前言:最近花了一段时间,把google/gemma-4-31B-it真正部署到了本地服务器,。把它做成了一个可以通过局域网访问的 vLLM 服务 ,并进一步接入了OpenCode,能够在真实工具链里稳定使用。整个过程比想象中更折腾一些。模型路径、镜像兼容、显存残留、toolcalling、reasoning、长上下文、客户端配置对齐,这些问题单看都不复杂,但只有全部打通之后,模型才算真正"能用"。这篇文章就按实际操作过程,把Gemma-4-31B-it从启动到服务化接入的完整链路记录下来,希望能帮后来者少走一点弯路。
本文实验基于一台 Ubuntu 服务器完成,硬件侧使用 NVIDIA A100 80G GPU。部署前,服务器已完成 NVIDIA 驱动、Docker 与 NVIDIA Container Toolkit 的安装配置;模型运行采用 Gemma 4 专用 vLLM 镜像,目标模型为 google/gemma-4-31B-it,本地模型文件已提前准备完成:
本次部署的最终目标如下:
- 在服务器上启动
google/gemma-4-31B-it; - 使用 vLLM 提供 OpenAI-Compatible API;
- 将模型固定运行在第二张 GPU;
- 在局域网内通过 HTTP 接口访问;
- 后续可接入 OpenCode 使用。
一、模型下载
在正式部署之前,先简单说明一下 Google Gemma-4 系列模型的组成。根据 Google 官方介绍,Gemma 4 目前主要包含四种不同规模的模型,分别是:
- Gemma 4 E2B
- Gemma 4 E4B
- Gemma 4 26B-A4B
- Gemma 4 31B
其中,E2B 和 E4B 属于较小规模模型,更强调端侧或轻量化部署;26B-A4B 属于混合专家(MoE)模型,特点是总参数规模较大,但推理时激活参数更少;31B 则属于较大规模的密集型模型,整体能力更强,更适合服务器侧部署。
从模态能力上看,Gemma 4 系列整体属于多模态模型,支持文本与图像输入;其中 E2B 和 E4B 原生支持音频输入,而 31B 与 26B-A4B 主要面向文本与图像场景。Google 官方模型卡还给出了更具体的说明:31B 模型为约 307 亿参数 的 Dense 模型,支持文本和图像输入,不包含音频编码器。
本文实际部署使用的模型为:google/gemma-4-31B-it
其中,后缀 it 表示这是 instruction-tuned版本,也就是指令微调版本,更适合对话、问答、代码生成和工具调用场景的模型版本,而不是纯预训练版本。
1.1模型从哪里下载
本文使用的模型是 Hugging Face 上的官方模型:
