纯 JSON 序列化 QPS 10784,加上数据库查询和缓存后 QPS 仅剩 1775,衰减 84%。你的 Go 服务,到底在第几层?
大多数人聊 Go HTTP 优化,要么讲单机调优(超时配置、sync.Pool、pprof),要么讲微服务拆分(gRPC、服务发现、分布式事务)。很少有人把这两件事连起来看:从第 0 行配置到分布式可观测性,中间到底有几层?每层值不值?
这篇文章帮你做一件事:看清自己在哪一层,每一层的 ROI 是多少,什么时候该往上走,什么时候该停下来。
五层演进全景:第 0 层一行超时配置值 1.7 秒 P99 改善 → 第 1 层单机优化天花板在串行 IO → 第 2 层模块化单体 P99 比微服务低 3-8 倍 → 第 3 层分布式代价(超时传播 + 可靠性衰减)→ 第 4 层演进信号清单。
一、第 0 层:一行超时配置值多少钱
Go 的 net/http 包开箱即用,http.ListenAndServe(":8080", nil) 就能跑起来。但默认配置没有任何超时限制,这在生产环境是个定时炸弹。
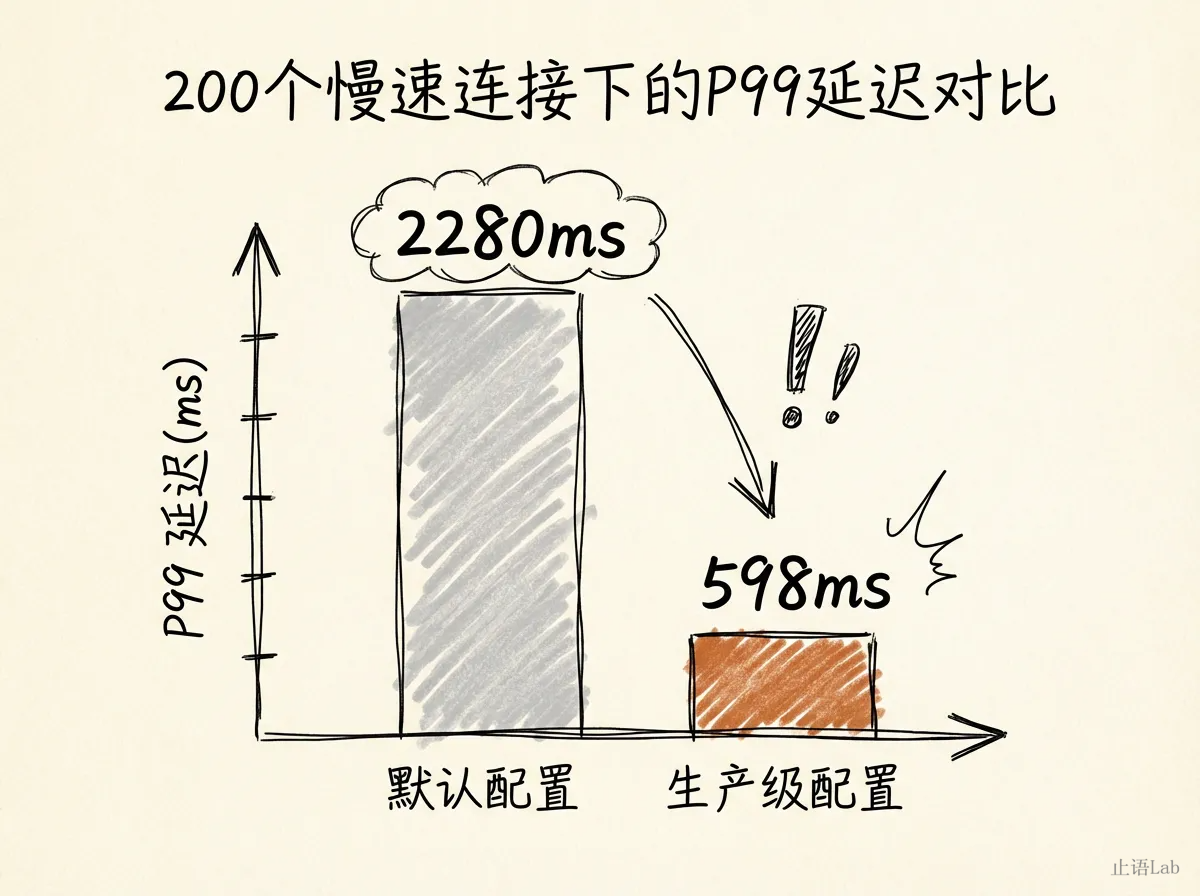
我跑了一组实测:同一台机器,同一个业务逻辑(返回 JSON),区别只在超时配置。默认配置什么都不设,生产级配置加了 ReadTimeout: 5s, ReadHeaderTimeout: 5s, WriteTimeout: 10s, IdleTimeout: 120s。
纯正常流量下,默认配置反而更快------因为少了超时检查的开销。但加上 200 个慢连接(模拟 Slowloris 攻击,每 5 秒发 1 字节),差距就出来了:
| 指标 | 默认配置 | 生产级配置 |
|---|---|---|
| P50 | 786ms | 336ms |
