编者按: 你是否也曾在深夜调试大语言模型服务时,对着飙升的延迟和捉襟见肘的 GPU 显存一筹莫展?为什么同样的模型,在线服务商能支撑高并发,而你自建的推理服务却频频超时?当你试图通过增大 batch size 提升吞吐量时,却换来首字延迟的恶性膨胀 ------ 这些问题的根源,往往藏在黑盒般的推理引擎内部。
这篇文章没有停留在理论层面,而是深入 Nano-vLLM ------ 一个由 DeepSeek 贡献者开源的、仅 1200 行代码却完整实现 vLLM 核心机制的推理引擎。从生产者-消费者调度器如何平衡吞吐量与延迟,到 BlockManager 如何通过哈希实现前缀缓存,再到张量并行下 Leader-Worker 的共享内存通信,文章用清晰的工程视角拆解了从提示词到输出词元的完整路径。
作者 | Neutree AI
编译 | 岳扬
01 整体架构设计、调度策略以及从提示词到词元的完整路径
在生产环境中部署大语言模型时,推理引擎是一种关键的基础设施组件。你所使用的每一个 LLM API,无论是 OpenAI、Claude** 还是 DeepSeek,都运行在这样的推理引擎之上。尽管大多数开发者通过高层 API 与 LLM 交互,但深入理解其底层运作机制,提示词如何处理、请求如何被批处理、GPU 资源如何调度,将对系统设计决策产生重要影响。
本系列文章分为两部分,通过 Nano-vLLM1 来深入探讨这些内部机制。这是一个精简版(约 1200 行 Python 代码)但达到生产级标准的推理引擎实现,它提炼了 vLLM2 这一最广泛采用的开源推理引擎的核心思想。
Nano-vLLM 由 DeepSeek 的一位贡献者创建,他的名字出现在了 DeepSeek-V3 和 R1 等模型的技术报告中。尽管代码库极为精简,但它却实现了使 vLLM 具备生产就绪能力的关键特性:前缀缓存(prefix caching)、张量并行(tensor parallelism)、CUDA 图编译(CUDA graph compilation)以及 torch 编译优化(torch compilation optimizations)。