一、Jmeter分布式执行原理:
1、Jmeter分布式测试时,选择其中一台作为调度机(master),其它机器做为执行机(slave)。
2、执行时,master会把脚本发送到每台slave上,slave 拿到脚本后就开始执行,slave执行时不需要启动GUI,我理解它应该是通过命令行模式执行的。
3、执行完成后,slave会把结果回传给master,master会收集所有slave的信息并汇总。
二、执行机器(slave)配置:
在执行机上启动jmeter-server.bat
如果需要修改端口,修改properties中
第一个:server_port=xxxx
第二个:server.rmi.localport=xxxx
启动后,执行机这样就算启动成功了,ip和端口号复制下来。

三、调度机器(master)配置:
在调度机上,机器的JMeter安装目录下找到bin目录,再找到jmeter.properties这个文件,使用记事本打开它
查找"remote_host",
remote_hosts=127.0.0.1"其中127.0.0.1代表本机,这里需要修改成这样:
remote_hosts=127.0.0.1, 192.168.1.131:1099,192.168.254.1:1099
多个执行机,就用逗号隔开。如果本机也要运行,可以将本机ip加入进去,本机打开server.bat就行。
然后在jmeter页面进行运行操作
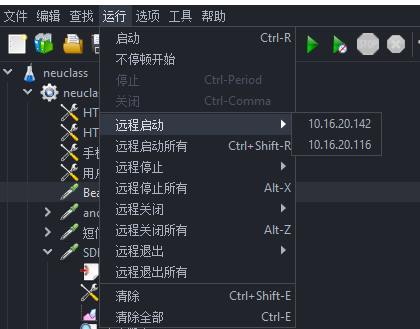
四、注意事项:
1、调度机(master)和执行机(slave)最好分开,由于master需要发送信息给slave并且会接收slave回传回来的测试数据,所以mater自身会有消耗,所以建议单独用一台机器作为mater。
2、参数文件:如果使用csv进行参数化,那么需要把参数文件在每台slave上拷一份且路径需要设置成一样的。可以放在jmeter文件夹中,参数化中可以用...代表bin目录。
3、每台机器上安装的Jmeter版本和插件最好都一致,否则会出一些意外的问题。