google/gemma-4-31B-it
可以直接在 Hugging Face 模型页面下载,或者在有网环境下使用 Hugging Face CLI / Python 工具将整个模型目录拉到本地。该模型页面同时给出了模型卡、文件列表和版本信息,适合作为部署前确认文件完整性的依据。(Hugging Face)
1.2确认模型路径:
先确认本地模型目录确实存在,并且是完整模型根目录。本次实际使用的模型目录为:
plain
/home/ubuntu/Test/Workspace/Models/google/gemma-4-31B-it先执行:
plain
ls -lah /home/ubuntu/Test/Workspace/Models/google/gemma-4-31B-it | head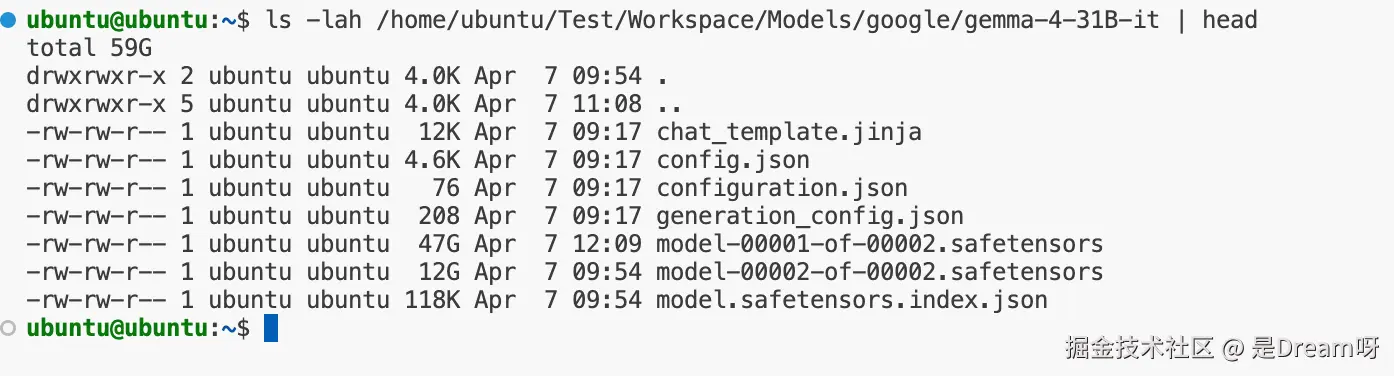
发现目录下存在我们需要的文件:
config.jsontokenizer.json或相关 tokenizer 文件generation_config.jsonmodel.safetensors.index.json- 若干
*.safetensors
这里一定要强调一点: 挂载到容器里的必须是模型根目录本身,不能挂到它的父目录,也不能挂到 Hugging Face 缓存目录的上层。否则 vLLM 很容易在启动时直接报模型目录无效。
二、准备 Gemma 4 专用镜像
本次部署最终没有继续沿用原先用于 Qwen / GLM 的旧镜像,而是改成了 Gemma 4 专用 vLLM 镜像。原因很直接:旧环境即使经过一定升级,也容易在 Gemma 4 上出现以下问题:
gemma4架构识别失败;- Transformers 版本不兼容;
- fallback 到 Transformers backend 后权重映射失败;
- tool calling 与 reasoning 参数支持不完整。
因此,更稳妥的做法是直接使用 Gemma 4 对应的 vLLM 专用环境。
2.1镜像从哪里获取
vLLM 官方在 Gemma 4 的部署说明中已经给出了对应镜像标签:
vllm/vllm-openai:gemma4vllm/vllm-openai:gemma4-cu130
如果服务器本身可以访问 Docker Hub,可以直接拉取对应镜像;如果服务器网络受限,也可以先在本地或其他有网机器上下载镜像,再导出为 tar 包上传到服务器。
2.2已有镜像包时的导入方式
如果你已经将镜像包上传到服务器,例如:
plain
~/vllm-openai-gemma4-x86_64-cu129.tar
则执行:
plain