基准测试显示,其吞吐量可与完整版的 vLLM 相媲美,甚至略有超越。这使得 Nano-vLLM 成为理解推理引擎设计的理想切入点,让我们无需迷失在支持数十种模型架构和硬件后端的复杂性之中。
在第一部分中,我们将聚焦工程架构:系统的组织方式、请求如何在 pipeline 中流转、以及调度决策如何制定。暂时我们会将实际的模型计算视为一个黑盒 ------ 第二部分将打开这个黑盒,深入探讨注意力机制、KV 缓存内部原理以及计算层面的张量并行技术**。
02 主流程:从 Prompt 到输出
Nano-vLLM 的入口设计得非常直观:一个带有 generate 方法的 LLM 类。你传入一组 prompt 和采样参数,就能拿到生成的文本。但在这个简洁的接口背后,是一套精心设计的 pipeline ------ 它负责把文本转换成 token、高效调度计算任务,并管理 GPU 资源。
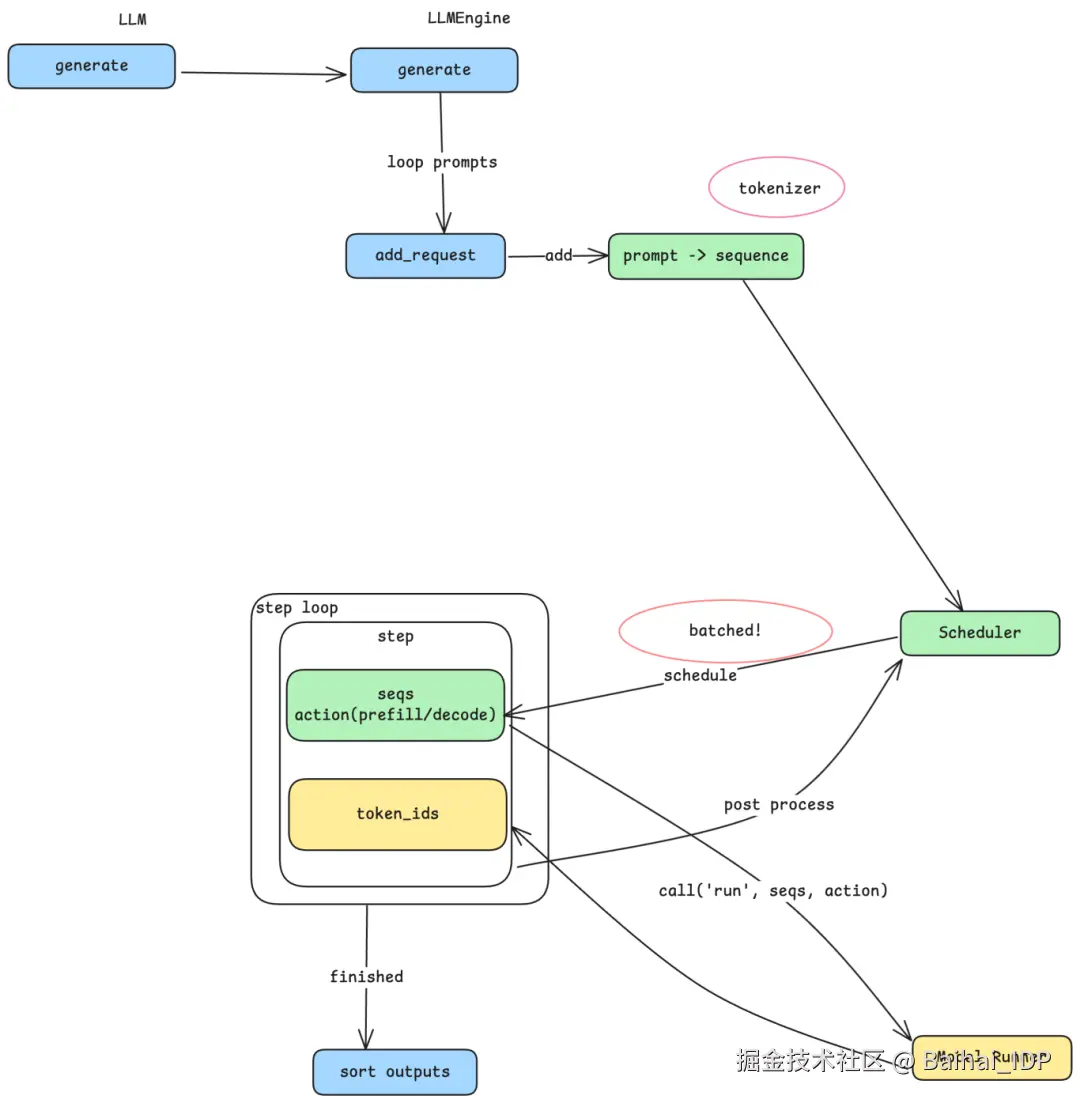
2.1 从 Prompts 到 Sequences(序列)
当 generate 方法被调用时,每个 prompt 字符串会先经过 tokenizer(分词器)------ 这是与特定模型配套的组件,它负责把自然语言切分成一个个 token,这些 token 就是 LLM 处理的基本单位。不同模型家族(Qwen、LLaMA、DeepSeek)使用不同的 tokenizer,这也解释了为什么相同长度的 prompt 在不同模型下可能产生不同数量的 token。tokenizer 会将每个 prompt 转换成一个 sequence(序列):一种内部数据结构,用于表示可变长度的 token ID 数组。这个 sequence 就成为流经系统其余部分的核心工作单元。
2.2 生产者 - 消费者模式