| P99 | 2.28s | 598ms |
模拟测试 Go 1.26.2 darwin/arm64,压测工具 hey,200 并发,持续 30s
默认配置 P99 飙到 2.28 秒,生产级配置 P99 只有 598ms。一行超时配置,值 1.7 秒的 P99 改善。
这不是微调,是防线。没有超时配置的 Go HTTP 服务,在任何有恶意流量的环境下都扛不住。这是底线。
超时配置推荐值:
srv := &http.Server{
Addr: ":8080",
ReadHeaderTimeout: 5 * time.Second, // 防御 Slowloris 的首选工具,Go 官方推荐优先使用
ReadTimeout: 5 * time.Second,
WriteTimeout: 10 * time.Second,
IdleTimeout: 120 * time.Second,
MaxHeaderBytes: 1 << 20, // 1MB
}ReadHeaderTimeout 专门限制请求头读取时间,是防御 Slowloris 的首选工具,Go 官方推荐优先使用它替代 ReadTimeout 对头部的限制。ReadTimeout 覆盖从开始读取请求到请求体读完的时间(不含 TCP 连接建立和 TLS 握手),WriteTimeout 覆盖响应写入时间,IdleTimeout 控制 Keep-Alive 连接的空闲时长。四个参数各有侧重,缺一不可。生产环境还需配合 srv.Shutdown(ctx) 做优雅关闭,避免直接杀进程截断进行中的请求。
这是第 0 层------不需要改架构,不需要加中间件,改几行代码就能从"随时可能被慢连接打挂"变成"能扛住基本攻击"。
二、第 1 层:单机优化的天花板在哪
防线有了,接下来看性能天花板。单机优化能走多远?
