前言:企业级数据融合的新范式
随着企业数字化转型的深入,多源异构数据管理已成为技术架构的重要挑战。如何将GIS地理信息、时序监控数据、文档存储、缓存系统等多样化数据源进行有效整合,是很多技术团队面临的实际问题。本文将从技术实现的角度,分享一种基于统一数据库平台的多源数据融合方案,并以实际代码示例说明关键技术的实现方式。"
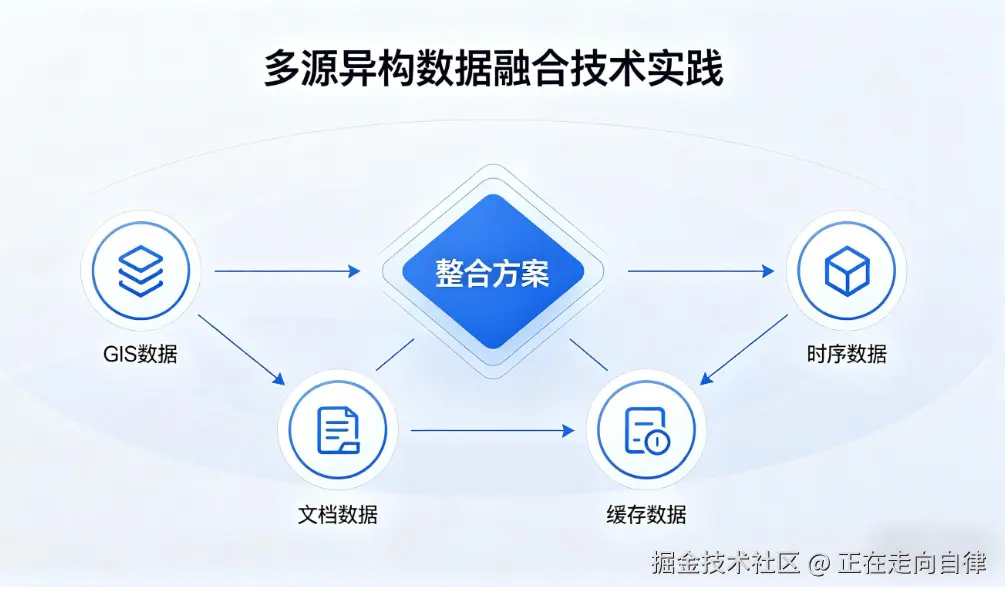
在当前的数据库技术生态中,多源异构数据融合是重要的技术方向。本文将以金仓KES为例,探讨实现GIS、时序、文档等多样化数据整合的技术方案。
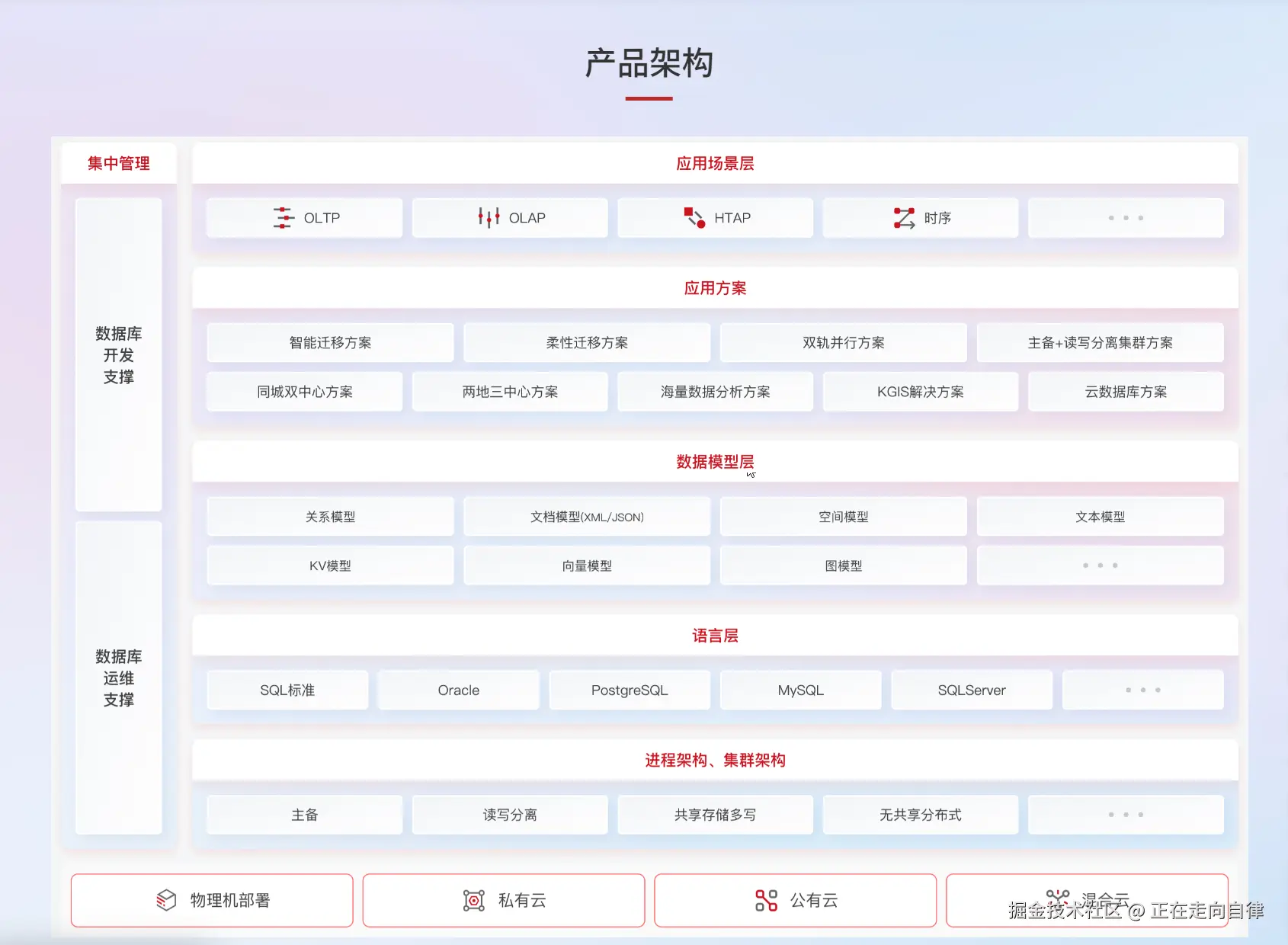
一、KES多源数据迁移技术架构
1.1 迁移引擎的模块化设计
在多源数据迁移的技术实现中,模块化架构设计是关键。一个完整的迁移系统通常包含连接适配器、模式转换器、数据迁移器、对象迁移器等核心组件。这种设计不仅保证了系统的可扩展性,也使得针对不同源数据库的优化成为可能。
连接适配器层需要支持主流数据库的本地协议连接。以从Oracle数据库迁移为例,可以通过外部数据包装器实现:
sql
-- 数据库连接配置示例
CREATE SERVER oracle_source
FOREIGN DATA WRAPPER kingbase_fdw
OPTIONS (
host '192.168.1.100',
port '1521',
dbname 'orcl',
service_name 'ORCLPDB'
);
-- 创建用户映射
CREATE USER MAPPING FOR current_user
SERVER oracle_source
OPTIONS (user 'source_user', password 'password123');
-- 创建外部表映射源表
CREATE FOREIGN TABLE oracle_employees (
emp_id INTEGER,
emp_name VARCHAR(100),
salary NUMBER(10,2),
hire_date DATE
) SERVER oracle_source
OPTIONS (schema 'HR', table 'EMPLOYEES');模式转换器通过智能映射算法处理数据类型转换。KES内置了超过200种数据类型的自动映射规则,同时支持用户自定义转换规则:
sql
-- 数据类型转换配置示例
CREATE TYPE MAPPING oracle_to_kes AS (
source_type VARCHAR(50),
target_type VARCHAR(50),
conversion_rule TEXT
);
-- 添加自定义转换规则
INSERT INTO type_conversion_rules VALUES
('Oracle.NUMBER(38)', 'KES.BIGINT', 'direct'),
('Oracle.NUMBER(10,2)', 'KES.DECIMAL(10,2)', 'direct'),
('Oracle.NVARCHAR2', 'KES.VARCHAR', 'utf8_conversion'),
('Oracle.RAW', 'KES.BYTEA', 'hex_decode');1.2 智能分片迁移策略
针对大规模数据迁移,KES采用智能分片策略。系统自动分析表的数据分布特征,生成最优的分片方案:
python
# 分片策略生成算法示例
class ShardingStrategyGenerator:
def __init__(self, source_conn, table_name):
self.source = source_conn
self.table = table_name
def analyze_data_distribution(self):
"""分析数据分布特征"""
# 获取表统计信息
stats = self.source.execute(f"""
SELECT column_name, data_type,
num_distinct, density,
histogram
FROM dba_tab_columns
WHERE table_name = '{self.table}'
""")
# 识别候选分片键
candidates = []
for col in stats:
if self._is_good_shard_key(col):
candidates.append(col['column_name'])
return self._select_best_shard_key(candidates)
def generate_shard_plan(self, shard_key):
"""生成分片迁移计划"""
# 获取分片键的值范围
min_max = self.source.execute(f"""
SELECT MIN({shard_key}), MAX({shard_key})
FROM {self.table}
""")
# 根据数据分布决定分片数量
shard_count = self._calculate_shard_count(min_max)
# 为每个分片生成查询条件
shard_queries = []
for i in range(shard_count):
start = min_max[0] + (min_max[1] - min_max[0]) * i / shard_count
end = min_max[0] + (min_max[1] - min_max[0]) * (i + 1) / shard_count
query = f"""
SELECT * FROM {self.table}
WHERE {shard_key} >= {start}
AND {shard_key} < {end}
ORDER BY {shard_key}
"""
shard_queries.append(query)
return shard_queries
def _is_good_shard_key(self, column):
"""判断是否为好的分片键"""
# 条件:高基数、均匀分布、查询常用
if column['num_distinct'] < 100:
return False
if column['density'] > 0.5: # 数据分布不均匀
return False
return True二、非结构化数据存储与管理
2.1 文档数据的原生支持
KES提供了对JSON/JSONB的原生支持,并在性能和功能上都进行了深度优化。相比传统的文本存储,KES的二进制JSONB格式提供了更好的查询性能:
vbnet
-- JSONB数据类型使用示例
CREATE TABLE product_catalog (
id SERIAL PRIMARY KEY,
product_data JSONB NOT NULL,
category VARCHAR(50),
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- 创建GIN索引加速JSON查询
CREATE INDEX idx_product_gin ON product_catalog
USING GIN (product_data);
-- 插入文档数据
INSERT INTO product_catalog (product_data, category) VALUES
('{
"name": "智能手机",
"brand": "华为",
"specs": {
"screen": "6.5英寸",
"memory": "8GB",
"storage": "256GB",
"camera": ["50MP", "12MP", "8MP"]
},
"price": 3999.00,
"tags": ["5G", "拍照", "快充"]
}', 'electronics'),
('{
"name": "笔记本电脑",
"brand": "联想",
"specs": {
"cpu": "Intel i7",
"memory": "16GB",
"storage": "1TB SSD",
"screen": "15.6英寸"
},
"price": 6999.00,
"tags": ["轻薄", "高性能", "商务"]
}', 'electronics');
-- 使用JSON路径查询
SELECT product_data->>'name' as product_name,
product_data->'specs'->>'memory' as memory,
product_data->>'price' as price
FROM product_catalog
WHERE product_data @> '{"brand": "华为"}'
AND product_data->'price' > '3000';
-- JSONB的高级操作
SELECT
jsonb_path_query_first(
product_data,
'$.specs.camera[0]'
) as main_camera,
jsonb_object_keys(product_data->'specs') as spec_keys
FROM product_catalog