这正是其架构设计的精妙之处。系统并没有立即处理每个 sequence,而是采用了以 Scheduler(调度器)为中心的生产者 - 消费者模式。 add_request 方法充当生产者:它把 prompt 转成 sequence,并放入 Scheduler 的队列中。与此同时,使用一个独立的 step 循环充当消费者,从 Scheduler 中批量取出 sequence 进行处理。这种解耦设计非常重要 ------ 它允许系统累积多个 sequence 并一起处理,性能提升的关键正源于此。
2.3 批处理与吞吐量 - 延迟的权衡
为什么批处理很重要?GPU 进行每一次计算,都存在一定的固定开销 ------ 初始化 CUDA kernel、在 CPU 与 GPU 内存间传输数据、同步结果等。 如果每次只处理一个 sequence,那么每个请求都要单独承担这份开销。而把多个 sequence 打包批处理后,这份开销就能被分摊到多个请求上,从而大幅提升整体吞吐量。
但批处理过程也伴随着一些权衡:当三个 prompt 被打包进同一个 batch 时,每个都必须等其他请求完成后才能返回结果。整个 batch 的耗时取决于最慢的那个 sequence。这意味着:batch 越大,吞吐量越高,但单个请求的延迟可能增加;batch 越小,延迟越低,但吞吐量会下降。这是推理引擎设计中的一个基本矛盾,而你配置的 batch size 参数,正是在直接调控这种权衡。
2.4 Prefill 与 Decode:生成过程的两个阶段
在深入探讨 Scheduler 之前,我们需要先理解一个关键的区别。LLM 推理过程分为两个阶段:
- Prefill:处理输入 prompt。所有输入 token 被一次性处理,用于构建模型的内部状态。这个阶段用户看不到任何输出。
- Decode:生成输出 token。模型逐个产生 token,每个新 token 都依赖之前所有的内容。这正是你看到文本流式输出的阶段。