docker load -i ~/vllm-openai-gemma4-x86_64-cu129.tar
docker images | grep vllm-openai如果导入成功,会看到类似输出:
plain
vllm/vllm-openai gemma4-x86_64-cu129这一步完成后,说明服务端运行 Gemma 4 所需的镜像环境已经准备好,可以进入后续的容器创建与 vLLM 服务启动阶段。
三、创建部署容器
为了方便排查问题,我没有采用一条 docker run 直接起服务的方式,而是采用更稳妥先见容器,再启动,
- 先启动容器;
- 再进入容器手动执行
vllm serve。
这样做的好处是:
- 容器状态和服务状态分离;
- 方便反复修改启动参数;
- 适合排查显存不足、上下文太大、tool calling 参数缺失等问题;
- 个人习惯问题,我习惯分两次启动。
3.1 删除旧容器
先清理之前残留的容器:
plain
docker stop gemma4_31b_gpu1 2>/dev/null || true
docker rm gemma4_31b_gpu1 2>/dev/null || true3.2 创建新容器
这里因为我的A100集群中有两张卡,第一张卡有别的用途,为了保证持久稳定的运行,我们只将模型绑定在第二张 GPU:
plain
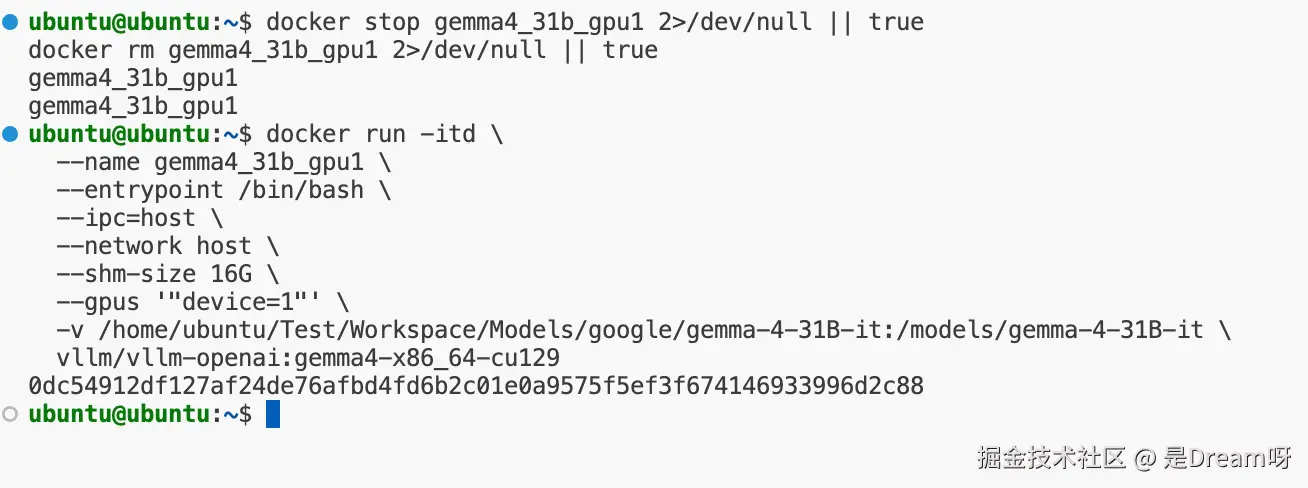
docker run -itd \
--name gemma4_31b_gpu1 \
--entrypoint /bin/bash \
--ipc=host \
--network host \
--shm-size 16G \
--gpus '"device=1"' \
-v /home/ubuntu/Test/Workspace/Models/google/gemma-4-31B-it:/models/gemma-4-31B-it \
vllm/vllm-openai:gemma4-x86_64-cu129这里几个参数需要重点说明:
--entrypoint /bin/bash强制覆盖镜像默认入口,避免镜像自动执行默认命令。--gpus '"device=1"'表示容器只映射宿主机第二张 GPU。这样容器内部看到的cuda:0,实际上就是宿主机的第二张卡。--network host让服务直接使用宿主机网络,后续局域网访问8000端口更方便。--ipc=host和--shm-size 16G避免大模型初始化时因为共享内存不足而出问题。
3.3 检查容器状态
plain
docker ps -a | grep gemma4_31b_gpu1状态正常,说明容器已经起来了:
0dc54912df12 vllm/vllm-openai:gemma4-x86_64-cu129 "/bin/bash" 22 seconds ago Up 21 seconds gemma4_31b_gpu1
四、进入容器并启动 vLLM 服务
4.1 进入容器
plain
docker exec -it gemma4_31b_gpu1 /bin/bash进入后,提示符一般类似:

4.2 启动基础服务
如果只是先验证模型能跑,可以使用基础版启动参数:
plain
vllm serve /models/gemma-4-31B-it \
--served-model-name gemma-4-31b-it \
--tensor-parallel-size 1 \
--max-model-len 8192 \
--gpu-memory-utilization 0.90 \
--host 0.0.0.0 \
--port 8000不过如果你的目标是后续接 OpenCode,那么建议直接一步到位,把 tool calling 和 reasoning 支持也一起开上:
--tool-call-parser gemma4Gemma 4 的工具调用必须使用对应 parser。--reasoning-parser gemma4Gemma 4 的 reasoning / thinking 模式同样需要显式指定 parser。
4.3 启动 OpenCode 可用版本
plain
vllm serve /models/gemma-4-31B-it \
--served-model-name gemma-4-31b-it \
--tensor-parallel-size 1 \
--max-model-len 32288 \
--gpu-memory-utilization 0.90 \
--enable-auto-tool-choice \
--tool-call-parser gemma4 \
--reasoning-parser gemma4 \
--host 0.0.0.0 \
--port 8000这里需要解释几个关键参数:
--served-model-name gemma-4-31b-it指定 API 层对外暴露的模型名,后续 curl、OpenCode 都要用这个名字。--tensor-parallel-size 1本次部署目标是单卡运行,所以固定为 1。--max-model-len 32288这是这次最终成功跑通的较大上下文长度。前期用 8192 可以起服务,但在 OpenCode 等长上下文场景下容易不够。--gpu-memory-utilization 0.90控制 vLLM 可以占用的显存比例。值越高,KV cache 空间越大,但显存压力也更高。--enable-auto-tool-choiceOpenCode build / agent 模式的关键参数,不开的话后面会直接报错。
