Anthropic的claude订阅计划里,从没有告诉用户他们 Pro / Max 5× / Max 20× 的真实额度到底是多少,不同的订阅只有一个倍率值。
Claude 使用的进度条也只会显示使用百分比,看不到任何精确数字。
这本来也没引起谁的注意。毕竟,大多数人不会去深究一个进度条能告诉你的信息
但有人注意到了。
开发者 shellac 发现:当你打开浏览器的开发者工具,抓取 Claude 后台的 /usage 接口返回值时,会得到一个奇怪的高精度浮点数 ------比如 0.16327272727272726,精确到了小数点后 17 位。
这看似只是一个普通的进度数字。但恰恰是这个小数点后 17 位,撕开了 Claude 订阅隐藏额度的大门。
shellac 沿着这串数字往下挖,愣是从一个17位小数点挖出了官方从未公开的真实数据。

核心发现:不同订阅的真实额度
先上数据,这是作者逆向工程出来的真实额度限制.
| 订阅层级 | 5小时额度(credits) | 每周额度(credits) | 价格 |
|---|---|---|---|
| Pro | 550,000(1×) | 5,000,000(1×) | $20 |
| Max 5× | 3,300,000(6×) | 41,666,700(8.33×) | $100 |
| Max 20× | 11,000,000(20×) | 83,333,300(16.67×) | $200 |
如果把订阅换算成 API 等效价值:
| 订阅层级 | 价格 | 月额度(credits) | Opus-rate tokens | API 等效价值 |
|---|---|---|---|---|
| Pro | $20 | 21.7M | 32.5M in or 6.5M out | $163 (8.1×) |
| Max 5× | $100 | 180.6M | 270.9M in or 54.2M out | $1,354 (13.5×) |
| Max 20× | $200 | 361.1M | 541.7M in or 108.3M out | $2,708 (13.5×) |
从以上数据可以看出
- Max 5× :官方说 5×,实际给的是 6 倍 (5小时)到 8.33 倍(每周),性价比最高
- Max 20× :官方说 20×,但每周只给了 16.67 倍,几乎打了 8 折
用订阅,比直接调用 API 便宜 8~14 倍。
因为作者发现 Claude 的缓存读取在订阅中是免费的,而在 API 中要收取 10% 的输入费用。这意味着:
- 冷缓存 :订阅便宜 13.5 倍
- 热缓存 (反复读缓存的场景):订阅便宜可达 36.7 倍
所以网上有人说 200美金的Max版订阅实际可用到1w美金的api价值调用真不是吹嘘的。
表格中的credits是什么?这只是一个计量单位,为了统一不同模型的使用量的。作者甚至给出了它的计算公式:
credits_used = ceil(input_tokens × f_i + output_tokens × f_o)
| Model | f_i: Input credits/token | f_o: Output credits/token |
|---|---|---|
| Haiku | 2/15 = 0.133... | 10/15 = 2/3 = 0.666... |
| Sonnet | 6/15 = 2/5 = 0.4 | 30/15 = 2 |
| Opus | 10/15 = 2/3 = 0.666... | 50/15 = 10/3 = 3.333... |
我来简单解释一下,不同模型价格不同,为了统一到同一个计量单位,在计算每个模型的输入和输出价格的时候会乘以一个系数,f_i对应每输入token数的系数, f_o对用输出token系数。
表格中的数字看起来没什么规则。不过它的数值精确反映了模型间的价格比例关系:
- 输出价格是输入的5倍
- Opus 价格是 Haiku价格的5倍
- Opus价格是 Sonnet 的 5/3 倍
整体来看作者逆向出来的数据还是比较可信的。不过 shellac 逆向的过程更是让人惊叹。
怎么发现的:一场「浮点数考古」
这部分聊聊技术原理,我尽量让它听得懂。
突破口:那个「未舍入」的浮点数
Claude进度条背后,调用了一个 /usage 的内部接口。这个接口返回的 JSON 里,有一个是 Usage Ratio。
关键来了:这个 Usage 是未经过四舍五入的高精度浮点数。
官方给你看的进度条是「约等于 16%」,但是接口的返回值是这样的:
0.16327272727272726这是什么呢?作者意识到,API 返回的这个浮点数,在业务逻辑上等于
Usage Ratio=总额度已消耗额度
换句话说,这是一个分数,只是被「翻译」成了浮点数。
3.2 浮点数 = 被「压缩」的分数
因为系统的计费/扣减单位(无论是 Token 还是内部 Credit)和总额度一定都是整数,所以这个由于计算而产生的浮点数,本质上是一个有理数(分数)。如果我们能把这个浮点数精准还原成原来的分数,那么分母就会暴露总额度上限的相关信息。
比如 0.16327272727272726,它一定是某个分数的近似值。
如果你能把这个浮点数还原成最简分数,会发生什么?