对单个 sequence 而言,有且仅有一次 prefill 阶段,随后是多个 decode 步骤。Scheduler 必须区分这两个阶段,因为它们的计算特性截然不同 ------ prefill 一次性处理大量 token,而 decode 每步只处理一个 token。
03 Scheduler 内部机制
Scheduler(调度器)的职责是决定处理哪些 sequence(序列),以及按什么顺序处理。它维护着两个队列:
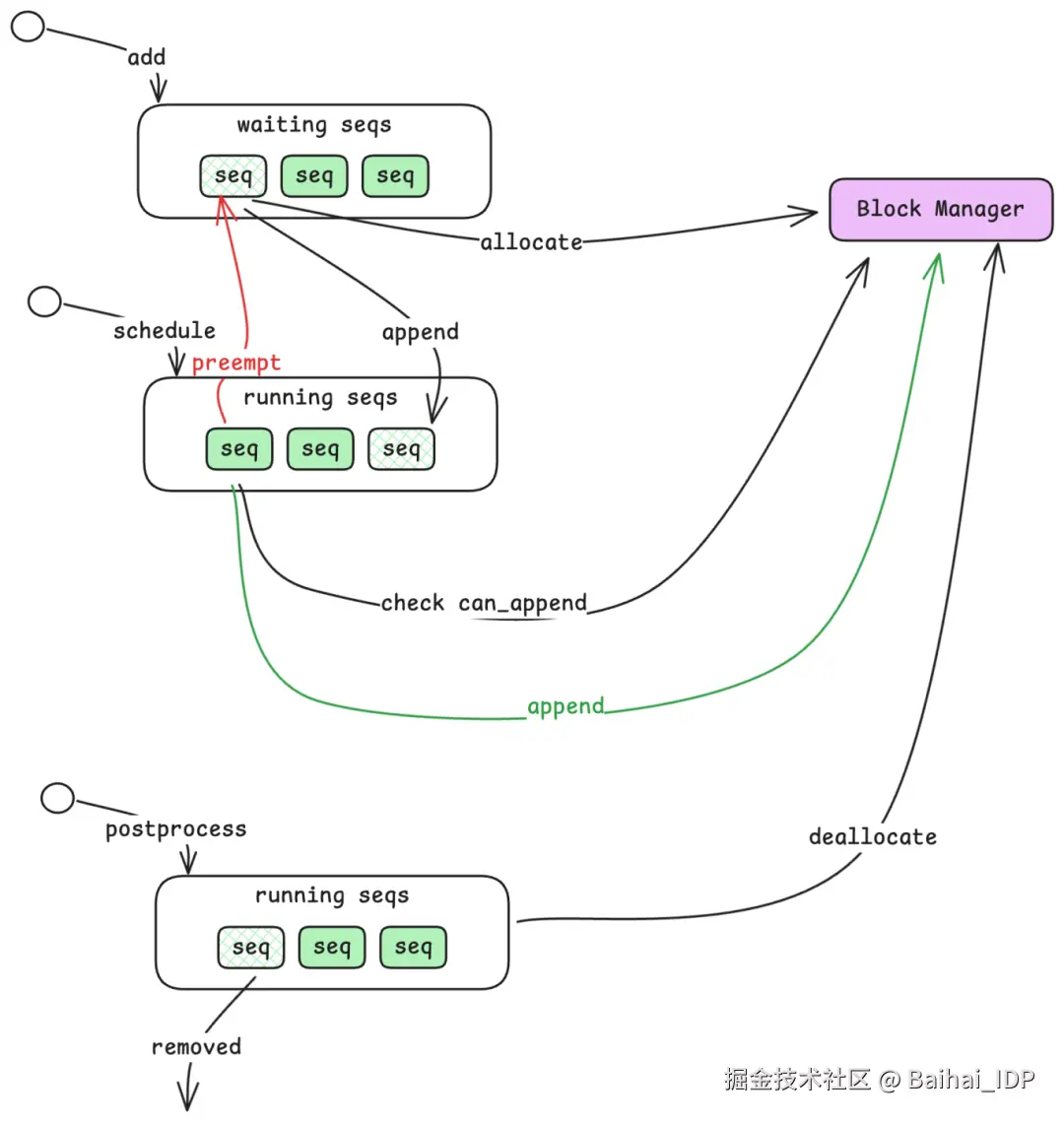
3.1 Waiting 与 Running 队列
- Waiting Queue:已提交但尚未开始处理的 sequence。通过 add_request 新增的 sequence 总是先进入这里。
- Running Queue:正在积极处理中的 sequence ------ 可能处于 prefill 阶段,也可能处于 decode 阶段。
当一个 sequence 进入 Waiting queue(等待队列)后,Scheduler 会与另一个名为 Block Manager 的组件协作,为其分配资源。资源分配完成后,该 sequence 就会转入 Running queue(处理队列)。随后,Scheduler 从 Running queue 中挑选 sequence,为下一步计算做准备,并将它们打包成一个 batch,同时附上操作标识(prefill 或 decode)。
3.2 处理资源耗尽的情况
当 GPU 显存被占满时会发生什么?KV cache(用于存储中间计算结果)的容量是有限的。如果 Running queue 中的某个 sequence 因为没空间存储下一个 token 的缓存而无法继续,Scheduler 就会将其 preempt ------ 把它移回 Waiting queue 的队首。这样既能保证该 sequence 在资源释放后优先恢复执行,又不会阻塞其他 sequence 继续推进。