我测了 Go HTTP 服务在 5 层业务复杂度下的 QPS 衰减:纯 JSON 序列化 → 加 DB 查询 → 加 Redis 缓存 → 加外部 HTTP 调用 → 加业务逻辑。
| 层级 | QPS | P50 | P99 | 相对 L0 |
|---|---|---|---|---|
| 纯 JSON | 10784 | 9.12ms | 17.77ms | 100% |
| +DB(2ms) | 10776 | 9.23ms | 10.65ms | 99.9% |
| +Cache+DB(2.5ms) | 1775 | 43.62ms | 237.18ms | 16.5% |
| +HTTP调用(5.5ms) | 1705 | 50.10ms | 219.34ms | 15.8% |
| +业务逻辑(6.5ms) | 1729 | 45.63ms | 238.10ms | 16.0% |
模拟测试 Go 1.26.2 darwin/arm64,time.Sleep 模拟 IO 延迟
本文实验数据基于 time.Sleep 模拟 IO 延迟,用于验证趋势和量级关系,具体数值因业务场景而异。
两个反直觉的发现:
第一,单个 2ms 的 DB 查询几乎不影响 QPS。 L0→L1 的 QPS 几乎没变(10784→10776)。原因:Go 的 goroutine 模型让 IO sleep 期间 CPU 被其他请求复用------一个 goroutine 在等数据库,另一个 goroutine 照常处理请求。这是 Go goroutine 模型相比传统 Java 线程池模型的优势------Java 的虚拟线程(Project Loom)正在弥补这个差距:Java 里一个线程等 IO 就占着线程池位,Go 里一个 goroutine 等 IO 就让出 CPU。
第二,多个串行 IO 叠加才是杀手。 L1→L2 QPS 从 10776 暴跌到 1775(衰减 84%)。不是单个 IO 延迟大,而是串行 IO 把请求拉长了------P50 从 9ms 飙到 43ms,P99 从 10ms 飙到 237ms。排队效应放大了延迟。

单机还能优化什么
pprof 是你的第一站。go tool pprof 能定位 CPU 热点和内存分配。但有一个常见的误区------很多人上来就加 sync.Pool,实测数据给出了另一个答案:
在微秒级 JSON 序列化场景下,sync.Pool 反而增加了 P99 开销。Pool 的 Get/Put 操作本身有锁竞争开销,如果序列化只需要几微秒,这个开销就超过了复用 buffer 的收益。sync.Pool 真正有价值的场景是大 body 解析、protobuf 序列化、模板渲染------堆分配越重,收益越大。
