作者:来自 Elastic Ishleen Kaur

了解并探索 Elastic 中的 OpenTelemetry 内容包如何为你的遥测数据提供即时仪表板、告警和 SLO。
如果你在过去几年一直关注可观测性领域,你会看到 OpenTelemetry 已经从 "有前景的标准" 变成了收集指标、日志和追踪数据的默认选择。Elastic 很早就参与了这一过程 ------ 这也是我们构建 Elastic Distributions of OpenTelemetry( EDOT )的原因:一个经过加固、可用于生产环境的 OTel 组件套件,包括 EDOT Collector 和各语言 SDK,专为基础设施与应用监控进行优化,避免了传统部署中的复杂配置负担。
EDOT 现已正式可用( GA )。Collector、SDK 以及整个技术栈------均已生产就绪,企业级支持,没有任何附加条件。
但问题在于:将数据接入 Elastic 只是完成了一半工作。实际更困难的另一半,是接入之后的事情。仍然需要有人构建仪表板、编写告警规则,并确定哪些 SLO 值值得追踪------在这些变得有用之前。
OpenTelemetry 内容包正是为了解决这一鸿沟而设计的。
什么是 OpenTelemetry 内容包?
Elastic 传统的基于 Beats 的集成通常会将数据采集和可视化打包在一起 ------ 当你启用某个功能时,就会立即获得精心设计的仪表板和告警。随着 Elastic 向 OpenTelemetry 优先的架构演进,这一理念被延续下来,但模型变得更加清晰。
OpenTelemetry 内容包专注于某一特定服务的可观测性资产。不再包含任何数据采集配置,因为在 OTel 体系中,这部分由 Collector 负责。每个包包含:
- 仪表板 ------ 为所监控服务定制的预构建 Kibana 可视化
- 告警规则 ------ 预先配置好的告警规则,在关键阈值触发时提醒团队,从而减少平均检测时间( MTTD )和平均修复时间( MTTR )
- SLO 模板 ------ 可直接使用的服务级别目标定义,用于跟踪可靠性目标、错误预算和消耗速率
随着内容包模型的持续演进,未来的版本还将支持更多类型的资产。
如何工作?
核心理念很简单:一旦数据进入 Elastic,对应的仪表板、告警规则和 SLO 模板就会立即可用。内容包会根据传入的数据自动激活,而不依赖这些数据是如何被采集的。
这个系统最强大的特性之一是自动安装。当 Elastic 检测到某个特定服务的数据开始进入 Elasticsearch 时,相应的内容包会自动安装 ------ 无需任何手动步骤,也无需在集成目录中查找。当你打开 Kibana 时,你的仪表板已经在那里等你,告警规则也已准备好启用,SLO 模板也已预先加载。
为了让数据真正流动起来,我们需要配置 Collector ------ 一个 YAML 文件,用于定义遥测管道的构建模块:
- Receivers ------ 定义要采集什么数据以及从哪里采集。每个服务都有自己的 receiver(例如 MySQL receiver 会直接从数据库抓取指标)。
- Exporters ------ 定义采集到的数据发送到哪里。在这里,我们使用 Elasticsearch exporter,将遥测数据以 OpenTelemetry 原生格式直接发送到 Elasticsearch。
- Pipelines ------ 将 receivers 和 exporters 连接起来,定义数据在 Collector 中的流动路径。
完成这些配置并启动 Collector 后,数据就会开始流入 Elasticsearch ------ 然后由内容包接管后续工作。
数据来源
OpenTelemetry 数据可以通过以下方式进入 Elastic:
- EDOT Collector ------ Elastic 分发版 OpenTelemetry Collector,可嵌入 Elastic Agent 或与其配合使用
- 上游 OTel Collector ------ 标准的社区版 OpenTelemetry Collector( Contrib 或自定义构建版本)
- EDOT Cloud Forwarder( ECF )------ 一种无服务器 OpenTelemetry Collector,可从 AWS、GCP 和 Azure 收集遥测数据(如 VPC Flow Logs、CloudTrail、CloudWatch 等),并直接转发到 Elastic Observability,无需管理基础设施
内容包不关心数据如何到达 ------ 只关心数据是否已经存在。
实践示例:MySQL 监控
假设有一个团队在运行 MySQL,他们希望跟踪查询吞吐量、连接数、缓冲池利用率以及慢查询速率------并在小问题演变成凌晨 2 点事故之前收到告警。传统做法意味着需要花费大量时间构建仪表板、编写自定义告警查询,并且很大程度依赖经验去判断哪些指标真正重要。
使用 MySQL OpenTelemetry 资产包,这些工作已经提前完成。下面来看整体是如何组合在一起的。