当某个 sequence 完成生成(遇到 end-of-sequence token(生成结束词元)或达到最大长度),Scheduler 会将其从 Running queue 中移除,并释放其占用的资源,为等待中的 sequence 腾出空间。
04 Block Manager:KV Cache 的控制平面
Block Manager 是 vLLM 内存管理创新的核心所在。要理解它,我们首先需要引入一个新的资源单元:block。
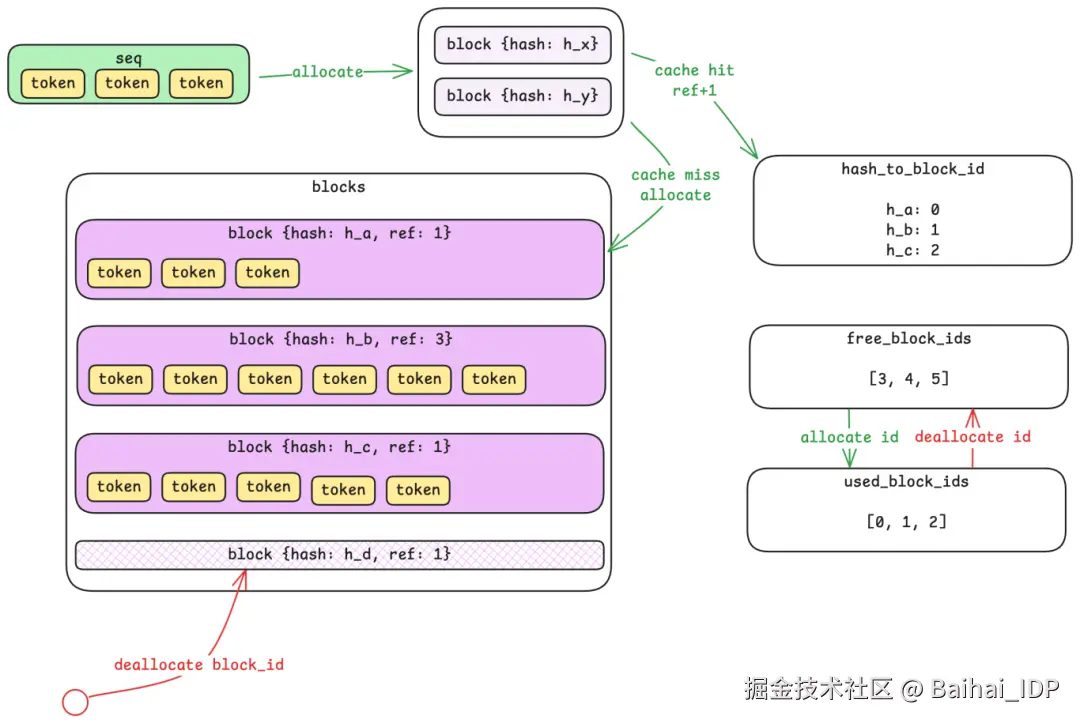
4.1 从 Sequences 到 Blocks
sequence 是一个可变长度的 token 数组 ------ 可能只有 10 个 token,也可能多达 10,000 个。但可变长度的内存分配对 GPU 显存管理来说效率很低。Block Manager 的解决思路是:将 sequence 切分成固定大小的 block(默认每个 block 容纳 256 个 token)。
一个 700 token 的 sequence 会占用三个 block:两个满的 block(各 256 token)和一个部分填充的 block(188 token,剩余 68 个槽位闲置)。需要注意的是,不同 sequence 的 token 绝不会共享同一个 block ------ 但一个较长的 sequence 可以横跨多个 block。
4.2 通过哈希实现 Prefix Caching
巧妙之处就在这里。每个 block 的内容都会被计算哈希值,Block Manager 则维护着一张「哈希值 → block id」的映射表。当新的 sequence 到达时,系统会为其各个 block 计算哈希,并检查缓存中是否已存在相同哈希的 block。
如果发现哈希相同的 block,系统只需增加其引用计数(reference count)即可复用,无需重复计算或存储。这在大量请求共享相同前缀的场景下尤为高效(比如聊天应用中的 system prompt)。前缀内容只需计算一次,后续请求都能直接复用缓存结果。