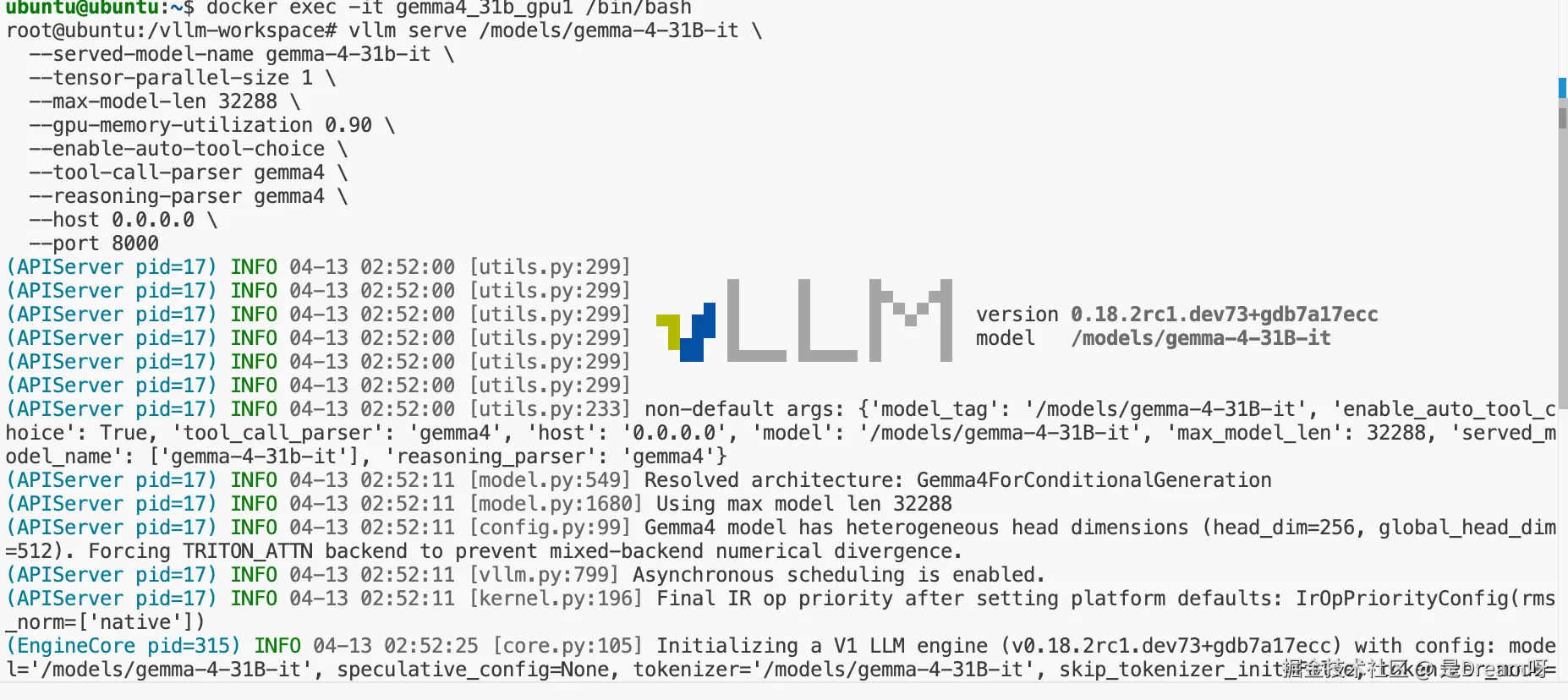
看到上面这个界面,就代表VLLM已经起来了,说明离成功已经不远了,这里我还排查了一些问题供大家参考:
4.4 如果启动失败怎么办
这一步最常见的问题有两个:
问题一:第二张 GPU 上还有残留进程
如果之前的模型或旧服务没关干净,vLLM 会在启动阶段直接报显存不足。
此时应该先在宿主机执行:
plain
nvidia-smi -i 1检查第二张 GPU 是否还有旧进程占用。
问题二:上下文过大导致单卡起不来
如果你直接上大上下文失败,可以先退回更保守参数,例如:
plain
vllm serve /models/gemma-4-31B-it \
--served-model-name gemma-4-31b-it \
--tensor-parallel-size 1 \
--max-model-len 12288 \
--gpu-memory-utilization 0.85 \
--enable-auto-tool-choice \
--tool-call-parser gemma4 \
--reasoning-parser gemma4 \
--host 0.0.0.0 \
--port 8000我自己的建议做法是先从能稳定启动的配置开始,再逐步增加上下文长度,而不是像我一样一开始就把参数拉到最大。但是其实因为我设备毕竟好的问题,我刚开始就是上的大Token也没有出现任何问题😜。
五、验证服务是否成功启动
服务起来后,差不多这个样子就是成功了:
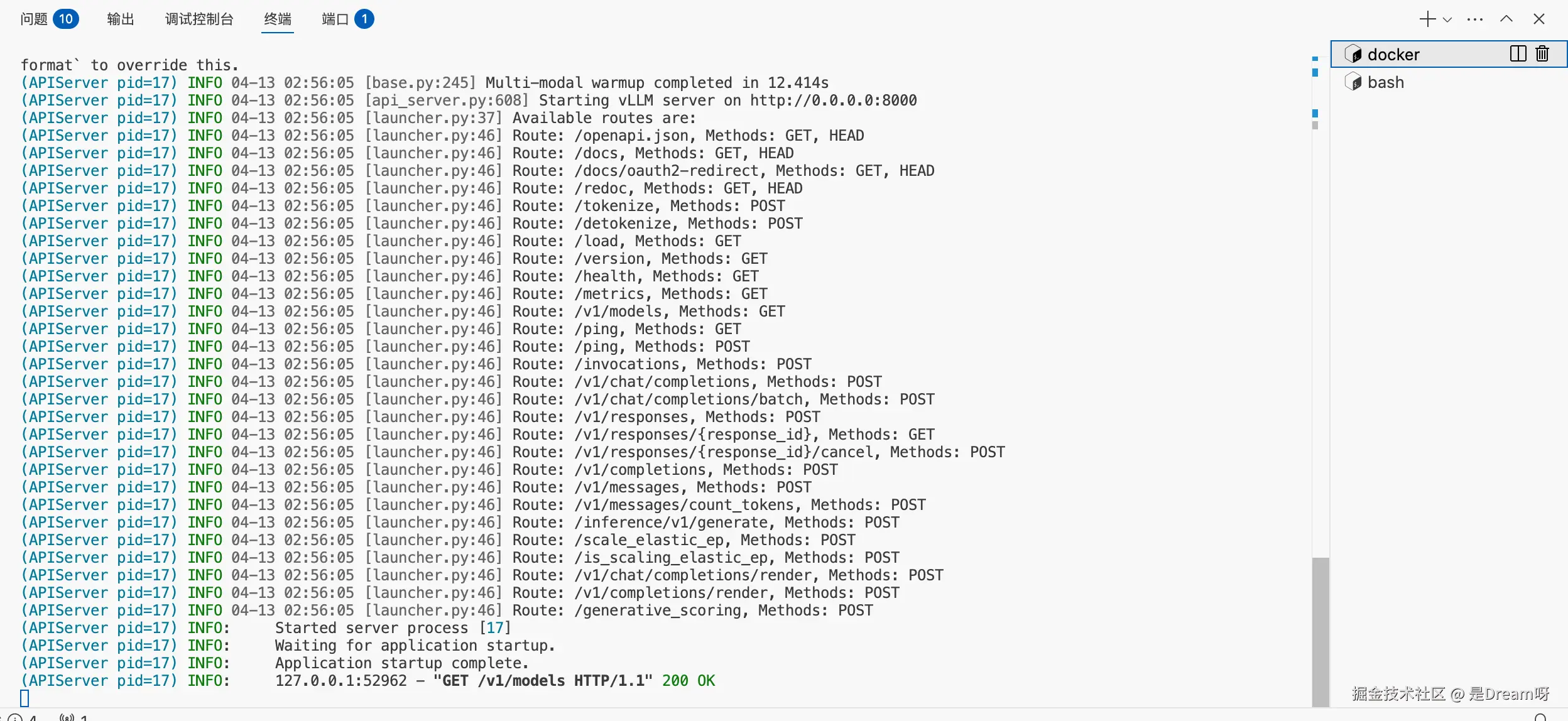
先不要急着接 OpenCode,应该先用最基础的 HTTP 请求验证服务状态:
5.1 查看模型列表
这里需要在服务器上新开一个终端,一定是服务器哈,不是你自己的电脑,在服务器上执行:
plain
curl http://127.0.0.1:8000/v1/models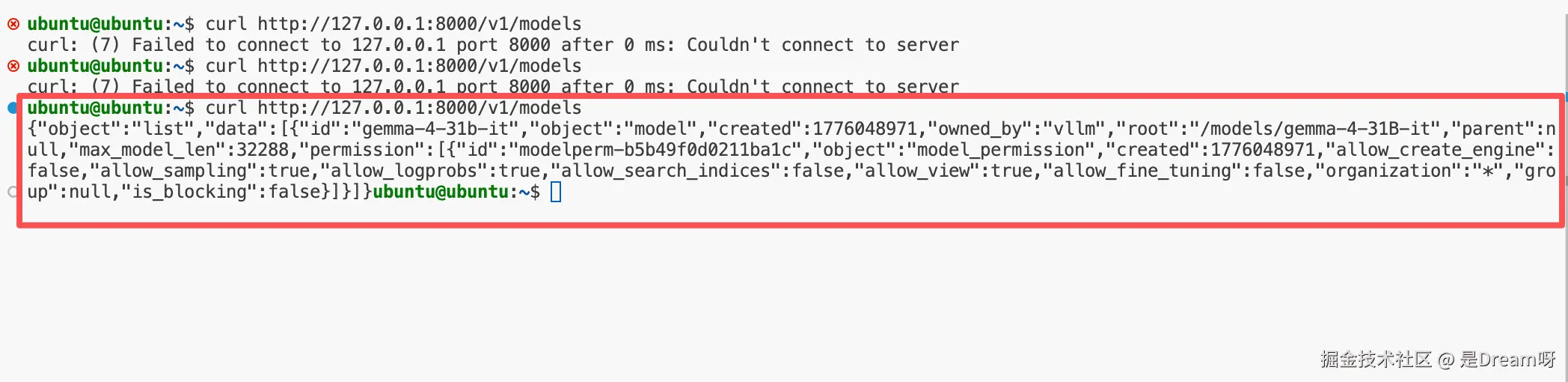
成功会返回包含如下字段的 JSON:
plain
{"object":"list","data":[{"id":"gemma-4-31b-it","object":"model","created":1776048971,"owned_by":"vllm","root":"/models/gemma-4-31B-it","parent":null,"max_model_len":32288,"permission":[{"id":"modelperm-b5b49f0d0211ba1c","object":"model_permission","created":1776048971,"allow_create_engine":false,"allow_sampling":true,"allow_logprobs":true,"allow_search_indices":false,"allow_view":true,"allow_fine_tuning":false,"organization":"*","group":null,"is_blocking":false}]}]}这说明服务已经启动,OpenAI-Compatible API 正常工作。
5.2 测试聊天接口(服务器本机)
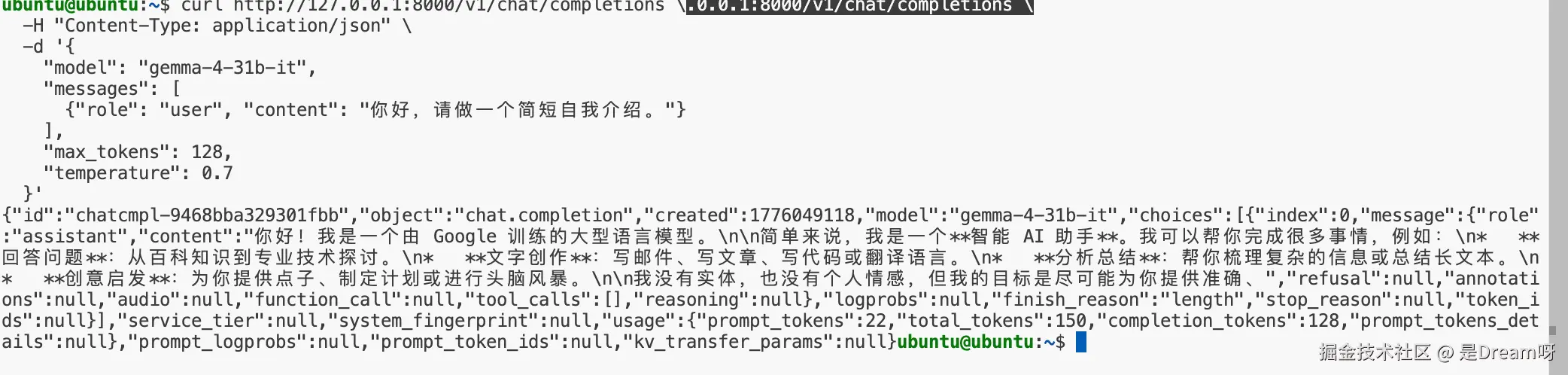
上面的命令接通之后,我们可以简单测试一下其对话能力:
plain
curl http://127.0.0.1:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "gemma-4-31b-it",
"messages": [
{"role": "user", "content": "你好,请做一个简短自我介绍。"}
],
"max_tokens": 128,
"temperature": 0.7
}'
5.3 测试聊天接口(局域网其他机器)
假设你自己所在的服务器局域网地址为:
plain
xxx.168.15.121确保你自己所在的电脑实在局域网上,在你自己的电脑上执行:
plain
curl http://xxx.168.15.121:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "gemma-4-31b-it",
"messages": [
{"role": "user", "content": "你好,请做一个简短自我介绍。"}
],
"max_tokens": 128,
"temperature": 0.7
}'
这里我用的是MAC,其已经可以在我们本地去进行使用了,同时注意这里有个很容易混淆的点:
- 在服务器本机 测试时,地址用
127.0.0.1 - 在局域网其他机器测试时,地址必须用服务器实际 IP
不能把这两种场景混着用。
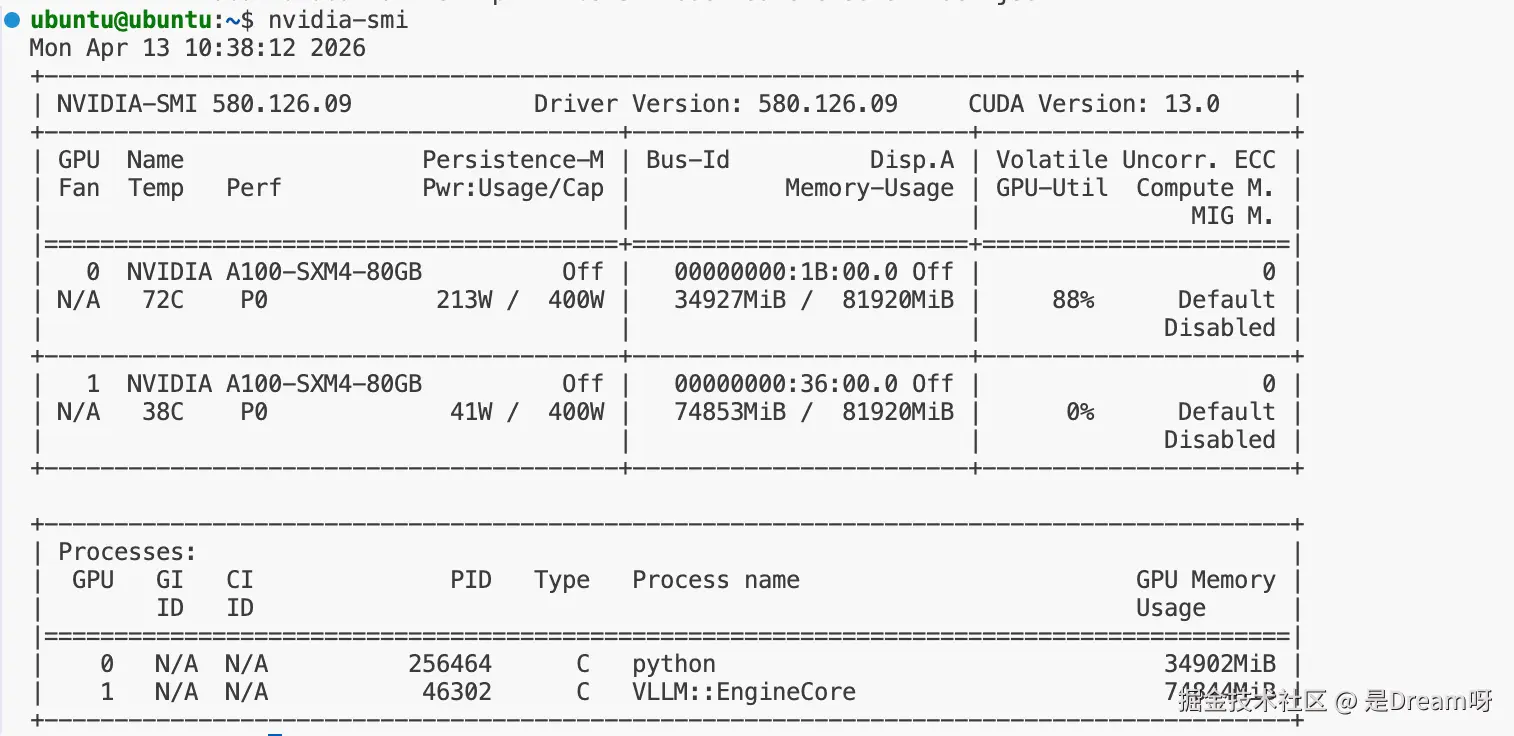
5.4 确认模型运行在第二张 GPU
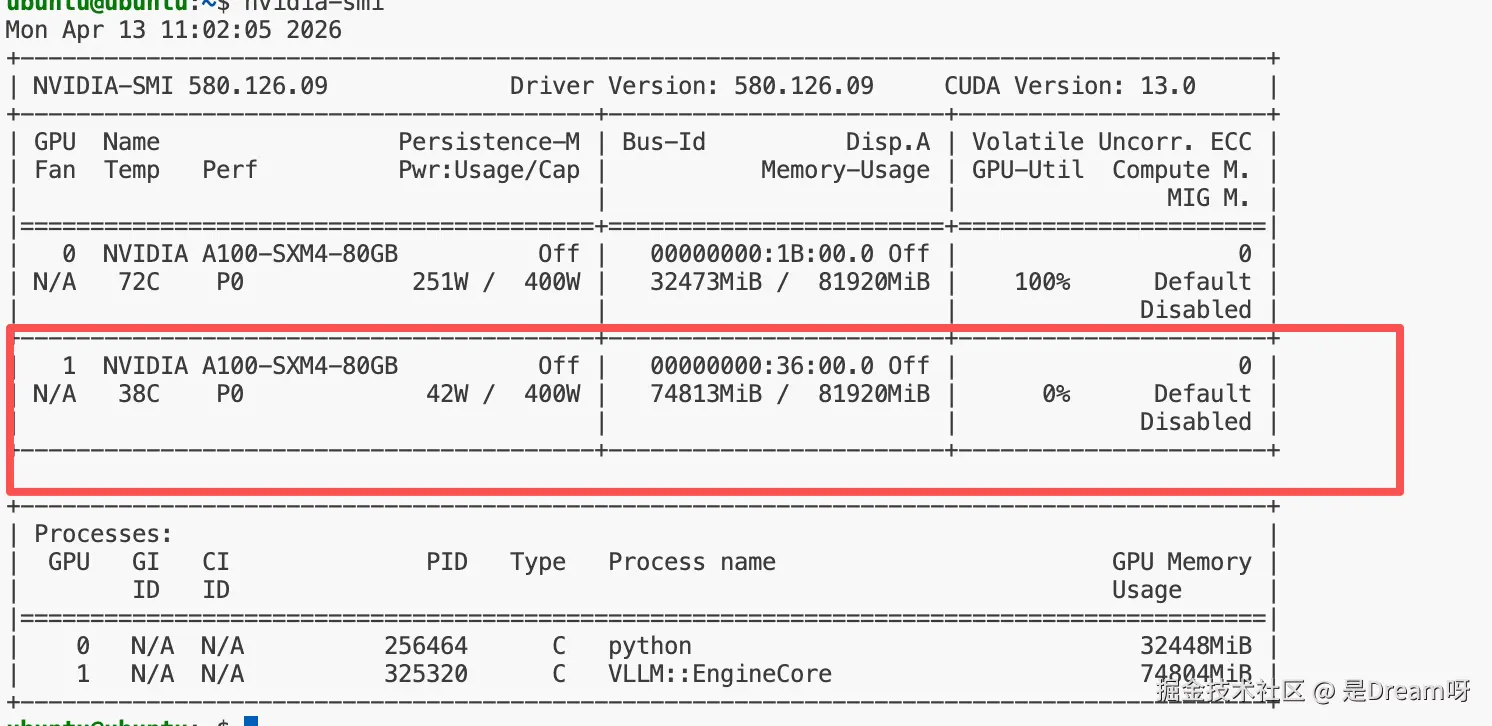
回到宿主机执行:
plain
nvidia-smi -i 1看到 vLLM/python 进程和显存占用,并且GPU利用率是0%,因为当前没有请求:
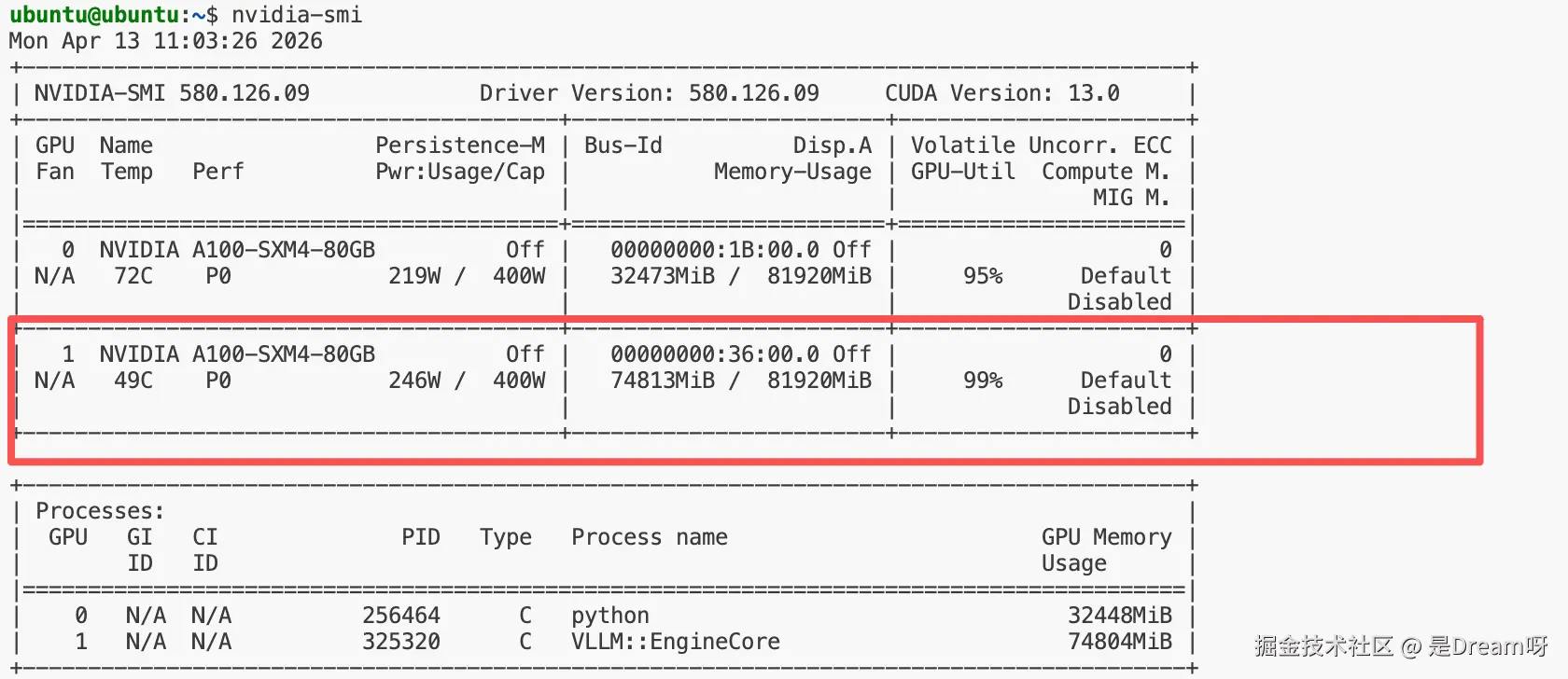
我们直接给他一个请求就会发现GPU利用率拉升,说明模型确实跑在第二张 GPU 上:
六、配置 OpenCode 接入局域网服务
当 vLLM 服务本身已经跑通后,下一步就是把 OpenCode 接进来。想要在OpenCode上使用我们本地部署的模型,首先就是安装opencode,这里的安装方法相信大家直接检索就能检索出来几万条,这里我就不再赘述了,也很简单。
OpenCode 的配置文件默认路径是:
plain
~/.config/opencode/opencode.json在运行 OpenCode 的那台机器上执行:
plain
mkdir -p ~/.config/opencode
cat > ~/.config/opencode/opencode.json <<'EOF'
{
"$schema": "https://opencode.ai/config.json",
"provider": {
"vllm": {
"npm": "@ai-sdk/openai-compatible",
"name": "Gemma 4 31B IT LAN vLLM",
"options": {
"baseURL": "http://192.168.15.121:8000/v1",
"apiKey": "EMPTY"
},
"models": {
"gemma-4-31b-it": {
"name": "Gemma 4 31B IT",
"limit": {
"context": 32288,
"output": 1024
}
}
}
}
},
"model": "vllm/gemma-4-31b-it"
}
EOF这里最重要的是两点:
baseURL必须写服务器局域网 IP,而不是127.0.0.1context要和服务端的--max-model-len对齐
如果你的服务端后来把上下文改成了别的值,这里也要同步修改:
配置完成后,在终端输入opencode就可以启动了,启动界面如上所示
七、Google Gemma-4-31B-it性能测试
当模型已经能够稳定启动,并且可以通过 /v1/chat/completions 正常返回结果后,下一步就不只是能不能用的问题,而是"用起来到底怎么样 "。这一部分主要从两个角度做一个简单测试:一是看模型的基础回答能力 ,二是看模型在当前单卡部署下的实际生成速度。
7.1 回答能力测试
回答能力测试我主要选了两类比较典型的提示词:一类偏代码生成,另一类偏逻辑推理。这样做的考虑很简单,因为这两种任务都比较常见,而且结果是否合格也比较直观,容易判断。
(1)代码生成测试
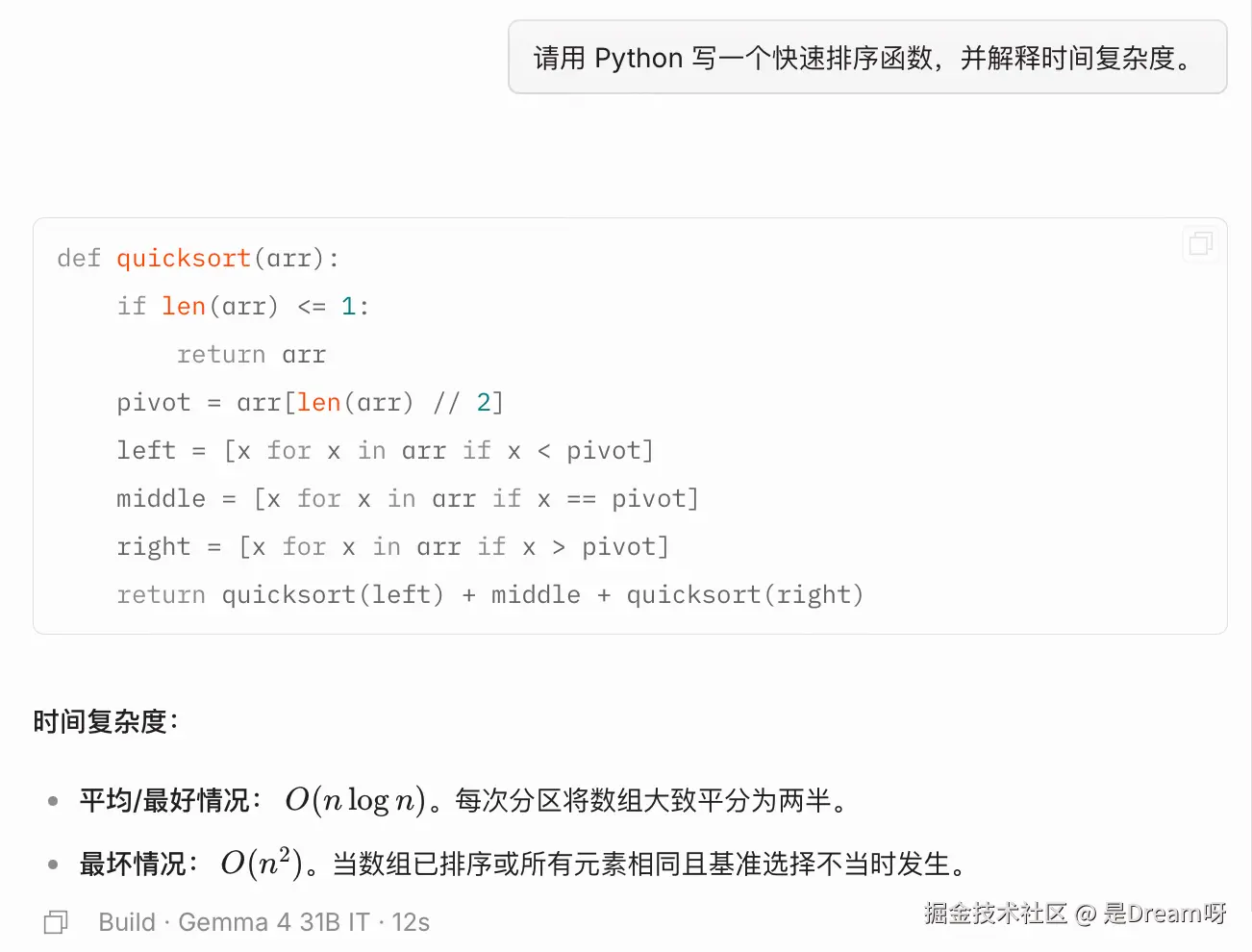
他能够直接给出可运行的 Python 版本快速排序实现,并且进一步说明平均情况、最好情况和最坏情况下的时间复杂度,可以看出较稳定的基础代码生成能力,能够完成常见的编程辅助任务:
(2)逻辑推理测试
然后我又测试了一个更偏逻辑过程的问题,从实际结果来看,模型能够分步骤给出完整运输过程,并且补充说明羊既会被狼吃,又会吃菜,因此必须始终处于被隔离或陪同状态这一核心逻辑,这说明模型在这类结构化推理问题上也是可以的:

7.2 文本生成速度测试
仅仅看回答质量还不够,部署完成后还需要关心一个很实际的问题:生成速度是否可以接受 。 这里我采用的是最简单、也最贴近真实服务使用场景的方式:直接通过 curl 访问 /v1/chat/completions 接口,并在命令前加上 time,统计一次较长输出请求的整体耗时。

从实际测试结果来看,这次请求返回的统计信息中:
prompt_tokens = 38completion_tokens = 1500total_tokens = 1538
同时,终端 time 给出的总耗时约为:
64.90 s
于是可以得到一个比较直接的粗略速度估算:
plain
每秒生成 token 数 ≈ completion_tokens / 总耗时
≈ 1500 / 64.90
≈ 23.1 token/s这个数值不是严格意义上的理论峰值,而是一次真实请求下测得的端到端结果,因此更接近实际使用体验。对于当前这套 单卡 A100 80G + Gemma-4-31B-it + OpenAI-Compatible API 服务化部署 的场景来说,这个速度已经能够满足日常测试、局域网调用以及一般交互式使用需求
结语
回头看这次 google/gemma-4-31B-it 的部署,最花时间的从来不是敲命令本身,而是不断把那些看起来不大的问题一个个补齐,也正是这些细节,决定了一个模型到底只是能启动,还是真正能使用。
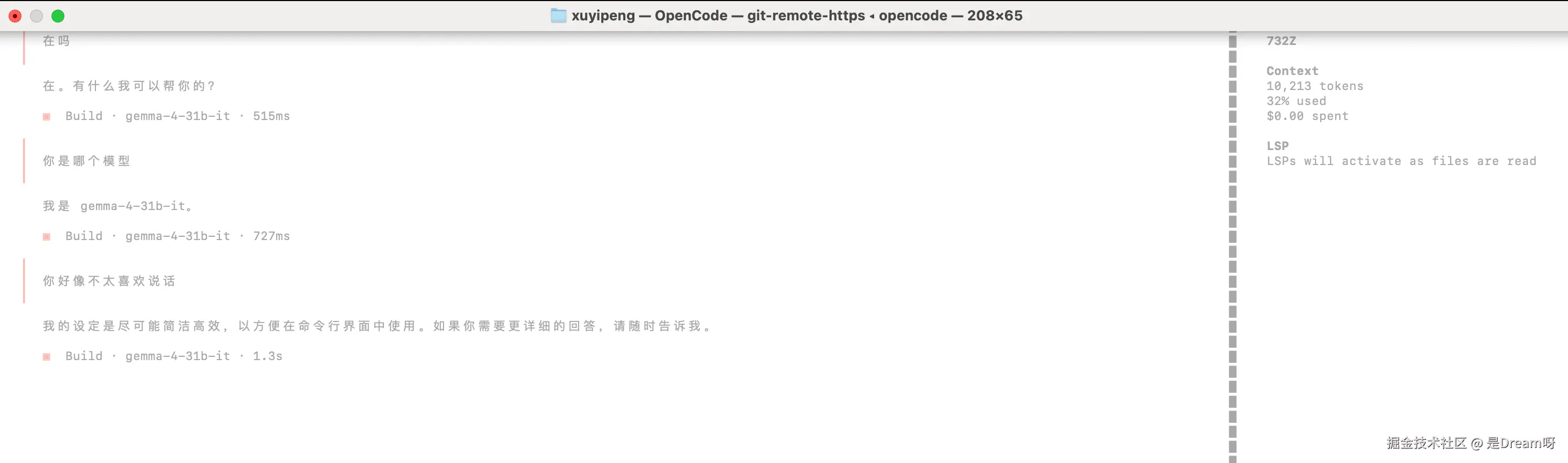
还有一点我个人印象很深。Gemma-4-31B-it 不是那种特别话痨的模型。当我们和AI对话,面对一个简单问题,他也会展开成长篇大论,往往使我们觉得很烦,但 Gemma-4-31B-it 经常会把答案收得更紧,回得更短,但重点又并不缺失。某种意义上,这正是指令微调最有价值的地方:不是让模型更能说,而是让模型更懂任务、更会克制、更知道如何围绕目标作答。