头文件,还需要包含#include <numeric>头文件
计算容器元素累计总和--accumlate

当需要类型自定义数据类型时,除了在类中重载+运算符,也可以直接使用匿名函数,如下
#include <iostream> #include <vector> #include <numeric> #include <string> using namespace std; class Person { public: string name; int age; Person(string name, int age) : name(name), age(age) {} }; int main() { vector<Person> v = {Person("a", 21), Person("b", 22), Person("c", 33)}; int total_age = accumulate(v.begin(), v.end(), 0, [](int sum, const Person& p) { return sum + p.age; // 只累加 age }); cout << "所有人的年龄总和:" << total_age << endl; return 0; }
向容器中添加元素--fill

fill只能把同一个固定值填充到整个区间,无法填充不同的值。
集合算法
| 需求 | 推荐算法 |
|---|---|
| 找两个有序序列的共同元素 | std::set_intersection |
| 合并两个有序序列,去重 | std::set_union |
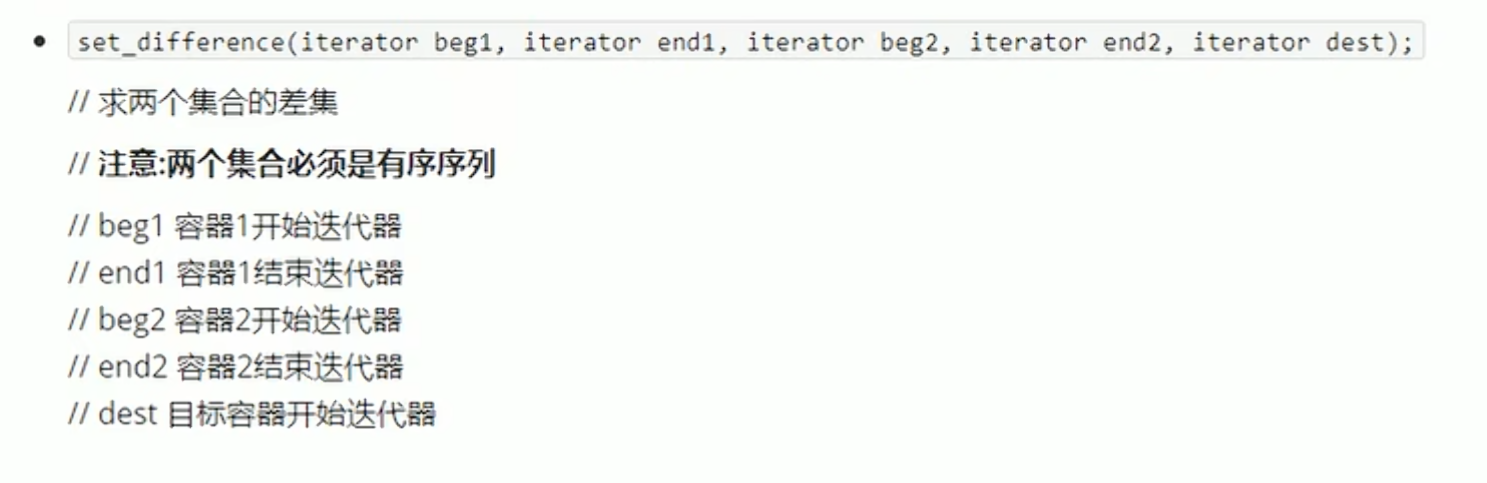
| 找 "在第一个序列有、第二个没有" 的元素 | std::set_difference |
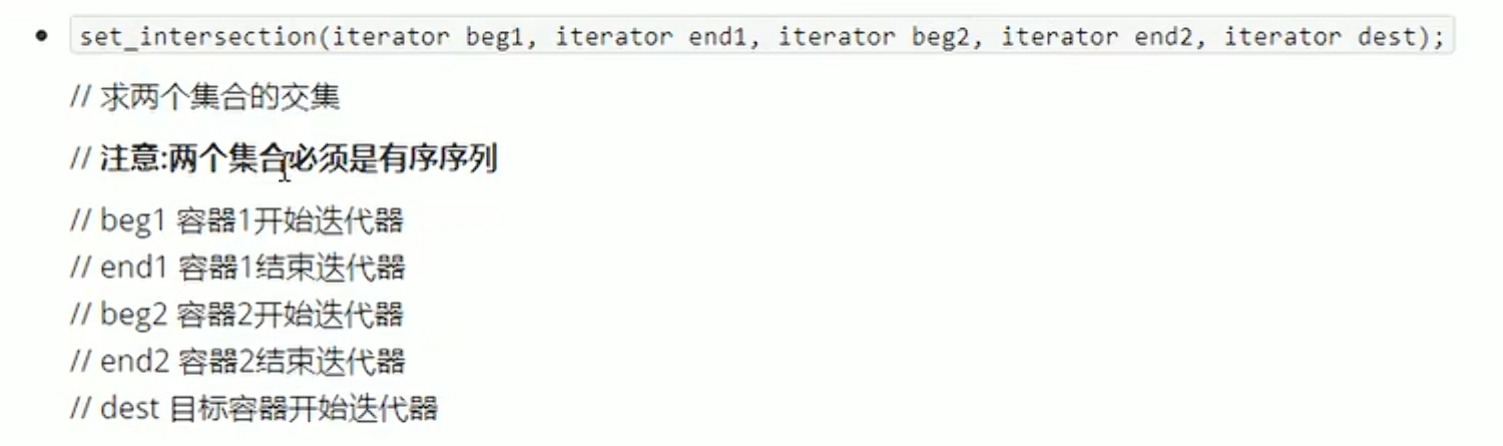
求两个容器的交集--set_intersection
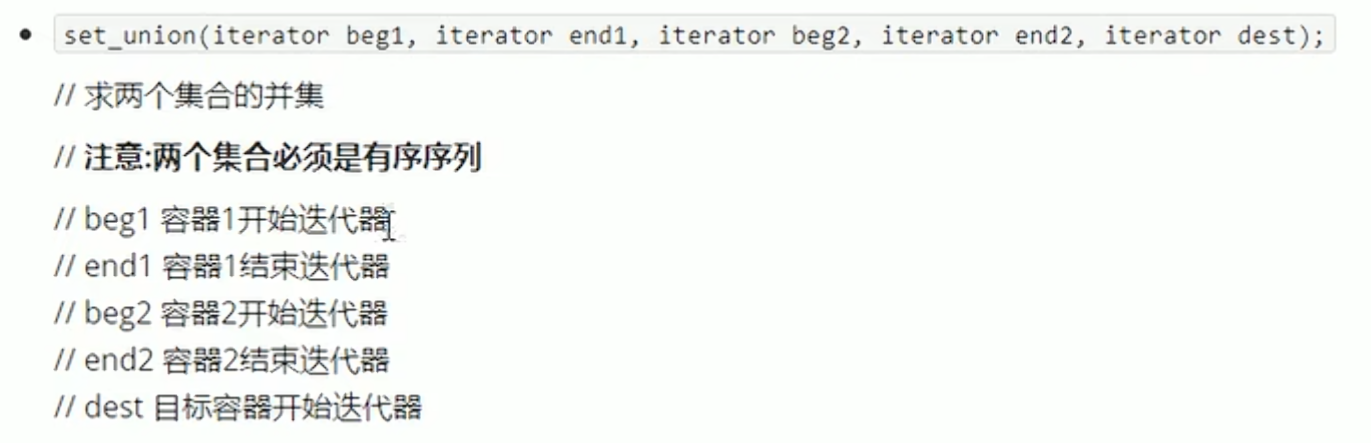
求两个容器的并集--set_union
求两个容器的差集--set_difference