4.3 控制平面 vs. 数据平面
一个细微但重要的区分点:Block Manager 运行在 CPU 内存中,仅负责追踪元数据 ------ 哪些 block 已被分配、它们的引用计数是多少、哈希映射关系如何。而真正的 KV cache 数据则存储在 GPU 上。 Block Manager 是控制平面,GPU 显存是数据平面。这种分离设计让资源分配决策可以快速完成,无需在实际计算发生前就操作 GPU 内存。
当 block 被释放时,Block Manager 会立即将其标记为空闲,但 GPU 内存并不会被清零 ------ 只有当该 block 被复用时,原有内容才会被直接覆盖。这样就能避免不必要的内存操作。
05 The Model Runner: 执行(Execution)和并行(Parallelism)
Model Runner 负责直接在 GPU 上实际运行模型。当 step 循环从 Scheduler(调度器)获取一批 sequences(序列)时,会将它们连同操作类型(prefill 或 decode)一起传给 Model Runner。
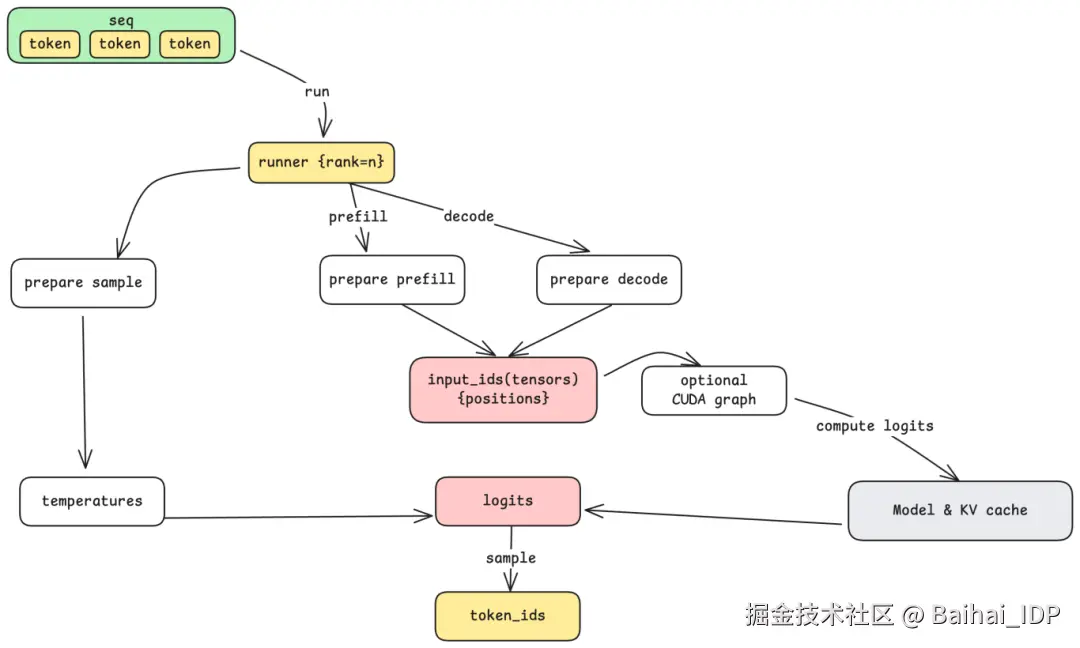
5.1 张量并行通信
当模型因太大而无法放入单张 GPU 时,Nano-vLLM 支持 tensor parallelism (TP,张量并行) ------ 将模型拆分到多张 GPU 上。例如 TP=8 时,八张 GPU 协同工作来运行同一个模型。
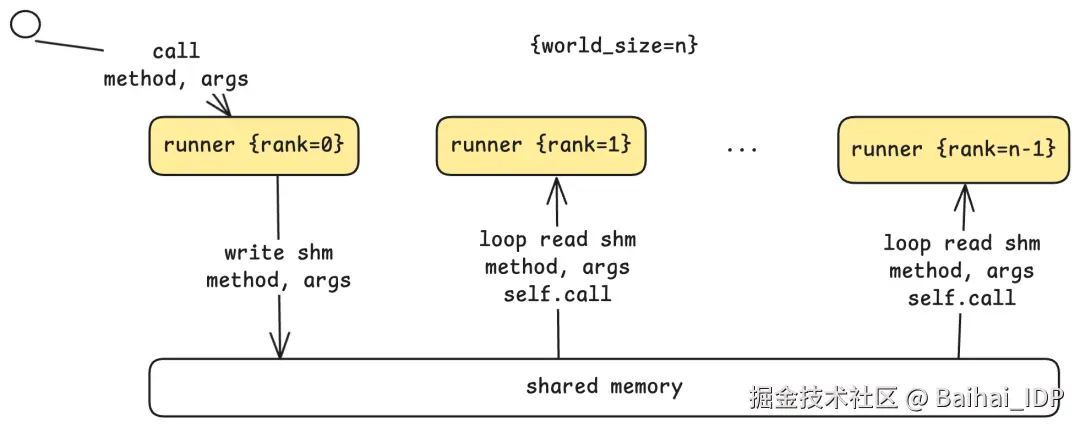
通信架构采用 leader-worker(领导者-工作者)模式:
- Rank 0 (Leader) : 接收来自 step 循环的指令,执行自己的那部分计算,并与 workers 协调。
- Ranks 1 to N-1 (Workers) : 持续轮询共享内存缓冲区(shared memory buffer),获取来自 leader 的指令。