比如还原后得到 449/2750。这个 2750,意味着真实总额度一定是 2750 的倍数。
分母 = 真实额度上限的可能性。
Stern-Brocot 树:数字界的「二分查找」
问题来了:怎么从浮点数还原最简分数?
这就用到数学里一个优雅的工具------Stern-Brocot 树。
你可以把它理解成:一棵包含所有正有理数 的「数字树」。通过二分搜索,你可以高效地在这棵树的无限的「叶子」中,找到唯一落在浮点数区间 [L, U) 内的那个最简分数。
就像你在一个无限大的数字字典里,用「翻页」的方式快速定位到那一页。
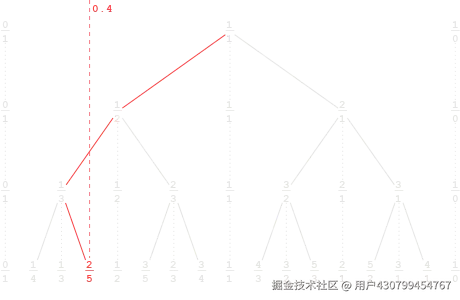
在这个场景里,由于小数精确到第17位,所以精度步长设置为最后一位(~10^-17)
针对浮点数0.16327272727272726,作者测试了 69 步,找到了 449/2750,验证后发现完全吻合。
text
step 00: left=0/1 right=∞ mediant=1 -> mediant ≥ U, move left
step 01: left=0/1 right=1/1 mediant=1/2 -> mediant ≥ U, move left
step 02: left=0/1 right=1/2 mediant=1/3 -> mediant ≥ U, move left
step 03: left=0/1 right=1/3 mediant=1/4 -> mediant ≥ U, move left
step 04: left=0/1 right=1/4 mediant=1/5 -> mediant ≥ U, move left
step 05: left=0/1 right=1/5 mediant=1/6 -> mediant ≥ U, move left
step 06: left=0/1 right=1/6 mediant=1/7 -> mediant < L, move right
step 07: left=1/7 right=1/6 mediant=2/13 -> mediant < L, move right
step 08: left=2/13 right=1/6 mediant=3/19 -> mediant < L, move right
... 57 more steps ...
step 66: left=8/49 right=417/2554 mediant=425/2603 -> mediant ≥ U, move left
step 67: left=8/49 right=425/2603 mediant=433/2652 -> mediant ≥ U, move left
step 68: left=8/49 right=433/2652 mediant=441/2701 -> mediant ≥ U, move left
step 69: left=8/49 right=441/2701 mediant=449/2750 -> HITLCM: 拼图的最后一块
但还没完。
因为分子分母在相除时可能被约分 ,所以一个分数推导出来的分母(比如 2750),可能只是真实总额度的一个因数,而不是总额度本身。
比如: 449/2750 和 11401/75000 均可通分至分母为 3,300,000 的分数
怎么办?
多次采样,取最小公倍数(LCM)。
- 在不同额度消耗阶段,调用 API 获取不同的浮点数
- 把每个浮点数还原成最简分数,得到一系列分母
- 求这些分母的 LCM
一开始,LCM 会不断跳跃变大。但在几次之后,数字就不再变了。
这个最终稳定下来的数字,就是 Claude 真实的额度上限。
最后
claude的订阅模式似乎开了一个不好的头,现在大家的coding plan几乎都不会公布真实限额,导致大家用起来像抓瞎一样。根据shellac 的发现,我们对claude的真实额度有了更清晰的认知。
海外模型对国内的封锁,催生了国内大批量的中转站服务,从这里面也可以看出中转站的盈利模式。他们使用批量MAX 账号套取coding plan额度,然后以api倍率的形式卖给用户,只要控制好倍率比例关系,这个生意就稳赚不赔。比如Max对应13.5倍api价值,那么他们以10倍api价值卖出去还能保留3.5倍api的利润。这还只是没有计算缓存的情况。这也解释了为什么中转站会比官方的直连api要便宜很多以及他们打着1人民币换1美金额度api的底气。
还有一个思考,claude的api真实成本到底是多少?在"商人都是逐利的"假设下,如果大家的订阅都是顶满格使用,再假设即便在这个场景下Anthropic也不会亏损,考虑到MAX订阅等于13.5倍api价值,那么现有的api真实成本应该在当前定价的十三分之一以内。当然这样计算似乎太暴力了,也有种说法是现在的coding plan,那些没有用满额度的用户才是赚钱的地方,这些没有用完的剩余额度会补贴高级订阅的满格消耗额度,同时产生盈余。
这只是一个粗浅的想法,大家觉得呢?