WHERE product_data->'tags' ? '5G';2.1.1 JSON数据处理的实践考虑
技术实现要点:
- 使用GIN索引优化JSON文档的全文搜索
- 支持JSON路径表达式进行复杂查询
- 提供JSON模式验证和转换功能
实际应用中的挑战:
- 大规模JSON文档的存储和索引效率
- JSON模式演化的管理复杂性
- 与其他系统的数据交换格式兼容性
技术方案的特点:
- 采用二进制JSONB格式减少存储空间
- 支持部分更新减少写放大
- 提供丰富的JSON处理函数库
多源数据迁移的技术选型考量
在实际项目中,选择多源数据迁移方案时需要考虑多个维度:
| 考量维度 | 传统方案 | 统一数据库平台方案 | 其他可选方案 |
|---|---|---|---|
| 迁移自动化程度 | 需编写大量脚本 | 提供图形化迁移工具 | AWS DMS、阿里云DTS |
| GIS支持完整性 | 需第三方插件 | 原生OGC标准支持 | PostGIS、Oracle Spatial |
| 时序数据性能 | 普通表+分区 | 专用时序存储引擎 | InfluxDB、TimescaleDB |
| 维护复杂度 | 多系统维护 | 统一平台维护 | 混合架构维护 |
| 学习成本 | 多种技术栈 | 统一技术栈 | 分散技术栈 |
| 扩展性 | 有限 | 较好 | 依赖具体方案 |
统一数据库平台方案的优势:在统一平台内提供了较为完整的多源数据支持,减少了系统集成的复杂度。
需要注意的点:在超大规模时序数据场景下,可能需要结合专门的时序数据库;在极高并发的缓存场景,专门的缓存数据库可能仍有优势。
2.2 大对象存储优化
对于大型文档、图片、音视频等非结构化数据,KES提供了优化的LOB存储引擎:
sql
-- 大对象存储示例
CREATE TABLE document_store (
doc_id BIGSERIAL PRIMARY KEY,
doc_name VARCHAR(255) NOT NULL,
doc_type VARCHAR(50),
metadata JSONB,
-- 使用KES优化的大对象存储
content OID,
created_by VARCHAR(100),
created_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- 存储大对象
CREATE OR REPLACE FUNCTION store_document(
p_name VARCHAR,
p_type VARCHAR,
p_metadata JSONB,
p_content BYTEA
) RETURNS BIGINT AS $$
DECLARE
v_oid OID;
v_doc_id BIGINT;
BEGIN
-- 创建大对象
v_oid := lo_create(0);
-- 写入内容
PERFORM lo_open(v_oid, 131072); -- 读写模式
PERFORM lowrite(v_oid, p_content);
PERFORM lo_close(v_oid);
-- 保存元数据
INSERT INTO document_store
(doc_name, doc_type, metadata, content)
VALUES (p_name, p_type, p_metadata, v_oid)
RETURNING doc_id INTO v_doc_id;
RETURN v_doc_id;
END;
$$ LANGUAGE plpgsql;
-- 读取大对象
CREATE OR REPLACE FUNCTION read_document(
p_doc_id BIGINT
) RETURNS BYTEA AS $$
DECLARE
v_oid OID;
v_content BYTEA;
v_buffer BYTEA;
v_read_len INTEGER;
BEGIN
-- 获取OID
SELECT content INTO v_oid
FROM document_store
WHERE doc_id = p_doc_id;
IF v_oid IS NULL THEN
RETURN NULL;
END IF;
-- 分块读取大对象
PERFORM lo_open(v_oid, 262144); -- 只读模式
v_content := '';
FOR i IN 0..lo_lseek(v_oid, 0, 2) / 8192 LOOP
PERFORM lo_lseek(v_oid, i * 8192, 0);
v_buffer := loread(v_oid, 8192);
IF v_buffer IS NULL THEN
EXIT;
END IF;
v_content := v_content || v_buffer;
END LOOP;
PERFORM lo_close(v_oid);
RETURN v_content;
END;
$$ LANGUAGE plpgsql;三、GIS空间数据处理
3.1 空间数据存储与索引
KES内置了完整的空间数据引擎,支持OGC标准的所有空间数据类型和操作:
sql
-- 创建空间数据表
CREATE TABLE spatial_data (
id SERIAL PRIMARY KEY,
location_name VARCHAR(100),
-- 使用KES的几何类型
geom GEOMETRY,
properties JSONB,
created_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- 创建空间索引
CREATE INDEX idx_spatial_geom
ON spatial_data USING GIST(geom);
-- 插入空间数据
INSERT INTO spatial_data (location_name, geom) VALUES
('天安门广场',
ST_GeomFromText('POINT(116.397477 39.908722)')),
('故宫博物院',
ST_PolygonFromText('POLYGON((116.397 39.916, 116.397 39.917,
116.398 39.917, 116.398 39.916,
116.397 39.916))')),
('长安街',
ST_LineFromText('LINESTRING(116.35 39.90, 116.40 39.90)'));
-- 空间查询示例
-- 1. 查找指定范围内的点
SELECT location_name,
ST_AsText(geom) as coordinates
FROM spatial_data
WHERE ST_DWithin(
geom,
ST_GeomFromText('POINT(116.40 39.91)'),
0.01 -- 约1公里范围
);
-- 2. 空间关系判断
SELECT a.location_name as place_a,
b.location_name as place_b,
ST_Relate(a.geom, b.geom) as relation
FROM spatial_data a, spatial_data b
WHERE a.id < b.id
AND ST_Intersects(a.geom, b.geom);
-- 3. 缓冲区分析
SELECT location_name,
ST_AsText(ST_Buffer(geom, 0.005)) as buffer_zone
FROM spatial_data
WHERE ST_GeometryType(geom) = 'ST_Point';
-- 4. 空间聚合
SELECT
ST_AsText(ST_ConvexHull(
ST_Collect(geom)
)) as convex_hull
FROM spatial_data;3.2 高性能空间分析函数
KES提供了优化的空间分析函数库,支持复杂的空间运算:
sql
-- 创建示例数据:城市区域和兴趣点
CREATE TABLE city_areas (
area_id SERIAL PRIMARY KEY,
area_name VARCHAR(50),
boundary GEOMETRY(POLYGON),
population INTEGER
);
CREATE TABLE points_of_interest (
poi_id SERIAL PRIMARY KEY,
poi_name VARCHAR(100),
poi_type VARCHAR(50),
location GEOMETRY(POINT),
properties JSONB
);
-- 高级空间分析查询
WITH spatial_analysis AS (
-- 计算每个区域内的兴趣点密度
SELECT
a.area_name,
a.population,
COUNT(p.poi_id) as poi_count,
ST_Area(a.boundary) as area_size,
-- 兴趣点密度 = 兴趣点数 / 面积
COUNT(p.poi_id) / NULLIF(ST_Area(a.boundary), 0)
as poi_density,
-- 计算质心
ST_Centroid(a.boundary) as centroid,
-- 计算最小边界矩形
ST_Envelope(a.boundary) as mbr
FROM city_areas a
LEFT JOIN points_of_interest p
ON ST_Contains(a.boundary, p.location)
GROUP BY a.area_id, a.area_name, a.boundary, a.population
),
-- 计算Voronoi图
voronoi_diagram AS (
SELECT
ST_VoronoiPolygons(
ST_Collect(location)
) as voronoi_cells
FROM points_of_interest
)
-- 综合查询结果
SELECT
sa.area_name,
sa.poi_density,
sa.population,
-- 判断区域形状的紧凑度
CASE
WHEN ST_Area(sa.mbr) > 0 THEN
ST_Area(sa.boundary) / ST_Area(sa.mbr)
ELSE 0
END as compactness_ratio,
-- 计算到最近兴趣点的平均距离
(SELECT AVG(ST_Distance(sa.centroid, p.location))
FROM points_of_interest p) as avg_distance_to_poi
FROM spatial_analysis sa
WHERE sa.poi_density > 0
ORDER BY sa.poi_density DESC;四、时序数据处理优化
4.1 时序数据表设计与优化
KES针对时序数据的特性进行了专门的存储和查询优化:
sql
-- 创建时序数据表
CREATE TABLE time_series_data (
-- 时间戳,使用分区键
ts TIMESTAMP NOT NULL,
-- 设备标识
device_id VARCHAR(50) NOT NULL,
-- 指标类型
metric_name VARCHAR(50) NOT NULL,
-- 指标值
metric_value DOUBLE PRECISION NOT NULL,
-- 标签(用于快速过滤)
tags JSONB DEFAULT '{}',
-- 创建时间分区
PRIMARY KEY (device_id, metric_name, ts)
) PARTITION BY RANGE (ts);
-- 创建时间分区
CREATE TABLE ts_data_2024q1
PARTITION OF time_series_data
FOR VALUES FROM ('2024-01-01') TO ('2024-04-01');
CREATE TABLE ts_data_2024q2
PARTITION OF time_series_data
FOR VALUES FROM ('2024-04-01') TO ('2024-07-01');
-- 创建复合索引
CREATE INDEX idx_ts_query ON time_series_data
USING BRIN(ts, device_id, metric_name);
-- 创建时间序列索引
CREATE INDEX idx_ts_time ON time_series_data (ts DESC)
WHERE metric_name = 'temperature';
-- 插入时序数据
INSERT INTO time_series_data
(ts, device_id, metric_name, metric_value, tags)
VALUES
('2024-01-15 10:00:00', 'device_001', 'temperature', 25.5,
'{"location": "room_a", "unit": "celsius"}'),
('2024-01-15 10:00:00', 'device_001', 'humidity', 60.3,
'{"location": "room_a", "unit": "percent"}'),
('2024-01-15 10:01:00', 'device_002', 'temperature', 26.1,
'{"location": "room_b", "unit": "celsius"}');4.2 时序数据分析函数
KES提供了丰富的时序分析函数,支持复杂的时序运算:
sql
-- 时序数据分析示例
WITH time_series_stats AS (
-- 基础聚合
SELECT
device_id,
metric_name,
-- 时间桶:按5分钟聚合
time_bucket('5 minutes', ts) as bucket,
-- 基本统计
COUNT(*) as sample_count,
AVG(metric_value) as avg_value,
MIN(metric_value) as min_value,
MAX(metric_value) as max_value,
STDDEV(metric_value) as std_value,
-- 百分位数
PERCENTILE_CONT(0.5) WITHIN GROUP
(ORDER BY metric_value) as median,
PERCENTILE_CONT(0.95) WITHIN GROUP
(ORDER BY metric_value) as p95,
-- 变化率
FIRST_VALUE(metric_value) OVER w as first_val,
LAST_VALUE(metric_value) OVER w as last_val
FROM time_series_data
WHERE ts >= NOW() - INTERVAL '1 day'
AND metric_name = 'temperature'
GROUP BY device_id, metric_name, time_bucket('5 minutes', ts)
WINDOW w AS (
PARTITION BY device_id
ORDER BY ts
ROWS BETWEEN UNBOUNDED PRECEDING
AND UNBOUNDED FOLLOWING
)
),
-- 移动平均和趋势分析
moving_averages AS (
SELECT
device_id,
bucket,
avg_value,
-- 简单移动平均
AVG(avg_value) OVER (
PARTITION BY device_id
ORDER BY bucket
ROWS BETWEEN 6 PRECEDING AND CURRENT ROW
) as sma_7,
-- 指数移动平均
EXP_MOVING_AVG(avg_value, 0.3) OVER (
PARTITION BY device_id
ORDER BY bucket
) as ema_alpha_03,
-- 趋势检测
CASE
WHEN avg_value > LAG(avg_value) OVER w THEN '上升'
WHEN avg_value < LAG(avg_value) OVER w THEN '下降'
ELSE '平稳'
END as trend
FROM time_series_stats
WINDOW w AS (
PARTITION BY device_id
ORDER BY bucket
)
),
-- 异常检测
anomaly_detection AS (
SELECT
device_id,
bucket,
avg_value,
sma_7,
-- 计算z-score
(avg_value - AVG(avg_value) OVER w) /
NULLIF(STDDEV(avg_value) OVER w, 0) as z_score,
-- 标记异常点
CASE
WHEN ABS((avg_value - AVG(avg_value) OVER w) /
NULLIF(STDDEV(avg_value) OVER w, 0)) > 3
THEN TRUE
ELSE FALSE
END as is_anomaly
FROM moving_averages
WINDOW w AS (
PARTITION BY device_id
ORDER BY bucket
ROWS BETWEEN 10 PRECEDING AND CURRENT ROW
)
)
-- 最终查询结果
SELECT
ad.device_id,
ad.bucket,
ad.avg_value,
ad.sma_7,
ad.z_score,
ad.is_anomaly,
ts.trend,
-- 计算预测值(基于简单线性回归)
REGR_SLOPE(ad.avg_value,
EXTRACT(EPOCH FROM ad.bucket))
OVER w * EXTRACT(EPOCH FROM ad.bucket) +
REGR_INTERCEPT(ad.avg_value,
EXTRACT(EPOCH FROM ad.bucket))
OVER w as predicted_value
FROM anomaly_detection ad
JOIN moving_averages ts
ON ad.device_id = ts.device_id
AND ad.bucket = ts.bucket
WINDOW w AS (
PARTITION BY ad.device_id
ORDER BY ad.bucket
ROWS BETWEEN 10 PRECEDING AND CURRENT ROW
)
ORDER BY ad.device_id, ad.bucket;五、缓存数据无缝集成
5.1 内存表与持久化缓存
KES提供了内存表功能,支持将热点数据完全加载到内存中:
sql
-- 创建内存表
CREATE MEMORY TABLE hot_user_session (
session_id VARCHAR(64) PRIMARY KEY,
user_id BIGINT NOT NULL,
login_time TIMESTAMP NOT NULL,
last_access TIMESTAMP NOT NULL,
session_data JSONB,
-- 内存表特有属性
TTL INTERVAL '1 hour', -- 生存时间
COMPRESSION 'lz4' -- 内存压缩
);
-- 创建基于内存表的物化视图
CREATE MATERIALIZED VIEW user_online_status
WITH (ENGINE = 'MEMORY') AS
SELECT
user_id,
COUNT(*) as session_count,
MAX(last_access) as last_activity,
NOW() - MAX(last_access) as inactive_duration
FROM hot_user_session
GROUP BY user_id
HAVING MAX(last_access) > NOW() - INTERVAL '5 minutes';
-- 自动刷新物化视图
CREATE OR REPLACE FUNCTION refresh_session_status()
RETURNS TRIGGER AS $$
BEGIN
REFRESH MATERIALIZED VIEW CONCURRENTLY user_online_status;
RETURN NULL;
END;
$$ LANGUAGE plpgsql;
CREATE TRIGGER trigger_refresh_status
AFTER INSERT OR UPDATE OR DELETE ON hot_user_session
FOR EACH STATEMENT
EXECUTE FUNCTION refresh_session_status();5.2 Redis兼容接口
KES提供了Redis协议兼容层,支持现有的Redis客户端无缝连接:
typescript
// Java示例:使用Jedis客户端连接KES缓存
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
public class KESCacheClient {
private JedisPool jedisPool;
public KESCacheClient(String host, int port) {
JedisPoolConfig config = new JedisPoolConfig();
config.setMaxTotal(100);
config.setMaxIdle(20);
config.setMinIdle(5);
config.setMaxWaitMillis(3000);
this.jedisPool = new JedisPool(config, host, port);
}
// 字符串操作
public String cacheString(String key, String value, int ttl) {
try (Jedis jedis = jedisPool.getResource()) {
jedis.setex(key, ttl, value);
return value;
}
}
// 哈希操作
public void cacheUserInfo(String userId, Map<String, String> userInfo) {
try (Jedis jedis = jedisPool.getResource()) {
jedis.hset("user:" + userId, userInfo);
jedis.expire("user:" + userId, 3600);
}
}
// 列表操作
public void pushMessage(String queueName, String message) {
try (Jedis jedis = jedisPool.getResource()) {
jedis.lpush(queueName, message);
// 保持队列长度
jedis.ltrim(queueName, 0, 999);
}
}
// 事务操作
public boolean transferBalance(
String fromAccount,
String toAccount,
double amount
) {
try (Jedis jedis = jedisPool.getResource()) {
// 监视关键键
jedis.watch(fromAccount, toAccount);
double fromBalance = Double.parseDouble(
jedis.get(fromAccount)
);
if (fromBalance < amount) {
jedis.unwatch();
return false;
}
// 开启事务
Transaction tx = jedis.multi();
tx.decrByFloat(fromAccount, amount);
tx.incrByFloat(toAccount, amount);
List<Object> results = tx.exec();
return results != null;
}
}
// Lua脚本支持
public Object evalLuaScript(String script,
List<String> keys,
List<String> args) {
try (Jedis jedis = jedisPool.getResource()) {
return jedis.eval(script, keys, args);
}
}
}六、迁移中的数据一致性保障
6.1 在线数据同步机制
KES提供了多种数据同步机制,确保迁移过程中的数据一致性:
sql
-- 创建逻辑复制槽
SELECT * FROM pg_create_logical_replication_slot(
'kes_migration_slot',
'kingbase_decoding'
);
-- 配置数据过滤规则
CREATE PUBLICATION migration_publication
FOR TABLE users, orders, products
WITH (
publish = 'insert,update,delete',
-- 条件过滤
where_users = 'status = "active"',
where_orders = 'order_date > "2024-01-01"'
);
-- 目标端创建订阅
CREATE SUBSCRIPTION migration_subscription
CONNECTION 'host=source_host port=5432 dbname=source_db'
PUBLICATION migration_publication
WITH (
copy_data = true,
create_slot = false,
enabled = true,
slot_name = 'kes_migration_slot',
-- 同步参数
synchronous_commit = 'remote_apply',
binary = true
);
-- 监控同步状态
SELECT
subname,
received_lsn,
last_msg_send_time,
last_msg_receipt_time,
latest_end_lsn,
slot_name,
active,
-- 计算延迟
pg_wal_lsn_diff(
pg_current_wal_lsn(),
received_lsn
) as replication_lag
FROM pg_stat_subscription;6.2 数据校验与修复
python
# 数据一致性校验工具
class DataConsistencyChecker:
def __init__(self, source_conn, target_conn):
self.source = source_conn
self.target = target_conn
self.batch_size = 10000
def checksum_verification(self, table_name, pk_column):
"""使用校验和验证数据一致性"""
source_checksums = []
target_checksums = []
# 分片计算校验和
source_total = self._get_table_count(self.source, table_name)
target_total = self._get_table_count(self.target, table_name)
if source_total != target_total:
return False, f"记录数不匹配: {source_total} != {target_total}"
# 分段计算校验和
for offset in range(0, source_total, self.batch_size):
source_checksum = self._calculate_checksum(
self.source, table_name, pk_column, offset, self.batch_size
)
target_checksum = self._calculate_checksum(
self.target, table_name, pk_column, offset, self.batch_size
)
if source_checksum != target_checksum:
# 定位不一致的精确位置
diff_rows = self._find_difference(
table_name, pk_column, offset, self.batch_size
)
return False, f"数据不一致: {diff_rows}"
source_checksums.append(source_checksum)
target_checksums.append(target_checksum)
return True, "数据一致"
def _calculate_checksum(self, conn, table, pk_column, offset, limit):
"""计算数据块的校验和"""
query = f"""
SELECT MD5(
STRING_AGG(
CONCAT_WS('|', {pk_column}, col1, col2, ...),
'#'
)
) as chunk_checksum
FROM (
SELECT * FROM {table}
ORDER BY {pk_column}
LIMIT {limit} OFFSET {offset}
) subquery
"""
result = conn.execute(query)
return result.fetchone()['chunk_checksum']
def incremental_sync(self, table_name, last_sync_time):
"""增量同步"""
# 获取源端变更
changes = self._get_changes_since(
self.source, table_name, last_sync_time
)
# 应用变更到目标端
with self.target.transaction():
for change in changes:
if change['operation'] == 'INSERT':
self._apply_insert(self.target, table_name, change['data'])
elif change['operation'] == 'UPDATE':
self._apply_update(self.target, table_name, change['data'])
elif change['operation'] == 'DELETE':
self._apply_delete(self.target, table_name, change['key'])
return len(changes)七、性能优化与调优
7.1 查询性能优化
sql
-- 查询执行计划分析
EXPLAIN (ANALYZE, BUFFERS, VERBOSE)
SELECT
u.user_id,
u.username,
COUNT(o.order_id) as order_count,
SUM(o.amount) as total_amount,
AVG(o.amount) as avg_amount,
MAX(o.order_date) as last_order
FROM users u
JOIN orders o ON u.user_id = o.user_id
WHERE u.register_date >= '2024-01-01'
AND o.status = 'completed'
GROUP BY u.user_id, u.username
HAVING COUNT(o.order_id) > 5
ORDER BY total_amount DESC
LIMIT 100;
-- 创建优化索引
-- 复合索引
CREATE INDEX idx_user_orders ON orders(user_id, status, order_date)
INCLUDE (amount);
-- 条件索引
CREATE INDEX idx_recent_active_users ON users(register_date)
WHERE last_login_date > CURRENT_DATE - INTERVAL '30 days';
-- 表达式索引
CREATE INDEX idx_user_email_domain ON users(LOWER(SPLIT_PART(email, '@', 2)));
-- 并行查询优化
SET max_parallel_workers_per_gather = 4;
SET parallel_setup_cost = 10;
SET parallel_tuple_cost = 0.1;
-- 物化视图预计算
CREATE MATERIALIZED VIEW user_order_stats
WITH (refresh_mode = 'incremental') AS
SELECT
u.user_id,
u.user_level,
COUNT(o.order_id) as total_orders,
SUM(o.amount) as total_amount,
AVG(o.amount) as avg_order_value,
MAX(o.order_date) as last_order_date,
MIN(o.order_date) as first_order_date
FROM users u
LEFT JOIN orders o ON u.user_id = o.user_id
WHERE o.status = 'completed'
OR o.status IS NULL
GROUP BY u.user_id, u.user_level;
-- 自动刷新物化视图
CREATE OR REPLACE FUNCTION refresh_user_stats()
RETURNS trigger AS $$
BEGIN
REFRESH MATERIALIZED VIEW CONCURRENTLY user_order_stats;
RETURN NULL;
END;
$$ LANGUAGE plpgsql;
CREATE TRIGGER trigger_refresh_stats
AFTER INSERT OR UPDATE OR DELETE ON orders
FOR EACH STATEMENT
EXECUTE FUNCTION refresh_user_stats();7.2 分区表优化
sql
-- 创建范围分区表
CREATE TABLE sensor_data (
sensor_id VARCHAR(50) NOT NULL,
metric_time TIMESTAMP NOT NULL,
metric_name VARCHAR(50) NOT NULL,
metric_value DOUBLE PRECISION NOT NULL,
tags JSONB
) PARTITION BY RANGE (metric_time);
-- 按月自动创建分区
CREATE OR REPLACE FUNCTION create_monthly_partition()
RETURNS void AS $$
DECLARE
partition_name TEXT;
start_date DATE;
end_date DATE;
BEGIN
FOR i IN 0..12 LOOP
start_date := DATE_TRUNC('MONTH', CURRENT_DATE) +
(i || ' MONTHS')::INTERVAL;
end_date := DATE_TRUNC('MONTH', CURRENT_DATE) +
((i + 1) || ' MONTHS')::INTERVAL;
partition_name := 'sensor_data_' ||
TO_CHAR(start_date, 'YYYY_MM');
IF NOT EXISTS (
SELECT 1 FROM information_schema.tables
WHERE table_name = partition_name
) THEN
EXECUTE format('
CREATE TABLE %I PARTITION OF sensor_data
FOR VALUES FROM (%L) TO (%L)
WITH (parallel_workers = 4)
', partition_name, start_date, end_date);
-- 为分区创建索引
EXECUTE format('
CREATE INDEX %I ON %I
(sensor_id, metric_name, metric_time)
', 'idx_' || partition_name, partition_name);
END IF;
END LOOP;
END;
$$ LANGUAGE plpgsql;
-- 自动分区管理
CREATE OR REPLACE FUNCTION manage_partitions()
RETURNS trigger AS $$
DECLARE
current_month DATE;
partition_date DATE;
partition_name TEXT;
BEGIN
current_month := DATE_TRUNC('MONTH', NEW.metric_time);
partition_name := 'sensor_data_' ||
TO_CHAR(current_month, 'YYYY_MM');
-- 检查分区是否存在
IF NOT EXISTS (
SELECT 1 FROM information_schema.tables
WHERE table_name = partition_name
) THEN
-- 自动创建新分区
PERFORM create_monthly_partition();
END IF;
RETURN NEW;
END;
$$ LANGUAGE plpgsql;
CREATE TRIGGER trigger_manage_partitions
BEFORE INSERT ON sensor_data
FOR EACH ROW
EXECUTE FUNCTION manage_partitions();八、高可用与容灾方案
8.1 主从复制配置
sql
-- 主库配置
ALTER SYSTEM SET wal_level = 'logical';
ALTER SYSTEM SET max_wal_senders = 10;
ALTER SYSTEM SET max_replication_slots = 10;
ALTER SYSTEM SET synchronous_standby_names = 'kes_standby_1, kes_standby_2';
-- 创建复制用户
CREATE ROLE replicator WITH REPLICATION LOGIN
PASSWORD 'secure_password';
-- 配置复制槽
SELECT * FROM pg_create_physical_replication_slot('kes_slot_1');
-- 从库配置(恢复模式)
-- 使用KES的pg_basebackup工具进行基础备份
pg_basebackup -h primary_host -D /kes/data/standby \
-U replicator -v -P --wal-method=stream
-- 配置恢复参数
cat > /kes/data/recovery.conf << EOF
standby_mode = 'on'
primary_conninfo = 'host=primary_host port=5432 user=replicator password=secure_password application_name=kes_standby_1'
primary_slot_name = 'kes_slot_1'
recovery_target_timeline = 'latest'
promote_trigger_file = '/kes/data/promote_trigger'
EOF
-- 监控复制状态
SELECT
client_addr,
application_name,
state,
sync_state,
sync_priority,
flush_lsn,
replay_lsn,
write_lag,
flush_lag,
replay_lag
FROM pg_stat_replication;
-- 自动故障转移配置
CREATE OR REPLACE FUNCTION check_replication_health()
RETURNS TABLE (
standby_name TEXT,
is_healthy BOOLEAN,
replication_lag INTERVAL,
last_heartbeat TIMESTAMP
) AS $$
BEGIN
RETURN QUERY
SELECT
application_name,
state = 'streaming' AND
sync_state IN ('sync', 'potential') AND
replay_lag < INTERVAL '1 minute',
replay_lag,
reply_time
FROM pg_stat_replication
WHERE application_name LIKE 'kes_standby_%';
END;
$$ LANGUAGE plpgsql;8.2 数据备份与恢复
bash
#!/bin/bash
# KES备份脚本
BACKUP_DIR="/backup/kes"
LOG_FILE="/var/log/kes_backup.log"
DATE=$(date +%Y%m%d_%H%M%S)
# 全量备份函数
full_backup() {
echo "[$(date)] 开始全量备份" >> $LOG_FILE
# 创建备份目录
BACKUP_PATH="$BACKUP_DIR/full_$DATE"
mkdir -p $BACKUP_PATH
# 执行基础备份
pg_basebackup \
-D $BACKUP_PATH \
-h localhost \
-U backup_user \
-v \
-P \
--wal-method=stream \
--checkpoint=fast \
2>> $LOG_FILE
if [ $? -eq 0 ]; then
echo "[$(date)] 全量备份完成: $BACKUP_PATH" >> $LOG_FILE
# 备份配置文件
cp $KES_DATA_DIR/*.conf $BACKUP_PATH/
# 保留策略:保留最近7天备份
find $BACKUP_DIR/full_* -maxdepth 0 -type d -mtime +7 -exec rm -rf {} ;
return 0
else
echo "[$(date)] 全量备份失败" >> $LOG_FILE
return 1
fi
}
# 增量备份函数
incremental_backup() {
echo "[$(date)] 开始增量备份" >> $LOG_FILE
# 开始WAL归档
psql -U postgres -c "SELECT pg_start_backup('incremental_backup', true);"
# 复制变化的文件
BACKUP_PATH="$BACKUP_DIR/incr_$DATE"
mkdir -p $BACKUP_PATH
# 使用rsync同步变化
rsync -av --delete \
--exclude="pg_wal/*" \
--exclude="*.pid" \
$KES_DATA_DIR/ $BACKUP_PATH/ \
2>> $LOG_FILE
# 停止WAL归档
psql -U postgres -c "SELECT pg_stop_backup();"
# 归档WAL日志
find $KES_DATA_DIR/pg_wal -name "*.backup" -mtime -1 -exec cp {} $BACKUP_PATH/ ;
echo "[$(date)] 增量备份完成: $BACKUP_PATH" >> $LOG_FILE
return 0
}
# 点时间恢复函数
point_in_time_recovery() {
local RECOVERY_TIME=$1
local BACKUP_FILE=$2
echo "[$(date)] 开始时间点恢复: $RECOVERY_TIME" >> $LOG_FILE
# 停止数据库
systemctl stop kes
# 清空数据目录
rm -rf $KES_DATA_DIR/*
# 恢复基础备份
tar -xzf $BACKUP_FILE -C $KES_DATA_DIR/
# 配置恢复参数
cat > $KES_DATA_DIR/recovery.conf << EOF
restore_command = 'cp /backup/kes/wal/%f "%p"'
recovery_target_time = '$RECOVERY_TIME'
recovery_target_timeline = 'latest'
recovery_target_action = 'promote'
EOF
# 启动数据库
systemctl start kes
echo "[$(date)] 时间点恢复完成" >> $LOG_FILE
return 0
}
# 主备份逻辑
case $1 in
"full")
full_backup
;;
"incremental")
incremental_backup
;;
"restore")
point_in_time_recovery "$2" "$3"
;;
*)
echo "用法: $0 {full|incremental|restore [time] [backup_file]}"
exit 1
;;
esac九、监控与运维管理
9.1 性能监控系统
sql
-- 创建性能监控表
CREATE TABLE kes_performance_metrics (
metric_id BIGSERIAL PRIMARY KEY,
metric_time TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,
metric_name VARCHAR(100) NOT NULL,
metric_value DOUBLE PRECISION NOT NULL,
tags JSONB DEFAULT '{}',
instance_name VARCHAR(50) NOT NULL
) PARTITION BY RANGE (metric_time);
-- 创建索引
CREATE INDEX idx_metrics_query ON kes_performance_metrics
USING BRIN(metric_time, metric_name, instance_name);
-- 关键性能指标收集函数
CREATE OR REPLACE FUNCTION collect_performance_metrics()
RETURNS void AS $$
DECLARE
current_time TIMESTAMP := CURRENT_TIMESTAMP;
BEGIN
-- 收集连接数统计
INSERT INTO kes_performance_metrics
(metric_time, metric_name, metric_value, tags, instance_name)
SELECT
current_time,
'connection_count',
COUNT(*),
jsonb_build_object('state', state),
'kes_primary'
FROM pg_stat_activity
WHERE pid != pg_backend_pid()
GROUP BY state;
-- 收集锁等待统计
INSERT INTO kes_performance_metrics
(metric_time, metric_name, metric_value, tags, instance_name)
SELECT
current_time,
'lock_wait_count',
COUNT(*),
jsonb_build_object(
'lock_type', locktype,
'relation', relation::regclass
),
'kes_primary'
FROM pg_locks
WHERE NOT granted
GROUP BY locktype, relation;
-- 收集缓存命中率
INSERT INTO kes_performance_metrics
(metric_time, metric_name, metric_value, tags, instance_name)
SELECT
current_time,
'cache_hit_ratio',
CASE
WHEN blks_hit + blks_read = 0 THEN 0
ELSE blks_hit::float / (blks_hit + blks_read)
END * 100,
jsonb_build_object('database', datname),
'kes_primary'
FROM pg_stat_database;
-- 收集表大小和膨胀情况
INSERT INTO kes_performance_metrics
(metric_time, metric_name, metric_value, tags, instance_name)
SELECT
current_time,
'table_bloat_ratio',
CASE
WHEN pg_relation_size(relid) = 0 THEN 0
ELSE (pg_total_relation_size(relid) -
pg_relation_size(relid))::float /
pg_total_relation_size(relid) * 100
END,
jsonb_build_object(
'schema', schemaname,
'table', relname
),
'kes_primary'
FROM pg_stat_user_tables
WHERE pg_total_relation_size(relid) > 1000000; -- 只监控大于1MB的表
END;
$$ LANGUAGE plpgsql;
-- 创建定期收集任务
SELECT cron.schedule(
'collect-performance-metrics',
'*/5 * * * *', -- 每5分钟执行
'SELECT collect_performance_metrics();'
);9.2 自动化维护脚本
python
#!/usr/bin/env python3
"""
KES数据库自动化维护脚本
"""
import psycopg2
from psycopg2.extras import RealDictCursor
import schedule
import time
import logging
from datetime import datetime, timedelta
import json
class KESMaintenance:
def __init__(self, db_config):
self.db_config = db_config
self.logger = self._setup_logging()
def _setup_logging(self):
"""配置日志"""
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s',
handlers=[
logging.FileHandler('/var/log/kes_maintenance.log'),
logging.StreamHandler()
]
)
return logging.getLogger(__name__)
def connect(self):
"""连接数据库"""
try:
conn = psycopg2.connect(**self.db_config)
conn.autocommit = False
return conn
except Exception as e:
self.logger.error(f"数据库连接失败: {e}")
raise
def analyze_tables(self):
"""定期分析表统计信息"""
self.logger.info("开始分析表统计信息")
try:
with self.connect() as conn:
with conn.cursor() as cur:
# 获取需要分析的表
cur.execute("""
SELECT schemaname, relname
FROM pg_stat_user_tables
WHERE last_analyze IS NULL
OR last_analyze < NOW() - INTERVAL '1 day'
OR n_mod_since_analyze > 1000
ORDER BY n_mod_since_analyze DESC
LIMIT 50
""")
tables = cur.fetchall()
analyzed_count = 0
for schema, table in tables:
try:
cur.execute(f'ANALYZE {schema}.{table}')
analyzed_count += 1
self.logger.info(f"已分析表: {schema}.{table}")
except Exception as e:
self.logger.error(f"分析表失败 {schema}.{table}: {e}")
conn.commit()
self.logger.info(f"表分析完成,共分析 {analyzed_count} 张表")
except Exception as e:
self.logger.error(f"表分析任务失败: {e}")
def vacuum_tables(self, aggressive=False):
"""自动清理表"""
self.logger.info("开始自动清理表")
try:
with self.connect() as conn:
with conn.cursor() as cur:
# 获取需要清理的表
if aggressive:
# 激进模式:清理所有有死元组的表
cur.execute("""
SELECT schemaname, relname,
n_dead_tup,
n_live_tup
FROM pg_stat_user_tables
WHERE n_dead_tup > 0
ORDER BY n_dead_tup DESC
""")
else:
# 保守模式:只清理死元组较多的表
cur.execute("""
SELECT schemaname, relname,
n_dead_tup,
n_live_tup
FROM pg_stat_user_tables
WHERE n_dead_tup > 1000
AND n_dead_tup::float /
NULLIF(n_live_tup, 0) > 0.1
ORDER BY n_dead_tup DESC
LIMIT 20
""")
tables = cur.fetchall()
vacuumed_count = 0
for schema, table, dead_tup, live_tup in tables:
try:
vacuum_cmd = 'VACUUM'
if aggressive:
vacuum_cmd = 'VACUUM FULL'
cur.execute(f'{vacuum_cmd} {schema}.{table}')
vacuumed_count += 1
self.logger.info(
f"已清理表: {schema}.{table}, "
f"死元组: {dead_tup}, 活元组: {live_tup}"
)
except Exception as e:
self.logger.error(f"清理表失败 {schema}.{table}: {e}")
conn.commit()
self.logger.info(f"表清理完成,共清理 {vacuumed_count} 张表")
except Exception as e:
self.logger.error(f"表清理任务失败: {e}")
def rebuild_indexes(self):
"""重建索引"""
self.logger.info("开始重建索引")
try:
with self.connect() as conn:
with conn.cursor() as cur:
# 获取需要重建的索引
cur.execute("""
SELECT schemaname, tablename, indexname,
indexdef
FROM pg_indexes
WHERE schemaname NOT IN ('pg_catalog', 'information_schema')
AND indexname NOT LIKE '%pkey'
ORDER BY tablename, indexname
""")
indexes = cur.fetchall()
rebuilt_count = 0
for schema, table, index, indexdef in indexes:
try:
# 检查索引碎片率
cur.execute(f"""
SELECT schemaname, tablename, indexname,
avg_leaf_density
FROM kes_index_stats
WHERE schemaname = %s
AND tablename = %s
AND indexname = %s
""", (schema, table, index))
stats = cur.fetchone()
if stats and stats['avg_leaf_density'] < 70:
# 碎片率大于30%,需要重建
new_index_name = f"{index}_rebuilt_{int(time.time())}"
# 创建新索引
new_indexdef = indexdef.replace(
f'INDEX {index} ON',
f'INDEX CONCURRENTLY {new_index_name} ON'
)
cur.execute(new_indexdef)
# 删除旧索引
cur.execute(f'DROP INDEX CONCURRENTLY {schema}.{index}')
# 重命名新索引
cur.execute(f'ALTER INDEX {schema}.{new_index_name} '
f'RENAME TO {index}')
rebuilt_count += 1
self.logger.info(f"已重建索引: {schema}.{index}")
except Exception as e:
self.logger.error(f"重建索引失败 {schema}.{index}: {e}")
conn.commit()
self.logger.info(f"索引重建完成,共重建 {rebuilt_count} 个索引")
except Exception as e:
self.logger.error(f"索引重建任务失败: {e}")
def check_replication_status(self):
"""检查复制状态"""
self.logger.info("检查复制状态")
try:
with self.connect() as conn:
with conn.cursor(cursor_factory=RealDictCursor) as cur:
cur.execute("""
SELECT
application_name,
client_addr,
state,
sync_state,
write_lag,
flush_lag,
replay_lag
FROM pg_stat_replication
""")
replicas = cur.fetchall()
unhealthy = []
for replica in replicas:
self.logger.info(f"复制状态: {replica}")
# 检查是否健康
if (replica['state'] != 'streaming' or
replica['replay_lag'] > timedelta(seconds=30)):
unhealthy.append(replica['application_name'])
if unhealthy:
self.logger.warning(f"以下复制节点不健康: {unhealthy}")
# 可以发送告警
self.send_alert(f"复制节点异常: {unhealthy}")
except Exception as e:
self.logger.error(f"检查复制状态失败: {e}")
def send_alert(self, message):
"""发送告警"""
# 实现告警逻辑,如发送邮件、微信、钉钉等
self.logger.error(f"告警: {message}")
# 这里可以集成各种告警渠道
def run_maintenance(self):
"""运行所有维护任务"""
self.logger.info("开始执行数据库维护任务")
try:
# 执行各项维护任务
self.analyze_tables()
self.vacuum_tables(aggressive=False)
self.rebuild_indexes()
self.check_replication_status()
self.logger.info("数据库维护任务执行完成")
except Exception as e:
self.logger.error(f"维护任务执行失败: {e}")
def main():
"""主函数"""
db_config = {
'host': 'localhost',
'port': 54321,
'database': 'kesdb',
'user': 'maintenance_user',
'password': 'secure_password'
}
maintenance = KESMaintenance(db_config)
# 设置定时任务
schedule.every().day.at("02:00").do(maintenance.analyze_tables)
schedule.every().sunday.at("03:00").do(
lambda: maintenance.vacuum_tables(aggressive=True)
)
schedule.every().day.at("04:00").do(maintenance.rebuild_indexes)
schedule.every(5).minutes.do(maintenance.check_replication_status)
# 立即执行一次
maintenance.run_maintenance()
# 运行调度器
while True:
schedule.run_pending()
time.sleep(60)
if __name__ == "__main__":
main()总结
总结来说,实现多源异构数据的有效融合需要考虑迁移策略、存储优化、查询性能等多个方面。文中所讨论的技术方案展示了在统一数据库平台中处理多样化数据的可行性,但实际应用中仍需根据具体业务场景进行技术选型和架构设计。随着数据技术的不断发展,企业需要建立灵活、可扩展的数据架构,以应对未来更复杂的数据管理需求。"