当 leader 收到 run 命令时,它会将方法名和参数写入共享内存。Workers 检测到后,读取参数并在各自的 GPUs 上执行相同操作。每个 worker 都知道自己的 rank,因此能够计算分配给它的那部分工作。这种 shared-memory(共享内存)方法对于单机多 GPU(single-machine multi-GPU)设置非常高效,避免了网络开销。
5.2 计算前的准备
在调用模型之前,Model Runner 会根据操作类型准备输入数据:
- Prefill 准备: 将多个可变长度的 sequences(序列)组合成一个 batch,计算累计序列长度(cumulative sequence lengths),以便进行高效的注意力计算。
- Decode 准备: 将单个 tokens**(每个 sequence 一个)与其 positions(位置信息)和 slot mappings(KV Cache 的槽位映射)一起组合成一个 batch,以便模型能快速找到并读取之前所有 token 的缓存数据,而不需要重新计算。
此准备过程还包括将 CPU 端的词元数据转换为 GPU 张量 ------ 这是数据从 CPU memory 跨越到 GPU memory 的时刻。
5.3 CUDA Graphs: 减少 Kernel 启动开销
对于 decode 步骤(每个 sequence 仅处理一个 token),相对于实际计算,kernel 启动的开销变得不容忽视。CUDA Graphs 通过一次性记录一系列 GPU 操作,然后使用不同的输入进行重放来解决这一问题。Nano-vLLM 为常见的 batch sizes (1, 2, 4, 8, 16, 直至 512) 预先捕获了 CUDA graphs,使 decode 步骤能以最小的启动开销执行。
5.4 Sampling: 从 Logits 到 Tokens
模型输出的不是单个 token ------ 它输出的是 logits,即整个 vocabulary(词表)上的概率分布。最后一步是 sampling:从这个分布(distribution)中选择一个 token。