实测 Go 1.26.2 darwin/arm64
单机优化的天花板取决于你的业务复杂度。如果你的服务在第 2 层(串行 IO 叠加),pprof 和 sync.Pool 帮不了你------瓶颈在架构,不在代码。
三、第 2 层:模块化单体------Go 最被低估的架构选择
当单机优化到头了,最常见的建议是"上微服务"。但 Martin Fowler 的 Monolith First 原则说得很清楚:先建单体再考虑微服务,一开始就从零构建微服务的系统几乎都陷入困境。
这是工程智慧,先跑通再演进。但"先建单体"不意味着"永远不演进"。关键问题是:单体和微服务之间,有没有中间态?
有。模块化单体。
进程内调用 vs HTTP 跨服务调用
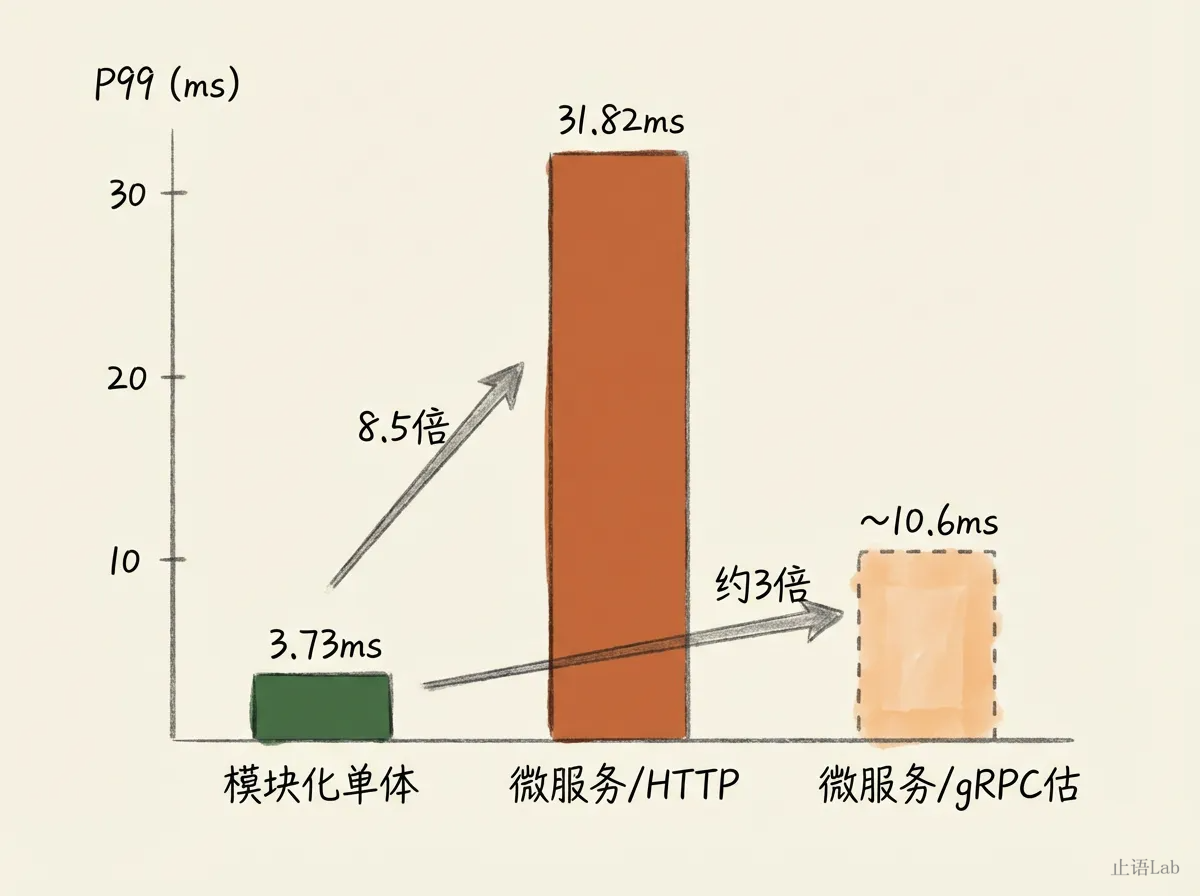
我用 Go 实测了同一个业务逻辑(订单→库存→支付)在两种架构下的延迟:
| 指标 | 模块化单体(进程内) | 微服务(HTTP调用) | 微服务(gRPC估) |
|---|---|---|---|
| P50 | 3.44ms | 4.83ms | ~3.9ms |
| P99 | 3.73ms | 31.82ms | ~10.6ms |
模拟测试 Go 1.26.2 darwin/arm64,time.Sleep 模拟业务处理
本实验用 HTTP 做远程调用基准。gRPC 延迟更低(典型场景约为 HTTP 的 1/3,HTTP/2 多路复用 + Protobuf 二进制编码),P99 差距约为 3 倍而非 8.5 倍------但 3 倍仍然是显著的架构成本。
P50 差异不大,但 P99 差距显著:HTTP 调用慢 8.5 倍,即使换 gRPC 仍慢约 3 倍。3 倍的 P99 差距意味着什么?如果 SLA 要求 P99 < 100ms,模块化单体留给你 96ms 的业务处理时间,gRPC 微服务只留 89ms。越往深处走,余量越薄。
[
Go 做模块化单体有几个语言层面的便利
Go 的 internal 包限制了项目外部的导入,项目内的模块边界主要靠 interface 约定和团队纪律维护。配合 interface 做依赖倒置,进程内事件总线做异步通信,你能在单体内部实现微服务的核心优势(模块独立、接口解耦、异步通信),而无需承担分布式的全部成本。
一个典型的目录结构:
order-service/
├── cmd/ # 启动入口
├── internal/
│ ├── order/ # 订单模块
│ │ ├── handler.go
│ │ └── service.go
│ ├── inventory/ # 库存模块
│ │ ├── handler.go
│ │ └── service.go
│ └── payment/ # 支付模块
│ ├── handler.go
│ └── service.go
├── pkg/ # 公共接口定义
│ └── interfaces.go # InventoryService, PaymentService 接口
└── go.mod关键设计:order 模块不直接依赖 inventory 的实现,而是依赖 pkg/interfaces.go 中的 InventoryService 接口。真正的模块边界在这里------internal 只是辅助手段,pkg/ 下的接口定义才是解耦的保障。启动时通过构造函数注入具体实现。这样,当你需要把 inventory 拆成独立服务时,只需要换一个实现了 InventoryService 接口的 HTTP client------业务代码零改动。
进程内事件总线用 channel 实现即可,不需要引入消息队列:
type EventBus struct {
subscribers map[string][]chan Event
mu sync.RWMutex
}
func (b *EventBus) Publish(topic string, event Event) {
b.mu.RLock()
defer b.mu.RUnlock()
for _, ch := range b.subscribers[topic] {
select {
case ch <- event:
default: // 不阻塞发布者(注意:channel 满时会丢弃事件,生产环境需评估是否可接受)
}
}
}模块化单体是 Go 生态中 10-50 人后端团队在大多数场景下的优选架构,不是过渡妥协。它的成本是单体的成本,收益接近微服务的收益。用 Go 语言特性(internal + interface + channel)实现微服务的解耦效果,用单体的部署成本运行。
什么时候不够?当不同模块的扩展需求差一个数量级以上(如支付模块 QPS 是内容模块的 10 倍),或者不同模块需要独立的部署节奏和 SLA------那时候,把高扩展差异的模块拆出去,其余保持进程内。按需拆,不是全拆。
四、第 3 层:分布式的真实代价
分布式的 ROI:P99 成本比模块化单体贵 3-8 倍,可用性随层数指数衰减,超时传播一个误判就能级联雪崩。
"微服务"三个字听起来很酷。但每多一个服务,你就多了一层网络延迟、多了一份运维开销、多了一个故障点。
超时传播:你以为的优雅可能更危险
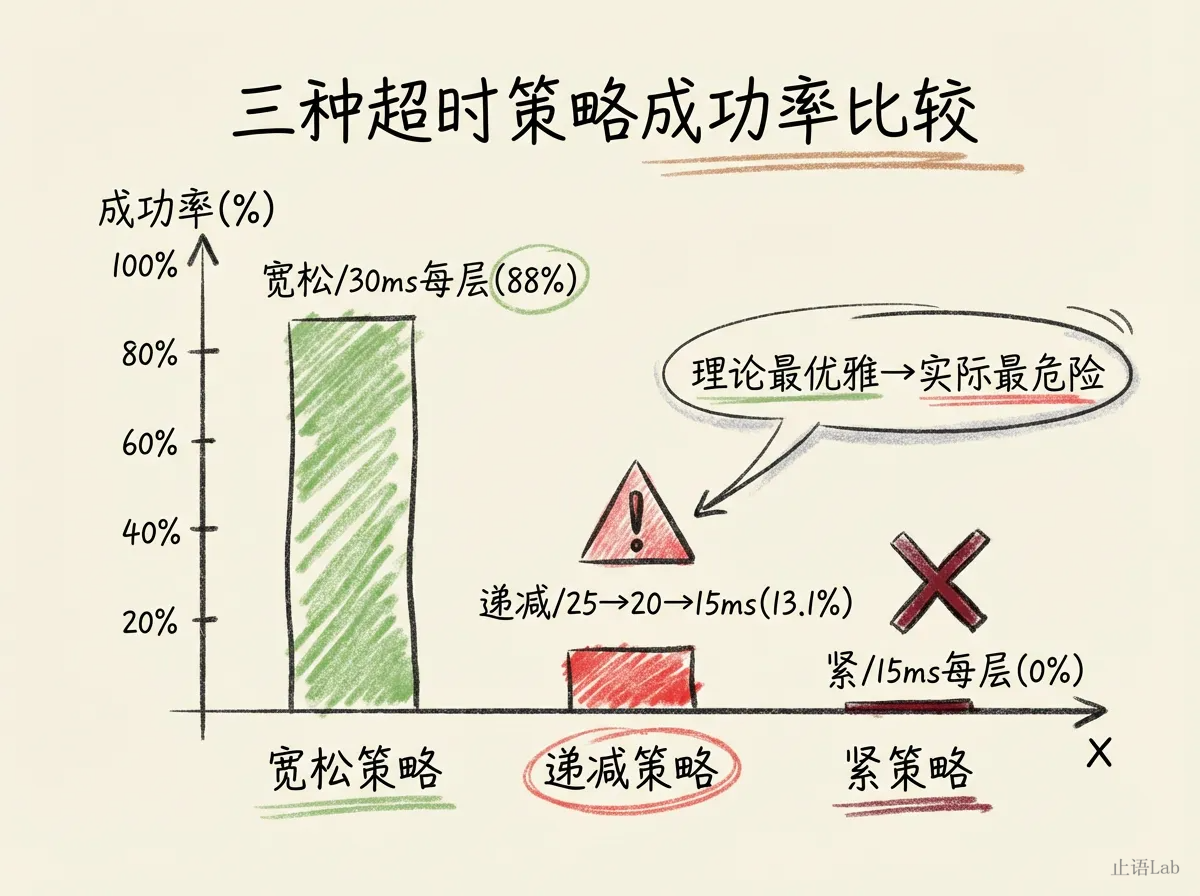
我测了 3 层调用链(Gateway→Service→DataLayer),10% 的请求是慢查询(50ms),比较了三种超时策略:
| 策略 | P50 | P99 | 成功率 |
|---|---|---|---|
| 宽松超时(每层30ms) | 27.81ms | 49.76ms | 88.0% |
| 递减超时(25→20→15ms) | 22.30ms | 1210.97ms | 13.1% |
| 紧超时(每层15ms) | 31.38ms | 1566.34ms | 0.0% |
模拟测试 Go 1.26.2 darwin/arm64,time.Sleep 模拟处理延迟
递减超时------理论上最优雅的策略------成功率只有 13.1%。原因:Gateway 的 25ms 超时不够覆盖整条调用链。这个实验的递减值设定低于下游实际处理时间(含 10% 慢查询 50ms),结果证明的是"对下游处理时间判断不准时递减超时很危险",而非"递减超时本身不可用"。你对下游处理时间的判断哪怕只差几毫秒,级联超时就会把正常请求也杀掉。
核心原则:超时 = 下游预期处理时间 × 2 + 安全余量。宁可宽松也不要误杀------一个慢请求的代价远低于一个被误杀的正常请求。
Go 中最安全的超时传播方式是让上游的 context.Deadline() 自动向下传递:
func gatewayHandler(w http.ResponseWriter, r *http.Request) {
// 上游设定 5s 超时
ctx, cancel := context.WithTimeout(r.Context(), 5*time.Second)
defer cancel()
// 下游自动继承剩余时间,无需手动计算
req, _ := http.NewRequestWithContext(ctx, "GET", serviceURL, nil)
resp, err := client.Do(req)
// ...
}关键:如果上游已经设了 deadline,context.WithTimeout 会自动取较小值------这就是传播。如果上游没有 deadline(如本例),就是在创建。两种情况下游都无需手动计算。ctx.Deadline() 返回的是绝对时间点,Go 标准库帮我们做的正确的事------用 context 传播超时,不要自己算。
可靠性衰减:99.9% ^ N 不是理论
超时之外,熔断器(circuit breaker)和带退避重试是分布式系统的另外两道防线,本文聚焦超时策略。
3 层串联,每层可用性 99.9%,总可用性 = 99.9%³ = 99.7%。换算成月停机时间:约 2 小时。如果每层 99.5%,3 层串联月停机约 11 小时。5 层串联?月停机约 18 小时。
Amazon Prime Video 团队 2023 年做过一个决定:把视频质量分析系统从微服务架构回迁到单体进程。结果:成本降 90%,5% 预期负载即触顶的扩展性问题解决了。他们的场景是高频数据密集交互------跨组件通信开销远超独立扩展收益。注意:不是所有回迁都合理,他们的成功在于识别了通信密集 + 扩展需求同质这个特征。
回迁是演进的闭环:先经历再简化,比一开始就简化更成熟。
分布式单体:拆了但没解耦
最糟糕的状态是"拆了但没解耦"------分布式单体。
一个模拟场景:8 人后端团队,5 个微服务。半夜 payment-service 因 Redis 连接池泄漏 OOM 了,结果 4 个团队的 PagerDuty 全响。改一个"订单列表加预计送达时间"的需求,3 个服务的 API 都要改,部署要协调 3 个团队的发布窗口,上线花了 2 周。首页加载产生 8 次网络调用,P99 = 320ms。
诊断:服务在物理上拆了,逻辑上没解耦。payment-service 是所有业务流的必经节点,order-service 和 inventory-service 通过共享数据库隐式耦合。
模拟场景,基于多个真实案例的共性特征构造
自救方向是"先合再拆"------把高耦合的服务合回一个模块化单体,用 Go interface 做模块边界,等边界清晰了再按需拆。
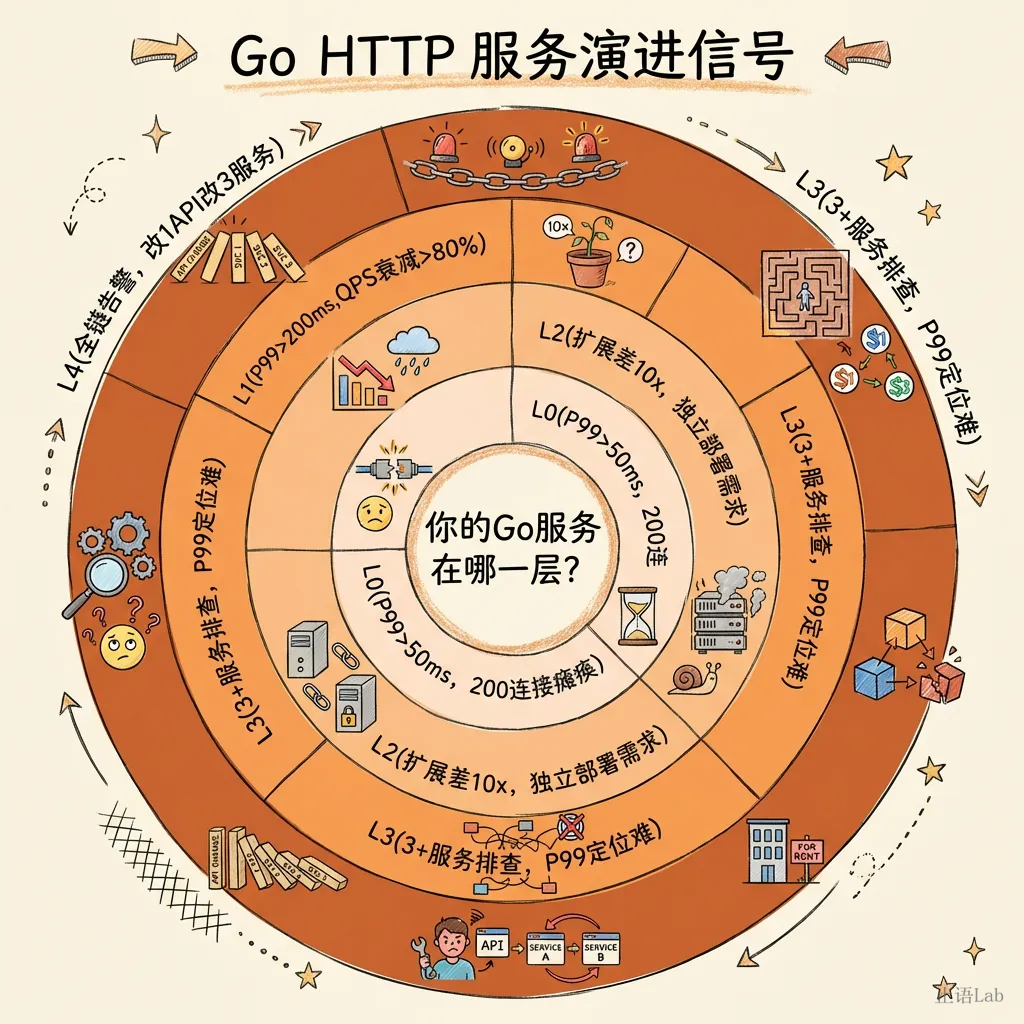
五、第 4 层:演进信号清单------你该往哪一层
前面 4 层讲了"每层是什么、值不值"。最后一层是带走的东西------演进信号清单。当你站在决策路口,这些信号帮你判断该不该往上走。
5 个层级的演进信号
以下阈值基于工程经验和本文模拟测试数据的综合判断,具体值需根据业务场景调整。
你需要开始优化了(第 0 层→第 1 层)
满足任一:
- 默认配置下,100 并发 P99 > 50ms
- 服务器在慢连接攻击下 200 连接即瘫痪
- 内存使用持续增长(goroutine 泄漏嫌疑)
行动:加超时配置,引入 sync.Pool(仅在堆分配重的场景),用 pprof 找瓶颈。
单机优化到头了(第 1 层→第 2 层)
满足 2 个以上:
- 单机 P99 > 200ms 且 GC 优化 2 轮无改善(改善 < 10%)
- 业务复杂度到了串行 IO 叠加层,QPS 衰减超过 80%
- 多个团队争抢同一个 repo 的发布窗口
- 单一故障域:一台机器挂了全挂,且 RTO > 30 分钟
行动:考虑模块化单体------用 Go interface + internal 包做模块边界。
模块边界不够了(第 2 层→第 3 层)
满足 2 个以上:
- 不同模块需要独立扩展(如支付 QPS 是其他模块 10 倍)
- 不同模块需要不同的部署节奏
- 团队超过 15 人,模块间代码冲突频繁
- 某个模块需要独立的 SLA
行动:将高扩展差异的模块拆为独立服务,其余保持进程内。
分布式需要眼睛(第 3 层→可观测性)
满足任一:
- 服务超过 3 个,排查问题需要登录 3+ 台机器看日志
- 一个请求跨 3+ 个服务,P99 异常但不知道卡在哪
- 月度 P0 事故中,"定位慢"是主要瓶颈
行动:引入分布式追踪(OpenTelemetry),统一日志格式,建立服务拓扑图。从0到1的路径:先在网关层加 trace ID 传播,让每个请求有唯一标识;再在慢服务接入 span 采集;最后补齐全链路。
Go 接入 OpenTelemetry 的最小改动:
import (
"context"
"go.opentelemetry.io/otel"
"go.opentelemetry.io/otel/exporters/otlp/otlptrace/otlptracegrpc"
"go.opentelemetry.io/otel/sdk/trace"
)
func initTracer() (*trace.TracerProvider, error) {
exporter, err := otlptracegrpc.New(context.Background(),
otlptracegrpc.WithEndpoint("localhost:4317"),
otlptracegrpc.WithInsecure(),
)
if err != nil {
return nil, err
}
tp := trace.NewTracerProvider(trace.WithBatcher(exporter))
otel.SetTracerProvider(tp) // 全局注册,追踪才会生效
return tp, nil
}一个 trace ID 贯穿整个调用链,在 Jaeger/Zipkin 里能看到每个服务的耗时占比。有了这个,"P99 异常但不知道卡在哪"的问题就不存在了。
你拆过头了(回退信号)
满足 2 个以上:
- 一个服务挂了触发所有服务的告警
- 改一个 API 需要同步改 3+ 个服务
- 首页请求产生 100+ 网络调用
- 运维人力 > 开发人力的 50%
- 团队人均维护 > 3 个服务
行动:合并高耦合服务为模块化单体。回迁是演进的闭环,不是失败。
[
不是所有服务都需要演进到分布式,但每个服务都应该知道自己在哪一层。演进的关键是每一步都算清楚值不值------不必到终点。
从今天开始:检查你的 Go HTTP 服务有没有设超时。如果没设,你已经站在第 0 层的起点了。