步骤 1:获取数据
数据管道由一个 Collector 配置驱动,该配置定义了 receivers(从哪里抓取数据)、processors(如何增强或转换数据)以及 exporters(将数据发送到哪里 ------ 在这里是 Elasticsearch)。
无论你使用 EDOT Collector 还是 Upstream OTel Collector,基础配置结构都是一致的。下面的配置为主实例和副本实例分别使用了不同的 receiver,因为复制指标仅在副本上可用。请将其中的占位符替换为你的实际端点、凭据以及 Elasticsearch 配置信息。
yaml
`
1. receivers:
2. mysql/primary:
3. endpoint: <MYSQL_PRIMARY_ENDPOINT>
4. username: <MYSQL_USER>
5. password: <MYSQL_PASSWORD>
6. collection_interval: 10s
7. statement_events:
8. digest_text_limit: 120
9. limit: 250
10. query_sample_collection:
11. max_rows_per_query: 100
12. events:
13. db.server.query_sample:
14. enabled: true
15. db.server.top_query:
16. enabled: true
17. metrics:
18. mysql.client.network.io:
19. enabled: true
20. mysql.connection.errors:
21. enabled: true
22. mysql.max_used_connections:
23. enabled: true
24. mysql.query.client.count:
25. enabled: true
26. mysql.query.count:
27. enabled: true
28. mysql.query.slow.count:
29. enabled: true
30. mysql.table.rows:
31. enabled: true
32. mysql.table.size:
33. enabled: true
35. processors:
36. resourcedetection:
37. detectors: [system, env]
39. exporters:
40. elasticsearch/otel:
41. endpoint: <ES_ENDPOINT>
42. api_key: <ES_API_KEY>
43. mapping:
44. mode: otel
46. service:
47. pipelines:
48. metrics:
49. receivers: [mysql/primary, mysql/replica]
50. processors: [resourcedetection]
51. exporters: [elasticsearch/otel]
`AI写代码收起代码块MySQL receiver 会按照配置的时间间隔从数据库中抓取指标和事件,并将其作为 OpenTelemetry metrics 输出。这些数据会流经 pipeline 并进入 Elasticsearch,随后即可用于可视化。
步骤 2:打开 Kibana ------ 一切已就绪
仪表板
一旦 MySQL 的指标和事件进入 Elasticsearch,MySQL OpenTelemetry 资产包就会在后台自动安装。当你进入 Kibana 时,仪表板已经被填充好并等待使用。
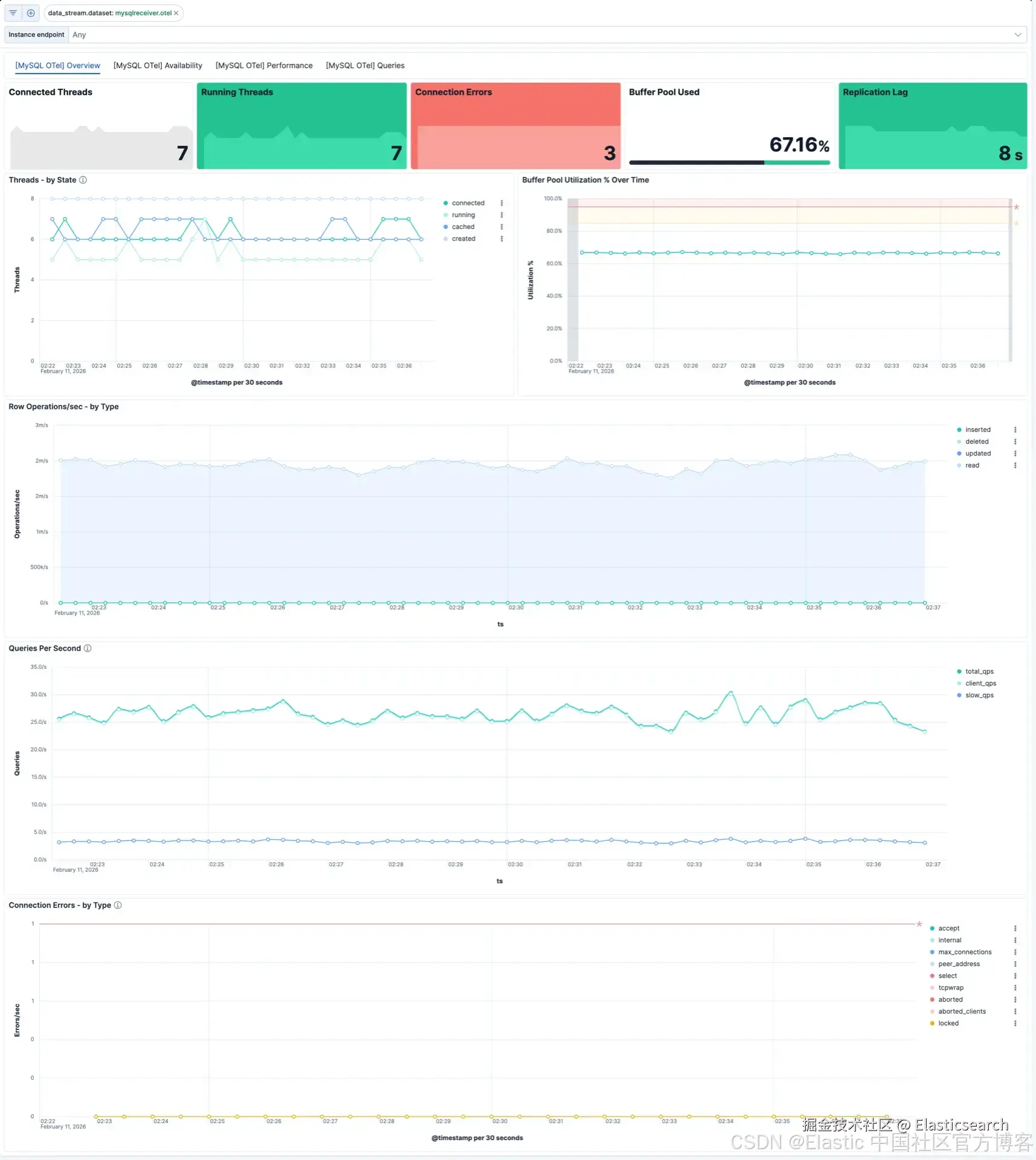
用户可以立即获得以下可观测性视图:
- 活跃连接数与最大连接数
- 查询吞吐量------每秒执行的语句数
- InnoDB 缓冲池命中率与内存使用情况
- 慢查询数量与趋势
- 表锁等待与资源争用情况
- 随时间变化的发送与接收字节数
- 复制延迟(用于主从架构)
无需手动字段映射,无需从零构建仪表板。只需数据进入,即可获得洞察。
下面是 Kibana 中 MySQL OpenTelemetry 仪表板的截图,展示了当数据开始流动时即可自动使用的开箱即用可视化内容。
概览仪表板
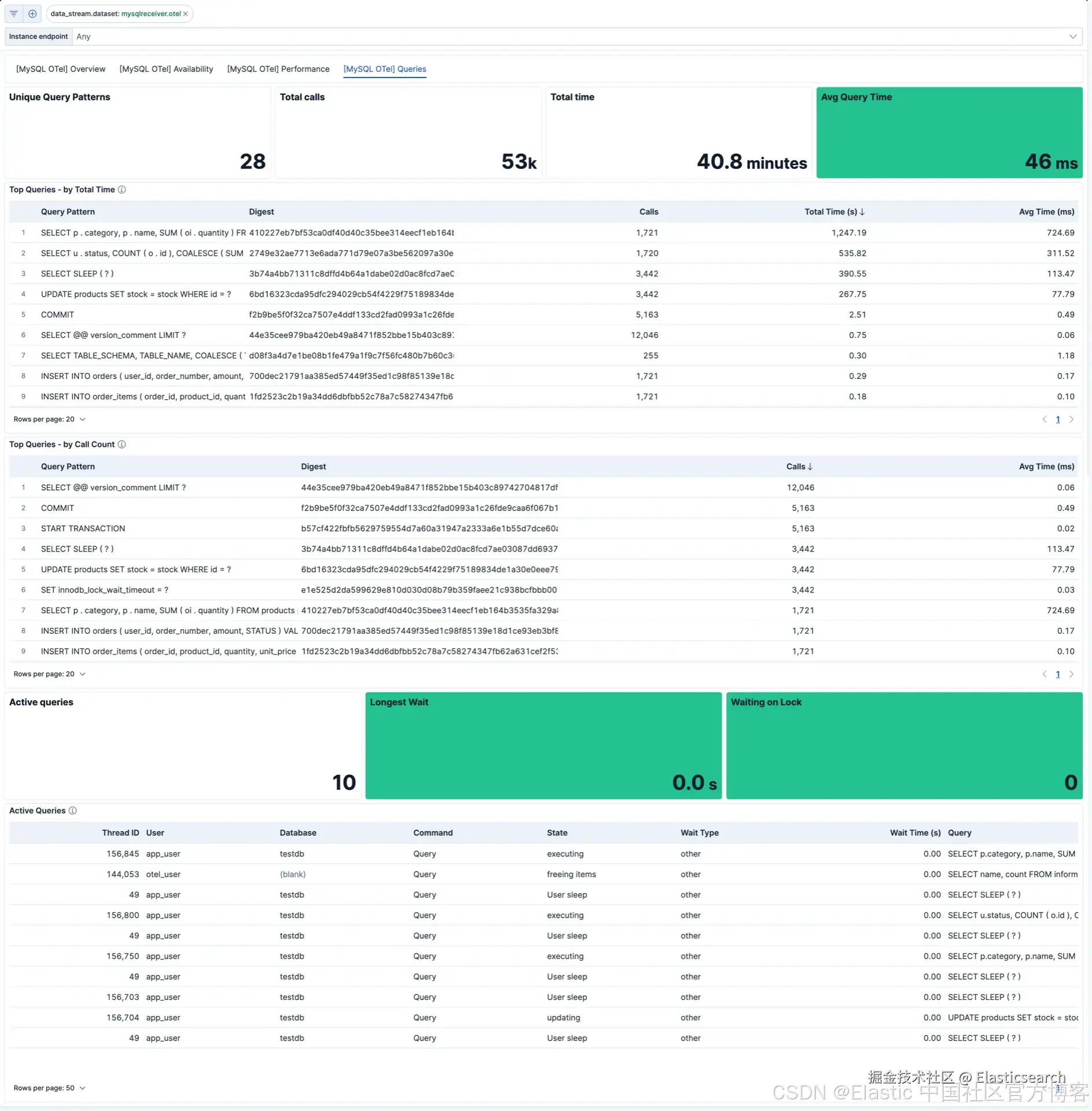
查询仪表板
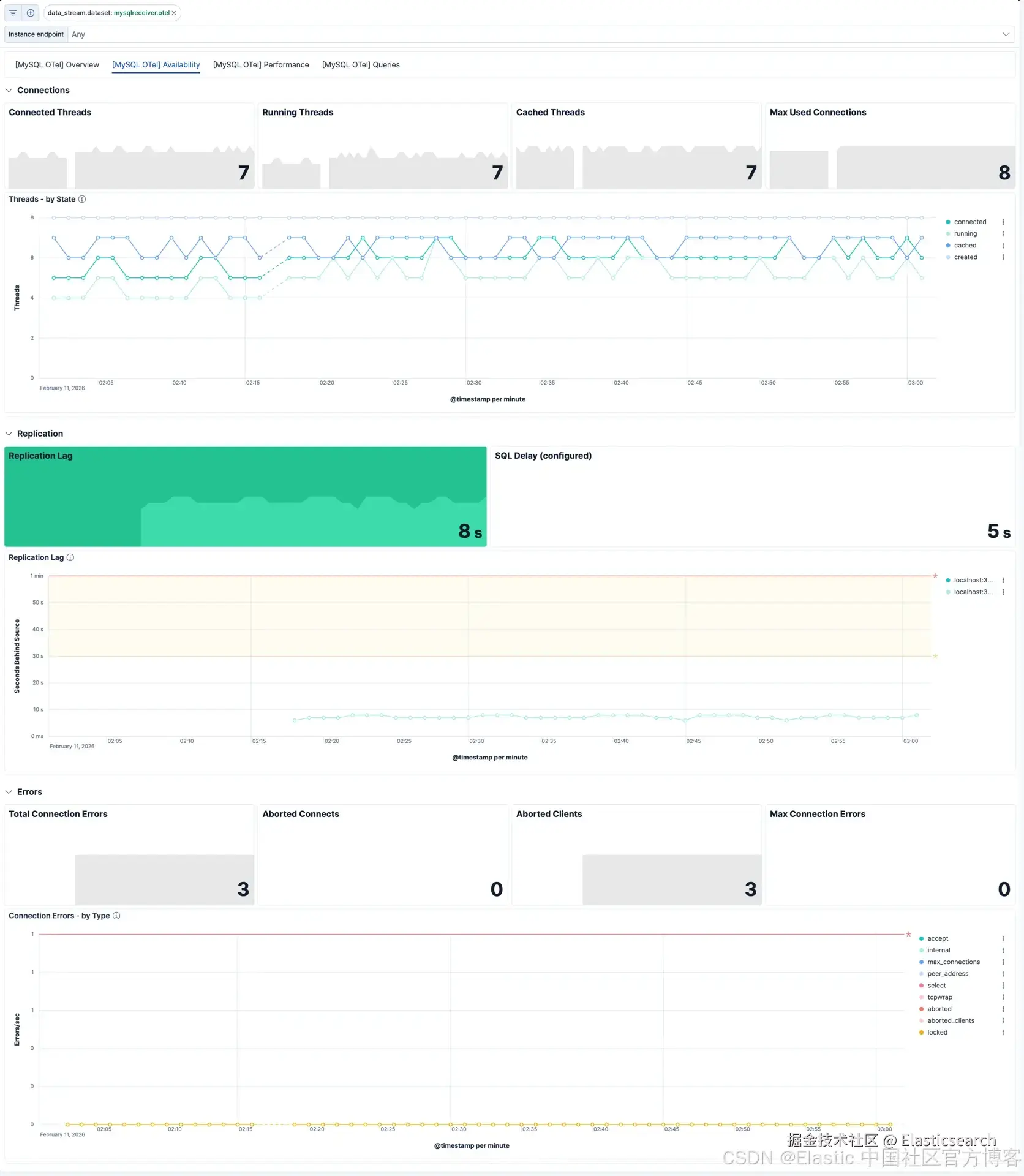
可用性仪表板
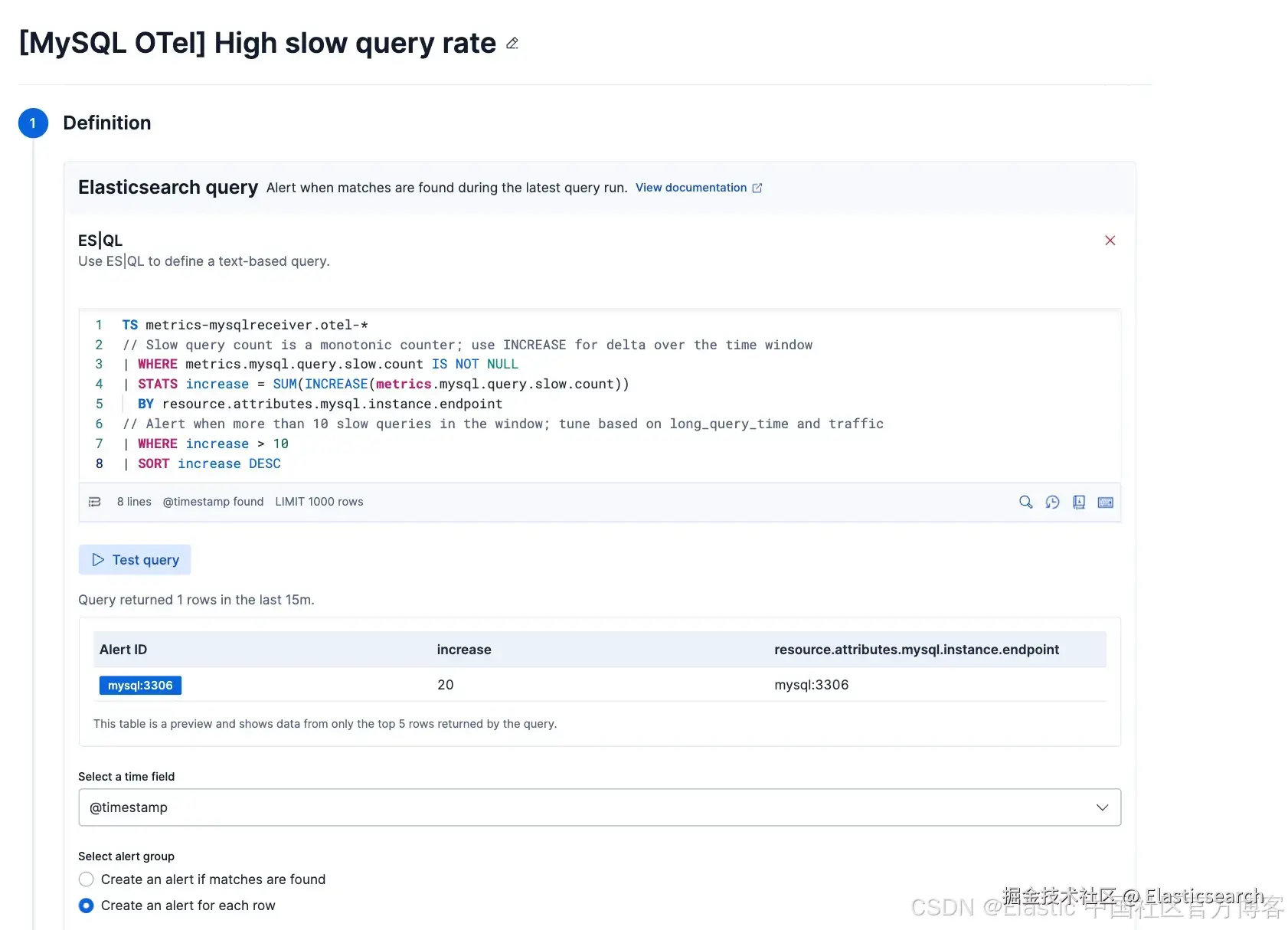
告警规则,已准备启用
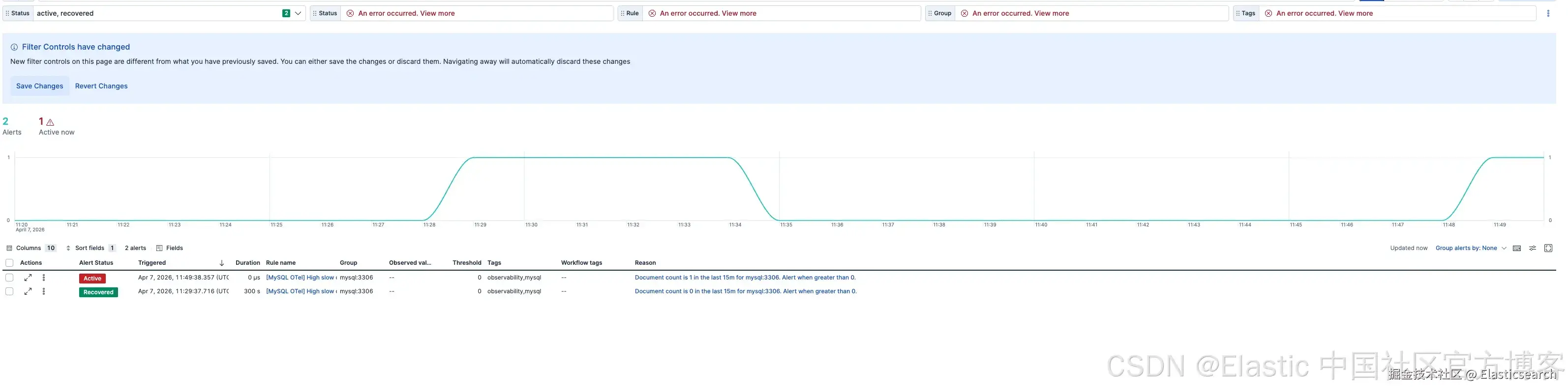
该内容包包含六条预构建告警规则 ------ 涵盖高连接错误率、慢查询激增、线程饱和、复制延迟、缓冲池脏页比例(buffer pool dirty page ratio)以及行锁竞争 ------ 每一条都带有推荐阈值和严重级别。这些规则在安装后即可使用,并且可以在 Kibana 中直接启用、调整和扩展,无需编写任何自定义查询。下面是其中一条告警的示例。
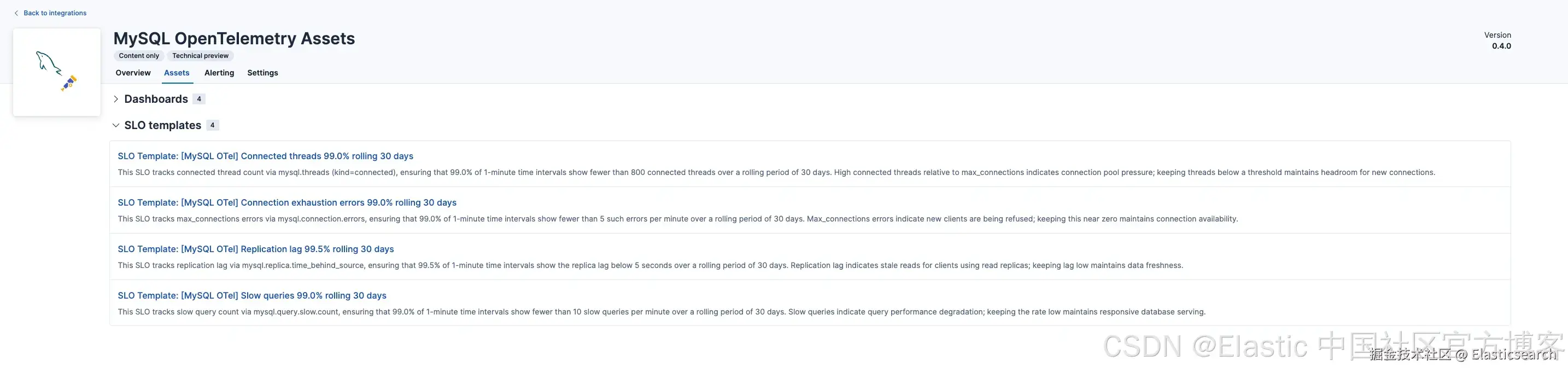
SLO 模板,已预加载
开箱即用包含四个 SLO 模板,用于跟踪复制延迟、连接耗尽错误、慢查询速率以及已连接线程数------每个模板都预先配置了目标值和 30 天滚动窗口。团队可以直接采用这些模板,也可以调整阈值以匹配自身的可靠性需求。
当前可用内容
MySQL OpenTelemetry 资产包只是 Elastic 已构建的不断增长的 OpenTelemetry 内容包库中的一个示例。内容包已覆盖多种服务------同时我们也开始将其扩展到云端,初步支持云服务提供商集成,通过 EDOT Cloud Forwarder( ECF )将 AWS、GCP 和 Azure 的遥测数据引入 Elastic,并提供现成的仪表板。
这一模式在所有内容包中都是一致的------数据进入后,一个完整的可观测性套件(仪表板、告警规则、SLO 模板)会立即可用------无论你是在监控自建数据库,还是来自你首选云服务提供商的云原生服务。
未来的发展方向
值得关注的下一步是 OTel 集成包,它将允许你直接从 Kibana UI 推送 Collector 配置------让整个设置体验变为点选式操作,从数据采集到可视化全流程完成,无需编辑 YAML。
开始使用
准备好尝试了吗?从 EDOT Collector 文档开始,并在 Kibana 的 Integrations 页面中探索不断扩展的 OpenTelemetry 内容包库。