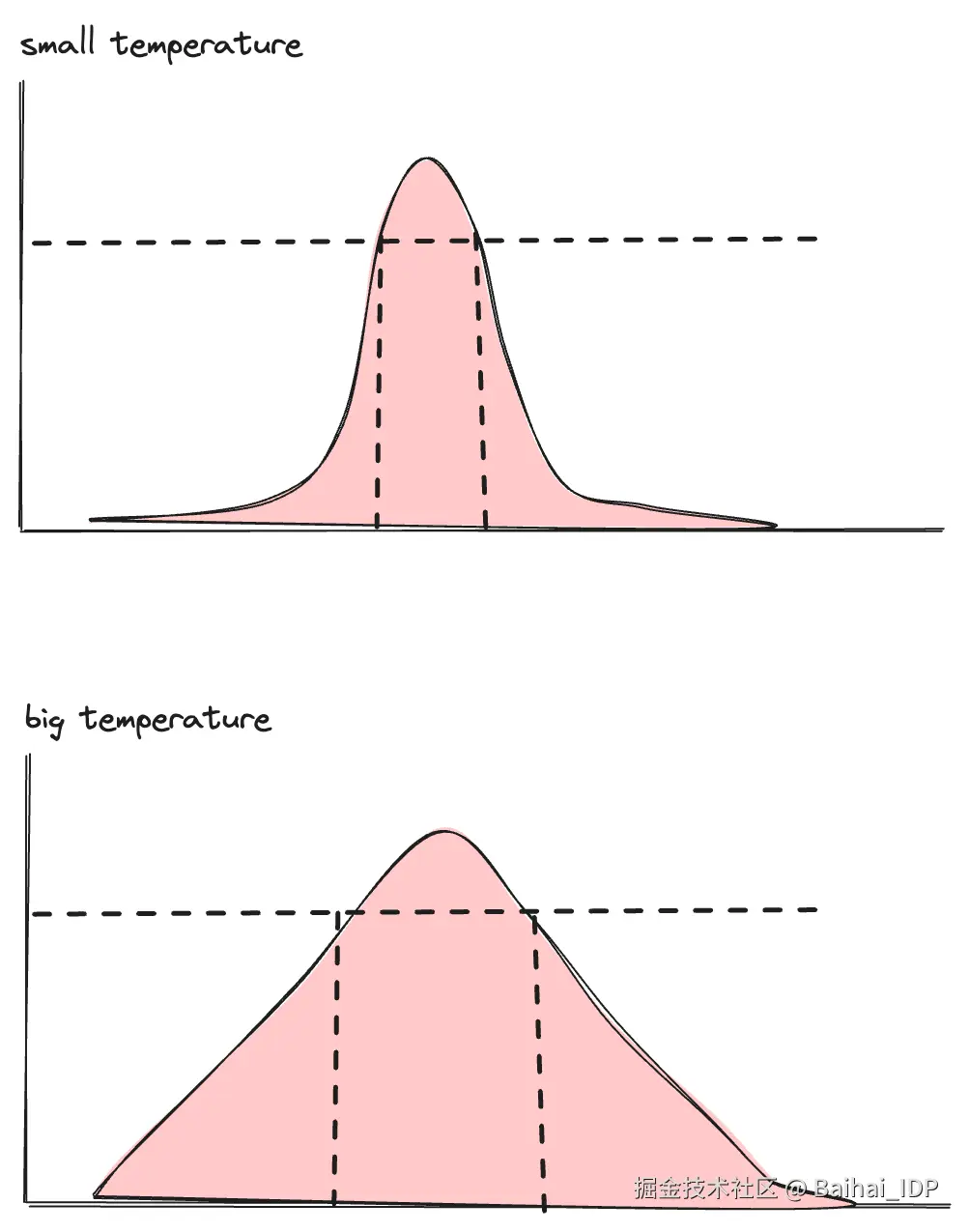
temperature 参数控制这个选择过程。从数学上讲,它调整了概率分布的形状:
- 低 temperature 值(接近 0) : 分布变得尖锐。概率最高的 token 几乎总是被选中,使得输出更具确定性和聚焦性。
- 高 temperature 值: 分布变得平坦。概率较低的 token 有更大的机会被选中,使得输出更加多样化和具有创造性。
这就是 LLM 输出中"随机性"的来源 ------ 也是为什么相同的提示词会产生不同响应的原因。sampling 步骤从有效候选范围中进行选择,引入了 controlled variability(译者注:系统通过 sampling 参数(如 temperature),在"每次都一样的确定性"和"完全随机的混乱"之间,找到那个恰到好处的平衡点。)。
06 What's Next
在第二部分中,我们将打开模型的黑盒。我们将深入探讨:
- 模型如何将 tokens 转换为 hidden states,再转换回 tokens
- 注意力机制的运作原理,以及多头注意力机制为何重要
- KV cache 在 GPU memory 中的物理布局方式
- Dense 架构与 MoE (Mixture of Experts) 架构的对比
- tensor parallelism(张量并行)在 computation level(计算层面)是如何实现的
理解这些内部机制,才能拼出完整图景 ------ 从提示词字符串到生成的文本,全程透明,再无任何隐藏。
END
本期互动内容 🍻
❓Nano-vLLM 用极简代码实现了生产级特性。如果让你设计一个「教学级」推理引擎,你会优先保留哪三个核心模块?为什么?
文中链接
本文经原作者授权,由 Baihai IDP 编译。如需转载译文,请联系获取授权。
原文链接: